
基础知识
操作系统相关
芯片工作的原理
芯片工作的原理简单图示:
图灵机在计算科学有两个巨大的贡献:
1.清楚地定义了计算机能力的边界,也就是可计算理论。
2.定义了计算机由哪些部分组成,程序又是如何执行的。
图灵机的构造
想要学懂程序执行的原理,就要从图灵机说起了。它在计算机科学方面有两个巨大的贡献:
第一,它清楚地定义了计算机能力的边界,也就是可计算理论;
第二,它定义了计算机由哪些部分组成,程序又是如何执行的。
我们先来看一看图灵机的内部构造:
图灵机拥有一条无限长的纸带,纸带上是一个格子挨着一个格子,格子中可以写字符,你可以把纸带看作内存,而这些字符可以看作是内存中的数据或者程序。
图灵机有一个读写头,读写头可以读取任意格子上的字符,也可以改写任意格子的字符。
读写头上面的盒子里是一些精密的零件,包括图灵机的存储、控制单元和运算单元。
图灵机如何执行程序
首先,我们将“11、15、+” 分别写入纸带上的 3 个格子(现在纸带上的字符串是11、15、 +),然后将读写头先停在 11 对应的格子上。
接下来,图灵机通过读写头读入 11 到它的存储设备中(这个存储设备也叫作图灵机的状态)。图灵机没有说读写头为什么可以识别纸带上的字符,而是假定读写头可以做到这点。
然后读写头向右移动一个格,用同样的方法将 15 读入图灵机的状态中。现在图灵机的状态中有两个连续的数字,11 和 15。
接下来重复上面的过程,会读到一个+号。下面我详细说一下这个运算流程:
读写头读到一个 + 号 ;
然后将 + 号传输给控制单元 ;
控制单元发现是一个 + 号,所以没有存入状态中。因为 + 号是一个我们预设的控制符(指令),它的作用是加和目前状态。因此,控制单元识别出是控制符,并通知运算单元工作;
运算单元从状态中读入 11、15 并进行计算,将结果 26 存储到状态;
运算单元将结果回传给控制单元;
控制单元将结果传输给读写头。
读写头向右移动,将结果 26 写入纸带。
这样,我们就通过图灵机计算出了 11+15 的值。不知道你有没有发现,图灵机构造的这一台机器,主要功能就是读写纸带然后计算;纸带中有数据、也有控制字符(也就是指令),这个设计和我们今天的计算机是一样的。
图灵通过数学证明了,一个问题如果可以拆解成图灵机的可执行步骤,那问题就是可计算的。另一方面,图灵机定义了计算机的组成以及工作原理,但是没有给出具体的实现。
冯诺依曼模型
具体的实现是 1945 年冯诺依曼和其他几位科学家在著名的 101 页报告中提出的。报告遵循了图灵机的设计,并提出用电子元件构造计算机,约定了用二进制进行计算和存储,并且将计算机结构分成以下 5 个部分:
输入设备;
输出设备;
内存;
中央处理器;
总线。
这个模型也被称为冯诺依曼模型,下面我们具体来看看这 5 部分的作用。
内存
在冯诺依曼模型中,程序和数据被存储在一个被称作内存的线性排列存储区域。存储的数据单位是一个二进制位,英文是 bit。最小的存储单位叫作字节,也就是 8 位,英文是 byte,每一个字节都对应一个内存地址。内存地址由 0 开始编号,比如第 1 个地址是 0,第 2 个地址是 1, 然后自增排列,最后一个地址是内存中的字节数减 1。
我们通常说的内存都是随机存取器,也就是读取任何一个地址数据的速度是一样的,写入任何一个地址数据的速度也是一样的。
CPU
冯诺依曼模型中 CPU 负责控制和计算。为了方便计算较大的数值,CPU 每次可以计算多个字节的数据。
如果 CPU 每次可以计算 4 个 byte,那么我们称作 32 位 CPU;
如果 CPU 每次可以计算 8 个 byte,那么我们称作 64 位 CPU。
这里的 32 和 64,称作 CPU 的位宽。
为什么 CPU 要这样设计呢? 因为一个 byte 最大的表示范围就是 0~255。比如要计算 20000*50,就超出了byte 最大的表示范围了。因此,CPU 需要支持多个 byte 一起计算。当然,CPU 位数越大,可以计算的数值就越大。但是在现实生活中不一定需要计算这么大的数值。比如说 32 位 CPU 能计算的最大整数是 4294967295,这已经非常大了。
控制单元和逻辑运算单元
CPU 中有一个控制单元专门负责控制 CPU 工作;还有逻辑运算单元专门负责计算。具体的工作原理我们在指令部分给大家分析。
寄存器
CPU 要进行计算,比如最简单的加和两个数字时,因为 CPU 离内存太远,所以需要一种离自己近的存储来存储将要被计算的数字。这种存储就是寄存器。寄存器就在 CPU 里,控制单元和逻辑运算单元非常近,因此速度很快。
寄存器中有一部分是可供用户编程用的,比如用来存加和指令的两个参数,是通用寄存器。
还有一部分寄存器有特殊的用途,叫作特殊寄存器。比如程序指针,就是一个特殊寄存器。它存储了 CPU 要执行的下一条指令所在的内存地址。注意,程序指针不是存储了下一条要执行的指令,此时指令还在内存中,程序指针只是存储了下一条指令的地址。
下一条要执行的指令,会从内存读入到另一个特殊的寄存器中,这个寄存器叫作指令寄存器。指令被执行完成之前,指令都存储在这里。
总线
CPU 和内存以及其他设备之间,也需要通信,因此我们用一种特殊的设备进行控制,就是总线。总线分成 3 种:
一种是地址总线,专门用来指定 CPU 将要操作的内存地址。
还有一种是数据总线,用来读写内存中的数据。
当 CPU 需要读写内存的时候,先要通过地址总线来指定内存地址,再通过数据总线来传输数据。
最后一种总线叫作控制总线,用来发送和接收关键信号,比如后面我们会学到的中断信号,还有设备复位、就绪等信号,都是通过控制总线传输。同样的,CPU 需要对这些信号进行响应,这也需要控制总线。
输入、输出设备
输入设备向计算机输入数据,计算机经过计算,将结果通过输出设备向外界传达。如果输入设备、输出设备想要和 CPU 进行交互,比如说用户按键需要 CPU 响应,这时候就需要用到控制总线。
冯诺依曼模型的几个问题:
1.线路位宽问题
第一个问题是,你可能会好奇数据如何通过线路传递。其实是通过操作电压,低电压是 0,高电压是 1。
如果只有一条线路,每次只能传递 1 个信号,因为你必须在 0,1 中选一个。比如你构造高高低低这样的信号,其实就是 1100,相当于你传了一个数字 10 过去。大家注意,这种传递是相当慢的,因为你需要传递 4 次。
这种一个 bit 一个 bit 发送的方式,我们叫作串行。如果希望每次多传一些数据,就需要增加线路,也就是需要并行。
如果只有 1 条地址总线,那每次只能表示 0-1 两种情况,所以只能操作 2 个内存地址;如果有 10 条地址总线,一次就可以表示 210 种情况,也就是可以操作 1024 个内存地址;如果你希望操作 4G 的内存,那么就需要 32 条线,因为 232 是 4G。
到这里,你可能会问,那我串行发送行不行?当然也不是不行,只是速度会很慢,因为每多增加一条线路速度就会翻倍。
2. 64 位和 32 位的计算
第二个问题是,CPU 的位宽会对计算造成什么影响?
我们来看一个具体场景:要用 32 位宽的 CPU,加和两个 64 位的数字。
32 位宽的 CPU 控制 40 位宽的地址总线、数据总线工作会非常麻烦,需要双方制定协议。 因此通常 32 位宽 CPU 最多操作 32 位宽的地址总线和数据总线。
因此必须把两个 64 位数字拆成 2 个 32 位数字来计算,这样就需要一个算法,比如用像小时候做加法竖式一样,先加和两个低位的 32 位数字,算出进位,然后加和两个高位的 32 位数字,最后再加上进位。
而 64 位的 CPU 就可以一次读入 64 位的数字,同时 64 位的 CPU 内部的逻辑计算单元,也支持 64 位的数字进行计算。但是你千万不要仅仅因为位宽的区别,就认为 64 位 CPU 性能比 32 位高很多。
要知道大部分应用不需要计算超过 32 位的数字,比如你做一个电商网站,用户的金额通常是 10 万以下的,而 32 位有符号整数,最大可以到 20 亿。所以这样的计算在 32 位还是 64 位中没有什么区别。
还有一点要注意,32 位宽的 CPU 没办法控制超过 32 位的地址总线、数据总线工作。比如说你有一条 40 位的地址总线(其实就是 40 条线),32 位的 CPU 没有办法一次给 40 个信号,因为它最多只有 32 位的寄存器。因此 32 位宽的 CPU 最多操作 232 个内存地址,也就是 4G 内存地址。
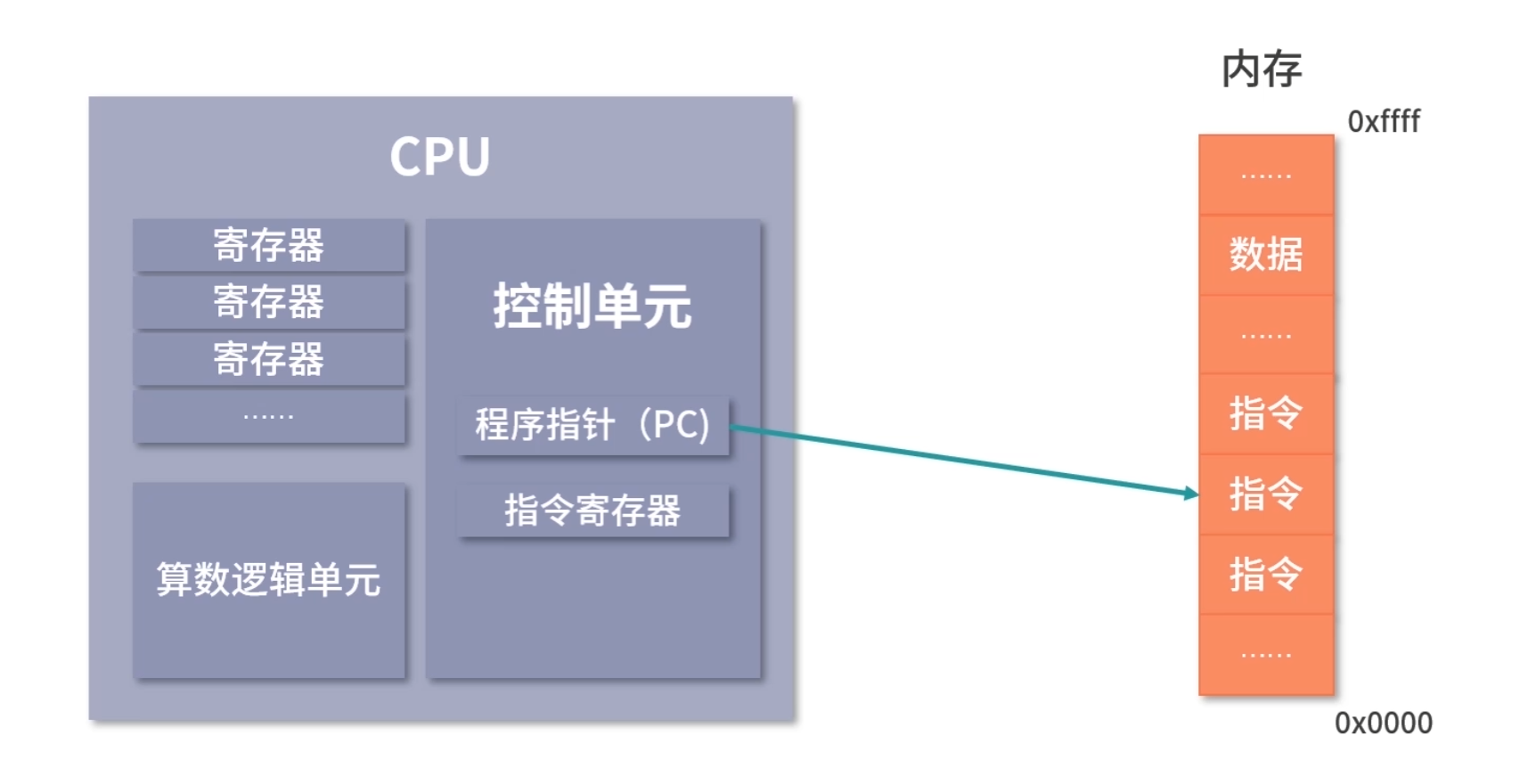
程序的执行过程
当 CPU 执行程序的时候:
1.首先,CPU 读取 PC 指针指向的指令,将它导入指令寄存器。具体来说,完成读取指令这件事情有 3 个步骤:
步骤 1:CPU 的控制单元操作地址总线指定需要访问的内存地址(简单理解,就是把 PC 指针中的值拷贝到地址总线中)。
步骤 2:CPU 通知内存设备准备数据(内存设备准备好了,就通过数据总线将数据传送给 CPU)。
步骤 3:CPU 收到内存传来的数据后,将这个数据存入指令寄存器。
完成以上 3 步,CPU 成功读取了 PC 指针指向指令,存入了指令寄存器。
2.然后,CPU 分析指令寄存器中的指令,确定指令的类型和参数。
3.如果是计算类型的指令,那么就交给逻辑运算单元计算;如果是存储类型的指令,那么由控制单元执行。
4.PC 指针自增,并准备获取下一条指令。
比如在 32 位的机器上,指令是 32 位 4 个字节,需要 4 个内存地址存储,因此 PC 指针会自增 4。
了解了程序的执行过程后,我还有一些问题想和大家一起讨论:
内存虽然是一个随机存取器,但是我们通常不会把指令和数据存在一起,这是为了安全起见。具体的原因我会在模块四进程部分展开讲解,欢迎大家在本课时的留言区讨论起来,我会结合你们留言的内容做后续的课程设计。
程序指针也是一个寄存器,64 位的 CPU 会提供 64 位的寄存器,这样就可以使用更多内存地址。特别要说明的是,64 位的寄存器可以寻址的范围非常大,但是也会受到地址总线条数的限制。比如和 64 位 CPU 配套工作的地址总线只有 40 条,那么可以寻址的范围就只有 1T,也就是 240。
从 PC 指针读取指令、到执行、再到下一条指令,构成了一个循环,这个不断循环的过程叫作CPU 的指令周期,下面我们会详细讲解这个概念。
详解 a = 11 + 15 的执行过程
上面我们了解了基本的程序执行过程,接下来我们来看看如果用冯诺依曼模型执行a=11+15是一个怎样的过程。
我们再 Review 下这个问题:程序员写的程序a=11+15是字符串,CPU 不能执行字符串,只能执行指令。所以这里需要用到一种特殊的程序——编译器。编译器的核心能力是翻译,它把一种程序翻译成另一种程序语言。
这里,我们需要编译器将程序员写的程序翻译成 CPU 认识的指令(指令我们认为是一种低级语言,我们平时书写的是高级语言)。你可以先跟我完整地学完操作系统,再去深入了解编译原理的内容。
下面我们来详细阐述 a=11+15 的执行过程:
1.编译器通过分析,发现 11 和 15 是数据,因此编译好的程序启动时,会在内存中开辟出一个专门的区域存这样的常数,这个专门用来存储常数的区域,就是数据段,如下图所示:
11 被存储到了地址 0x100;
15 被存储到了地址 0x104;
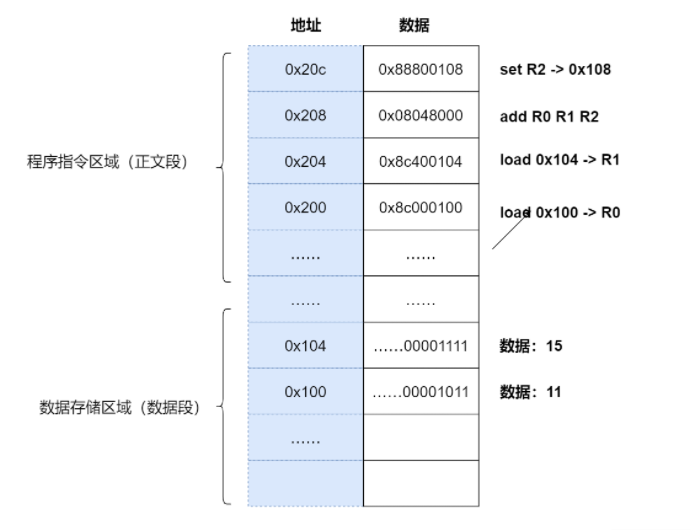
2.编译器将a=11+15转换成了 4 条指令,程序启动后,这些指令被导入了一个专门用来存储指令的区域,也就是正文段。如上图所示,这 4 条指令被存储到了 0x200-0x20c 的区域中:
0x200 位置的 load 指令将地址 0x100 中的数据 11 导入寄存器 R0;
0x204 位置的 load 指令将地址 0x104 中的数据 15 导入寄存器 R1;
0x208 位置的 add 指令将寄存器 R0 和 R1 中的值相加,存入寄存器 R2;
0x20c 位置的 store 指令将寄存器 R2 中的值存回数据区域中的 0x1108 位置。
3.具体执行的时候,PC 指针先指向 0x200 位置,然后依次执行这 4 条指令。
这里还有几个问题要说明一下:
变量 a 实际上是内存中的一个地址,a 是给程序员的助记符。
为什么 0x200 中代表加载数据到寄存器的指令是 0x8c000100,我们会在下面详细讨论。
不知道细心的同学是否发现,在上面的例子中,我们每次操作 4 个地址,也就是 32 位,这是因为我们在用 32 位宽的 CPU 举例。在 32 位宽的 CPU 中,指令也是 32 位的。但是数据可以小于 32 位,比如可以加和两个 8 位的字节。
关于数据段和正文段的内容,会在模块四进程和线程部分继续讲解。
指令
接下来我会带你具体分析指令的执行过程。
在上面的例子中,load 指令将内存中的数据导入寄存器,我们写成了 16 进制:0x8c000100,拆分成二进制就是:
这里大家还是看下图,需要看一下才能明白。

最左边的 6 位,叫作操作码,英文是 OpCode,100011 代表 load 指令;
中间的 4 位 0000是寄存器的编号,这里代表寄存器 R0;
后面的 22 位代表要读取的地址,也就是 0x100。
所以我们是把操作码、寄存器的编号、要读取的地址合并到了一个 32 位的指令中。
我们再来看一条求加法运算的 add 指令,16 进制表示是 0x08048000,换算成二进制就是:
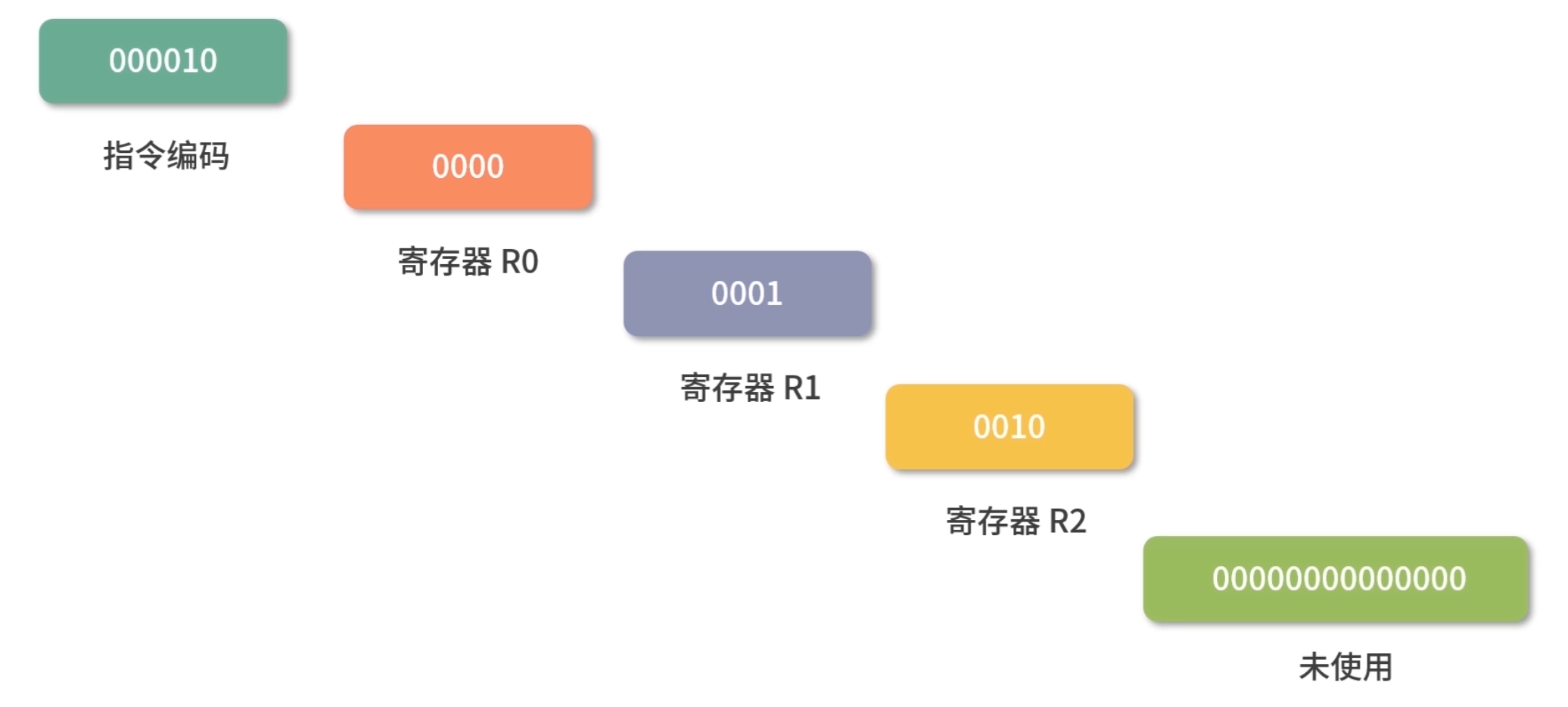
最左边的 6 位是指令编码,代表指令 add;
紧接着的 4 位 0000 代表寄存器 R0;
然后再接着的 4 位 0001 代表寄存器 R1;
再接着的 4 位 0010 代表寄存器 R2;
最后剩下的 14 位没有被使用。
构造指令的过程,叫作指令的编码,通常由编译器完成;解析指令的过程,叫作指令的解码,由 CPU 完成。由此可见 CPU 内部有一个循环:
首先 CPU 通过 PC 指针读取对应内存地址的指令,我们将这个步骤叫作 Fetch,就是获取的意思。
CPU 对指令进行解码,我们将这个部分叫作 Decode。
CPU 执行指令,我们将这个部分叫作 Execution。
CPU 将结果存回寄存器或者将寄存器存入内存,我们将这个步骤叫作 Store。
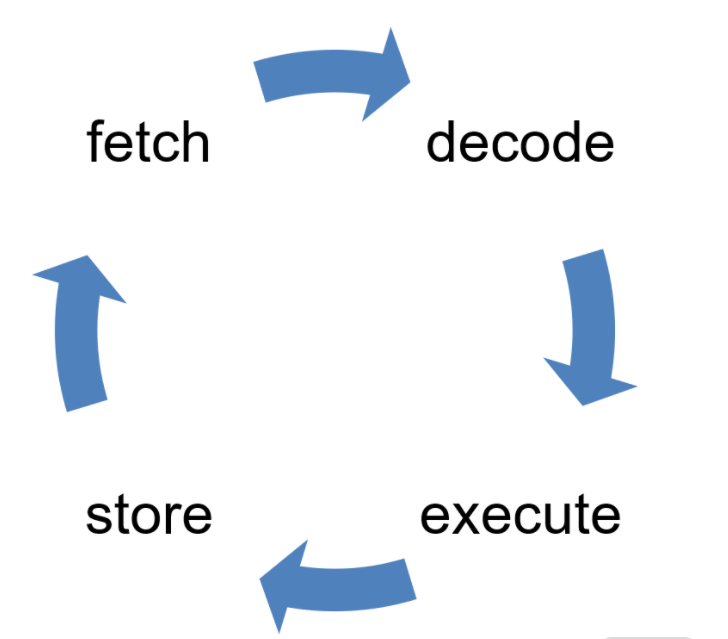
上面 4 个步骤,我们叫作 CPU 的指令周期。CPU 的工作就是一个周期接着一个周期,周而复始。
指令的类型
通过上面的例子,你会发现不同类型(不同 OpCode)的指令、参数个数、每个参数的位宽,都不一样。而参数可以是以下这三种类型:
寄存器;
内存地址;
数值(一般是整数和浮点)。
当然,无论是寄存器、内存地址还是数值,它们都是数字。
指令从功能角度来划分,大概有以下 5 类:
I/O 类型的指令,比如处理和内存间数据交换的指令 store/load 等;再比如将一个内存地址的数据转移到另一个内存地址的 mov 指令。
计算类型的指令,最多只能处理两个寄存器,比如加减乘除、位运算、比较大小等。
跳转类型的指令,用处就是修改 PC 指针。比如编程中大家经常会遇到需要条件判断+跳转的逻辑,比如 if-else,swtich-case、函数调用等。
信号类型的指令,比如发送中断的指令 trap。
闲置 CPU 的指令 nop,一般 CPU 都有这样一条指令,执行后 CPU 会空转一个周期。
指令还有一个分法,就是寻址模式,比如同样是求和指令,可能会有 2 个版本:
将两个寄存器的值相加的 add 指令。
将一个寄存器和一个整数相加的 addi 指令。
另外,同样是加载内存中的数据到寄存器的 load 指令也有不同的寻址模式:
比如直接加载一个内存地址中的数据到寄存器的指令la,叫作直接寻址。
直接将一个数值导入寄存器的指令li,叫作寄存器寻址。
将一个寄存器中的数值作为地址,然后再去加载这个地址中数据的指令lw,叫作间接寻址。
因此寻址模式是从指令如何获取数据的角度,对指令的一种分类,目的是给编写指令的人更多选择。
了解了指令的类型后,我再强调几个细节问题:
关于寻址模式和所有的指令,只要你不是嵌入式开发人员,就不需要记忆,理解即可。
不同 CPU 的指令和寄存器名称都不一样,因此这些名称也不需要你记忆。
有几个寄存器在所有 CPU 里名字都一样,比如 PC 指针、指令寄存器等。
指令的执行速度
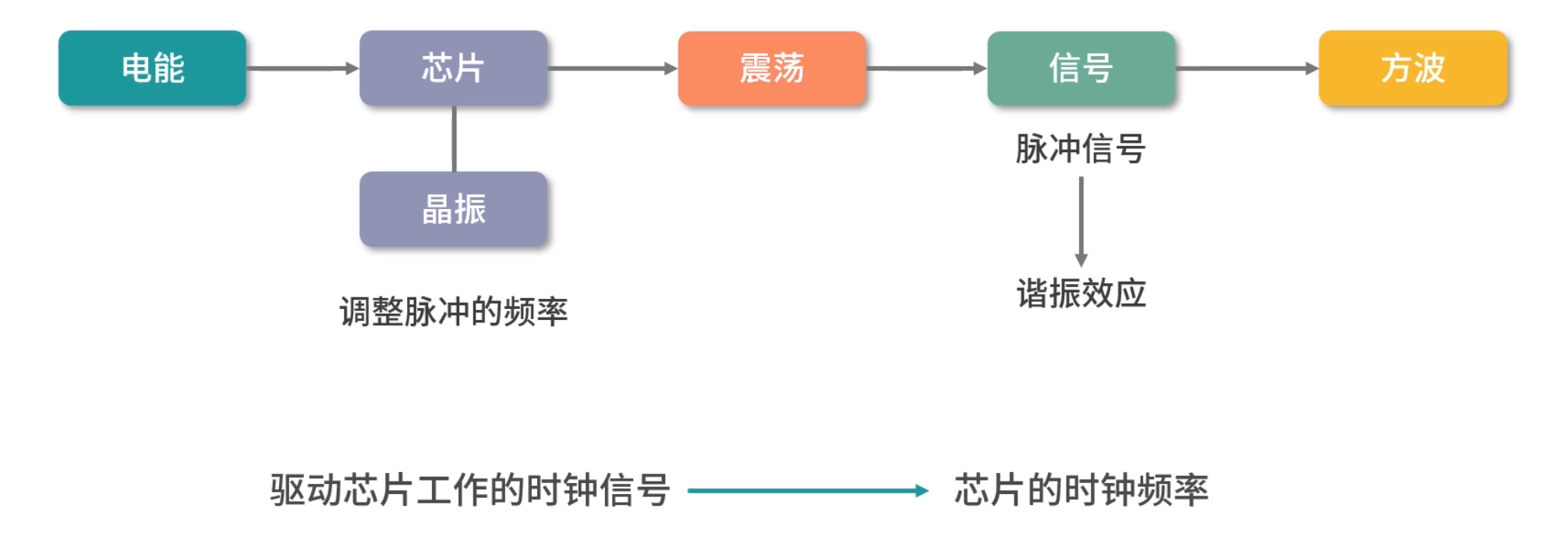
之前我们提到过 CPU 是用石英晶体产生的脉冲转化为时钟信号驱动的,每一次时钟信号高低电平的转换就是一个周期,我们称为时钟周期。CPU 的主频,说的就是时钟信号的频率。比如一个 1GHz 的 CPU,说的是时钟信号的频率是 1G。
到这里你可能会有疑问:是不是每个时钟周期都可以执行一条指令?其实,不是的,多数指令不能在一个时钟周期完成,通常需要 2 个、4 个、6 个时钟周期。
64 位和 32 位比较有哪些优势?
优势 1:64 位 CPU 可以执行更大数字的运算,这个优势在普通应用上不明显,但是对于数值计算较多的应用就非常明显。
优势 2:64 位 CPU 可以寻址更大的内存空间
如果 32 位/64 位说的是程序,那么说的是指令是 64 位还是 32 位的。32 位指令在 64 位机器上执行,困难不大,可以兼容。 如果是 64 位指令,在 32 位机器上执行就困难了。因为 32 位指令在 64 位机器执行的时候,需要的是一套兼容机制;但是 64 位指令在 32 位机器上执行,32 位的寄存器都存不下指令的参数。
操作系统也是一种程序,如果是 64 位操作系统,也就是操作系统中程序的指令都是 64 位指令,因此不能安装在 32 位机器上。
for 循环如何被执行
首先,我们来看 for 循环是如何实现的。
下面是一个求 1 加到 100 的 Java 程序,请你思考如何将它转换为指令:
1 | var i = 1, s = 0; |
经过思考,如果按照顺序执行上面的程序,则需要很多指令,因为 for 循环可以执行 1 次,也可以执行 100W 次,还可以执行无数次。因此,指令的设计者提供了一种 jump 类型的指令,让你可以在程序间跳跃,比如:
1 | loop: |
这就实现了一个无限循环,程序执行到 jumploop 的时候,就会跳回 loop 标签。
用这种方法,我们可以将 for 循环用底层的指令实现:
1 | # var i = 1, s = 0 |
Tips:
- jump 指令直接操作 PC 指针,但是很多 CPU 会抢先执行下一条指令,因此通常我们在 jump 后面要跟随一条 nop 指令,让 CPU 空转一个周期,避免 jump 下面的指令被执行。是不是到了微观世界,和你所认识的程序还不太一样?
- 上面我写指令的时候用到了 add/store 这些指令,它们叫作助记符,是帮助你记忆的。整体这段程序,我们就称作汇编程序。
- 因为不同的机器助记符也不一样,所以你不用太关注我用的是什么汇编语言,也不用去记忆这些指令。当你拿到指定芯片的时候,直接去查阅芯片的说明书就可以了。
- 虽然不同 CPU 的指令不一样,但也是有行业标准的。现在使用比较多的是 RISC(精简指令集)和 CISC(复杂指令集)。比如目前Inte 和 AMD 家族主要使用 CISC 指令集,ARM 和 MIPS 等主要使用RISC 指令集。
条件控制程序
条件控制程序有两种典型代表,一种是 if-else ,另一种是 switch-case 。 总体来说, if-else 翻译成指令,是比较简单的,你需要用跳转指令和比较指令处理它的跳转逻辑。
当然,它们的使用场景不同,这块我不展开了。在这里我主要想跟你说说,它们的内部实现是不一样的。if-else 是一个自上向下的执行逻辑, switch-case是一种精确匹配算法。比如你有 1000 个 case,如果用 if-else 你需要一个个比较,最坏情况下需要比较 999 次;而如果用 switch-case ,就不需要一个个比较,通过算法就可以直接定位到对应的case 。
举个具体的例子,比如一个根据数字返回星期的程序。如果用if-else,那么你需要这样做:
1 | if(week == 1) { |
如果用 switch-case 的逻辑,你可能会这样计算:
1 | 跳转位置=当前PC + 4*(week * 2 - 1) |
函数
了解了循环和条件判断,我们再来看看函数是如何被执行的。函数的执行过程必须深入到底层,也会涉及一种叫作栈的数据结构。
下面是一段 C 程序,传入两个参数,然后返回两个参数的和:
1 | int add(int a, int b){ |
这里我先不说具体的解决方案,希望你可以先自己思考。其实到这里,你已经学了不少知识了。下面我们一起分析一下,一种思考的方向是:
- 通过观察,我们发现函数的参数 a,b 本质是内存中的数据,因此需要给它们分配内存地址。
- 函数返回值也是内存中的数据,也就是返回值也需要分配内存地址。
- 调用函数其实就是跳转到函数体对应的指令所在的位置,因此函数名可以用一个标签,调用时,就用
jump指令跟这个标签。
比如上面函数进行了a+b的运算,我们可以这样构造指令:
1 | # 首先我们定义一个叫作add的标签 |
当我们需要调用这个函数的时候,我们就构造下面这样的指令:
1 | jump add |
细心的同学可能已经发现,这里有 2 个问题还没有解决:
- 参数如何传递给函数?
- 返回值如何传递给调用者?
为了解决这 2 个问题,我们就需要用到前面提到的一个叫作栈的数据结构。栈的英文是 Stack,意思是码放整齐的一堆东西。首先在调用方,我们将参数传递给栈;然后在函数执行过程中,我们从栈中取出参数。
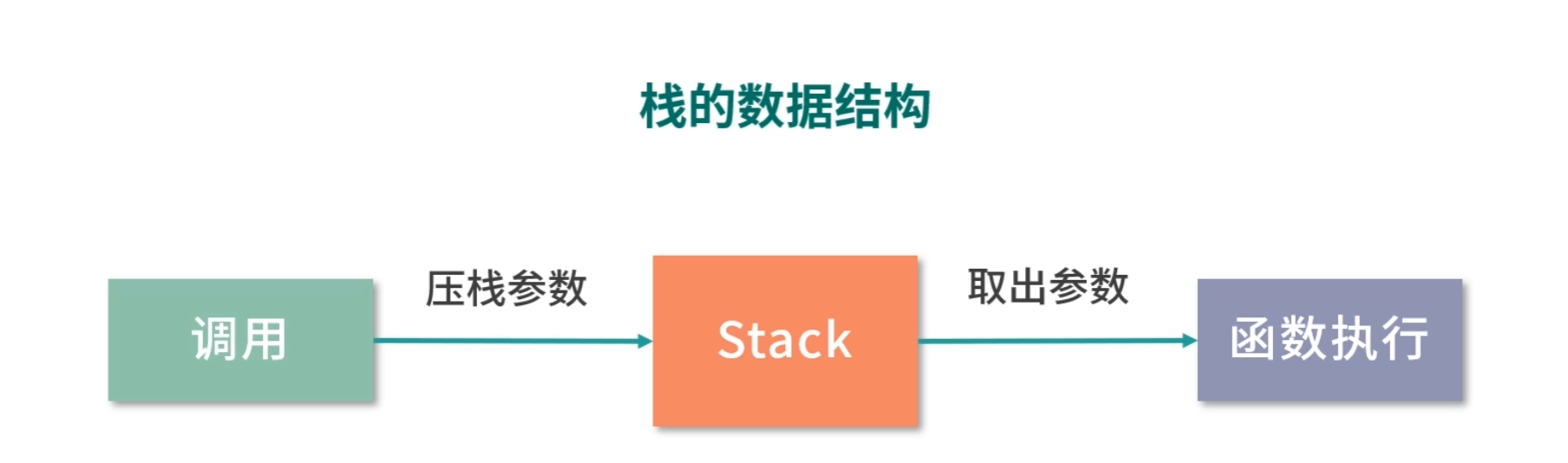
函数执行过程中,先将执行结果写入栈中,然后在返回前把之前压入的参数出栈,调用方再从栈中取出执行结果。
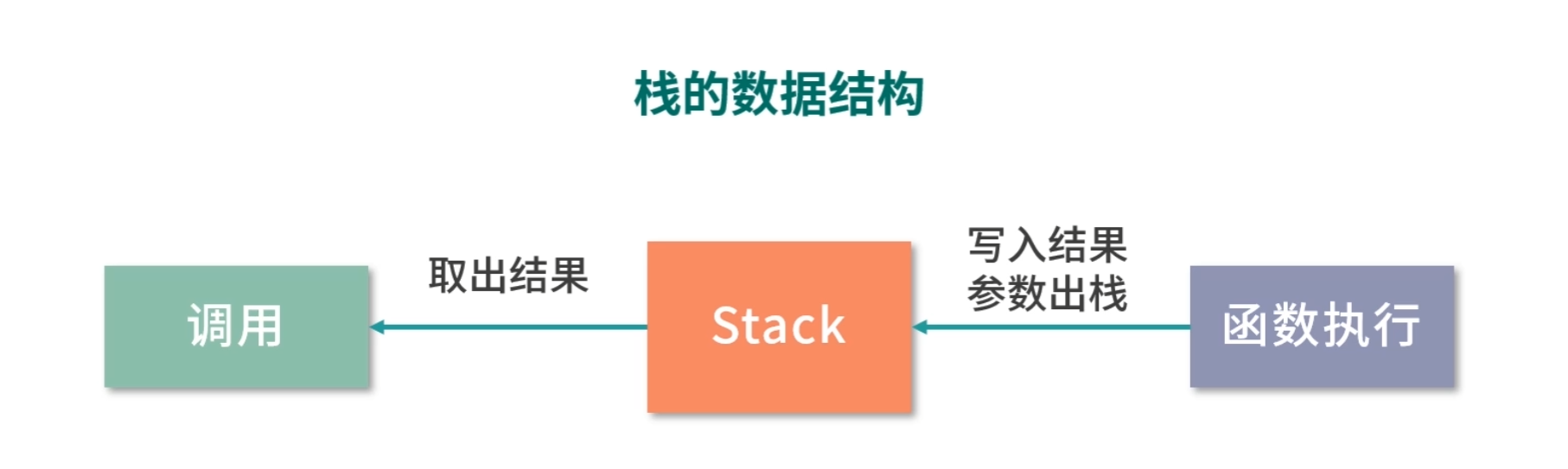
将参数传递给 Stack 的过程,叫作压栈。取出结果的过程,叫作出栈。栈就好像你书桌上的一摞书,压栈就是把参数放到书上面,出栈就是把顶部的书拿下来。
因为栈中的每个数据大小都一样,所以在函数执行的过程中,我们可以通过参数的个数和参数的序号去计算参数在栈中的位置。
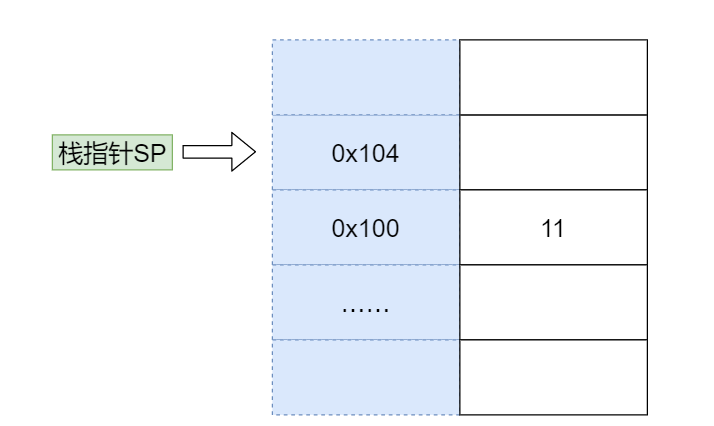
接下来我们来看看函数执行的整体过程:假设要计算 11 和 15 的和,我们首先在内存中开辟一块单独的空间,也就是栈。
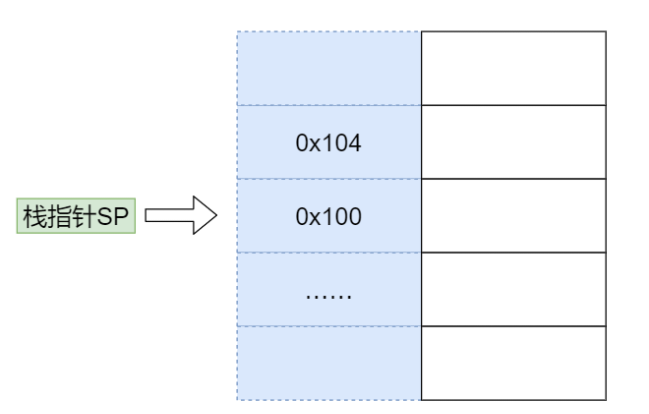
就如前面所讲,栈的使用方法是不断往上堆数据,所以需要一个栈指针(Stack Pointer, SP)指向栈顶(也就是下一个可以写入的位置)。每次将数据写入栈时,就把数据写到栈指针指向的位置,然后将 SP 的值增加。
为了提高效率,我们通常会用一个特殊的寄存器来存储栈指针,这个寄存器就叫作 Stack Pointer,在大多数芯片中都有这个特殊的寄存器。一开始,SP 指向 0x100 位置,而 0x100 位置还没有数据。
- 压栈参数11
接下来我们开始传参,我们先将 11 压栈,之所以称作压栈( Push),就好像我们把数据 11 堆在内存中一样。模拟压栈的过程是下面两条指令:
1 | store #11 -> $SP // 将11存入SP指向的地址0x100 |
第一条 store 指令将 SP 寄存器指向的内存地址设置为常数 11。
第二条指令将栈指针自增 4。
这里用美元符号代表将 11 存入的是 SP 寄存器指向的内存地址,这是一次间接寻址。存入后,栈指针不是自增 1 而是自增了 4,因为我在这里给你讲解时,用的是一个 32 位宽的 CPU 。如果是 64 位宽的 CPU,那么栈指针就需要自增 8。
压栈完成后,内存变成下图中所示的样子。11 被写入内存,并且栈指针指向了 0x104 位置。
- 压栈参数15
然后我们用同样的方法将参数 15 压栈。
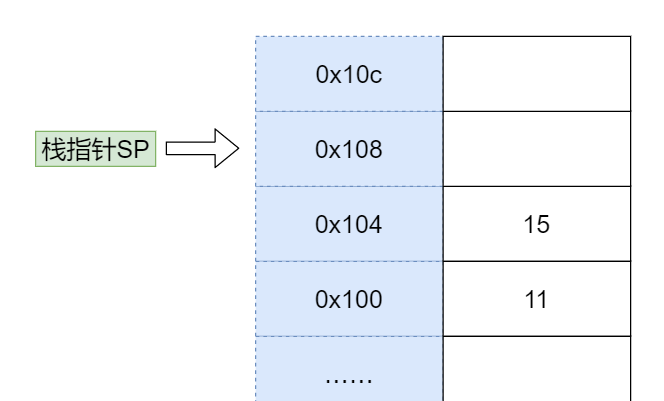
压栈后,11 和 15 都被放入了对应的内存位置,并且栈指针指向了 0x108。
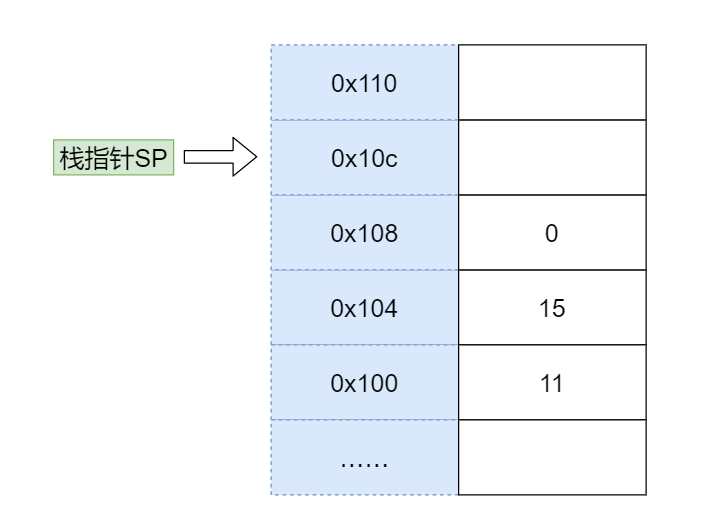
- 将返回值压栈
接下来,我们将返回值压栈。到这里你可能会问,返回值还没有计算呢,怎么就压栈了?其实这相当于一个占位,后面我们会改写这个地址。
- 调用函数
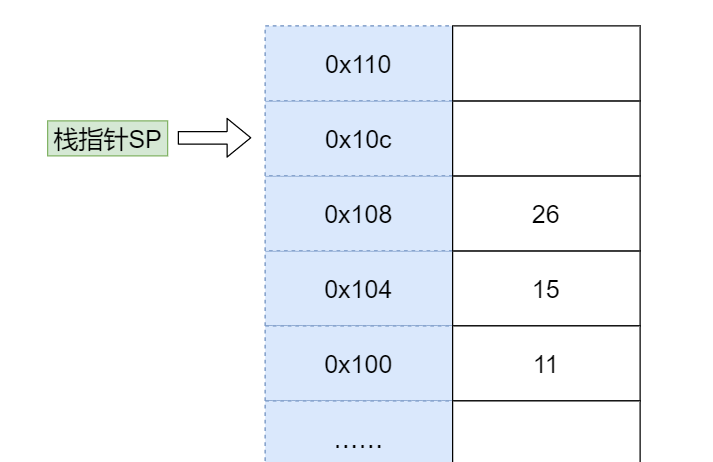
当我们完成了上面的压栈后,就开始调用函数,一种简单的做法是用 jump 指令直接跳转到函数的标签,比如:
1 | jump add |
这个时候,要加和在栈中的数据 11 和 15,我们可以利用 SP 指针寻找数据。11 距离当前 SP 指针差 3 个位置,15 距离 SP 指针差 2 个位置。这种寻址方式是一种复合的寻址方式,是间接 + 偏移量寻址。
我们可以用下面的代码完成将 11 和 15 导入寄存器的过程:
1 | load $(SP - 12) -> R0 |
然后进行加和,将结果存入 R2。
1 | load R0 R1 R2 |
最后我们可以再次利用数学关系将结果写入返回值所在的位置。
1 | store R2 -> $(SP-4) |
上面我们用到了一种间接寻址的方式来进行加和运算,也就是利用 SP 中的地址做加减法操作内存。
经过函数调用的结果如下图所示,运算结果 26 已经被写入了返回值的位置:
- 发现-解决问题
一个好的解决方案,也会面临问题。现在我们就遇到了麻烦:
- 函数计算完成,这时应该跳转回去。可是我们没有记录函数调用前 PC 指针的位置,因此这里需要改进,我们需要存储函数调用前的 PC 指针方便调用后恢复。
- 栈不可以被无限使用,11和 15 作为参数,计算出了结果 26,那么它们就可以清空了。如果用调整栈指针的方式去清空,我们就会先清空 26。此时就会出现顺序问题,因此我们需要调整压栈的顺序。
具体顺序你可以看下图。首先,我们将函数参数和返回值换位,这样在清空数据的时候,就会先清空参数,再清空返回值。

然后我们在调用函数前,还需要将返回地址压栈。这样在函数计算完成前,就能跳转回对应的返回地址。翻译成指令,就是下面这样:
1 |
|
递归函数如何被执行
我们刚刚使用了栈解决了函数的调用问题。但是这个方案究竟合不合理,还需要用更复杂的情况来验证。
如下所示,我们给出一个递归函数,请你判断是否可以用上面的方法执行:
1 | int sum(int n){ |
递归的时候,我们每次执行函数都形成一个如下所示的栈结构:

比如执行 sum(100),我们就会形成一个复杂的栈,第一次调用 n = 100,第二次递归调用 n = 99:

它们堆在了一起,就形成了一个很大的栈,简化一下就是这样的一个模型,如下所示:

到这里,递归消耗了更多空间,但是也保证了中间计算的独立性。当递归执行到 100 次的时候,就会执行下面的语句:
1 | if(n == 1) {return 1;} |
于是触发第 99 次递归执行:
1 | return 2 + sum(1) // sum(1) = 1 |
上面程序等价于return 3,接着再触发第 98 次递归的执行,然后是第 97 次,最终触发到第一次函数调用返回结果。
由此可见,栈这种结构同样适合递归的计算。事实上,计算机编程语言就是用这种结构来实现递归函数。
类型(class)如何实现
按照我们之前已经学习到的知识:
- 变量是一个内存地址,所以只需要分配内存就好了;
- 循环控制可以用跳转加判断实现;
- 条件控制也可以用跳转加判断实现,只不过如果是
switch-case还需要一定的数学计算; - 函数调用需要压栈参数、返回值和返回地址。
最后,我们来说说类型是如何实现的,也就是很多语言都支持的 class 如何被翻译成指令。其实 class 实现非常简单,首先一个 class 会分成两个部分,一部分是数据(也称作属性),另一部分是函数(也称作方法)。
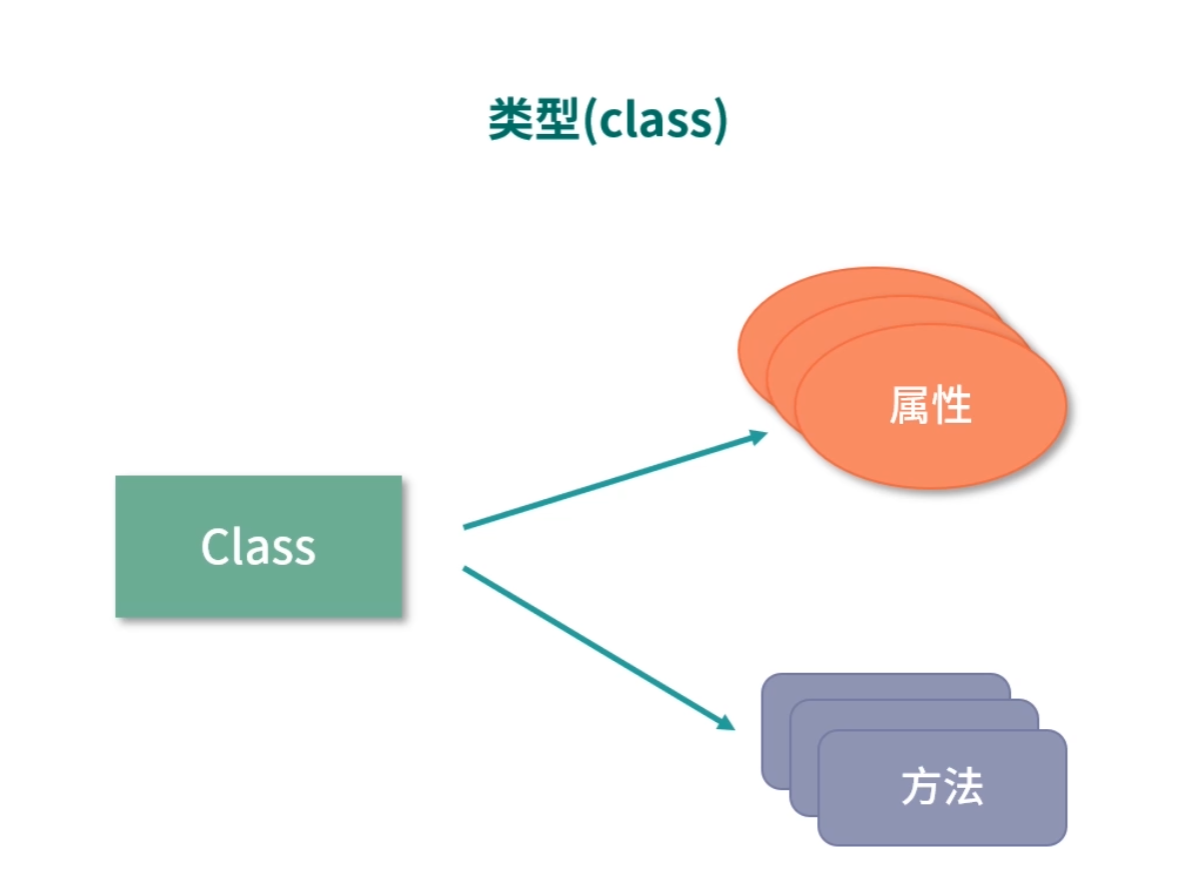
class 有一个特殊的方法叫作构造函数,它会为 class 分配内存。构造函数执行的时候,开始扫描类型定义中所有的属性和方法。
- 如果遇到属性,就为属性分配内存地址;
- 如果遇到方法,方法本身需要存到正文段(也就是程序所在的内存区域),再将方法的值设置为方法指令所在的内存地址。
当我们调用一个 class 方法的时候,本质上是执行了一个函数,因此和函数调用是一致的:
- 首先把返回值和返回地址压栈;
- 然后压栈参数;
- 最后执行跳转。
这里有一个小问题,有时候 class 的方法会用到this ,这其实并不复杂,你仔细想想, this指针不就是构造函数创建的一个指向 class 实例的地址吗?那么,有一种简单的实现,就是我们可以把 this 作为函数的第一个参数压栈。这样,类型的函数就可以访问类型的成员了,而类型也就可以翻译成指令了。
下面我们做一个简单的总结:
- 我们写的程序需要翻译成指令才能被执行,在前面中我们提到过,这个翻译工具叫作编译器。
- 平时你编程做的事情,用机器指令也能做,所以从计算能力上来说它们是等价的,最终这种计算能力又和图灵机是等价的。如果一个语言的能力和图灵机等价,我们就说这个语言是图灵完备的语言。现在市面上的绝大多数语言都是图灵完备的语言,但也有一些不是,比如 HTML、正则表达式和 SQL 等。
- 我们通过汇编语言构造高级程序;通过高级程序构造自己的业务逻辑,这些都是工程能力的一种体现。
一个程序语言如果不支持递归函数的话,该如何实现递归算法?
- 我们需要用到一个栈(其实用数组就可以);
- 我们还需要一个栈指针,支持寄存器的编程语言能够直接用寄存器,而不支持直接用寄存器的编程语言,比如 Java,我们可以用一个变量;
- 然后我们可以实现压栈、出栈的操作,并按照上面学习的函数调用方法操作我们的栈。
为什么会有存储器分级策略?
要想弄清楚存储器分级策略。
首先,你要弄清楚,“我们希望存储器是什么样子的”,也就是“我们的需求是什么”?
然后,你要弄清楚,我们的需求有哪些“实现约束”。
从需求上讲,我们希望存储器速度快、体积小、空间大、能耗低、散热好、断电数据不丢失。但在现实中,我们往往无法把所有需求都实现。
下面我们举几个例子,带你深入体会一下,比如:
- 如果一个存储器的体积小,那它存储空间就会受到制约。
- 如果一个存储器电子元件密度很大,那散热就会有问题。因为电子元件都会产生热能,所以电子元件非常集中的 CPU,就需要单独的风扇或者水冷帮助电子元件降温。
- 如果一个存储器离 CPU 较远,那么在传输过程中必然会有延迟,因此传输速度也会下降。
这里你可能会有疑问,因为在大多数人的认知里,光速是很快的,而信号又是以光速传输的。既然光速这么快,那信号的延迟应该很小才对。但事实并不是这样,比如时钟信号是 1GHz 的 CPU,1G 代表 10 个亿,因此时钟信号的一个周期是 1/10 亿秒。而光的速度是 3×10 的 8 次方米每秒,就是 3 亿米每秒。所以在一个周期内,光只能前进 30 厘米。
你看!虽然在宏观世界里光速非常快,但是到计算机世界里,光速并没有像我们认知中的那么快。所以即使元件离 CPU 的距离稍微远了一点,运行速度也会下降得非常明显。
你可能还会问,那干吗不把内存放到 CPU 里?
如果你这么做的话,除了整个电路散热和体积会出现问题,服务器也没有办法做定制内存了。也就是说 CPU 在出厂时就决定了它的内存大小,如果你想换更大的内存,就要换 CPU,而组装定制化是你非常重要的诉求,这肯定是不能接受的。
此外,在相同价格下,一个存储器的速度越快,那么它的能耗通常越高。能耗越高,发热量越大。
因此,我们上面提到的需求是不可能被全部满足的,除非将来哪天存储技术有颠覆性的突破。
存储器分级策略
既然我们不能用一块存储器来解决所有的需求,那就必须把需求分级。
一种可行的方案,就是根据数据的使用频率使用不同的存储器:高频使用的数据,读写越快越好,因此用最贵的材料,放到离 CPU 最近的位置;使用频率越低的数据,我们放到离 CPU 越远的位置,用越便宜的材料。

具体来说,通常我们把存储器分成这么几个级别:
- 寄存器;
- L1-Cache;
- L2-Cache;
- L3-Cahce;
- 内存;
- 硬盘/SSD。
寄存器(Register)
寄存器紧挨着 CPU 的控制单元和逻辑计算单元,它所使用的材料速度也是最快的。就像我们前面讲到的,存储器的速度越快、能耗越高、产热越大,而且花费也是最贵的,因此数量不能很多。
寄存器的数量通常在几十到几百之间,每个寄存器可以用来存储一定字节(byte)的数据。比如:
- 32 位 CPU 中大多数寄存器可以存储 4 个字节;
- 64 位 CPU 中大多数寄存器可以存储 8 个字节。
寄存机的访问速度非常快,一般要求在半个 CPU 时钟周期内完成读写。比如一条要在 4 个周期内完成的指令,除了读写寄存器,还需要解码指令、控制指令执行和计算。如果寄存器的速度太慢,那 4 个周期就可能无法完成这条指令了。
L1-Cache
L1- 缓存在 CPU 中,相比寄存器,虽然它的位置距离 CPU 核心更远,但造价更低。通常 L1-Cache 大小在几十 Kb 到几百 Kb 不等,读写速度在 2~4 个 CPU 时钟周期。
L2-Cache
L2- 缓存也在 CPU 中,位置比 L1- 缓存距离 CPU 核心更远。它的大小比 L1-Cache 更大,具体大小要看 CPU 型号,有 2M 的,也有更小或者更大的,速度在 10~20 个 CPU 周期。
L3-Cache
L3- 缓存同样在 CPU 中,位置比 L2- 缓存距离 CPU 核心更远。大小通常比 L2-Cache 更大,读写速度在 20~60 个 CPU 周期。L3 缓存大小也是看型号的,比如 i9 CPU 有 512KB L1 Cache;有 2MB L2 Cache; 有16MB L3 Cache。
内存
内存的主要材料是半导体硅,是插在主板上工作的。因为它的位置距离 CPU 有一段距离,所以需要用总线和 CPU 连接。因为内存有了独立的空间,所以体积更大,造价也比上面提到的存储器低得多。现在有的个人电脑上的内存是 16G,但有些服务器的内存可以到几个 T。内存速度大概在 200~300 个 CPU 周期之间。
SSD 和硬盘
SSD 也叫固态硬盘,结构和内存类似,但是它的优点在于断电后数据还在。内存、寄存器、缓存断电后数据就消失了。内存的读写速度比 SSD 大概快 10~1000 倍。以前还有一种物理读写的磁盘,我们也叫作硬盘,它的速度比内存慢 100W 倍左右。因为它的速度太慢,现在已经逐渐被 SSD 替代。
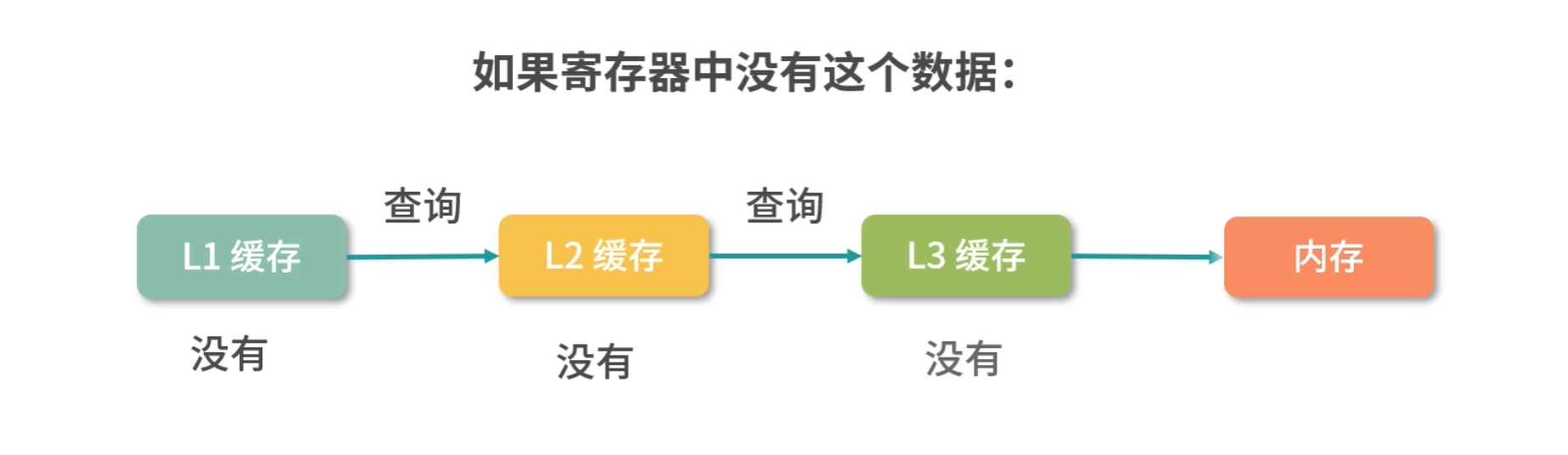
当 CPU 需要内存中某个数据的时候,如果寄存器中有这个数据,我们可以直接使用;如果寄存器中没有这个数据,我们就要先查询 L1 缓存;L1 中没有,再查询 L2 缓存;L2 中没有再查询 L3 缓存;L3 中没有,再去内存中拿。
缓存条目结构
上面我们介绍了存储器分级结构大概有哪些存储以及它们的特点,接下来还有一些缓存算法和数据结构的设计困难要和你讨论。比如 CPU 想访问一个内存地址,那么如何检查这个数据是否在 L1- 缓存中?换句话说,缓存中的数据结构和算法是怎样的?
无论是缓存,还是内存,它们都是一个线性存储器,也就是数据一个挨着一个的存储。如果我们把内存想象成一个只有 1 列的表格,那么缓存就是一个多列的表格,这个表格中的每一行叫作一个缓存条目。
方案 1
缓存本质上是一个 Key-Value 的存储,它的 Key 是内存地址,值是缓存时刻内存地址中的值。我们先思考一种简单的方案,一个缓存条目设计 2 列:
- 内存的地址;
- 缓存的值。
CPU 读取到一个内存地址,我们就增加一个条目。当我们要查询一个内存地址的数据在不在 L1- 缓存中的时候,可以遍历每个条目,看条目中的内存地址是否和查询的内存地址相同。如果相同,我们就取出条目中缓存的值。
这个方法需要遍历缓存中的每个条目,因此计算速度会非常慢,在最坏情况下,算法需要检查所有的条目,所以这不是一个可行的方案。
方案 2
其实很多优秀的方案,往往是从最笨的方案改造而来的。现在我们已经拥有了一个方案,但是这个方案无法快速确定一个内存地址缓存在哪一行。因此我们想要找到一个更好的方法,让我们看到一个内存地址,就能够快速知道它在哪一行。
这里,我们可以用一个数学的方法。比如有 1000 个内存地址,但只有 10 个缓存条目。内存地址的编号是 0、1、2、3,…,999,缓存条目的编号是 0~9。我们思考一个内存编号,比如 701,然后用数学方法把它映射到一个缓存条目,比如 701 整除 10,得到缓存条目 1。
用这种方法,我们每次拿到一个内存地址,都可以快速确定它的缓存条目;然后再比较缓存条目中的第一列内存地址和查询的内存地址是否相同,就可以确定内存地址有没有被缓存。
延伸一下,这里用到了一种类似哈希表的方法:地址 % 10,其实就构成了一个简单的哈希函数。
指令的预读
接下来我们讨论下指令预读的问题。
之前我们学过,CPU 顺序执行内存中的指令,CPU 执行指令的速度是非常快的,一般是 26 个 CPU 时钟周期;这节课,我们学习了存储器分级策略,发现内存的读写速度其实是非常慢的,大概有 200300 个时钟周期。
不知道你发现没有?这也产生了一个非常麻烦的问题:CPU 其实是不能从内存中一条条读取指令再执行的,如果是这样做,那每执行一条指令就需要 200~300 个时钟周期了。
那么,这个问题如何处理呢?
这里我再多说一句,你在做业务开发 RPC 调用的时候,其实也会经常碰到这种情况,远程调用拖慢了整体执行效率,下面我们一起讨论这类问题的解决方案。
一个解决办法就是 CPU 把内存中的指令预读几十条或者上百条到读写速度较快的 L1- 缓存中,因为 L1- 缓存的读写速度只有 2~4 个时钟周期,是可以跟上 CPU 的执行速度的。
这里又产生了另一个问题:如果数据和指令都存储在 L1- 缓存中,如果数据缓存覆盖了指令缓存,就会产生非常严重的后果。因此,L1- 缓存通常会分成两个区域,一个是指令区,一个是数据区。
与此同时,又出现了一个问题,L1- 缓存分成了指令区和数据区,那么 L2/L3 需不需要这样分呢?其实,是不需要的。因为 L2 和 L3,不需要协助处理指令预读的问题。
缓存的命中率
接下来,还有一个重要的问题需要解决。就是 L1/L2/L3 加起来,缓存的命中率有多少?
所谓命中就是指在缓存中找到需要的数据。和命中相反的是穿透,也叫 miss,就是一次读取操作没有从缓存中找到对应的数据。
据统计,L1 缓存的命中率在 80% 左右,L1/L2/L3 加起来的命中率在 95% 左右。因此,CPU 缓存的设计还是相当合理的。只有 5% 的内存读取会穿透到内存,95% 都能读取到缓存。 这也是为什么程序语言逐渐取消了让程序员操作寄存器的语法,因为缓存保证了很高的命中率,多余的优化意义不大,而且很容易出错。
缓存置换问题
最后的一个问题,比如现在 L1- 缓存条目已经存满了,接下来 CPU 又读了内存,需要把一个新的条目存到 L1- 缓存中,既然有一个新的条目要进来,那就有一个旧的条目要出去。所以,这个时候我们就需要用一个算法去计算哪个条目应该被置换出去。这个问题叫作缓存置换问题。有关缓存置换问题,我会在 “21 | 进程的调度:进程调度都有哪些方法?”中和你讨论。
SSD、内存和 L1 Cache 相比速度差多少倍?
【解析】 因为内存比 SSD 快 101000 倍,L1 Cache 比内存快 100 倍左右。因此 L1 Cache 比 SSD 快了 1000100000 倍。所以你有没有发现 SSD 的潜力很大,好的 SSD 已经接近内存了,只不过造价还略高。
这个问题告诉我们,不同的存储器之间性能差距很大,构造存储器分级很有意义,分级的目的是要构造缓存体系。
存不存在一个通用函数判断另一个函数是否会停止?
假设存在一个函数willStop, 它只有一个参数func,willStop可以判断任意函数func是否会停止。

存在这么一个悖论,所以这个问题是不可计算问题。
假设一个维维数组,总共有1M个条目,如果我们要遍历这个二维数组,应该逐行遍历还是逐列遍历?
首先要知道,二维数组在内存中的排列情况,
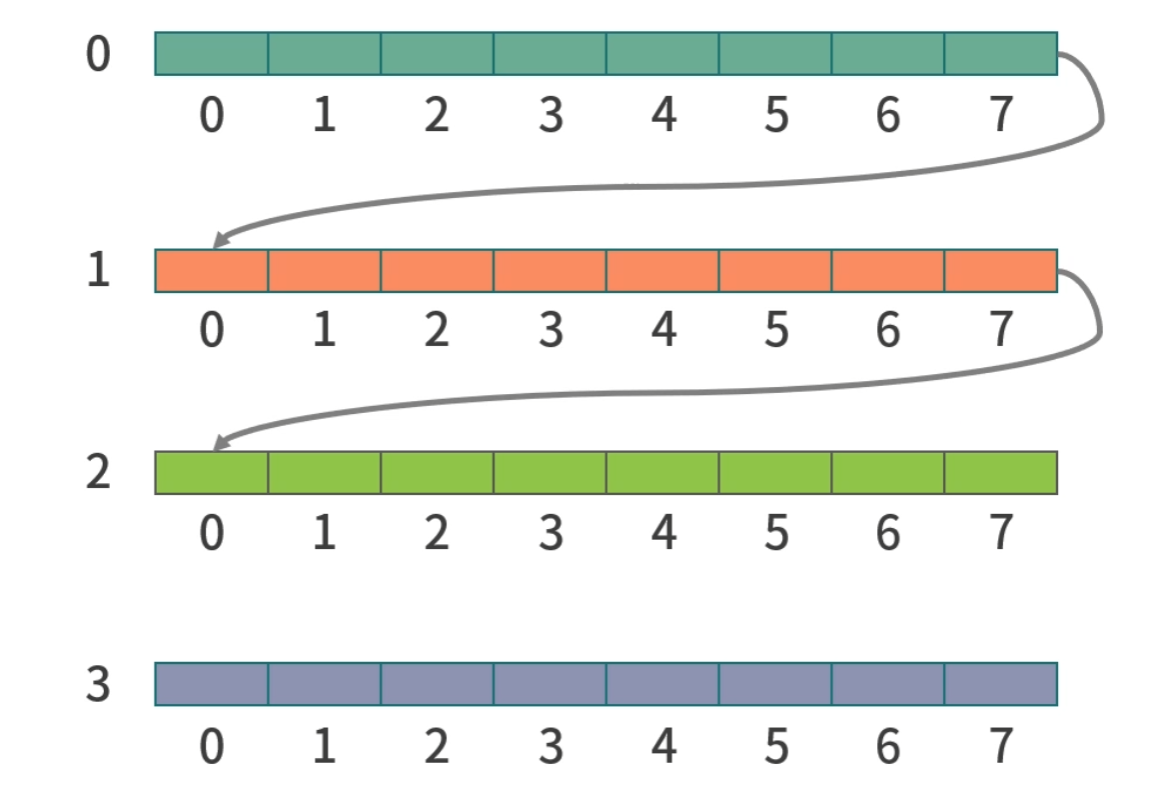
本质上还是一位数组的一个状态,只不过每行是连续的,由多个连续内存拼接在一起。
当CPU遍历二维数组的时候,存在一个预读取的操作,我们按行读取的话,会利用这个机制,并且,当我们在读取内存地址比较跳跃的数据的时候,会触发CPU的一个分页操作,更加增加了开销,降低了效率。
这里我比较好奇,就用Java实现了一个两种不同的遍历方式,逻辑比较简陋,属于是够用就好,结果一起附上。
什么是 Shell 和 Bash
在我们学习 Linux 指令之前,先来说一下什么是 Shell?Shell 把我们输入的指令,传递给操作系统去执行,所以 Shell 是一个命令行的用户界面。
早期程序员没有图形界面用,就用 Shell。而且图形界面制作成本较高,不能实现所有功能,因此今天的程序员依然在用 Shell。
你平时还经常会看到一个词叫作bash(Bourne Again Shell),它是用 Shell 组成的程序。这里的 Bourne 是一个人名,Steve Bourne 是 bash 的发明者。
几种常见的文件类型
另一方面,Linux 下的目录也是一种文件;但是文件也不只有目录和可执行文件两种。常见的文件类型有以下 7 种:
- 普通文件(比如一个文本文件);
- 目录文件(目录也是一个特殊的文件,它用来存储文件清单,比如
/也是一个文件); - 可执行文件(上面的
rm就是一个可执行文件); - 管道文件(我们会在 07 课时讨论管道文件);
- Socket 文件(我们会在模块七网络部分讨论 Socket 文件);
- 软链接文件(相当于指向另一个文件所在路径的符号);
- 硬链接文件(相当于指向另一个文件的指针,关于软硬链接我们将在模块六文件系统部分讨论)。
你如果使用ls -F就可以看到当前目录下的文件和它的类型。比如下面这种图:
- * 结尾的是可执行文件;
- = 结尾的是 Socket 文件;
- @ 结尾的是软链接;
- | 结尾的管道文件;
- 没有符号结尾的是普通文件;
- / 结尾的是目录。

more
more可以帮助我们读取文件,但不需要读取整个文件到内存中。本身more的定位是一个阅读过滤器,比如你在more里除了可以向下翻页,还可以输入一段文本进行搜索。
less
less是一个和more功能差不多的工具,打开man能够看到less的介绍上写着自己是more的反义词(opposite of more)。这样你可以看出linux生态其实也是很自由的一个生态,在这里创造工具也可以按照自己的喜好写文档。less支持向上翻页,这个功能more是做不到的。所以现在less用得更多一些。
head/tail
head和tail是一组,它们用来读取一个文件的头部 N 行或者尾部 N 行。比如一个线上的大日志文件,当线上出了 bug,服务暂停的时候,我们就可以用tail -n 1000去查看最后的 1000 行日志文件,寻找导致服务异常的原因。
另一个比较重要的用法是,如果你想看一个实时的nginx日志,可以使用tail -f 文件名,这样你会看到用户的请求不断进来。查一下man,你会发现-f是 follow 的意思,就是文件追加的内容会跟随输出到标准输出流。
grep
有时候你需要查看一个指定ip的nginx日志,或者查看一段时间内的nginx日志。如果不想用less和more进入文件中去查看,就可以用grep命令。Linux 的文件命名风格都很短,所以也影响了很多人,比如之前我看到过一个大牛的程序,变量名从来不超过 5 个字母,而且都有意义。
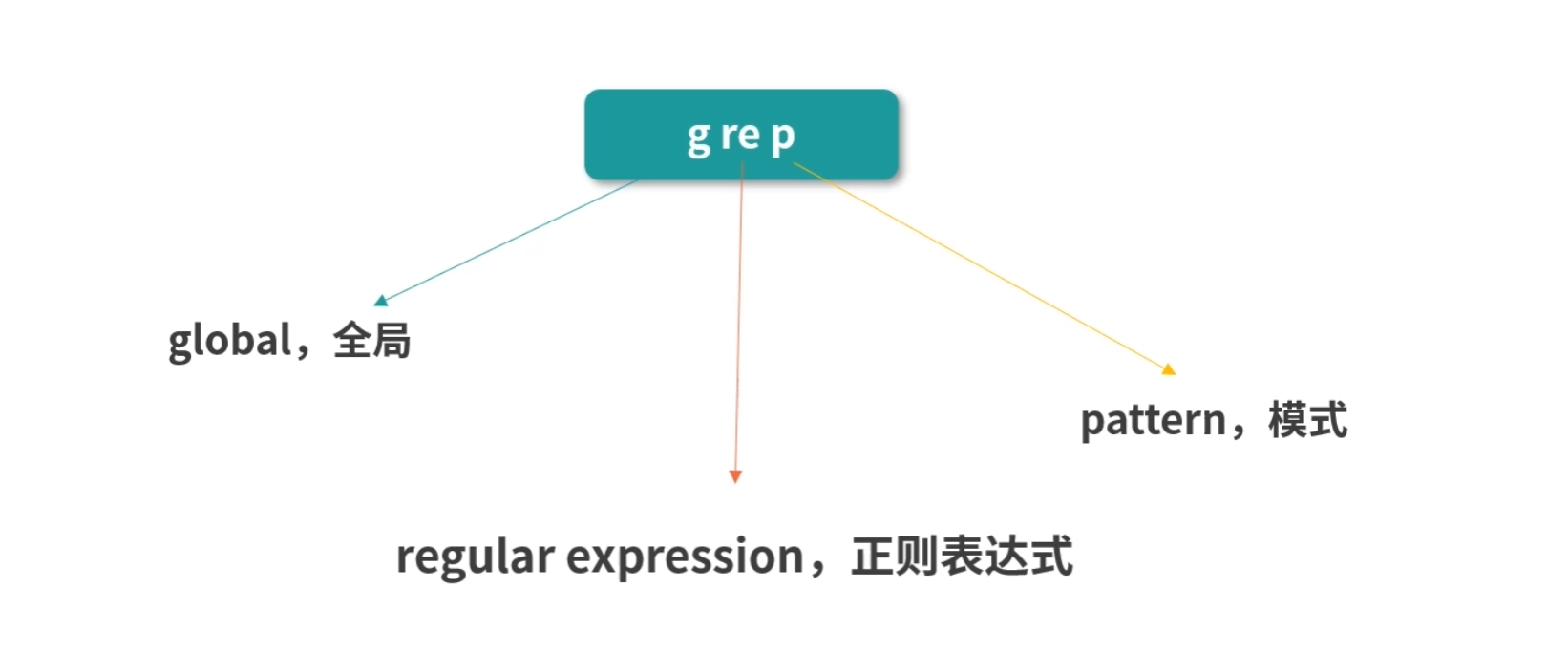
grep 这个词,我们分成三段来看,是 g|re|p。
- g 就是 global,全局;
- re 就是 regular expression,正则表达式;
- p 就是 pattern,模式。
所以这个指令的作用是通过正则表达式全局搜索一个文件找到匹配的模式。我觉得这种命名真的很牛,软件命名也是一个世纪难题,grep这个名字不但发音不错,而且很有含义,又避免了名字过长,方便记忆。
下面我们举两个例子看看 grep 的用法:
- 例 1:查找 ip 地址
我们可以通过grep命令定位某个ip地址的用户都做了什么事情,如下图所示:


man 指令:相当于指令手册
进程
什么是进程?
*可以回答:进程是应用的执行副本;而不要回答进程是操作系统分配资源的最小单位。前者是定义,后者是作用**。*
ps
如果你要看当前的进程,可以用ps指令。p 代表 processes,也就是进程;s 代表 snapshot,也就是快照。所谓快照,就是像拍照一样。
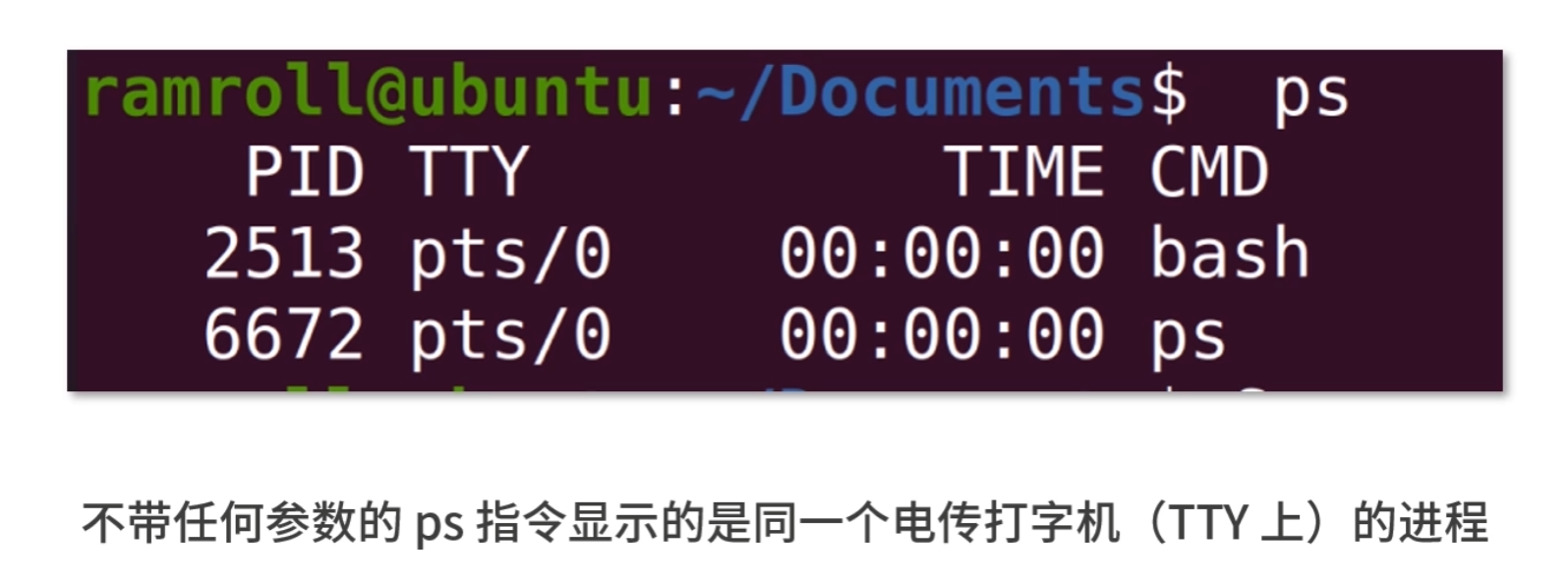
TTY:TTY 这个概念是一个历史的概念,过去用来传递信息,现在已经被传真、邮件、微信等取代。
操作系统上的 TTY 是一个输入输出终端的概念,比如用户打开 bash,操作系统就为用户分配了一个输入输出终端。没有加任何参数的ps只显示在同一个 TTY 的进程。
如果想看到所有的进程,可以用ps -e,-e没有特殊含义,只是为了和-A区分开。我们通常不直接用ps -e而是用ps -ef,这是因为-f可以带上更多的描述字段,如下图所示:
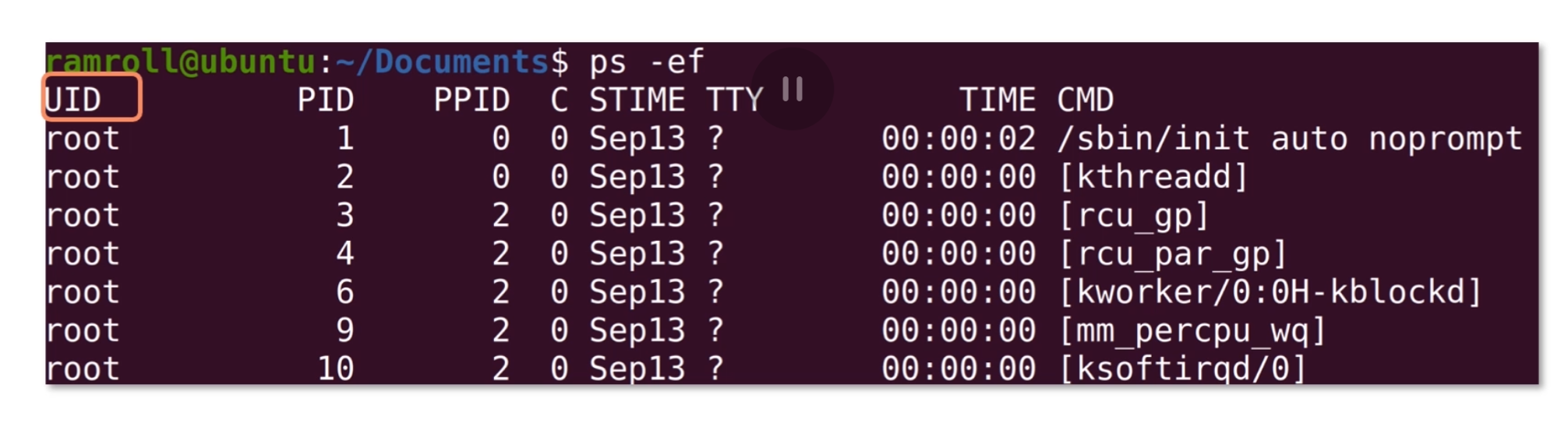
- UID 指进程的所有者;
- PID 是进程的唯一标识;
- PPID 是进程的父进程 ID;
- C 是 CPU 的利用率(就是 CPU 占用);
- STIME 是开始时间;
- TTY 是进程所在的 TTY,如果没有 TTY 就是 ?号;
- TIME;
- CMD 是进程启动时的命令,如果不是一个 Shell 命令,而是用方括号括起来,那就是系统进程或者内核过程。
另外一个用得比较多的是ps aux,它和ps -ef能力差不多,但是是 BSD 风格的。就是加州伯克利分校研发的 Unix 分支版本的衍生风格,这种风格其实不太好描述,我截了一张图,你可以体会一下:
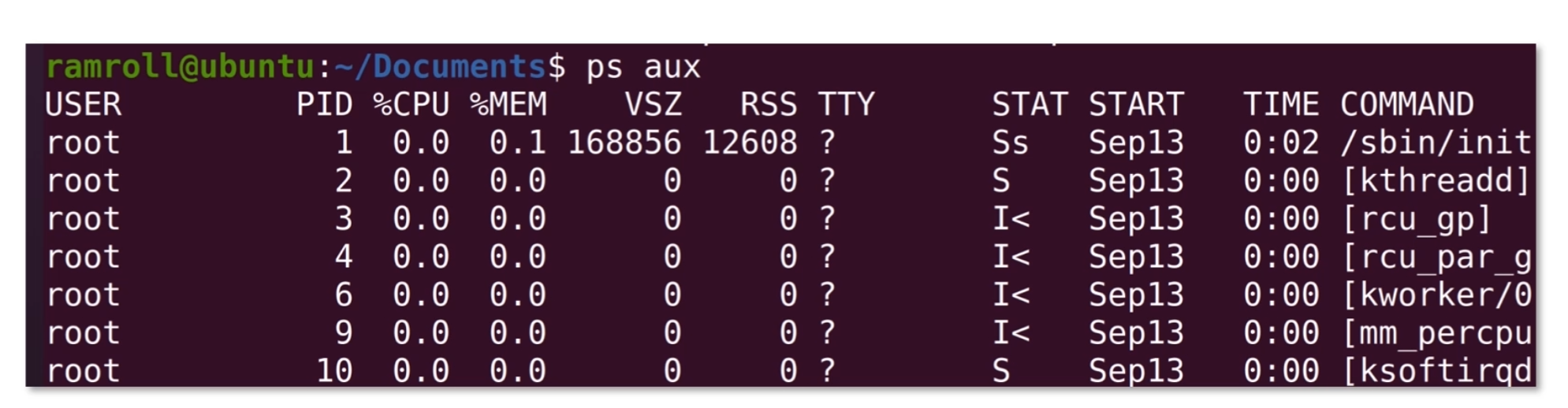
在 BSD 风格中有些字段的叫法和含义变了。
top
另外还有一个和ps能力差不多,但是显示的不是快照而是实时更新数据的top指令。因为自带的top显示的内容有点少, 所以我喜欢用一个叫作htop的指令,是需要额外安装的。
管道(Pipeline)
现管道(Pipeline)的作用是在命令和命令之间,传递数据。比如说一个命令的结果,就可以作为另一个命令的输入。我们了解了进程,所以这里说的命令就是进程。更准确地说,管道在进程间传递数据。
输入输出流
每个进程拥有自己的标准输入流、标准输出流、标准错误流。
这几个标准流说起来很复杂,但其实都是文件。
- 标准输入流(用 0 表示)可以作为进程执行的上下文(进程执行可以从输入流中获取数据)。
- 标准输出流(用 1 表示)中写入的结果会被打印到屏幕上。
- 如果进程在执行过程中发生异常,那么异常信息会被记录到标准错误流(用 2 表示)中。
重定向
我们执行一个指令,比如ls -l,结果会写入标准输出流,进而被打印。这时可以用重定向符将结果重定向到一个文件,比如说ls -l > out,这样out文件就会有ls -l的结果;而屏幕上也不会再打印ls -l的结果。
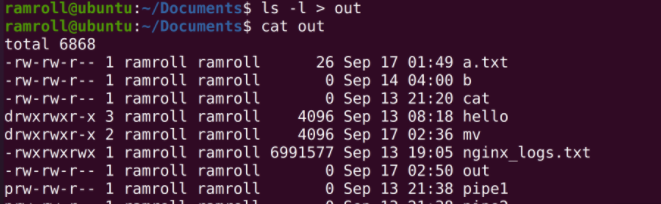
具体来说>符号叫作覆盖重定向;>>叫作追加重定向。>每次都会把目标文件覆盖,>>会在目标文件中追加。经过这样的操作后,每次执行程序日志就不会被覆盖了。
另外还有一种情况,比如我们输入:
1 | ls1 > out |
结果并不会存入out文件,因为ls1指令是不存在的。结果会输出到标准错误流中,仍然在屏幕上。这里我们可以把标准错误流也重定向到标准输出流,然后再重定向到文件。
1 | ls1 &> out |
这个写法等价于:
1 | ls1 > out 2>&1 |
管道的作用和分类
有了进程和重定向的知识,接下来我们梳理下管道的作用。管道(Pipeline)将一个进程的输出流定向到另一个进程的输入流,就像水管一样,作用就是把这两个文件接起来。如果一个进程输出了一个字符 X,那么另一个进程就会获得 X 这个输入。
管道和重定向很像,但是管道是一个连接一个进行计算,重定向是将一个文件的内容定向到另一个文件,这二者经常会结合使用。
Linux 中的管道也是文件,有两种类型的管道:
- 匿名管道(Unnamed Pipeline),这种管道也在文件系统中,但是它只是一个存储节点,不属于任何一个目录。说白了,就是没有路径。
- 命名管道(Named Pipeline),这种管道就是一个文件,有自己的路径。
FIFO
管道具有 FIFO(First In First Out),FIFO 和排队场景一样,先排到的先获得。所以先流入管道文件的数据,也会先流出去传递给管道下游的进程。
使用场景分析
接下来我们以多个场景举例帮助你深入学习管道。
排序
比如我们用ls,希望按照文件名排序倒序,可以使用匿名管道,将ls的结果传递给sort指令去排序。你看,这样ls的开发者就不用关心排序问题了。
去重
另一个比较常见的场景是去重,比如有一个字典文件,里面都是词语。如下所示:
1 | Apple |
如果我们想要去重可以使用uniq指令,uniq指令能够找到文件中相邻的重复行,然后去重。但是我们上面的文件重复行是交替的,所以不可以直接用uniq,因此可以先sort这个文件,然后利用管道将sort的结果重定向到uniq指令。指令如下:

筛选
有时候我们想根据正则模式筛选对应的内容。比如说我们想找到项目文件下所有文件名中含有Spring的文件。就可以利用grep指令,操作如下:
1 | find ./ | grep Spring |
find ./递归列出当前目录下所有目录中的文件。grep从find的输出流中找出含有Spring关键字的行。
如果我们希望包含Spring但不包含MyBatis就可以这样操作:
1 | find ./ | grep Spring | grep -v MyBatis |
grep -v是匹配不包含 MyBatis 的结果。
数行数
还有一个比较常见的场景是数行数。比如你写了一个 Java 文件想知道里面有多少行,就可以使用wc -l指令,如下所示:

但是如果你想知道当前目录下有多少个文件,可以用ls | wc -l,如下所示:

接下来请你思考一个问题:我们如何知道当前java的项目目录下有多少行代码?
提示一下。你可以使用下面这个指令:
1 | find -i ".java" ./ | wc -l |
中间结果
管道一个接着一个,是一个计算逻辑。有时候我们想要把中间的结果保存下来,这就需要用到tee指令。tee指令从标准输入流中读取数据到标准输出流。
tee还有一个能力,就是自己利用这个过程把输入流中读取到的数据存到文件中。比如下面这条指令:
1 | find ./ -i "*.java" | tee JavaList | grep Spring |
这句指令的意思是从当前目录中找到所有含有 Spring 关键字的 Java 文件。tee 本身不影响指令的执行,但是 tee 会把 find 指令的结果保存到 JavaList 文件中。
tee这个执行就像英文字母中的 T 一样,连通管道两端,下面又开了口。这个开口,在函数式编程里面叫作副作用。
xargs
xargs指令从标准数据流中构造并执行一行行的指令。xargs从输入流获取字符串,然后利用空白、换行符等切割字符串,在这些字符串的基础上构造指令,最后一行行执行这些指令。
举个例子,如果我们重命名当前目录下的所有 .a 的文件,想在这些文件前面加一个前缀prefix_。比如说x.a文件需要重命名成prefix_x.a,我们就可以用xargs指令构造模块化的指令。
现在我们有x.a``y.a``z.a三个文件,然后使用下图中的指令构造我们需要的指令::

- 我们用
ls找到所有的文件; -I参数是查找替换符,这里我们用GG替代ls找到的结果;-I GG后面的字符串 GG 会被替换为x.a``x.b或x.z;echo是一个在命令行打印字符串的指令。使用echo主要是为了安全,帮助我们检查指令是否有错误。
我们用xargs构造了 3 条指令。这里我再多讲一个词,叫作样板代码。如果你没有用xargs指令,而是用一条条mv指令去敲,这样就构成了样板代码。
最后去掉 echo,就是我们想要的结果,如下所示:

管道文件
上面我们花了较长的一段时间讨论匿名管道,用|就可以创造和使用。匿名管道也是利用了文件系统的能力,是一种文件结构。当你学到模块六文件系统的内容,会知道匿名管道拥有一个自己的inode,但不属于任何一个文件夹。
还有一种管道叫作命名管道(Named Pipeline)。命名管道是要挂到文件夹中的,因此需要创建。用mkfifo指令可以创建一个命名管道,下面我们来创建一个叫作pipe1的命名管道,如下图所示:

命名管道和匿名管道能力类似,可以连接一个输出流到另一个输入流,也是 First In First Out。
当执行cat pipe1的时候,你可以观察到,当前的终端处于等待状态。因为我们cat pipe1的时候pipe1中没有内容。
如果这个时候我们再找一个终端去写一点东西到pipe中,比如说:
1 | echo "XXX" > pipe1 |
这个时候,cat pipe1就会返回,并打印出xxx,如下所示:

我们可以像上图那样演示这段程序,在cat pipe1后面增加了一个&符号。这个&符号代表指令在后台执行,不会阻塞用户继续输入。然后我们通过echo指令往pipe1中写入东西,接着就会看到xxx被打印出来。
xargs 的作用
xargs 将标准输入流中的字符串分割成一条条子字符串,然后再按照我们自己想要的方式构建成一条条指令,大大拓展了 Linux 指令的能力。
权限抽象
首先,我们先来说说用户和组。Linux 是一个多用户平台,允许多个用户同时登录系统工作。Linux 将用户抽象成了账户,账户可以登录系统,比如通过输入登录名 + 密码的方式登录;也可以通过证书的方式登录。
但为了方便分配每个用户的权限,Linux 还支持组 (Group)账户。组账户是多个账户的集合,组可以为成员们分配某一类权限。每个用户可以在多个组,这样就可以利用组给用户快速分配权限。
组的概念有点像微信群。一个用户可以在多个群中。比如某个组中分配了 10 个目录的权限,那么新建用户的时候可以将这个用户增加到这个组中,这样新增的用户就不必再去一个个目录分配权限。
而每一个微信群都有一个群主,Root 账户也叫作超级管理员,就相当于微信群主,它对系统有着完全的掌控。一个超级管理员可以使用系统提供的全部能力。
此外,Linux 还对文件进行了权限抽象(注意目录也是一种文件)。Linux 中一个文件可以设置下面 3 种权限:
- 读权限(r):控制读取文件。
- 写权限(w):控制写入文件。
- 执行权限(x):控制将文件执行,比如脚本、应用程序等。
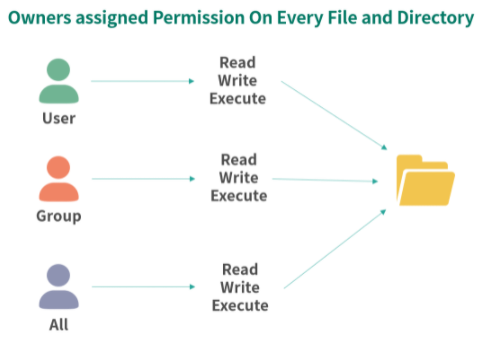
然后每个文件又可以从 3 个维度去配置上述的 3 种权限:
- 用户维度。每个文件可以所属 1 个用户,用户维度配置的 rwx 在用户维度生效;
- 组维度。每个文件可以所属 1 个分组,组维度配置的 rwx 在组维度生效;
- 全部用户维度。设置对所有用户的权限。

因此 Linux 中文件的权限可以用 9 个字符,3 组rwx描述:第一组是用户权限,第二组是组权限,第三组是所有用户的权限。然后用-代表没有权限。比如rwxrwxrwx代表所有维度可以读写执行。rw--wxr-x代表用户维度不可以执行,组维度不可以读取,所有用户维度不可以写入。
通常情况下,如果用ls -l查看一个文件的权限,会有 10 个字符,这是因为第一个字符代表的是文件类型。我们在 06 课时讲解“几种常见的文件类型”时提到过,有管道文件、目录文件、链接文件等等。-代表普通文件、d代表目录、p代表管道。
问题一:初始权限问题
一个文件创建后,文件的所属用户会被设置成创建文件的用户。谁创建谁拥有,这个逻辑很顺理成章。但是文件的组又是如何分配的呢?
这里 Linux 想到了一个很好的办法,就是为每个用户创建一个同名分组。
比如说zhang这个账户创建时,会创建一个叫作zhang的分组。zhang登录之后,工作分组就会默认使用它的同名分组zhang。如果zhang想要切换工作分组,可以使用newgrp指令切换到另一个工作分组。因此,被创建文件所属的分组是当时用户所在的工作分组,如果没有特别设置,那么就属于用户所在的同名分组。
再说下文件的权限如何?文件被创建后的权限通常是:
1 | rw-rw-r-- |
也就是用户、组维度不可以执行,所有用户可读。
问题二:公共执行文件的权限
前面提到过可以用which指令查看ls指令所在的目录,我们发现在/usr/bin中。然后用ls -l查看ls的权限,可以看到下图所示:
- 第一个
-代表这是一个普通文件,后面的 rwx 代表用户维度可读写和执行; - 第二个
r-x代表组维度不可读写; - 第三个
r-x代表所有用户可以读和执行; - 后两个
root,第一个代表所属用户,第二个代表所属分组。
如果一个文件设置为不可读,但是可以执行,那么结果会怎样?
答案当然是不可以执行,无法读取文件内容自然不可以执行。
问题三:执行文件
在 Linux 中,如果一个文件可以被执行,则可以直接通过输入文件路径(相对路径或绝对路径)的方式执行。如果想执行一个不可以执行的文件,Linux 则会报错。
当用户输入一个文件名,如果没有指定完整路径,Linux 就会在一部分目录中查找这个文件。你可以通过echo $PATH看到 Linux 会在哪些目录中查找可执行文件,PATH是 Linux 的环境变量。
问题四:可不可以都 root
不可以
下面我们就来说说 root 的危害。
举个例子,你有一个 MySQL 进程执行在 root(最大权限)账户上,如果有黑客攻破了你的 MySQL 服务,获得了在 MySQL 上执行 SQL 的权限,那么,你的整个系统就都暴露在黑客眼前了。这会导致非常严重的后果。
黑客可以利用 MySQL 的 Copy From Prgram 指令为所欲为,比如先备份你的关键文件,然后再删除他们,并要挟你通过指定账户打款。如果执行最小权限原则,那么黑客即便攻破我们的 MySQL 服务,他也只能获得最小的权限。当然,黑客拿到 MySQL 权限也是非常可怕的,但是相比拿到所有权限,这个损失就小多了。
内核是操作系统连接硬件、提供最核心能力的程序。
内核提供操作硬件、磁盘、内存分页、进程等最核心的能力,并拥有直接操作全部内存的权限,因此内核不能把自己的全部能力都提供给用户,而且也不能允许用户通过shell指令进行系统调用。Linux 下内核把部分进程需要的系统调用以 C 语言 API 的形式提供出来。部分系统调用会有权限检查,比如说设置系统时间的系统调用。
权限架构思想
优秀的权限架构主要目标是让系统安全、稳定且用户、程序之间相互制约、相互隔离。这要求权限系统中的权限划分足够清晰,分配权限的成本足够低。
因此,优秀的架构,应该遵循最小权限原则(Least Privilege)。权限设计需要保证系统的安全和稳定。比如:每一个成员拥有的权限应该足够的小,每一段特权程序执行的过程应该足够的短。对于安全级别较高的时候,还需要成员权限互相牵制。比如金融领域通常登录线上数据库需要两次登录,也就是需要两个密码,分别掌握在两个角色手中。这样即便一个成员出了问题,也可以保证整个系统安全。
同样的,每个程序也应该减少权限,比如说只拥有少量的目录读写权限,只可以进行少量的系统调用。
权限划分
此外,权限架构思想还应遵循一个原则,权限划分边界应该足够清晰,尽量做到相互隔离。Linux 提供了用户和分组。当然 Linux 没有强迫你如何划分权限,这是为了应对更多的场景。通常我们服务器上重要的应用,会由不同的账户执行。比如说 Nginx、Web 服务器、数据库不会执行在一个账户下。现在随着容器化技术的发展,我们甚至希望每个应用独享一个虚拟的空间,就好像运行在一个单独的操作系统中一样,让它们互相不用干扰。
分级保护
因为内核可以直接操作内存和 CPU,因此非常危险。驱动程序可以直接控制摄像头、显示屏等核心设备,也需要采取安全措施,比如防止恶意应用开启摄像头盗用隐私。通常操作系统都采取一种环状的保护模式。
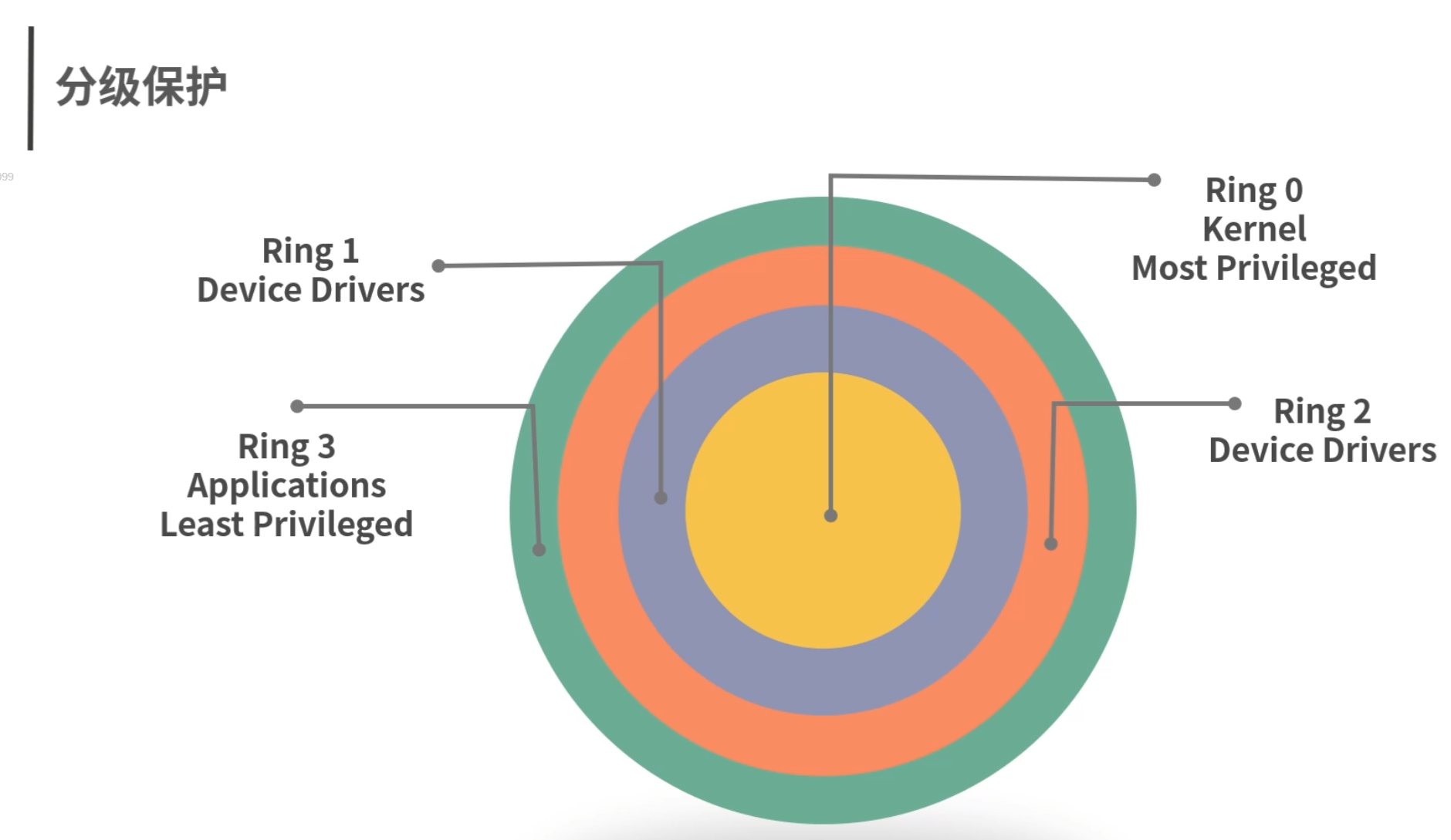
如上图所示,内核在最里面,也就是 Ring 0。 应用在最外面也就是 Ring 3。驱动在中间,也就是 Ring 1 和 Ring 2。对于相邻的两个 Ring,内层 Ring 会拥有较高的权限,可以改变外层的 Ring;而外层的 Ring 想要使用内层 Ring 的资源时,会有专门的程序(或者硬件)进行保护。
比如说一个 Ring3 的应用需要使用内核,就需要发送一个系统调用给内核。这个系统调用会由内核进行验证,比如验证用户有没有足够的权限,以及这个行为是否安全等等。
权限包围(Privilege Bracking)
之前我们讨论过,当 MySQL 跑在 root 权限时,如果 MySQLl 被攻破,整个机器就被攻破了。因此我们所有应用都不要跑在 root 上。如果所有应用都跑在普通账户下,那么就会有临时提升权限的场景。比如说安装程序可能需要临时拥有管理员权限,将应用装到/usr/bin目录下。
Linux 提供了权限包围的能力。比如一个应用,临时需要高级权限,可以利用交互界面(比如让用户输入 root 账户密码)验证身份,然后执行需要高级权限的操作,然后马上恢复到普通权限工作。这样做可以减少应用在高级权限的时间,并做到专权专用,防止被恶意程序利用。
用户分组指令
上面我们讨论了 Linux 权限的架构,接下来我们学习一些具体的指令。
查看
如果想查看当前用户的分组可以使用groups指令。

上面指令列出当前用户的所有分组。第一个是同名的主要分组,后面从adm开始是次级分组。
我先给你介绍两个分组,其他分组你可以去查资料:
- adm 分组用于系统监控,比如
/var/log中的部分日志就是 adm 分组。 - sudo 分组用户可以通过 sudo 指令提升权限。
如果想查看当前用户,可以使用id指令,如下所示:

- uid 是用户 id;
- gid 是组 id;
- groups 后面是每个分组和分组的 id。
如果想查看所有的用户,可以直接看/etc/passwd。
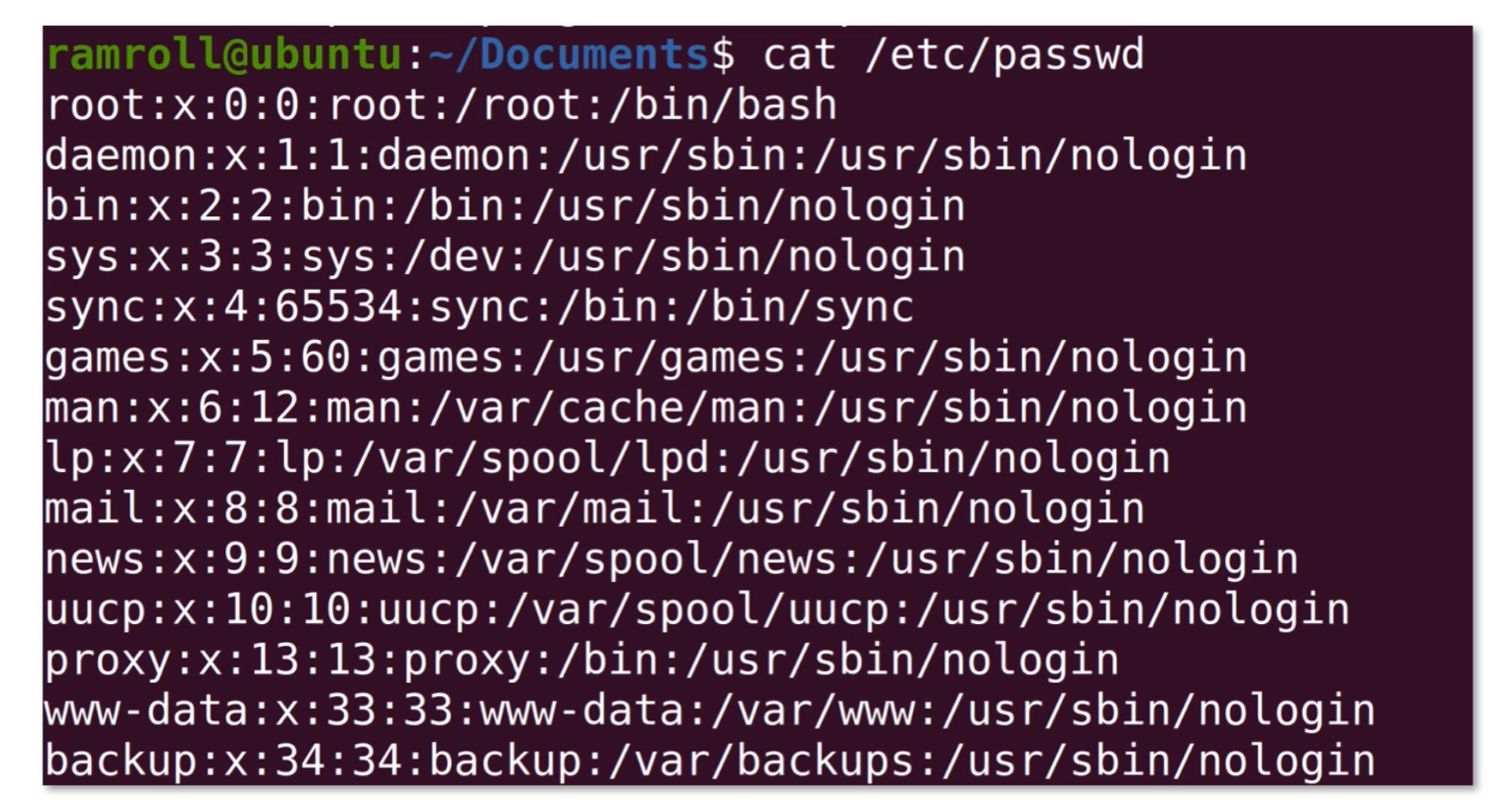
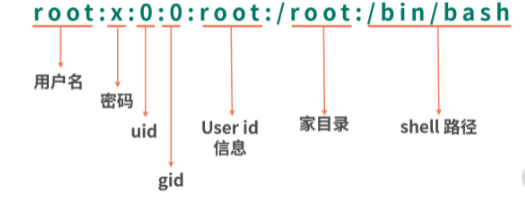
/etc/passwd这个文件存储了所有的用户信息,如下图所示:
创建用户
创建用户用useradd指令。
1 | sudo useradd foo |
sudo 原意是 superuser do,后来演变成用另一个用户的身份去执行某个指令。如果没有指定需要 sudo 的用户,就可以像上面那样,以超级管理员的身份。因为 useradd 需要管理员身份。这句话执行后,会进行权限提升,并弹出输入管理员密码的输入界面。
创建分组
创建分组用groupadd指令。下面指令创建一个叫作hello的分组。
1 | sudo groupadd hello |
为用户增加次级分组
组分成主要分组(Primary Group)和次级分组(Secondary Group)。主要分组只有 1 个,次级分组可以有多个。如果想为用户添加一个次级分组,可以用usermod指令。下面指令将用户foo添加到sudo分组,从而foo拥有了sudo的权限。
1 | sudo usermod -a -G sudo foo |
-a代表append,-G代表一个次级分组的清单, 最后一个foo是账户名。
修改用户主要分组
修改主要分组还是使用usermod指令。只不过参数是小写的-g。
1 | sudo usermod -g somegroup foo |
文件权限管理指令
接下来我们学习文件管理相关的指令。
查看
我们可以用ls -l查看文件的权限,相关内容在本课时前面已经介绍过了。
修改文件权限
可以用chmod修改文件权限,chmod( change file mode bits),也就是我们之前学习的 rwx,只不过 rwx 在 Linux 中是用三个连在一起的二进制位来表示。
1 | # 设置foo可以执行 |
因为rwx在 Linux 中用相邻的 3 个位来表示。比如说111代表rwx,101代表r-x。而rwx总共有三组,分别是用户权限、组权限和全部用户权限。也就是可以用111111111 9 个 1 代表rwxrwxrwx。又因为11110 进制是 7,因此当需要一次性设置用户权限、组权限和所有用户权限的时候,我们经常用数字表示。
1 | # 设置rwxrwxrwx (111111111 -> 777) |
修改文件所属用户
有时候我们需要修改文件所属用户,这个时候会使用chown指令。 下面指令修改foo文件所属的用户为bar。
1 | chown bar ./foo |
还有一些情况下,我们需要同时修改文件所属的用户和分组,比如我们想修改foo的分组位g,用户为u,可以使用:
1 | chown g.u ./foo |
简述 Linux 权限划分的原则?
老规矩,请你先在脑海里构思下给面试官的表述,并把你的思考写在留言区,然后再来看我接下来的分析。
【解析】 Linux 遵循最小权限原则。
- 每个用户掌握的权限应该足够小,每个组掌握的权限也足够小。实际生产过程中,最好管理员权限可以拆分,互相牵制防止问题。
- 每个应用应当尽可能小的使用权限。最理想的是每个应用单独占用一个容器(比如 Docker),这样就不存在互相影响的问题。即便应用被攻破,也无法攻破 Docker 的保护层。
- 尽可能少的
root。如果一个用户需要root能力,那么应当进行权限包围——马上提升权限(比如 sudo),处理后马上释放权限。 - 系统层面实现权限分级保护,将系统的权限分成一个个 Ring,外层 Ring 调用内层 Ring 时需要内层 Ring 进行权限校验。
远程操作指令
远程操作指令用得最多的是ssh,ssh指令允许远程登录到目标计算机并进行远程操作和管理。还有一个比较常用的远程指令是scp,scp帮助我们远程传送文件。
ssh(Secure Shell)
有一种场景需要远程登录一个 Linux 系统,这时我们会用到ssh指令。比如你想远程登录一台机器,可以使用ssh user@ip的方式。
scp
另一种场景是我需要拷贝一个文件到远程,这时可以使用scp指令,如下图,我使用scp指令将本地计算机的一个文件拷贝到了 ubuntu 虚拟机用户的家目录中。
比如从u1拷贝家目录下的文件a.txt到u2。家目录有一个简写,就是用~。
输入 scp 指令之后会弹出一个提示,要求输入密码,系统验证通过后文件会被成功拷贝。
查看本地网络状态
如果你想要了解本地的网络状态,比较常用的网络指令是ifconfig和netstat。
ifconfig
当你想知道本地ip以及本地有哪些网络接口时,就可以使用ifconfig指令。你可以把一个网络接口理解成一个网卡,有时候虚拟机会装虚拟网卡,虚拟网卡是用软件模拟的网卡。
比如:VMware 为每个虚拟机创造一个虚拟网卡,通过虚拟网卡接入虚拟网络。当然物理机也可以接入虚拟网络,它可以通过虚拟网络向虚拟机的虚拟网卡上发送信息。
下图是我的 ubuntu 虚拟机用 ifconfig 查看网络接口信息。
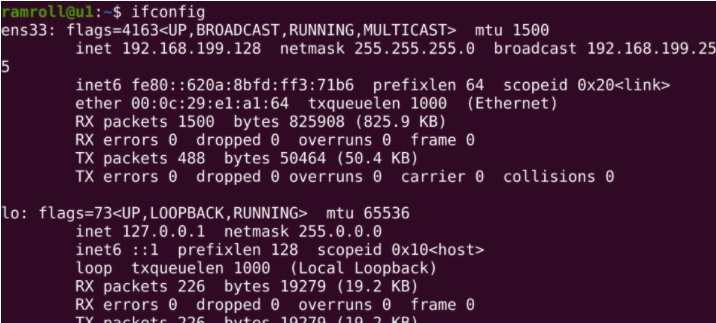
可以看到我的这台 ubuntu 虚拟机一共有 2 个网卡,ens33 和 lo。lo是本地回路(local lookback),发送给lo就相当于发送给本机。ens33是一块连接着真实网络的虚拟网卡。
netstat
另一个查看网络状态的场景是想看目前本机的网络使用情况,这个时候可以用netstat。
默认行为
不传任何参数的netstat帮助查询所有的本地 socket,下图是netstat | less的结果。
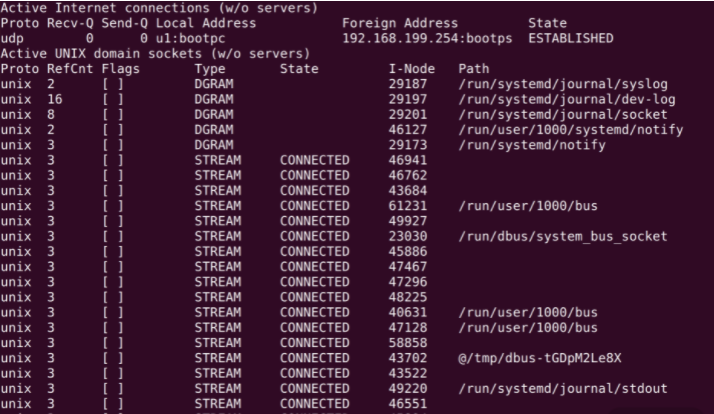
如上图,我们看到的是 socket 文件。socket 是网络插槽被抽象成了文件,负责在客户端、服务器之间收发数据。当客户端和服务端发生连接时,客户端和服务端会同时各自生成一个 socket 文件,用于管理这个连接。这里,可以用wc -l数一下有多少个socket。

这里没有找到连接中的tcp,因为我们这台虚拟机当时没有发生任何的网络连接。因此我们尝试从机器u2(另一台机器)ssh 登录进u1,再看一次:

如上图所示,可以看到有一个 TCP 连接了。

查看端口占用
还有一种非常常见的情形,我们想知道某个端口是哪个应用在占用。如下图所示:

这里我们看到 22 端口被 sshd,也就是远程登录模块被占用了。-n是将一些特殊的端口号用数字显示,-t是指看 TCP 协议,-l是只显示连接中的连接,-p是显示程序名称。
网络测试
当我们需要测试网络延迟、测试服务是否可用时,可能会用到ping和telnet指令。
ping
想知道本机到某个网站的网络延迟,就可以使用ping指令。如下图所示:

ping一个网站需要使用 ICMP 协议。因此你可以在上图中看到 icmp 序号。 这里的时间time是往返一次的时间。ttl叫作 time to live,是封包的生存时间。就是说,一个封包从发出就开始倒计时,如果途中超过 128ms,这个包就会被丢弃。如果包被丢弃,就会被算进丢包率。
另外ping还可以帮助我们看到一个网址的 IP 地址。 通过网址获得 IP 地址的过程叫作 DNS Lookup(DNS 查询)。ping利用了 DNS 查询,但是没有显示全部的 DNS 查询结果。
telnet
有时候我们想知道本机到某个 IP + 端口的网络是否通畅,也就是想知道对方服务器是否在这个端口上提供了服务。这个时候可以用telnet指令。 如下图所示:
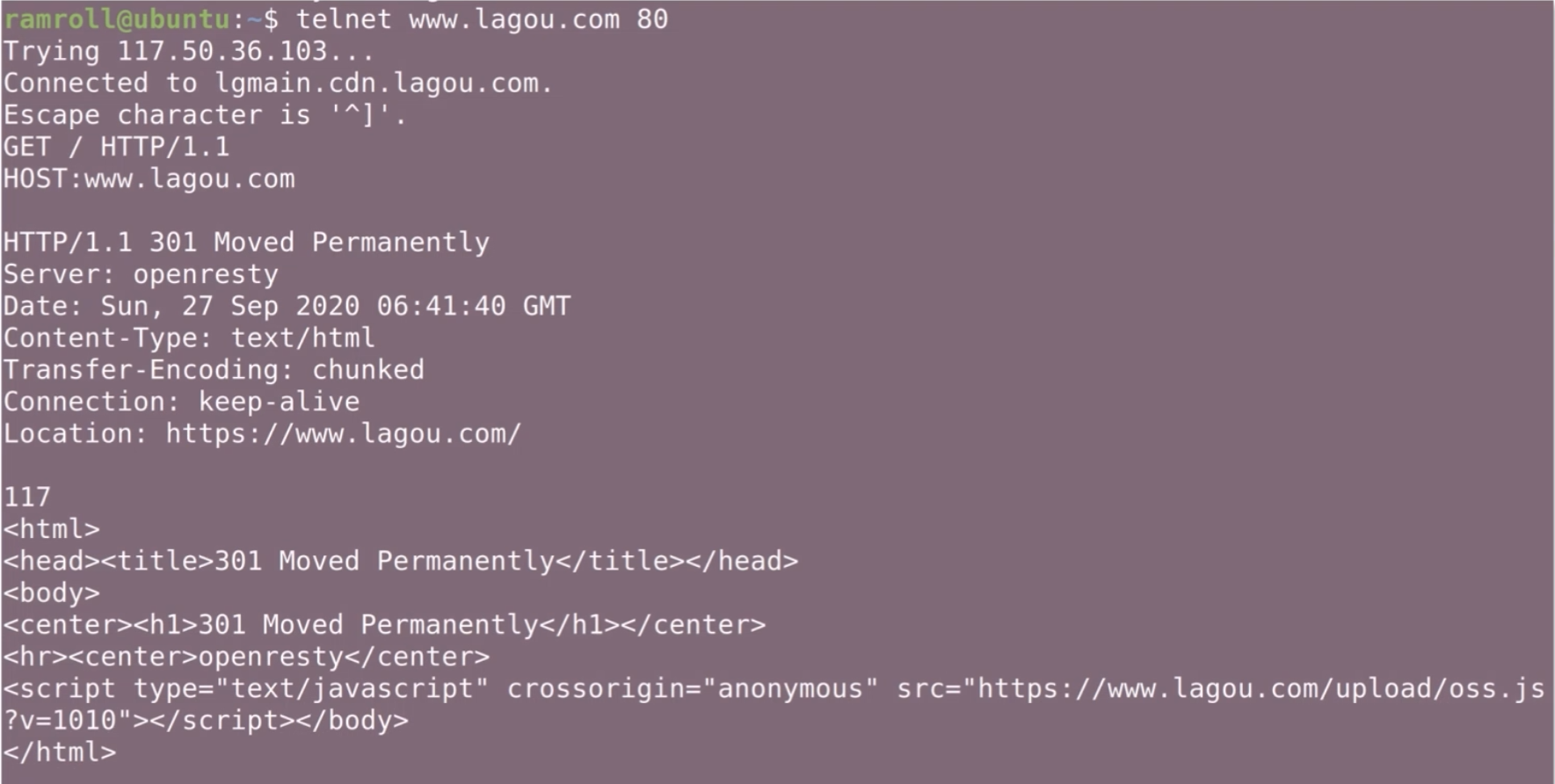
如上图所示,第 5 行的GET 和第 6 行的HOST是我输入的。 拉勾网返回了一个 301 永久跳转。这是因为拉勾网尝试把http协议链接重定向到https。
DNS 查询
我们排查网络故障时想要进行一次 DNS Lookup,想知道一个网址 DNS 的解析过程。这个时候有多个指令可以用。
host
host 就是一个 DNS 查询工具。比如我们查询拉勾网的 DNS,如下图所示:

我们看到拉勾网 www.lagou.com 是一个别名,它的原名是 lgmain 开头的一个域名,这说明拉勾网有可能在用 CDN 分发主页(关于 CDN,我们《计算机网络》专栏见)。
上图中,可以找到 3 个域名对应的 IP 地址。
如果想追查某种类型的记录,可以使用host -t。比如下图我们追查拉勾的 AAAA 记录,因为拉勾网还没有部署 IPv6,所以没有找到。

dig
dig指令也是一个做 DNS 查询的。不过dig指令显示的内容更详细。下图是dig拉勾网的结果。
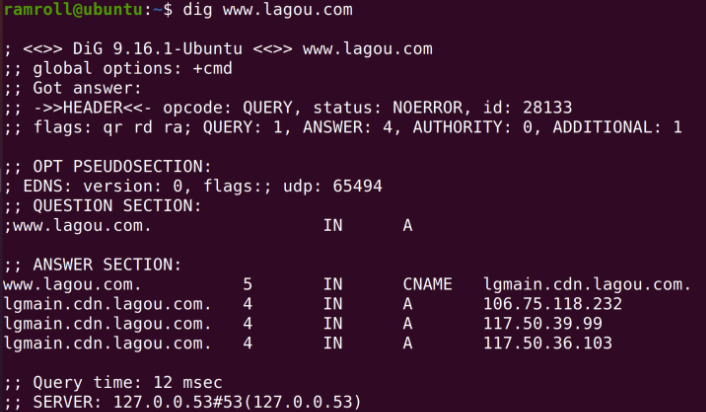
从结果可以看到www.lagou.com 有一个别名,用 CNAME 记录定义 lgmain 开头的一个域名,然后有 3 条 A 记录,通常这种情况是为了均衡负载或者分发内容。
HTTP 相关
最后我们来说说http协议相关的指令。
curl
如果要在命令行请求一个网页,或者请求一个接口,可以用curl指令。curl支持很多种协议,比如 LDAP、SMTP、FTP、HTTP 等。
我们可以直接使用 curl 请求一个网址,获取资源,比如我用 curl 直接获取了拉勾网的主页,如下图所示:
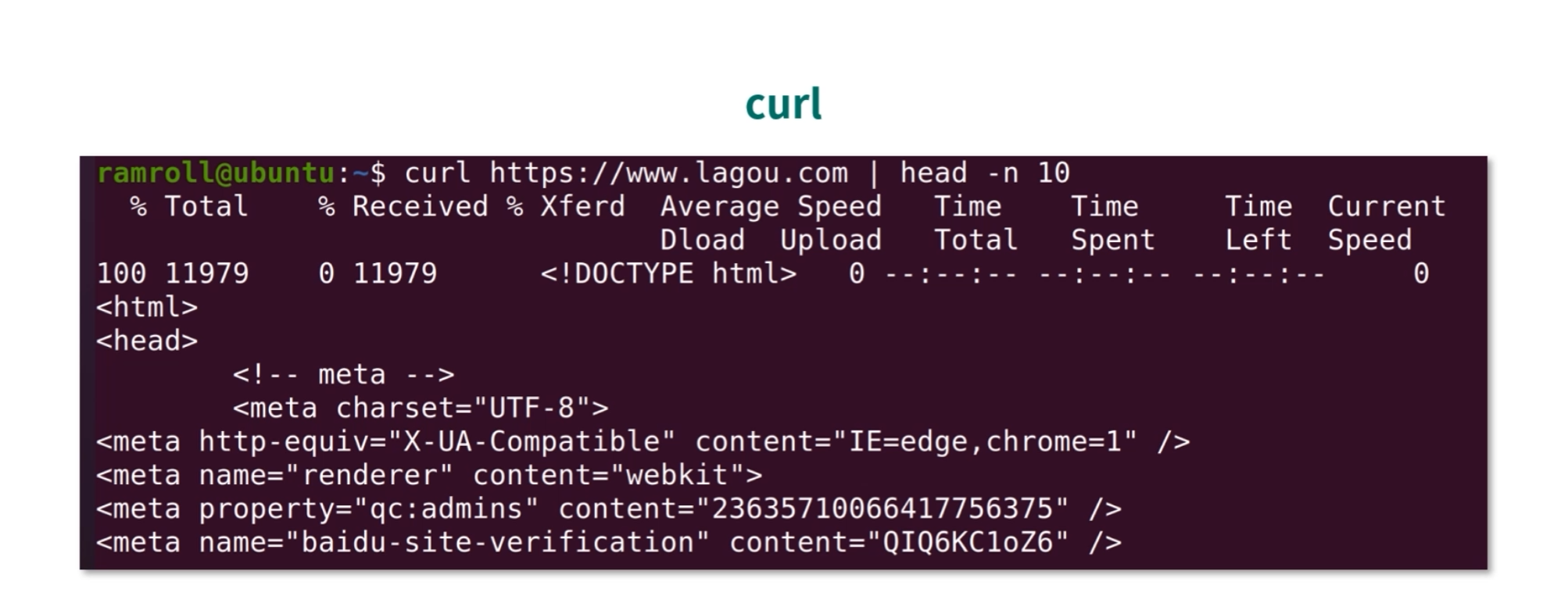
如果只想看 HTTP 返回头,可以使用curl -I。
另外curl还可以执行 POST 请求,比如下面这个语句:
1 | curl -d '{"x" : 1}' -H "Content-Type: application/json" -X POST http://localhost:3000/api |
curl在向localhost:3000发送 POST 请求。-d后面跟着要发送的数据, -X后面是用到的 HTTP 方法,-H是指定自定义的请求头。
如何查看一个域名有哪些 NS 记录?
【解析】 host 指令提供了一个-t参数指定需要查找的记录类型。我们可以使用host -t ns {网址}。另外 dig 也提供了同样的能力。如果你感兴趣,还可以使用man对系统进行操作。
安装程序
在 Linux 上安装程序大概有 2 种思路:
- 直接编译源代码;
- 使用包管理器。
受开源运动影响,Linux 上很多软件都可以拿到源代码,这也是 Linux 能取得成功的一个重要原因。接下来我们先尝试用包管理器安装应用,然后再用一个实战的例子,教你如何编译安装nginx。
包管理器使用
Linux 下的应用程序多数以软件包的形式发布,用户拿到对应的包之后,使用包管理器进行安装。说到包管理器,就要提到dpkg和rpm。
我们先说说包。 Linux 下两大主流的包就是rpm和dpkg。
dpkg(debian package),是linux一个主流的社区分支开发出来的。社区就是开源社区,有很多世界顶级的程序员会在社区贡献代码,比如 github。一般衍生于debian的 Linux 版本都支持dpkg,比如ubuntu。
rpm(redhatpackage manager)。在正式讲解之前,我们先来聊聊 RedHat 这家公司。
RedHat 是一个做 Linux 的公司,你可以把它理解成一家“保险公司”。 很多公司购买红帽的服务,是为了给自己的业务上一个保险。以防万一哪天公司内部搞不定 Linux 底层,或者底层有 Bug,再或者底层不适合当下的业务发展,需要修改等问题,红帽的工程师都可以帮企业解决。
再比如,RedHat 收购了JBoss,把 JBoss 改名为 WildFly。 像 WildFly 这种工具更多是面向企业级,比如没有大量研发团队的企业会更倾向使用成熟的技术。RedHat 公司也有自己的 Linux,就叫作 RedHat。RedHat 系比较重要的 Linux 有 RedHat/Fedora 等。
无论是dpkg还是rpm都抽象了自己的包格式,就是以.dpkg或者.rpm结尾的文件。
dpkg和rpm也都提供了类似的能力:
- 查询是否已经安装了某个软件包;
- 查询目前安装了什么软件包;
- 给定一个软件包,进行安装;
- 删除一个安装好的软件包。
关于dpkg和rpm的具体用法,你可以用man进行学习。接下来我们聊聊yum和apt。
自动依赖管理
Linux 是一个开源生态,因此工具非常多。工具在给用户使用之前,需要先打成dpkg或者rpm包。 有的时候一个包会依赖很多其他的包,而dpkg和rpm不会对这种情况进行管理,有时候为了装一个包需要先装十几个依赖的包,过程非常艰辛!因此现在多数情况都在用yum和apt。
yum
你可能会说,我不用yum也不用apt,我只用docker。首先给你一个连击 666,然后我还是要告诉你,如果你做docker镜像,那么还是要用到yum和apt,因此还是有必要学一下。
yum的全名是 Yellodog Updator,Modified。 看名字就知道它是基于Yellodog Updator这款软件修改而来的一个工具。yum是 Python 开发的,提供的是rpm包,因此只有redhat系的 Linux,比如 Fedora,Centos 支持yum。yum的主要能力就是帮你解决下载和依赖两个问题。
下载之所以是问题,是因为 Linux 生态非常庞大,有时候用户不知道该去哪里下载一款工具。比如用户想安装vim,只需要输入sudo yum install vim就可以安装了。yum的服务器收集了很多linux软件,因此yum会帮助用户找到vim的包。
另一方面,yum帮助用户解决了很多依赖,比如用户安装一个软件依赖了 10 个其他的软件,yum会把这 11 个软件一次性的装好。
关于yum的具体用法,你可以使用man工具进行学习。
apt
接下来我们来重点说说apt,然后再一起尝试使用。因为我这次是用ubuntuLinux 给你教学,所以我以 apt 为例子,yum 的用法是差不多的,你可以自己 man 一下。
apt全名是 Advanced Packaging Tools,是一个debian及其衍生 Linux 系统下的包管理器。由于advanced(先进)是相对于dpkg而言的,因此它也能够提供和yum类似的下载和依赖管理能力。比如在没有vim的机器上,我们可以用下面的指令安装vim。如下图所示:
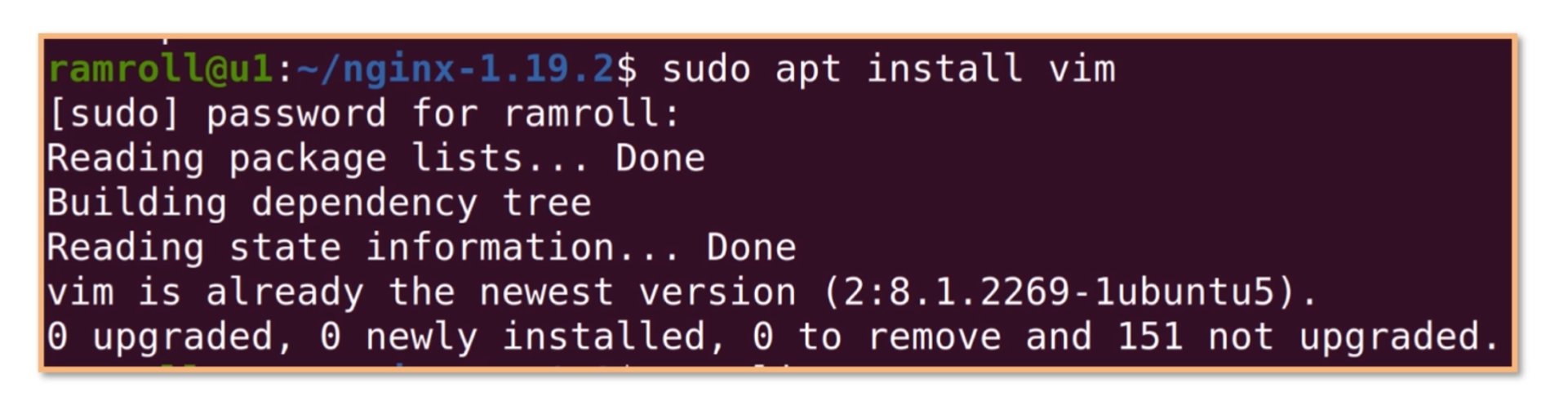
然后用dpkg指令查看 vim 的状态是ii。第一个i代表期望状态是已安装,第二个i代表实际状态是已安装。
下面我们卸载vim,再通过dpkg查看,如下图所示:
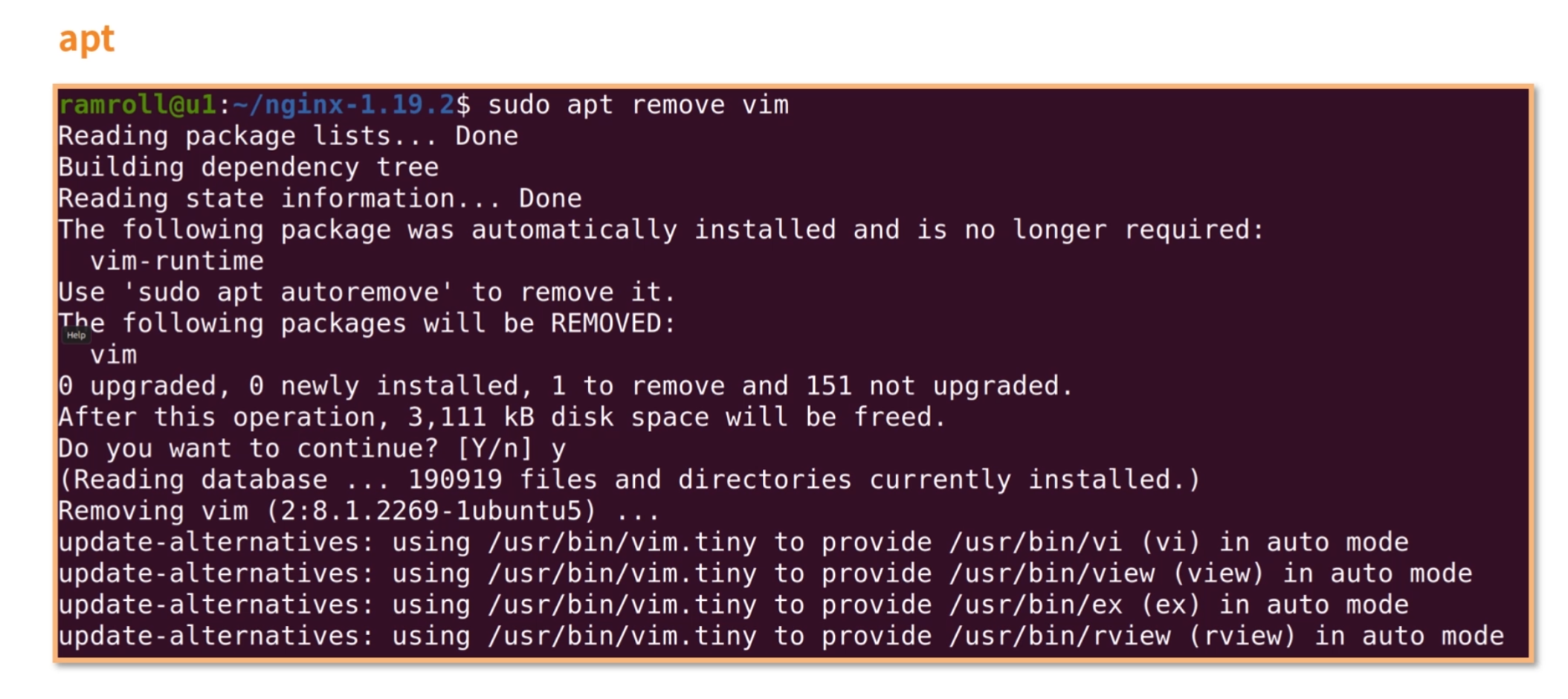
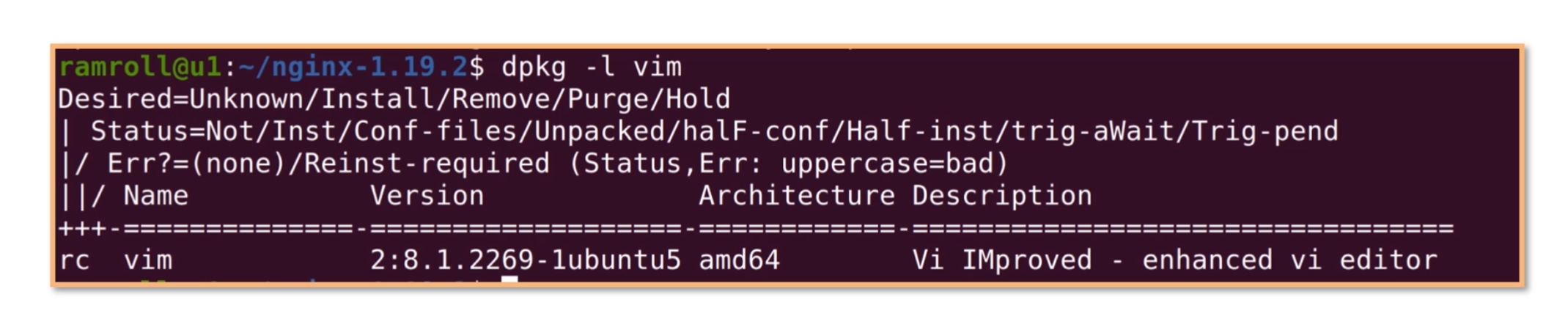
我们看到 vim 的状态从ii变成了rc,r是期望删除,c是实际上还有配置文件遗留。 如果我们想彻底删除配置文件,可以使用apt purge,就是彻底清除的意思,如下图所示:
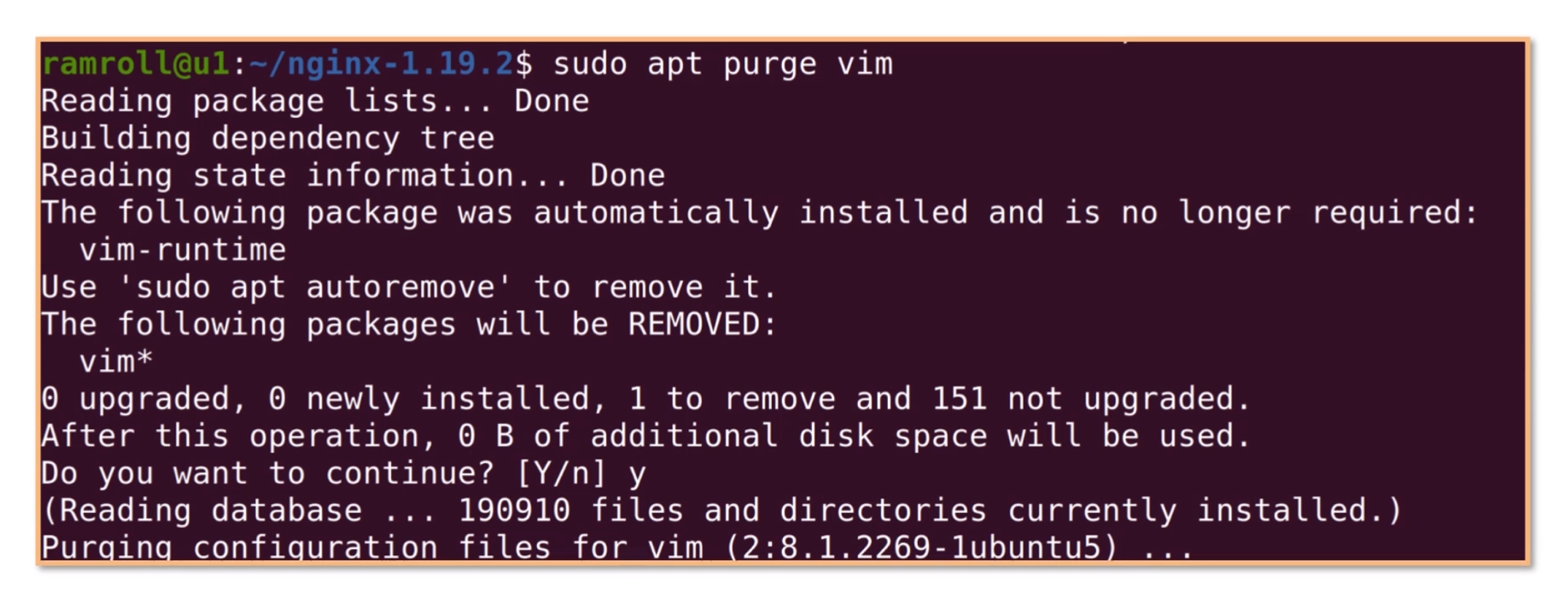
再使用dpkg -l时,vim已经清除了。

期待结果是u就是 unkonw(未知)说明已经没有了。实际结果是n,就是 not-installed(未安装)。
如果想查询mysql相关的包,可以使用apt serach mysql,这样会看到很多和mysql相关的包,如下图所示:
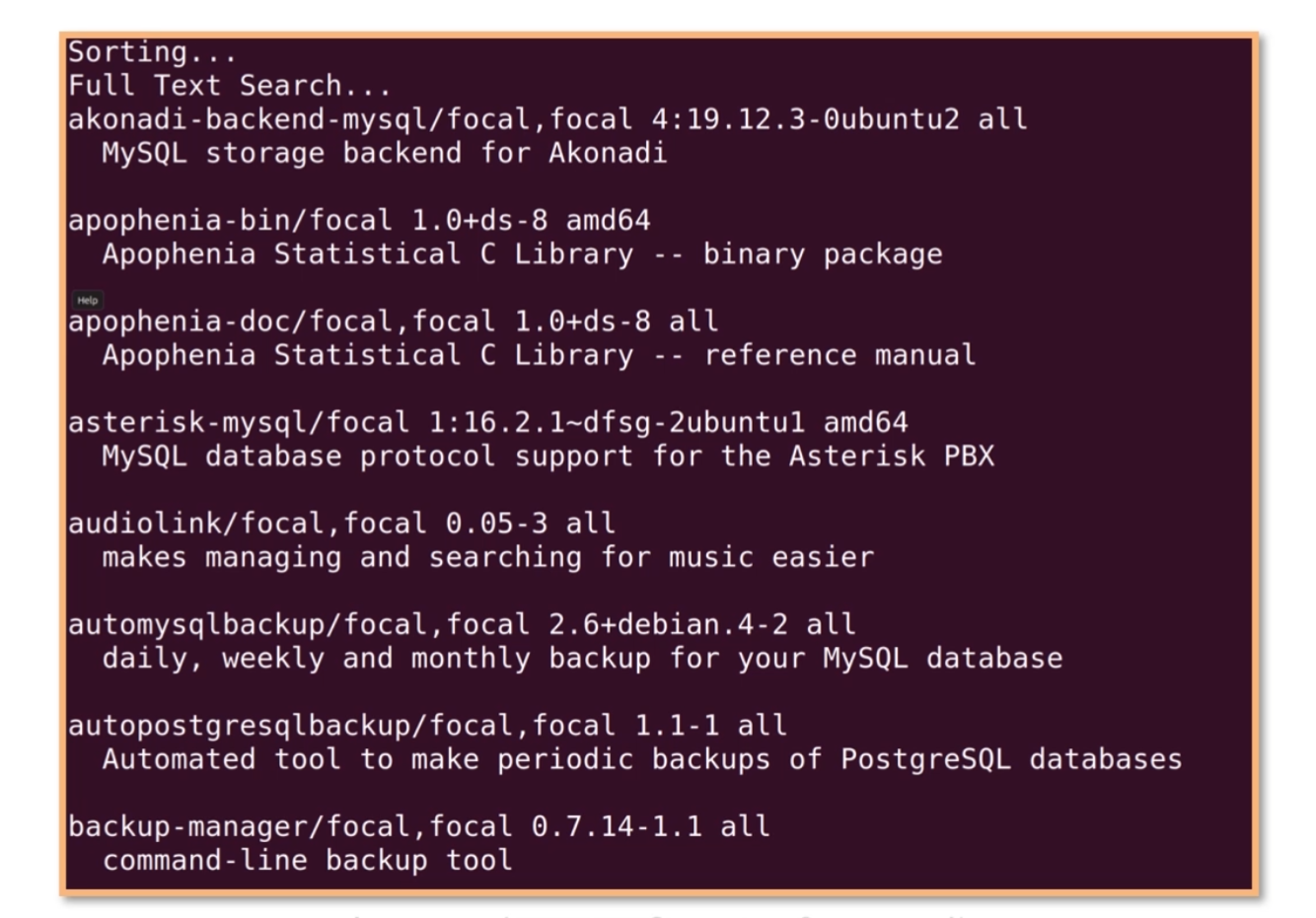
如果我们想精确查找一个叫作mysql-server的包,可以用apt list。

这里我们找到了mysql-server包。
另外有时候国内的apt服务器速度比较慢,你可以尝试使用阿里云的镜像服务器。具体可参考我下面的操作:
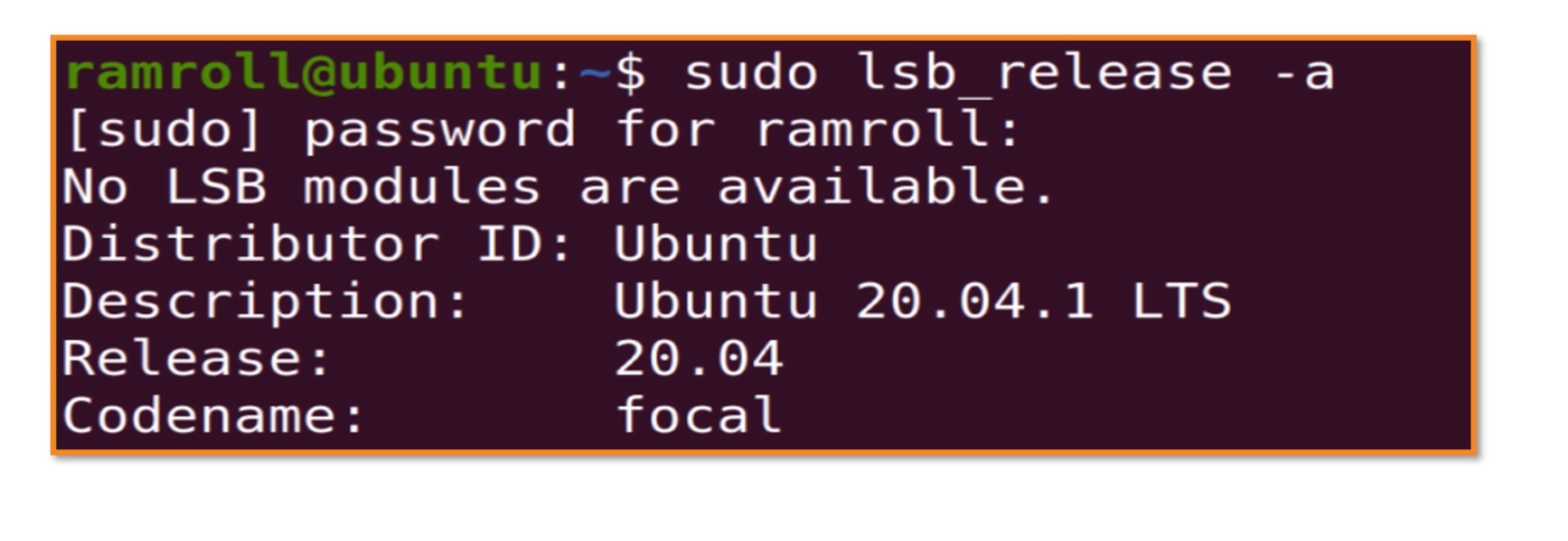
1 | cat /etc/apt/sources.list |
镜像地址可以通过/etc/apt/sources.list配置,注意focal是我用的ubuntu版本,你可以使用sudo lsb_release查看自己的 Ubuntu 版本。如果你想用我上面给出的内容覆盖你的sources.list,只需把版本号改成你自己的。注意,每个ubuntu版本都有自己的代号。
通过上面的学习,相信你已经逐渐了解了包管理器的基本概念和使用。如果你是centos或者fedora,需要自己man一下yum。
编译安装 Nginx
接下来我们说说编译安装 Nginx(发音是 engine X),是一个家喻户晓的 Web 服务器。 它的发明者是俄国的伊戈尔·赛索耶夫。赛索耶夫 2002 年开始写 Nginx,主要目的是解决同一个互联网节点同时进入大量并发请求的问题。注意,大量并发请求不是大量 QPS 的意思,QPS 是吞吐量大,需要快速响应,而高并发时则需要合理安排任务调度。
后来塞索耶夫成立了 Nginx 公司, 2018 年估值到达到 4.3 亿美金。现在基本上国内大厂的 Web 服务器都是基于 Nginx,只不过进行了特殊的修改,比如淘宝用 Tengine。
下面我们再来看看源码安装,在 Linux 上获取nginx源码,可以去搜索 Nginx 官方网站,一般都会提供源码包。
如上图所示,可以看到 nginx-1.18.0 的网址是:http://nginx.org/download/nginx-1.19.2.tar.gz。然后我们用 wget 去下载这个包。 wget 是 GNU 项目下的下载工具,GNU 是早期unix项目的一个变种。linux下很多工具都是从unix继承来的,这就是开源的好处,很多工具不用再次开发了。你可能很难想象windows下的命令工具可以在linux下用,但是linux下的工具却可以在任何系统中用。 因此,linux下面的工具发展速度很快,如今已成为最受欢迎的服务器操作系统。
当然也有同学的机器上没有wget,那么你可以用apt安装一下。
- 第一步:下载源码。我们使用
wget下载nginx源码包:
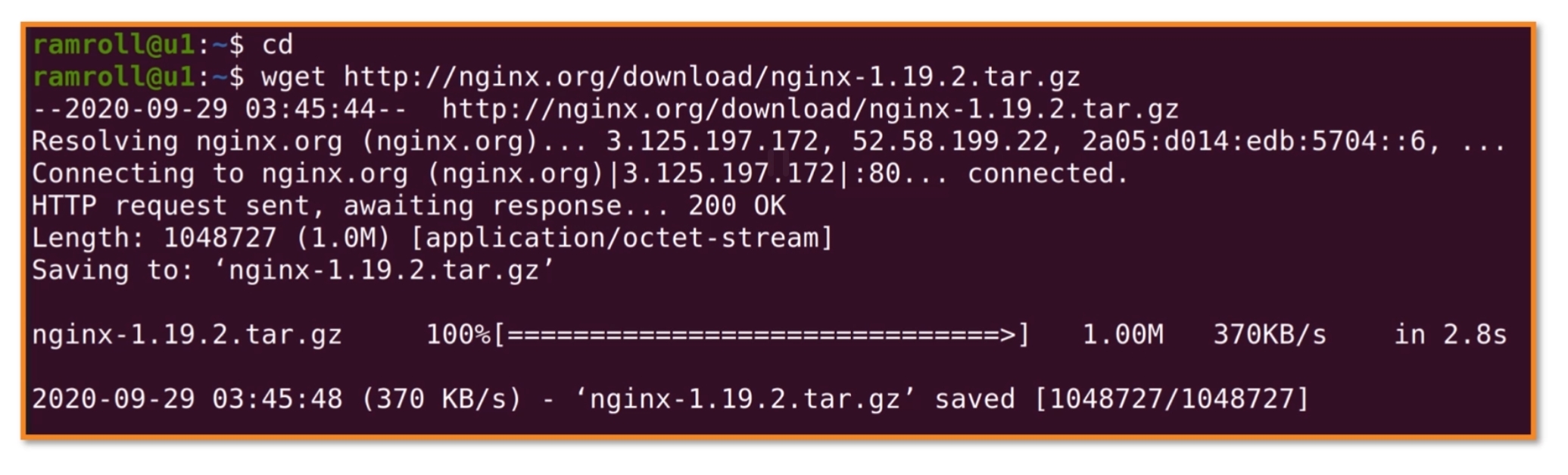
可以像我这样使用cd先切换到家目录。
- 第二步:解压。我们解压下载好的
nginx源码包。
用ls发现包已经存在了,然后使用tar命令解压。
tar是用来打包和解压用的。之所以叫作tar是有一些历史原因:t代表tape(磁带);ar是 archive(档案)。因为早期的存储介质很小,人们习惯把文件打包然后存储到磁带上,那时候unix用的命令就是tar。因为linux是个开源生态,所以就沿袭下来继续使用tar。
-x代表 extract(提取)。-z代表gzip,也就是解压gz类型的文件。-v代表 verbose(显示细节),如果你不输入-v,就不会打印解压过程了。-f代表 file,这里指的是要操作文件,而不是磁带。 所以tar解压通常带有x和f,打包通常是c就是 create 的意思。
- 第三步:配置和解决依赖。解压完,我们进入
nginx的目录看一看。 如下图所示:

可以看到一个叫作configure的文件是绿色的,也就是可执行文件。然后我们执行 configure 文件进行配置,这个配置文件来自一款叫作autoconf的工具,也是 GNU 项目下的,说白了就是bash(Bourne Shell)下的安装打包工具(就是个安装程序)。这个安装程序支持很多配置,你可以用./configure --help看到所有的配置项,如下图所示:
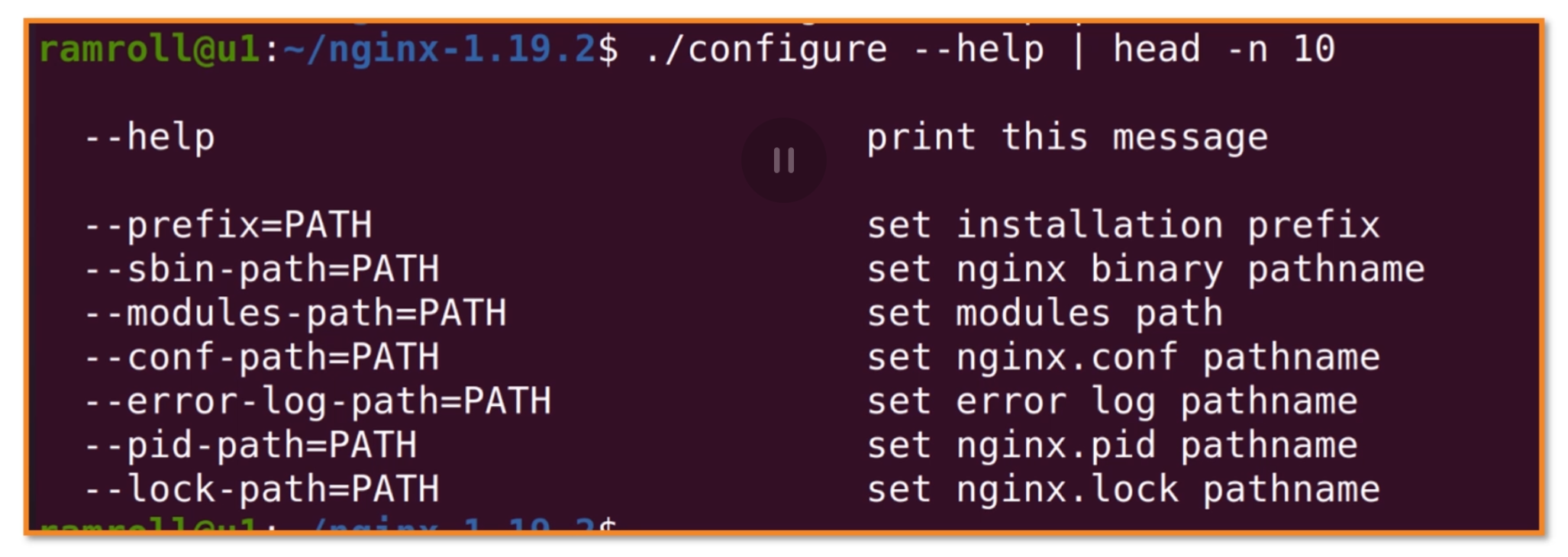
这里有几个非常重要的配置项,叫作prefix。prefix配置项决定了软件的安装目录。如果不配置这个配置项,就会使用默认的安装目录。sbin-path决定了nginx的可执行文件的位置。conf-path决定了nginx配置文件的位置。我们都使用默认,然后执行./configure,如下图所示:
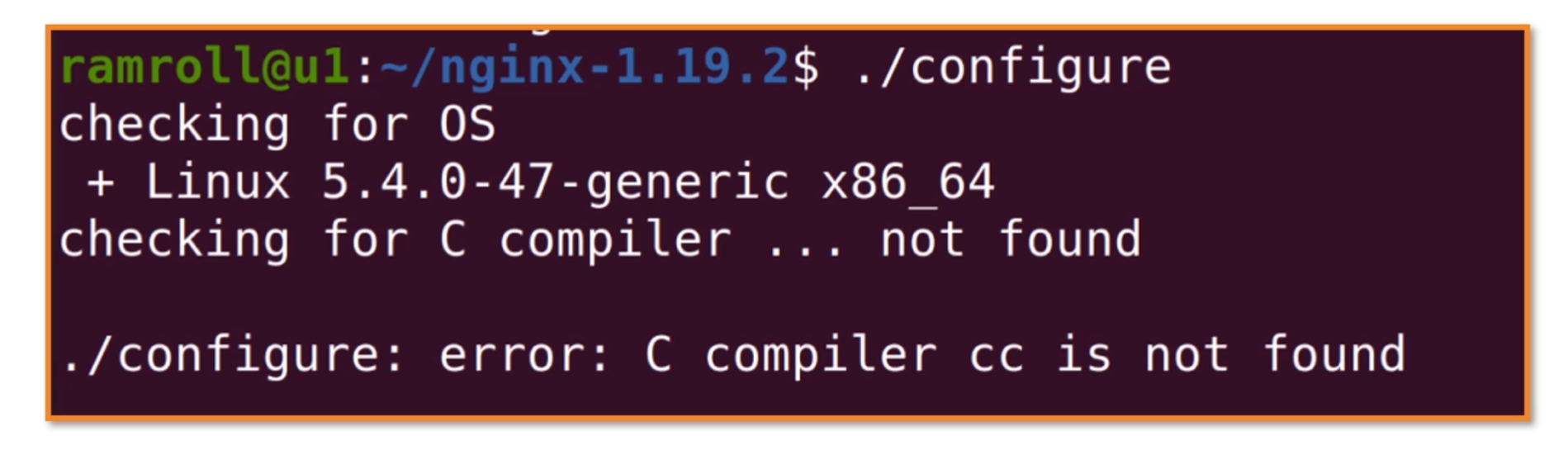
autoconf进行依赖检查的时候,报了一个错误,cc 没有找到。这是因为机器上没有安装gcc工具,gcc 是家喻户晓的工具套件,全名是 GNU Compiler Collection——里面涵盖了包括 c/c++ 在内的多门语言的编译器。
我们用包管理器,安装gcc,如下图所示。安装gcc通常是安装build-essential这个包。
安装完成之后,再执行./configure,如下图所示:
我们看到配置程序开始执行。但是最终报了一个错误,如下图所示:

报错的内容是,nginx的HTTP rewrite模块,需要PCRE库。 PCRE 是perl语言的兼容正则表达式库。perl语言一直以支持原生正则表达式,而受到广大编程爱好者的喜爱。我曾经看到过一个 IBM 的朋友用perl加上wget就实现了一个简单的爬虫。接下来,我们开始安装PCRE。
一般这种依赖库,会叫pcre-dev或者libpcre。用apt查询了一下,然后grep。
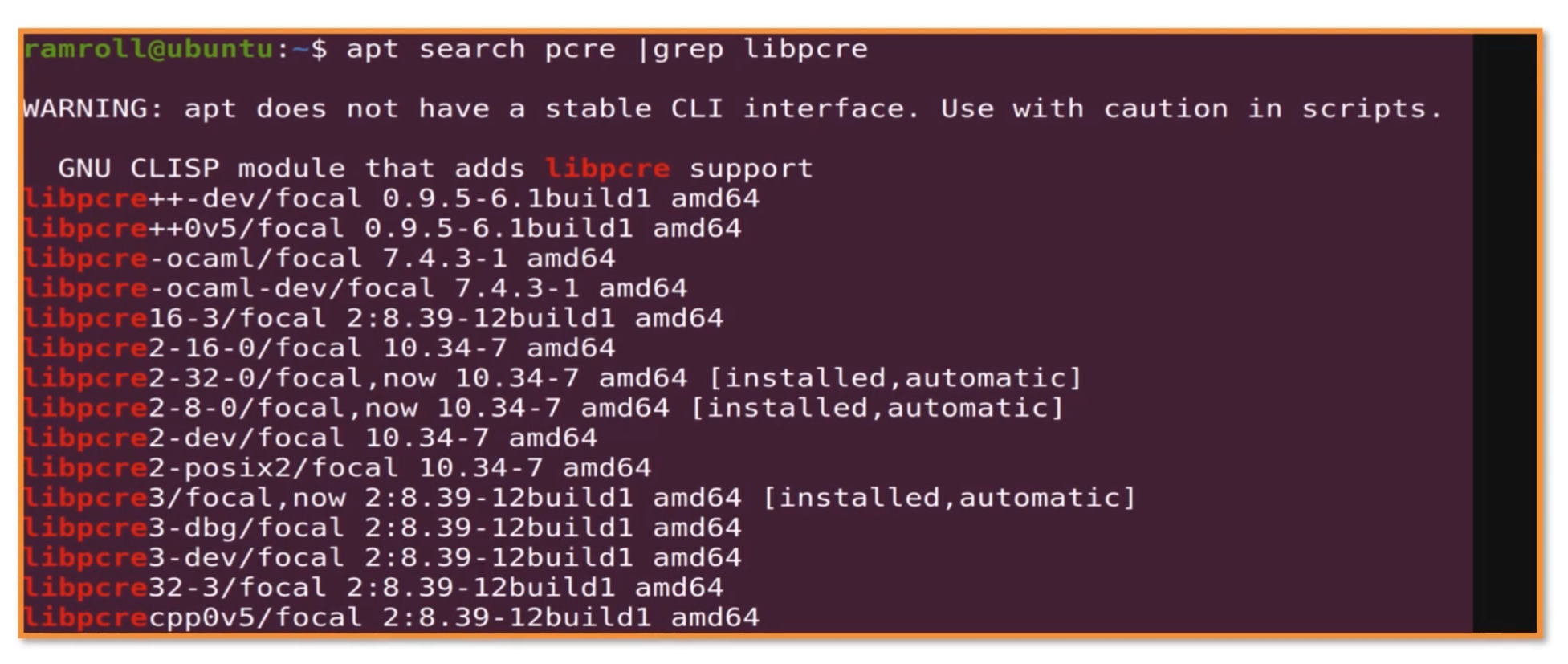
我们看到有pcre2也有pcre3。这个时候可以考虑试试pcre3。
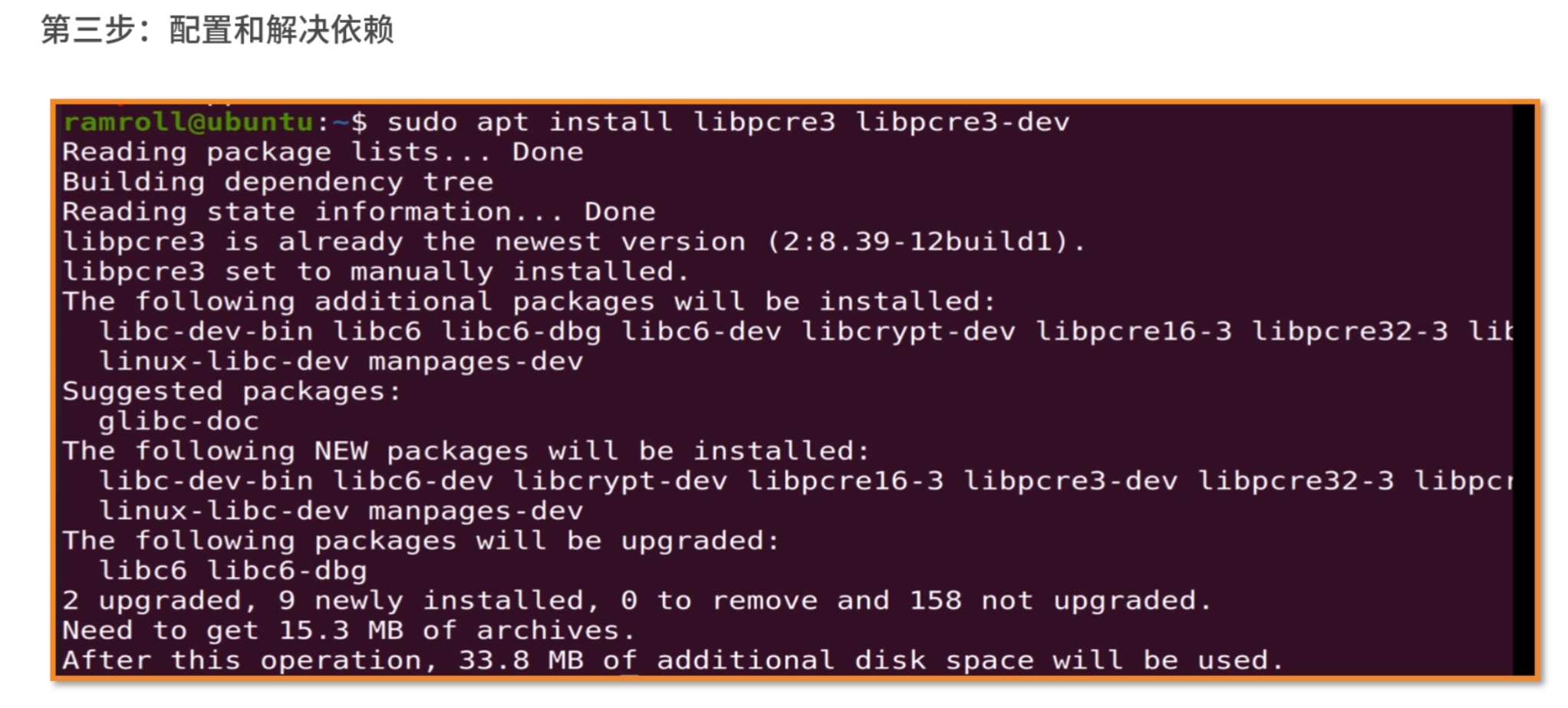
安装完成之后再试试./configure,提示还需要zlib。然后我们用类似的方法解决zlib依赖。
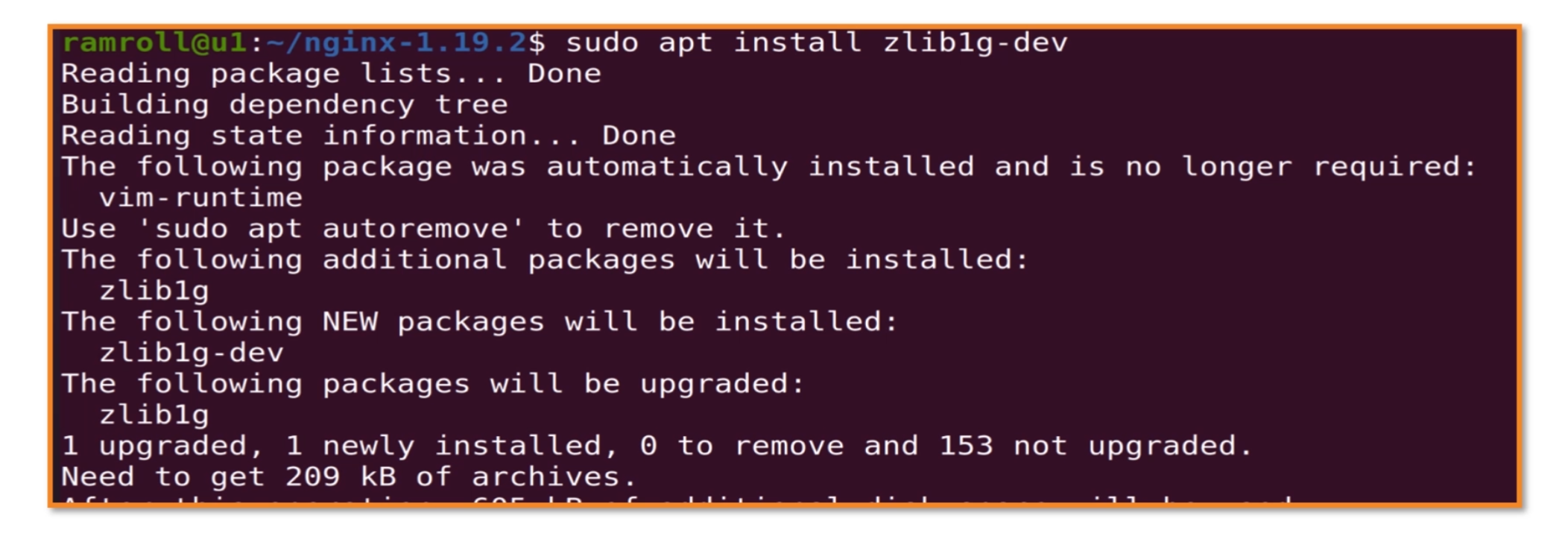
zlib包的名字叫zlib1g不太好找,需要查资料才能确定是这个名字。
我们再尝试配置,终于配置成功了。
- 第四步:编译和安装。
通常配置完之后,我们输入make && sudo make install进行编译和安装。make是linux下面一个强大的构建工具。autoconf也就是./configure会在当前目录下生成一个 MakeFile 文件。make会根据MakeFile文件编译整个项目。编译完成后,能够形成和当前操作系统以及 CPU 指令集兼容的二进制可执行文件。然后再用make install安装。&&符号代表执行完make再去执行make installl。
你可以看到编译是个非常慢的活。等待了差不多 1 分钟,终于结束了。nginx被安装到了/usr/local/nginx中,如果需要让nginx全局执行,可以设置一个软连接到/usr/local/bin,具体如下:
1 | ln -sf /usr/local/nginx/sbin/nginx /usr/local/sbin/nginx |
为什么会有编译安装?
学完整个编译安装 Ngnix 过程后,你可能会问,为什么会有编译安装这么复杂的事情。
原来使用 C/C++ 写的程序存在一个交叉编译的问题。就是写一次程序,在很多个平台执行。而不同指令集的 CPU 指令,还有操作系统的可执行文件格式是不同的。因此,这里有非常多的现实问题需要解决。一般是由操作系统的提供方,比如 RedHat 来牵头解决这些问题。你可以用apt等工具提供给用户已经编译好的包。apt会自动根据用户的平台类型选择不同的包。
但如果某个包没有在平台侧注册,也没有提供某个 Linux 平台的软件包,我们就需要回退到编译安装,通过源代码直接在某个平台安装。
编译安装和包管理安装有什么优势和劣势?
老规矩,请你先在脑海里构思下给面试官的表述,并把你的思考写在留言区,然后再来看我接下来的分析。
【解析】 包管理安装很方便,但是有两点劣势。
第一点是需要提前将包编译好,因此有一个发布的过程,如果某个包没有发布版本,或者在某个平台上找不到对应的发布版本,就需要编译安装。
第二点就是如果一个软件的定制程度很高,可能会在编译阶段传入参数,比如利用configure传入配置参数,这种时候就需要编译安装。
利用 Linux 指令分析 Web 日志
第一步:能不能这样做?
当我们想要分析一个线上文件的时候,首先要思考,能不能这样做? 这里你可以先用htop指令看一下当前的负载。如果你的机器上没有htop,可以考虑用yum或者apt去安装。
然后我们用ls查看文件大小。发现这只是一个 7M 的文件,因此对线上的影响可以忽略不计。如果文件太大,建议你用scp指令将文件拷贝到闲置服务器再分析。下图中我使用了--block-size让ls以M为单位显示文件大小。

第二步:LESS 日志文件
在分析日志前,给你提个醒,记得要less一下,看看日志里面的内容。之前我们说过,尽量使用less这种不需要读取全部文件的指令,因为在线上执行cat是一件非常危险的事情,这可能导致线上服务器资源不足。
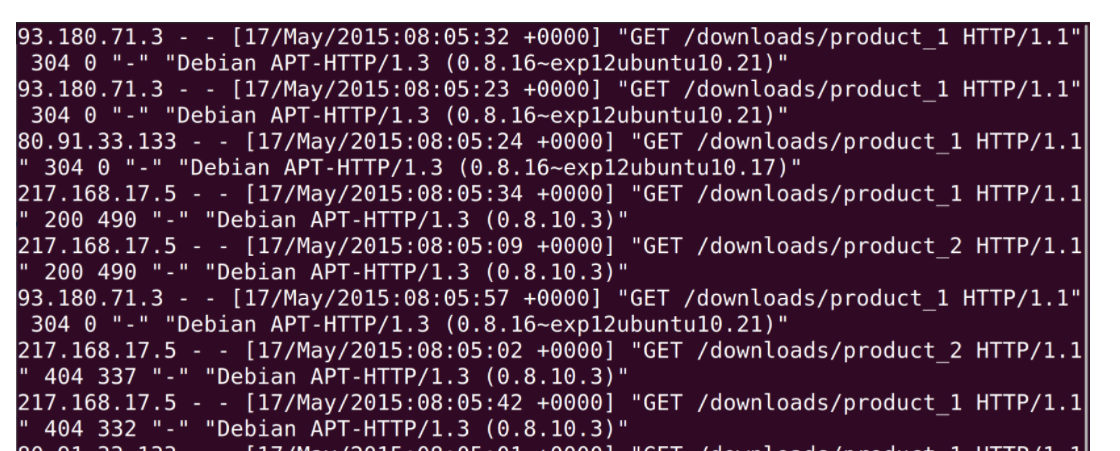
如上图所示,我们看到nginx的access_log每一行都是一次用户的访问,从左到右依次是:
- IP 地址;
- 时间;
- HTTP 请求的方法、路径和协议版本、返回的状态码;
- User Agent。
第三步:PV 分析
PV(Page View),用户每访问一个页面就是一次Page View。对于nginx的acess_log来说,分析 PV 非常简单,我们直接使用wc -l就可以看到整体的PV。

如上图所示:我们看到了一共有 51462 条 PV。
第四步:PV 分组
通常一个日志中可能有几天的 PV,为了得到更加直观的数据,有时候需要按天进行分组。为了简化这个问题,我们先来看看日志中都有哪些天的日志。
使用awk '{print $4}' access.log | less可以看到如下结果。awk是一个处理文本的领域专有语言。这里就牵扯到领域专有语言这个概念,英文是Domain Specific Language。领域专有语言,就是为了处理某个领域专门设计的语言。比如awk是用来分析处理文本的DSL,html是专门用来描述网页的DSL,SQL是专门用来查询数据的DSL……大家还可以根据自己的业务设计某种针对业务的DSL。
你可以看到我们用$4代表文本的第 4 列,也就是时间所在的这一列,如下图所示:
我们想要按天统计,可以利用 awk提供的字符串截取的能力。
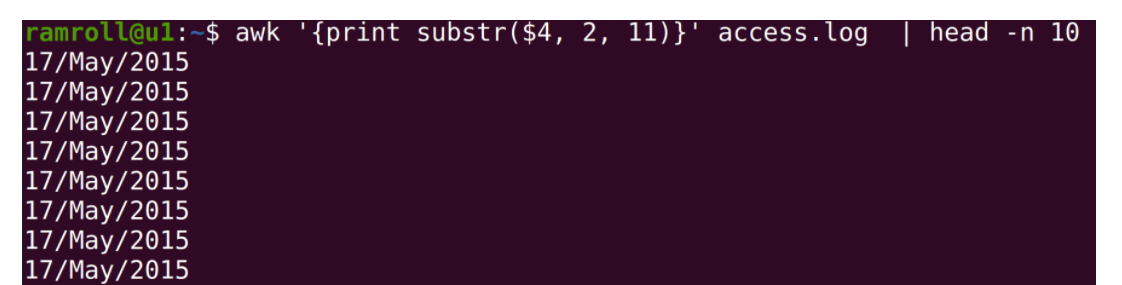
上图中,我们使用awk的substr函数,数字2代表从第 2 个字符开始,数字11代表截取 11 个字符。
接下来我们就可以分组统计每天的日志条数了。
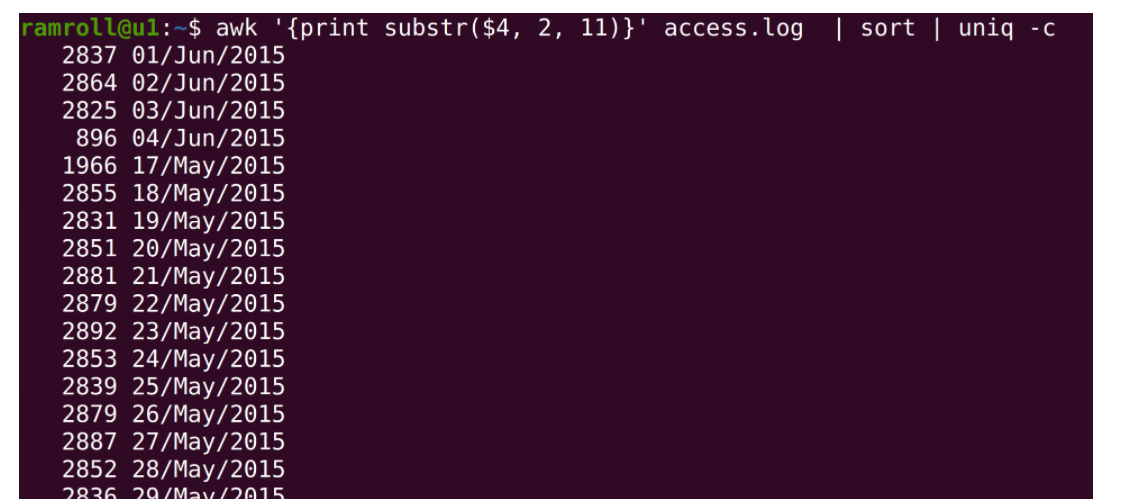
上图中,使用sort进行排序,然后使用uniq -c进行统计。你可以看到从 2015 年 5 月 17 号一直到 6 月 4 号的日志,还可以看到每天的 PV 量大概是在 2000~3000 之间。
第五步:分析 UV
接下来我们分析 UV。UV(Uniq Visitor),也就是统计访问人数。通常确定用户的身份是一个复杂的事情,但是我们可以用 IP 访问来近似统计 UV。

上图中,我们使用 awk 去打印$1也就是第一列,接着sort排序,然后用uniq去重,最后用wc -l查看条数。 这样我们就知道日志文件中一共有2660个 IP,也就是2660个 UV。
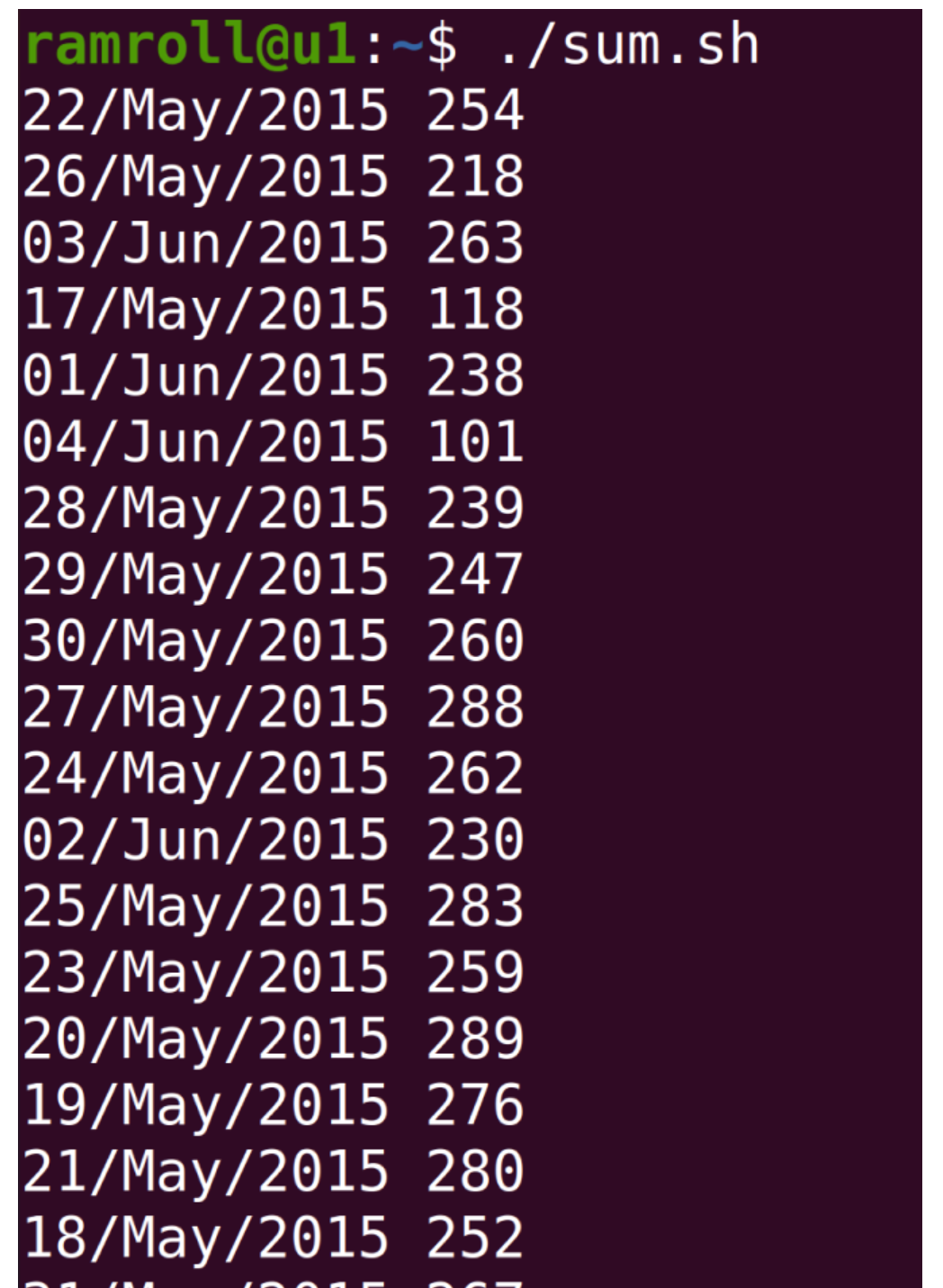
第六步:分组分析 UV
接下来我们尝试按天分组分析每天的 UV 情况。这个情况比较复杂,需要较多的指令,我们先创建一个叫作sum.sh的bash脚本文件,写入如下内容:
1 |
|
具体分析如下。
- 文件首部我们使用
#!,表示我们将使用后面的/usr/bin/bash执行这个文件。 - 第一次
awk我们将第 4 列的日期和第 1 列的ip地址拼接在一起。 - 下面的
sort是把整个文件进行一次字典序排序,相当于先根据日期排序,再根据 IP 排序。 - 接下来我们用
uniq去重,日期 +IP 相同的行就只保留一个。 - 最后的
awk我们再根据第 1 列的时间和第 2 列的 IP 进行统计。
为了理解最后这一行描述,我们先来简单了解下awk的原理。
awk本身是逐行进行处理的。因此我们的next关键字是提醒awk跳转到下一行输入。 对每一行输入,awk会根据第 1 列的字符串(也就是日期)进行累加。之后的END关键字代表一个触发器,就是 END 后面用 {} 括起来的语句会在所有输入都处理完之后执行——当所有输入都执行完,结果被累加到uv中后,通过foreach遍历uv中所有的key,去打印ip和ip对应的数量。
编写完上面的脚本之后,我们保存退出编辑器。接着执行chmod +x ./sum.sh,给sum.sh增加执行权限。然后我们可以像下图这样执行,获得结果:
在成百上千的集群中安装一个 Java 环境
第一步:搭建学习用的集群
第一步我们先搭建一个学习用的集群。这里简化一下模型。我在自己的电脑上装一个ubuntu桌面版的虚拟机,然后再装两个ubuntu服务器版的虚拟机。
相对于桌面版,服务器版对资源的消耗会少很多。我将教学材料中桌面版的ubuntu命名为u1,两个用来被管理的服务器版ubuntu叫作v1和v2。
用桌面版的原因是:我喜欢ubuntu漂亮的开源字体,这样会让我在给你准备素材的时候拥有一个好心情。如果你对此感兴趣,可以搜索ubuntu mono,尝试把这个字体安装到自己的文本编辑器中。不过我还是觉得在ubuntu中敲代码更有感觉。
注意,我在这里只用了 3 台服务器,但是接下来我们要写的脚本是可以在很多台服务器之间复用的。
第二步:循环遍历 IP 列表
你可以想象一个局域网中有很多服务器需要管理,它们彼此之间网络互通,我们通过一台主服务器对它们进行操作,即通过u1操作v1和v2。
在主服务器上我们维护一个ip地址的列表,保存成一个文件,如下图所示:

目前iplist中只有两项,但是如果我们有足够的机器,可以在里面放成百上千项。接下来,请你思考shell如何遍历这些ip?
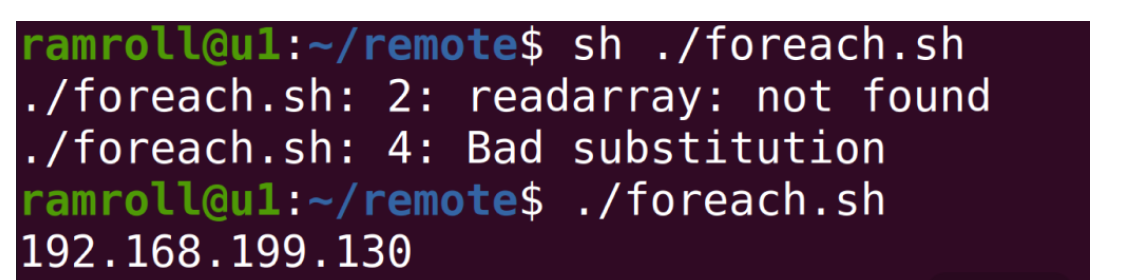
你可以先尝试实现一个最简单的程序,从文件iplist中读出这些ip并尝试用for循环遍历这些ip,具体程序如下:
1 |
|
首行的#!叫作 Shebang。Linux 的程序加载器会分析 Shebang 的内容,决定执行脚本的程序。这里我们希望用bash来执行这段程序,因为我们用到的 readarray 指令是bash 4.0后才增加的能力。
readarray指令将 iplist 文件中的每一行读取到变量ips中。ips是一个数组,可以用echo ${ips[@]}打印其中全部的内容:@代表取数组中的全部内容;$符号是一个求值符号。不带$的话,ips[@]会被认为是一个字符串,而不是表达式。
for循环遍历数组中的每个ip地址,echo把地址打印到屏幕上。
如果用shell执行上面的程序会报错,因为readarray是bash 4.0后支持的能力,因此我们用chomd为foreach.sh增加执行权限,然后直接利用shebang的能力用bash执行,如下图所示:
第三步:创建集群管理账户
为了方便集群管理,通常使用统一的用户名管理集群。这个账号在所有的集群中都需要保持命名一致。比如这个集群账号的名字就叫作lagou。
接下来我们探索一下如何创建这个账户lagou,如下图所示:
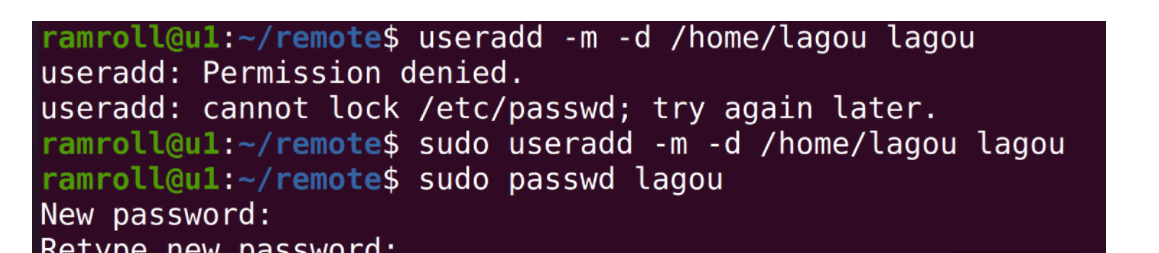
上面我们创建了lagou账号,然后把lagou加入sudo分组。这样lagou就有了sudo成为root的能力,如下图所示:

接下来,我们设置lagou用户的初始化shell是bash,如下图所示:

这个时候如果使用命令su lagou,可以切换到lagou账号,但是你会发现命令行没有了颜色。因此我们可以将原来用户下面的.bashrc文件拷贝到/home/lagou目录下,如下图所示:

这样,我们就把一些自己平时用的设置拷贝了过去,包括终端颜色的设置。.bashrc是启动bash的时候会默认执行的一个脚本文件。
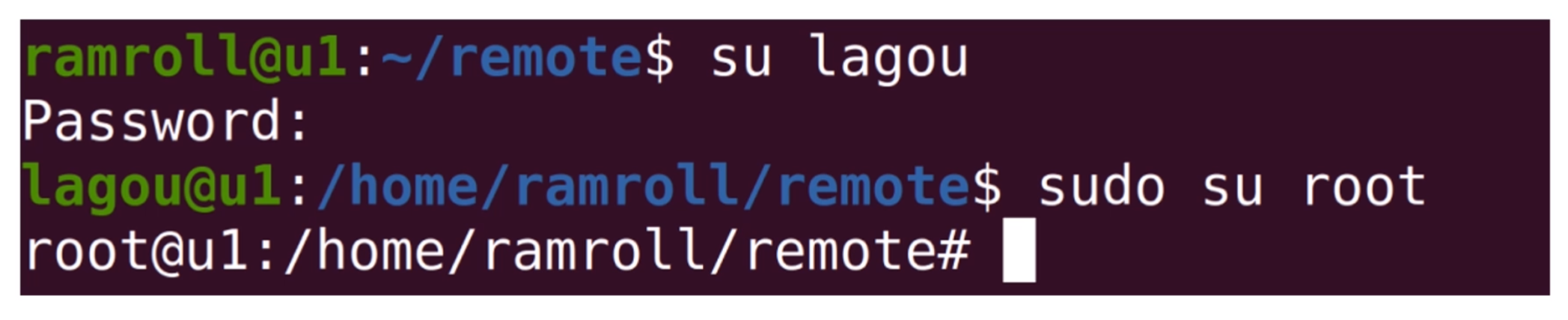
接下来,我们编辑一下/etc/sudoers文件,增加一行lagou ALL=(ALL) NOPASSWD:ALL表示lagou账号 sudo 时可以免去密码输入环节,如下图所示:
我们可以把上面的完整过程整理成指令文件,create_lagou.sh:
1 | sudo useradd -m -d /home/lagou lagou |
你可以删除用户lagou,并清理/etc/sudoers文件最后一行。用指令userdel lagou删除账户,然后执行create_lagou.sh重新创建回lagou账户。如果发现结果一致,就代表create_lagou.sh功能没有问题。
最后我们想在v1``v2上都执行create_logou.sh这个脚本。但是你不要忘记,我们的目标是让程序在成百上千台机器上传播,因此还需要一个脚本将create_lagou.sh拷贝到需要执行的机器上去。
这里,可以对foreach.sh稍做修改,然后分发create_lagou.sh文件。
如果你的机器非常多,上述过程会变得非常烦琐。你可以先带着这个问题学习下面的Step 4,然后再返回来重新思考这个问题,当然你也可以远程执行脚本。另外,还有一个叫作sshpass的工具,可以帮你把密码传递给要远程执行的指令,如果你对这块内容感兴趣,可以自己研究下这个工具。
第四步: 打通集群权限
接下来我们需要打通从主服务器到v1和v2的权限。当然也可以每次都用ssh输入用户名密码的方式登录,但这并不是长久之计。 如果我们有成百上千台服务器,输入用户名密码就成为一件繁重的工作。
这时候,你可以考虑利用主服务器的公钥在各个服务器间登录,避免输入密码。接下来我们聊聊具体的操作步骤:
首先,需要在u1上用ssh-keygen生成一个公私钥对,然后把公钥写入需要管理的每一台机器的authorized_keys文件中。如下图所示:我们使用ssh-keygen在主服务器u1中生成公私钥对。
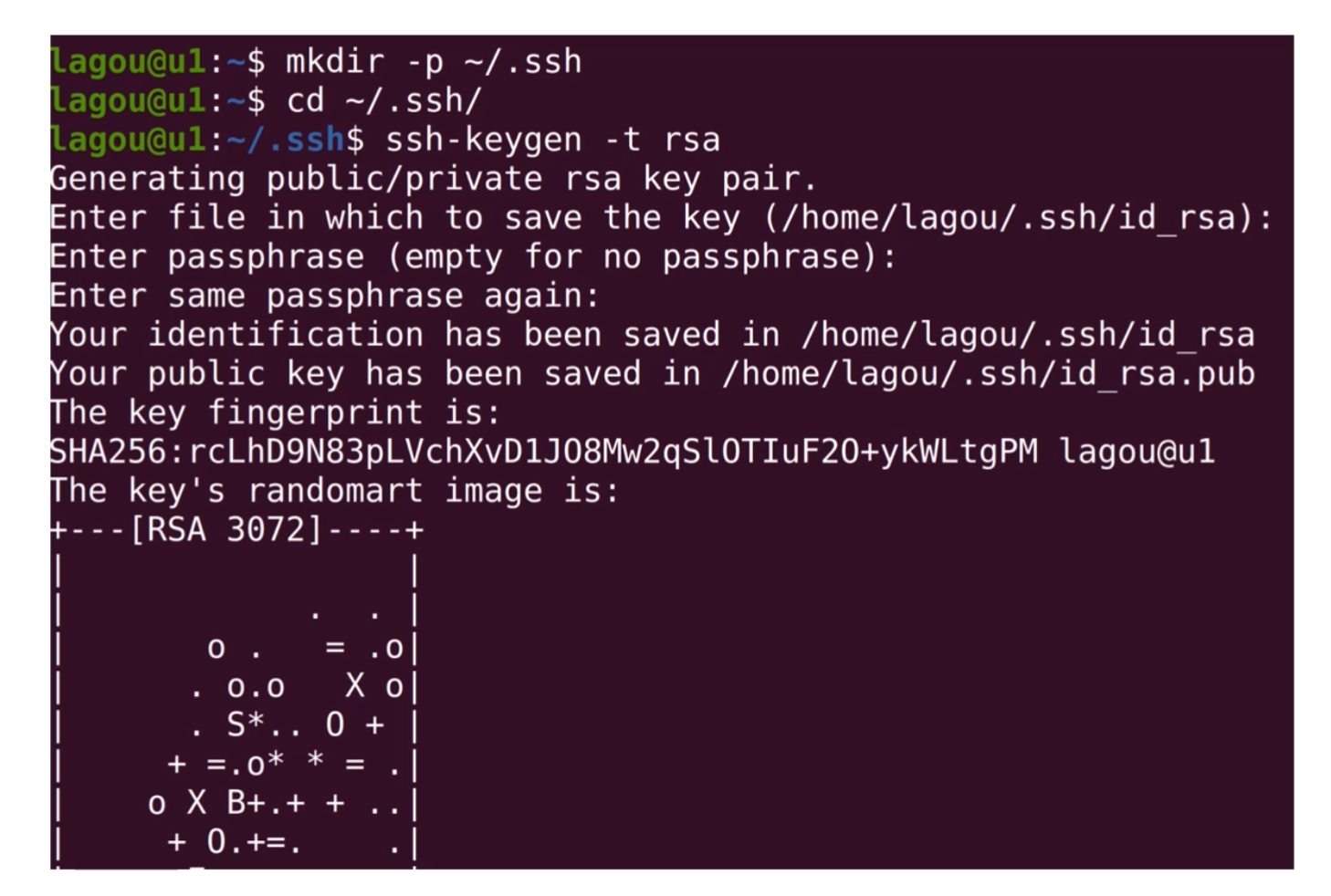
然后使用mkdir -p创建~/.ssh目录,-p的优势是当目录不存在时,才需要创建,且不会报错。~代表当前家目录。 如果文件和目录名前面带有一个.,就代表该文件或目录是一个需要隐藏的文件。平时用ls的时候,并不会查看到该文件,通常这种文件拥有特别的含义,比如~/.ssh目录下是对ssh的配置。
我们用cd切换到.ssh目录,然后执行ssh-keygen。这样会在~/.ssh目录中生成两个文件,id_rsa.pub公钥文件和is_rsa私钥文件。 如下图所示:
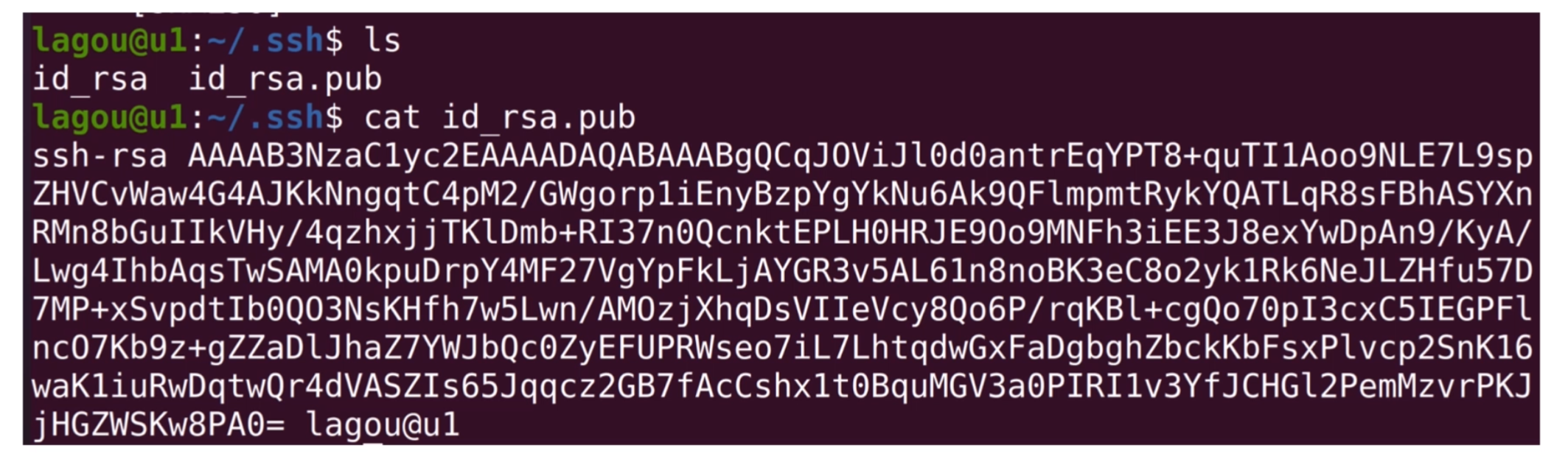
可以看到id_rsa.pub文件中是加密的字符串,我们可以把这些字符串拷贝到其他机器对应用户的~/.ssh/authorized_keys文件中,当ssh登录其他机器的时候,就不用重新输入密码了。 这个传播公钥的能力,可以用一个shell脚本执行,这里我用transfer_key.sh实现。
我们修改一下foreach.sh,并写一个transfer_key.sh配合foreach.sh的工作。transfer_key.sh内容如下:
foreach.sh
1 |
|
tranfer_key.sh
1 | ip=$1 |
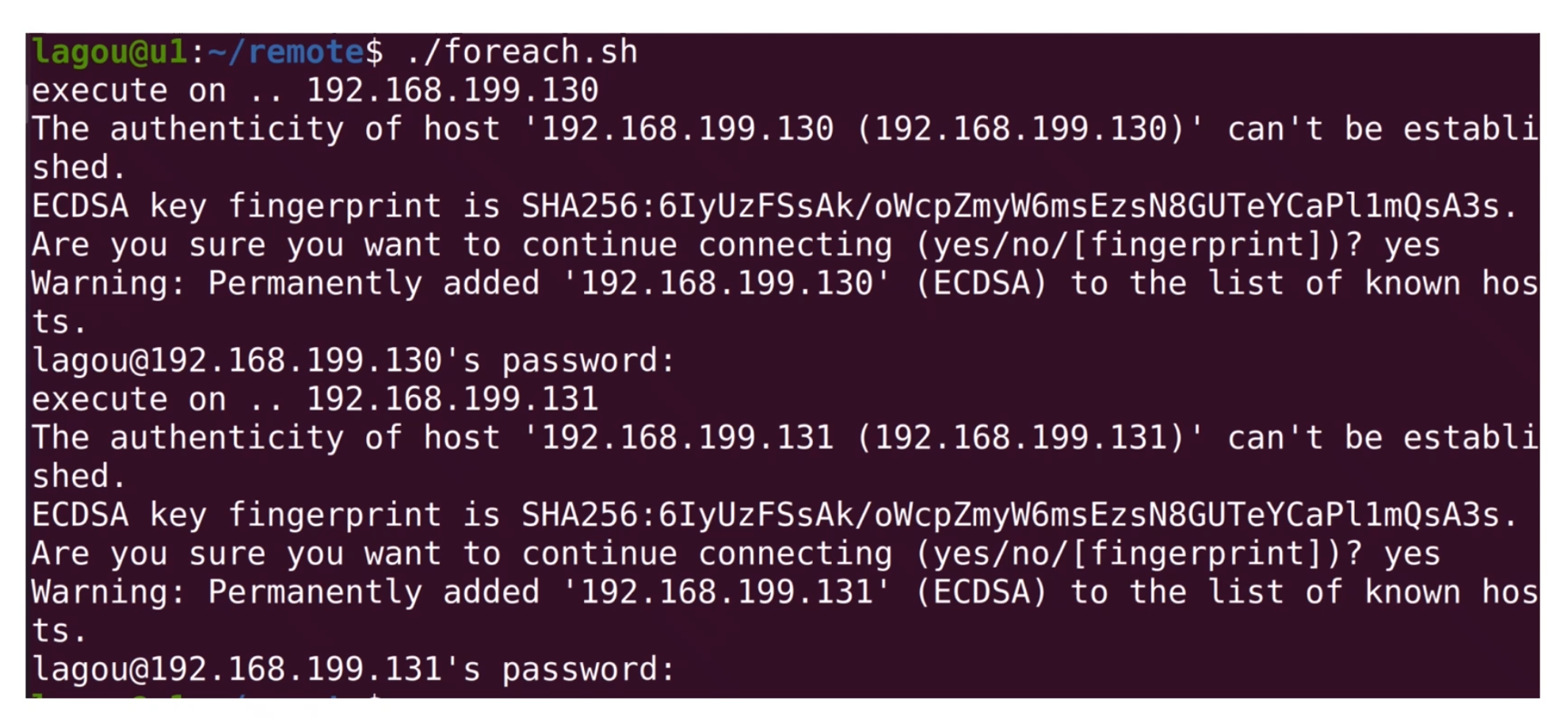
在foreach.sh中我们执行 transfer_key.sh,并且将 IP 地址通过参数传递过去。在 transfer_key.sh 中,用$1读出 IP 地址参数, 再将公钥写入变量pubkey,然后登录到对应的服务器,执行多行指令。用mkdir指令检查.ssh目录,如不存在就创建这个目录。最后我们将公钥追加写入目标机器的~/.ssh/authorized_keys中。
chmod 700和chmod 600是因为某些特定的linux版本需要.ssh的目录为可读写执行,authorized_keys文件的权限为只可读写。而为了保证安全性,组用户、所有用户都不可以访问这个文件。
此前,我们执行foreach.sh需要输入两次密码。完成上述操作后,我们再登录这两台服务器就不需要输入密码了。
接下来,我们尝试一下免密登录,如下图所示:
第五步:单机安装 Java 环境
在远程部署 Java 环境之前,我们先单机完成以下 Java 环境的安装,用来收集需要执行的脚本。
在ubuntu上安装java环境可以直接用apt。
我们通过下面几个步骤脚本配置 Java 环境:
1 | sudo apt install openjdk-11-jdk |
经过一番等待我们已经安装好了java,然后执行下面的脚本确认java安装。
1 | which java |
根据最小权限原则,执行 Java 程序我们考虑再创建一个用户ujava。
1 | sudo useradd -m -d /opt/ujava ujava |
这个用户可以不设置密码,因为我们不会真的登录到这个用户下去做任何事情。接下来我们为用户配置 Java 环境变量,如下图所示:

通过两次 ls 追查,可以发现java可执行文件软连接到/etc/alternatives/java然后再次软连接到/usr/lib/jvm/java-11-openjdk-amd64下。
这样我们就可以通过下面的语句设置 JAVA_HOME 环境变量了。
1 | export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64/ |
Linux 的环境变量就好比全局可见的数据,这里我们使用 export 设置JAVA_HOME环境变量的指向。如果你想看所有的环境变量的指向,可以使用env指令。
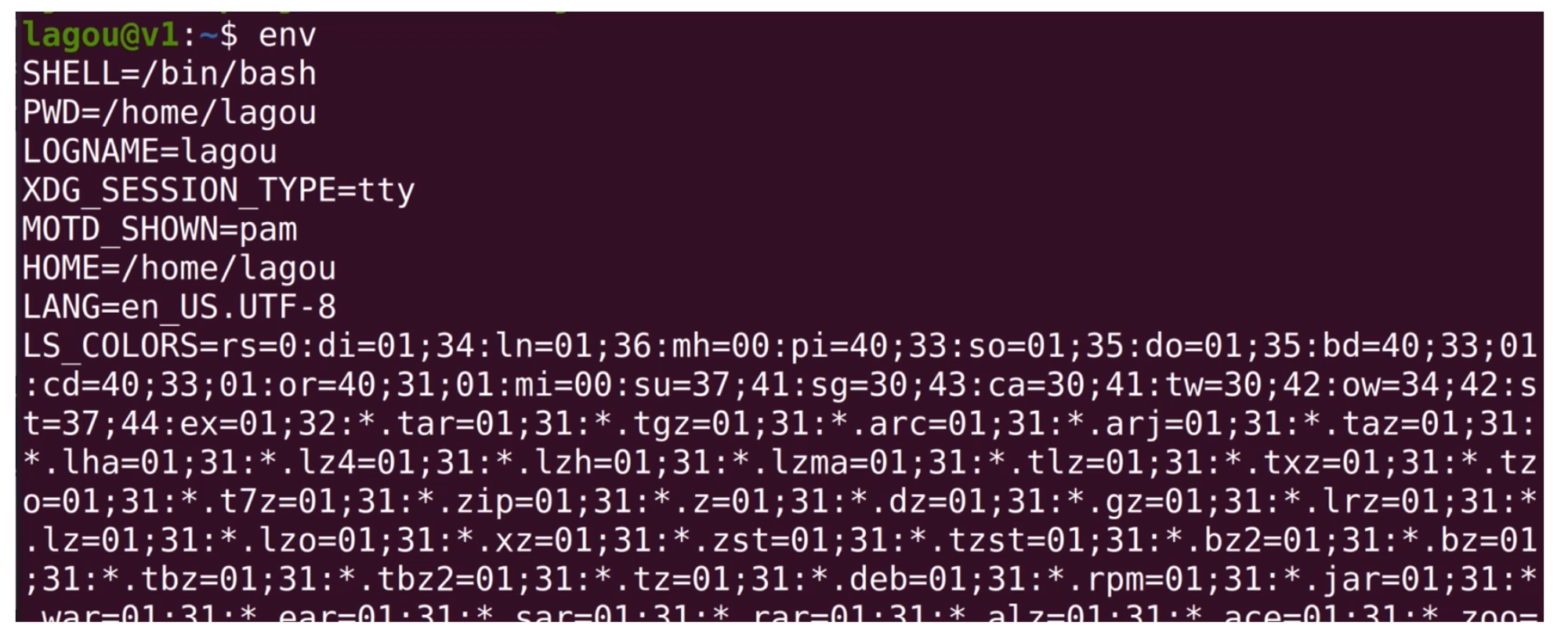
其中有一个环境变量比较重要,就是PATH。

如上图,我们可以使用shell查看PATH的值,PATH中用:分割,每一个目录都是linux查找执行文件的目录。当用户在命令行输入一个命令,Linux 就会在PATH中寻找对应的执行文件。
当然我们不希望JAVA_HOME配置后重启一次电脑就消失,因此可以把这个环境变量加入ujava用户的profile中。这样只要发生用户登录,就有这个环境变量。
1 | sudo sh -c 'echo "export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64/" >> /opt/ujava/.bash_profile' |
将JAVA_HOME加入bash_profile,这样后续远程执行java指令时就可以使用JAVA_HOME环境变量了。
最后,我们将上面所有的指令整理起来,形成一个install_java.sh。
1 | sudo apt -y install openjdk-11-jdk |
apt后面增了一个-y是为了让执行过程不弹出确认提示。
第六步:远程安装 Java 环境
终于到了远程安装 Java 环境这一步,我们又需要用到foreach.sh。为了避免每次修改,你可以考虑允许foreach.sh带一个文件参数,指定需要远程执行的脚本。
1 |
|
改写后的foreach会读取第一个执行参数作为远程执行的脚本文件。 而bash -s会提示使用标准输入流作为命令的输入;< $script负责将脚本文件内容重定向到远程bash的标准输入流。
然后我们执行foreach.sh install_java.sh,机器等待 1 分钟左右,在执行结束后,可以用下面这个脚本检测两个机器中的安装情况。
1 | sudo -u ujava -i /bin/bash -c 'echo $JAVA_HOME' |
check.sh中我们切换到ujava用户去检查JAVA_HOME环境变量和 Java 版本。执行的结果如下图所示:
linux命令的一些题目
搜索文件系统中所有以包含 std字符串且以.h扩展名结尾的文件。
1 | sudo find / -name "*std*.h" |
请问下面这段 Shell 程序的作用是什么?
1 | mkfifo pipe1 |
前 2 行代码创建了两个管道文件。
从第 3 行开始,代码变得复杂。echo -n run就是向输出流中写入一个run字符串(不带回车,所以用-n)。通过管道,将这个结果传递给了cat。cat是 concatenate 的缩写,意思是把文件粘在一起。
- 当
cat用>重定向输出到一个管道文件时,如果没有其他进程从管道文件中读取内容,cat会阻塞。 - 当
cat用<读取一个管道内容时,如果管道中没有输入,也会阻塞。
从这个角度来看,总共有 3 次重定向:
- 将
-也就是输入流的内容和pipe1内容合并重定向到pipe2; - 将
pipe2内容重定向到cat; - 将
cat的内容重定向到pipe1。
仔细观察下路径:pipe1->pipe2->pipe1,构成了一个循环。 这样导致管道pipe1管道pipe2中总是有数据(没有数据的时间太短)。于是,就构成了一个无限循环。我们打开执行这个程序后,可以用htop查看当前的 CPU 使用情况,会发现 CPU 占用率很高。
如果一个目录是只读权限,那么这个目录下面的文件还可写吗?
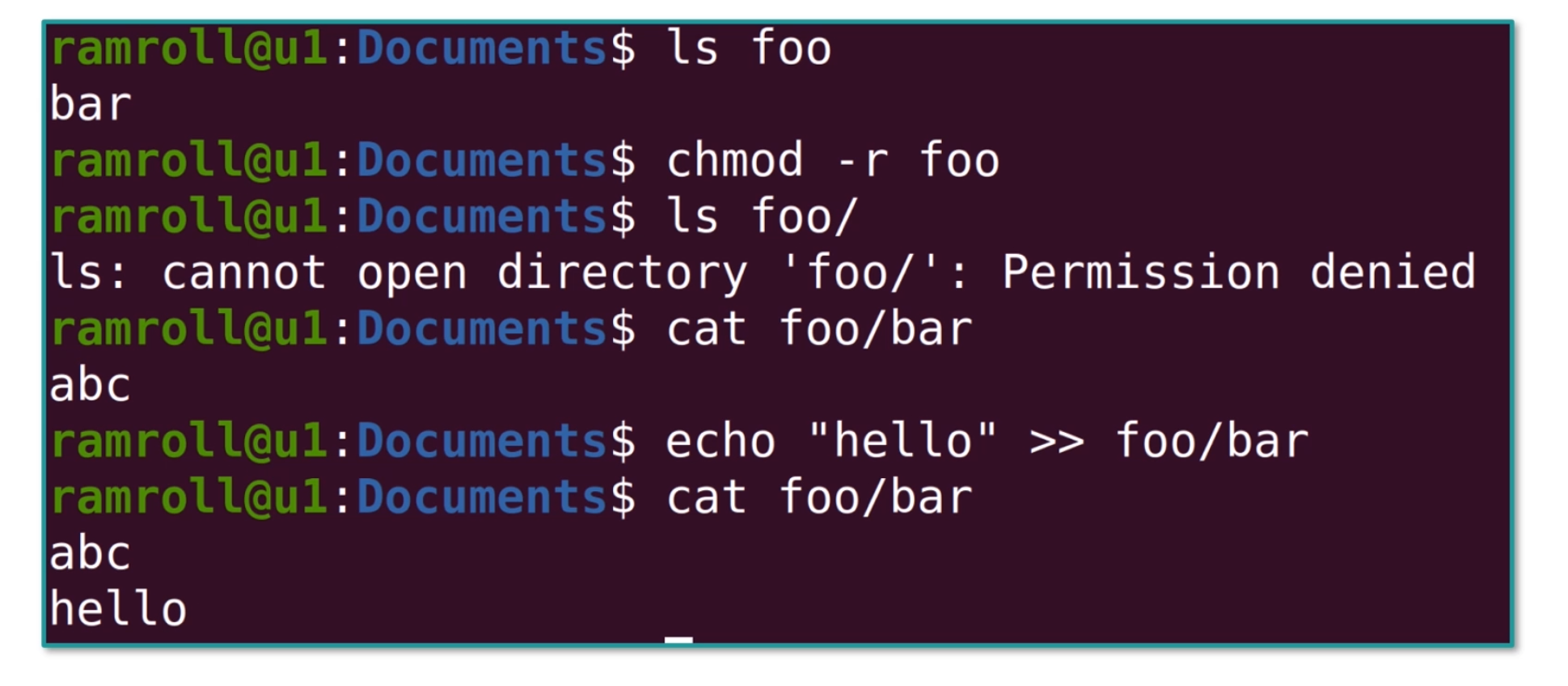
你可以看到上图中,foo 目录不可读了,下面的foo/bar文件还可以写。 即便它不可写了,下面的foo/bar文件还是可以写。
但是想要创建新文件就会出现报错,因为创建新文件也需要改目录文件。这个例子说明 Linux 中的文件内容并没有存在目录中,目录中却有文件清单。
如何查看正在 TIME_WAIT 状态的连接数量?
注意,这里有个小坑,就是 netstat 会有两行表头,这两行可以用 tail 过滤掉,下面tail -n +3就是告诉你 tail 从第 3 行开始显示。-a代表显示所有的 socket。
1 | netstat -a | tail -n +3 | wc -l |
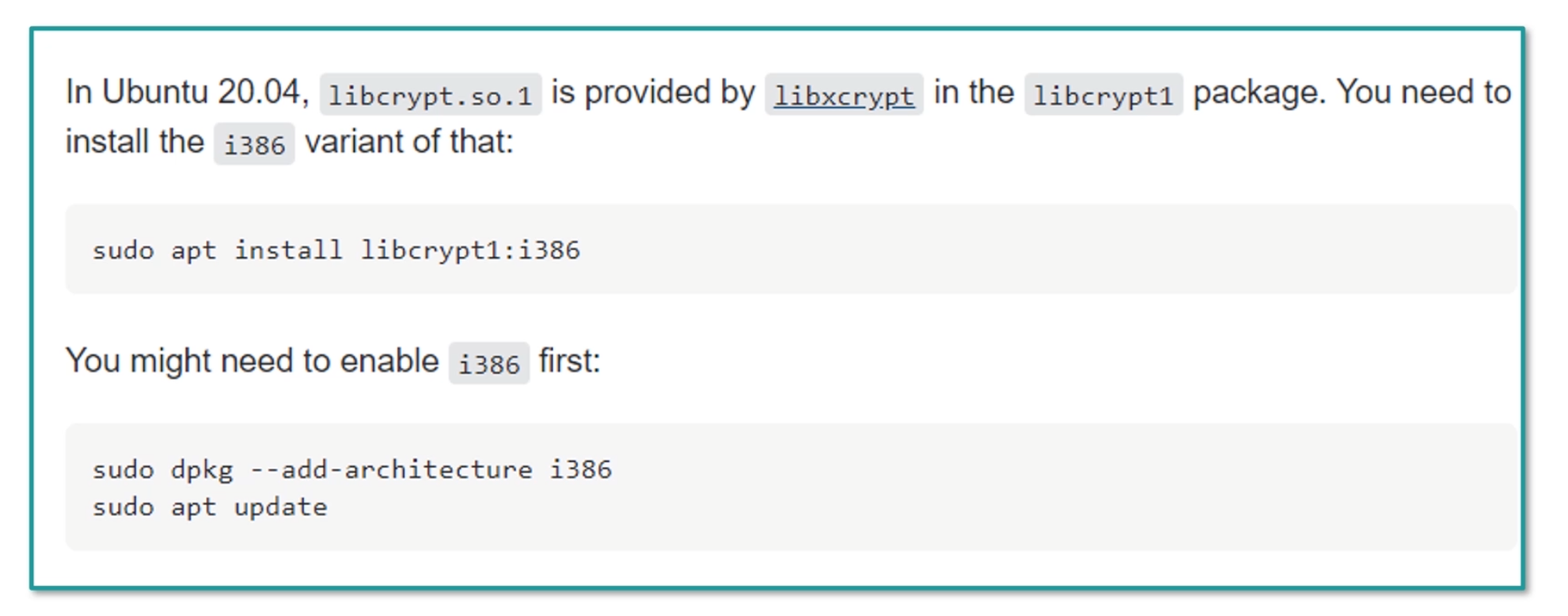
如果你在编译安装 MySQL 时,发现找不到libcrypt.so ,应该如何处理?
遇到这类问题,首先应该去查资料。 比如查 StackOverflow,搜索关键词:libcrypt.so not found,或者带上自己的操作系统ubuntu。下图是关于 Stackoverflow 的一个解答:
根据今天的 access_log 分析出有哪些终端访问了这个网站,并给出分组统计结果。
access_log中有Debian和Ubuntu等等。我们可以利用下面的指令看到,第 12 列是终端,如下图所示:
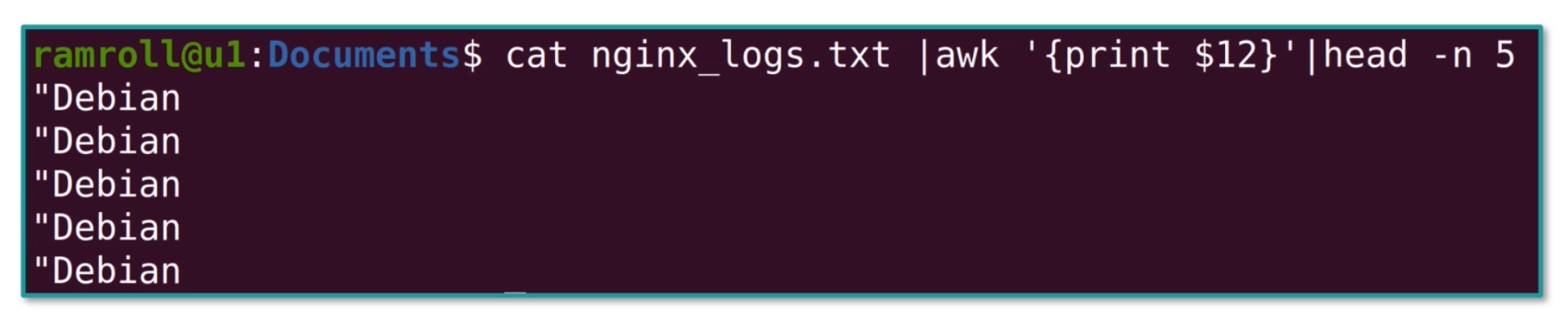
我们还可以使用sort和uniq查看有哪些终端,如下图所示:
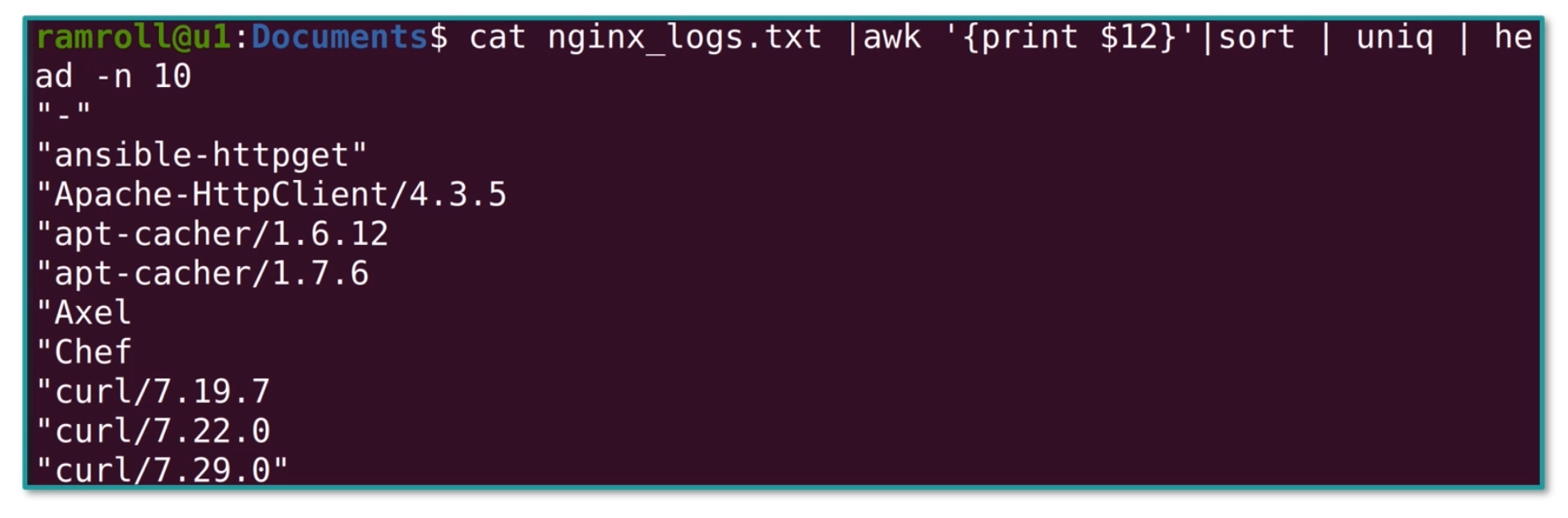
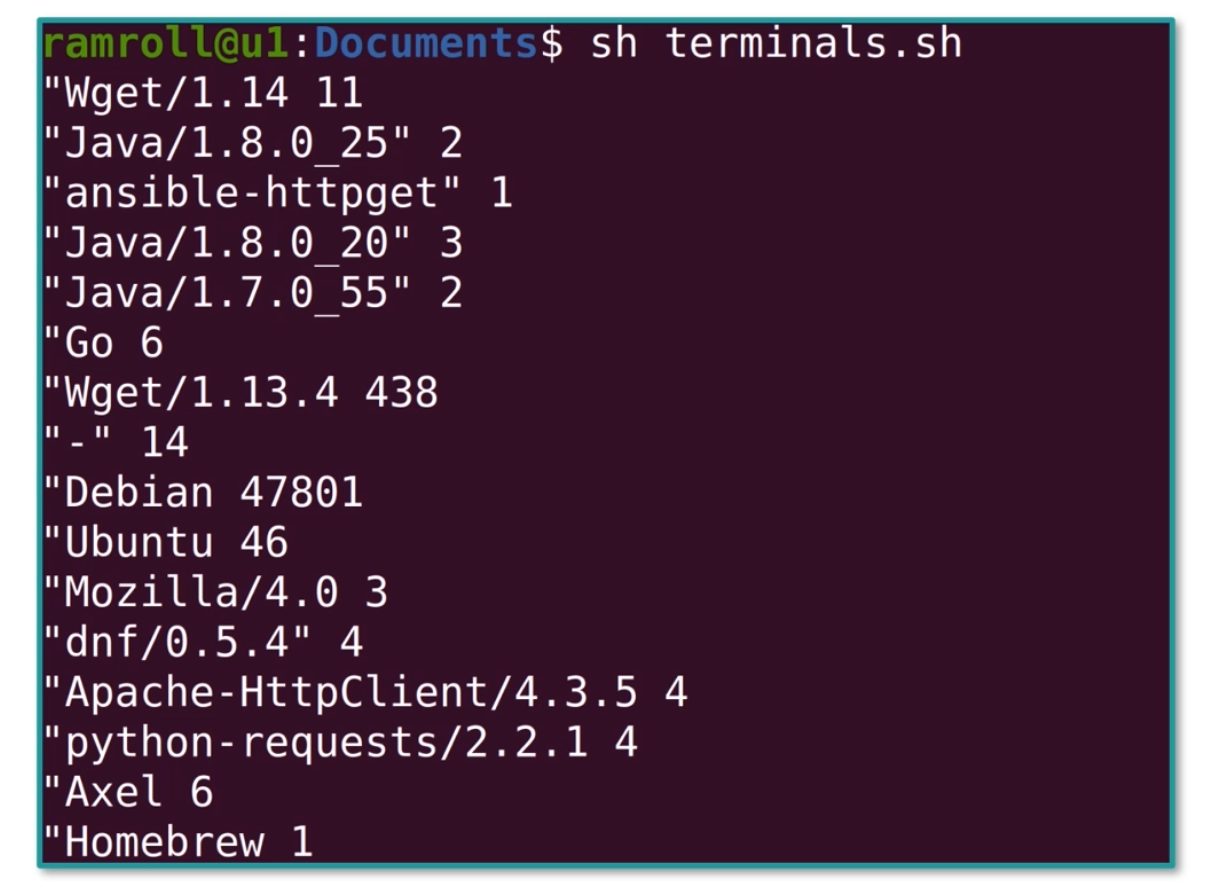
最后需要写一个脚本,进行统计:
1 | cat nginx_logs.txt |\ |
结果如下:
根据 access_log 分析出访问量 Top 前三的网页。
如果不需要 Substring 等复杂的处理,也可以使用sort和uniq的组合。如下图所示:

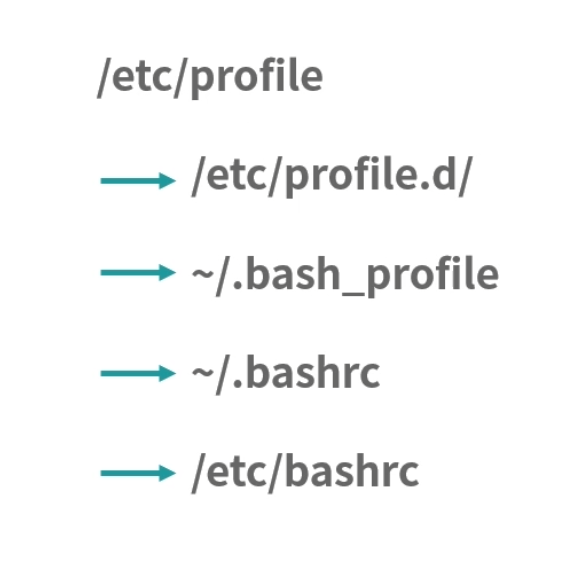
~/.bashrc ~/.bash_profile, ~/.profile 和 /etc/profile 的区别是什么?
执行一个 shell 的时候分成login shell和non-login shell。顾名思义我们使用了sudo``su切换到某个用户身份执行 shell,也就是login shell。还有 ssh 远程执行指令也是 login shell,也就是伴随登录的意思——login shell 会触发很多文件执行,路径如下:
如果以当前用户身份正常执行一个 shell,比如说./a.sh,就是一个non-login的模式。 这时候不会触发上述的完整逻辑。
另外shell还有另一种分法,就是interactive和non-interactive。interactive 是交互式的意思,当用户打开一个终端命令行工具后,会进入一个输入命令得到结果的交互界面,这个时候,就是interactive shell。
baserc文件通常只在interactive模式下才会执行,这是因为~/.bashrc文件中通常有这样的语句,如下图所示:

这个语句通过$-看到当前shell的执行环境,如下图所示:

带 i 字符的就是interactive,没有带i字符就不是。
因此, 如果你需要通过 ssh 远程 shell 执行一个文件,你就不是在 interactive 模式下,bashrc 不会触发。但是因为登录的原因,login shell 都会触发,也就是说 profile 文件依然会执行。
Linux 内核和 Windows 内核有什么区别?
Windows 和 Linux 是当今两款最主流的服务器操作系统产品,都拥有广泛的用户和信徒。Windows 通过强大的商业运作,驱动了大量优秀人才加盟到它的开发团队中;Linux 通过社区产品的魅力吸引着世界上大量的顶级程序员为它贡献源代码、解答问题。两者在服务器市场上竞争激烈,不分伯仲,但也存在互相扶持的关系。
今天从一道面试题目“ Linux 内核和 Windows 内核有什么区别?”入手,去了解这两个操作系统内核的设计,帮助你学习操作系统中最核心的一个概念——内核,并希望这些知识可以伴随你日后的每个系统设计。
什么是内核?
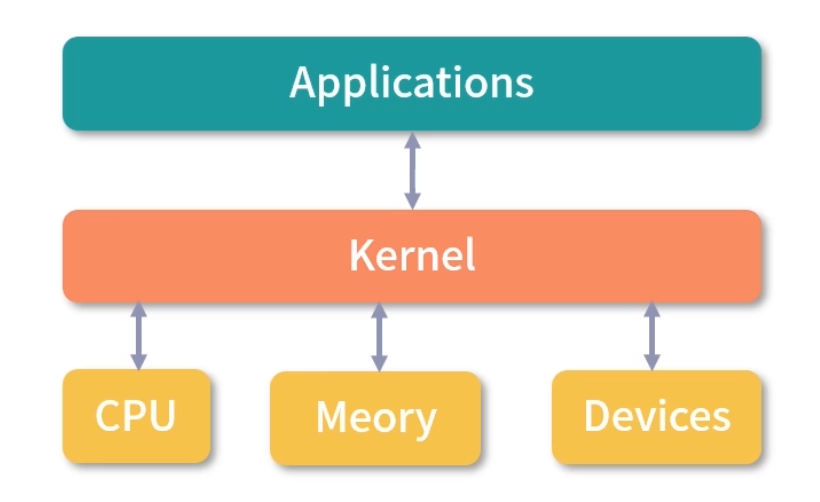
说到操作系统,就必须说内核。内核是操作系统中应用连接硬件设备的桥梁。
内核的能力
对于一个现代的操作系统来说,它的内核至少应该提供以下 4 种基本能力:
- 管理进程、线程(决定哪个进程、线程使用 CPU);
- 管理内存(决定内存用来做什么);
- 连接硬件设备(为进程、和设备间提供通信能力);
- 提供系统调用(接收进程发送来的系统调用)。

操作系统分层
从上面 4 种能力来看操作系统和内核之间的关系,通常可以把操作系统分成 3 层,最底层的硬件设备抽象、中间的内核和最上层的应用。
内核是如何工作的?
为了帮助你理解什么是内核,请你先思考一个问题:进程和内核的关系,是不是像浏览器请求服务端服务?你可以先自己思考,然后在留言区写下你此时此刻对这个问题的认知,等学完“模块三”再反过头来回顾这个知识,相信你定会产生新的理解。
接下来,我们先一起分析一下这个问题。
内核权限非常高,它可以管理进程、可以直接访问所有的内存,因此确实需要和进程之间有一定的隔离。这个隔离用类似请求/响应的模型,非常符合常理。
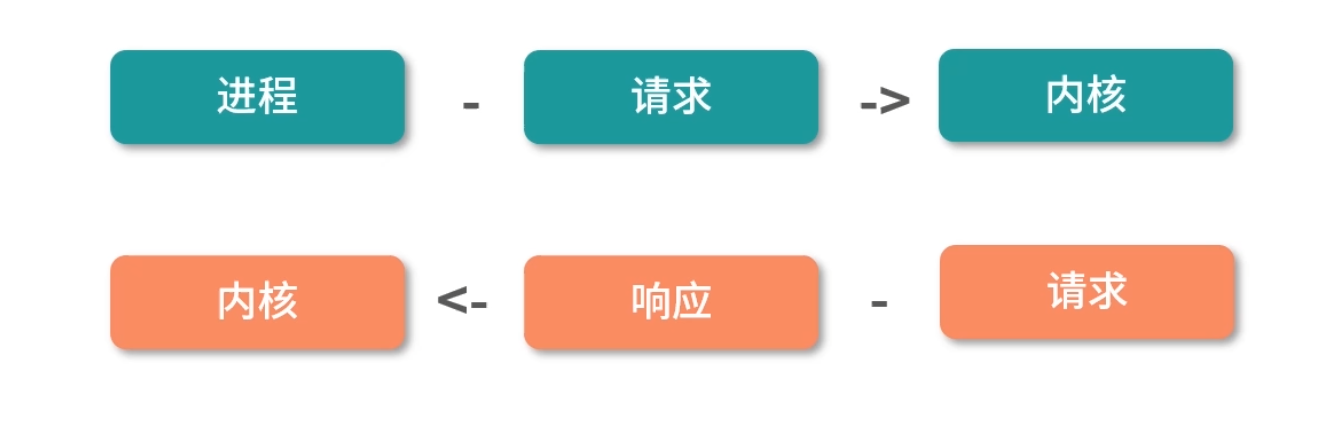
但不同的是在浏览器、服务端模型中,浏览器和服务端是用不同的机器在执行,因此不需要共享一个 CPU。但是在进程调用内核的过程中,这里是存在资源共享的。
- 比如,一个机器有 4 个 CPU,不可能让内核用一个 CPU,其他进程用剩下的 CPU。这样太浪费资源了。
- 再比如,进程向内核请求 100M 的内存,内核把 100M 的数据传回去。 这个模型不可行,因为传输太慢了。
所以,这里多数操作系统的设计都遵循一个原则:进程向内核发起一个请求,然后将 CPU 执行权限让出给内核。内核接手 CPU 执行权限,然后完成请求,再转让出 CPU 执行权限给调用进程。
Linux 的设计
Linux 操作系统第一版是1991 年林纳斯托·瓦兹(一个芬兰的小伙子,当时 22 岁)用 C 语音写的。 写完之后他在网络上发布了 Linux 内核的源代码。又经过了 3 年的努力,在 1994 年发布了完整的核心 Version 1.0。
说到 Linux 内核设计,这里有很多有意思的名词。大多数听起来复杂、专业,但是理解起来其实很简单。接下来我们一一讨论。
- Multitask and SMP(Symmetric multiprocessing)
MultiTask 指多任务,Linux 是一个多任务的操作系统。多任务就是多个任务可以同时执行,这里的“同时”并不是要求并发,而是在一段时间内可以执行多个任务。当然 Linux 支持并发。
SMP 指对称多处理。其实是说 Linux 下每个处理器的地位是相等的,内存对多个处理器来说是共享的,每个处理器都可以访问完整的内存和硬件资源。 这个特点决定了在 Linux 上不会存在一个特定的处理器处理用户程序或者内核程序,它们可以被分配到任何一个处理器上执行。
- ELF(Executable and Linkable Format)
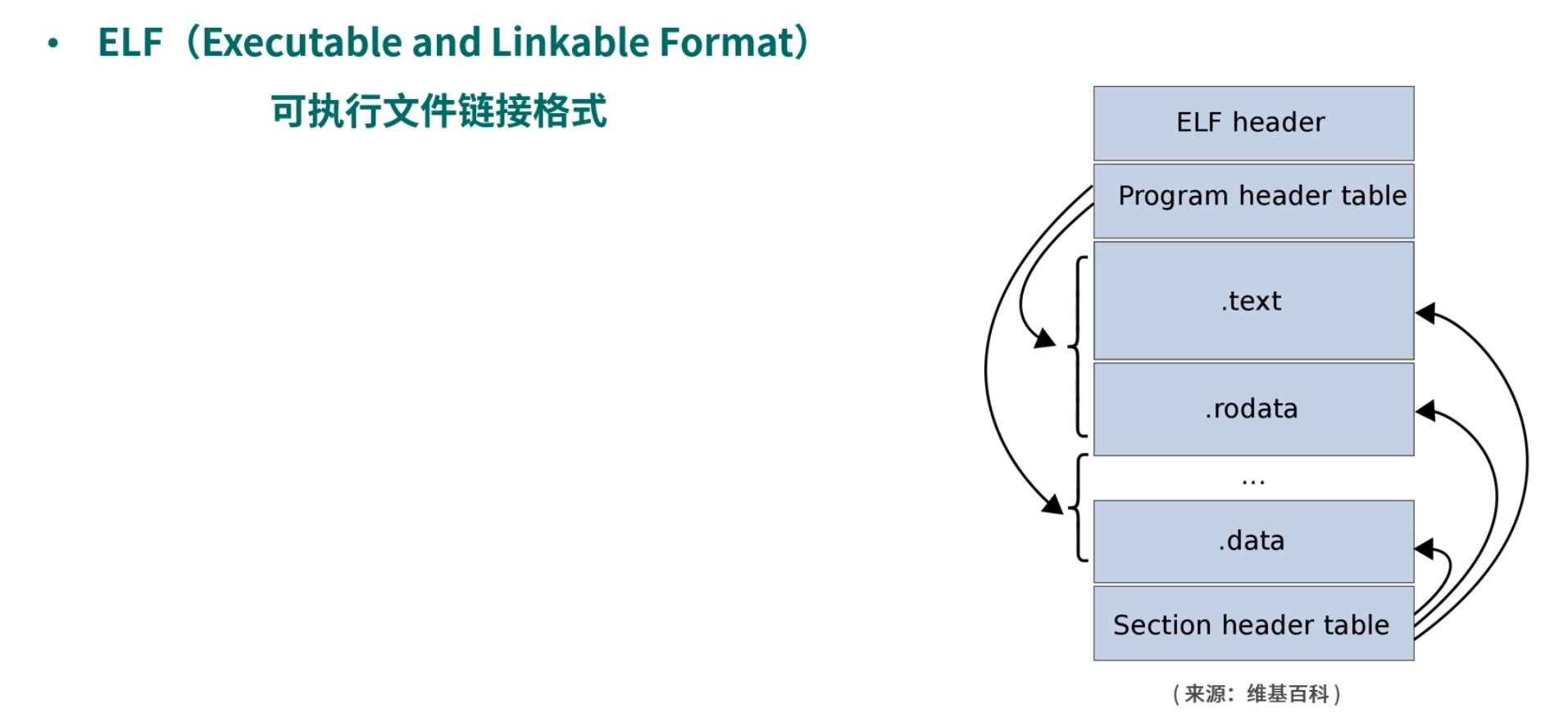
这个名词翻译过来叫作可执行文件链接格式。这是一种从 Unix 继承而来的可执行文件的存储格式。我们可以看到 ELF 中把文件分成了一个个分段(Segment),每个段都有自己的作用。如果想要深入了解这块知识,会涉及部分编译原理的知识,如果你感兴趣可以去网上多查些资料或者去留言区我们一起讨论。
- Monolithic Kernel
这个名词翻译过来就是宏内核,宏内核反义词就是 Microkernel ,微内核的意思。Linux 是宏内核架构,这说明 Linux 的内核是一个完整的可执行程序,且内核用最高权限来运行。宏内核的特点就是有很多程序会打包在内核中,比如,文件系统、驱动、内存管理等。当然这并不是说,每次安装驱动都需要重新编译内核,现在 Linux 也可以动态加载内核模块。所以哪些模块在内核层,哪些模块在用户层,这是一种系统层的拆分,并不是很强的物理隔离。
与宏内核对应,接下来说说微内核,内核只保留最基本的能力。比如进程调度、虚拟内存、中断。多数应用,甚至包括驱动程序、文件系统,是在用户空间管理的。
与宏内核对应,接下来说说微内核,内核只保留最基本的能力。比如进程调度、虚拟内存、中断。多数应用,甚至包括驱动程序、文件系统,是在用户空间管理的。
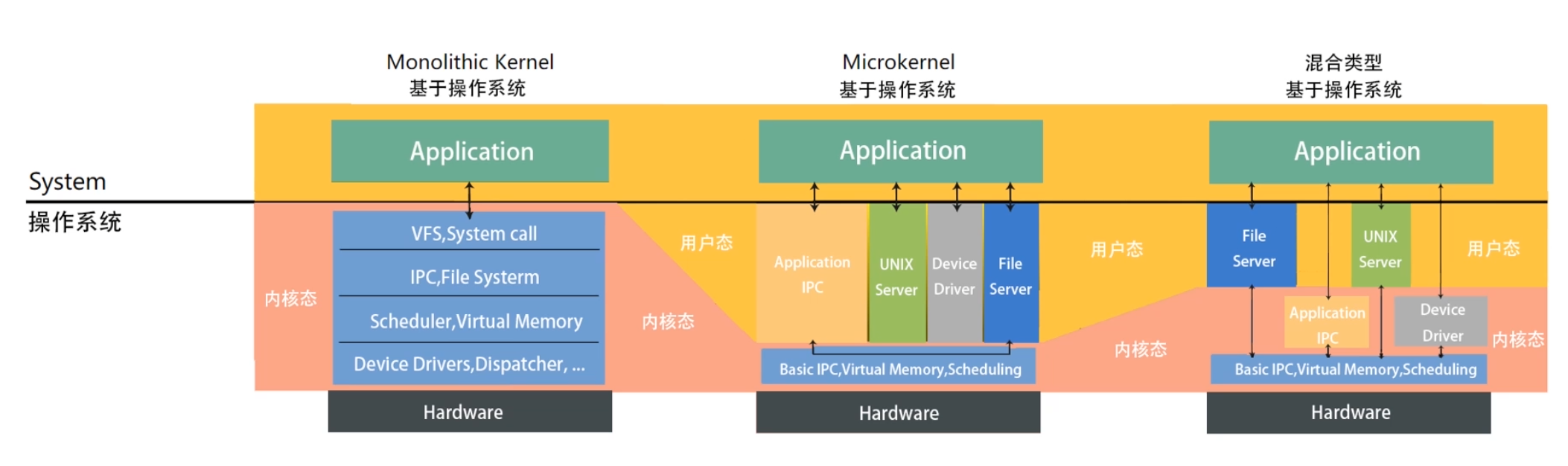
学到这里,你可能会问:在内核层和在用户层有什么区别吗?
感觉分层其实差不多。 我这里说一个很大的区别,比如说驱动程序是需要频繁调用底层能力的,如果在内核中,性能肯定会好很多。对于微内核设计,驱动在内核外,驱动和硬件设备交互就需要频繁做内核态的切换。
当然微内核也有它的好处,比如说微内核体积更小、可移植性更强。不过我认为,随着计算能力、存储技术越来越发达,体积小、安装快已经不能算是一个很大的优势了。现在更重要的是如何有效利用硬件设备的性能。
之所以这么思考,也可能因为我是带着现代的目光回望当时人们对内核的评判,事实上,当时 Linux 团队也因此争论过很长一段时间。 但是我觉得历史往往是螺旋上升的,说不定将来性能发展到了一个新的阶段,像微内核的灵活性、可以提供强大的抽象能力这样的特点,又重新受到人们的重视。
还有一种就是混合类型内核。 混合类型的特点就是架构像微内核,内核中会有一个最小版本的内核,其他功能会在这个能力上搭建。但是实现的时候,是用宏内核的方式实现的,就是内核被做成了一个完整的程序,大部分功能都包含在内核中。就是在宏内核之内有抽象出了一个微内核。
上面我们大体介绍了内核几个重要的特性,有关进程、内存、虚拟化等特性,我们会在后面几个模块中逐步讨论。
Window 设计
接下来我们说说 Windows 的设计,Windows 和 Linux 的设计有很大程度的相似性。Windows也有内核,它的内核是 C/C++ 写的。准确地说,Windows 有两个内核版本。一个是早期的Windows 9x 内核,早期的 Win95, Win98 都是这个内核。我们今天用的 Windows 7, Windows 10 是另一个内核,叫作 Windows NT。NT 指的是 New Technology。接下来我们讨论的都是 NT 版本的内核。
下面我找到一张 Windows 内核架构的图片给你一个直观感受。
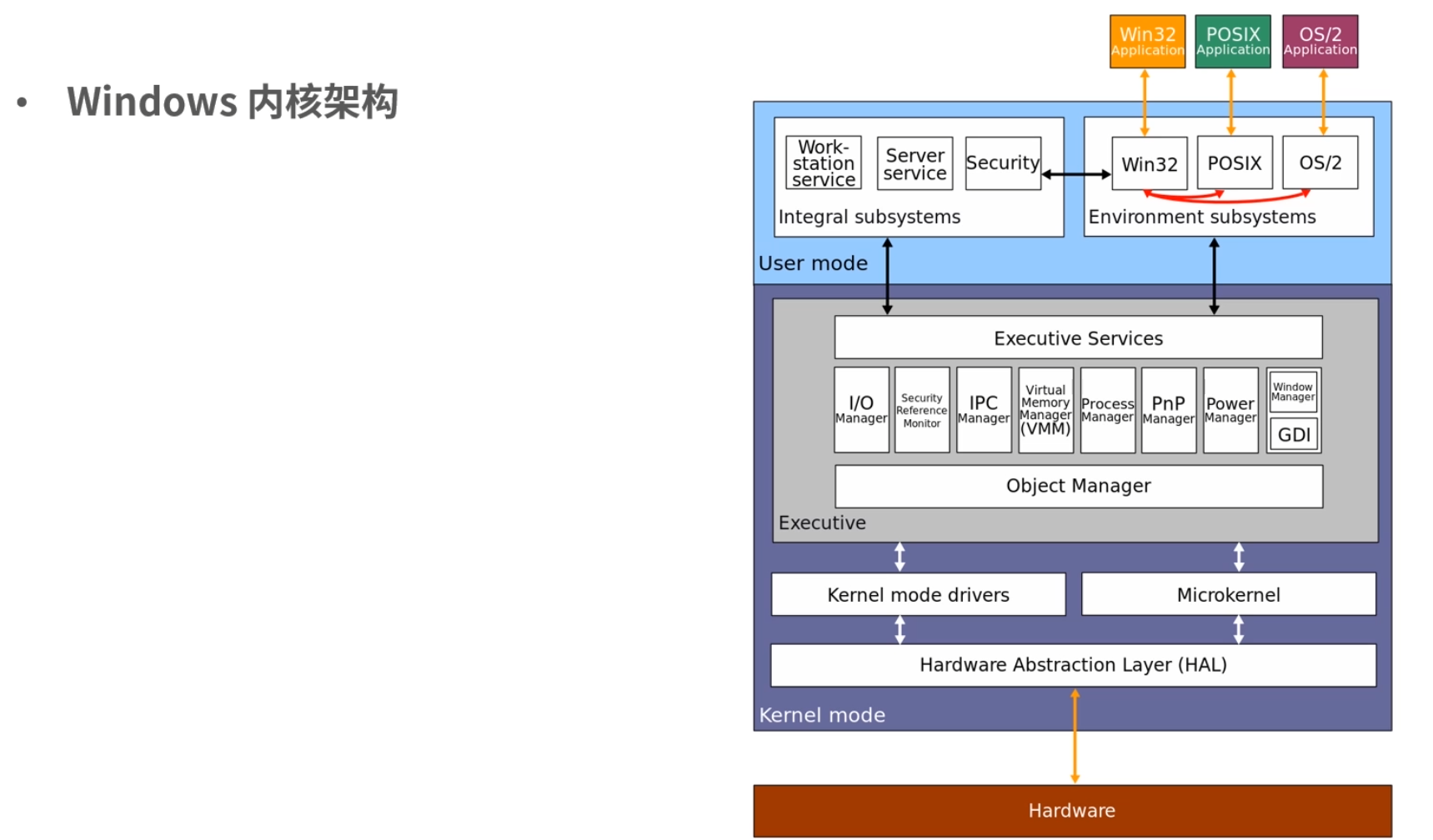
Windows 同样支持 Multitask 和 SMP(对称多处理)。Windows 的内核设计属于混合类型。你可以看到内核中有一个 Microkernel 模块。而整个内核实现又像宏内核一样,含有的能力非常多,是一个完整的整体。
Windows 下也有自己的可执行文件格式,这个格式叫作 Portable Executable(PE),也就是可移植执行文件,扩展名通常是.exe、.dll、.sys等。
PE 文件的结构和 ELF 结构有很多相通的地方,我找到了一张图片帮助你更直观地理解。 因为这部分知识涉及编译原理,我这里就不详细介绍了

Windows 还有很多独特的能力,比如 Hyper-V 虚拟化技术,有关虚拟化技术我们将在“模块八:虚拟化和其他”中详细讲解。
Linux 内核和 Windows 内核有什么区别?
Windows 有两个内核,最新的是 NT 内核,目前主流的 Windows 产品都是 NT 内核。NT 内核和 Linux 内核非常相似,没有太大的结构化差异。
从整体设计上来看,Linux 是宏内核,NT 内核属于混合型内核。和微内核不同,宏内核和混合类型内核从实现上来看是一个完整的程序。只不过混合类型内核内部也抽象出了微内核的概念,从内核内部看混合型内核的架构更像微内核。
另外 NT 内核和 Linux 内核还存在着许多其他的差异,比如:
- Linux 内核是一个开源的内核;
- 它们支持的可执行文件格式不同;
- 它们用到的虚拟化技术不同。
用户态线程和内核态线程
什么是用户态和内核态
Kernel 运行在超级权限模式(Supervisor Mode)下,所以拥有很高的权限。按照权限管理的原则,多数应用程序应该运行在最小权限下。因此,很多操作系统,将内存分成了两个区域:
- 内核空间(Kernal Space),这个空间只有内核程序可以访问;
- 用户空间(User Space),这部分内存专门给应用程序使用。
用户态和内核态
用户空间中的代码被限制了只能使用一个局部的内存空间,我们说这些程序在用户态(User Mode) 执行。内核空间中的代码可以访问所有内存,我们称这些程序在内核态(Kernal Mode) 执行。
系统调用过程
如果用户态程序需要执行系统调用,就需要切换到内核态执行。下面我们来讲讲这个过程的原理。
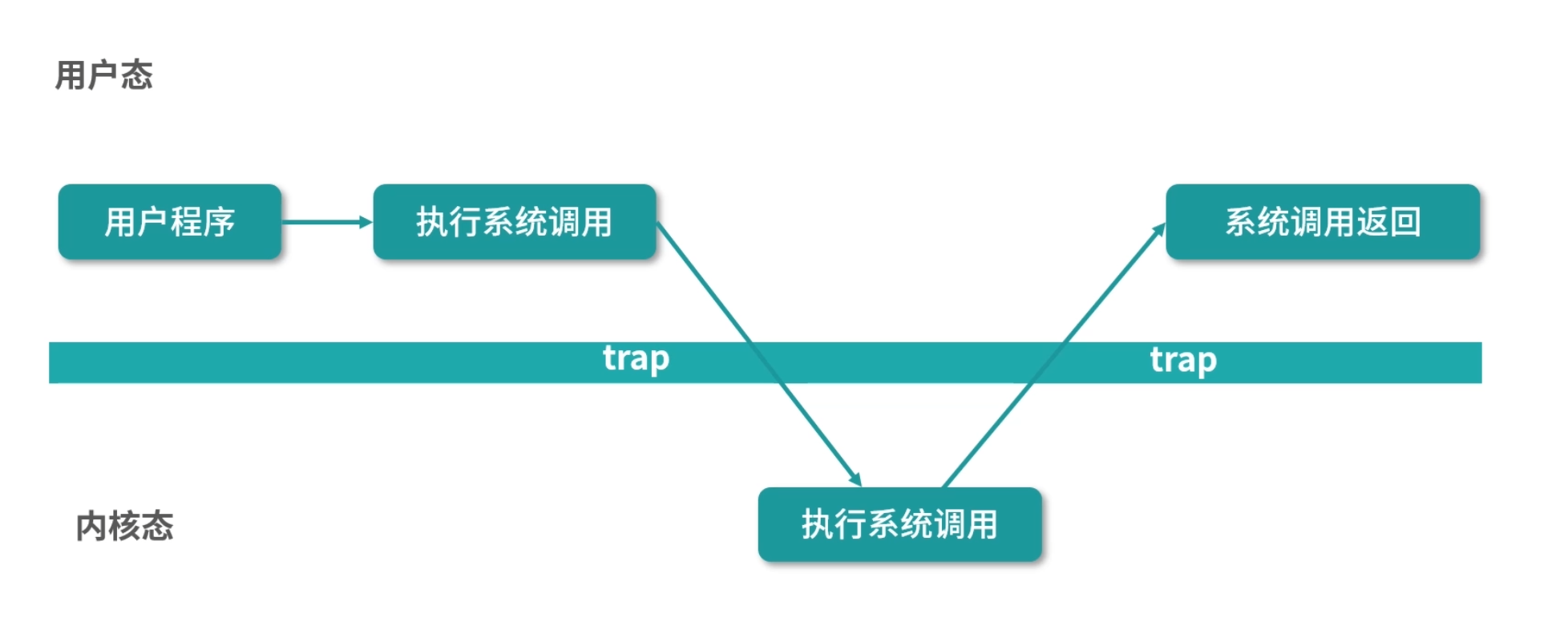
如上图所示:内核程序执行在内核态(Kernal Mode),用户程序执行在用户态(User Mode)。当发生系统调用时,用户态的程序发起系统调用。因为系统调用中牵扯特权指令,用户态程序权限不足,因此会中断执行,也就是 Trap(Trap 是一种中断)。
发生中断后,当前 CPU 执行的程序会中断,跳转到中断处理程序。内核程序开始执行,也就是开始处理系统调用。内核处理完成后,主动触发 Trap,这样会再次发生中断,切换回用户态工作。关于中断,后续会补充。
上面我们学习了用户态和内核态,接下来我们从进程和线程的角度进一步思考本课时开头抛出的问题。
进程和线程
一个应用程序启动后会在内存中创建一个执行副本,这就是进程。Linux 的内核是一个 Monolithic Kernel(宏内核),因此可以看作一个进程。也就是开机的时候,磁盘的内核镜像被导入内存作为一个执行副本,成为内核进程。
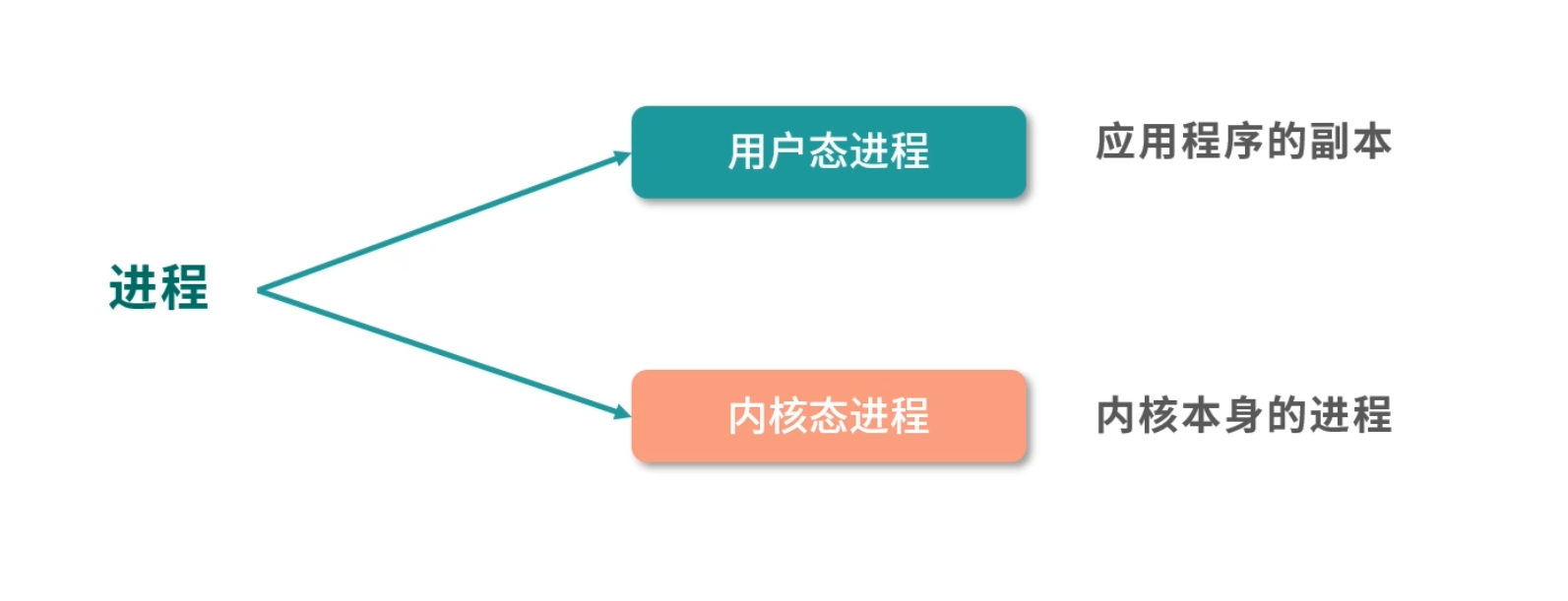
进程可以分成用户态进程和内核态进程两类。用户态进程通常是应用程序的副本,内核态进程就是内核本身的进程。如果用户态进程需要申请资源,比如内存,可以通过系统调用向内核申请。
那么用户态进程如果要执行程序,是否也要向内核申请呢?
程序在现代操作系统中并不是以进程为单位在执行,而是以一种轻量级进程(Light Weighted Process),也称作线程(Thread)的形式执行。
如果进程想要创造更多的线程,就需要思考一件事情,这个线程创建在用户态还是内核态。
你可能会问,难道不是用户态的进程创建用户态的线程,内核态的进程创建内核态的线程吗?
其实不是,进程可以通过 API 创建用户态的线程,也可以通过系统调用创建内核态的线程,接下来我们说说用户态的线程和内核态的线程。
用户态线程
用户态线程也称作用户级线程(User Level Thread)。操作系统内核并不知道它的存在,它完全是在用户空间中创建。
用户级线程有很多优势,比如。
- 管理开销小:创建、销毁不需要系统调用。
- 切换成本低:用户空间程序可以自己维护,不需要走操作系统调度。
但是这种线程也有很多的缺点。
- 与内核协作成本高:比如这种线程完全是用户空间程序在管理,当它进行 I/O 的时候,无法利用到内核的优势,需要频繁进行用户态到内核态的切换。
- 线程间协作成本高:设想两个线程需要通信,通信需要 I/O,I/O 需要系统调用,因此用户态线程需要支付额外的系统调用成本。
- 无法利用多核优势:比如操作系统调度的仍然是这个线程所属的进程,所以无论每次一个进程有多少用户态的线程,都只能并发执行一个线程,因此一个进程的多个线程无法利用多核的优势。
- 操作系统无法针对线程调度进行优化:当一个进程的一个用户态线程阻塞(Block)了,操作系统无法及时发现和处理阻塞问题,它不会更换执行其他线程,从而造成资源浪费。
内核态线程
内核态线程也称作内核级线程(Kernel Level Thread)。这种线程执行在内核态,可以通过系统调用创造一个内核级线程。
内核级线程有很多优势。
- 可以利用多核 CPU 优势:内核拥有较高权限,因此可以在多个 CPU 核心上执行内核线程。
- 操作系统级优化:内核中的线程操作 I/O 不需要进行系统调用;一个内核线程阻塞了,可以立即让另一个执行。
当然内核线程也有一些缺点。
- 创建成本高:创建的时候需要系统调用,也就是切换到内核态。
- 扩展性差:由一个内核程序管理,不可能数量太多。
- 切换成本较高:切换的时候,也同样存在需要内核操作,需要切换内核态。
用户态线程和内核态线程之间的映射关系
线程简单理解,就是要执行一段程序。程序不会自发的执行,需要操作系统进行调度。我们思考这样一个问题,如果有一个用户态的进程,它下面有多个线程。如果这个进程想要执行下面的某一个线程,应该如何做呢?
这时,比较常见的一种方式,就是将需要执行的程序,让一个内核线程去执行。毕竟,内核线程是真正的线程。因为它会分配到 CPU 的执行资源。
如果一个进程所有的线程都要自己调度,相当于在进程的主线程中实现分时算法调度每一个线程,也就是所有线程都用操作系统分配给主线程的时间片段执行。这种做法,相当于操作系统调度进程的主线程;进程的主线程进行二级调度,调度自己内部的线程。
这样操作劣势非常明显,比如无法利用多核优势,每个线程调度分配到的时间较少,而且这种线程在阻塞场景下会直接交出整个进程的执行权限。
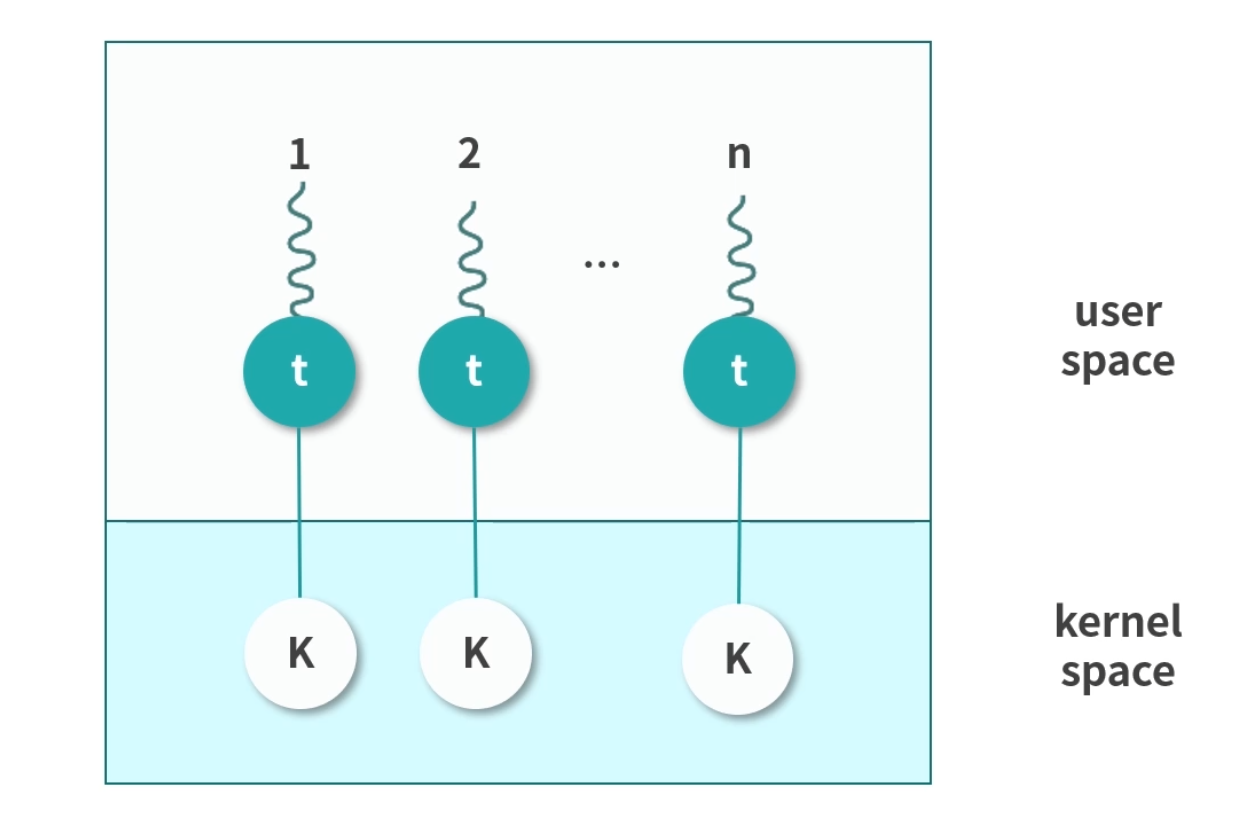
由此可见,用户态线程创建成本低,问题明显,不可以利用多核。内核态线程,创建成本高,可以利用多核,切换速度慢。因此通常我们会在内核中预先创建一些线程,并反复利用这些线程。这样,用户态线程和内核态线程之间就构成了下面 4 种可能的关系:
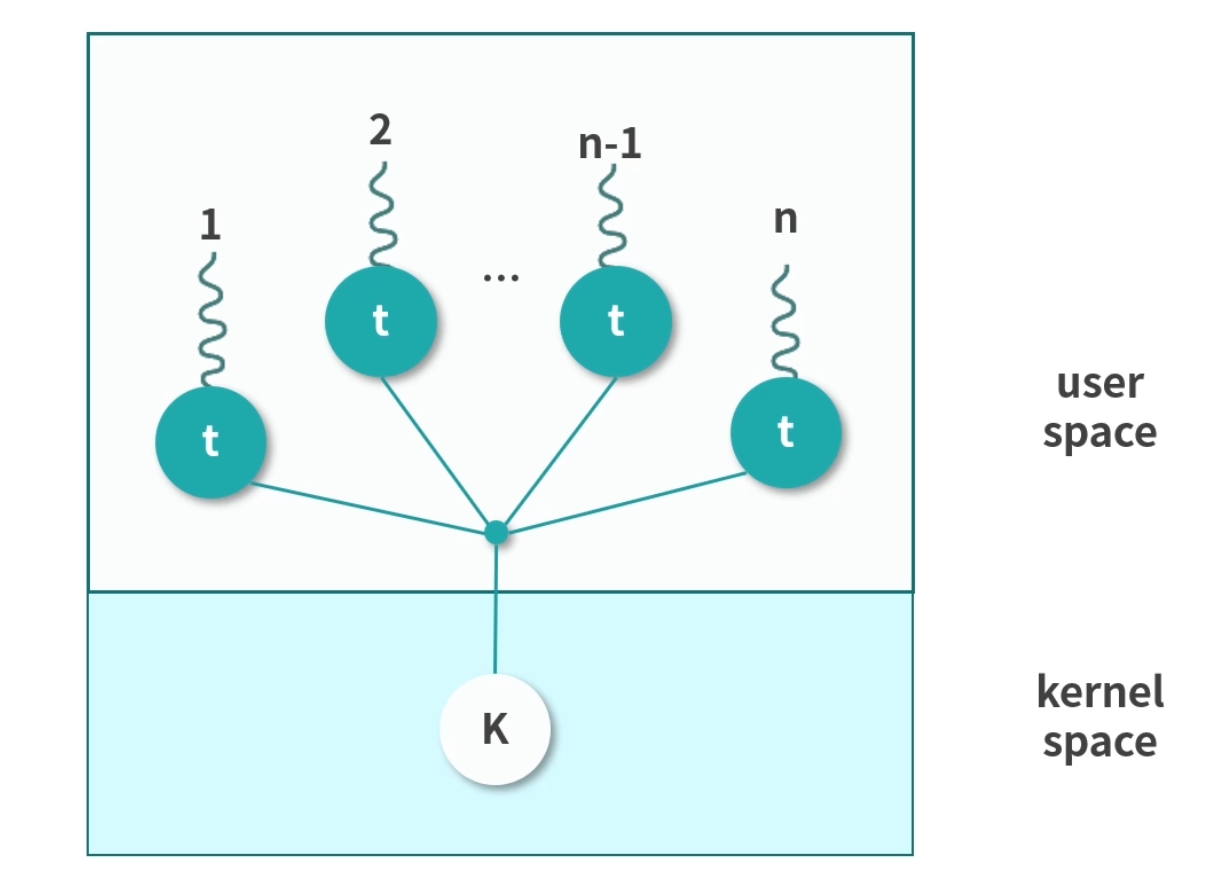
多对一(Many to One)
用户态进程中的多线程复用一个内核态线程。这样,极大地减少了创建内核态线程的成本,但是线程不可以并发。因此,这种模型现在基本上用的很少。我再多说一句,这里你可能会有疑问,比如:用户态线程怎么用内核态线程执行程序?
程序是存储在内存中的指令,用户态线程是可以准备好程序让内核态线程执行的。后面的几种方式也是利用这样的方法。
一对一(One to One)
该模型为每个用户态的线程分配一个单独的内核态线程,在这种情况下,每个用户态都需要通过系统调用创建一个绑定的内核线程,并附加在上面执行。 这种模型允许所有线程并发执行,能够充分利用多核优势,Windows NT 内核采取的就是这种模型。但是因为线程较多,对内核调度的压力会明显增加。
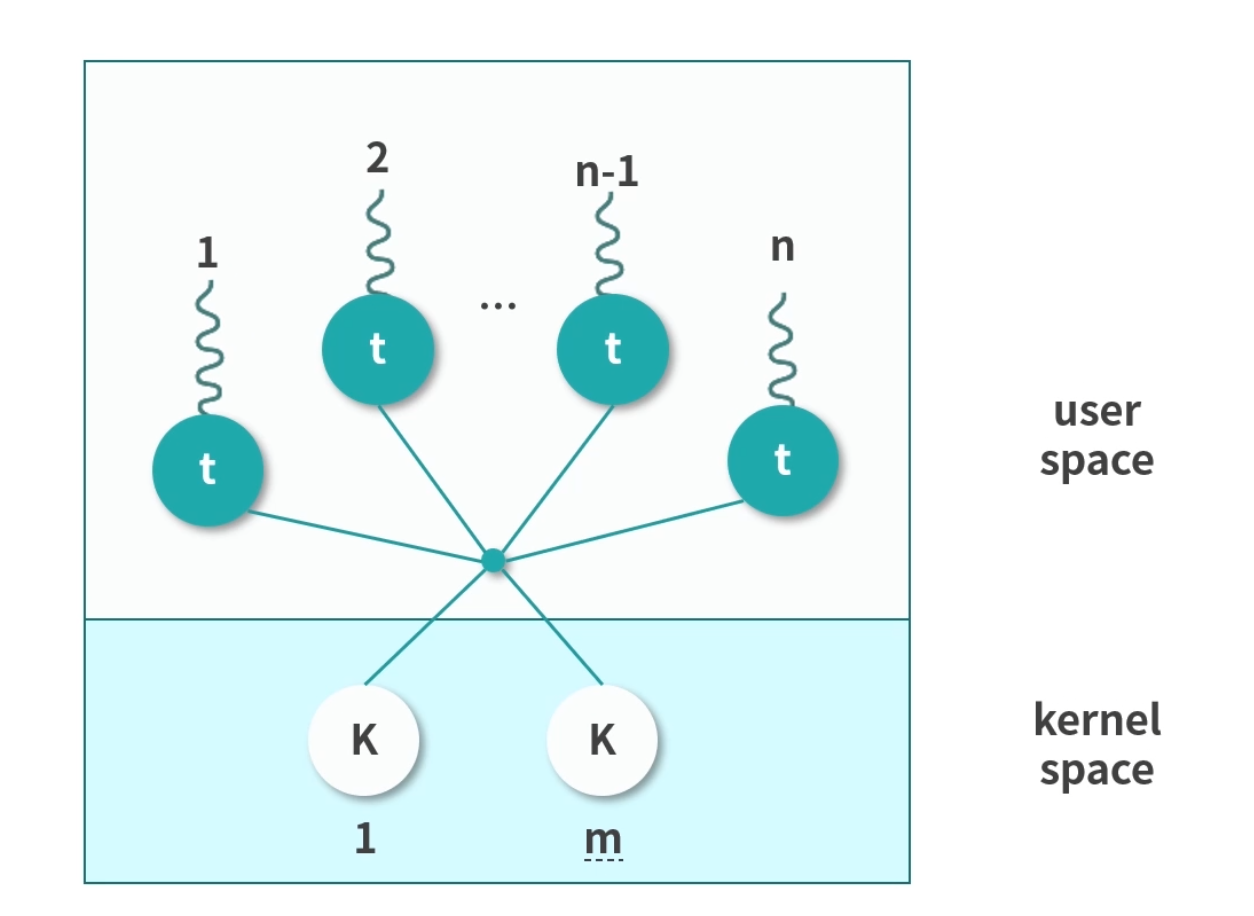
多对多(Many To Many)
这种模式下会为 n 个用户态线程分配 m 个内核态线程。m 通常可以小于 n。一种可行的策略是将 m 设置为核数。这种多对多的关系,减少了内核线程,同时也保证了多核心并发。Linux 目前采用的就是该模型。
两层设计(Two Level)
这种模型混合了多对多和一对一的特点。多数用户态线程和内核线程是 n 对 m 的关系,少量用户线程可以指定成 1 对 1 的关系。
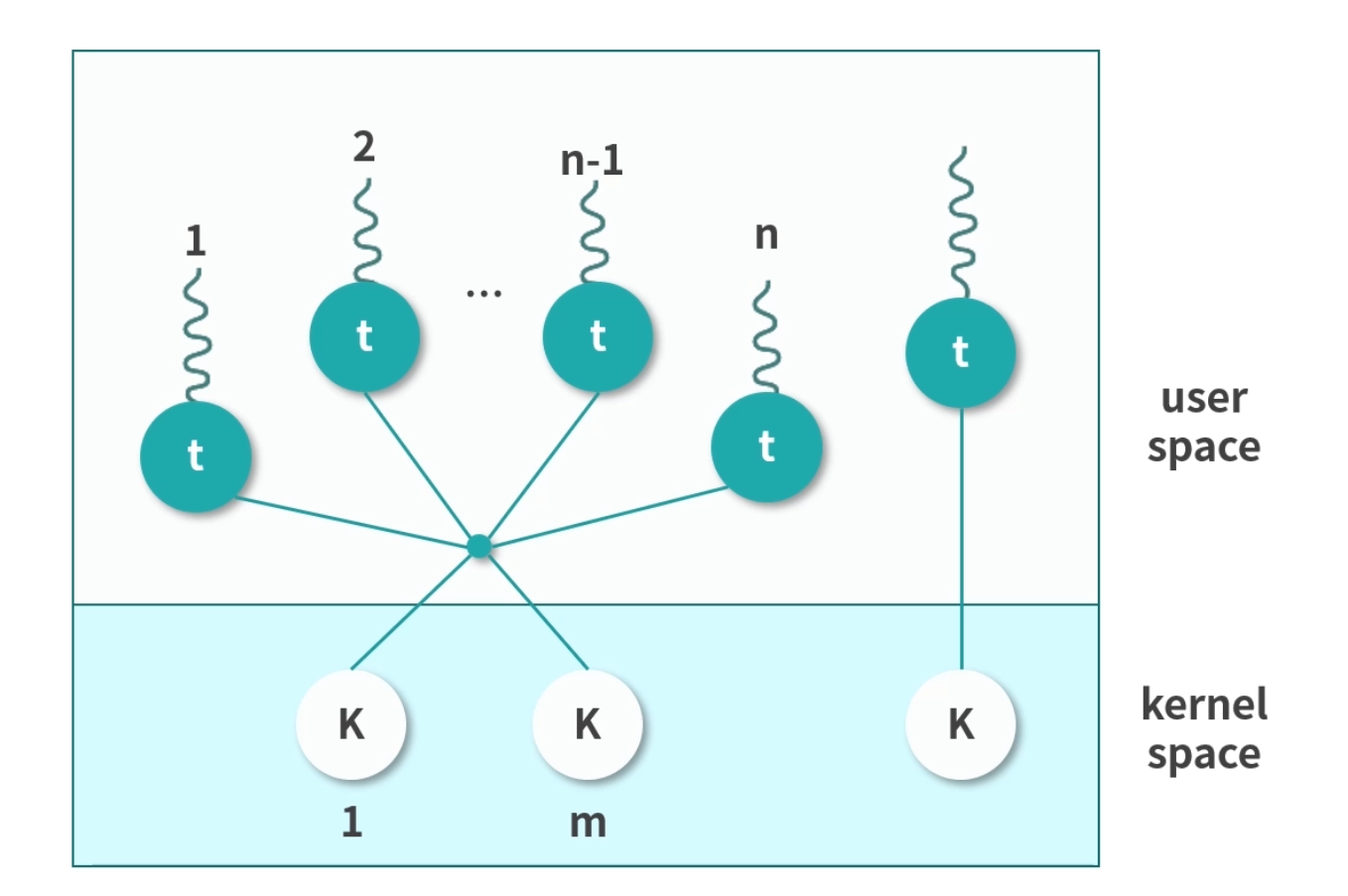
上图所展现的是一个非常经典的设计。
我们这节课讲解的问题、考虑到的情况以及解决方法,将为你今后解决实际工作场景中的问题打下坚实的基础。比如处理并发问题、I/O 性能瓶颈、思考数据库连接池的配置等,要想完美地解决问题,就必须掌握这些模型,了解问题的本质上才能更好地思考问题衍生出来的问题。
用户态线程和内核态线程的区别?
用户态线程工作在用户空间,内核态线程工作在内核空间。用户态线程调度完全由进程负责,通常就是由进程的主线程负责。相当于进程主线程的延展,使用的是操作系统分配给进程主线程的时间片段。内核线程由内核维护,由操作系统调度。
用户态线程无法跨核心,一个进程的多个用户态线程不能并发,阻塞一个用户态线程会导致进程的主线程阻塞,直接交出执行权限。这些都是用户态线程的劣势。内核线程可以独立执行,操作系统会分配时间片段。因此内核态线程更完整,也称作轻量级进程。内核态线程创建成本高,切换成本高,创建太多还会给调度算法增加压力,因此不会太多。
实际操作中,往往结合两者优势,将用户态线程附着在内核态线程中执行。
中断和中断向量
如何设计响应键盘的整个链路?
当你拿到一个问题时,需要冷静下来思考和探索解决方案。你可以查资料、看视频或者咨询专家,但是在这之前,你先要进行一定的思考和梳理,有的问题可以直接找到答案,有的问题却需要继续深挖寻找其背后的理论支撑。
问题 1:我们的目标是什么?
我们的目标是在 Java/JS 中实现按键响应程序。这种实现有点像 Switch-Case 语句——根据不同的按键执行不同的程序,比如按下回车键可以换行,按下左右键可以移动光标。
问题 2:按键怎么抽象?
键盘上一般不超过 100 个键。因此我们可以考虑用一个 Byte 的数据来描述用户按下了什么键。按键有两个操作,一个是按下、一个是释放,这是两个不同的操作。对于一个 8 位的字节,可以考虑用最高位的 1 来描述按下还是释放的状态,然后后面的 7 位(0~127)描述具体按了哪个键。这样我们只要确定了用户按键/释放的顺序,对我们的系统来说,就不会有歧义。
问题 3:如何处理按键?使用操作系统处理还是让每个程序自己实现?
处理按键是一个通用程序,可以考虑由操作系统先进行一部分处理,比如:
- 用户按下了回车键,先由操作系统进行统一的封装,再把按键的编码转换为字符串
Enter方便各种程序使用。 - 处理组合键这种操作,由操作系统先一步进行计算比较好。因为底层只知道按键、释放,组合键必须结合时间因素判断。
你可以把下面这种情况看作是一个Ctrl + C组合键,这种行为可以由操作系统进行统一处理,如下所示:
1 | 按下 Ctrl |
问题 4:程序用什么模型响应按键?
当一个 Java 或者 JS 写的应用程序想要响应按键时,应该考虑消息模型。因为如果程序不停地扫描按键,会给整个系统带来很大的负担。比如程序写一个while循环去扫描有没有按键,开销会很大。 如果程序在操作系统端注册一个响应按键的函数,每次只有真的触发按键时才执行这个函数,这样就能减少开销了。
问题 5:处理用户按键,需不需要打断正在执行的程序?
从用户体验上讲,按键应该是一个高优先级的操作,比如用户按 Ctrl+C 或者 Esc 的时候,可能是因为用户想要打断当前执行的程序。即便是用户只想要输入,也应该尽可能地集中资源给到用户,因为我们不希望用户感觉到延迟。
如果需要考虑到程序随时会被中断,去响应其他更高优先级的情况,那么从程序执行的底层就应该支持这个行为,而且最好从硬件层面去支持,这样速度最快。 这就引出了本课时的主角——中断。具体如何处理,见下面我们关于中断部分的分析。
问题 6:操作系统如何知道用户按了哪个键?
这里有一个和问题 5 类似的问题。操作系统是不断主动触发读取键盘按键,还是每次键盘按键到来的时候都触发一段属于操作系统的程序呢?
显然,后者更节省效率。
那么谁能随时随地中断操作系统的程序? 谁有这个权限?是管理员账号吗? 当然不是,拥有这么高权限的应该是机器本身。
我们思考下这个模型,用户每次按键,触发一个 CPU 的能力,这个能力会中断正在执行的程序,去处理按键。那 CPU 内部是不是应该有处理按键的程序呢?这肯定不行,因为我们希望 CPU 就是用来做计算的,如果 CPU 内部有自带的程序,会把问题复杂化。这在软件设计中,叫作耦合。CPU 的工作就是专注高效的执行指令。
因此,每次按键,必须有一个机制通知 CPU。我们可以考虑用总线去通知 CPU,也就是主板在通知 CPU。
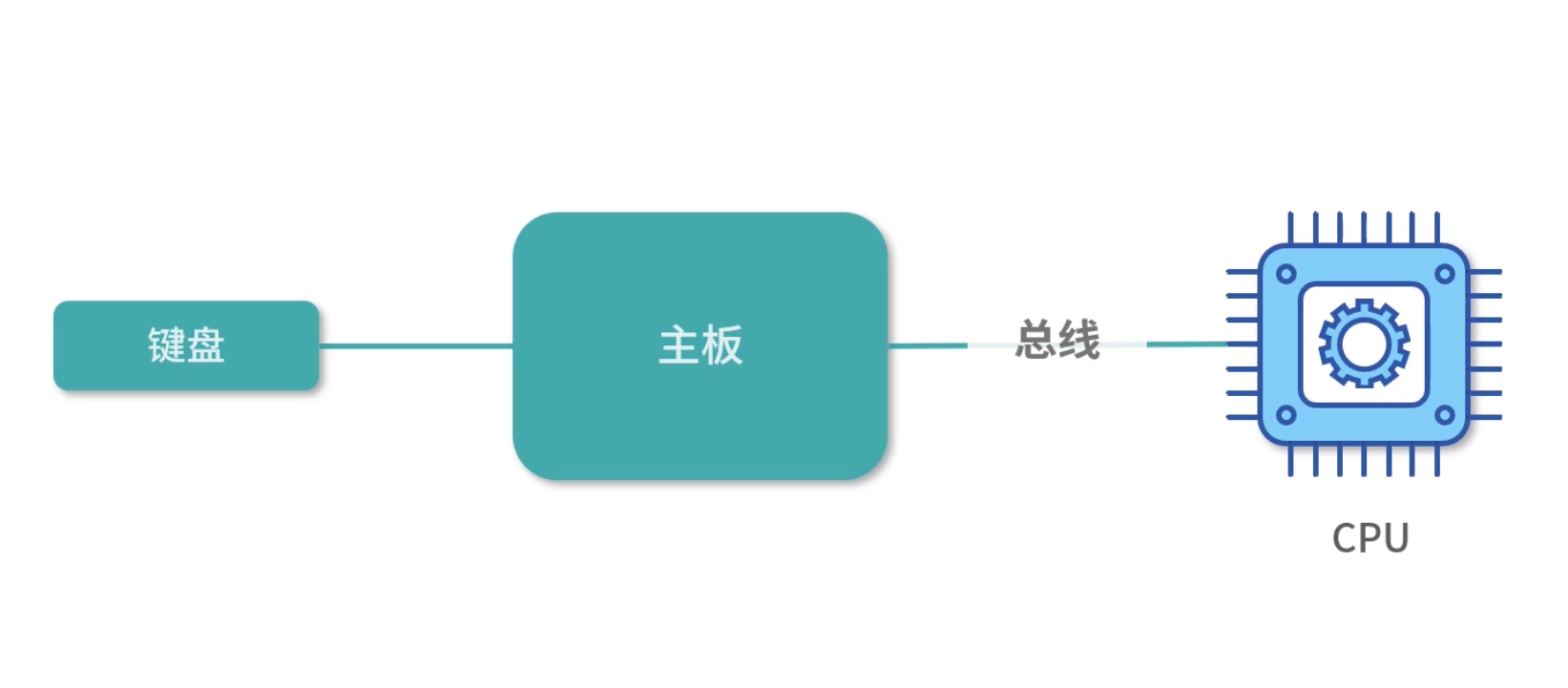
那么 CPU 接收到通知后,如何通知操作系统呢?CPU 只能中断正在执行的程序,然后切换到另一个需要执行的程序。说白了就是改变 PC 指针,CPU 只有这一种办法切换执行的程序。这里请你思考,是不是只有这一种方法:CPU 中断当前执行的程序,然后去执行另一个程序,才能改变 PC 指针?
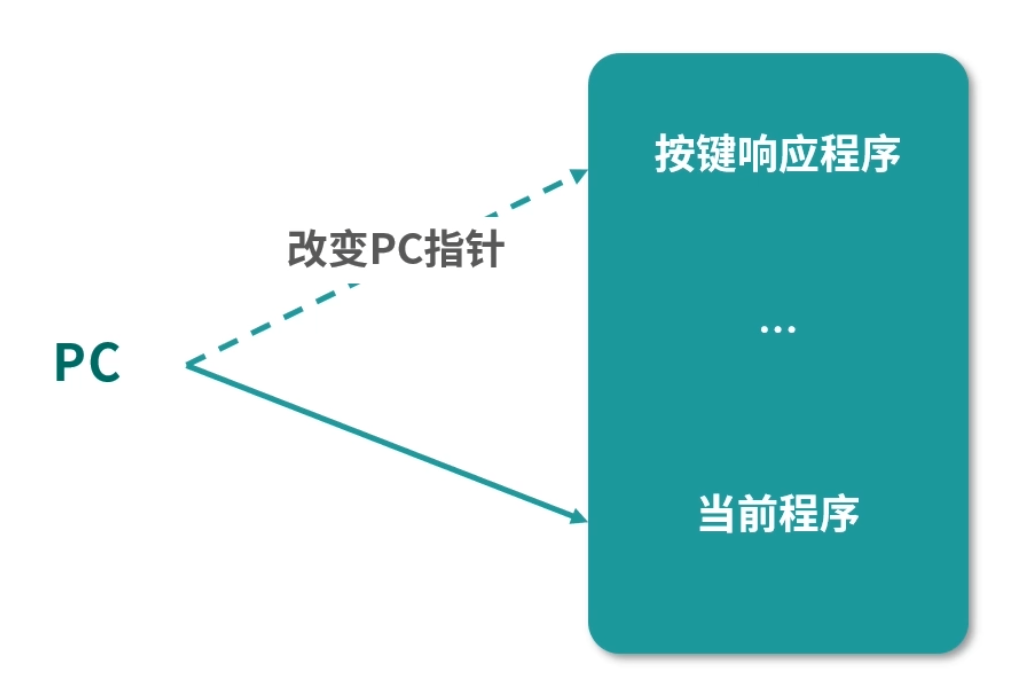
接下来我们进一步思考,CPU 怎么知道 PC 指针应该设置为多少呢?是不是 CPU 知道操作系统响应按键的程序位置呢?
答案当然是不知道。
因此,我们只能控制 CPU 跳转到一个固定的位置。比如说 CPU 一收到主板的信息(某个按键被触发),CPU 就马上中断当前执行的程序,将 PC 指针设置为 0。也就是 PC 指针下一步会从内存地址 0 中读取下一条指令。当然这只是我们的一个思路,具体还需要进一步考虑。而操作系统要做的就是在这之前往内存地址 0 中写一条指令,比如说让 PC 指针跳转到自己处理按键程序的位置。
讲到这里,我们总结一下,CPU 要做的就是一看到中断,就改变 PC 指针(相当于中断正在执行的程序),而 PC 改变成多少,可以根据不同的类型来判断,比如按键就到 0。操作系统就要向这些具体的位置写入指令,当中断发生时,接管程序的控制权,也就是让 PC 指针指向操作系统处理按键的程序。
上面这个模型和实际情况还有出入,但是我们已经开始逐渐完善了。
问题 7:主板如何知道键盘被按下?
经过一层一层地深挖“如何设计响应键盘的整个链路?”这个问题,目前操作系统已经能接管按键,接下来,我们还需要思考主板如何知道有按键,并且通知 CPU。
你可以把键盘按键看作按下了某个开关,我们需要一个芯片将按键信息转换成具体按键的值。比如用户按下 A 键,A 键在第几行、第几列,可以看作一个电学信号。接着我们需要芯片把这个电学信号转化为具体的一个数字(一个 Byte)。转化完成后,主板就可以接收到这个数字(按键码),然后将数字写入自己的一个寄存器中,并通知 CPU。
为了方便 CPU 计算,CPU 接收到主板通知后,按键码会被存到一个寄存器里,这样方便处理按键的程序执行。
通过对以上 7 个问题的思考和分析,我们已经有了一个粗浅的设计,接下来就要开始整理思路了。
思路的整理:中断的设计
整体设计分成了 3 层,第一层是硬件设计、第二层是操作系统设计、第三层是程序语言的设计。

按键码的收集,是键盘芯片和主板的能力。主板知道有新的按键后,通知 CPU,CPU 要中断当前执行的程序,将 PC 指针跳转到一个固定的位置,我们称为一次中断(interrupt)。
考虑到系统中会出现各种各样的事件,我们需要根据中断类型来判断PC 指针跳转的位置,中断类型不同,PC 指针跳转的位置也可能会不同。比如按键程序、打印机就绪程序、系统异常等都需要中断,包括在“14 课时”我们学习的系统调用,也需要中断正在执行的程序,切换到内核态执行内核程序。
考虑到系统中会出现各种各样的事件,我们需要根据中断类型来判断PC 指针跳转的位置,中断类型不同,PC 指针跳转的位置也可能会不同。比如按键程序、打印机就绪程序、系统异常等都需要中断.
因此我们需要把不同的中断类型进行分类,这个类型叫作中断识别码。比如按键,我们可以考虑用编号 16,数字 16 就是按键中断类型的识别码。不同类型的中断发生时,CPU 需要知道 PC 指针该跳转到哪个地址,这个地址,称为中断向量(Interupt Vector)。
你可以考虑这样的实现:当编号 16 的中断发生时,32 位机器的 PC 指针直接跳转到内存地址 16*4 的内存位置。如果设计最多有 255 个中断,编号就是从 0~255,刚好需要 1K 的内存地址存储中断向量——这个 1K 的空间,称为中断向量表。
因此 CPU 接收到中断后,CPU 根据中断类型操作 PC 指针,找到中断向量。操作系统必须在这之前,修改中断向量,插入一条指令。比如操作系统在这里写一条Jump指令,将 PC 指针再次跳转到自己处理对应中断类型的程序。
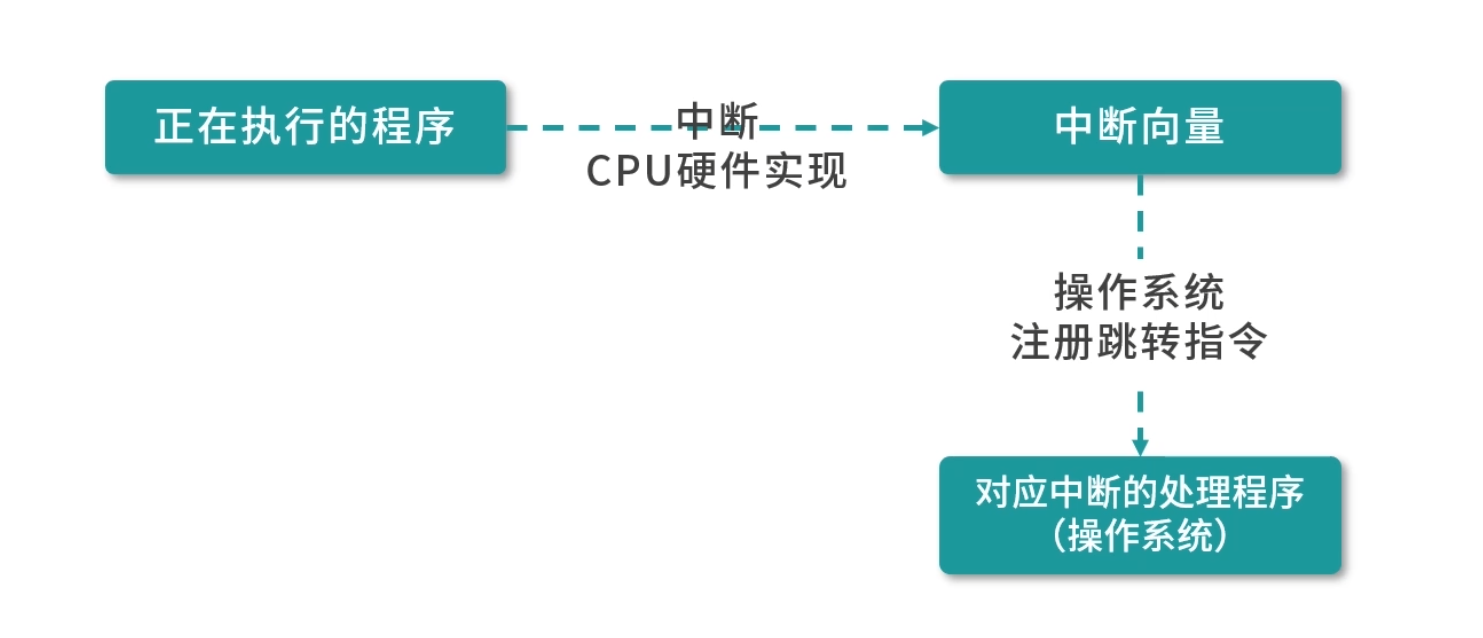
操作系统接管之后,以按键程序为例,操作系统会进行一些处理,包括下面的几件事情:
- 将按键放入一个队列,保存下来。这是因为,操作系统不能保证及时处理所有的按键,比如当按键过快时,需要先存储下来,再分时慢慢处理。
- 计算组合键。可以利用按下、释放之间的时间关系。
- 经过一定计算将按键抽象成消息(事件结构或对象)。
- 提供 API 给应用程序,让应用程序可以监听操作系统处理后的消息。
- 分发按键消息给监听按键的程序。
所以程序在语言层面,比如像 Java/Node.js 这种拥有虚拟机的语言,只需要对接操作系统 API 就可以了。
中断的类型
接下来我们一起讨论下中断的分类方法:
- 按照中断的触发方分成同步中断和异步中断;
- 根据中断是否强制触发分成可屏蔽中断和不可屏蔽中断。
中断可以由 CPU 指令直接触发,这种主动触发的中断,叫作同步中断。同步中断有几种情况。
- 之前我们学习的系统调用,需要从用户态切换内核态,这种情况需要程序触发一个中断,叫作陷阱(Trap),中断触发后需要继续执行系统调用。
- 还有一种同步中断情况是错误(Fault),通常是因为检测到某种错误,需要触发一个中断,中断响应结束后,会重新执行触发错误的地方,比如后面我们要学习的缺页中断。
- 最后还有一种情况是程序的异常,这种情况和 Trap 类似,用于实现程序抛出的异常。
另一部分中断不是由 CPU 直接触发,是因为需要响应外部的通知,比如响应键盘、鼠标等设备而触发的中断。这种中断我们称为异步中断。
CPU 通常都支持设置一个中断屏蔽位(一个寄存器),设置为 1 之后 CPU 暂时就不再响应中断。对于键盘鼠标输入,比如陷阱、错误、异常等情况,会被临时屏蔽。但是对于一些特别重要的中断,比如 CPU 故障导致的掉电中断,还是会正常触发。可以被屏蔽的中断我们称为可屏蔽中断,多数中断都是可屏蔽中断。
所以这里我们讲了两种分类方法,一种是同步中断和异步中断。另一种是可屏蔽中断和不可屏蔽中断。
Java/Js 等语言为什么可以捕获到键盘输入?
为了捕获到键盘输入,硬件层面需要把按键抽象成中断,中断 CPU 执行。CPU 根据中断类型找到对应的中断向量。操作系统预置了中断向量,因此发生中断后操作系统接管了程序。操作系统实现了基本解析按键的算法,将按键抽象成键盘事件,并且提供了队列存储多个按键,还提供了监听按键的 API。因此应用程序,比如 Java/Node.js 虚拟机,就可以通过调用操作系统的 API 使用键盘事件。
Unix 和 Mac OS 内核属于哪种类型?
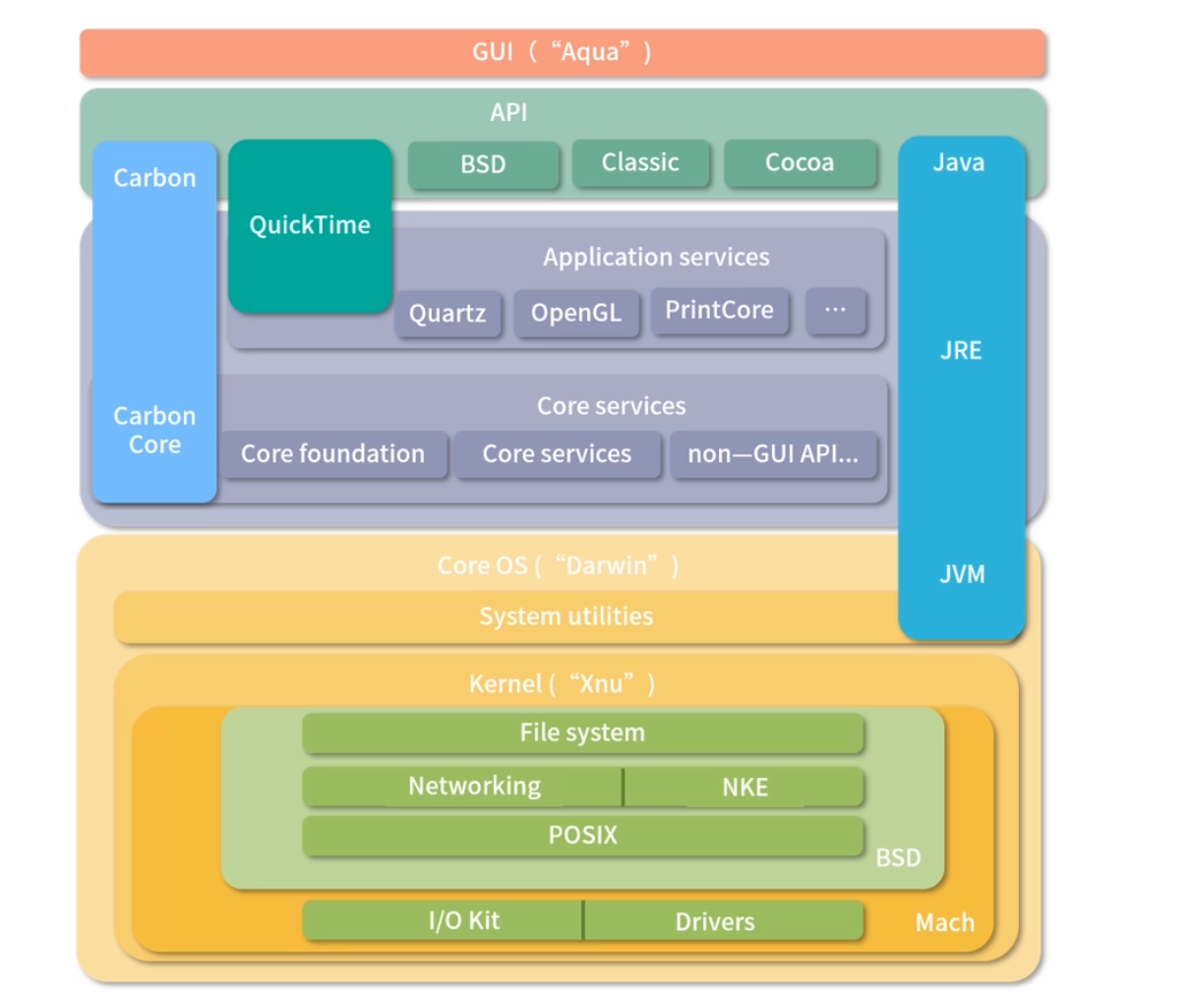
Unix 和 Linux 非常类似,也是宏内核。Mac OS 用的是 XNU 内核, XNU 是一种混合型内核。为了帮助你理解,我找了一张 Mac OS 的内核架构图。 如下图所示,可以看到内部是一个叫作 XNU 的宏内核。XNU 是 X is not Unix 的意思, 是一个受 Unix 影响很大的内核。
JVM 的线程是用户态线程还是内核态线程?
JVM 自己本身有一个线程模型。在 JDK 1.1 的时候,JVM 自己管理用户级线程。这样做缺点非常明显,操作系统只调度内核级线程,用户级线程相当于基于操作系统分配到进程主线程的时间片,再次拆分,因此无法利用多核特性。
为了解决这个问题,后来 Java 改用线程映射模型,因此,需要操作系统支持。在 Windows 上是 1 对 1 的模型,在 Linux 上是 n 对 m 的模型。顺便说一句,Linux 的PThreadAPI 创建的是用户级线程,如果 Linux 要创建内核级线程有KThreadAPI。映射关系是操作系统自动完成的,用户不需要管。
操作系统可以处理键盘按键,这很好理解,但是在开机的时候系统还没有载入内存,为什么可以使用键盘呢?这个怎么解释?
主板的一块 ROM 上往往还有一个简化版的操作系统,叫 BIOS(Basic Input/Ouput System)。在 OS 还没有接管计算机前,先由 BIOS 管理机器,并协助加载 OS 到内存。早期的 OS 还会利用 BIOS 的能力,现代的 OS 接管后,就会替换掉 BIOS 的中断向量。
林纳斯 21 岁写出 Linux,那么开发一个操作系统的难度到底大不大?
毫无疑问能在 21 岁就写出 Linux 的人定是天赋异禀,林纳斯是参照一个 Minix 系统写的 Linux 内核。如果你对此感兴趣,可以参考这个 1991 年的源代码。
写一个操作系统本身并不是非常困难。需要了解一些基础的数据结构与算法,硬件设备工作原理。关键是要有参照,比如核心部分可以参考前人的内核。
但是随着硬件、软件技术发展了这么多年,如果想再写一个大家能够接受的内核,是一件非常困难的事情。内核的能力在上升,硬件的种类在上升,所以 Android 和很多后来的操作系统都是拿 Linux 改装。
进程和线程
进程(Process),顾名思义就是正在执行的应用程序,是软件的执行副本。而线程是轻量级的进程。
进程是分配资源的基础单位。而线程很长一段时间被称作轻量级进程(Light Weighted Process),是程序执行的基本单位。
在计算机刚刚诞生的年代,程序员拿着一个写好程序的闪存卡,插到机器里,然后电能推动芯片计算,芯片每次从闪存卡中读出一条指令,执行后接着读取下一条指令。闪存中的所有指令执行结束后,计算机就关机。
一开始,这种单任务的模型,在那个时代叫作作业(Job),当时计算机的设计就是希望可以多处理作业。图形界面出现后,人们开始利用计算机进行办公、购物、聊天、打游戏等,因此一台机器正在执行的程序会被随时切来切去。于是人们想到,设计进程和线程来解决这个问题。
每一种应用,比如游戏,执行后是一个进程。但是游戏内部需要图形渲染、需要网络、需要响应用户操作,这些行为不可以互相阻塞,必须同时进行,这样就设计成线程。
资源分配问题
设计进程和线程,操作系统需要思考分配资源。最重要的 3 种资源是:计算资源(CPU)、内存资源和文件资源。早期的 OS 设计中没有线程,3 种资源都分配给进程,多个进程通过分时技术交替执行,进程之间通过管道技术等进行通信。
但是这样做的话,设计者们发现用户(程序员),一个应用往往需要开多个进程,因为应用总是有很多必须要并行做的事情。并行并不是说绝对的同时,而是说需要让这些事情看上去是同时进行的——比如图形渲染和响应用户输入。于是设计者们想到了,进程下面,需要一种程序的执行单位,仅仅被分配 CPU 资源,这就是线程。
轻量级进程
线程设计出来后,因为只被分配了计算资源(CPU),因此被称为轻量级进程。被分配的方式,就是由操作系统调度线程。操作系统创建一个进程后,进程的入口程序被分配到了一个主线程执行,这样看上去操作系统是在调度进程,其实是调度进程中的线程。
这种被操作系统直接调度的线程,我们也成为内核级线程。另外,有的程序语言或者应用,用户(程序员)自己还实现了线程。相当于操作系统调度主线程,主线程的程序用算法实现子线程,这种情况我们称为用户级线程。Linux 的 PThread API 就是用户级线程,KThread API 则是内核级线程。
分时和调度
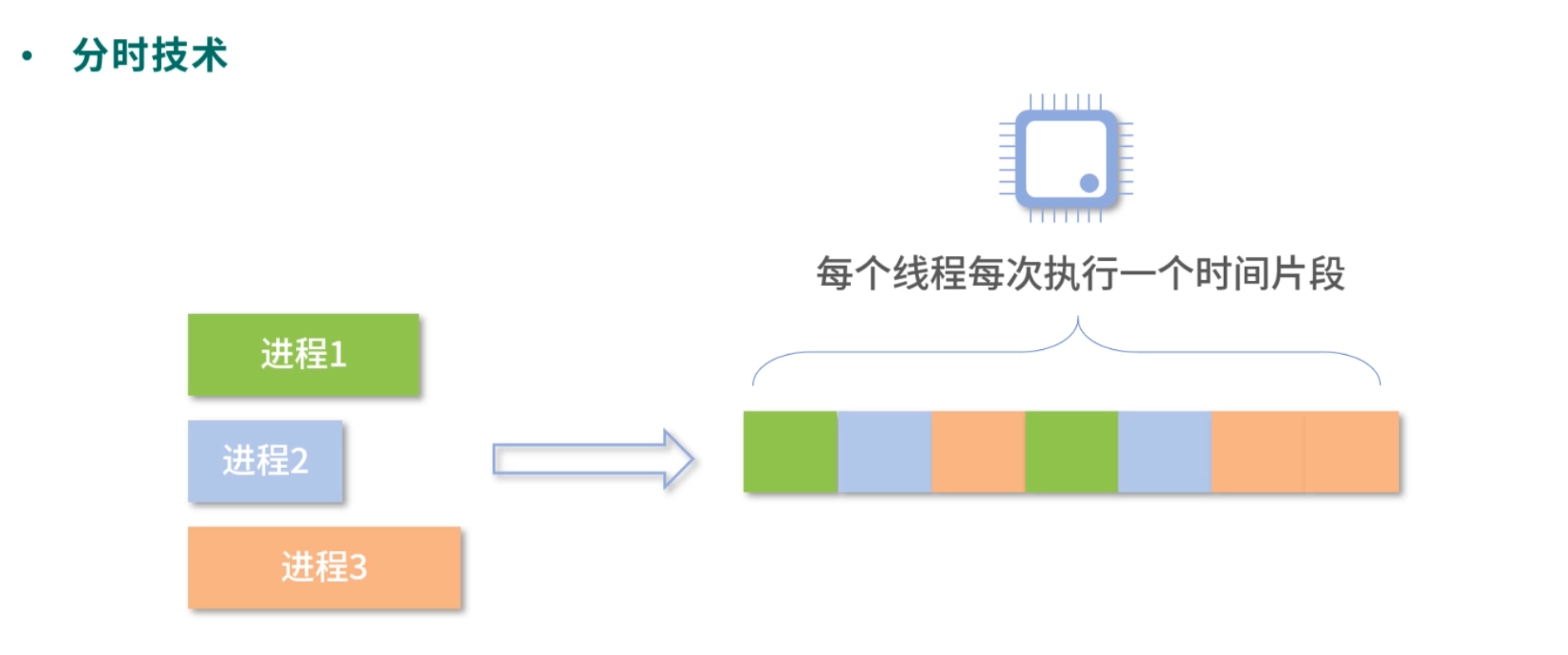
因为通常机器中 CPU 核心数量少(从几个到几十个)、进程&线程数量很多(从几十到几百甚至更多),你可以类比为发动机少,而机器多,因此进程们在操作系统中只能排着队一个个执行。每个进程在执行时都会获得操作系统分配的一个时间片段,如果超出这个时间,就会轮到下一个进程(线程)执行。再强调一下,现代操作系统都是直接调度线程,不会调度进程。
分配时间片段
如下图所示,进程 1 需要 2 个时间片段,进程 2 只有 1 个时间片段,进程 3 需要 3 个时间片段。因此当进程 1 执行到一半时,会先挂起,然后进程 2 开始执行;进程 2 一次可以执行完,然后进程 3 开始执行,不过进程 3 一次执行不完,在执行了 1 个时间片段后,进程 1 开始执行;就这样如此周而复始。这个就是分时技术。
下面这张图更加直观一些,进程 P1 先执行一个时间片段,然后进程 P2 开始执行一个时间片段, 然后进程 P3,然后进程 P4……
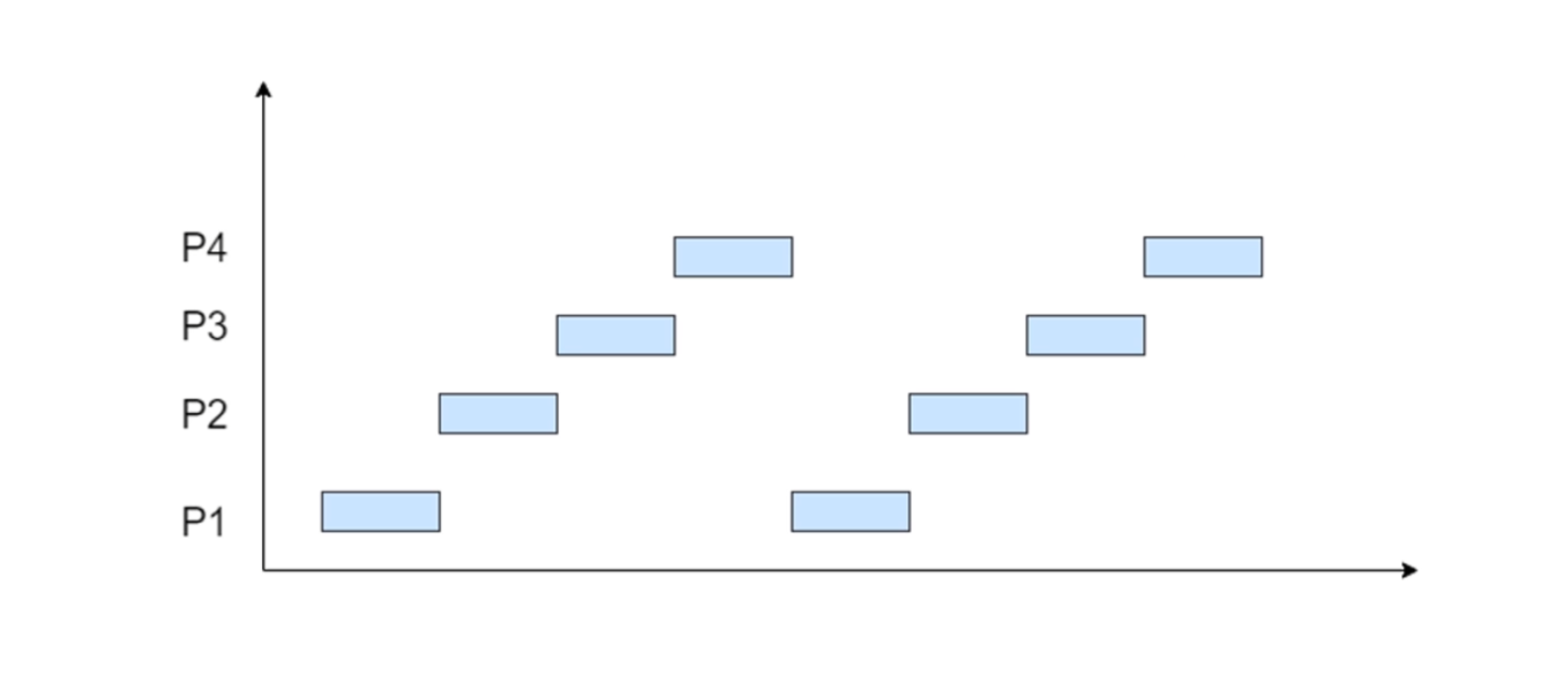
注意,上面的两张图是以进程为单位演示,如果换成线程,操作系统依旧是这么处理。
进程和线程的状态
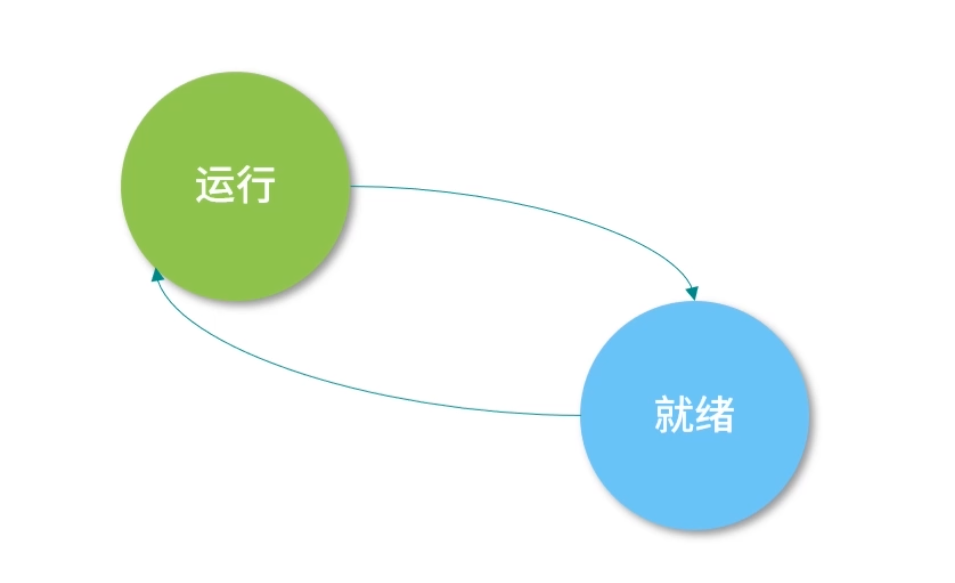
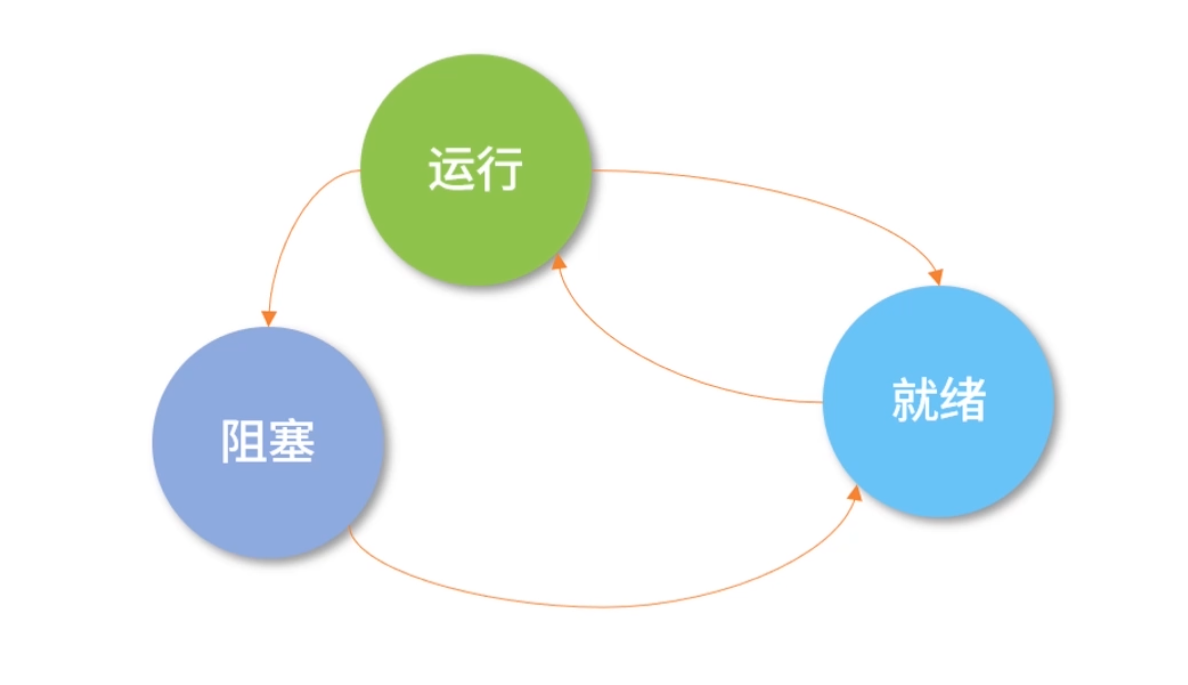
一个进程(线程)运行的过程,会经历以下 3 个状态:
进程(线程)创建后,就开始排队,此时它会处在“就绪”(Ready)状态;
当轮到该进程(线程)执行时,会变成“运行”(Running)状态;
当一个进程(线程)将操作系统分配的时间片段用完后,会回到“就绪”(Ready)状态。
我这里一直用进程(线程)是因为旧的操作系统调度进程,没有线程;现代操作系统调度线程。
有时候一个进程(线程)会等待磁盘读取数据,或者等待打印机响应,此时进程自己会进入“阻塞”(Block)状态。
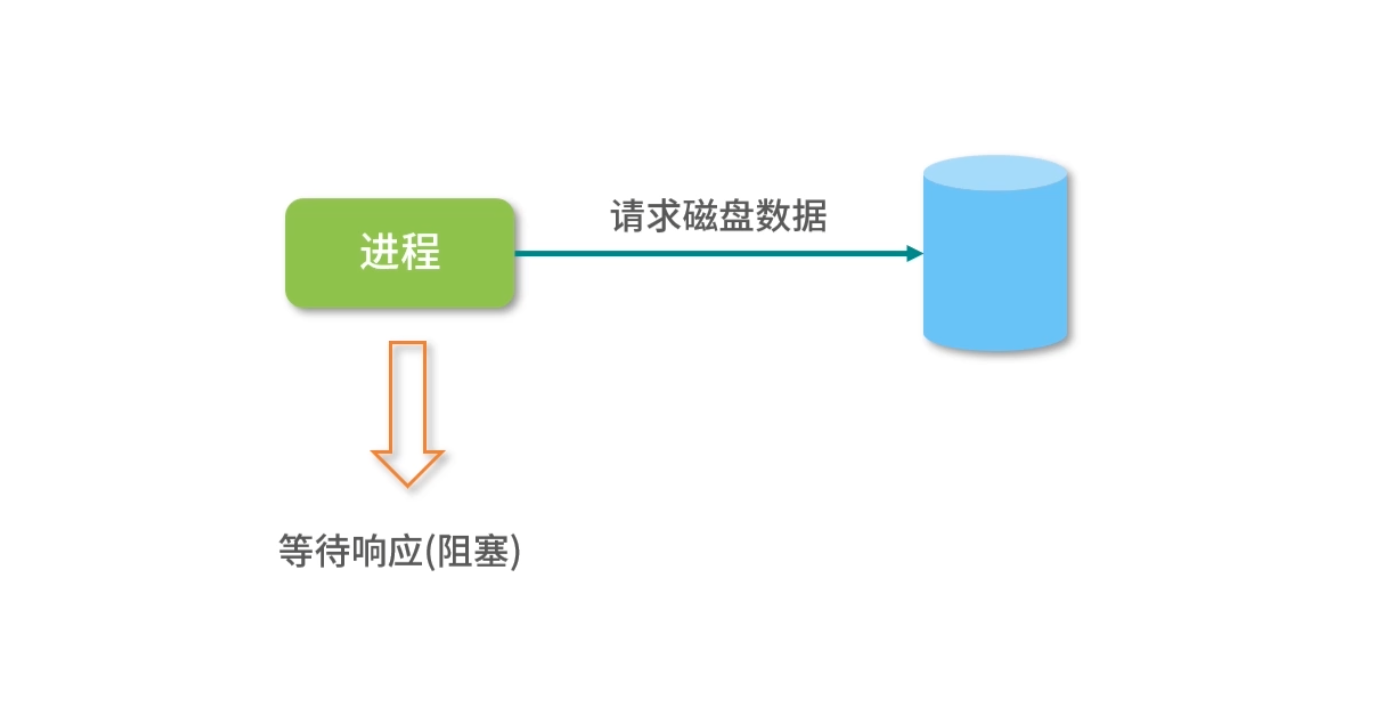
因为这时计算机的响应不能马上给出来,而是需要等待磁盘、打印机处理完成后,通过中断通知 CPU,然后 CPU 再执行一小段中断控制程序,将控制权转给操作系统,操作系统再将原来阻塞的进程(线程)置为“就绪”(Ready)状态重新排队。
而且,一旦一个进程(线程)进入阻塞状态,这个进程(线程)此时就没有事情做了,但又不能让它重新排队(因为需要等待中断),所以进程(线程)中需要增加一个“阻塞”(Block)状态。
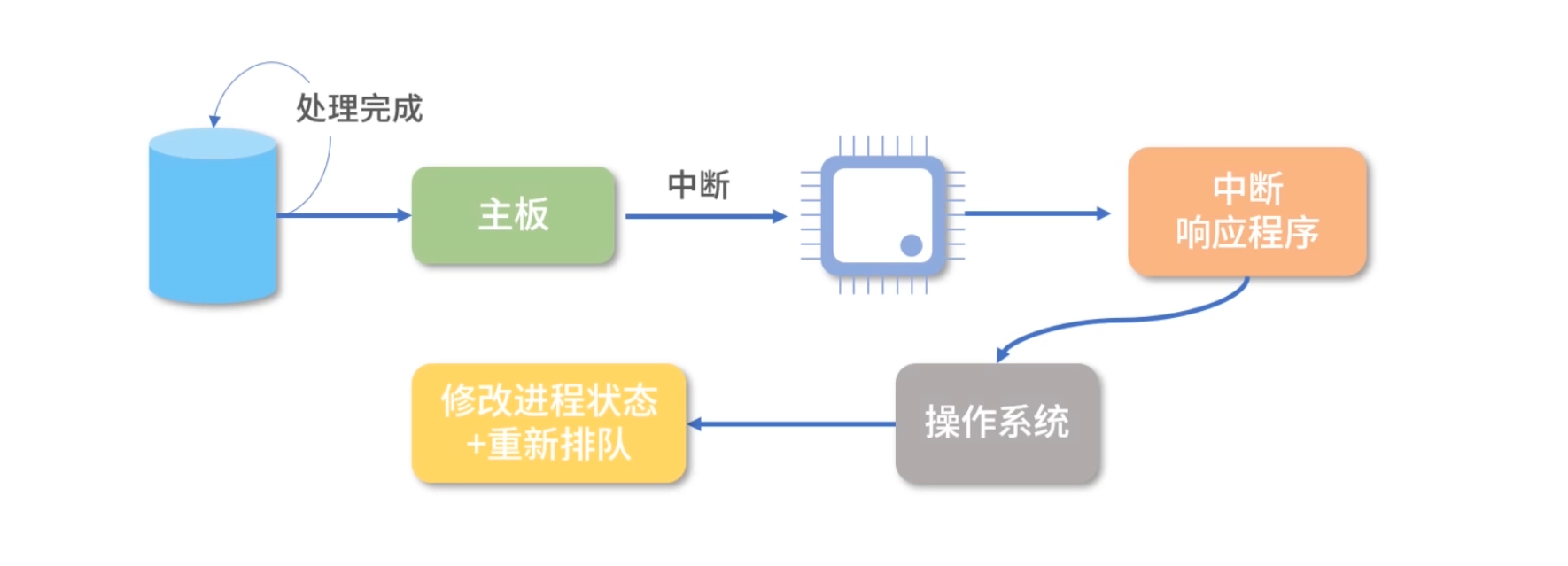
注意,因为一个处于“就绪”(Ready)的进程(线程)还在排队,所以进程(线程)内的程序无法执行,也就是不会触发读取磁盘数据的操作,这时,“就绪”(Ready)状态无法变成阻塞的状态,因此下图中没有从就绪到阻塞的箭头。
而处于“阻塞”(Block)状态的进程(线程)如果收到磁盘读取完的数据,它又需要重新排队,所以它也不能直接回到“运行”(Running)状态,因此下图中没有从阻塞态到运行态的箭头。
进程和线程的设计
接下来我们思考几个核心的设计约束:
进程和线程在内存中如何表示?需要哪些字段?
进程代表的是一个个应用,需要彼此隔离,这个隔离方案如何设计?
操作系统调度线程,线程间不断切换,这种情况如何实现?
需要支持多 CPU 核心的环境,针对这种情况如何设计?
接下来我们来讨论下这4个问题。
进程和线程的表示
可以这样设计,在内存中设计两张表,一张是进程表、一张是线程表。
进程表记录进程在内存中的存放位置、PID 是多少、当前是什么状态、内存分配了多大、属于哪个用户等,这就有了进程表。如果没有这张表,进程就会丢失,操作系统不知道自己有哪些进程。这张表可以考虑直接放到内核中。
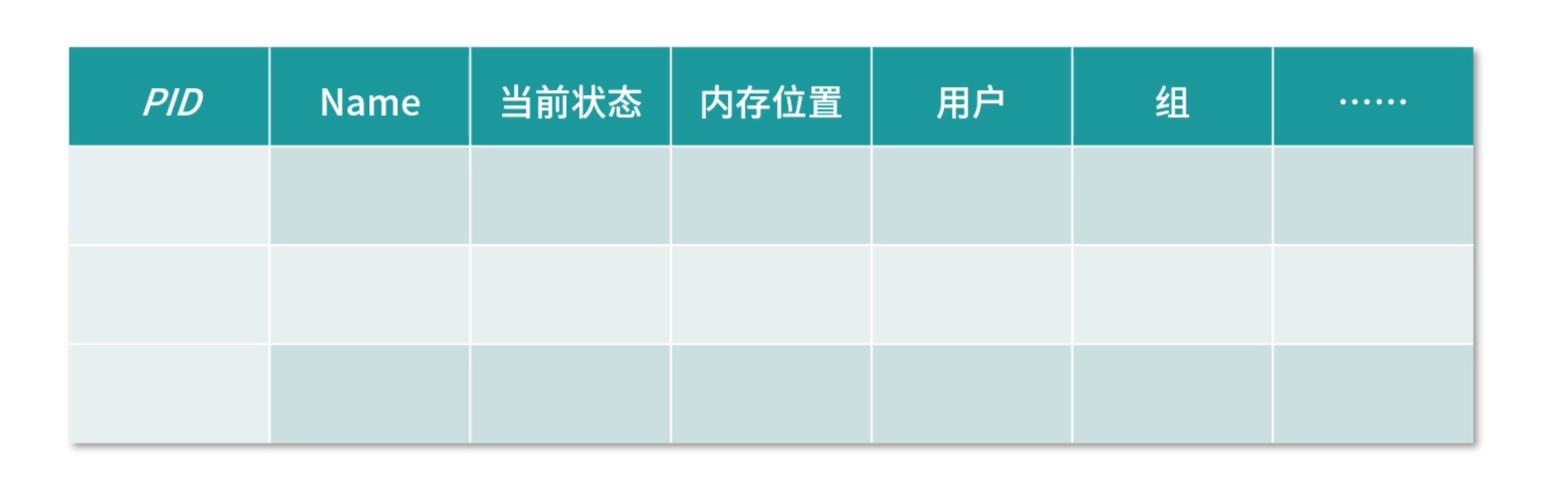
细分的话,进程表需要这几类信息。
描述信息:这部分是描述进程的唯一识别号,也就是 PID,包括进程的名称、所属的用户等。
资源信息:这部分用于记录进程拥有的资源,比如进程和虚拟内存如何映射、拥有哪些文件、在使用哪些 I/O 设备等,当然 I/O 设备也是文件。
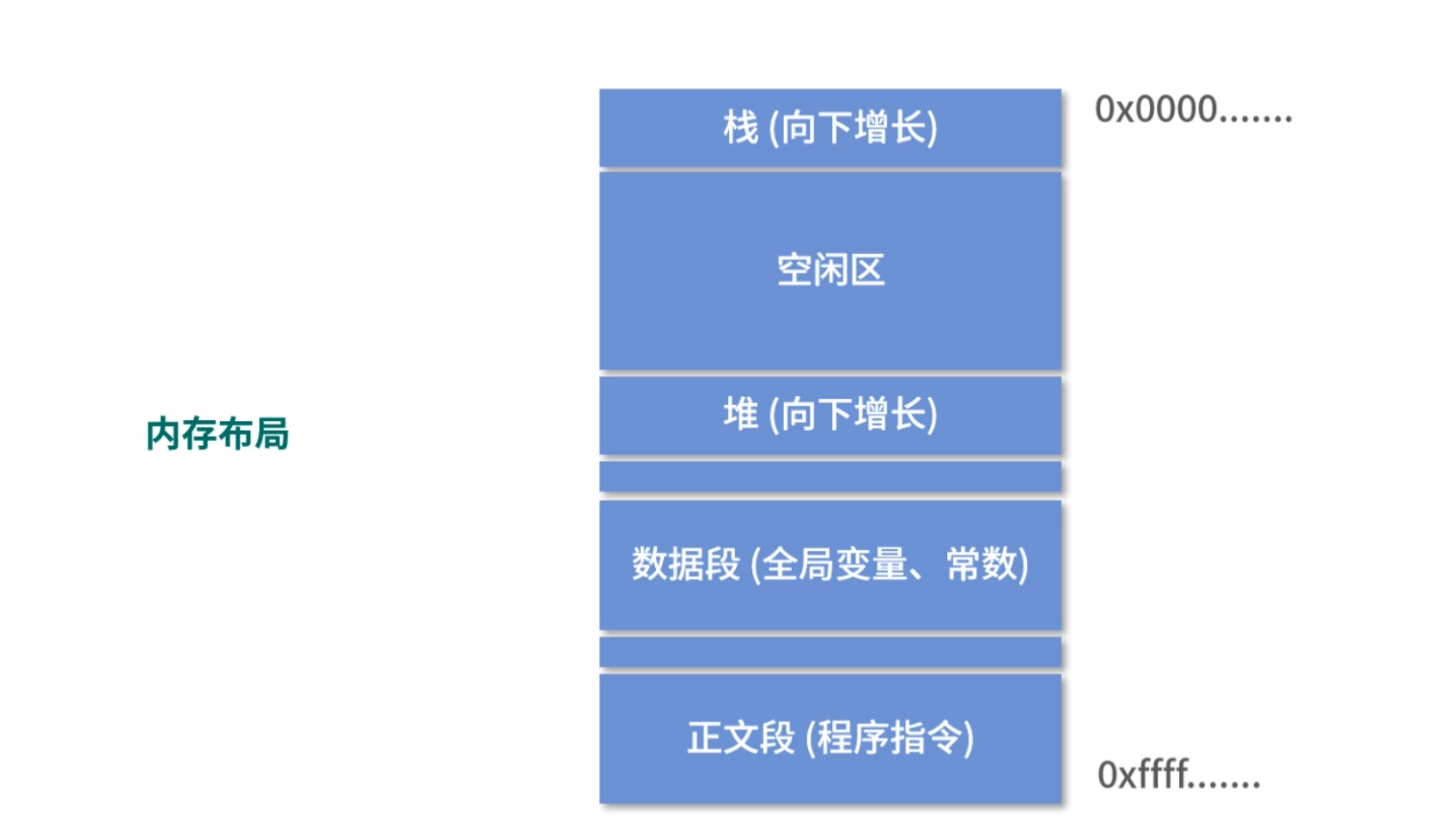
内存布局:操作系统也约定了进程如何使用内存。如下图所示,描述了一个进程大致内存分成几个区域,以及每个区域用来做什么。 每个区域我们叫作一个段。
操作系统还需要一张表来管理线程,这就是线程表。线程也需要 ID, 可以叫作 ThreadID。然后线程需要记录自己的执行状态(阻塞、运行、就绪)、优先级、程序计数器以及所有寄存器的值等等。线程需要记录程序计数器和寄存器的值,是因为多个线程需要共用一个 CPU,线程经常会来回切换,因此需要在内存中保存寄存器和 PC 指针的值。
用户级线程和内核级线程存在映射关系,因此可以考虑在内核中维护一张内核级线程的表,包括上面说的字段。
如果考虑到这种映射关系,比如 n-m 的多对多映射,可以将线程信息还是存在进程中,每次执行的时候才使用内核级线程。相当于内核中有个线程池,等待用户空间去使用。每次用户级线程把程序计数器等传递过去,执行结束后,内核线程不销毁,等待下一个任务。这里其实有很多灵活的实现,总体来说,创建进程开销大、成本高;创建线程开销小,成本低。
隔离方案
操作系统中运行了大量进程,为了不让它们互相干扰,可以考虑为它们分配彼此完全隔离的内存区域,即便进程内部程序读取了相同地址,而实际的物理地址也不会相同。这就好比 A 小区的 10 号楼 808 和 B 小区的 10 号楼 808 不是一套房子,这种方法叫作地址空间,我们将在“21 讲”的页表部分讨论“地址空间”的详细内容。
所以在正常情况下进程 A 无法访问进程 B 的内存,除非进程 A 找到了某个操作系统的漏洞,恶意操作了进程 B 的内存,或者利用我们在“21 讲”讲到的“进程间通信”的手段。

对于一个进程的多个线程来说,可以考虑共享进程分配到的内存资源,这样线程就只需要被分配执行资源。
进程(线程)切换
进程(线程)在操作系统中是不断切换的,现代操作系统中只有线程的切换。 每次切换需要先保存当前寄存器的值的内存,注意 PC 指针也是一种寄存器。当恢复执行的时候,就需要从内存中读出所有的寄存器,恢复之前的状态,然后执行。
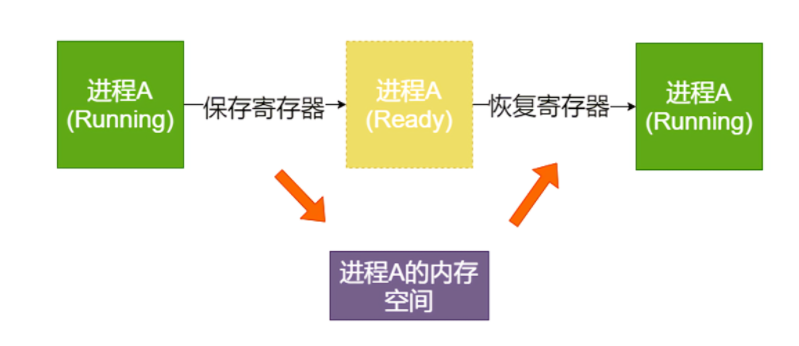
上面讲到的内容,我们可以概括为以下 5 个步骤:
当操作系统发现一个进程(线程)需要被切换的时候,直接控制 PC 指针跳转是非常危险的事情,所以操作系统需要发送一个“中断”信号给 CPU,停下正在执行的进程(线程)。
当 CPU 收到中断信号后,正在执行的进程(线程)会立即停止。注意,因为进程(线程)马上被停止,它还来不及保存自己的状态,所以后续操作系统必须完成这件事情。
操作系统接管中断后,趁寄存器数据还没有被破坏,必须马上执行一小段非常底层的程序(通常是汇编编写),帮助寄存器保存之前进程(线程)的状态。
操作系统保存好进程状态后,执行调度程序,决定下一个要被执行的进程(线程)。
最后,操作系统执行下一个进程(线程)。
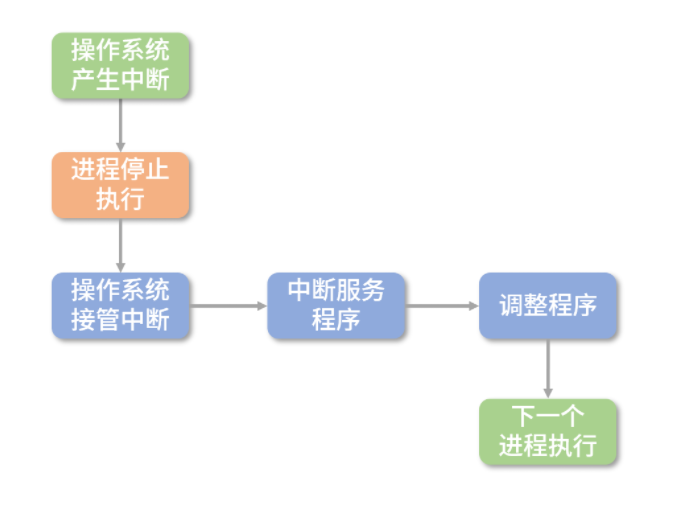
当然,一个进程(线程)被选择执行后,它会继续完成之前被中断时的任务,这需要操作系统来执行一小段底层的程序帮助进程(线程)恢复状态。
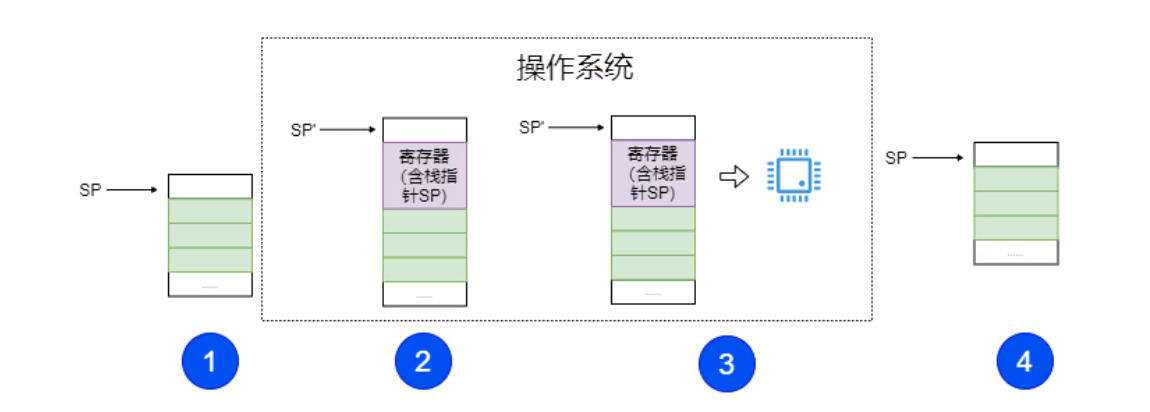
一种可能的算法就是通过栈这种数据结构。进程(线程)中断后,操作系统负责压栈关键数据(比如寄存器)。恢复执行时,操作系统负责出栈和恢复寄存器的值。
多核处理
在多核系统中我们上面所讲的设计原则依然成立,只不过动力变多了,可以并行执行的进程(线程)。通常情况下,CPU 有几个核,就可以并行执行几个进程(线程)。这里强调一个概念,我们通常说的并发,英文是 concurrent,指的在一段时间内几个任务看上去在同时执行(不要求多核);而并行,英文是 parallel,任务必须绝对的同时执行(要求多核)。
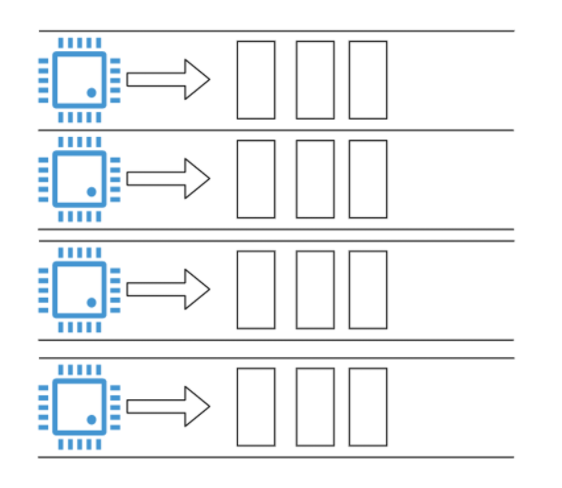
比如一个 4 核的 CPU 就好像拥有 4 条流水线,可以并行执行 4 个任务。一个进程的多个线程执行过程则会产生竞争条件,这块我们会在“19 讲”锁和信号量部分给你介绍。因为操作系统提供了保存、恢复进程状态的能力,使得进程(线程)也可以在多个核心之间切换。
创建进程(线程)的 API
用户想要创建一个进程,最直接的方法就是从命令行执行一个程序,或者双击打开一个应用。但对于程序员而言,显然需要更好的设计。
站在设计者的角度,你可以这样思考:首先,应该有 API 打开应用,比如可以通过函数打开某个应用;另一方面,如果程序员希望执行完一段代价昂贵的初始化过程后,将当前程序的状态复制好几份,变成一个个单独执行的进程,那么操作系统提供了 fork 指令。
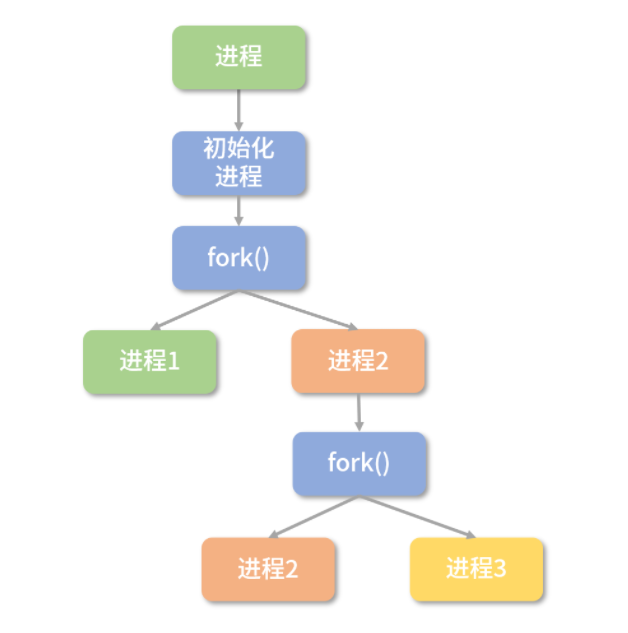
也就是说,每次 fork 会多创造一个克隆的进程,这个克隆的进程,所有状态都和原来的进程一样,但是会有自己的地址空间。如果要创造 2 个克隆进程,就要 fork 两次。
你可能会问:那如果我就是想启动一个新的程序呢?
我在上文说过:操作系统提供了启动新程序的 API。
你可能还会问:如果我就是想用一个新进程执行一小段程序,比如说每次服务端收到客户端的请求时,我都想用一个进程去处理这个请求。
如果是这种情况,我建议你不要单独启动进程,而是使用线程。因为进程的创建成本实在太高了,因此不建议用来做这样的事情:要创建条目、要分配内存,特别是还要在内存中形成一个个段,分成不同的区域。所以通常,我们更倾向于多创建线程。
不同程序语言会自己提供创建线程的 API,比如 Java 有 Thread 类;go 有 go-routine(注意不是协程,是线程)。
进程的开销比线程大在了哪里?
Linux 中创建一个进程自然会创建一个线程,也就是主线程。创建进程需要为进程划分出一块完整的内存空间,有大量的初始化操作,比如要把内存分段(堆栈、正文区等)。创建线程则简单得多,只需要确定 PC 指针和寄存器的值,并且给线程分配一个栈用于执行程序,同一个进程的多个线程间可以复用堆栈。因此,创建进程比创建线程慢,而且进程的内存开销更大。
如何控制同一时间只有 2 个线程运行?
锁是一个面试的热门话题,有乐观锁、悲观锁、重入锁、公平锁、分布式锁。有很多和锁相关的数据结构,比如说阻塞队列。还有一些关联的一些工具,比如说 Semaphore、Monitor 等。这些知识点可以关联很多的面试题目,比如:
锁是如何实现的?
如何控制同一时间只有 2 个线程运行?
如何实现分布式锁?
原子操作
要想弄清楚锁,就要弄清楚锁的实现,实现锁需要底层提供的原子操作,因此我们先来学习下原子操作。
原子操作就是操作不可分。在多线程环境,一个原子操作的执行过程无法被中断。那么你可以思考下,具体原子操作的一个示例。
比如i++就不是一个原子操作,因为它是 3 个原子操作组合而成的:
读取 i 的值;
计算 i+1;
写入新的值。
像这样的操作,在多线程 + 多核环境会造成竞争条件。
竞争条件
竞争条件就是说多个线程对一个资源(内存地址)的读写存在竞争,在这种条件下,最后这个资源的值不可预测,而是取决于竞争时具体的执行顺序。
举个例子,比如两个线程并发执行i++。那么可以有下面这个操作顺序,假设执行前i=0:
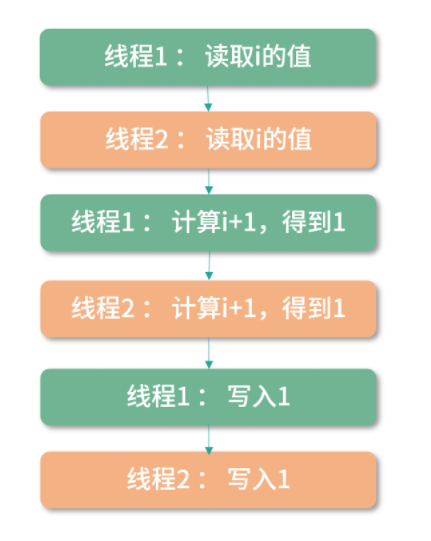
虽然上面的程序执行了两次i++,但最终i的值为 1。
i++这段程序访问了共享资源,也就是变量i,这种访问共享资源的程序片段我们称为临界区。在临界区,程序片段会访问共享资源,造成竞争条件,也就是共享资源的值最终取决于程序执行的时序,因此这个值不是确定的。
竞争条件是一件非常糟糕的事情,你可以把上面的程序想象成两个自动提款机。如果用户同时操作两个自动提款机,用户的余额就可能会被算错。
解决竞争条件
解决竞争条件有很多方案,一种方案就是不要让程序同时进入临界区,这个方案叫作互斥。还有一些方案旨在避免竞争条件,比如 ThreadLocal、 cas 指令以及 “19 讲”中我们要学习的乐观锁。
避免临界区
不让程序同时进入临界区这个方案比较简单,核心就是我们给每个线程一个变量i,比如利用 ThreadLocal,这样线程之间就不存在竞争关系了。这样做优点很明显,缺点就是并不是所有的情况都允许你这样做。有一些资源是需要共享的,比如一个聊天室,如果每次用户请求都有一个单独的线程在处理,不可能为每个请求(线程)都维护一份聊天记录。
cas 指令
另一个方案是利用 CPU 的指令,让i++成为一个原子操作。 很多 CPU 都提供 Compare And Swap 指令。这个指令的作用是更新一个内存地址的值,比如把i更新为i+1,但是这个指令明确要求使用者必须确定知道内存地址中的值是多少。比如一个线程想把i从100更新到101,线程必须明确地知道现在i是 100,否则就会更新失败。
cas 可以用下面这个函数表示:
1 | cas(&oldValue, expectedValue, targetValue) |
这里我用的是伪代码,用&符号代表这里取内存地址。注意 cas 是 CPU 提供的原子操作。因此上面的比较和设置值的过程,是原子的,也就是不可分。
比如想用 cas 更新i的值,而且知道i是 100,想更新成101。那么就可以这样做:
1 | cas(&i, 100, 101) |
如果在这个过程中,有其他线程把i更新为101,这次调用会返回 false,否则返回 true。
所以i++程序可以等价的修改为:
1 | cas(&i, i, i+1) |
上面的程序执行时,其实是 3 条指令:
1 | 读取i |
假设i=0,考虑两个线程分别执行一次这个程序,尝试构造竞争条件:
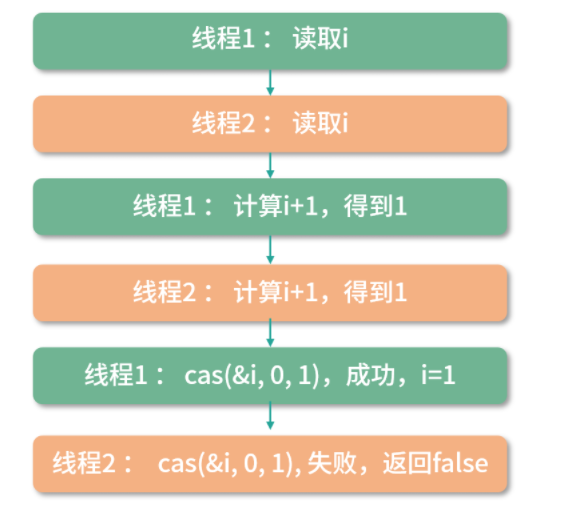
你可以看到通过这种方式,cas 解决了一部分问题,找到了竞争条件,并返回了 false。但是还是无法计算出正确的结果。因为最后一次 cas 失败了。
如果要完全解决可以考虑这样去实现:
1 | while(!cas(&i, i, i+1)){ |
如果 cas 返回 false,那么会尝试再读一次 i 的值,直到 cas 成功。
tas 指令
还有一个方案是 tas 指令,有的 CPU 没有提供 cas(大部分服务器是提供的),提供一种 Test-And-Set 指令(tas)。tas 指令的目标是设置一个内存地址的值为 1,它的工作原理和 cas 相似。首先比较内存地址的数据和 1 的值,如果内存地址是 0,那么把这个地址置 1。如果是 1,那么失败。
所以你可以把 tas 看作一个特殊版的cas,可以这样来理解:
1 | tas(&lock) { |
锁
锁(lock),目标是实现抢占(preempt)。就是只让给定数量的线程进入临界区。锁可以用tas或者cas来实现。
举个例子:如果希望同时只能有一个线程执行i++,伪代码可以这么写:
1 | enter(); |
可以考虑用cas实现enter和leave函数,代码如下:
1 | int lock = 0; |
多个线程竞争一个整数的 lock 变量,0 代表目前没有线程进入临界区,1 代表目前有线程进入临界区。利用cas原子指令我们可以对临界区进行管理。如果一个线程利用 cas 将 lock 设置为 1,那么另一个线程就会一直执行cas操作,直到锁被释放。
语言级锁的实现
上面解决竞争条件的时候,我们用到了锁。 相比 cas,锁是一种简单直观的模型。总体来说,cas 更底层,用 cas 解决问题优化空间更大。但是用锁解决问题,代码更容易写——进入临界区之前 lock,出去就 unlock。 从上面这段代码可以看出,为了定义锁,我们需要用到一个整型。如果实现得好,可以考虑这个整数由语言级定义。
比如考虑让用户传递一个变量过去:
1 | int lock = 0; |
自旋锁
上面我们已经用过自旋锁了,这是之前的代码:
1 | enter(){ |
这段代码不断在 CPU 中执行指令,直到锁被其他线程释放。这种情况线程不会主动释放资源,我们称为自旋锁。自旋锁的优点就是不会主动发生 Context Switch,也就是线程切换,因为线程切换比较消耗时间。自旋锁缺点也非常明显,比较消耗 CPU 资源。如果自旋锁一直拿不到锁,会一直执行。
wait 操作
你可以考虑实现一个 wait 操作,主动触发 Context Switch。这样就解决了 CPU 消耗的问题。但是触发 Context Switch 也是比较消耗成本的事情,那么有没有更好的方法呢?
1 | enter(){ |
你可以看下上面的代码,这里有一个更好的方法:就是 cas 失败后,马上调用sleep方法让线程休眠一段时间。但是这样,可能会出现锁已经好了,但是还需要多休眠一小段时间的情况,影响计算效率。
另一个方案,就是用wait方法,等待一个信号——直到另一个线程调用notify方法,通知这个线程结束休眠。但是这种情况——wait 和 notify 的模型要如何实现呢?
生产者消费者模型
一个合理的实现就是生产者消费者模型。 wait 是一个生产者,将当前线程挂到一个等待队列上,并休眠。notify 是一个消费者,从等待队列中取出一个线程,并重新排队。
如果使用这个模型,那么我们之前简单用enter和leave来封装加锁和解锁的模式,就需要变化。我们需要把enter leave wait notify的逻辑都封装起来,不让用户感知到它们的存在。
比如 Java 语言,Java 为每个对象增加了一个 Object Header 区域,里面一个锁的位(bit),锁并不需要一个 32 位整数,一个 bit 足够。下面的代码用户使用 synchronized 关键字让临界区访问互斥。
1 | synchronized(obj){// enter |
synchronized 关键字的内部实现,用到了封装好的底层代码——Monitor 对象。每个 Java 对象都关联了一个 Monitor 对象。Monitor 封装了对锁的操作,比如 enter、leave 的调用,这样简化了 Java 程序员的心智负担,你只需要调用 synchronized 关键字。
另外,Monitor 实现了生产者、消费者模型。
- 如果一个线程拿到锁,那么这个线程继续执行;
- 如果一个线程竞争锁失败,Montior 就调用 wait 方法触发生产者的逻辑,把线程加入等待集合;
- 如果一个线程执行完成,Monitor 就调用一次 notify 方法恢复一个等待的线程。
这样,Monitor 除了提供了互斥,还提供了线程间的通信,避免了使用自旋锁,还简化了程序设计。
信号量
接下来介绍一个叫作信号量的方法,你可以把它看作是互斥的一个广义版。我们考虑一种更加广义的锁,这里请你思考如何同时允许 N 个线程进入临界区呢?
我们先考虑实现一个基础的版本,用一个整数变量lock来记录进入临界区线程的数量。
1 | int lock = 0; |
上面的代码具有一定的欺骗性,没有考虑到竞争条件,执行的时候会出问题,可能会有超过2个线程同时进入临界区。
下面优化一下,作为一个考虑了竞争条件的版本:
1 | up(&lock){ |
为了简化模型,我们重新设计了两个原子操作up和down。up将lock增 1,down将lock减 1。当 lock 为 0 时,如果还在down那么会自旋。考虑用多个线程同时执行下面这段程序:
1 | int lock = 2; |
如果只有一个线程在临界区,那么lock等于 1,第 2 个线程还可以进入。 如果两个线程在临界区,第 3 个线程尝试down的时候,会陷入自旋锁。当然我们也可以用其他方式来替代自旋锁,比如让线程休眠。
当lock初始值为 1 的时候,这个模型就是实现互斥(mutex)。如果 lock 大于 1,那么就是同时允许多个线程进入临界区。这种方法,我们称为信号量(semaphore)。
信号量实现生产者消费者模型
信号量可以用来实现生产者消费者模型。下面我们通过一段代码实现生产者消费者:
1 | int empty = N; // 当前空位置数量 |
代码中 wait 是生产者,notify 是消费者。 每次wait操作减少一个空位置数量,empty-1;增加一个等待的线程,full+1。每次notify操作增加一个空位置,empty+1,减少一个等待线程,full-1。
insert和remove方法是互斥的操作,需要用另一个 mutex 锁来保证。insert方法将当前线程加入等待队列,并且调用 yield 方法,交出当前线程的控制权,当前线程休眠。remove方法从等待队列中取出一个线程,并且调用resume进行恢复。以上, 就构成了一个简单的生产者消费者模型。
死锁问题
另外就是在并行的时候,如果两个线程互相等待对方获得的锁,就会发生死锁。你可以把死锁理解成一个环状的依赖关系。比如:
1 | int lock1 = 0; |
上面的程序,如果是按照下面这个顺序执行,就会死锁:
1 | 线程1: enter(&lock1); |
上面程序线程 1 获得了lock1,线程 2 获得了lock2。接下来线程 1 尝试获得lock2,线程 2 尝试获得lock1,于是两个线程都陷入了等待。这个等待永远都不会结束,我们称之为死锁。
关于死锁如何解决,我们会在“21 | 哲学家就餐问题:什么情况下会触发饥饿和死锁?”讨论。这里我先讲一种最简单的解决方案,你可以尝试让两个线程对锁的操作顺序相同,这样就可以避免死锁问题。
分布式环境的锁
最后,我们留一点时间给分布式锁。我们之前讨论了非常多的实现,是基于多个线程访问临界区。现在要考虑一个更庞大的模型,我们有 100 个容器,每一个里面有一个为用户减少积分的服务。
简化下模型,假设积分存在 Redis 中。当然数据库中也有,但是我们只考虑 Redis。使用 Redis,我们目标是给数据库减负。
假设这个接口可以看作 3 个原子操作:
- 从 Redis 读出当前库存;
- 计算库存 -1;
- 更新 Redis 库存。
和i++类似,很明显,当用户并发的访问这个接口,是会发生竞争条件的。 因为程序已经不是在同一台机器上执行了,解决方案就是分布式锁。实现锁,我们需要原子操作。
在单机多线程并发的场景下,原子操作由 CPU 指令提供,比如 cas 和 tas 指令。那么在分布式环境下,原子操作由谁提供呢?``
有很多工具都可以提供分布式的原子操作,比如 Redis 的 setnx 指令,Zookeeper 的节点操作等等。作为操作系统课程,这部分我不再做进一步的讲解。这里是从多线程的处理方式,引出分布式的处理方式,通过两个类比,帮助你提高。如果你感兴趣,可以自己查阅更多的分布式锁的资料。
如何控制同一时间只有 2 个线程运行?
同时控制两个线程进入临界区,一种方式可以考虑用信号量(semaphore)。
另一种方式是考虑生产者、消费者模型。想要进入临界区的线程先在一个等待队列中等待,然后由消费者每次消费两个。这种实现方式,类似于实现一个线程池,所以也可以考虑实现一个 ThreadPool 类,然后再实现一个调度器类,最后实现一个每次选择两个线程执行的调度算法。
除了上锁还有哪些并发控制方法?
上面这道面试题是在“有哪些并发控制方法?”这个问题的基础上加了一个限制条件。
在我面试候选人的过程中,“上锁”是我听到过回答频次最多的答案,也就是说大多数程序员都可以想到这个并发控制方法。因此,是否能回答出上锁以外的方法,是检验程序员能力的一个分水岭,其实锁以外还有大量优秀的方法。
你掌握的方法越多,那么在解决实际问题的时候,思路就越多。即使你没有做过高并发场景的设计,但是如果脑海中有大量优秀的方法可以使用,那么公司也会考虑培养你,将高并发场景交给你去解决。今天我们就以这道面试题为引,一起探讨下“锁以外的并发控制方法”。
悲观锁/乐观锁
说到并发场景,设计系统的目的往往是达到同步(Synchronized)的状态,同步就是大家最终对数据的理解达成了一致。
同步的一种方式,就是让临界区互斥。 这种方式,每次只有一个线程可以进入临界区。比如多个人修改一篇文章,这意味着必须等一个人编辑完,另一个人才能编辑。但是从实际问题出发,如果多个人编辑的不是文章的同一部分,是可以同时编辑的。因此,让临界区互斥的方法(对临界区上锁),具有强烈的排他性,对修改持保守态度,我们称为悲观锁(Pressimistic Lock)。
通常意义上,我们说上锁,就是悲观锁,比如说 MySQL 的表锁、行锁、Java 的锁,本质是互斥(mutex)。
和悲观锁(PressimisticLock)持相反意见的,是乐观锁(Optimistic Lock)。你每天都用的,基于乐观锁的应用就是版本控制工具 Git。Git 允许大家一起编辑,将结果先存在本地,然后都可以向远程仓库提交,如果没有版本冲突,就可以提交上去。这就是一种典型的乐观锁的场景,或者称为基于版本控制的场景。
Git 的类比
比如现在代码仓库的版本是 100。Bob 和 Alice 把版本 100 拷贝到本地,Bob 在本地写到了 106 版本,Alice 在本地写到 108 版本。那么如果 Alice 先提交,代码仓库的版本就到了 108。 Bob 再提交的时候,发现版本已经不是 100 了,就需要把最新的代码 fetch 到本地,然后合并冲突,再尝试提交一个更新的版本,比如 110。
这种方式非常类似cas指令的形式,就是每次更新的发起方,需要明确地知道想从多少版本更新到多少版本。以 Git 为例,可以写出cas的伪代码:
1 | cas(&version, 100, 108); // 成功 |
购物车的类比
再举个例子,比如说要实现一个购物车。用户可能在移动端、PC 端之间切换,比如他用一会手机累了,然后换成用电脑,当他用电脑累了,再换回手机。
在移动端和 PC 端,用户都在操作购物车。 比如在移动端上,用户增加了商品 A;然后用户打开 PC 端,增加了商品 B;然后用户又换回了移动端,想增加商品 C。
这种时候,如果用悲观锁,用户登录移动端后,一种方案就是把 PC 端下线——当然这个方案显然不合理。 合理的方案是给购物车一个版本号,假设是 MySQL 表,那么购物车表中就会多一个版本字段。这样当用户操作购物车的时候,检查一下当前购物车的版本号是不是最新的,如果是最新的,那么就正常操作。如果不是最新的,就提示用户购物车在其他地方已被更新,需要刷新。
去中心化方案:区块链的类比
继续类比,我们可以思考一个更加有趣的方案。在传统的架构中,我们之所以害怕并发,是因为中心化。比如说 DNS 系统,如果全球所有的 DNS 查询都执行一个集群,这个吞吐量是非常恐怖的,因此 DNS 系统用了一个分级缓存的策略。
但是交易数据分布的时候,比如下单、支付、修改库存,如果用分布式处理,就牵扯到分布式锁(分布式事务)。那么,有没有一个去中心化的方案,让业务不需要集中处理呢?比如说双 11 期间你在淘宝上买东西,可不可以直接和商家下单,而不用通过淘宝的中心系统呢?——如果可以,这也就相当于实现了同步,或者说去掉了高并发的同步。
解决最基本的信用问题
考虑购买所有的网购产品,下单不再走中心化的平台。比如阿里、拼多多、 京东、抖音……这些平台用户都不走平台的中心系统下单,而是用户直接和商家签订合同。这个技术现在已经实现了,叫作电子合同。
举例:Alice(A)向苹果店 B 购买了一个 iPhone。那么双方签订电子合同,合同内容 C 是:
1 | from=A, to=B, price=10000, signature=alice的签名 |
上面两条记录,第 1 条是说 A 同意给 B 转 10000 块钱;第 2 条记录说,B 同意给 A 一个 iPhone。如果 A 收了 iPhone 不给 B 打款,B 可以拿着这个电子合同去法院告 A。因为用 A 的签名,可以确定是 Alice 签署了这份协议。同理,如果苹果店不给 Alice iPhone,Alice 可以去法院告苹果店,因为 Alice 可以用苹果店的签名证明合同是真的。
解决货币和库存的问题
有了上面的例子,最基本的信用问题解决了。接下来,你可能会问,Alice 怎么证明自己有足够的钱买 iPhone?苹果店怎么证明有足够的 iPhone?
比如在某个对公开放的节点中,记录了:
1 | account=alice, money=10000 |
我们假设这里的钱可能是 Alice 用某种手段放进来的。或者我们再简化这个模型,比如全世界所有人的钱,都在这个系统里,这样我们就不用关心钱从哪里来这个问题了。如果是比特币,钱是需要挖矿的。
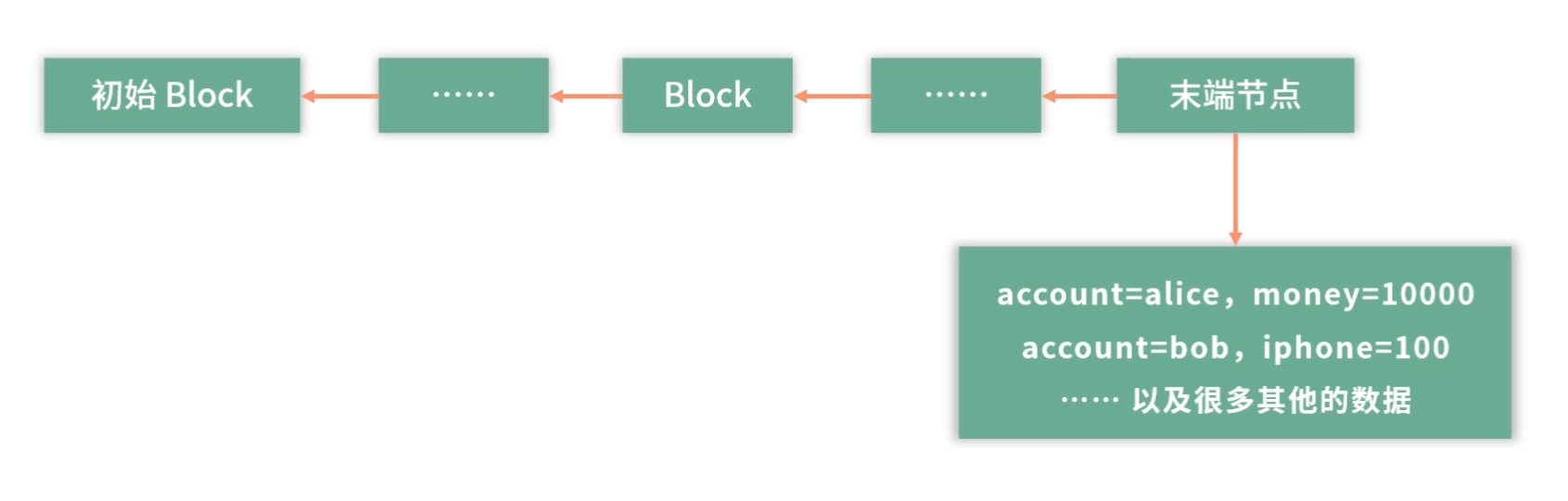
如图,这个结构也叫作区块链。每个 Block 下面可以存一些数据,每个 Block 知道上一个节点是谁。每个 Block 有上一个节点的摘要签名。也就是说,如果 Block 10 是 Block 11 的上一个节点,那么 Block 11 会知道 Block 10 的存在,且用 Block 11 中 Block 10 的摘要签名,可以证明 Block 10 的数据没有被篡改过。
区块链构成了一个基于历史版本的事实链,前一个版本是后一个版本的历史。Alice 的钱和苹果店的 iPhone 数量,包括全世界所有人的钱,都在这些 Block 里。
购买转账的过程
下面请你思考,Alice 购买了 iPhone,需要提交两条新数据到上面的区块链。
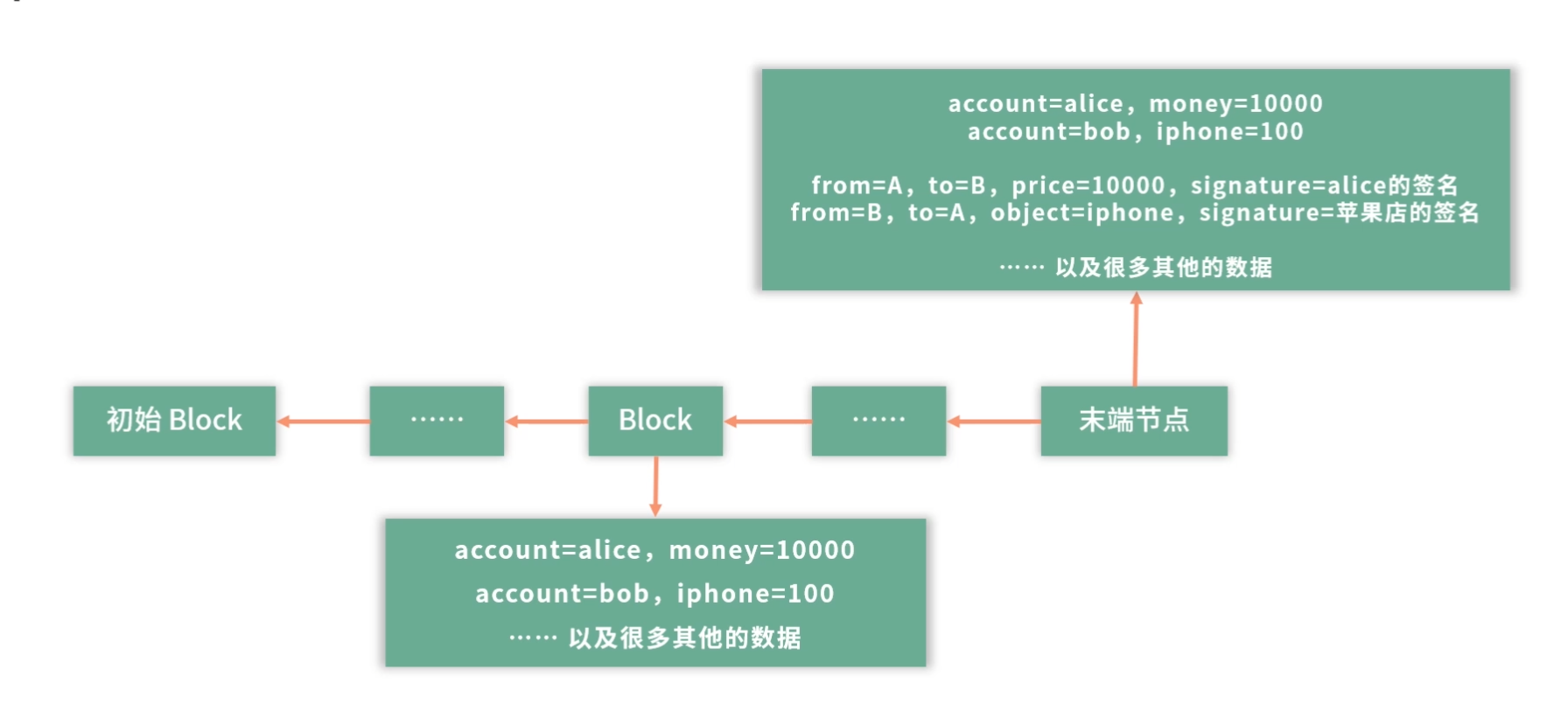
比如,Alice 先在本地完成这件事情,本地的区块链就会像上图那样。 假设有一个中心化的服务器,专门接收这些区块数据,Alice 接下来就可以把数据提交到中心化的服务器,苹果店从中心化服务器上看到这条信息,认为交易被 Alice 执行了,就准备发货。
如果世界上有很多人同时在这个末端节点上写新的 Block。那么可以考虑由一个可信任的中心服务帮助合并新增的区块数据。就好像多个人同时编辑了一篇文章,发生了冲突,那就可以考虑由一个人整合大家需要修改和新增的内容,避免同时操作产生混乱。
解决欺诈问题
正常情况下,所有记录都可以直接合并。但是比如Alice在一家店购买了 1 个 iPhone,在另外一家店购买了 2 个 iPhone,这个时候 Alice 的钱就不够付款了。 或者说 Alice 想用 20000 块买 3 个 iPhone,她还想骗一个。
那么 Alice 最终就需要写这样的记录:
1 | from=A, to=B, price=10000, signature=alice的签名 |
无论 Alice 以什么顺序写入这些记录,她的钱都是不够的,因为她只有 20000 的余额。 这样简单地就解决了欺诈问题。
如果 Alice 想要修改自己的余额,那么 Alice 怎么做呢?
Alice 需要新增一个末端的节点,比如她在末端节点上将自己的余额修改为 999999。那么 Alice 的余额,就和之前 Block 中记录的冲突了。简单一查,就知道 Alice 在欺诈。如果 Alice 想要修改之前的某个节点的数据,这个节点的摘要签名就会发生变化了, 那么后面所有的节点就失效了。
比如 Alice 修改了 Block 9 的数据,并把整个区块链拷贝给 Bob。Bob 通过验证签名,就知道 Alice 在骗人。如果 Alice 修改了所有 Block 9 以后的 Block,相当于修改了完整的一个链条,且修改了所有的签名。Bob 只需要核对其中几个版本和其他人,或者和中心服务的签名的区别就知道 Alice 在欺诈。
刚才有一个设计,就是有一个中心平台供 Bob 下载。如果中心平台修改了数据。那么 Bob 会马上发现存在本地的和自己相关的数据与中心平台不一致。这样 Bob 就会联合其他用户一起抵制中心平台。
所以结论是,区块链一旦写入就不能修改,这样可以防止很多欺诈行为。
解决并发问题
假设全球有几十亿人都在下单。那么每次下单,需要创建新的一个 Block。这种情况,会导致最后面的 Block,开很多分支。
这个时候你会发现,这里有同步问题对不对? 最傻的方案就是用锁解决,比如用一个集中式的办法,去接收所有的请求,这样就又回到中心化的设计。
还有一个高明的办法,就是允许商家开分支。 用户和苹果店订合同,苹果店独立做一个分支,把用户的合同连起来。
这样苹果店自己先维护自己的 Block-Chain,等待合适的时机,再去合并到主分支上。 如果有合同合并不进去,比如余额不足,那再作废这个合同(不发货了)。
这里请你思考这样一种处理方式:如果全世界每天有 1000 亿笔订单要处理,那么可以先拆分成 100 个区域,每个区域是 10W 家店。这样最终每家店的平均并发量在 10000 单。 然后可以考虑每过多长时间,比如 10s,进行一次逐级合并。
这样,整体每个节点的压力就不是很大了。
并发问题也不仅仅是要解决并发问题,并发还伴随着一致性、可用性、欺诈及吞吐量等。一名优秀的架构师是需要储备多个维度的知识,所以还是我常常跟你强调的,知识在于积累,绝非朝夕之功。
除了上锁还有哪些并发控制方法?
这一讲我们介绍了基于乐观锁的版本控制,还介绍了区块链技术。另外还有一个名词,并不属于操作系统课程范畴,我也简单给你介绍下。处理并发还可以考虑 Lock-Free 数据结构。比如 Lock-Free 队列,是基于 cas 指令实现的,允许多个线程使用这个队列。再比如 ThreadLocal,让每个线程访问不同的资源,旨在用空间换时间,也是避免锁的一种方案。
线程调度都有哪些方法?
所谓调度,是一个制定计划的过程,放在线程调度背景下,就是操作系统如何决定未来执行哪些线程?
第一条是形形色色调度场景怎么来的?第二条是每个调度算法是如何工作的?
先到先服务
早期的操作系统是一个个处理作业(Job),比如很多保险业务,每处理一个称为一个作业(Job)。处理作业最容易想到的就是先到先服务(First Come First Service,FCFS),也就是先到的作业先被计算,后到的作业,排队进行。
这里需要用到一个叫作队列的数据结构,具有先入先出(First In First Out,FIFO)性质。先进入队列的作业,先处理,因此从公平性来说,这个算法非常朴素。另外,一个作业完全完成才会进入下一个作业,作业之间不会发生切换,从吞吐量上说,是最优的——因为没有额外开销。
但是这样对于等待作业的用户来说,是有问题的。比如一笔需要用时 1 天的作业 ,如果等待了 10 分钟,用户是可以接受的;一个用时 10 分钟的作业,用户等待一天就要投诉了。 因此如果用时 1 天的作业先到,用时 10 分钟的任务后到,应该优先处理用时少的,也就是短作业优先(Shortest Job First,SJF)。
短作业优先
通常会同时考虑到来顺序和作业预估时间的长短,比如下面的到来顺序和预估时间:
这样就会优先考虑第一个到来预估时间为 3 分钟的任务。 我们还可以从另外一个角度来审视短作业优先的优势,就是平均等待时间。
平均等待时间 = 总等待时间/任务数
上面例子中,如果按照 3,3,10 的顺序处理,平均等待时间是:(0 + 3 + 6) / 3 = 3 分钟。 如果按照 10,3,3 的顺序来处理,就是( 0+10+13 )/ 3 = 7.66 分钟。
平均等待时间和用户满意度是成反比的,等待时间越长,用户越不满意,因此在大多数情况下,应该优先处理用时少的,从而降低平均等待时长。
采用 FCFS 和 SJF 后,还有一些问题没有解决。
- 紧急任务如何插队?比如老板安排的任务。
- 等待太久的任务如何插队?比如用户等太久可能会投诉。
- 先执行的大任务导致后面来的小任务没有执行如何处理?比如先处理了一个 1 天才能完成的任务,工作半天后才发现预估时间 1 分钟的任务也到来了。
为了解决上面的问题,我们设计了两种方案, 一种是优先级队列(PriorityQueue),另一种是抢占(Preemption)。
优先级队列(PriorityQueue)
刚才提到老板安排的任务需要紧急插队,那么下一个作业是不是应该安排给老板?毫无疑问肯定是这样!那么如何控制这种优先级顺序呢?一种方法是用优先级队列。优先级队列可以给队列中每个元素一个优先级,优先级越高的任务就会被先执行。
优先级队列的一种实现方法就是用到了堆(Heap)这种数据结构,更最简单的实现方法,就是每次扫描一遍整个队列找到优先级最高的任务。也就是说,堆(Heap)可以帮助你在 O(1) 的时间复杂度内查找到最大优先级的元素。
比如老板的任务,就给一个更高的优先级。 而对于普通任务,可以在等待时间(W) 和预估执行时间(P) 中,找一个数学关系来描述。比如:优先级 = W/P。W 越大,或者 P 越小,就越排在前面。 当然还可以有很多其他的数学方法,利用对数计算,或者某种特别的分段函数。
这样,关于紧急任务如何插队?等待太久的任务如何插队?这两个问题我们都解决了,接下来我们来看先执行的大任务导致后面来的小任务没有执行的情况如何处理?
抢占
为了解决这个问题,我们需要用到抢占(Preemption)。
抢占就是把执行能力分时,分成时间片段。 让每个任务都执行一个时间片段。如果在时间片段内,任务完成,那么就调度下一个任务。如果任务没有执行完成,则中断任务,让任务重新排队,调度下一个任务。
拥有了抢占的能力,再结合之前我们提到的优先级队列能力,这就构成了一个基本的线程调度模型。线程相对于操作系统是排队到来的,操作系统为每个到来的线程分配一个优先级,然后把它们放入一个优先级队列中,优先级最高的线程下一个执行。
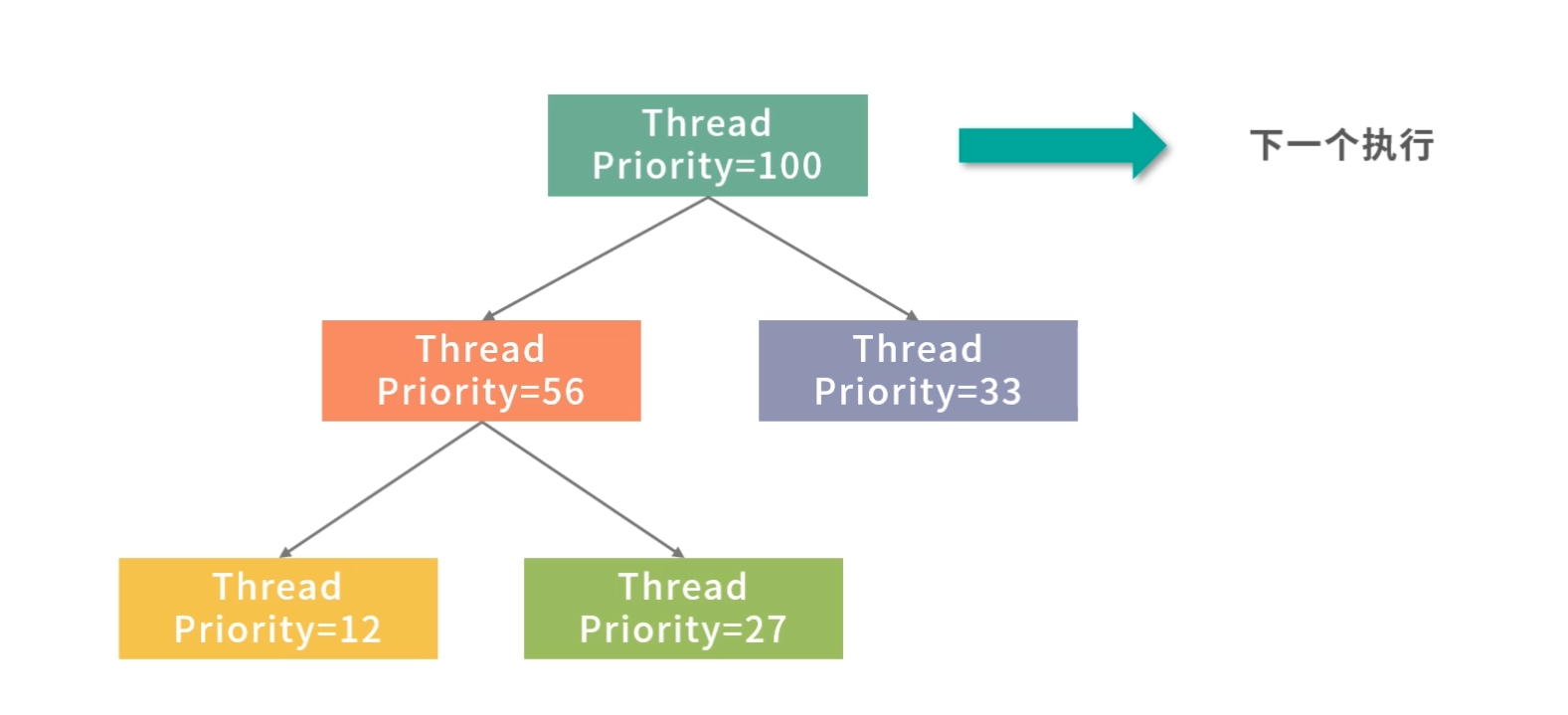
每个线程执行一个时间片段,然后每次执行完一个线程就执行一段调度程序。

图中用红色代表调度程序,其他颜色代表被调度线程的时间片段。调度程序可以考虑实现为一个单线程模型,这样不需要考虑竞争条件。
上面这个模型已经是一个非常优秀的方案了,但是还有一些问题可以进一步处理得更好。
- 如果一个线程优先级非常高,其实没必要再抢占,因为无论如何调度,下一个时间片段还是给它。那么这种情况如何实现?
- 如果希望实现最短作业优先的抢占,就必须知道每个线程的执行时间,而这个时间是不可预估的,那么这种情况又应该如何处理?
为了解决上面两个问题,我们可以考虑引入多级队列模型。
多级队列模型
多级队列,就是多个队列执行调度。 我们先考虑最简单的两级模型,如图:
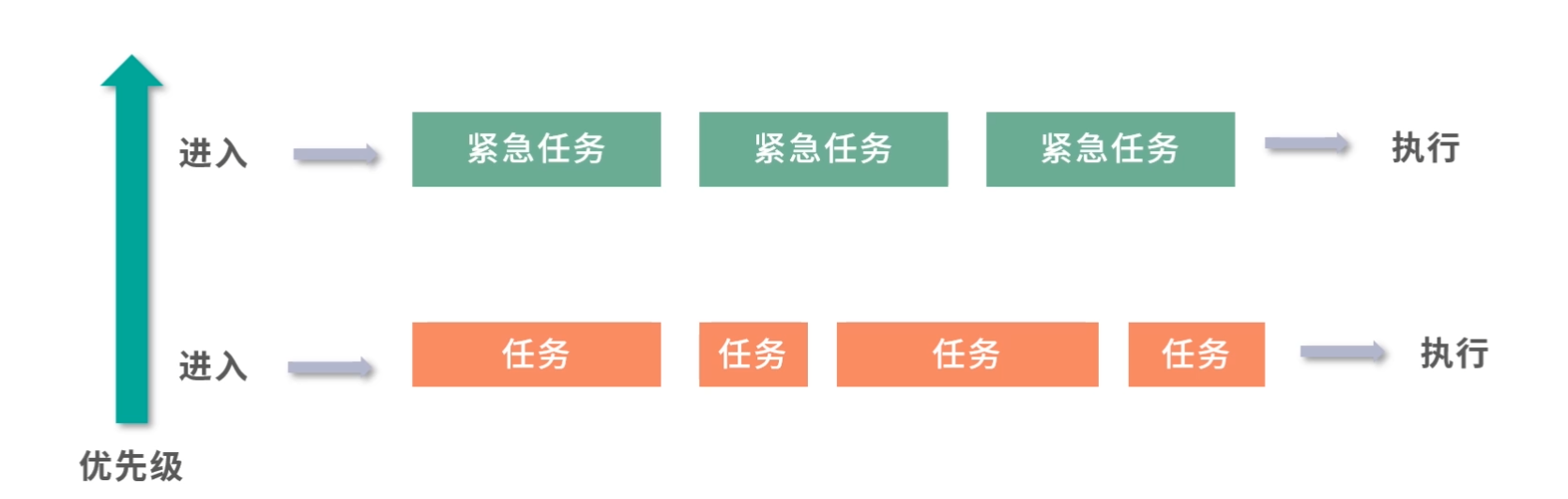
上图中设计了两个优先级不同的队列,从下到上优先级上升,上层队列调度紧急任务,下层队列调度普通任务。只要上层队列有任务,下层队列就会让出执行权限。
- 低优先级队列可以考虑抢占 + 优先级队列的方式实现,这样每次执行一个时间片段就可以判断一下高优先级的队列中是否有任务。
- 高优先级队列可以考虑用非抢占(每个任务执行完才执行下一个)+ 优先级队列实现,这样紧急任务优先级有个区分。如果遇到十万火急的情况,就可以优先处理这个任务。
上面这个模型虽然解决了任务间的优先级问题,但是还是没有解决短任务先行的问题。可以考虑再增加一些队列,让级别更多。比如下图这个模型:
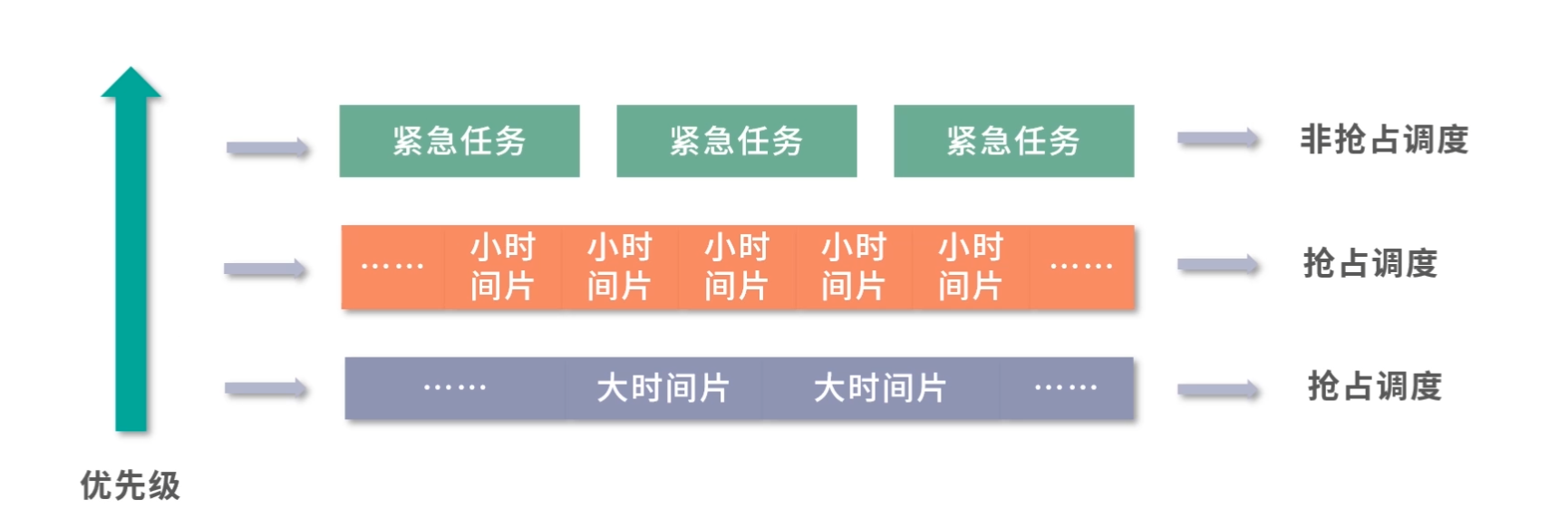
紧急任务仍然走高优队列,非抢占执行。普通任务先放到优先级仅次于高优任务的队列中,并且只分配很小的时间片;如果没有执行完成,说明任务不是很短,就将任务下调一层。下面一层,最低优先级的队列中时间片很大,长任务就有更大的时间片可以用。通过这种方式,短任务会在更高优先级的队列中执行完成,长任务优先级会下调,也就类似实现了最短作业优先的问题。
实际操作中,可以有 n 层,一层层把大任务筛选出来。 最长的任务,放到最闲的时间去执行。要知道,大部分时间 CPU 不是满负荷的。
线程调度都有哪些方法?
回答这个问题你要把握主线,千万不要教科书般的回答:任务调度分成抢占和非抢占的,抢占的可以轮流执行,也可以用优先级队列执行;非抢占可以先到先服务,也可以最短任务优先。
上面这种回答可以用来过普通的程序员岗位,但是面试官其实更希望听到你的见解,这是初中级开发人员与高级开发人员之间的差异。
比如你告诉面试官:非抢占的先到先服务的模型是最朴素的,公平性和吞吐量可以保证。但是因为希望减少用户的平均等待时间,操作系统往往需要实现抢占。操作系统实现抢占,仍然希望有优先级,希望有最短任务优先。
但是这里有个困难,操作系统无法预判每个任务的预估执行时间,就需要使用分级队列。最高优先级的任务可以考虑非抢占的优先级队列。 其他任务放到分级队列模型中执行,从最高优先级时间片段最小向最低优先级时间片段最大逐渐沉淀。这样就同时保证了小任务先行和高优任务最先执行。
什么情况下会触发饥饿和死锁?
读题可知,这道题目在提问“场景”,从表面来看,解题思路是列举几个例子。但是在回答这类面试题前你一定要想一想面试官在考察什么,往往在题目中看到“什么情况下”时,其实考察的是你总结和概括信息的能力。
关于上面这道题目,如果你只回答一个场景,而没有输出概括性的总结内容,就很容易被面试官认为对知识理解不到位,因而挂掉面试。另外,提问死锁和饥饿还有一个更深层的意思,就是考察你在实战中对并发控制算法的理解,是否具备设计并发算法来解决死锁问题并且兼顾性能(并发量)的思维和能力。
要学习这部分知识有一个非常不错的模型,就是哲学家就餐问题。1965 年,计算机科学家 Dijkstra 为了帮助学生更好地学习并发编程设计的一道练习题,后来逐渐成为大家广泛讨论的问题。
哲学家就餐问题
问题描述如下:有 5 个哲学家,围着一个圆桌就餐。圆桌上有 5 份意大利面和 5 份叉子。哲学家比较笨,他们必须拿到左手和右手的 2 个叉子才能吃面。哲学不饿的时候就在思考,饿了就去吃面,吃面的必须前提是拿到 2 个叉子,吃完面哲学家就去思考。

问题的抽象
接下来请你继续思考,我们对问题进行一些抽象,比如哲学是一个数组,编号 0~4。我这里用 Java 语言给你演示,哲学家是一个类,代码如下:
1 | static class Philosopher implements Runnable { |
这里考虑叉子也使用编号 0~4,代码如下:
1 | private static Integer[] forks; |
forks[i]的值等于 x,相当于编号为i的叉子被编号为 x 的哲学家拿起;如果等于-1,那么叉子目前放在桌子上。
我们经常需要描述左、右的关系,为了方便计算,可以设计 1 个帮助函数(helper functions),帮助我们根据一个编号,计算它左边的编号。
1 | private static int LEFT(int i) { |
假设和哲学家编号一致的叉子在右边,这样如果要判断编号为id哲学家是否可以吃面,需要这样做:
1 | if(forks[LEFT(id)] == id && forks[id] == id) { |
然后定义一个_take函数拿起编号为i叉子; 再设计一个_put方法放下叉子:
1 | void _take(int i) throws InterruptedException { |
forks[i]的值等于 x,相当于编号为i的叉子被编号为 x 的哲学家拿起;如果等于-1,那么叉子目前放在桌子上。
我们经常需要描述左、右的关系,为了方便计算,可以设计 1 个帮助函数(helper functions),帮助我们根据一个编号,计算它左边的编号。
1 | private static int LEFT(int i) { |
假设和哲学家编号一致的叉子在右边,这样如果要判断编号为id哲学家是否可以吃面,需要这样做:
1 | if(forks[LEFT(id)] == id && forks[id] == id) { |
然后定义一个_take函数拿起编号为i叉子; 再设计一个_put方法放下叉子:
1 | void _take(int i) throws InterruptedException { |
_take函数之所以会等待 10ms,是因为哲学家就餐问题的实际意义,是 I/O 处理的场景,拿起叉子好比读取磁盘,需要有一等的时间开销,这样思考才有意义。
然后是对think和eat两个方法的抽象。首先我封装了一个枚举类型,描述哲学家的状态,代码如下:
1 | enum PHIS { |
然后实现think方法,think方法不需要并发控制,但是这里用Thread.sleep模拟实际思考需要的开销,代码如下:
1 | void think() throws InterruptedException { |
最后是eat方法:
1 | void eat() throws InterruptedException { |
eat方法依赖于forks对象的锁,相当于eat方法这里会同步——因为这里有读取临界区操作做。Thread.sleep依然用于描述eat方法的时间开销。sleep方法没有放到synchronized内是因为在并发控制时,应该尽量较少锁的范围,这样可以增加更大的并发量。
以上,我们对问题进行了一个基本的抽象。接下来请你思考在什么情况会发生死锁?
死锁(DeadLock)和活锁(LiveLock)
首先,可以思考一种最简单的解法,每个哲学家用一个while循环表示,代码如下:
1 | while(true){ |
_take可以考虑阻塞,直到哲学家得到叉子。上面程序我们还没有进行并发控制,会发生竞争条件。 顺着这个思路,就可以想到加入并发控制,代码如下:
1 | while(true){ |
上面的并发控制,会发生死锁问题,大家可以思考这样一个时序,如果 5 个哲学家都同时通过synchronized(fork[LEFT(id)]),有可能会出现下面的情况:
- 第 0 个哲学家获得叉子 4,接下来请求叉子 0;
- 第 1 个哲学家获得叉子 0,接下来请求叉子 1;
- 第 2 个哲学家获得叉子 1,接下来请求叉子 2;
- 第 3 个哲学家获得叉子 2,接下来请求叉子 3;
- 第 4 个哲学家获得叉子 3,接下来请求叉子 4。
为了帮助你理解,这里我画了一幅图。
如上图所示,可以看到这是一种循环依赖的关系,在这种情况下所有哲学家都获得了一个叉子,并且在等待下一个叉子。这种等待永远不会结束,因为没有哲学家愿意放弃自己拿起的叉子。
以上这种情况称为死锁(Deadlock),这是一种饥饿(Starvation)的形式。从概念上说,死锁是线程间互相等待资源,但是没有一个线程可以进行下一步操作。饥饿就是因为某种原因导致线程得不到需要的资源,无法继续工作。死锁是饥饿的一种形式,因为循环等待无法得到资源。哲学家就餐问题,会形成一种环状的死锁(循环依赖), 因此非常具有代表性。
死锁有 4 个基本条件。
- 资源存在互斥逻辑:每次只有一个线程可以抢占到资源。这里是哲学家抢占叉子。
- 持有等待:这里哲学家会一直等待拿到叉子。
- 禁止抢占:如果拿不到资源一直会处于等待状态,而不会释放已经拥有的资源。
- 循环等待:这里哲学家们会循环等待彼此的叉子。
刚才提到死锁也是一种饥饿(Starvation)的形式,饥饿比较简单,就是线程长期拿不到需要的资源,无法进行下一步操作。
要解决死锁的问题,可以考虑哲学家拿起 1 个叉子后,如果迟迟没有等到下一个叉子,就放弃这次操作。比如 Java 的 Lock Interface 中,提供的tryLock方法,就可以实现定时获取:
1 | var lock = new ReentrantLock(); |
Java 提供的这个能力是拿不到锁,就报异常,并可以依据这个能力开发释放已获得资源的能力。
但是这样,我们会碰到一个叫作活锁(LiveLock)的问题。LiveLock 也是一种饥饿。可能在某个时刻,所有哲学及都拿起了左手的叉子,然后发现右手的叉子拿不到,就放下了左手的叉子——如此周而复始,这就是一种活锁。所有线程都在工作,但是没有线程能够进一步——解决问题。
在实际工作场景下,LiveLock 可以靠概率解决,因为同时拿起,又同时放下这种情况不会很多。实际工作场景很多系统,确实依赖于这个问题不频发。但是,优秀的设计者不能把系统设计依托在一个有概率风险的操作上,因此我们需要继续往深一层思考。
解决方案
其实解决上述问题有很多的方案,最简单、最直观的方法如下:
1 | while(true){ |
上面这段程序同时只允许一个哲学家使用所有资源,我们用synchronized构造了一种排队的逻辑。而哲学家,每次必须拿起所有的叉子,吃完,再到下一哲学家。 这样并发度是 1,同时最多有一个线程在执行。 这样的方式可以完成任务,但是性能太差。
另一种方法是规定拿起过程必须同时拿起,放下过程也同时放下,代码如下:
1 | while(true){ |
上面这段程序,think函数没有并发控制,一个哲学家要么拿起两个叉子,要么不拿起,这样并发度最高为 2(最多有两个线程同时执行)。而且,这个算法中只有一个锁,因此不存在死锁和饥饿问题。
到这里,我们已经对这个问题有了一个初步的方案,那么如何进一步优化呢?
思考和最终方案
整个问题复杂度的核心在于哲学家拿起叉子是有成本的。好比线程读取磁盘,需要消耗时间。哲学家的思考,是独立的。好比读取了磁盘数据,进行计算。那么有没有办法允许 5 个哲学家都同时去拿叉子呢?这样并发度是最高的。
经过初步思考,马上会发现这里有环状依赖, 会出现死锁。 原因就是如果 5 个哲学家同时拿叉子,那就意味着有的哲学家必须要放弃叉子。但是如果不放下会出现什么情况呢?
假设当一个哲学家发现自己拿不到两个叉子的时候,他去和另一个哲学家沟通把自己的叉子给对方。这样就相当于,有一个转让方法。相比于磁盘 I/O,转让内存中的数据成本就低的多了。 我们假设有这样一个转让的方法,代码如下:
1 | void _transfer(int fork, int philosopher) { |
这个方法相当于把叉子转让给另一个哲学家,这里你先不用管上面代码中的 dirty,后文中会讲到。而获取叉子的过程,我们可以进行调整,代码如下:
1 | void take(int i) throws InterruptedException { |
这里我们把每个叉子看作一个锁,有多少个叉子,就有多少个锁,相当于同时可以拿起 5 个叉子(并发度是 5)。如果当前没有人拿起叉子,那么可以自己拿起。 如果叉子属于其他哲学家,就需要判断对方的状态。只要对方不在EATING,就可以考虑转让叉子。
最后是对 LiveLock 的思考,为了避免叉子在两个哲学家之间来回转让,我们为每个叉子增加了一个dirty属性。一开始叉子的dirty是true,每次转让后,哲学家会把自己的叉子擦干净给另一个哲学家。转让的前置条件是叉子是dirty的,所以叉子在两个哲学家之间只会转让一次。
通过上面算法,我们就可以避免死锁、饥饿以及提高读取数据(获取叉子)的并发度。最后完整的程序如下,给你做参考:
1 | package test; |
什么情况下会触发饥饿和死锁?
【解析】 线程需要资源没有拿到,无法进行下一步,就是饥饿。死锁(Deadlock)和活锁(Livelock)都是饥饿的一种形式。 非抢占的系统中,互斥的资源获取,形成循环依赖就会产生死锁。死锁发生后,如果利用抢占解决,导致资源频繁被转让,有一定概率触发活锁。死锁、活锁,都可以通过设计并发控制算法解决,比如哲学家就餐问题。
进程间通信都有哪些方法?
在上一讲中,我们提到过,凡是面试官问“什么情况下”的时候,面试官实际想听的是你经过理解,整理得到的认知。回答应该是概括的、简要的。而不是真的去列举每一种 case。
另外,面试官考察进程间通信,有一个非常重要的意义——进程间通信是架构复杂系统的基石。复杂系统往往是分成各种子系统、子模块、微服务等等,按照 Unix 的设计哲学,系统的每个部分应该是稳定、独立、简单有效,而且强大的。系统本身各个模块就像人的器官,可以协同工作。而这个协同的枢纽,就是我们今天的主题——进程间通信。
什么是进程间通信?
进程间通信(Intermediate Process Communication,IPC)。所谓通信就是交换数据。所以,狭义地说,就是操作系统创建的进程们之间在交换数据。 我们今天不仅讨论狭义的通信,还要讨论 IPC 更广泛的意义——程序间的通信。 程序可以是进程,可以是线程,可以是一个进程的两个部分(进程自己发送给自己),也可以是分布式的——总之,今天讨论的是广义的交换数据。
管道
之前我们在“07 | 进程、重定向和管道指令:xargs 指令的作用是?”中讲解过管道和命名管道。 管道提供了一种非常重要的能力,就是组织计算。进程不用知道有管道存在,因此管道的设计是非侵入的。程序员可以先着重在程序本身的设计,只需要预留响应管道的接口,就可以利用管道的能力。比如用shell执行MySQL语句,可能会这样:
1 | 进程1 | 进程2 | 进程3 | mysql -u... -p | 爬虫进程 |
我们可以由进程 1、进程 2、进程 3 计算出 MySQL 需要的语句,然后直接通过管道执行。MySQL经过计算将结果传给一个爬虫进程,爬虫就开始工作。MySQL并不是设计用于管道,爬虫进程也不是设计专门用于管道,只是程序员恰巧发现可以这样用,完美地解决了自己的问题,比如:用管道构建一个微型爬虫然后把结果入库。
我们还学过一个词叫作命名管道。命名管道并没有改变管道的用法。相比匿名管道,命名管道提供了更多的编程手段。比如:
1 | 进程1 > namedpipe |
上面的程序将两个进程的临时结果都同时重定向到 namedpipe,相当于把内容合并了再找机会处理。再比如说,你的进程要不断查询本地的 MySQL,也可以考虑用命名管道将查询传递给 MySQL,再用另一个命名管道传递回来。这样可以省去和 localhost 建立 TCP 3 次握手的时间。 当然,现在数据库都是远程的了,这里只是一个例子。
管道的核心是不侵入、灵活,不会增加程序设计负担,又能组织复杂的计算过程。
本地内存共享
同一个进程的多个线程本身是共享进程内存的。 这种情况不需要特别考虑共享内存。如果是跨进程的线程(或者理解为跨进程的程序),可以考虑使用共享内存。内存共享是现代操作系统提供的能力, Unix 系操作系统,包括 Linux 中有 POSIX 内存共享库——shmem。(如果你感兴趣可以参考网页中的内容,这里不做太深入地分析。)Linux 内存共享库的实现原理是以虚拟文件系统的形式,从内存中划分出一块区域,供两个进程共同使用。看上去是文件,实际操作是内存。
共享内存的方式,速度很快,但是程序不是很好写,因为这是一种侵入式的开发,也就是说你需要为此撰写大量的程序。比如如果修改共享内存中的值,需要调用 API。如果考虑并发控制,还要处理同步问题等。因此,只要不是高性能场景,进程间通信通常不考虑共享内存的方式。
本地消息/队列
内存共享不太好用,因此本地消息有两种常见的方法。一种是用消息队列——现代操作系统都会提供类似的能力。Unix 系可以使用 POSIX 标准的 mqueue。另一种方式,就是直接用网络请求,比如 TCP/IP 协议,也包括建立在这之上的更多的通信协议(这些我们在下文中的“远程调用”部分详细讲解)。
本质上,这些都是收/发消息的模式。进程将需要传递的数据封装成格式确定的消息,这对写程序非常有帮助。程序员可以根据消息类型,分门别类响应消息;也可以根据消息内容,触发特殊的逻辑操作。在消息体量庞大的情况下,也可以构造生产者队列和消费者队列,用并发技术进行处理。
远程调用
远程调用(Remote Procedure Call,RPC)是一种通过本地程序调用来封装远程服务请求的方法。
程序员调用 RPC 的时候,程序看上去是在调用一个本地的方法,或者执行一个本地的任务,但是后面会有一个服务程序(通常称为 stub),将这种本地调用转换成远程网络请求。 同理,服务端接到请求后,也会有一个服务端程序(stub),将请求转换为一个真实的服务端方法调用。
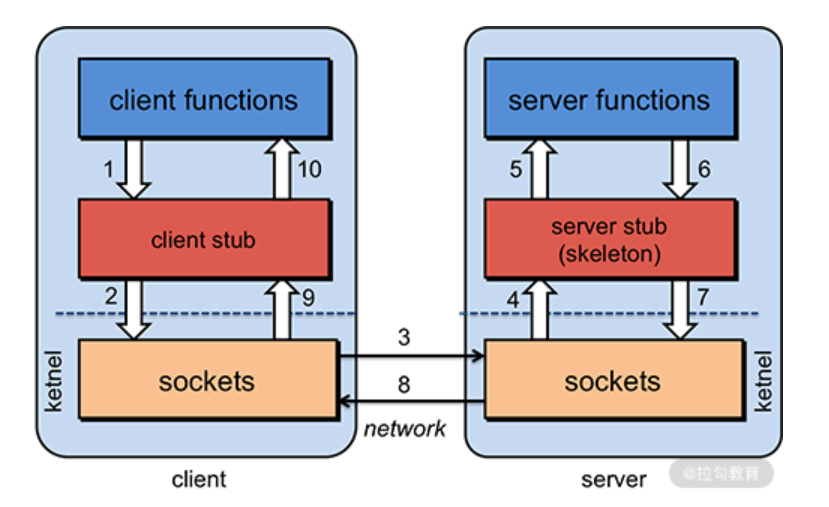
你可以观察上面这张图,表示客户端和服务端通信的过程,一共是 10 个步骤,分别是:
- 客户端调用函数(方法);
- stub 将函数调用封装为请求;
- 客户端 socket 发送请求,服务端 socket 接收请求;
- 服务端 stub 处理请求,将请求还原为函数调用;
- 执行服务端方法;
- 返回结果传给 stub;
- stub 将返回结果封装为返回数据;
- 服务端 socket 发送返回数据,客户端 socket 接收返回数据;
- 客户端 socket 将数据传递给客户端 stub;
- 客户端 stub 把返回数据转义成函数返回值。
RPC 调用过程有很多约定, 比如函数参数格式、返回结果格式、异常如何处理。还有很多细粒度的问题,比如处理 TCP 粘包、处理网络异常、I/O 模式选型——其中有很多和网络相关的知识比较复杂,你可以参考我将在拉勾教育上线的《计算机网络》专栏。
上面这些问题比较棘手,因此在实战中通常的做法是使用框架。比如 Thrift 框架(Facebook 开源)、Dubbo 框架(阿里开源)、grpc(Google 开源)。这些 RPC 框架通常支持多种语言,这需要一个接口定义语言支持在多个语言间定义接口(IDL)。
RPC 调用的方式比较适合微服务环境的开发,当然 RPC 通常需要专业团队的框架以支持高并发、低延迟的场景。不过,硬要说 RPC 有额外转化数据的开销(主要是序列化),也没错,但这不是 RPC 的主要缺点。RPC 真正的缺陷是增加了系统间的耦合。当系统主动调用另一个系统的方法时,就意味着在增加两个系统的耦合。长期增加 RPC 调用,会让系统的边界逐渐腐化。这才是使用 RPC 时真正需要注意的东西。
进程间通信都有哪些方法?
【解析】 你可以从单机和分布式角度给面试管阐述。
- 如果考虑单机模型,有管道、内存共享、消息队列。这三个模型中,内存共享程序最难写,但是性能最高。管道程序最好写,有标准接口。消息队列程序也比较好写,比如用发布/订阅模式实现具体的程序。
- 如果考虑分布式模型,就有远程调用、消息队列和网络请求。直接发送网络请求程序不好写,不如直接用实现好的 RPC 调用框架。RPC 框架会增加系统的耦合,可以考虑 消息队列,以及发布订阅事件的模式,这样可以减少系统间的耦合。
服务应该开多少个进程、多少个线程?
计算密集型和 I/O 密集型
通常我们会遇到两种任务,一种是计算、一种是 I/O。
计算,就是利用 CPU 处理算数运算。比如深度神经网络(Deep Neural Networks),需要大量的计算来计算神经元的激活和传播。再比如,根据营销规则计算订单价格,虽然每一个订单只需要少量的计算,但是在并发高的时候,所有订单累计加起来就需要大量计算。如果一个应用的主要开销在计算上,我们称为计算密集型。
再看看 I/O 密集型,I/O 本质是对设备的读写。读取键盘的输入是 I/O,读取磁盘(SSD)的数据是 I/O。通常 CPU 在设备 I/O 的过程中会去做其他的事情,当 I/O 完成,设备会给 CPU 一个中断,告诉 CPU 响应 I/O 的结果。比如说从硬盘读取数据完成了,那么硬盘给 CPU 一个中断。如果操作对 I/O 的依赖强,比如频繁的文件操作(写日志、读写数据库等),可以看作I/O 密集型。
你可能会有一个疑问,读取硬盘数据到内存中这个过程,CPU 需不需要一个个字节处理?
通常是不用的,因为在今天的计算机中有一个叫作 Direct Memory Access(DMA)的模块,这个模块允许硬件设备直接通过 DMA 写内存,而不需要通过 CPU(占用 CPU 资源)。
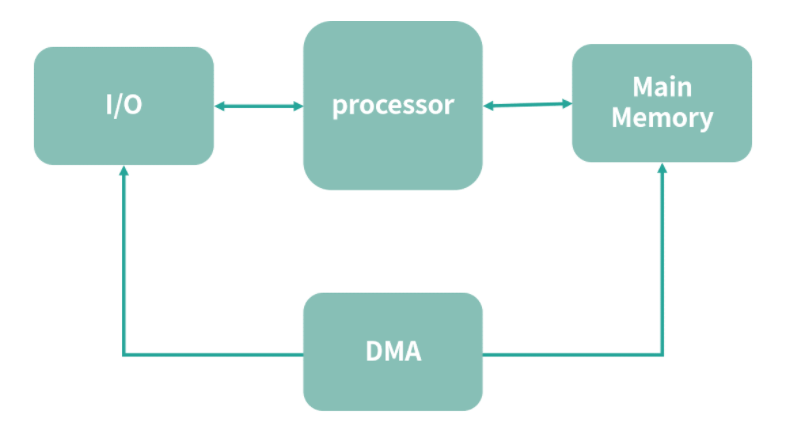
很多情况下我们没法使用 DMA,比如说你想把一个数组拷贝到另一个数组内,执行的 memcpy 函数内部实现就是一个个 byte 拷贝,这种情况也是一种CPU 密集的操作。
可见,区分是计算密集型还是 I/O 密集型这件事比较复杂。按说查询数据库是一件 I/O 密集型的事情,但是如果存储设备足够好,比如用了最好的固态硬盘阵列,I/O 速度很快,反而瓶颈会在计算上(对缓存的搜索耗时成为主要部分)。因此,需要一些可衡量指标,来帮助我们确认应用的特性。
衡量 CPU 的工作情况的指标
我们先来看一下 CPU 关联的指标。如下图所示:CPU 有 2 种状态,忙碌和空闲。此外,CPU 的时间还有一种被偷走的情况。
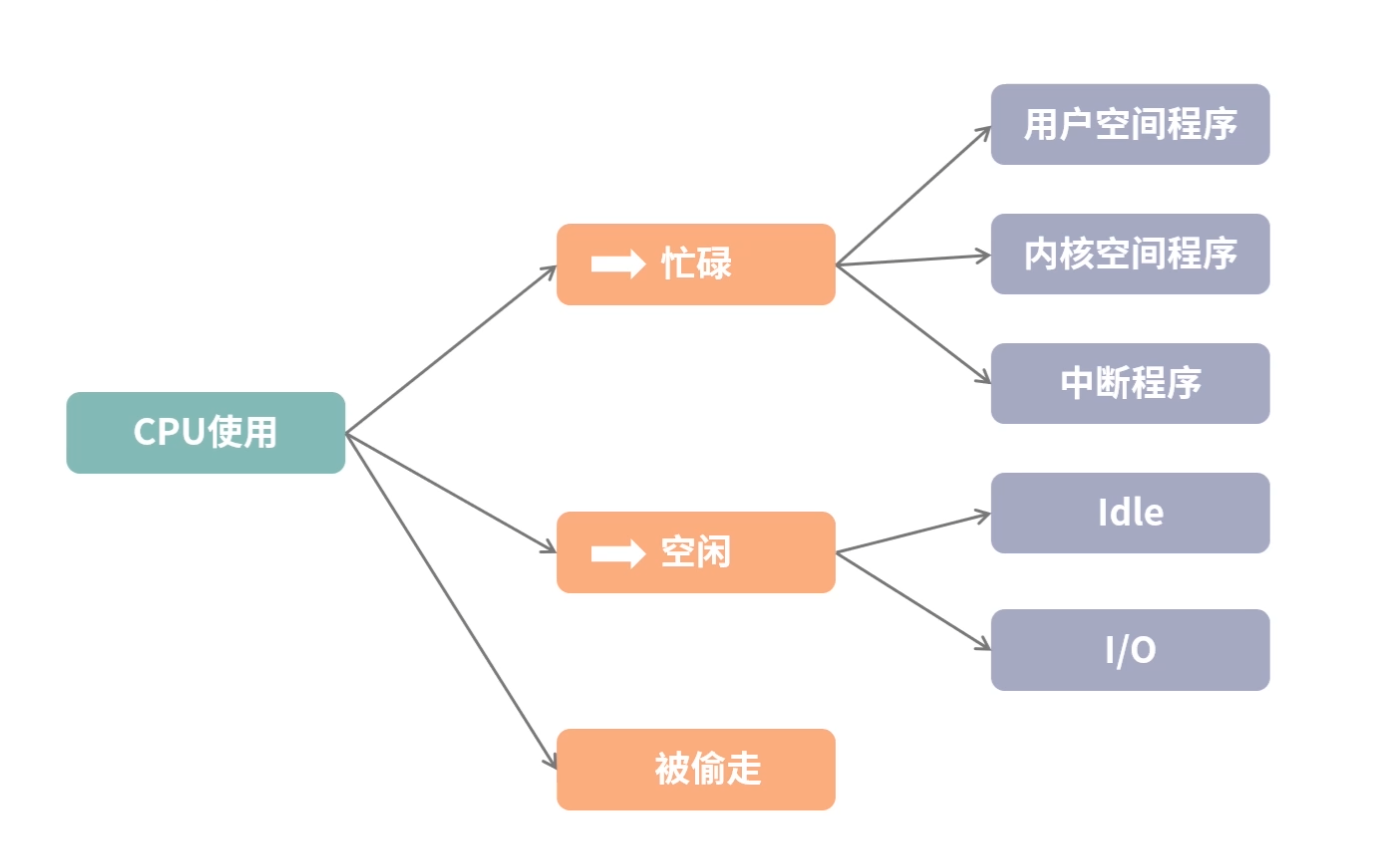
忙碌就是 CPU 在执行有意义的程序,空闲就是 CPU 在执行让 CPU 空闲(空转)的指令。通常让 CPU 空转的指令能耗更低,因此让 CPU 闲置时,我们会使用特别的指令,最终效果和让 CPU 计算是一样的,都可以把 CPU 执行时间填满,只不过这类型指令能耗低一些而已。除了忙碌和空闲,CPU 的时间有可能被宿主偷走,比如一台宿主机器上有 10 个虚拟机,宿主可以偷走给任何一台虚拟机的时间。
如上图所示,CPU 忙碌有 3 种情况:
- 执行用户空间程序;
- 执行内核空间程序;
- 执行中断程序。
CPU 空闲有 2 种情况。
- CPU 无事可做,执行空闲指令(注意,不能让 CPU 停止工作,而是执行能耗更低的空闲指令)。
- CPU 因为需要等待 I/O 而空闲,比如在等待磁盘回传数据的中断,这种我们称为 I/O Wait。
下图是我们执行 top 指令看到目前机器状态的快照,接下来我们仔细研究一下这些指标的含义:

如上图所示,你可以细看下 %CPU(s) 开头那一行(第 3 行):
- us(user),即用户空间 CPU 使用占比。
- sy(system),即内核空间 CPU 使用占比。
- ni(nice),nice 是 Unix 系操作系统控制进程优先级用的。-19 是最高优先级, 20 是最低优先级。这里代表了调整过优先级的进程的 CPU 使用占比。
- id(idle),闲置的 CPU 占比。
- wa(I/O Wait),I/O Wait 闲置的 CPU 占比。
- hi(hardware interrupts),响应硬件中断 CPU 使用占比。
- si(software interrrupts),响应软件中断 CPU 使用占比。
- st(stolen),如果当前机器是虚拟机,这个指标代表了宿主偷走的 CPU 时间占比。对于一个宿主多个虚拟机的情况,宿主可以偷走任何一台虚拟机的 CPU 时间。
上面我们用 top 看的是一个平均情况,如果想看所有 CPU 的情况可以 top 之后,按一下1键。结果如下图所示:
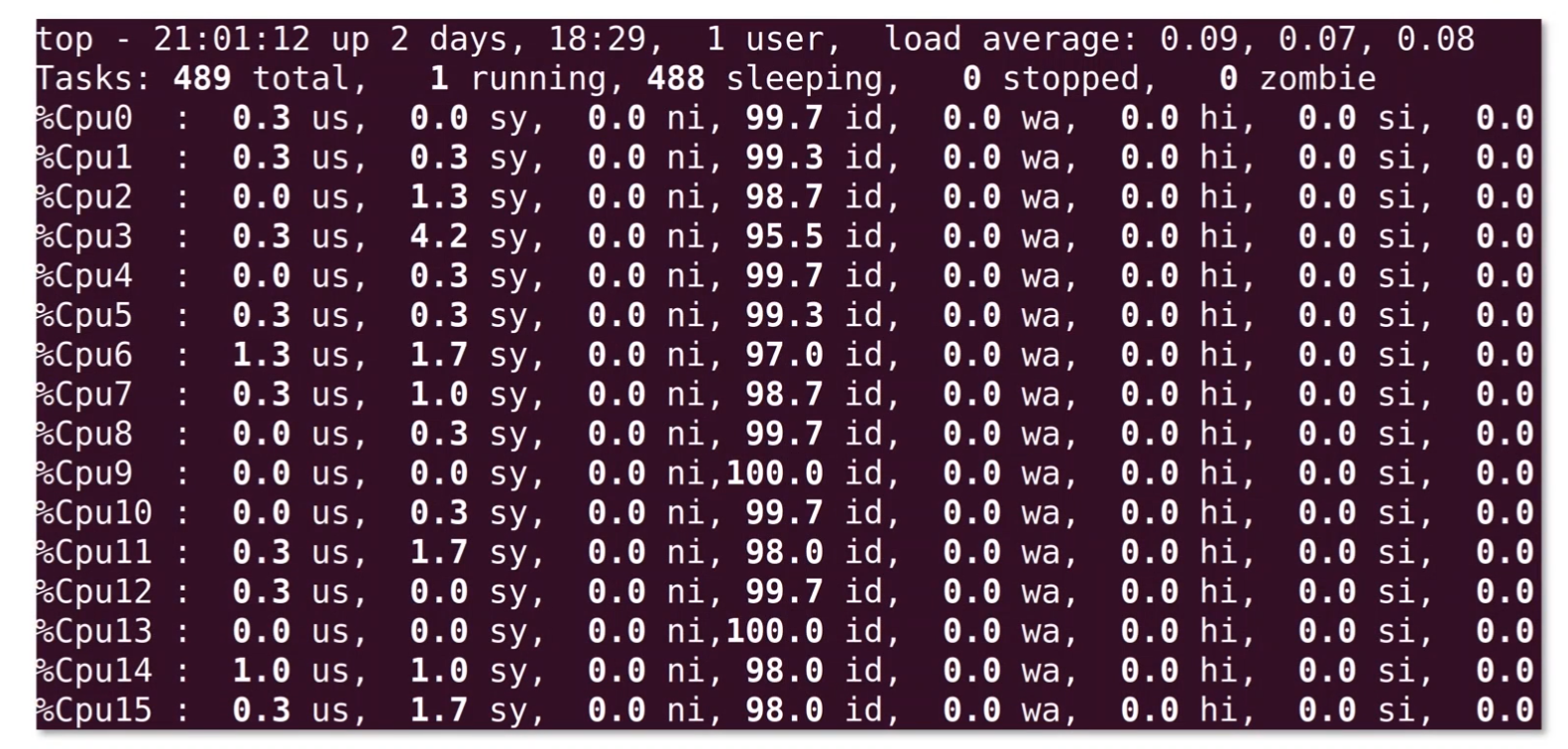
当然,对性能而言,CPU 数量也是一个重要因素。可以看到我这台虚拟机一共有 16 个核心。
负载指标
上面的指标非常多,在排查问题的时候,需要综合分析。其实还有一些更简单的指标,比如上图中 top 指令返回有一项叫作load average——平均负载。 负载可以理解成某个时刻正在排队执行的进程数除以 CPU 核数。平均负载需要多次采样求平均值。 如果这个值大于1,说明 CPU 相当忙碌。因此如果你想发现问题,可以先检查这个指标。
具体来说,如果平均负载很高,CPU 的 I/O Wait 也很高, 那么就说明 CPU 因为需要大量等待 I/O 无法处理完成工作。产生这个现象的原因可能是:线上服务器打日志太频繁,读写数据库、网络太频繁。你可以考虑进行批量读写优化。
到这里,你可能会有一个疑问:为什么批量更快呢?我们知道一次写入 1M 的数据,就比写一百万次一个 byte 快。因为前者可以充分利用 CPU 的缓存、复用发起写操作程序的连接和缓冲区等。
如果想看更多load average,你可以看/proc/loadavg文件。
通信量(Traffic)
如果怀疑瓶颈发生在网络层面,或者想知道当前网络状况。可以查看/proc/net/dev,下图是在我的虚拟机上的查询结果:

我们来一起看一下上图中的指标。表头分成了 3 段:
- Interface(网络接口),可以理解成网卡
- Receive:接收的数据
- Transmit:发送的数据
然后再来看具体的一些参数:
- byte 是字节数
- package 是封包数
- erros 是错误数
- drop 是主动丢弃的封包,比如说时间窗口超时了
- fifo: FIFO 缓冲区错误(如果想了解更多可以关注我即将推出的《计算机网络》专栏)
- frame: 底层网络发生了帧错误,代表数据出错了
如果你怀疑自己系统的网络有故障,可以查一下通信量部分的参数,相信会有一定的收获。
衡量磁盘工作情况
有时候 I/O 太频繁导致磁盘负载成为瓶颈,这个时候可以用iotop指令看一下磁盘的情况,如图所示:
上图中是磁盘当前的读写速度以及排行较靠前的进程情况。
另外,如果磁盘空间不足,可以用df指令:
其实 df 是按照挂载的文件系统计算空间。图中每一个条目都是一个文件系统。有的文件系统直接挂在了一个磁盘上,比如图中的/dev/sda5挂在了/上,因此这样可以看到各个磁盘的使用情况。
如果想知道更细粒度的磁盘 I/O 情况,可以查看/proc/diskstats文件。 这里有 20 多个指标我就不细讲了,如果你将来怀疑自己系统的 I/O 有问题,可以查看这个文件,并阅读相关手册。
监控平台
Linux 中有很多指令可以查看服务器当前的状态,有 CPU、I/O、通信、Nginx 等维度。如果去记忆每个指令自己搭建监控平台,会非常复杂。这里你可以用市面上别人写好的开源系统帮助你收集这些资料。 比如 Taobao System Activity Report(tsar)就是一款非常好用的工具。它集成了大量诸如上面我们使用的工具,并且帮助你定时收集服务器情况,还能记录成日志。你可以用 logstash 等工具,及时将日志收集到监控、分析服务中,比如用 ELK 技术栈。
决定进程/线程数量
最后我们讲讲如何决定线程、进程数量。 上面观察指标是我们必须做的一件事情,通过观察上面的指标,可以对我们开发的应用有一个基本的认识。
下面请你思考一个问题:如果线程或进程数量 = CPU 核数,是不是一个好的选择?
有的应用不提供线程,比如 PHP 和 Node.js。
Node.js 内部有一个事件循环模型,这个模型可以理解成协程(Coroutine),相当于大量的协程复用一个进程,可以达到比线程池更高的效率(减少了线程切换)。PHP 模型相对则差得多。Java 是一个多线程的模型,线程和内核线程对应比 1:1;Go 有轻量级线程,多个轻量级线程复用一个内核级线程。
以 Node.js 为例,如果现在是 8 个核心,那么开 8 个 Node 进程,是不是就是最有效利用 CPU 的方案呢? 乍一看——8 个核、8 个进程,每个进程都可以使用 1 个核,CPU 利用率很高——其实不然。 你不要忘记,CPU 中会有一部分闲置时间是 I/O Wait,这个时候 CPU 什么也不做,主要时间用于等待 I/O。
假设我们应用执行的期间只用 50% CPU 的执行时间,其他 50% 是 I/O Wait。那么 1 个 CPU 同时就可以执行两个进程/线程。
我们考虑一个更一般的模型,如果你的应用平均 I/O 时间占比是 P,假设现在内存中有 n 个这样的线程,那么 CPU 的利用率是多少呢?
假设我们观察到一个应用 (进程),I/O 时间占比是 P,那么可以认为这个进程等待 I/O 的概率是 P。那么如果有 n 个这样的线程,n 个线程都在等待 I/O 的概率是Pn。而满负荷下,CPU 的利用率就是 CPU 不能空转——也就是不能所有进程都在等待 I/O。因此 CPU 利用率 = 1 -Pn。
理论上,如果 P = 50%,两个这样的进程可以达到满负荷。 但是从实际出发,何时运行线程是一个分时的调度行为,实际的 CPU 利用率还要看开了多少个这样的线程,如果是 2 个,那么还是会有一部分闲置资源。
因此在实际工作中,开的线程、进程数往往是超过 CPU 核数的。你可能会问,具体是多少最好呢?——这里没有具体的算法,要以实际情况为准。比如:你先以 CPU 核数 3 倍的线程数开始,然后进行模拟真实线上压力的测试,分析压测的结果。
- 如果发现整个过程中,瓶颈在 CPU,比如
load average很高,那么可以考虑优化 I/O Wait,让 CPU 有更多时间计算。 - 当然,如果 I/O Wait 优化不动了,算法都最优了,就是磁盘读写速度很高达到瓶颈,可以考虑延迟写、延迟读等等技术,或者优化减少读写。
- 如果发现 idle 很高,CPU 大面积闲置,就可以考虑增加线程。
我的服务应该开多少个进程、多少个线程?
【解析】 计算密集型一般接近核数,如果负载很高,建议留一个内核专门给操作系统。I/O 密集型一般都会开大于核数的线程和进程。 但是无论哪种模型,都需要实地压测,以压测结果分析为准;另一方面,还需要做好监控,观察服务在不同并发场景的情况,避免资源耗尽。
然后具体语言的特性也要考虑,Node.js 每个进程内部实现了大量类似协程的执行单元,因此 Node.js 即便在 I/O 密集型场景下也可以考虑长期使用核数 -1 的进程模型。而 Java 是多线程模型,线程池通常要大于核数才能充分利用 CPU 资源。
所以核心就一句,眼见为实,上线前要进行压力测试。
相关面试题


如果考虑到 CPU 缓存的存在,会对上面我们讨论的算法有什么影响?
这是一道需要大家查一些资料的题目。这里涉及一个叫作内存一致性模型的概念。具体就是说,在同一时刻,多线程之间,对内存中某个地址的数据认知是否一致(简单理解,就是多个线程读取同一个内存地址能不能读到一致的值)。
对某个地址,和任意时刻,如果所有线程读取值,得到的结果都一样,是一种强一致性,我们称为线性一致性(Sequencial Consistency),含义就是所有线程对这个地址中数据的历史达成了一致,历史没有分差,有一条大家都能认可的主线,因此称为线性一致。 如果只有部分时刻所有线程的理解是一致的,那么称为弱一致性(Weak Consistency)。
那么为什么会有内存不一致问题呢? 这就是因为 CPU 缓存的存在。
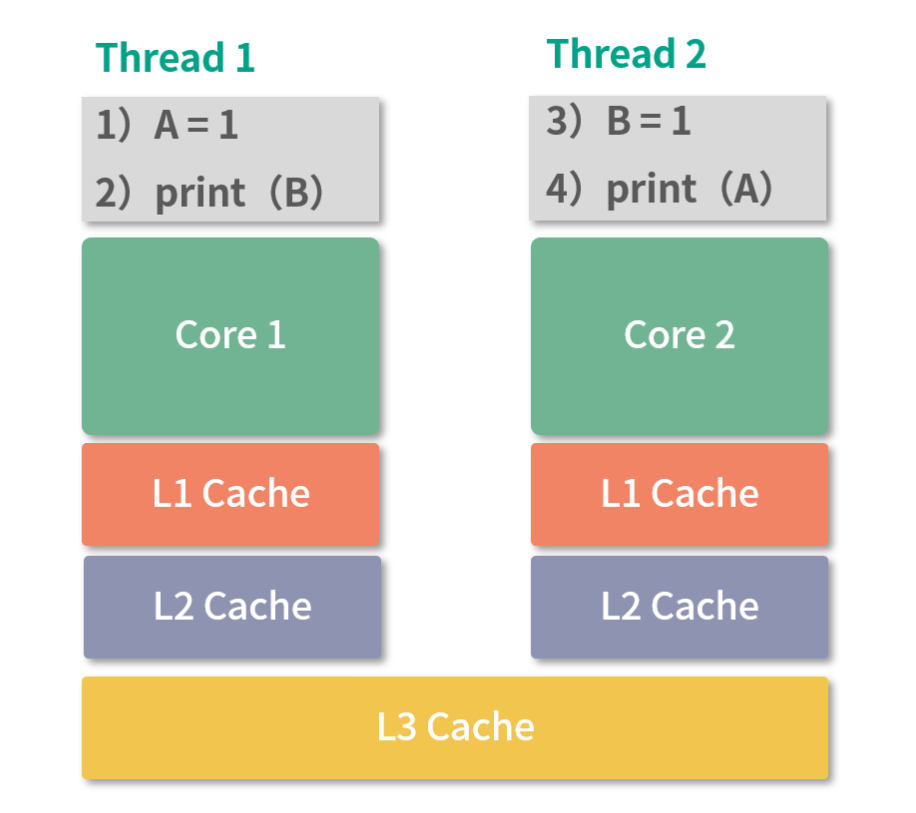
如上图所示:假设一开始 A=0,B=0。两个不在同一个 CPU 核心执行的 Thread1、Thread2 分别执行上图中的简单程序。在 CPU 架构中,Thread1,Thread2 在不同核心,因此它们的 L1\L2 缓存不共用, L3 缓存共享。
在这种情况下,如果 Thread1 发生了写入 A=1,这个时候会按照 L1,L2,L3 的顺序写入缓存,最后写内存。而对于 Thread2 而言,在 Thread1 刚刚发生写入时,如果去读取 A 的值,就需要去内存中读,这个时候 A=1 可能还没有写入内存。但是对于线程 1 来说,它只要发生了写入 A=1,就可以从 L1 缓存中读取到这次写入。所以在线程 1 写入 A=1 的瞬间,线程 1 线程 2 无法对 A 的值达成一致,造成内存不一致。这个结果会导致 print 出来的 A 和 B 结果不确定,可能是 0 也可能是 1,取决于具体线程执行的时机。
考虑一个锁变量,和 cas 上锁操作,代码如下:
1 | int lock = 0 |
上述程序构成了一个简单的自旋锁(spin-lock)。如果考虑到内存一致性模型,线程 1 通过 cas 操作将 lock 从 0 置 1。这个操作会先发生在线程所在 CPU 的 L1 缓存中。cas 函数通过底层 CPU 指令保证了原子性,cas 执行完成之前,线程 2 的 cas 无法执行。当线程 1 开始临界区的时候,假设这个时候线程 2 开始执行,尝试获取锁。如果这个过程切换非常短暂,线程 2 可能会从内存中读取 lock 的值(而这个值可能还没有写入,还在 Thread 所在 CPU 的 L1、L2 中),线程 2 可能也会通过 cas 拿到锁。两个线程同时进入了临界区,造成竞争条件。
这个时候,就需要强制让线程 2的读取指令一定等到写入指令彻底完成之后再执行,避免使用 CPU 缓存。Java 提供了一个 volatile 关键字实现这个能力,只需要这样:
1 | volatile int lock = 0; |
就可以避免从读取不到对lock的写入问题。
举例各 2 个悲观锁和乐观锁的应用场景?
乐观锁、悲观锁都能够实现避免竞争条件,实现数据的一致性。 比如减少库存的操作,无论是乐观锁、还是悲观锁都能保证最后库存算对(一致性)。 但是对于并发减库存的各方来说,体验是不一样的。悲观锁要求各方排队等待。 乐观锁,希望各方先各自进步。所以进步耗时较长,合并耗时较短的应用,比较适合乐观锁。 比如协同创作(写文章、视频编辑、写程序等),协同编辑(比如共同点餐、修改购物车、共同编辑商品、分布式配置管理等),非常适合乐观锁,因为这些操作需要较长的时间进步(比如写文章要思考、配置管理可能会连续修改多个配置)。乐观锁可以让多个协同方不急于合并自己的版本,可以先 focus 在进步上。
相反,悲观锁适用在进步耗时较短的场景,比如锁库存刚好是进步(一次库存计算)耗时少的场景。这种场景使用乐观锁,不但没有足够的收益,同时还会导致各个等待方(线程、客户端等)频繁读取库存——而且还会面临缓存一致性的问题(类比内存一致性问题)。这种进步耗时短,频繁同步的场景,可以考虑用悲观锁。类似的还有银行的交易,订单修改状态等。
再比如抢购逻辑,就不适合乐观锁。抢购逻辑使用乐观锁会导致大量线程频繁读取缓存确认版本(类似 cas 自旋锁),这种情况下,不如用队列(悲观锁实现)。
综上:有一个误区就是悲观锁对冲突持有悲观态度,所以性能低;乐观锁,对冲突持有乐观态度,鼓励线程进步,因此性能高。 这个不能一概而论,要看具体的场景。最后补充一下,悲观锁性能最高的一种实现就是阻塞队列,你可以参考 Java 的 7 种继承于 BlockingQueue 阻塞队列类型。

用你最熟悉的语言模拟分级队列调度的模型?
我用 Java 实现了一个简单的 yield 框架。 没有到协程的级别,但是也初具规模。考虑到协程实现需要更复杂一些,所以我用 PriorityQueue 来放高优任务;然后我用 LinkedList 来作为放普通任务的队列。Java 语言中的add和remove方法刚好构成了入队和出队操作。
1 | private PriorityQueue<Task> urgents; |
我实现了一个submit方法用于提交任务,代码如下:
1 | var scheduler = new MultiLevelScheduler(); |
普通任务我的程序中默认是 3 级队列。提交的任务优先级小于 100 的会放入紧急队列。每个任务就是一个简单的函数。我构造了一个 next() 方法用于决定下一个执行的任务,代码如下:
1 | private Task next(){ |
先判断高优队列,然后再逐级看普通队列。
执行的程序就是递归调用 runNext() 方法,代码如下:
1 | private void runNext(){ |
上面程序中,如果当前任务在yield状态,那么终止当前程序。yield相当于函数调用,从yield函数调用中返回相当于继续执行。yield相当于任务主动让出执行时间。使用yield模式不需要线程切换,可以最大程度利用单核效率。
最后是yield的实现,nextTask.run 后面的匿名函数就是yield方法,它像一个调度程序一样,先简单保存当前的状态,然后将当前任务放到对应的位置(重新入队,或者移动到下一级队列)。如果当前任务是高优任务,yield程序会直接返回,因为高优任务没有必要yield,代码如下:
1 | nextTask.run(() -> { |
下面是完成的程序,你可以在自己的 IDE 中尝试。
1 | package test; |
最后是执行结果如下:
Most Urgent
Urgent
A1
B
C
A2
Process finished with exit code 0
我们看到结果中任务 1 发生了yield在打印 A2 之前交出了控制权导致任务 B,C 先被执行。如果你想在 yield 出上增加定时的功能,可以考虑 yield 发生后将任务移出队列,并在定时结束后重新插入回来。
什么情况下会触发饥饿和死锁?
如果哲学家就餐问题拿起叉子、放下叉子,只需要微小的时间,主要时间开销集中在 think 需要计算资源(CPU 资源)上,那么使用什么模型比较合适?
哲学家就餐问题最多允许两组哲学家就餐,如果开销集中在计算上,那么只要同时有两组哲学家可以进入临界区即可。不考虑 I/O 成本,问题就很简化了,也失去了讨论的意义。比如简单要求哲学家们同时拿起左右手的叉子的做法就可以达到 2 组哲学家同时进餐。
还有哪些我没有讲到的进程间通信方法?
我看到有同学提到了 Android 系统的 OpenBinder 机制——允许不同进程的线程间调用(类似 RPC)。底层是 Linux 的文件系统和内核对 Binder 的驱动。
我还有没讲到的进程间的通信方法,比如说:
- 使用数据库
- 使用普通文件
- 还有一种是信号,一个进程可以通过操作系统提供的信号。举个例子,假如想给某个进程(pid=9999)发送一个 USR1 信号,那么可以用:
1 | kill -s USR1 9999 |
进程 9999 可以通过写程序接收这个信号。 上述过程除了用kill指令外,还可以调用操作系统 API 完成。
如果磁盘坏了,通常会是怎样的情况?
磁盘如果彻底坏了,服务器可能执行程序报错,无法写入,甚至死机。这些情况非常容易发现。而比较不容易观察的是坏道,坏道是磁盘上某个小区域数据无法读写了。有可能是硬损坏,就是物理损坏了,相当于永久损坏。也有可能是软损坏,比如数据写乱了。导致磁盘坏道的原因很多,比如电压不稳、灰尘、磁盘质量等问题。
磁盘损坏之前,往往还伴随性能整体的下降;坏道也会导致读写错误。所以在出现问题前,通常是可以在监控系统中观察到服务器性能指标变化的。比如 CPU 使用量上升,I/O Wait 增多,相同并发量下响应速度变慢等。
如果在工作中你怀疑磁盘坏了,可以用下面这个命令检查坏道:
1 | sudo badblocks -v /dev/sda5 |
我的机器上是 /dev/sda5,你可以用df命令查看自己的文件系统。
一个程序最多能使用多少内存?
为什么内存不够用?
总体来说,虚拟化技术是为了解决内存不够用的问题
历史上有过不少的解决方案,但最终沉淀下的是虚拟化技术。接下来我为你介绍一种历史上存在过的 Swap 技术以及虚拟化技术。
交换(Swap)技术
Swap 技术允许一部分进程使用内存,不使用内存的进程数据先保存在磁盘上。注意,这里提到的数据,是完整的进程数据,包括正文段(程序指令)、数据段、堆栈段等。轮到某个进程执行的时候,尝试为这个进程在内存中找到一块空闲的区域。如果空间不足,就考虑把没有在执行的进程交换(Swap)到磁盘上,把空间腾挪出来给需要的进程。
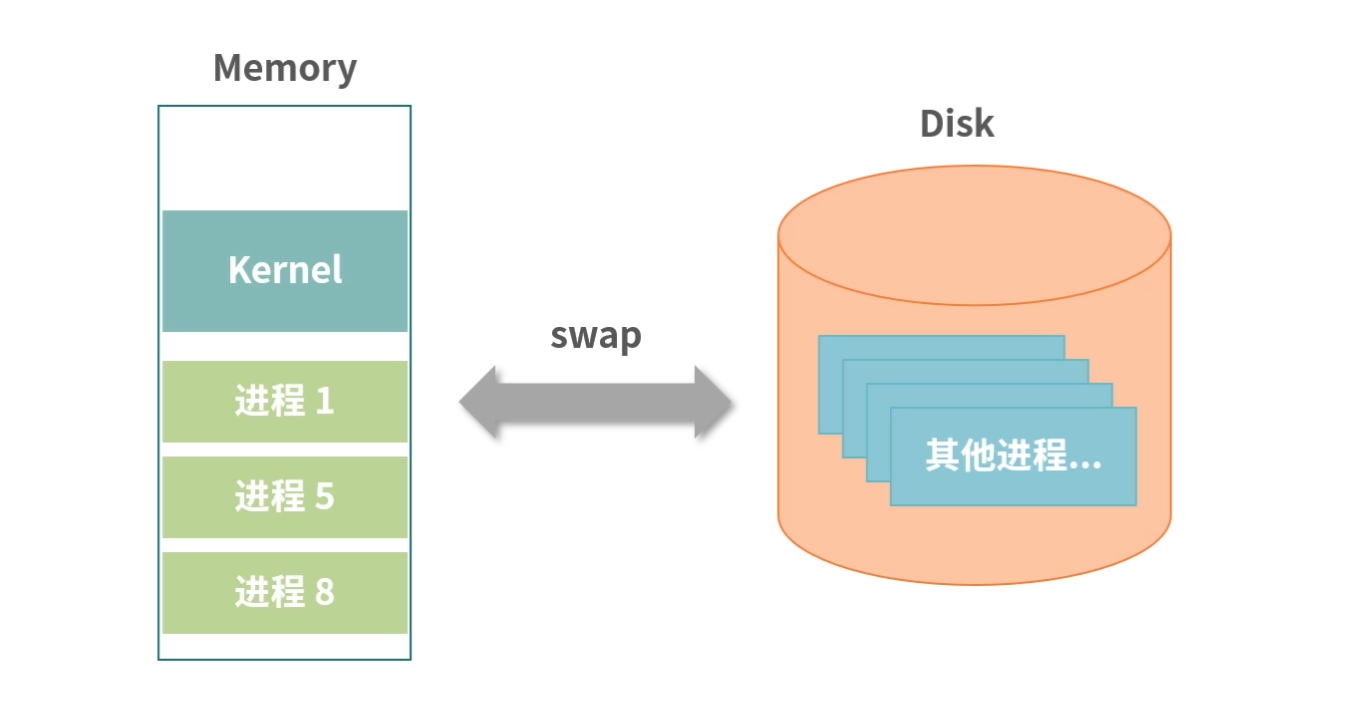
上图中,内存被拆分成多个区域。 内核作为一个程序也需要自己的内存。另外每个进程独立得到一个空间——我们称为地址空间(Address Space)。你可以认为地址空间是一块连续分配的内存块。每个进程在不同地址空间中工作,构成了一个原始的虚拟化技术。
比如:当进程 A 想访问地址 100 的时候,实际上访问的地址是基于地址空间本身位置(首字节地址)计算出来的。另外,当进程 A 执行时,CPU 中会保存它地址空间的开始位置和结束位置,当它想访问超过地址空间容量的地址时,CPU 会检查然后报错。
上图描述的这种方法,是一种比较原始的虚拟化技术,进程使用的是基于地址空间的虚拟地址。但是这种方案有很多明显的缺陷,比如:
- 碎片问题:上图中我们看到进程来回分配、回收交换,内存之间会产生很多缝隙。经过反反复复使用,内存的情况会变得十分复杂,导致整体性能下降。
- 频繁切换问题:如果进程过多,内存较小,会频繁触发交换。
你可以先思考这两个问题的解决方案,接下来我会带你进行一些更深入地思考——首先重新 Review 下我们的设计目标。
- 隔离:每个应用有自己的地址空间,互不影响。
- 性能:高频使用的数据保留在内存中、低频使用的数据持久化到磁盘上。
- 程序好写(降低程序员心智负担):让程序员不用关心底层设施。
现阶段,Swap 技术已经初步解决了问题 1。关于问题 2,Swap 技术在性能上存在着碎片、频繁切换等明显劣势。关于问题 3,使用 Swap 技术,程序员需要清楚地知道自己的应用用多少内存,并且小心翼翼地使用内存,避免需要重新申请,或者研发不断扩容的算法——这让程序心智负担较大。
经过以上分析,需要更好的解决方案,就是我们接下来要学习的虚拟化技术。
虚拟内存
虚拟化技术中,操作系统设计了虚拟内存(理论上可以无限大的空间),受限于 CPU 的处理能力,通常 64bit CPU,就是 264 个地址。
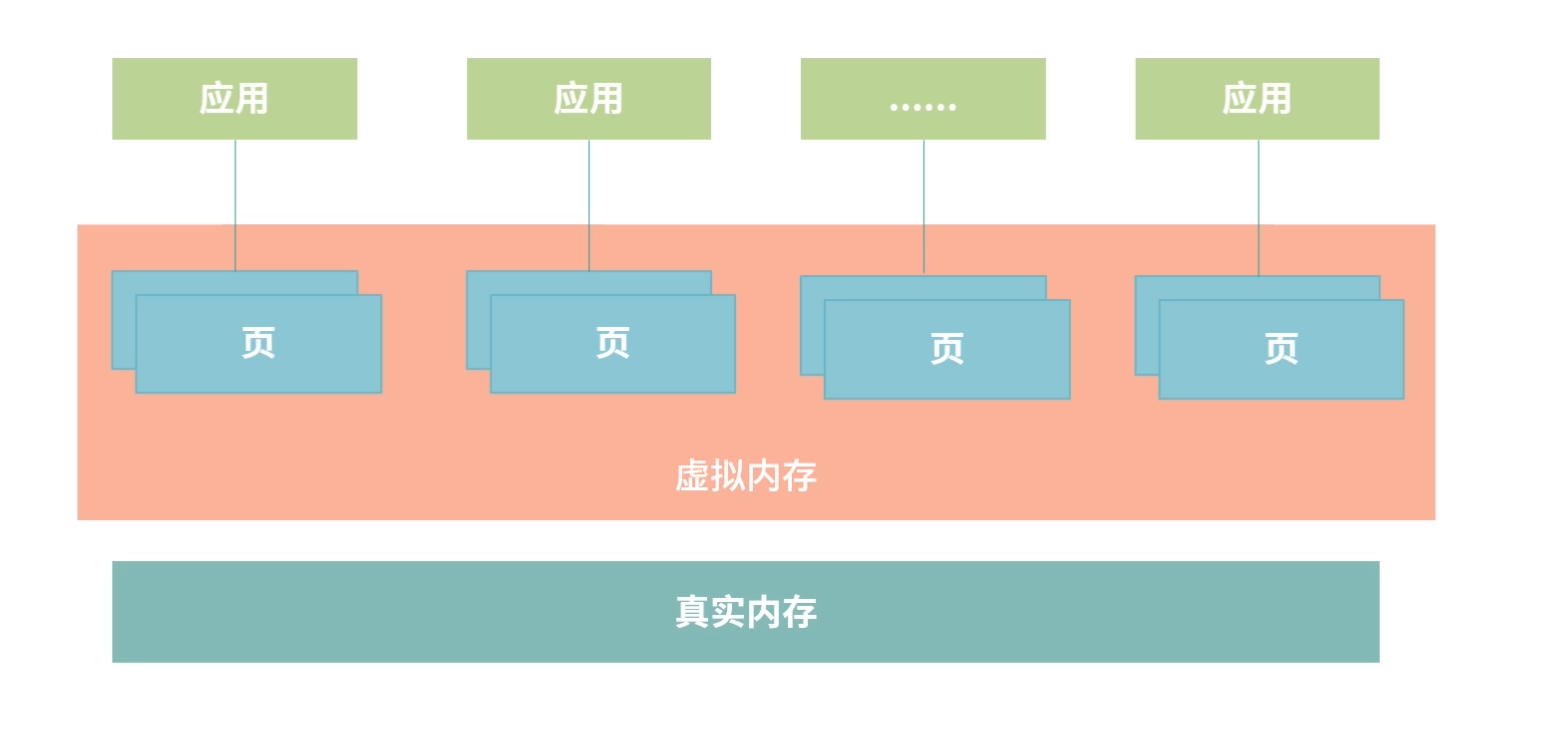
虚拟化技术中,应用使用的是虚拟内存,操作系统管理虚拟内存和真实内存之间的映射。操作系统将虚拟内存分成整齐小块,每个小块称为一个页(Page)。之所以这样做,原因主要有以下两个方面。
一方面应用使用内存是以页为单位,整齐的页能够避免内存碎片问题。
另一方面,每个应用都有高频使用的数据和低频使用的数据。这样做,操作系统就不必从应用角度去思考哪个进程是高频的,仅需思考哪些页被高频使用、哪些页被低频使用。如果是低频使用,就将它们保存到硬盘上;如果是高频使用,就让它们保留在真实内存中。
如果一个应用需要非常大的内存,应用申请的是虚拟内存中的很多个页,真实内存不一定需要够用。
页(Page)和页表
接下来,我们详细讨论下这个设计。操作系统将虚拟内存分块,每个小块称为一个页(Page);真实内存也需要分块,每个小块我们称为一个 Frame。Page 到 Frame 的映射,需要一种叫作页表的结构。
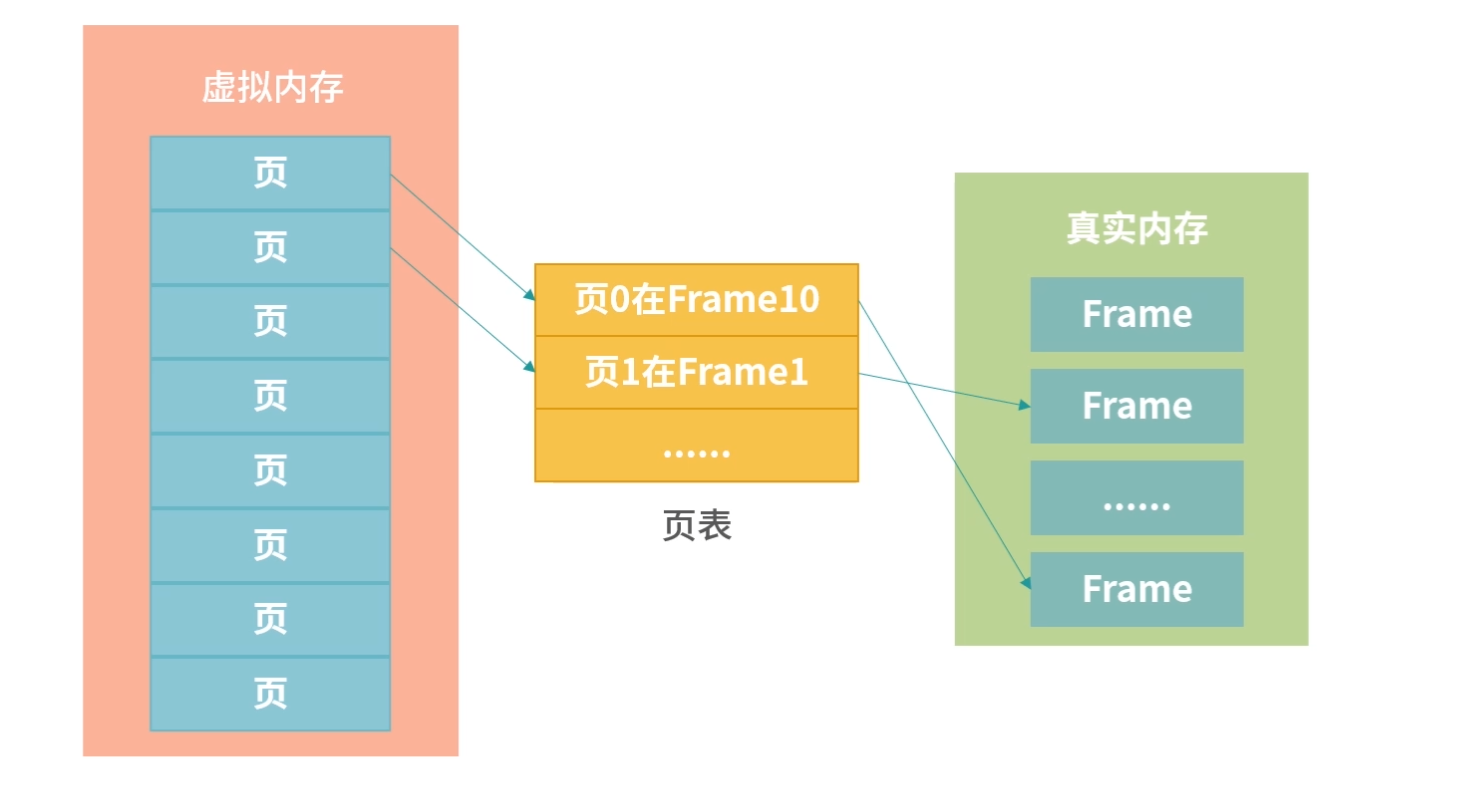
上图展示了 Page、Frame 和页表 (PageTable)三者之间的关系。 Page 大小和 Frame 大小通常相等,页表中记录的某个 Page 对应的 Frame 编号。页表也需要存储空间,比如虚拟内存大小为 10G, Page 大小是 4K,那么需要 10G/4K = 2621440 个条目。如果每个条目是 64bit,那么一共需要 20480K = 20M 页表。操作系统在内存中划分出小块区域给页表,并负责维护页表。
页表维护了虚拟地址到真实地址的映射。每次程序使用内存时,需要把虚拟内存地址换算成物理内存地址,换算过程分为以下 3 个步骤:
- 通过虚拟地址计算 Page 编号;
- 查页表,根据 Page 编号,找到 Frame 编号;
- 将虚拟地址换算成物理地址。
下面我通过一个例子给你讲解上面这个换算的过程:如果页大小是 4K,假设程序要访问地址:100,000。那么计算过程如下。
- 页编号(Page Number) = 100,000/4096 = 24 余1619。 24 是页编号,1619 是地址偏移量(Offset)。
- 查询页表,得到 24 关联的 Frame 编号(假设查到 Frame 编号 = 10)。
- 换算:通常 Frame 和 Page 大小相等,替换 Page Number 为 Frame Number 物理地址 = 4096 * 10 + 1619 = 42579。
MMU
上面的过程发生在 CPU 中一个小型的设备——内存管理单元(Memory Management Unit, MMU)中。如下图所示:
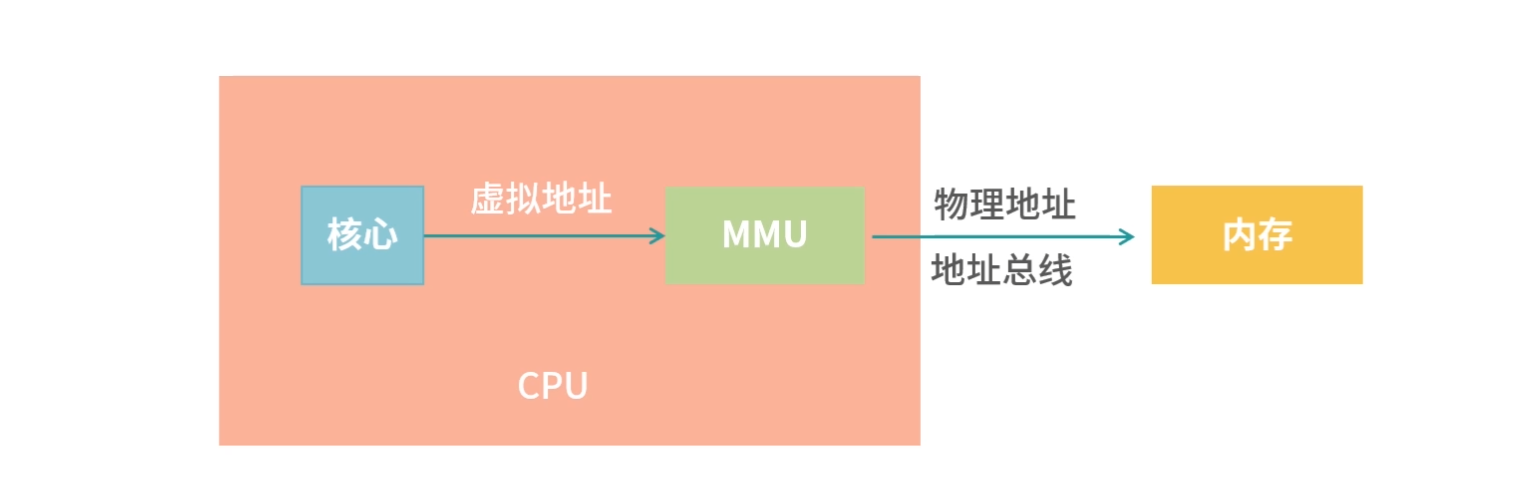
当 CPU 需要执行一条指令时,如果指令中涉及内存读写操作,CPU 会把虚拟地址给 MMU,MMU 自动完成虚拟地址到真实地址的计算;然后,MMU 连接了地址总线,帮助 CPU 操作真实地址。
这样的设计,就不需要在编写应用程序的时候担心虚拟地址到物理地址映射的问题。我们把全部难题都丢给了操作系统——操作系统要确定MMU 可以读懂自己的页表格式。所以,操作系统的设计者要看 MMU 的说明书完成工作。
难点在于不同 CPU 的 MMU 可能是不同的,因此这里会遇到很多跨平台的问题。解决跨平台问题不但有繁重的工作量,更需要高超的编程技巧,Unix 最初期的移植性(跨平台)是 C 语言作者丹尼斯·里奇实现的。
学到这里,细心的同学可能会有疑问:MMU 需要查询页表(这是内存操作),而 CPU 执行一条指令通过 MMU 获取内存数据,难道可以容忍在执行一条指令的过程中,发生多次内存读取(查询)操作?难道一次普通的读取操作,还要附加几次查询页表的开销吗?当然不是,这里还有一些高速缓存的设计,这部分我们放到“25 讲”中详细讨论。
页表条目
上面我们笼统介绍了页表将 Page 映射到 Frame。那么,页表中的每一项(页表条目)长什么样子呢?下图是一个页表格式的一个演示。
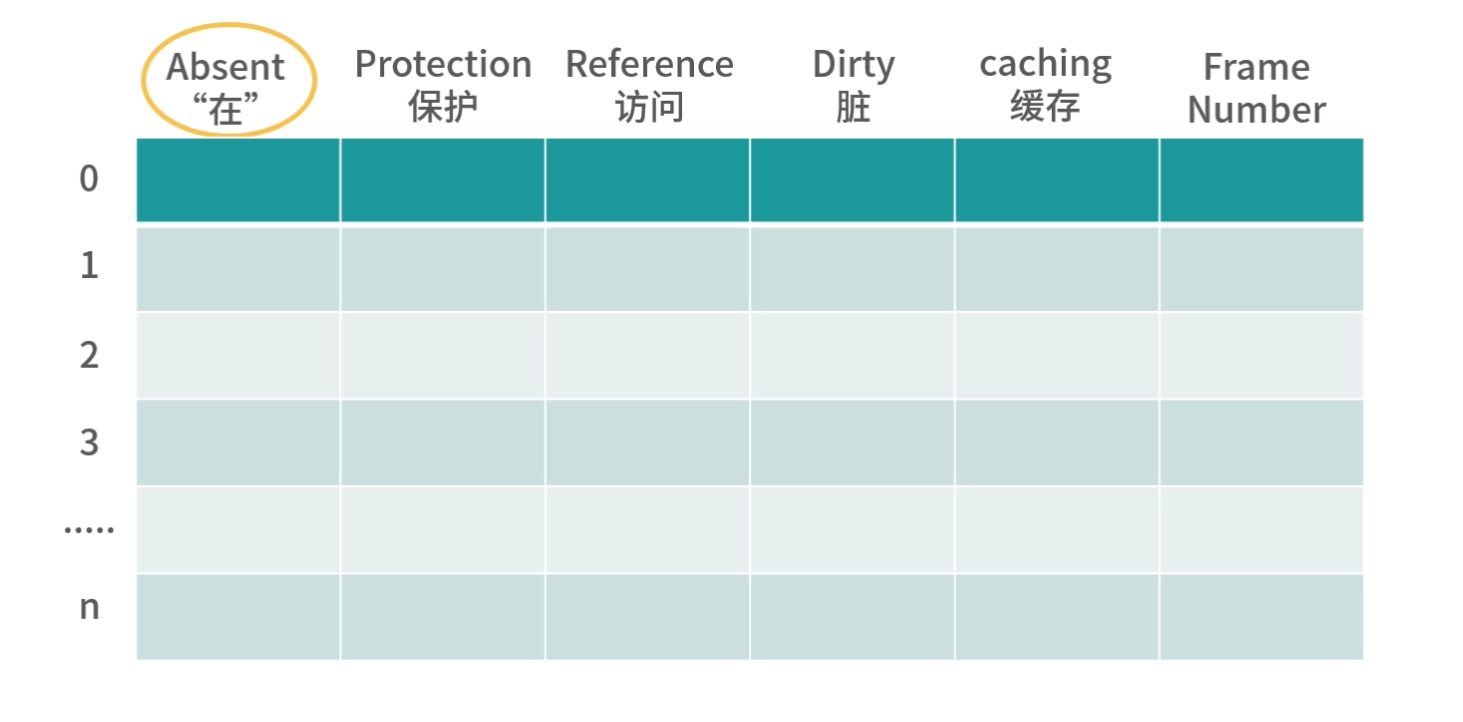
页表条目本身的编号可以不存在页表中,而是通过偏移量计算。 比如地址 100,000 的编号,可以用 100,000 除以页大小确定。
- Absent(“在”)位,是一个 bit。0 表示页的数据在磁盘中(不再内存中),1 表示在内存中。如果读取页表发现 Absent = 0,那么会触发缺页中断,去磁盘读取数据。
- Protection(保护)字段可以实现成 3 个 bit,它决定页表用于读、写、执行。比如 000 代表什么都不能做,100 代表只读等。
- Reference(访问)位,代表这个页被读写过,这个记录对回收内存有帮助。
- Dirty(“脏”)位,代表页的内容被修改过,如果 Dirty =1,那么意味着页面必须回写到磁盘上才能置换(Swap)。如果 Dirty = 0,如果需要回收这个页,可以考虑直接丢弃它(什么也不做,其他程序可以直接覆盖)。
- Caching(缓存位),描述页可不可以被 CPU 缓存。CPU 缓存会造成内存不一致问题,在上个模块的加餐中我们讨论了内存一致性问题,具体你可以参考“模块四”的加餐内容。
- Frame Number(Frame 编号),这个是真实内存的位置。用 Frame 编号乘以页大小,就可以得到 Frame 的基地址。
在 64bit 的系统中,考虑到 Absent、Protection 等字段需要占用一定的位,因此不能将 64bit 都用来描述真实地址。但是 64bit 可以寻址的空间已经远远超过了 EB 的级别(1EB = 220TB),这已经足够了。在真实世界,我们还造不出这么大的内存呢。
大页面问题
最后,我们讨论一下大页面的问题。假设有一个应用,初始化后需要 12M 内存,操作系统页大小是 4K。那么应该如何设计呢?
为了简化模型,下图中,假设这个应用只有 3 个区域(3 个段)——正文段(程序)、数据段(常量、全局变量)、堆栈段。一开始我们 3 个段都分配了 4M 的空间。随着程序执行,堆栈段的空间会继续增加,上不封顶。
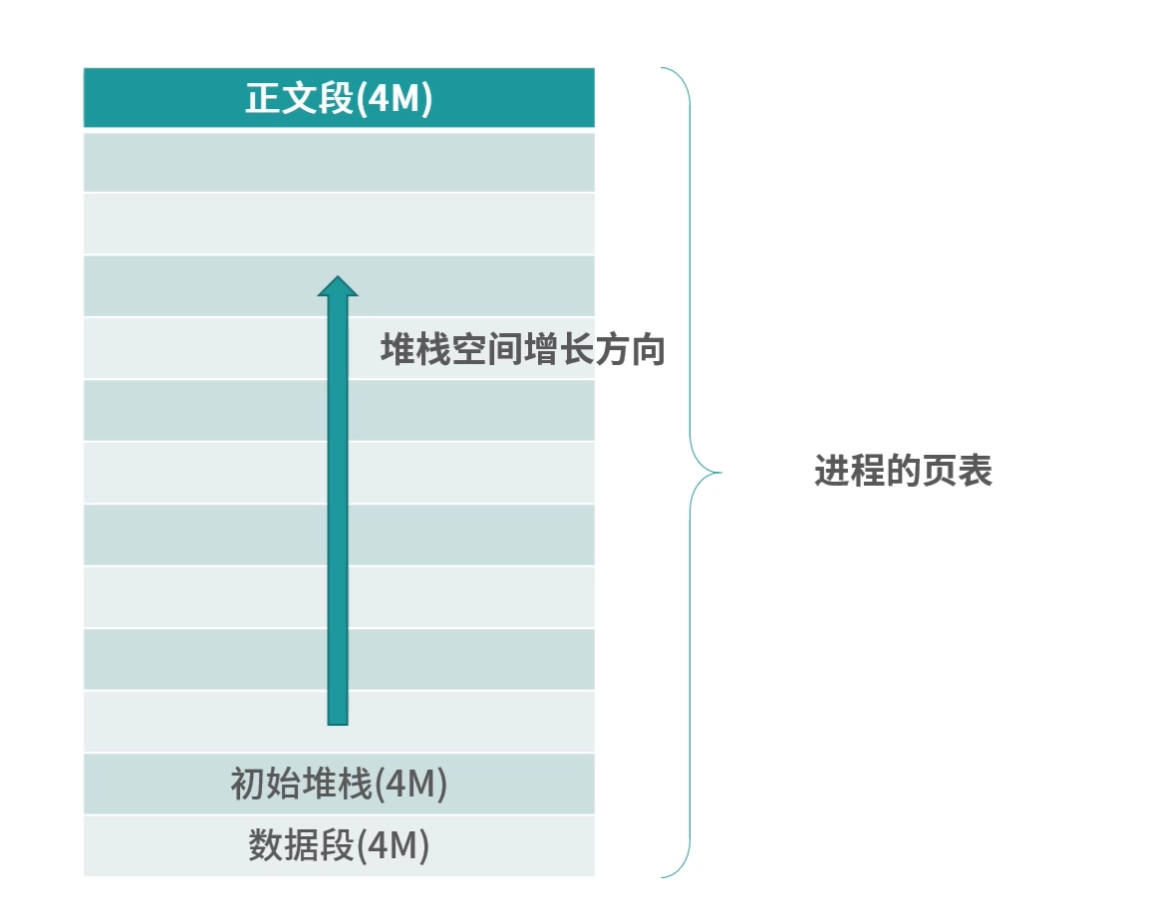
上图中,进程内部需要一个页表存储进程的数据。如果进程的内存上不封顶,那么页表有多少个条目合适呢? 进程分配多少空间合适呢? 如果页表大小为 1024 个条目,那么可以支持 1024*4K = 4M 空间。按照这个计算,如果进程需要 1G 空间,则需要 256K 个条目。我们预先为进程分配这 256K 个条目吗? 创建一个进程就划分这么多条目是不是成本太高了?
为了减少条目的创建,可以考虑进程内部用一个更大的页表(比如 4M),操作系统继续用 4K 的页表。这就形成了一个二级页表的结构,如下图所示:

这样 MMU 会先查询 1 级页表,再查询 2 级页表。在这个模型下,进程如果需要 1G 空间,也只需要 1024 个条目。比如 1 级页编号是 2, 那么对应 2 级页表中 [2* 1024, 3*1024-1] 的部分条目。而访问一个地址,需要同时给出一级页编号和二级页编号。整个地址,还可以用 64bit 组装,如下图所示:
MMU 根据 1 级编号找到 1 级页表条目,1 级页表条目中记录了对应 2 级页表的位置。然后 MMU 再查询 2 级页表,找到 Frame。最后通过地址偏移量和 Frame 编号计算最终的物理地址。这种设计是一个递归的过程,因此还可增加 3 级、4 级……每增加 1 级,对空间的利用都会提高——当然也会带来一定的开销。这对于大应用非常划算,比如需要 1T 空间,那么使用 2 级页表,页表的空间就节省得多了。而且,这种多级页表,顶级页表在进程中可以先只创建需要用到的部分,就这个例子而言,一开始只需要 3 个条目,从 256K 个条目到 3 个,这就大大减少了进程创建的成本。
一个程序最多能使用多少内存?
目前我们主要都是在用 64bit 的机器。因为 264 数字过于大,即便是虚拟内存都不需要这么大的空间。因此通常操作系统会允许进程使用非常大,但是不到 264 的地址空间。通常是几十到几百 EB(1EB = 106TB = 109GB)。
什么情况下使用大内存分页?
虚拟地址到物理地址的转换过程:
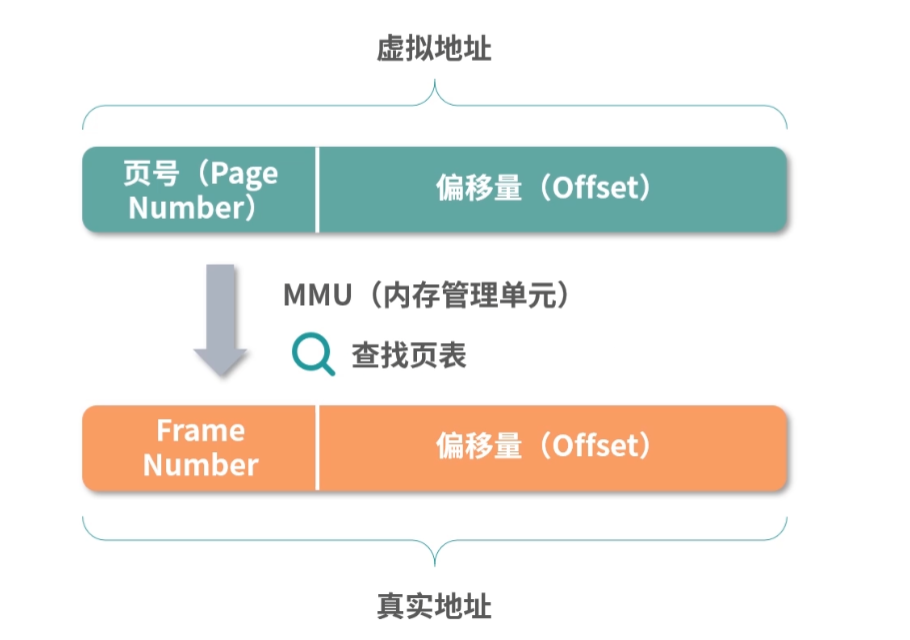
MMU: Memory Management Unit
你可以把虚拟地址看成由页号和偏移量组成,把物理地址看成由 Frame Number 和偏移量组成。在 CPU 中有一个完成虚拟地址到物理地址转换的小型设备,叫作内存管理单元(Memory Management Unit(MMU)。
在程序执行的时候,指令中的地址都是虚拟地址,虚拟地址会通过 MMU,MMU 会查询页表,计算出对应的 Frame Number,然后偏移量不变,组装成真实地址。然后 MMU 通过地址总线直接去访问内存。所以 MMU 承担了虚拟地址到物理地址的转换以及 CPU 对内存的操作这两件事情。
如下图所示,从结构上 MMU 在 CPU 内部,并且直接和地址总线连接。因此 MMU 承担了 CPU 和内存之间的代理。对操作系统而言,MMU 是一类设备,有多种型号,就好比显卡有很多型号一样。操作系统需要理解这些型号,会使用 MMU。
TLB 和 MMU 的性能问题
上面的过程,会产生一个问题:指令的执行速度非常快,而 MMU 还需要从内存中查询页表。最快的内存查询页需要从 CPU 的缓存中读取,假设缓存有 95% 的命中率,比如读取到 L2 缓存,那么每次操作也需要几个 CPU 周期。你可以回顾一下 CPU 的指令周期,如下图所示,有 fetch/decode/execute 和 store。
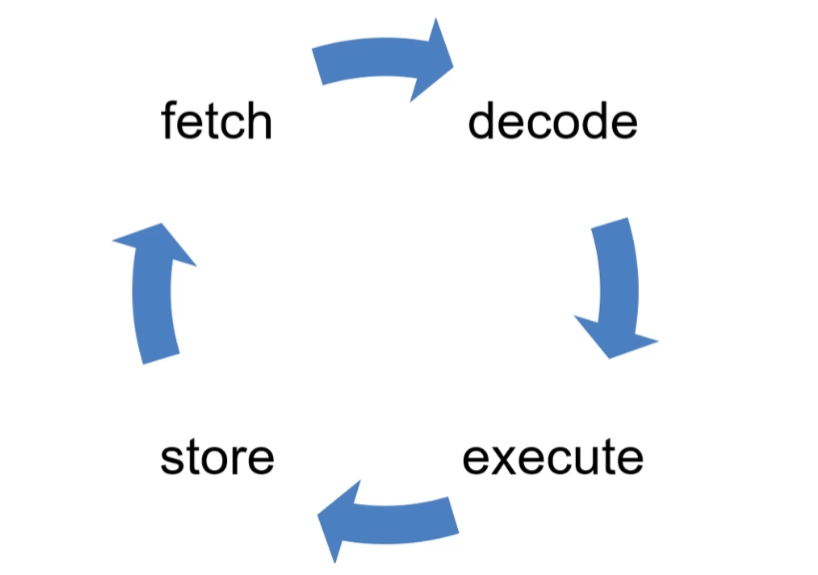
在 fetch、execute 和 store 这 3 个环节中都有可能发生内存操作,因此内存操作最好能在非常短的时间内完成,尤其是 Page Number 到 Frame Number 的映射,我们希望尽快可以完成,最好不到 0.2 个 CPU 周期,这样就不会因为地址换算而增加指令的 CPU 周期。
因此,在 MMU 中往往还有一个微型的设备,叫作转置检测缓冲区(Translation Lookaside Buffer,TLB)。
缓存的设计,通常是一张表,所以 TLB 也称作快表。TLB 中最主要的信息就是 Page Number到 Frame Number 的映射关系。
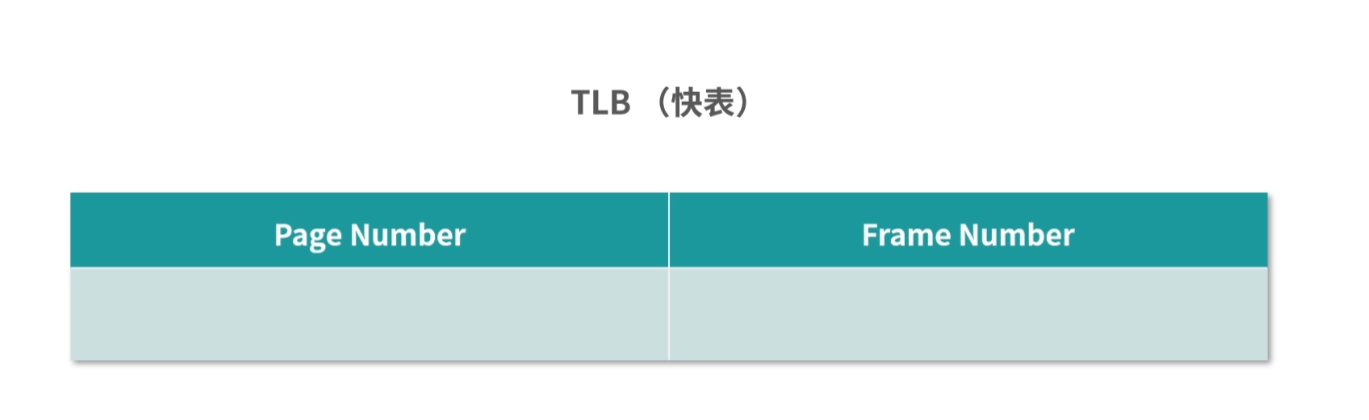
如上表所示,最简单的表达就是一个二维表格,每一行是一个 Page Number 和一个 Frame Number。我们把这样的每一行称为一个缓存行(Cache Line),或者缓存条目(Entry)。
TLB 的作用就是根据输入的 Page Number,找到 Frame Number。TLB 是硬件实现的,因此速度很快。因为用户的局部程序,往往会反复利用相同的内存地址。比如说 for 循环会反复利用循环变量,因此哪怕是只有几十个缓存行的 TLB,也会有非常高的命中率。而且现在的多核 CPU,会为每个核心提供单独的 TLB。这样,相当于减少了 TLB 的冲突。比如酷睿 i7 CPU 当中,每个核心都有自己的 TLB,而且 TLB 还进行了类似 CPU 缓存的分级策略。在 i7 CPU 中,L1 级 TLB 一共 64 个,L2 级 TLB 一共 1024 个。通过这样的设计,绝大多数的页表查询就可以用 TLB 实现了。
TLB Miss 问题
如果 Page Number 在 TLB 总没有找到,我们称为TLB 失效(Miss)。这种情况,分成两种。
一种是软失效(Soft Miss),这种情况 Frame 还在内存中,只不过 TLB 缓存中没有。那么这个时候需要刷新 TLB 缓存。如果 TLB 缓存已经满了,就需要选择一个已经存在的缓存条目进行覆盖。具体选择哪个条目进行覆盖,我们称为缓存置换(缓存不够用了,需要置换)。缓存置换时,通常希望高频使用的数据保留,低频使用的数据被替换。比如常用的 LRU(Least Recently Used)算法就是基于这种考虑,每次置换最早使用的条目。
另一种情况是硬失效(Hard Miss)**,这种情况下对应的 Frame 没有在内存中,需要从磁盘加载。这种情况非常麻烦,首先操作系统要触发一个缺页中断(原有需要读取内存的线程被休眠),然后中断响应程序开始从磁盘读取对应的 Frame 到内存中,读取完成后,再次触发中断通知更新 TLB,并且唤醒被休眠的线程去排队。注意,线程不可能从休眠态不排队就进入执行态,因此 Hard Miss 是相对耗时的**。
无论是软失效、还是硬失效,都会带来性能损失,这是我们不希望看到的。因此缓存的设计,就非常重要了。
TLB 缓存的设计
每个缓存行可以看作一个映射,TLB 的缓存行将 Page Number 映射到 Frame Number,通常我们设计这种基于缓存行(Cache Line)的缓存有 3 种映射方案:
- 全相联映射(Fully Associative Mapping)
- 直接映射(Direct Mapping)
- n 路组相联映射(n-way Set-Associative Mapping)
所谓相联(Associative),讲的是缓存条目和缓存数据之间的映射范围。如果是全相联,那么一个数据,可能在任何条目。如果是组相联(Set-Associative),意味对于一个数据,只能在一部分缓存条目中出现(比如前 4 个条目)。
方案一:全相联映射(Fully Associative Mapping)
如果 TLB 用全相联映射实现,那么一个 Frame,可能在任何缓存行中。虽然名词有点复杂,但是通常新人设计缓存时,会本能地想到全相联。因为在给定的空间下,最容易想到的就是把缓存数据都放进一个数组里。
对于 TLB 而言,如果是全相联映射,给定一个具体的 Page Number,想要查找 Frame,需要遍历整个缓存。当然作为硬件实现的缓存,如果缓存条目少的情况下,可以并行查找所有行。这种行为在软件设计中是不存在的,软件设计通常需要循环遍历才能查找行,但是利用硬件电路可以实现这种并行查找到过程。可是如果条目过多,比如几百个上千个,硬件查询速度也会下降。所以,全相联映射,有着明显性能上的缺陷。我们不考虑采用。
方案二:直接映射(Direct Mapping)
对于水平更高一些的同学,马上会想到直接映射。直接映射类似一种哈希函数的形式,给定一个内存地址,可以通过类似于哈希函数计算的形式,去计算它在哪一个缓存条目。假设我们有 64 个条目,那么可以考虑这个计算方法:缓存行号 = Page Number % 64。
当然在这个方法中,假如实际的虚拟地址空间大小是 1G,页面大小是 4K,那么一共有 1G/4K = 262144 个页,平均每 262144/64 = 4096 个页共享一个条目。这样的共享行为是很正常的,本身缓存大小就不可能太大,之前我们讲过,性能越高的存储离 CPU 越近,成本越高,空间越小。
上面的设计解决了全相联映射的性能缺陷,那么缓存命中率如何呢?
一种最简单的思考就是能不能基于直接映射实现 LRU 缓存。仔细思考,其实是不可能实现的。因为当我们想要置换缓存的时候(新条目进来,需要寻找一个旧条目出去),会发现每次都只有唯一的选择,因为对于一个确定的虚拟地址,它所在的条目也是确定的。这导致直接映射不支持各种缓存置换算法,因此 TLB Miss 肯定会更高。
综上,我们既要解决直接映射的缓存命中率问题,又希望解决全相联映射的性能问题。而核心就是需要能够实现类似 LRU 的算法,让高频使用的缓存留下来——最基本的要求,就是一个被缓存的值,必须可以存在于多个位置——于是人们就发明了 n 路组相联映射。
方案三:n 路组相联映射(n-way Set-Associative Mapping)
组相联映射有点像哈希表的开放寻址法,但是又有些差异。组相联映射允许一个虚拟页号(Page Number)映射到固定数量的 n 个位置。举个例子,比如现在有 64 个条目,要查找地址 100 的位置,可以先用一个固定的方法计算,比如 100%64 = 36。这样计算出应该去条目 36 获取 Frame 数据。但是取出条目 36 看到条目 36 的 Page Number 不是 100,这个时候就顺延一个位置,去查找 37,38,39……如果是 4 路组相联,那么就只看 36,37,38,39,如果是8 路组相联,就只看 36-43 位置。
这样的方式,一个 Page Number 可以在 n 个位置出现,这样就解决了 LRU 算法的问题。每次新地址需要置换进来的时候,可以从 n 个位置中选择更新时间最早的条目置换出去。至于具体 n 设置为多少,需要实战的检验。而且缓存是一个模糊、基于概率的方案,本身对 n 的要求不是很大。比如:i7 CPU 的 L1 TLB 采用 4-way 64 条目的设计;L2 TLB 采用 8-way 1024 条目的设计。Intel 选择了这样的设计,背后有大量的数据支撑。这也是缓存设计的一个要点,在做缓存设计的时候,你一定要收集数据实际验证。
以上,我们解决了 TLB 的基本设计问题,最后选择采用 n 路组相联映射。 然后还遗留了一个问题,如果一个应用(进程)对内存的需求比较大,比如 1G,而默认分页 4K 比较小。 这种情况下会有 262144 个页。考虑到 1024 个条目的 TLB,那么 262144/1024 = 256,如果 256 个地址复用 1 个缓存,很容易冲突。这个问题如何解决呢?
大内存分页
解决上面的遗留问题,可以考虑采用大内存分页(Large Page 或 Huge Page)。 这里我们先复习一下上一讲学习的多级页表。 多层页面就是进程内部维护一张页表,比如说 4M 一个页表(一级),然后每个一级页表关联 1024 个二级页表。 这样会给 MMU 带来一定的负担,因为 MMU 需要先检查一级页表,再检查二级页表。 但是 MMU 仍然可以利用 TLB 进行加速。因为 TLB 是缓存,所有根据值查找结果的逻辑,都可以用 TLB。
但是这没有解决我们提出的页表太多的问题,最终这种多级页表的设计还是需要查询大小为 4K 的页(这里请你思考上面的例子,如果是 1G 空间有 262144 个页)。如果我们操作系统能够提供大小为 4M 的页,那么是不是就减少了 1024 倍的页数呢? ——这样就大大提高了 TLB 的查询性能。
因此 Linux 内核 2.6 版之后就开始提供大内存分页(HugeTable),默认是不开启的。如果你有应用需要使用大内存分页,可以考虑用下面的语句开启它:
复制代码
1 | sudo sysctl -w vm.nr_hugepages=2048 |
sysctl其实就是修改一下配置项,上面我们允许应用使用最多 2048 个大内存页。上面语句执行后,你可以按照下方截图的方式去查看自己大内存页表使用的情况。
从上图中你可以看到我总共有 2048 个大内存页,每个大小是 2048KB。具体这个大小是不可以调整的,这个和机器用的 MMU 相关。
打开大内存分页后如果有应用需要使用,就会去申请大内存分页。比如 Java 应用可以用-XX:+UseLargePages开启使用大内存分页。 下图是我通过一个 Java 程序加上 UseLargePages 参数的结果。
注意:我的 Java 应用使用的分页数 = Total-Free+Rsvd = 2048-2032+180 = 196。Total 就是总共的分页数,Free 代表空闲的(包含 Rsvd,Reserved 预留的)。因此是上面的计算关系。
什么情况下使用大内存分页?
通常应用对内存需求较大时,可以考虑开启大内存分页。比如一个搜索引擎,需要大量在内存中的索引。有时候应用对内存的需求是隐性的。比如有的机器用来抗高并发访问,虽然平时对内存使用不高,但是当高并发到来时,应用对内存的需求自然就上去了。虽然每个并发请求需要的内存都不大, 但是总量上去了,需求总量也会随之提高高。这种情况下,你也可以考虑开启大内存分页。
LRU 用什么数据结构实现更合理?
LRU(最近最少使用),是一种缓存置换算法。缓存是用来存储常用的数据,加速常用数据访问的数据结构。有软件实现,比如数据库的缓存;也有硬件实现,比如我们上一讲学的 TLB。缓存设计中有一个重要的环节:当缓存满了,新的缓存条目要写入时,哪个旧条目被置换出去呢?
这就需要用到缓存置换算法(Cache Replacement Algorithm)。缓存置换应用场景非常广,比如发生缺页中断后,操作系统需要将磁盘的页导入内存,那么已经在内存中的页就需要置换出去。CDN 服务器为了提高访问速度,需要决定哪些 Web 资源在内存中,哪些在磁盘上。CPU 缓存每次写入一个条目,也就相当于一个旧的条目被覆盖。数据库要决定哪些数据在内存中,应用开发要决定哪些数据在 Redis 中,而空间是有限的,这些都关联着缓存的置换。
今天我们就以 LRU 用什么数据结构实现更合理,这道缓存设计题目为引,为你讲解缓存设计中(包括置换算法在内)的一些通用的思考方法。
理想状态
设计缓存置换算法的期望是:每次将未来使用频率最低的数据置换出去。假设只要我们知道未来的所有指令,就可以计算出哪些内存地址在未来使用频率高,哪些内存地址在未来使用频率低。这样,我们总是可以开发出理论上最高效的缓存置换算法。
再复习下缓存的基本概念,在缓存中找到数据叫作一次命中(Hit),没有找到叫作穿透(Miss)。假设穿透的概率为 M,缓存的访问时间(通常叫作延迟)是 L,穿透的代价(访问到原始数据,比如 Redis 穿透,访问到 DB)也就是穿透后获取数据的平均时间是 T,那么 M*T+L 可以看作是接近缓存的平均响应时间。L 通常是不变的,这个和我们使用了什么缓存相关。这样,如果我们知道未来访问数据的顺序,就可以把 M 降到最低,让缓存平均响应时间降到最低。
当然这只是美好的愿望,在实际工作中我们还不可能预知未来。
随机/FIFO/FILO
接下来我要和你讨论的 3 种策略,是对理想状态的一种悲观表达,或者说不好的设计。
比如说随机置换,一个新条目被写入,随机置换出去一个旧条目。这种设计,具有非常朴素的公平,但是性能会很差(穿透概率高),因为可能置换出去未来非常需要的数据。
再比如先进先出(First In First Out)。设计得不好的电商首页,每次把离现在时间最久的产品下线,让新产品有机会展示,而忽略销量、热度、好评等因素。这也是一种朴素的公平,但是和我们设计缓存算法的初衷——预估未来使用频率更高的数据保留在缓存中,相去甚远。所以,FIFO 的结构也是一种悲观的设计。
FIFO 的结构使用一个链表就能实现,如下图所示:
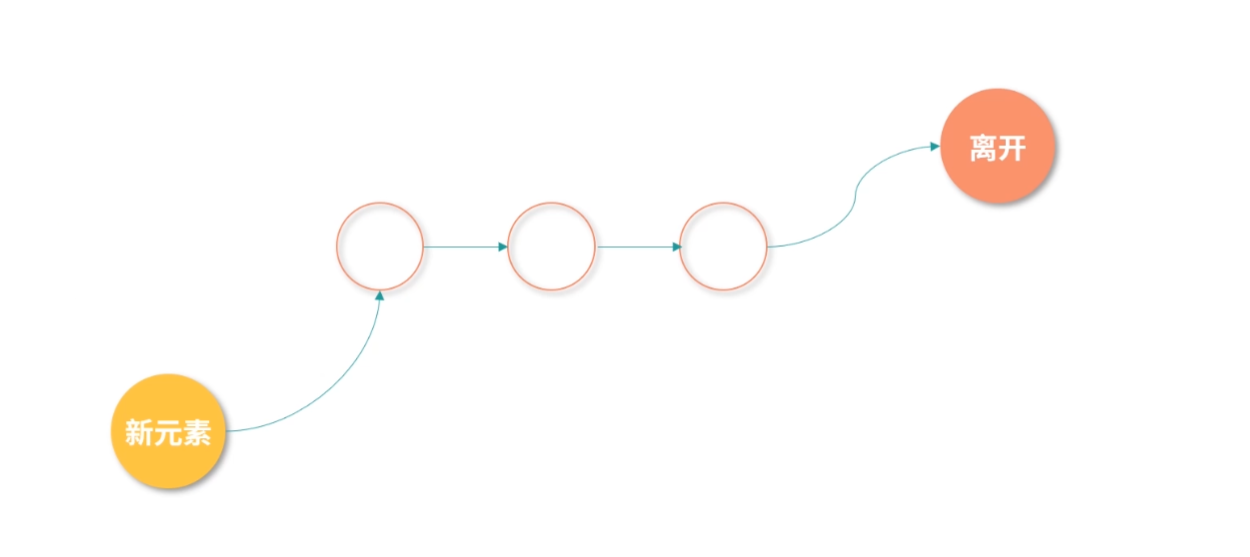
为了方便你理解本讲后面的内容,我在这里先做一个知识铺垫供你参考。上图中,新元素从链表头部插入,旧元素从链表尾部离开。 这样就构成了一个队列(Queue),队列是一个经典的 FIFO 模型。
还有一种策略是先进后出(First In Last Out)。但是这种策略和 FIFO、随机一样,没有太强的实际意义。因为先进来的元素、后进来的元素,还是随机的某个元素,和我们期望的未来使用频率,没有任何本质联系。
同样 FILO 的策略也可以用一个链表实现,如下图所示:
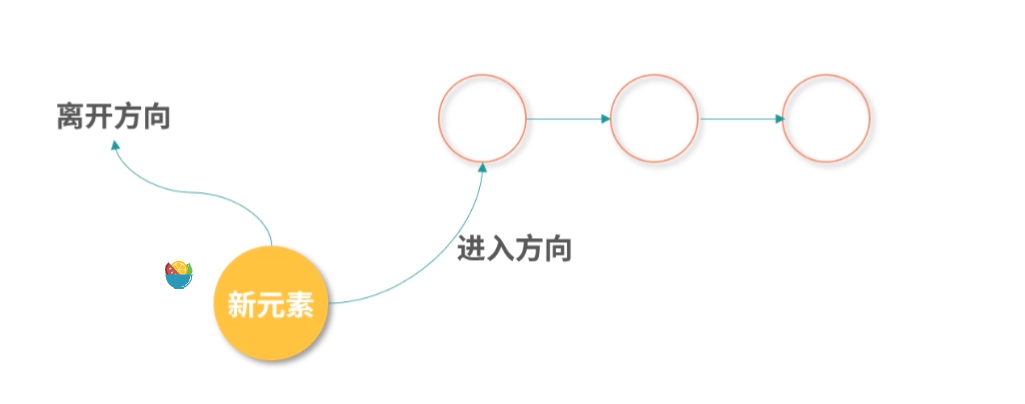
新元素从链表头部插入链表,旧元素从链表头部离开链表,就构成了一个栈(Stack),栈是一种天然的 FILO 数据结构。这里仅供参考了,我们暂时还不会用到这个方法。
当然我们不可能知道未来,但是可以考虑基于历史推测未来。经过前面的一番分析,接下来我们开始讨论一些更有价值的置换策略。
最近未使用(NRU)
一种非常简单、有效的缓存实现就是优先把最近没有使用的数据置换出去(Not Recently Used)。从概率上说,最近没有使用的数据,未来使用的概率会比最近经常使用的数据低。缓存设计本身也是基于概率的,一种方案有没有价值必须经过实践验证——在内存缺页中断后,如果采用 NRU 置换页面,可以提高后续使用内存的命中率,这是实践得到的结论。
而且 NRU 实现起来比较简单,下图是我们在“24 讲”中提到的页表条目设计。
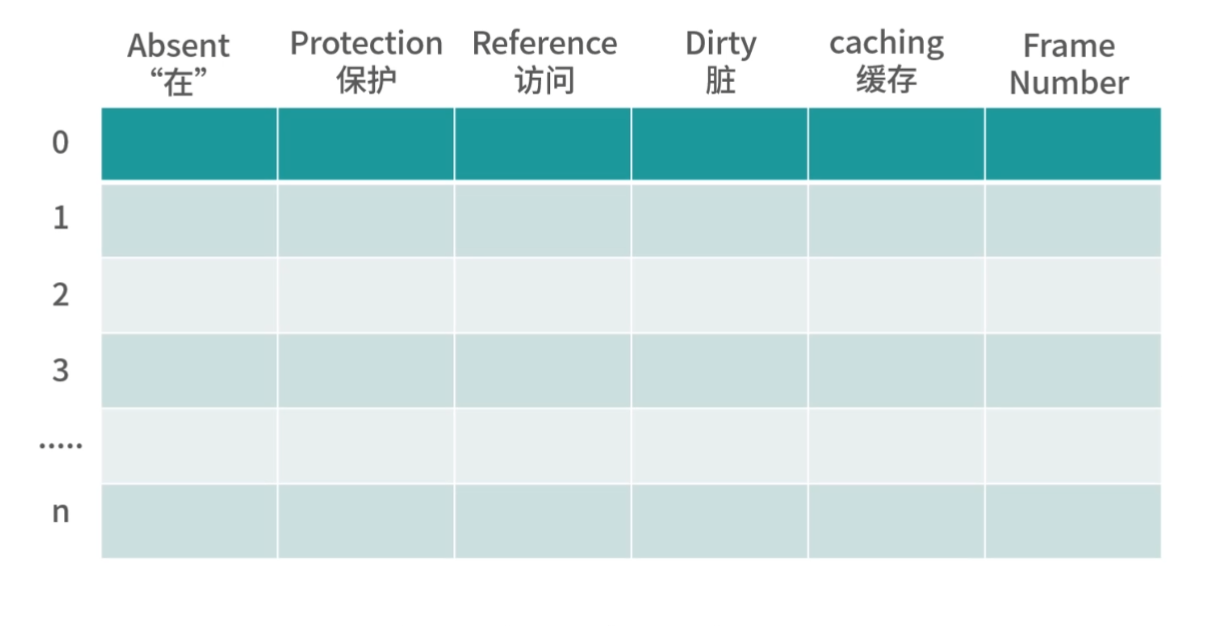
在页表中有一个访问位,代表页表有被读取过。还有一个脏位,代表页表被写入过。无论是读还是写,我们都可以认为是访问过。 为了提升效率,一旦页表被使用,可以用硬件将读位置 1,然后再设置一个定时器,比如 100ms 后,再将读位清 0。当有内存写入时,就将写位置 1。过一段时间将有内存写入的页回写到磁盘时,再将写位清 0。这样读写位在读写后都会置为 1,过段时间,也都会回到 0。
上面这种方式,就构成了一个最基本的 NRU 算法。每次置换的时候,操作系统尽量选择读、写位都是 0 的页面。而一个页面如果在内存中停留太久,没有新的读写,读写位会回到 0,就可能会被置换。
这里多说一句,NRU 本身还可以和其他方法结合起来工作,比如我们可以利用读、写位的设计去改进 FIFO 算法。
每次 FIFO 从队列尾部找到一个条目要置换出去的时候,就检查一下这个条目的读位。如果读位是 0,就删除这个条目。如果读位中有 1,就把这个条目从队列尾部移动到队列的头部,并且把读位清 0,相当于多给这个条目一次机会,因此也被称为第二次机会算法。多给一次机会,就相当于发生访问的页面更容易存活。而且,这样的算法利用天然的数据结构优势(队列),保证了 NRU 的同时,节省了去扫描整个缓存寻找读写位是 0 的条目的时间。
第二次机会算法还有一个更巧妙的实现,就是利用循环链表。这个实现可以帮助我们节省元素从链表尾部移动到头部的开销。
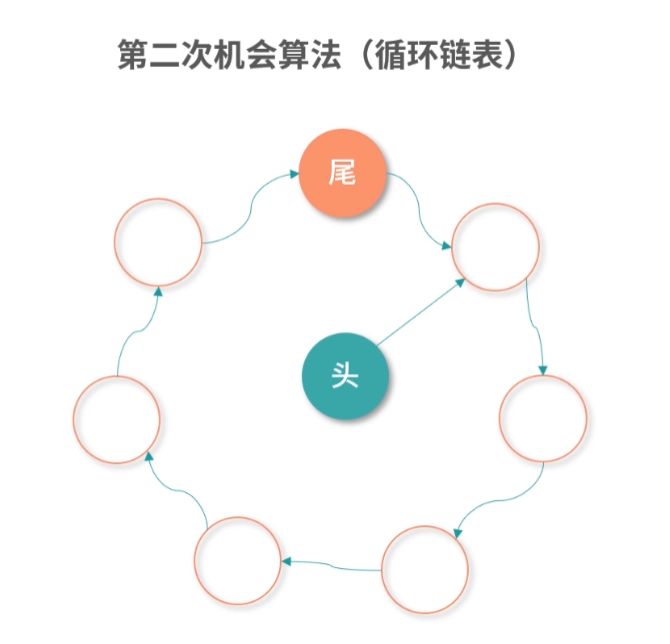
如上图所示,我们可以将从尾部移动条目到头部的这个操作简化为头指针指向下一个节点。每次移动链表尾部元素到头部,只需要操作头指针指向下一个元素即可。这个方法非常巧妙,而且容易实现,你可以尝试在自己系统的缓存设计中尝试使用它。
以上,是我们学习的第一个比较有价值的缓存置换算法。基本可用,能够提高命中率。缺点是只考虑了最近用没用过的情况,没有充分考虑综合的访问情况。优点是简单有效,性能好。缺点是考虑不周,对缓存的命中率提升有限。但是因为简单,容易实现,NRU 还是成了一个被广泛使用的算法。
最近使用最少(LRU)
一种比 NRU 考虑更周密,实现成本更高的算法是最近最少使用(Least Recently Used, LRU)算法,它会置换最久没有使用的数据。和 NRU 相比,LRU 会考虑一个时间范围内的数据,对数据的参考范围更大。LRU 认为,最近一段时间最少使用到的数据应该被淘汰,把空间让给最近频繁使用的数据。这样的设计,即便数据都被使用过,还是会根据使用频次多少进行淘汰。比如:CPU 缓存利用 LUR 算法将空间留给频繁使用的内存数据,淘汰使用频率较低的内存数据。
常见实现方案
LRU 的一种常见实现是链表,如下图所示:
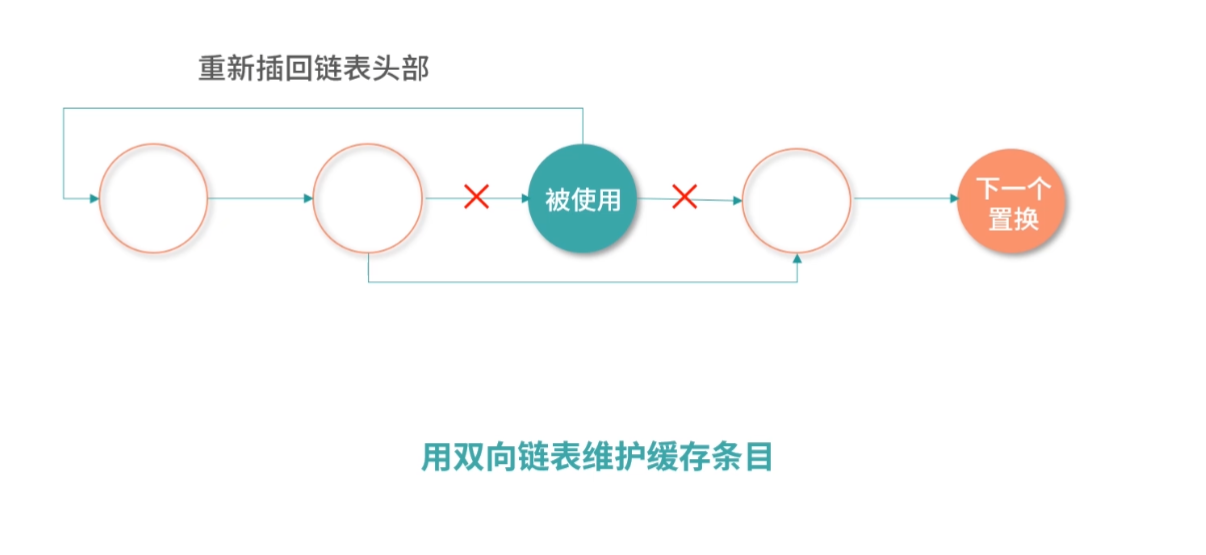
用双向链表维护缓存条目。如果链表中某个缓存条目被使用到,那么就将这个条目重新移动到表头。如果要置换缓存条目出去,就直接从双线链表尾部删除一个条目。
通常 LRU 缓存还要提供查询能力,这里我们可以考虑用类似 Java 中 LinkedHashMap 的数据结构,同时具备双向链表和根据 Key 查找值的能力。
以上是常见的实现方案,但是这种方案在缓存访问量非常大的情况下,需要同时维护一个链表和一个哈希表,因此开销较高。
举一个高性能场景的例子,比如页面置换算法。 如果你需要维护一个很大的链表来存储所有页,然后经常要删除大量的页面(置换缓存),并把大量的页面移动到链表头部。这对于页面置换这种高性能场景来说,是不可以接受的。
另外一个需要 LRU 高性能的场景是 CPU 的缓存,CPU 的多路组相联设计,比如 8-way 设计,需要在 8 个地址中快速找到最久未使用的数据,不可能再去内存中建立一个链表来实现。
正因为有这么多困难,才需要不断地优化迭代,让缓存设计成为一门艺术。接下来我选取了内存置换算法中数学模拟 LRU 的算法,分享给你。
如何描述最近使用次数?
设计 LRU 缓存第一个困难是描述最近使用次数。 因为“最近”是一个模糊概念,没有具体指出是多长时间?按照 CPU 周期计算还是按照时间计算?还是用其他模糊的概念替代?
比如说页面置换算法。在实际的设计中,可以考虑把页表的读位利用起来。做一个定时器,每隔一定的 ms 数,就把读位累加到一个计数器中。相当于在每个页表条目上再增加一个累计值。
例如:现在某个页表条目的累计值是 0, 接下来在多次计数中看到的读位是:1,0,0,1,1,那么累计值就会变成 3。这代表在某段时间内(5 个计数器 Tick 中)有 3 次访问操作。
通过这种方法,就解决了描述使用次数的问题。如果单纯基于使用次数最少判断置换,我们称为最少使用(Least Frequently Used,,LFU)算法。LFU 的劣势在于它不会忘记数据,累计值不会减少。比如如果有内存数据过去常常被用到,但是现在已经有很长一段时间没有被用到了,在这种情况下它并不会置换出去。那么我们该如何描述“最近”呢?
有一个很不错的策略就是利用一个叫作“老化”(Aging)的算法。比起传统的累加计数的方式,Aging 算法的累加不太一样。
比如用 8 位来描述累计数(A),那么每次当读位的值(R)到来的时候,我们都考虑将 A 的值右移,然后将 R 放到 A 的最高位。
例如 A 目前的值是00000000,在接下来的 5 个 Tick 中 R 来临的序列是11100,那么 A 的值变更顺序为:
- 10000000
- 11000000
- 11100000
- 01110000
- 00111000
你可以看到随着 Aging 算法的执行,有访问操作的时候 A 的值上升,没有访问操作的时候,A的值逐渐减少。如果一直没有访问操作,A 的值会回到 0。
这样的方式就巧妙地用数学描述了“最近”。然后操作系统每次页面置换的时候,都从 A 值最小的集合中取出一个页面放入磁盘。这个算法是对 LRU 的一种模拟,也被称作 LFUDA(动态老化最少使用,其中 D 是 Dynamic,,A 是 Aging)。
而计算 Aging(累计值)的过程,可以由硬件实现,这样就最大程度提升了性能。
相比写入操作,查询是耗时相对较少的。这是因为有 CPU 缓存的存在,我们通常不用直接去内存中查找数据,而是在缓存中进行。对于发生缺页中断的情况,并不需要追求绝对的精确,可以在部分页中找到一个相对累计值较小的页面进行置换。不过即便是模拟的 LRU 算法,也不是硬件直接支持的,总有一部分需要软件实现,因此还是有较多的时间开销。
是否采用 LRU,一方面要看你所在场景的性能要求,有没有足够的优化措施(比如硬件提速);另一方面,就要看最终的结果是否能够达到期望的命中率和期望的使用延迟了。
本讲我们讨论的频次较高、频次较低,是基于历史的。 历史在未来并不一定重演。比如读取一个大型文件,无论如何操作都很难建立一个有效的缓存。甚至有的时候,最近使用频次最低的数据被缓存,使用频次最高的数据被置换,效率会更高。比如说有的数据库设计同时支持 LRU 缓存和 MRU( Most Recently Used)缓存。MRU 是 LRU 的对立面,这看似茅盾,但其实是为了解决不同情况下的需求。
这并不是说缓存设计无迹可寻,而是经过思考和预判,还得以事实的命中率去衡量缓存置换算法是否合理。
LRU 用什么数据结构实现更合理?
最原始的方式是用数组,数组的每一项中有数据最近的使用频次。数据的使用频次可以用计时器计算。每次置换的时候查询整个数组实现。
另一种更好的做法是利用双向链表实现。将使用到的数据移动到链表头部,每次置换时从链表尾部拿走数据。链表头部是最近使用的,链表尾部是最近没有被使用到的数据。
但是在应对实际的场景的时候,有时候不允许我们建立专门用于维护缓存的数据结构(内存大小限制、CPU 使用限制等),往往需要模拟 LRU。比如在内存置换场景有用“老化”技术模拟 LRU 计算的方式。
如何解决内存的循环引用问题?
内存泄漏一直是很多大型系统故障的根源,也是一个面试热点。那么在编程语言层面已经提供了内存回收机制,为什么还会产生内存泄漏呢?
这是因为应用的内存管理一直处于一个和应用程序执行并发的状态,如果应用程序申请内存的速度,超过内存回收的速度,内存就会被用满。当内存用满,操作系统就开始需要频繁地切换页面,进行频繁地磁盘读写。
所以我们观察到的系统性能下降,往往是一种突然的崩溃,因为一旦内存被占满,系统性能就开始雪崩式下降。
特别是有时候程序员不懂内存回收的原理,错误地使用内存回收器,导致部分对象没有被回收。而在高并发场景下,每次并发都产生一点不能回收的内存,不用太长时间内存就满了,这就是泄漏通常的成因。
这一块知识点关联着很多常见的面试题,比如。
- 这一讲关联的题目:如何解决循环引用问题?
- 下节课关联的题目:三色标记-清除算法的工作原理?生代算法等。
- 还有一些题目会考察你对内存回收器整体的理解,比如如何在吞吐量、足迹和暂停时间之间选择?
接下来,我会用 27 和 28 两讲和你探讨内存回收技术,把这些问题一网打尽。
什么是 GC
通常意义上我们说的垃圾回收器(Garbage Collector,GC),和多数同学的理解会有出入。你可能认为 GC 是做内存回收用的模块,而事实上程序语言提供的 GC 往往是应用的实际内存管理者。刚刚入门咱们就遇到了一个容易出现理解偏差的问题,所以 GC 是值得花时间细学的。
如上图所示,一方面 GC 要承接操作系统虚拟内存的架构,另一方面 GC 还要为应用提供内存管理。GC 有一个含义,就是 Garbage Collection 内存回收的具体动作。无论是名词的回收器,还是动词的回收行为,在下文中我都称作 GC。
下面我们具体来看一下 GC 都需要承担哪些“工作”,这里我总结为以下 4 种。
- GC 要和操作系统进行交互,负责申请内存,并把不用的内存还给操作系统(释放内存)。
- 应用会向 GC 申请内存。
- GC 要承担我们通常意义上说的垃圾回收能力,标记不用的对象,并回收他们。
- GC 还需要针对应用特性进行动态的优化。
所以现在程序语言实现的 GC 模块通常是实际负责应用内存管理的模块。在程序语言实现 GC 的时候,会关注下面这几个指标。
- 吞吐量(Throughput):执行程序(不包括 GC 执行的时间)和总是间的占比。注意这个吞吐量和通常意义上应用去处理作业的吞吐量是不一样的,这是从 GC 的角度去看应用。只要不在 GC,就认为是吞吐量的一部分。
- 足迹(FootPrint): 一个程序使用了多少硬件的资源,也称作程序在硬件上的足迹。GC 里面说的足迹,通常就是应用对内存的占用情况。比如说应用运行需要 2G 内存,但是好的 GC 算法能够帮助我们减少 500MB 的内存使用,满足足迹这个指标。
- 暂停时间(Pause Time): GC 执行的时候,通常需要停下应用(避免同步问题),这称为 Stop The World,或者暂停。不同应用对某次内存回收可以暂停的时间需求是不同的,比如说一个游戏应用,暂停了几毫秒用户都可能有很大意见;而看网页的用户,稍微慢了几毫秒是没有感觉的。
GC 目标的思考
如果单纯从让 GC 尽快把工作做完的角度来讲,其实是提升吞吐量。比如利用好多核优势就是一种最直观的方法。
因为涉及并行计算,我这里给你讲讲并行计算领域非常重要的阿姆达定律,这个定律用来衡量并行计算对原有算法的改进,公式如下:
S = 1 / (1- P)
你现在看到的是一个简化版的阿姆达定律,P 是任务中可以并发执行部分的占比,S 是并行带来的理论提速倍数的极限。比如说 P 是 0.9,代入公式可得:
S = 1 / (1 - 0.9) = 10
上面表达式代表着有 90% 的任务可以并行,只有 10% 的任务不能够并行。假设我们拥有无限多的 CPU 去分担 90% 可以并行的任务,其实就相当于并行的任务可以在非常短的时间内完成。但是还有 10% 的任务不能并行,因此理论极限是 1/0.1=10 倍。
通常我们设计 GC,都希望它能够支持并行处理任务。因为 GC 本身也有着繁重的工作量,需要扫描所有的对象,对内存进行标记清除和整理等。
经过上述分析,那么我们在设计算法的时候是不是应该尽量做到高并发呢?
很可惜并不是这样。如果算法支持的并发度非常高,那么和单线程算法相比,它也会带来更多的其他开销。比如任务拆分的开销、解决同步问题的开销,还有就是空间开销,GC 领域空间开销通常称为 FootPrint。理想情况下当然是核越多越好,但是如果考虑计算本身的成本,就需要找到折中的方案。
还有一个问题是,GC 往往不能拥有太长的暂停时间(Pause Time),因为 GC 和应用是并发的执行。如果 GC 导致应用暂停(Stop The World,STL)太久,那么对有的应用来说是灾难性的。 比如说你用鼠标的时候,如果突然卡了你会很抓狂。如果一个应用提供给百万级的用户用,假设这个应用帮每个用户每天节省了 1s 的等待时间,那么按照乔布斯的说法每天就为用户节省了 11 天的时间,每年是 11 年——5 年就相当于拯救了一条生命。
如果暂停时间只允许很短,那么 GC 和应用的交替就需要非常频繁。这对 GC 算法要求就会上升,因为每次用户程序执行后,会产生新的变化,甚至会对已有的 GC 结果产生影响。后面我们在讨论标记-清除算法的时候,你会感受到这种情况。
所以说,吞吐量高,不代表暂停时间少,也不代表空间使用(FootPrint)小。 同样的,使用空间小的 GC 算法,吞吐量反而也会下降。正因为三者之间存在类似相同成本代价下不可兼得的关系,往往编程语言会提供参数让你选择根据自己的应用特性决定 GC 行为。
引用计数算法(Reference Counter)
接下来我们说说,具体怎么去实现 GC。实现 GC 最简单的方案叫作引用计数,下图中节点的引用计数是 2,代表有两个节点都引用了它。
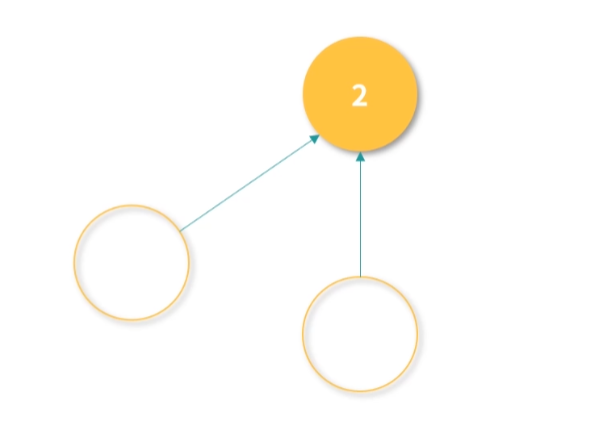
如果一个节点的引用计数是 0,就意味着没有任何一个节点引用它——此时,理论上这个节点应该被回收。GC 不断扫描引用计数为 0 的节点进行回收,就构成了最简单的一个内存回收算法。
但是,这个算法可能会出现下图中循环引用的问题(我们写程序的过程中经常会遇到这样的引用关系)。下图中三个节点,因为循环引用,引用计数都是 1。
引用计数是 1,因此就算这 3 个对象不会再使用了,GC 不会回收它们。
另一个考虑是在多线程环境下引用计数的算法一旦算错 1 次(比如因为没有处理好竞争条件),那么就无法再纠正了。而且处理竞争条件本身也比较耗费性能。
还有就是引用计数法回收内存会产生碎片,当然碎片不是只有引用计数法才有的问题,所有的 GC 都需要面对碎片。下图中内存回收的碎片可以通过整理的方式,清理出更多空间出来。关于内存空间的碎片,下一讲会有专门的一个小节讨论。
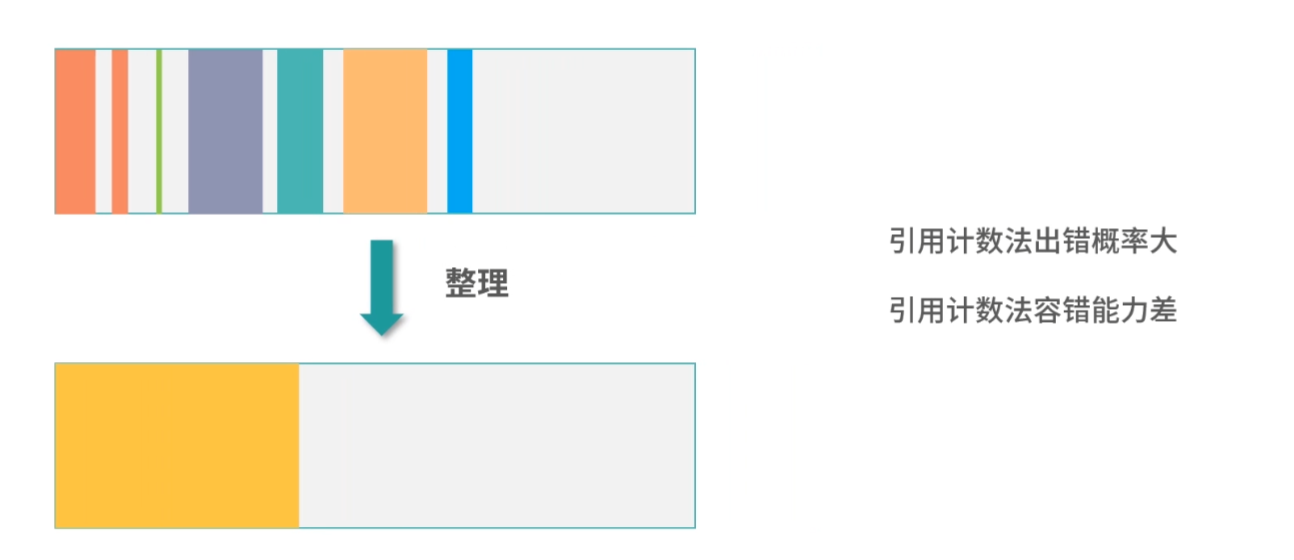
综上,引用计数法出错概率大,比如我们编程时会有对象的循环引用;另一方面,引用计数法容错能力差,一旦计算错了,就会导致内存永久无法被回收,因此我们需要更好的方式。
Root Tracing 算法
下面我再给你介绍一种更好的方式—— Root Tracing 算法。这是一类算法,后面我们会讲解的标记-清除算法和 3 色标记-清除算法都属于这一类。
Root Tracing 的原理是:从引用路径上,如果一个对象的引用链中包括一个根对象(Root Object),那么这个对象就是活动的。根对象是所有引用关系的源头。比如用户在栈中创建的对象指针;程序启动之初导入数据区的全局对象等。在 Java 中根对象就包括在栈上创建指向堆的对象;JVM 的一些元数据,包括 Method Area 中的对象等。
在 Root Tracing 工作过程中,如果一个对象和根对象间有连通路径,也就是从根节点开始遍历可以找到这个对象,代表有对象可以引用到这个对象,那么这个节点就不需要被回收。所以算法的本质还是引用,只不过判断条件从引用计数变成了有根对象的引用链。
如果一个对象从根对象不可达,那么这个对象就应该被回收,即便这个对象存在循环引用。可以看到,上图中红色的 3 个对象循环引用,并且到根集合没有引用链,因此需要被回收。这样就解决了循环引用的问题。
Root Tracing 的容错性很好,GC 通过不断地执行 Root Tracing 算法找到需要回收的元素。如果在这个过程中,有一些本来应该回收的元素没有被计算出(比如并发原因),也不会导致这些对象永久无法回收。因为在下次执行 Root Tracing 的时候,GC 就会通过执行 Root Tracing 算法找到这些元素。不像引用计数法,一旦算错就很难恢复。
标记-清除(Mark Sweep)算法
下面我为你具体介绍一种 Root Tracing 的算法, 就是标记清除-算法。标记-清除算法中,用白色代表一种不确定的状态:可能被回收。 黑色代表一种确定的状态:不会被回收。算法的实现,就是为所有的对象染色。算法执行结束后,所有是白色的对象就需要被回收。
算法实现过程中,假设有两个全局变量是已知的:
- heapSet 中拥有所有对象
- rootSet 中拥有所有 Root Object
算法执行的第一步,就是将所有的对象染成白色,代码如下:
1 | for obj in heapSet { |
接下来我们定义一个标记函数,它会递归地将一个对象的所有子对象染成黑色,代码如下:
1 | func mark(obj) { |

补充知识
上面的 mark 函数对 obj 进行了深度优先搜索。深度优先搜索,就是自然的递归序。随着递归函数执行,遇到子元素就遍历子元素,就构成了天然的深度优先搜索。还有一个相对的概念是广度优先搜索(Breadth First Serach),如果你不知道深度优先搜索和广度优先搜索,可以看下我下面的图例。
上图中,深度优先搜索优先遍历完整的子树(递归),广度优先搜索优先遍历所有的子节点(逐层)。
然后我们从所有的 Root Object 开始执行 mark 函数:
1 | for root in rootSet { |
以上程序执行结束后,所有和 Root Object 连通的对象都已经被染成了黑色。然后我们遍历整个 heapSet 找到白色的对象进行回收,这一步开始是清除(Sweep)阶段,以上是标记(Mark)阶段。
1 | for obj in heapSet { |
以上算法就是一个简单的标记-清除算法。相比引用计数,这个算法不需要维护状态。算法执行开始所有节点都被标记了一遍。结束的时候,算法找到的垃圾就被清除了。 算法有两个阶段,标记阶段(Mark),还有清除阶段(Sweep),因此被称为标记-清除算法。
这里请你思考:如果上面的 GC 程序在某个时刻暂停了下来,然后开始执行用户程序。如果用户程序删除了对某个已经标记为黑色对象的所有引用,用户程序没办法通知 GC 程序。这个节点就会变成浮动垃圾(Floating Garbage),需要等待下一个 GC 程序执行。
假设用户程序和 GC 交替执行,用户程序不断进行修改(Mutation),而 GC 不断执行标记-清除算法。那么这中间会产生大量浮动垃圾影响 GC 的效果。
另一方面,考虑到 GC 是一个非常消耗性能程序,在某些情况下,我们希望 GC 能够增量回收。 比如说,用户仅仅是高频删除了一部分对象,那么是否可以考虑设计不需要从整个 Root 集合进行遍历,而是增量的只处理最近这一批变更的算法呢?答案是可以的,我们平时可以多执行增量 GC,偶尔执行一次全量 GC。具体增量的方式会在下一讲为你讲解。
我们发现双色标记-清除算法有一个明显的问题,如下图所示:

你可以把 GC 的过程看作标记、清除及程序不断对内存进行修改的过程,分成 3 种任务:
标记程序(Mark)
清除程序(Sweep)
变更程序(Mutation)
标记(Mark)就是找到不用的内存,清除(Sweep)就是回收不用的资源,而修改(Muation)则是指用户程序对内存进行了修改。通常情况下,在 GC 的设计中,上述 3 种程序不允许并行执行(Simultaneously)。对于 Mark、Sweep、Mutation 来说内存是共享的。如果并行执行相当于需要同时处理大量竞争条件的手段,这会增加非常多的开销。当然你可以开多个线程去 Mark、Mutation 或者 Sweep,但前提是每个过程都是独立的。

因为 Mark 和 Sweep 的过程都是 GC 管理,而 Mutation 是在执行应用程序,在实时性要求高的情况下可以允许一边 Mark,一边 Sweep 的情况; 优秀的算法设计也可能会支持一边 Mark、一边 Mutation 的情况。这种算法通常使用了 Read On Write 技术,本质就是先把内存拷贝一份去 Mark/Sweep,让 Mutation 完全和 Mark 隔离。
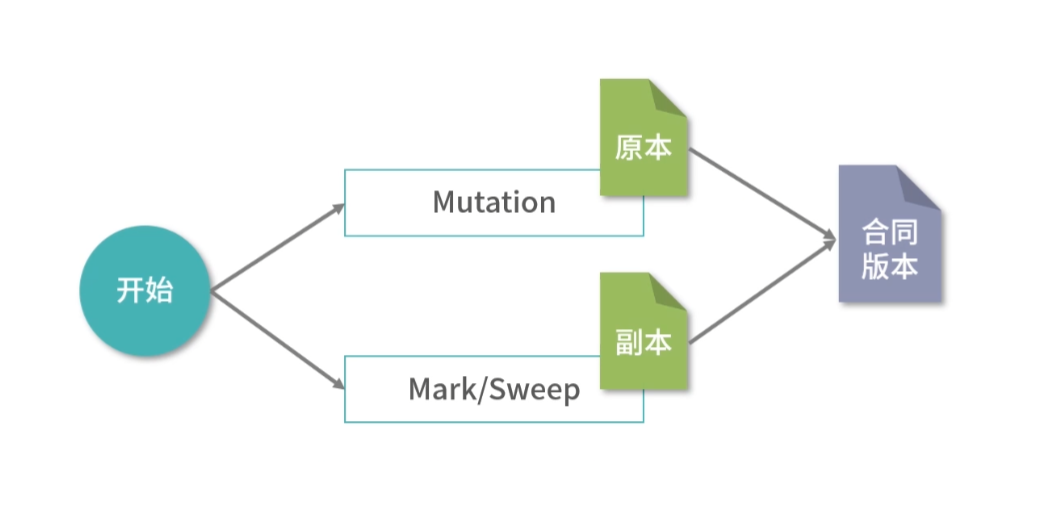
上图中 GC 开始后,拷贝了一份内存的原本,进行 Mark 和 Sweep,整理好内存之后,再将原本中所有的 Mutation 合并进新的内存。 这种算法设计起来会非常复杂,但是可以保证实时性 GC。
上图的这种 GC 设计比较少见,通常 GC 都会发生 STL(Stop The World)问题,Mark/Sweep/Mutation 只能够交替执行。也就是说, 一种程序执行的时候,另一种程序必须停止。
对于双色标记-清除算法,如果 Mark 和 Sweep 之间存在 Mutation,那么 Mutation 的伤害是比较大的。比如 Mutation 新增了一个白色的对象,这个白色的对象就可能会在 Sweep 启动后被清除。当然也可以考虑新增黑色的对象,这样对象就不会在 Sweep 启动时被回收。但是会发生下面这个问题,如下图所示:
如果一个新对象指向了一个已经删除的对象,一个新的黑色对象指向了一个白色对象,这个时候 GC 不会再遍历黑色对象,也就是白色的对象还是会被清除。因此,我们希望创建一个在并发环境更加稳定的程序,让 Mark/Mutation/Sweep 可以交替执行,不用特别在意它们之间的关联。
有一个非常优雅地实现就是再增加一种中间的灰色,把灰色看作可以增量处理的工作,来重新定义白色的含义。
三色标记-清除算法(Tri-Color Mark Sweep)
接下来,我会和你讨论这种有三个颜色标记的算法,通常称作三色标记-清除算法。首先,我们重新定义黑、白、灰三种颜色的含义:
白色代表需要 GC 的对象;
黑色代表确定不需要 GC 的对象;
灰色代表可能不需要 GC 的对象,但是还未完成标记的任务,也可以认为是增量任务。
在三色标记-清除算法中,一开始所有对象都染成白色。初始化完成后,会启动标记程序。在标记的过程中,是可以暂停标记程序执行 Mutation。
算法需要维护 3 个集合,白色集合、黑色集合、灰色集合。3 个集合是互斥的,对象只能在一个集合中。执行之初,所有对象都放入白色集合,如下图所示:
第一次执行,算法将 Root 集合能直接引用的对象加入灰色集合,如下图所示:
接下来算法会不断从灰色集合中取出元素进行标记,主体标记程序如下:
1 | while greySet.size() > 0 { |
标记的过程主要分为 3 个步骤:
- 如果对象在白色集合中,那么先将对象放入灰色集合;
- 然后遍历节点的所有的引用对象,并递归所有引用对象;
- 当一个对象的所有引用对象都在灰色集合中,就把这个节点放入为黑色集合。
伪代码如下:
1 | func mark(obj) { |
你可以观察下上面的程序,这是一个 DFS 的过程。如果多个线程对不同的 Root Object 并发执行这个算法,我们需要保证 3 个集合都是线程安全的,可以考虑利用 ConcurrentSet(这样性能更好),或者对临界区上锁。并发执行这个算法的时候,如果发现一个灰色节点说明其他线程正在处理这个节点,就忽略这个节点。这样,就解决了标记程序可以并发执行的问题。
当标记算法执行完成的时候,所有不需要 GC 的元素都会涂黑:
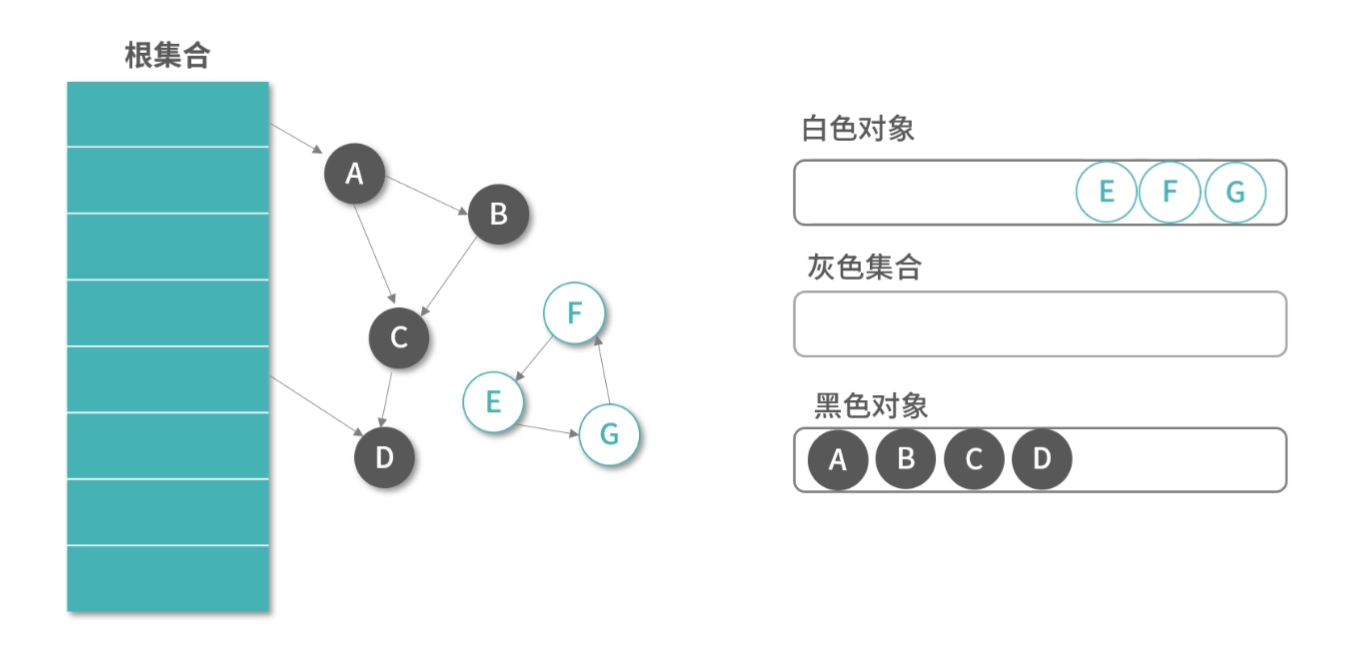
标记算法完成后,白色集合内就是需要回收的对象。
以上,是类似双色标记-清除算法的全量 GC 程序,我们从 Root 集合开始遍历,完成了对所有元素的标记(将它们放入对应的集合)。
接下来我们来考虑增加 GC(Incremental GC)的实现。首先对用户的修改进行分类,有这样 3 类修改(Mutation)需要考虑:
- 创建新对象
- 删除已有对象
- 调整已有引用
如果用户程序创建了新对象,可以考虑把新对象直接标记为灰色。虽然,也可以考虑标记为黑色,但是标记为灰色可以让 GC 意识到新增了未完成的任务。比如用户创建了新对象之后,新对象引用了之前删除的对象,就需要重新标记创建的部分。
如果用户删除了已有的对象,通常做法是等待下一次全量 Mark 算法处理。下图中我们删除了 Root Object 到 A 的引用,这个时候如果把 A 标记成白色,那么还需要判断是否还有其他路径引用到 A,而且 B,C 节点的颜色也需要重新计算。关键的问题是,虽然可以实现一个基于 A 的 DFS 去解决这个问题,但实际情况是我们并不着急解决这个问题,因为内存空间往往是有富余的。
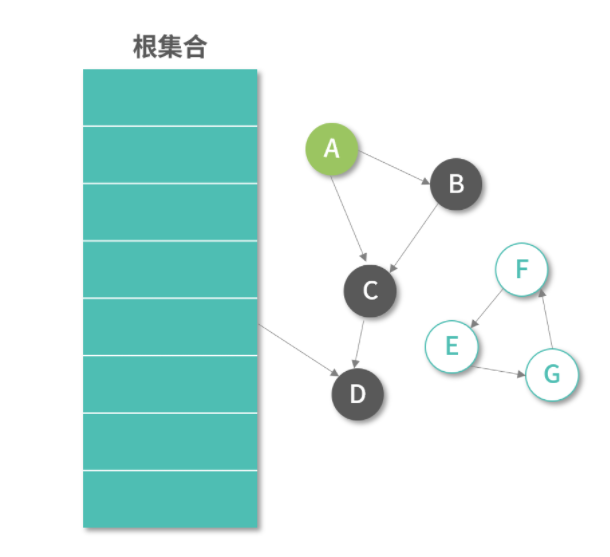
在调整已有的引用关系时,三色标记算法的表现明显更好。下图是对象 B 将对 C 的引用改成了对 F 的引用,C,F 被加入灰色集合。接下来 GC 会递归遍历 C,F,最终然后 F,E,G 都会进入灰色集合。
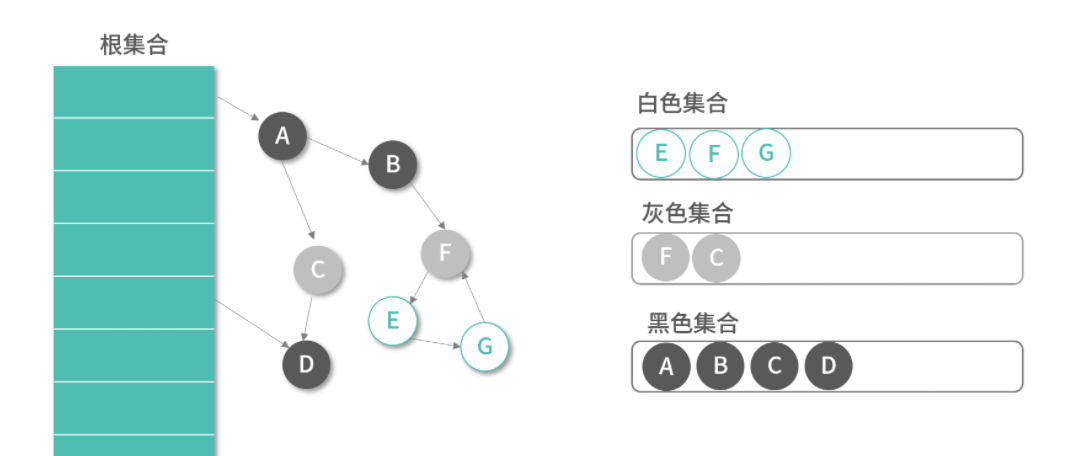
内存回收就好比有人在随手扔垃圾,清洁工需要不停打扫。如果清洁工能够跟上人们扔垃圾的速度,那么就不需要太多的 STL(Stop The World)。如果清洁工跟不上扔垃圾的速度,最终环境就会被全部弄乱,这个时候清洁工就会要求“Stop The World”。三色算法的优势就在于它支持多一些情况的 Mutation,这样能够提高“垃圾”被并发回收的概率。
目前的 GC 主要都是基于三色标记算法。 至于清除算法,有原地回收算法,也有把存活下来的对象(黑色对象)全部拷贝到一个新的区域的算法。
碎片整理和生代技术
三色标记-清除算法,还没有解决内存回收产生碎片的问题。通常,我们会在三色标记-清除算法之上,再构建一个整理内存(Compact)的算法。如下图所示:
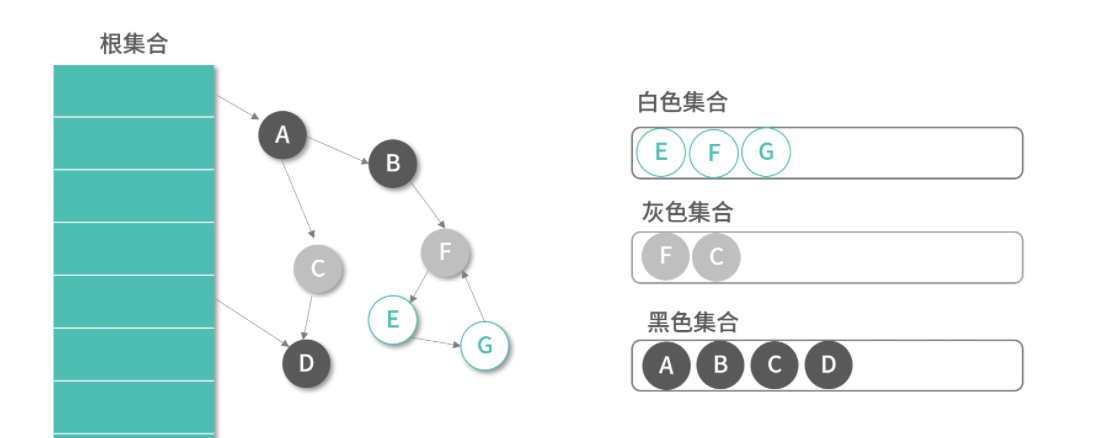
Compact 算法将对象重新挤压到一起,让更多空间可以被使用。我们在设计这个算法时,观察到了一个现象:新创建出来的对象,死亡(被回收)概率会更高,而那些已经存在了一段时间的对象,往往更不容易死亡。这有点类似 LRU 缓存,其实是一个概率问题。接下来我们考虑针对这个现象进行优化。

如上图所示,你可以把新创建的对象,都先放到一个统一的区域,在 Java 中称为伊甸园(Eden)。这个区域因为频繁有新对象死亡,因此需要经常 GC。考虑整理使用中的对象成本较高,因此可以考虑将存活下来的对象拷贝到另一个区域,Java 中称为存活区(Survior)。存活区生存下来的对象再进入下一个区域,Java 中称为老生代。
上图展示的三个区域,Eden、Survior 及老生代之间的关系是对象的死亡概率逐级递减,对象的存活周期逐级增加。三个区域都采用三色标记-清除算法。每次 Eden 存活下来的对象拷贝到 Survivor 区域之后,Eden 就可以完整的回收重利用。Eden 可以考虑和 Survivor 用 1:1 的空间,老生代则可以用更大的空间。Eden 中全量 GC 可以频繁执行,也可以增量 GC 混合全量 GC 执行。老生代中的 GC 频率可以更低,偶尔执行一次全量的 GC。
GC 的选择
最后我们来聊聊 GC 的选择。通常选择 GC 会有实时性要求(最大容忍的暂停时间),需要从是否为高并发场景、内存实际需求等维度去思考。在选择 GC 的时候,复杂的算法并不一定更有效。下面是一些简单有效的思考和判断。
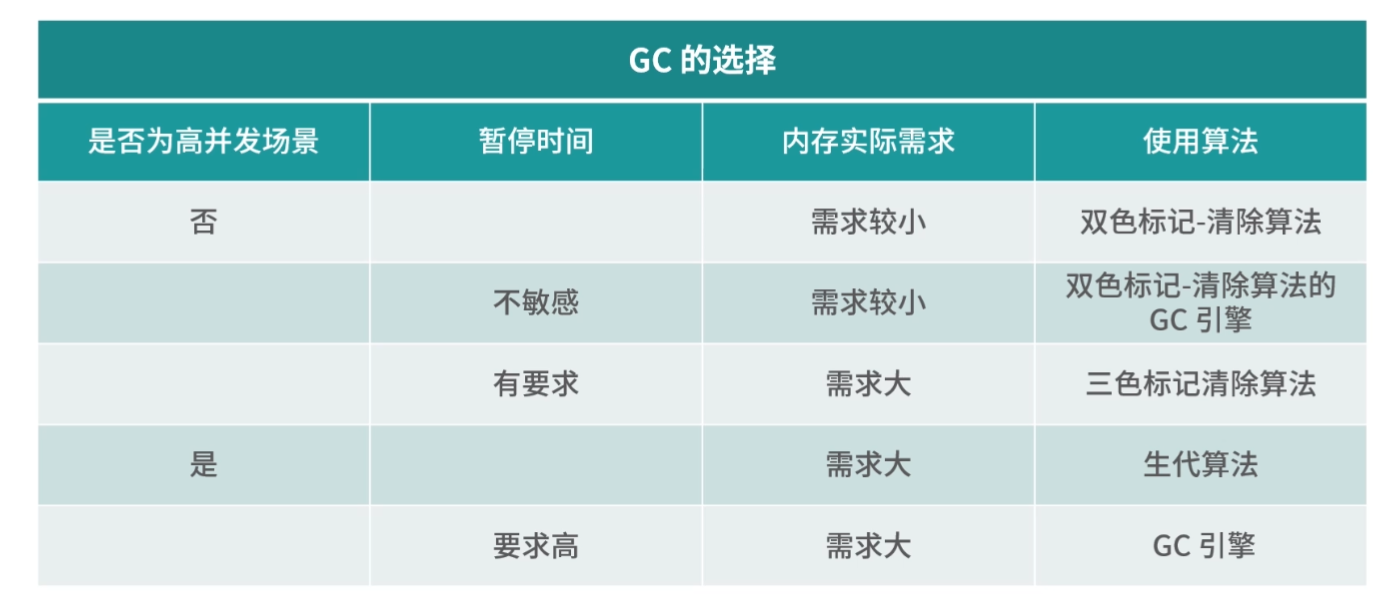
- 如果你的程序内存需求较小,GC 压力小,这个时候每次用双色标记-清除算法,等彻底标记-清除完再执行应用程序,用户也不会感觉到多少延迟。双色标记-清除算法在这种场景可能会更加节省时间,因为程序简单。
- 对于一些对暂停时间不敏感的应用,比如说数据分析类应用,那么选择一个并发执行的双色标记-清除算法的 GC 引擎,是一个非常不错的选择。因为这种应用 GC 暂停长一点时间都没有关系,关键是要最短时间内把整个 GC 执行完成。
- 如果内存的需求大,同时对暂停时间也有要求,就需要三色标记清除算法,让部分增量工作可以并发执行。
- 如果在高并发场景,内存被频繁迭代,这个时候就需要生代算法。将内存划分出不同的空间,用作不同的用途。
- 如果实时性要求非常高,就需要选择专门针对实时场景的 GC 引擎,比如 Java 的 Z。
当然,并不是所有的语言都提供多款 GC 选择。但是通常每个语言都会提供很多的 GC 参数。这里也有一些最基本的思路,下面我为你介绍一下。
如果内存不够用,有两种解决方案。一种是降低吞吐量——相当于 GC 执行时间上升;另一种是增加暂停时间,暂停时间较长,GC 更容易集中资源回收内存。那么通常语言的 GC 都会提供设置吞吐量和暂停时间的 API。
如果内存够用,有的 GC 引擎甚至会选择当内存达到某个阈值之后,再启动 GC 程序。通常阈值也是可以调整的。因此如果内存够用,就建议让应用使用更多的内存,提升整体的效率。
- 如何解决内存的循环引用问题?
- 三色标记清除算法的工作原理?
解决循环引用的问题可以考虑利用 Root Tracing 类的 GC 算法。从根集合利用 DFS 或者 BFS 遍历所有子节点,最终不能和根集合连通的节点都是需要回收的。
三色标记算法利用三种颜色进行标记。白色代表需要回收的节点;黑色代表不需要回收的节点;灰色代表会被回收,但是没有完成标记的节点。
初始化的时候所有节点都标记为白色,然后利用 DFS 从 Root 集合遍历所有节点。每遍历到一个节点就把这个节点放入灰色集合,如果这个节点所有的子节点都遍历完成,就把这个节点放入黑色的集合。最后白色集合中剩下的就是需要回收的元素。
可不可以利用哈希表直接将页编号映射到 Frame 编号?
按照普通页表的设计,如果页大小是 4K,1G 空间内存需要 262144 个页表条目,如果每个条目用 4 个字节来存储,就需要 1M 的空间。那么创建 1T 的虚拟内存,就需要 1G 的空间。这意味着操作系统需要在启动时,就把这块需要的内存空间预留出来。
正因为我们设计的虚拟内存往往大于实际的内存,因此在历史上出现过各种各样节省页表空间的方案,其中就有用 HashTable 存储页表的设计。HashTable 是一种将键(Key)映射到值(Value)的数据结构。在页表的例子中,键是页编号,值是 Frame 编号。 你可以把这个 HashTable 看作存储了很多 <PageId, FrameId> 键值对的数据结构。
为了方便你理解下面的内容,我绘制了一张图。下图使用了一个有 1024 个条目的 HashTable。当查找页面 50000 的时候,先通过哈希函数 h 计算出 50000 对应的 HashTable 条目是 24。HashTable 的每个条目都是一个链表,链表的每个节点是一个 PageId 和 FrameId 的组合。接下来,算法会遍历条目 24 上的链表,然后找到 Page = 50000 的节点。取出 Frame 编号为 1232。
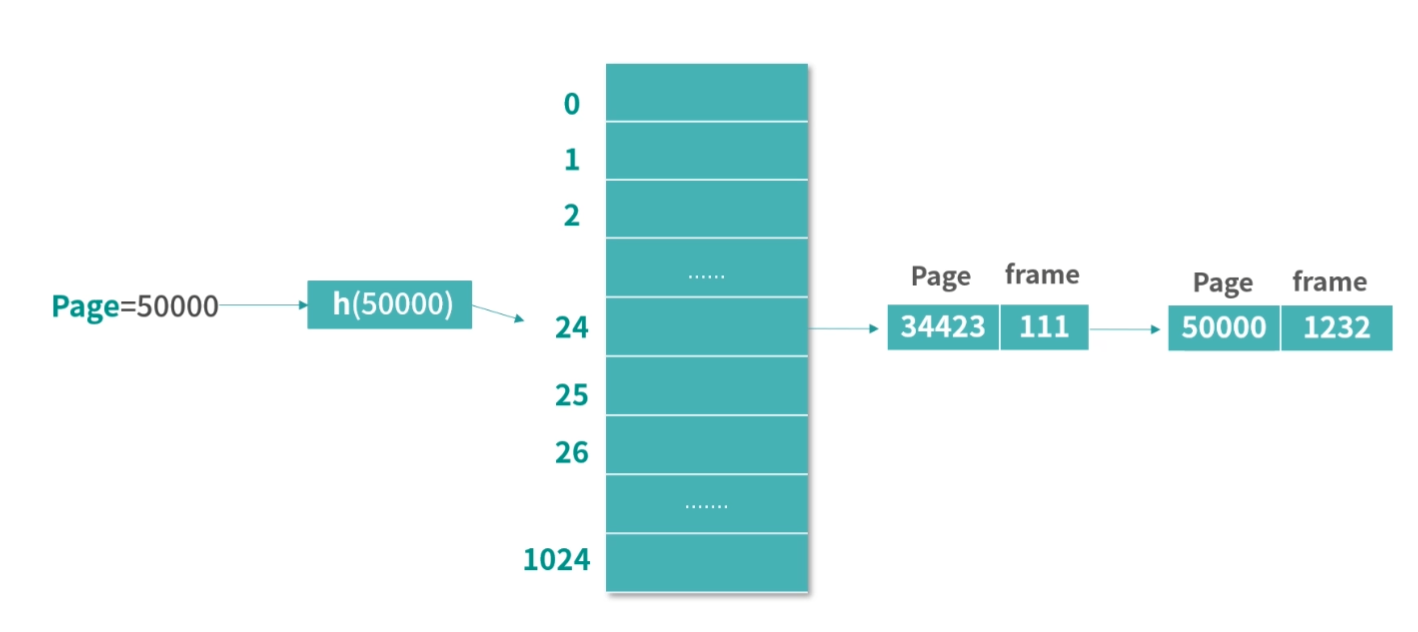
通常虚拟内存会有非常多的页,但是只有少数的页会被使用到。这种情况下,用传统的页表,会导致过多的空间被预分配。而基于 HashTable 的设计则不同,可以先分配少量的项,比如在上图中,先只分配了 1024 个项。每次查找一个页表编号发现不存在的情况,再去对应位置的链表中添加一个具体的键-值对。 这样就大大节省了内存。
当然节省空间也是有代价的,这会直接导致性能下降,因为比起传统页表我们可以直接通过页的编号知道页表条目,基于 HashTable 的做法需要先进行一次 Hash 函数的计算,然后再遍历一次链表。 最后,HashTable 的时间复杂度可以看作 O(k),k 为 HashTable 表中总共的 <k,v> 数量除以哈希表的条目数。当 k 较小的时候 HashTable 的时间复杂度趋向于 O(1)。
Java 和 Go 默认需不需要开启大内存分页?
在回答什么情况下使用前,我们先说说这两个语言对大内存分页的支持。
当然,两门语言能够使用大内存分页的前提条件,是通过“25 讲”中演示的方式,开启了操作系统的大内存分页。满足这个条件后,我们再来说说两门语言还需要做哪些配置。
Go 语言
Go 是一门编译执行的语言。在 Go 编译器的前端,源代码被转化为 AST;在 Go 编译器的后端,AST 经过若干优化步骤,转化为目标机器代码。因此 Go 的内存分配程序基本上可以直接和操作系统的 API 对应。因为 Go 没有虚拟机。
而且 Go 提供了一个底层的库 syscall,直接支持上百个系统调用。 具体请参考Go 的官方文档。其中的 syscall.madvise 系统调用,可以直接提示操作系统某个内存区间的程序是否使用大内存分页技术加速 TLB 的访问。具体可以参考 Linux 中madise 的文档,这个工具的作用主要是提示操作系统如何使用某个区域的内存,开启大内存分页是它之中的一个选项。
下面的程序通过 malloc 分配内存,然后用 madvise 提示操作系统使用大内存分页的示例:
1 | #include <sys/mman.h> |
如果放到 Go 语言,那么需要用的是runtime.sysAlloc和syscall.Madvise函数。
Java 语言
JVM 是一个虚拟机,应用了Just-In-Time 在虚拟指令执行的过程中,将虚拟指令转换为机器码执行。 JVM 自己有一套完整的动态内存管理方案,而且提供了很多内存管理工具可选。在使用 JVM 时,虽然 Java 提供了 UnSafe 类帮助我们执行底层操作,但是通常情况下我们不会使用UnSafe 类。一方面 UnSafe 类功能不全,另一方面看名字就知道它过于危险。
Java 语言在“25 讲”中提到过有一个虚拟机参数:XX:+UseLargePages,开启这个参数,JVM 会开始尝试使用大内存分页。
那么到底该不该用大内存分页?
首先可以分析下你应用的特性,看看有没有大内存分页的需求。通常 OS 是 4K,思考下你有没有需要反复用到大内存分页的场景。
另外你可以使用perf指令衡量你系统的一些性能指标,其中就包括iTLB-load-miss可以用来衡量 TLB Miss。 如果发现自己系统的 TLB Miss 较高,那么可以深入分析是否需要开启大内存分页。
在 TLB 多路组相联缓存设计中(比如 8-way),如何实现 LRU 缓存?
TLB 是 CPU 的一个“零件”,在 TLB 的设计当中不可能再去内存中创建数据结构。因此在 8 路组相联缓存设计中,我们每次只需要从 8 个缓存条目中选择 Least Recently Used 缓存。
增加累计值
先说一种方法, 比如用硬件同时比较 8 个缓存中记录的缓存使用次数。这种方案需要做到 2 点:
- 缓存条目中需要额外的空间记录条目的使用次数(累计位)。类似我们在页表设计中讨论的基于计时器的读位操作——每过一段时间就自动将读位累计到一个累计位上。
- 硬件能够实现一个快速查询最小值的算法。
第 1 种方法会产生额外的空间开销,还需要定时器配合,成本较高。 注意缓存是很贵的,对于缓存空间利用自然能省则省。而第 2 种方法也需要额外的硬件设计。那么,有没有更好的方案呢?
1bit 模拟 LRU
一个更好的方案就是模拟 LRU,我们可以考虑继续采用上面的方式,但是每个缓存条目只拿出一个 LRU 位(bit)来描述缓存近期有没有被使用过。 缓存置换时只是查找 LRU 位等于 0 的条目置换。
还有一个基于这种设计更好的方案,可以考虑在所有 LRU 位都被置 1 的时候,清除 8 个条目中的 LRU 位(置零),这样可以节省一个计时器。 相当于发生内存操作,LRU 位置 1;8 个位置都被使用,LRU 都置 0。
搜索树模拟 LRU
最后我再介绍一个巧妙的方法——用搜索树模拟 LRU。
对于一个 8 路组相联缓存,这个方法需要 8-1 = 7bit 去构造一个树。如下图所示:
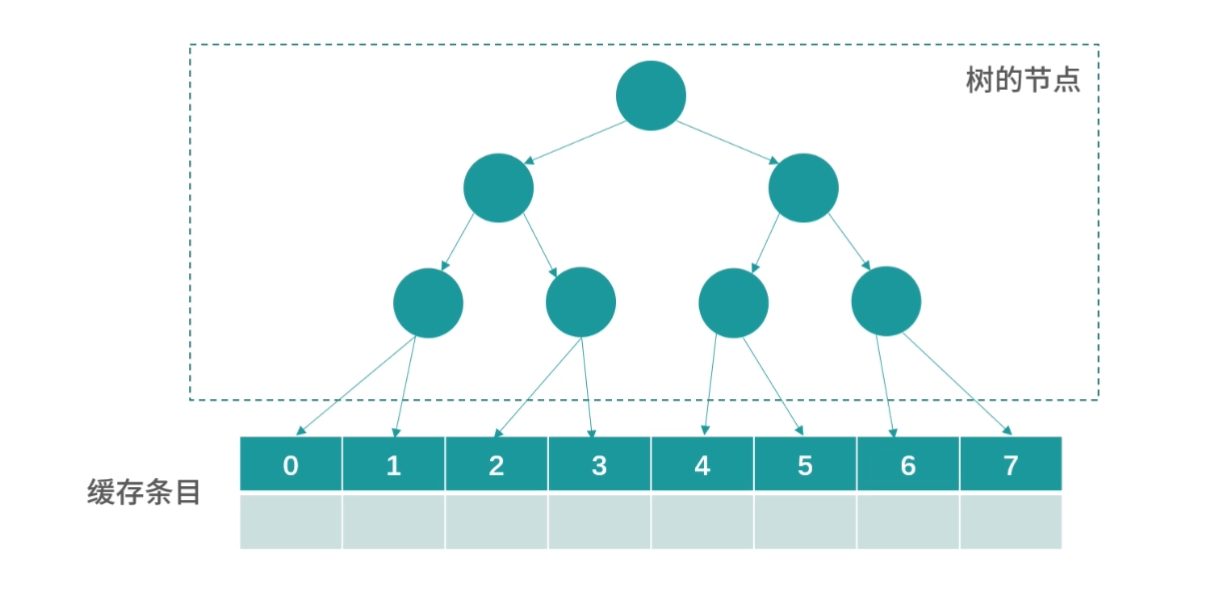
8 个缓存条目用 7 个节点控制,每个节点是 1 位。0 代表节点指向左边,1 代表节点指向右边。
初始化的时候,所有节点都指向左边,如下图所示:
接下来每次写入,会从根节点开始寻找,顺着箭头方向(0 向左,1 向右),找到下一个更新方向。比如现在图中下一个要更新的位置是 0。更新完成后,所有路径上的节点箭头都会反转,也就是 0 变成 1,1 变成 0。
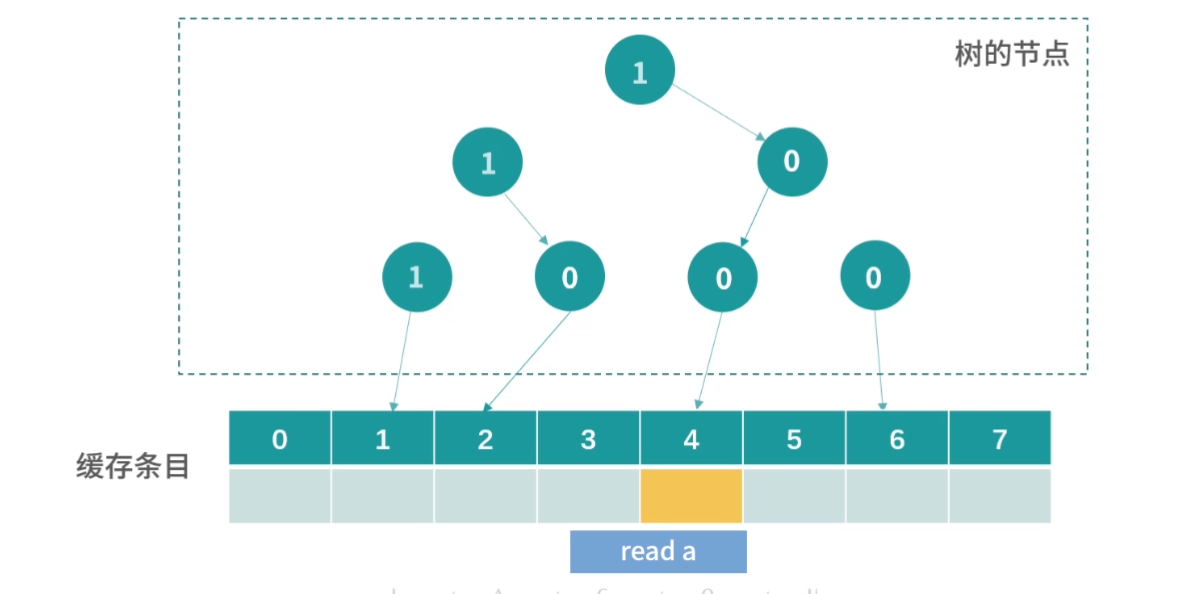
上图是read a后的结果,之前路径上所有的箭头都被反转,现在看到下一个位置是 4,我用橘黄色进行了标记。
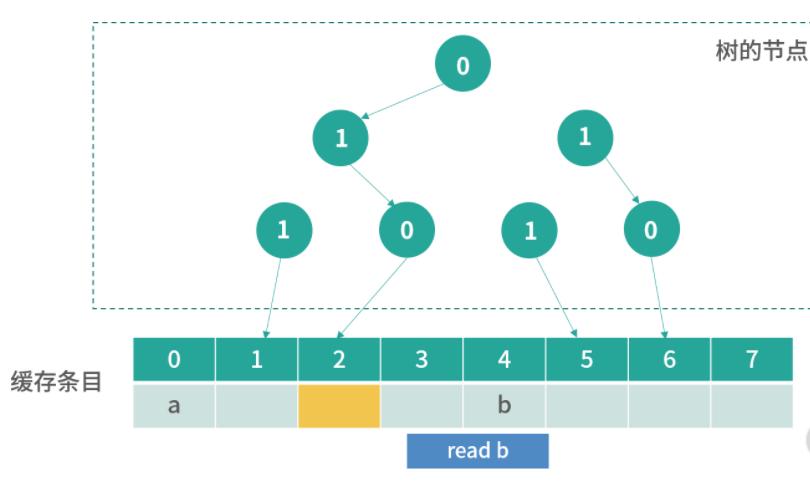
上图是发生操作read b之后的结果,现在橘黄色可以更新的位置是 2。
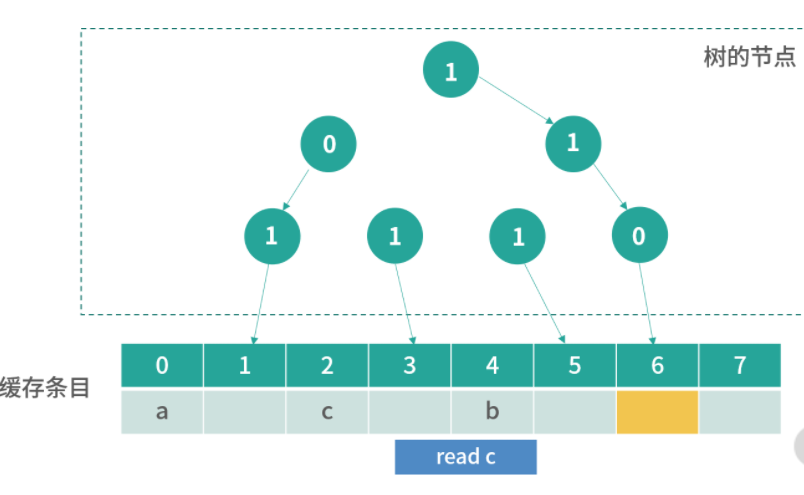
上图是读取 c 后的情况。后面我不一一绘出,假设后面的读取顺序是d,e,f,g,h,那么缓存会变成如下图所示的结果:
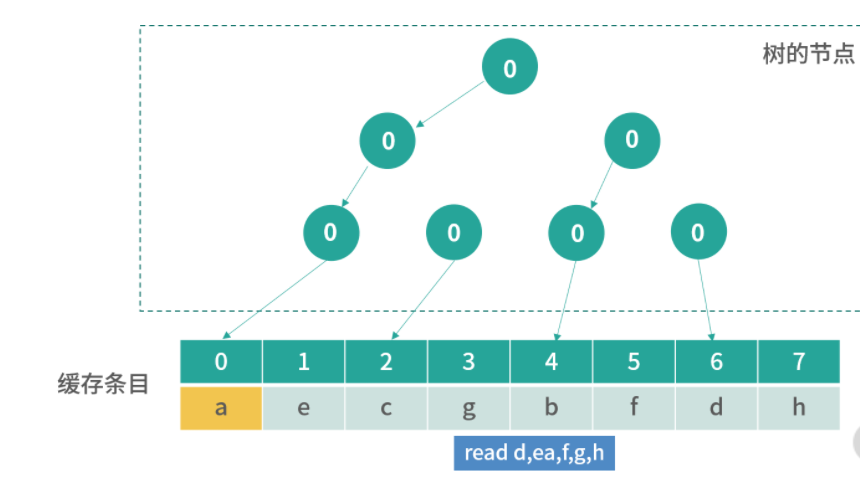
这个时候用户如果读取了已经存在的值,比如说c,那么指向c那路箭头会被翻转,下图是read c的结果:
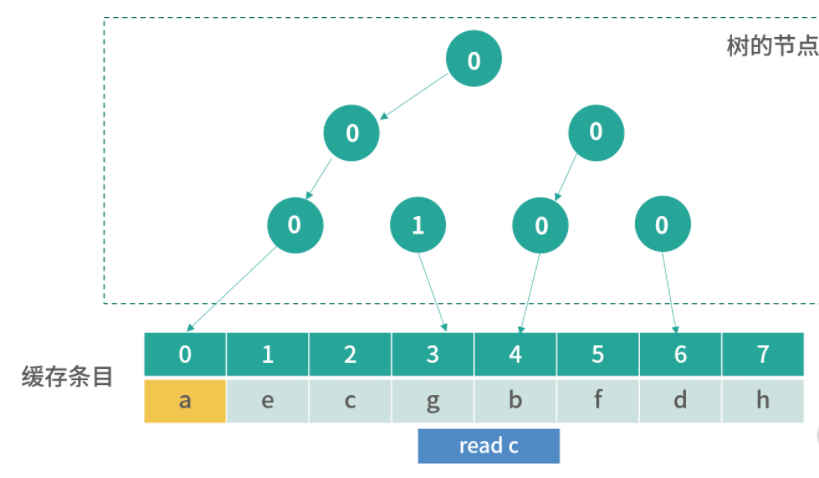
这个结果并没有改变下一个更新的位置,但是翻转了指向 c 的路径。 如果要读取x,那么这个时候就会覆盖橘黄色的位置。
因此,本质上这种树状的方式,其实是在构造一种先入先出的顺序。任何一个节点箭头指向的子节点,应该被先淘汰(最早被使用)。
这是一个我个人觉得非常天才的设计,因为如果在这个地方构造一个队列,然后每次都把命中的元素的当前位置移动到队列尾部。就至少需要构造一个链表,而链表的每个节点都至少要有当前的值和 next 指针,这就需要创建复杂的数据结构。在内存中创建复杂的数据结构轻而易举,但是在 CPU 中就非常困难。 所以这种基于 bit-tree,就轻松地解决了这个问题。当然,这是一个模拟 LRU 的情况,你还是可以构造出违反 LRU 缓存的顺序。
如果内存太大了,无论是标记还是清除速度都很慢,执行一次完整的 GC 速度下降该如何处理?
当应用申请到的内存很大的时候,如果其中内部对象太多。只简单划分几个生代,每个生代占用的内存都很大,这个时候使用 GC 性能就会很糟糕。
一种参考的解决方案就是将内存划分成很多个小块,类似在应用内部再做一个虚拟内存层。 每个小块可能执行不同的内存回收策略。
上图中绿色、蓝色和橘黄色代表 3 种不同的区域。绿色区域中对象存活概率最低(类似 Java 的 Eden),蓝色生存概率上升,橘黄色最高(类似 Java 的老生代)。灰色区域代表应用从操作系统中已经申请了,但尚未使用的内存。通过这种划分方法,每个区域中进行 GC 的开销都大大减少。Java 目前默认的内存回收器 G1,就是采用上面的策略。
通过内存管理的学习,我希望你开始理解虚拟化的价值,内存管理部分的虚拟化,是一种应对资源稀缺、增加资源流动性的手段(听起来那么像银行印的货币)。
Linux 下的各个目录有什么作用?
学习文件系统的意义在于文件系统有很多设计思路可以迁移到实际的工作场景中,比如:
- MySQL 的 binlog 和 Redis AOF 都像极了日志文件系统的设计;
- B Tree 用于加速磁盘数据访问的设计,对于索引设计也有通用的意义。
特别是近年来分布式系统的普及,学习分布式文件系统,也是理解分布式架构最核心的一个环节。其实文件系统最精彩的还是虚拟文件系统的设计,比如 Linux 可以支持每个目录用不同的文件系统。这些文件看上去是一个个目录和文件,实际上可能是磁盘、内存、网络文件系统、远程磁盘、网卡、随机数产生器、输入输出设备等,这样虚拟文件系统就成了整合一切设备资源的平台。大量的操作都可以抽象成对文件的操作,程序的书写就会完整而统一,且扩展性强。
这一讲,我会从 Linux 的目录结构和用途开始,带你认识 Linux 的文件系统。Linux 所有的文件都建立在虚拟文件系统(Virtual File System ,VFS)之上,如下图所示:
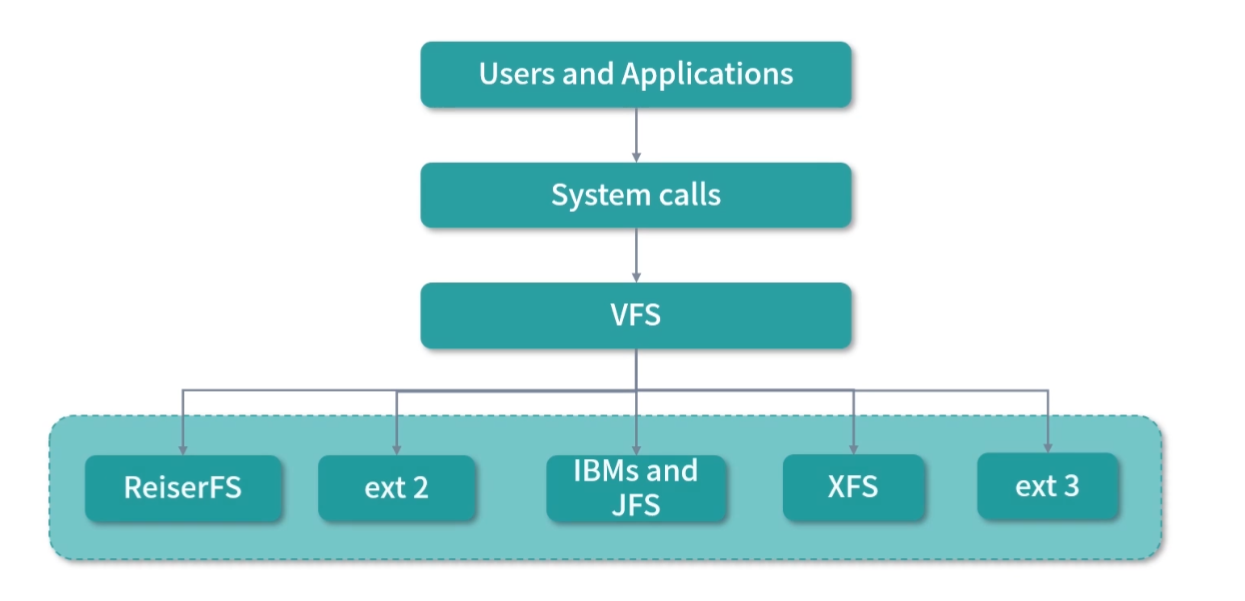
分区结构
在 Linux 中,/是根目录。之前我们在“08 讲”提到过,每个目录可以是不同的文件系统(不同的磁盘或者设备)。你可能会问我,/是对应一个磁盘还是多个磁盘呢?在/创建目录的时候,目录属于哪个磁盘呢?
当你访问一个目录或者文件,虽然用的是 Linux 标准的文件 API 对文件进行操作,但实际操作的可能是磁盘、内存、网络或者数据库等。因此,Linux 上不同的目录可能是不同的磁盘,不同的文件可能是不同的设备。
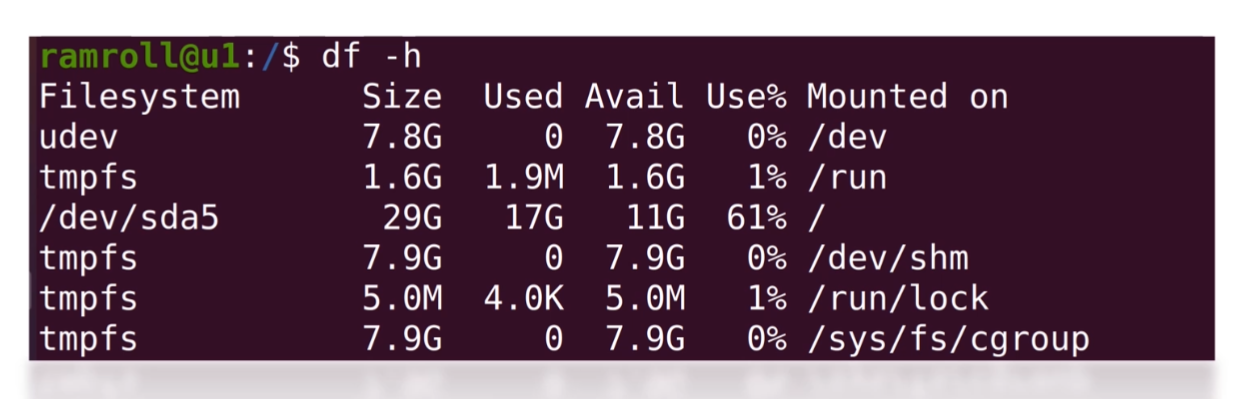
你可以用df -h查看上面两个问题的答案,在上图中我的/挂载到了/dev/sda5上。如果你想要看到更多信息,可以使用df -T,如下图所示:
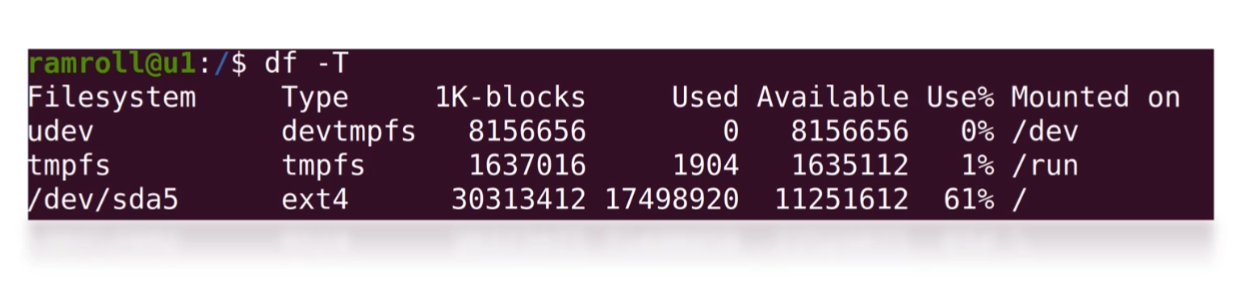
/的文件系统类型是ext4。这是一种常用的日志文件系统。关于日志文件系统,我会在“30 讲”为你介绍。然后你可能还会有一个疑问,/dev/sda5究竟是一块磁盘还是别的什么?这个时候你可以用fdisk -l查看,结果如下图:
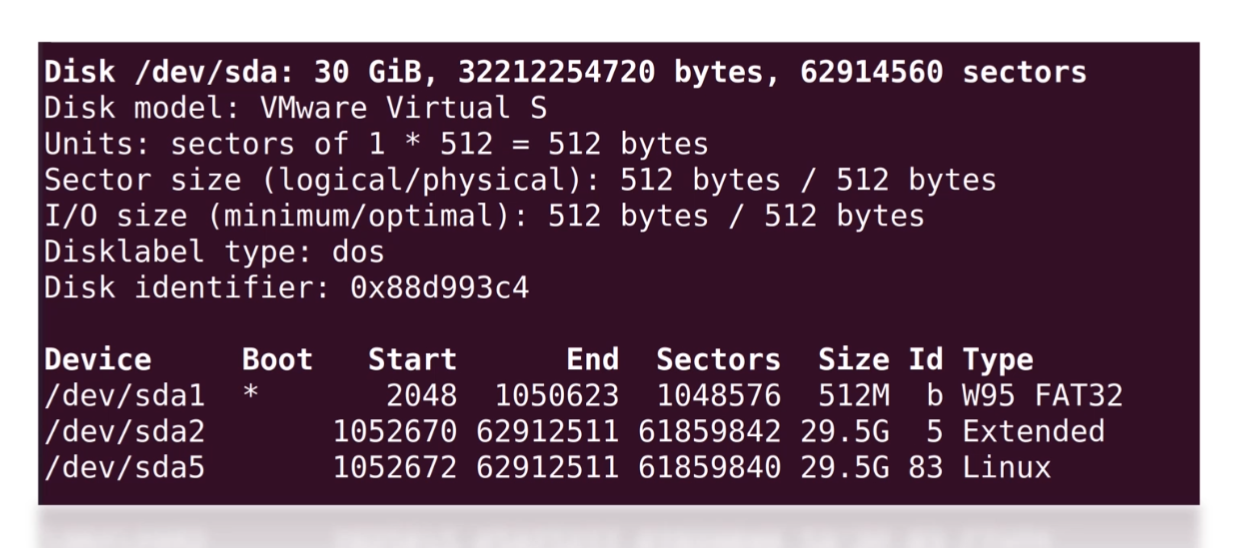
你可以看到我的 Linux 虚拟机上,有一块 30G 的硬盘(当然是虚拟的)。然后这块硬盘下有 3 个设备(Device):/dev/sda1, /dev/sda2 和 /dev/sda5。在 Linux 中,数字 1~4 结尾的是主分区,通常一块磁盘最多只能有 4 个主分区用于系统启动。主分区之下,还可以再分成若干个逻辑分区,4 以上的数字都是逻辑分区。因此/dev/sda2和/dev/sda5是主分区包含逻辑分区的关系。
挂载
分区结构最终需要最终挂载到目录上。上面例子中/dev/sda5分区被挂载到了/下。 这样在/创建的文件都属于这个/dev/sda5分区。 另外,/dev/sda5采用ext4文件系统。可见不同的目录可以采用不同的文件系统。
将一个文件系统映射到某个目录的过程叫作挂载(Mount)。当然这里的文件系统可以是某个分区、某个 USB 设备,也可以是某个读卡器等。你可以用mount -l查看已经挂载的文件系统。
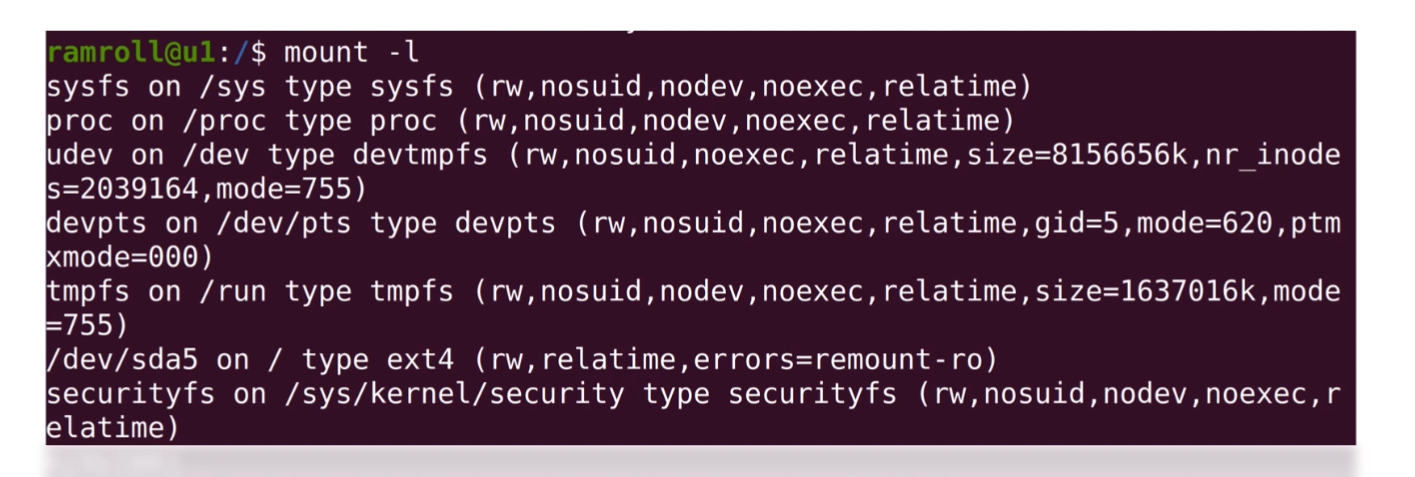
上图中的sysfs``proc``devtmpfs``tmpfs``ext4都是不同的文件系统,下面我们来说说它们的作用。
sysfs让用户通过文件访问和设置设备驱动信息。proc是一个虚拟文件系统,让用户可以通过文件访问内核中的进程信息。devtmpfs在内存中创造设备文件节点。tmpfs用内存模拟磁盘文件。ext4是一个通常意义上我们认为的文件系统,也是管理磁盘上文件用的系统。
你可以看到挂载记录中不仅有文件系统类型,挂载的目录(on 后面部分),还有读写的权限等。你也可以用mount指令挂载一个文件系统到某个目录,比如说:
1 | mount /dev/sda6 /abc |
上面这个命令将/dev/sda6挂载到目录abc。
目录结构
因为 Linux 内文件系统较多,用途繁杂,Linux 对文件系统中的目录进行了一定的归类,如下图所示:
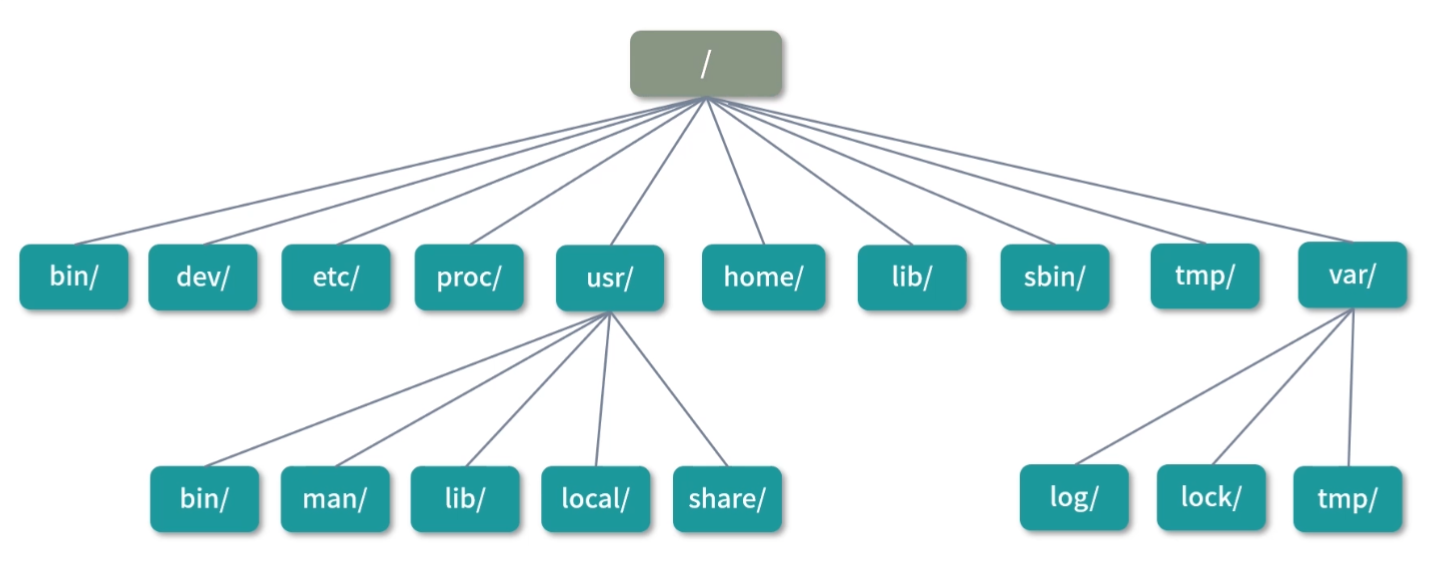
最顶层的目录称作根目录, 用/表示。/目录下用户可以再创建目录,但是有一些目录随着系统创建就已经存在,接下来我会和你一起讨论下它们的用途。
/bin(二进制)包含了许多所有用户都可以访问的可执行文件,如 ls, cp, cd 等。这里的大多数程序都是二进制格式的,因此称作bin目录。bin是一个命名习惯,比如说nginx中的可执行文件会在 Nginx 安装目录的 bin 文件夹下面。
/dev(设备文件) 通常挂载在devtmpfs文件系统上,里面存放的是设备文件节点。通常直接和内存进行映射,而不是存在物理磁盘上。
值得一提的是其中有几个有趣的文件,它们是虚拟设备。
/dev/null是可以用来销毁任何输出的虚拟设备。你可以用>重定向符号将任何输出流重定向到/dev/null来忽略输出的结果。
/dev/zero是一个产生数字 0 的虚拟设备。无论你对它进行多少次读取,都会读到 0。
/dev/ramdom是一个产生随机数的虚拟设备。读取这个文件中数据,你会得到一个随机数。你不停地读取这个文件,就会得到一个随机数的序列。
/etc(配置文件),/etc名字的含义是and so on……,也就是“等等及其他”,Linux 用它来保管程序的配置。比如说mysql通常会在/etc/mysql下创建配置。再比如说/etc/passwd是系统的用户配置,存储了用户信息。
/proc(进程和内核文件) 存储了执行中进程和内核的信息。比如你可以通过/proc/1122目录找到和进程1122关联的全部信息。还可以在/proc/cpuinfo下找到和 CPU 相关的全部信息。
/sbin(系统二进制) 和/bin类似,通常是系统启动必需的指令,也可以包括管理员才会使用的指令。
/tmp(临时文件) 用于存放应用的临时文件,通常用的是tmpfs文件系统。因为tmpfs是一个内存文件系统,系统重启的时候清除/tmp文件,所以这个目录不能放应用和重要的数据。
/var (Variable data file,,可变数据文件) 用于存储运行时的数据,比如日志通常会存放在/var/log目录下面。再比如应用的缓存文件、用户的登录行为等,都可以放到/var目录下,/var下的文件会长期保存。
/boot(启动) 目录下存放了 Linux 的内核文件和启动镜像,通常这个目录会写入磁盘最头部的分区,启动的时候需要加载目录内的文件。
/opt(Optional Software,可选软件) 通常会把第三方软件安装到这个目录。以后你安装软件的时候,可以考虑在这个目录下创建。
/root(root 用户家目录) 为了防止误操作,Linux 设计中 root 用户的家目录没有设计在/home/root下,而是放到了/root目录。
/home(家目录) 用于存放用户的个人数据,比如用户lagou的个人数据会存放到/home/lagou下面。并且通常在用户登录,或者执行cd指令后,都会在家目录下工作。 用户通常会对自己的家目录拥有管理权限,而无法访问其他用户的家目录。
/media(媒体) 自动挂载的设备通常会出现在/media目录下。比如你插入 U 盘,通常较新版本的 Linux 都会帮你自动完成挂载,也就是在/media下创建一个目录代表 U 盘。
/mnt(Mount,挂载) 我们习惯把手动挂载的设备放到这个目录。比如你插入 U 盘后,如果 Linux 没有帮你完成自动挂载,可以用mount命令手动将 U 盘内容挂载到/mnt目录下。
/svr(Service Data,,服务数据) 通常用来存放服务数据,比如说你开发的网站资源文件(脚本、网页等)。不过现在很多团队的习惯发生了变化, 有的团队会把网站相关的资源放到/www目录下,也有的团队会放到/data下。总之,在存放资源的角度,还是比较灵活的。
/usr(Unix System Resource) 包含系统需要的资源文件,通常应用程序会把后来安装的可执行文件也放到这个目录下,比如说
vim编辑器的可执行文件通常会在/usr/bin目录下,区别于ls会在/bin目录下/usr/sbin中会包含有通常系统管理员才会使用的指令。/usr/lib目录中存放系统的库文件,比如一些重要的对象和动态链接库文件。/usr/lib目录下会有大量的.so文件,这些叫作Shared Object,类似windows下的dll文件。/usr/share目录下主要是文档,比如说 man 的文档都在/usr/share/man下面。
FAT、NTFS 和 Ext3 文件系统有什么区别?
10 年前 FAT 文件系统还是常见的格式,而现在 Windows 上主要是 NTFS,Linux 上主要是 Ext3、Ext4 文件系统。关于这块知识,一般资料只会从支持的磁盘大小、数据保护、文件名等各种维度帮你比较,但是最本质的内容却被一笔带过。它们最大的区别是文件系统的实现不同,具体怎么不同?文件系统又有哪些实现?这一讲,我将带你一起来探索和学习这部分知识。
硬盘分块
在了解文件系统实现之前,我们先来了解下操作系统如何使用硬盘。
使用硬盘和使用内存有一个很大的区别,内存可以支持到字节级别的随机存取,而这种情况在硬盘中通常是不支持的。过去的机械硬盘内部是一个柱状结构,有扇区、柱面等。读取硬盘数据要转动物理的磁头,每转动一次磁头时间开销都很大,因此一次只读取一两个字节的数据,非常不划算。
随着 SSD 的出现,机械硬盘开始逐渐消失(还没有完全结束),现在的固态硬盘内部是类似内存的随机存取结构。但是硬盘的读写速度还是远远不及内存。而连续读多个字节的速度,还远不如一次读一个硬盘块的速度。
因此,为了提高性能,通常会将物理存储(硬盘)划分成一个个小块,比如每个 4KB。这样做也可以让硬盘的使用看起来非常整齐,方便分配和回收空间。况且,数据从磁盘到内存,需要通过电子设备,比如 DMA、总线等,如果一个字节一个字节读取,速度较慢的硬盘就太耗费时间了。过去的机械硬盘的速度可以比内存慢百万倍,现在的固态硬盘,也会慢几十到几百倍。即便是最新的 NvMe 接口的硬盘,和内存相比速度仍然有很大的差距。因此,一次读/写一个块(Block)才是可行的方案。
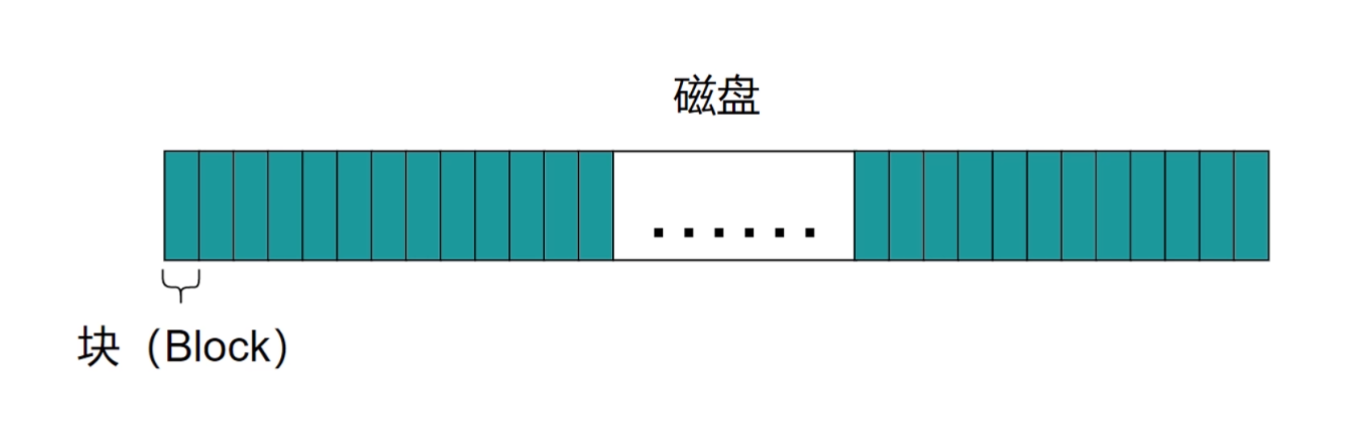
如上图所示,操作系统会将磁盘分成很多相等大小的块。这样做还有一个好处就是如果你知道块的序号,就可以准确地计算出块的物理位置。
文件的描述
我们将硬盘分块后,如何利用上面的硬盘存储文件,就是文件系统(File System)要负责的事情了。当然目录也是一种文件,因此我们先讨论文件如何读写。不同的文件系统利用方式不同,今天会重点讨论 3 种文件系统:
- 早期的 FAT 格式
- 基于 inode 的传统文件系统
- 日志文件系统(如 NTFS, EXT2、3、4)
FAT 表
早期人们找到了一种方案就是文件分配表(File Allocate Table,FAT)。如下图所示:

一个文件,最基本的就是要描述文件在硬盘中到底对应了哪些块。FAT 表通过一种类似链表的结构描述了文件对应的块。上图中:文件 1 从位置 5 开始,这就代表文件 1 在硬盘上的第 1 个块的序号是 5 的块 。然后位置 5 的值是 2,代表文件 1 的下一个块的是序号 2 的块。顺着这条链路,我们可以找到 5 → 2 → 9 → 14 → 15 → -1。-1 代表结束,所以文件 1 的块是:5,2,9,14,15。同理,文件 2 的块是 3,8,12。
FAT 通过一个链表结构解决了文件和物理块映射的问题,算法简单实用,因此得到过广泛的应用,到今天的 Windows/Linux/MacOS 都还支持 FAT 格式的文件系统。FAT 的缺点就是非常占用内存,比如 1T 的硬盘,如果块的大小是 1K,那么就需要 1G 个 FAT 条目。通常一个 FAT 条目还会存一些其他信息,需要 2~3 个字节,这就又要占用 2-3G 的内存空间才能用 FAT 管理 1T 的硬盘空间。显然这样做是非常浪费的,问题就出在了 FAT 表需要全部维护在内存当中。
索引节点(inode)
为了改进 FAT 的容量限制问题,可以考虑为每个文件增加一个索引节点(inode)。这样,随着虚拟内存的使用,当文件导入内存的时候,先导入索引节点(inode),然后索引节点中有文件的全部信息,包括文件的属性和文件物理块的位置。
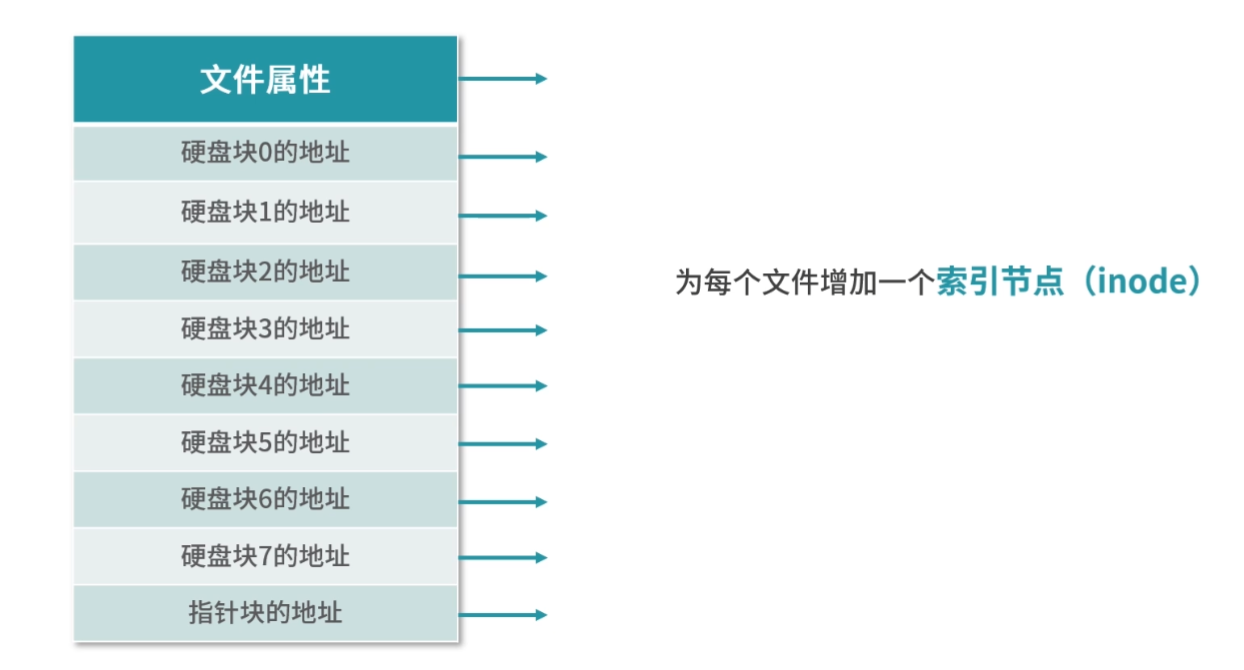
如上图,索引节点除了属性和块的位置,还包括了一个指针块的地址。这是为了应对文件非常大的情况。一个大文件,一个索引节点存不下,需要通过指针链接到其他的块去描述文件。
这种文件索引节点(inode)的方式,完美地解决了 FAT 的缺陷,一直被沿用至今。FAT 要把所有的块信息都存在内存中,索引节点只需要把用到的文件形成数据结构,而且可以使用虚拟内存分配空间,随着页表置换,这就解决了 FAT 的容量限制问题。
目录的实现
有了文件的描述,接下来我们来思考如何实现目录(Directory)。目录是特殊的文件,所以每个目录都有自己的 inode。目录是文件的集合,所以目录的内容中必须有所有其下文件的 inode 指针。
文件名也最好不要放到 inode 中,而是放到文件夹中。这样就可以灵活设置文件的别名,及实现一个文件同时在多个目录下。
如上图,/foo 和 /bar 两个目录中的 b.txt 和 c.txt 其实是一个文件,但是拥有不同的名称。这种形式我们称作“硬链接”,就是多个文件共享 inode。
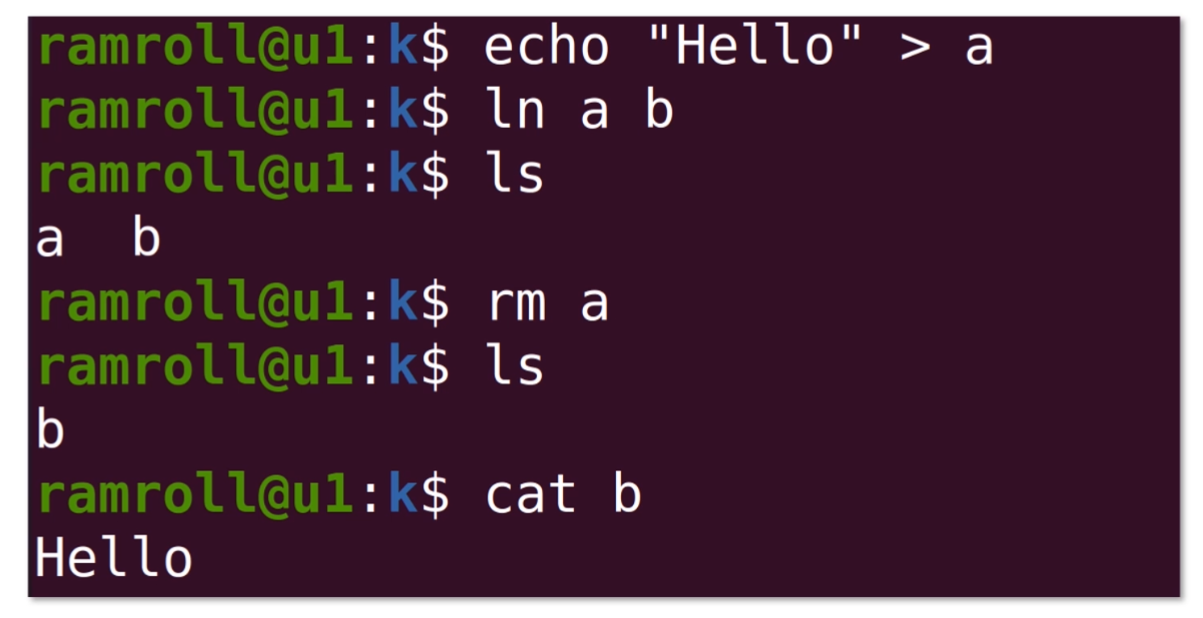
硬链接有一个非常显著的特点,硬链接的双方是平等的。上面的程序我们用ln指令为文件 a 创造了一个硬链接b。如果我们创造完删除了 a,那么 b 也是可以正常工作的。如果要删除掉这个文件的 inode,必须 a,b 同时删除。这里你可以看出 a,b 是平等的。
和硬链接相对的是软链接,软链接的原理如下图:
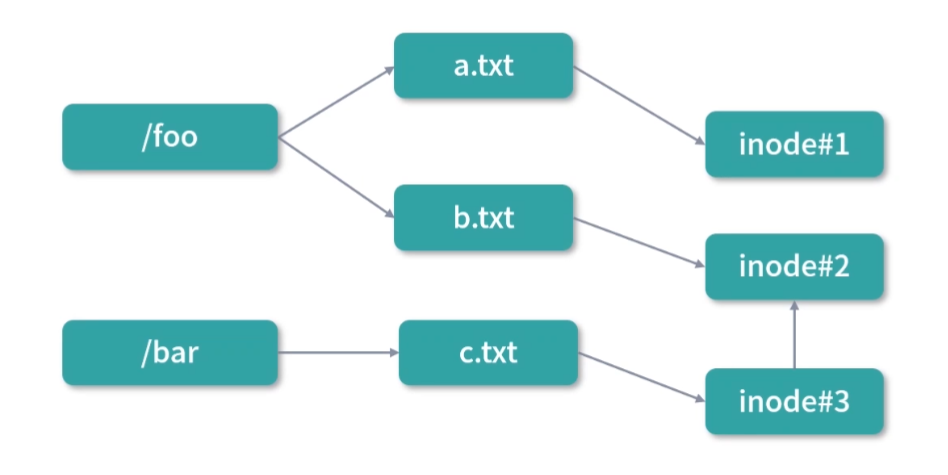
图中c.txt是b.txt的一个软链接,软链接拥有自己的inode,但是文件内容就是一个快捷方式。因此,如果我们删除了b.txt,那么b.txt对应的 inode 也就被删除了。但是c.txt依然存在,只不过指向了一个空地址(访问不到)。如果删除了c.txt,那么不会对b.txt造成任何影响。
在 Linux 中可以通过ln -s创造软链接。
1 | ln -s a b # 将b设置为a的软链接(b是a的快捷方式) |
以上,我们对文件系统的实现有了一个初步的了解。从整体设计上,本质还是将空间切块,然后划分成目录和文件管理这些分块。读、写文件需要通过 inode 操作磁盘。操作系统提供的是最底层读写分块的操作,抽象成文件就交给文件系统。比如想写入第 10001 个字节,那么会分成这样几个步骤:
- 修改内存中的数据
- 计算要写入第几个块
- 查询 inode 找到真实块的序号
- 将这个块的数据完整的写入一次磁盘
你可以思考一个问题,如果频繁读写磁盘,上面这个模型会有什么问题?可以把你的思考和想法写在留言区,我们在本讲后面会详细讨论。
解决性能和故障:日志文件系统
在传统的文件系统实现中,inode 解决了 FAT 容量限制问题,但是随着 CPU、内存、传输线路的速度越来越快,对磁盘读写性能的要求也越来越高。传统的设计,每次写入操作都需要进行一次持久化,所谓“持久化”就是将数据写入到磁盘,这种设计会成为整个应用的瓶颈。因为磁盘速度较慢,内存和 CPU 缓存的速度非常快,如果 CPU 进行高速计算并且频繁写入磁盘,那么就会有大量线程阻塞在等待磁盘 I/O 上。磁盘的瓶颈通常在写入上,因为通常读取数据的时候,会从缓存中读取,不存在太大的瓶颈。
加速写入的一种方式,就是利用缓冲区。
上图中所有写操作先存入缓冲区,然后每过一定的秒数,才进行一次持久化。 这种设计,是一个很好的思路,但最大的问题在于容错。 比如上图的步骤 1 或者步骤 2 只执行了一半,如何恢复?如果步骤 2 只写入了一半,那么数据就写坏了。如果步骤 1 只写入了一半,那么数据就丢失了。无论出现哪种问题,都不太好处理。更何况写操作和写操作之间还有一致性问题,比如说一次删除 inode 的操作后又发生了写入……
解决上述问题的一个非常好的方案就是利用日志。假设 A 是文件中某个位置的数据,比起传统的方案我们反复擦写 A,日志会帮助我们把 A 的所有变更记录下来,比如:
1 | A=1 |
上面 A 写入了 3 次,因此有 3 条日志。日志文件系统文件中存储的就是像上面那样的日志,而不是文件真实的内容。当用户读取文件的时候,文件内容会在内存中还原,所以内存中 A 的值是 3,但实际磁盘上有 3 条记录。
从性能上分析,如果日志造成了 3 倍的数据冗余,那么读取的速度并不会真的慢三倍。因为我们多数时候是从内存和 CPU 缓存中读取数据。而写入的时候,因为采用日志的形式,可以考虑下图这种方式,在内存缓冲区中积累一批日志才写入一次磁盘。
上图这种设计可以让写入变得非常快速,多数时间都是写内存,最后写一次磁盘。而上图这样的设计成不成立,核心在能不能解决容灾问题。
你可以思考一下这个问题——丢失一批日志和丢失一批数据的差别大不大。其实它们之间最大的差别在于,如果丢失一批日志,只不过丢失了近期的变更;但如果丢失一批数据,那么就可能造成永久伤害。
举个例子,比如说你把最近一天的订单数据弄乱了,你可以通过第三方支付平台的交易流水、系统的支付记录等帮助用户恢复数据,还可以通过订单关联的用户信息查询具体是哪些用户的订单出了问题。但是如果你随机删了一部分订单, 那问题就麻烦了。你要去第三发支付平台调出所有流水,用大数据引擎进行分析和计算。
为了进一步避免损失,一种可行的方案就是创建还原点(Checkpoint),比如说系统把最近 30s 的日志都写入一个区域中。下一个 30s 的日志,写入下一个区域中。每个区域,我们称作一个还原点。创建还原点的时候,我们将还原点涂成红色,写入完成将还原点涂成绿色。
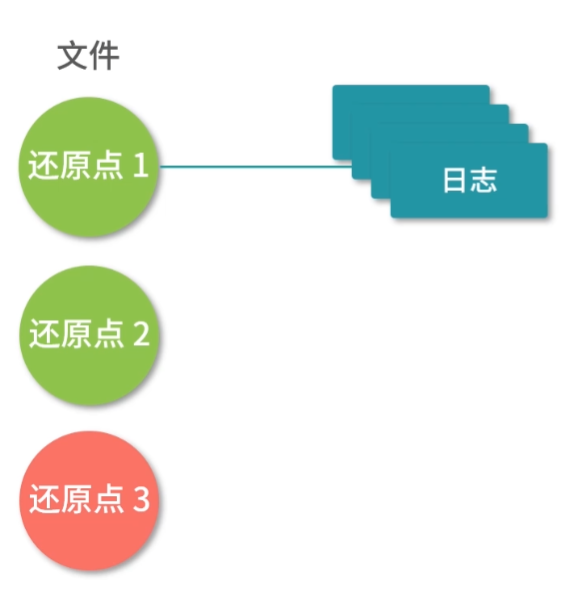
如上图,当日志文件系统写入磁盘的时候,每隔一段时间就会把这段时间内的所有日志写入一个或几个连续的磁盘块,我们称为还原点(Checkpoint)。操作系统读入文件的时候,依次读入还原点的数据,如果是绿色,那么就应用这些日志,如果是红色,就丢弃。所以上图中还原点 3 的数据是不完整的,这个时候会丢失不到 30s 的数据。如果将还原点的间隔变小,就可以控制风险的粒度。另外,我们还可以对还原点 3 的数据进行深度恢复,这里可以有人工分析,也可以通过一些更加复杂的算法去恢复。
- FAT 的设计简单高效,如果你要自己管理一定的空间,可以优先考虑这种设计。
- inode 的设计在内存中创造了一棵树状结构,对文件、目录进行管理,并且索引到磁盘中的数据。这是一种经典的数据结构,这种思路会被数据库设计、网络资源管理、缓存设计反复利用。
- 日志文件系统——日志结构简单、容易存储、按时间容易分块,这样的设计非常适合缓冲、批量写入和故障恢复。
现在我们很多分布式系统的设计也是基于日志,比如 MySQL 同步数据用 binlog,Redis 的 AOF,著名的分布式一致性算法 Paxos ,因此 Zookeeper 内部也在通过实现日志的一致性来实现分布式一致性。
FAT、NTFS 和 Ext3 有什么区别?
FAT 通过内存中一个类似链表的结构,实现对文件的管理。NTFS 和 Ext3 是日志文件系统,它们和 FAT 最大的区别在于写入到磁盘中的是日志,而不是数据。日志文件系统会先把日志写入到内存中一个高速缓冲区,定期写入到磁盘。日志写入是追加式的,不用考虑数据的覆盖。一段时间内的日志内容,会形成还原点。这种设计大大提高了性能,当然也会有一定的数据冗余。
MySQL 中 B 树和 B+ 树有什么区别?
B 树和 B+ 树是两种数据结构(关于它们的名字为什么以 B 开头,因为众说纷纭,本讲我就不介绍了),构建了磁盘中的高速索引结构,因此不仅 MySQL 在用,MongoDB、Oracle 等也在用,基本属于数据库的标配常规操作。
数据库要经常和磁盘与内存打交道,为了提升性能,通常需要自己去构建类似文件系统的结构。这一讲的内容有限,我只是先带你入一个门,如果你感兴趣后续可以自己深入学习。下面我们一起来探讨数据库如何利用磁盘空间设计索引。
行存储和列存储
在学习构建磁盘数据的索引结构前,我们先通过行存储、列存储的学习来了解一些基本的存储概念,帮助你建立一个基本的认知。
目前数据库存储一张表格主要是行存储(Row Storage)和列存储(Column Storage)两种存储方式。行存储将表格看作一个个记录,每个记录是一行。以包含订单号、金额、下单时间 3 项的表为例,行存储如下图所示:

如上图所示,在计算机中没有真正的行的概念。行存储本质就是数据一个接着一个排列,一行数据后面马上跟着另一行数据。如果订单表很大,一个磁盘块(Block)存不下,那么实际上就是每个块存储一定的行数。 类似下图这样的结构:

行存储更新一行的操作,往往可以在一个块(Block)中进行。而查询数据,聚合数据(比如求 4 月份的订单数),往往需要跨块(Block)。因此,行存储优点很明显,更新快、单条记录的数据集中,适合事务。但缺点也很明显,查询慢。
还有一种表格的存储方式是列存储(Column Storage),列存储中数据是一列一列存的。还以订单表为例,如下图所示:

你可以看到订单号在一起、姓名在一起、时间在一起、金额也在一起——每个列的数据都聚集在一起。乍一看这样的结构很低效,比如说你想取出第一条订单,需要取第 1 列的第 1 个数据1001,然后取第 2 列的第 1 个数据小明,以此类推,需要 4 次磁盘读取。特别是更新某一条记录的时候,需要更新多处,速度很慢。那么列存储优势在哪里呢?优势其实是在查询和聚合运算。
在列存储中同一列数据总是存放在一起,比如要查找某个时间段,很有可能在一个块中就可以找到,因为时间是集中存储的。假设磁盘块的大小是 4KB,一条记录是 100 字节, 那么 4KB 可以存 40 条记录;但是存储时间戳只需要一个 32 位整数,4KB 可以存储 1000 个时间。更关键的是,我们可以把一片连续的硬盘空间通过 DMA 技术直接映射到内存,这样就大大减少了搜索需要的时间。所以有时候在行存储需要几分钟的搜索操作,在列存储中只需几秒钟就可以完成。
总结一下,行存储、列存储,最终都需要把数据存到磁盘块。行存储记录一个接着一个,列存储一列接着一列。前面我们提到行存储适合更新及事务处理,更新好理解,因为一个订单可以在相同的 Block 中更新,那么为什么适合事务呢?
其实适合不适合是相对的,说行存储适合是因为列存储非常不适合事务。试想一下,你更新一个表的若干个数据,如果要在不同块中更新,就可能产生多次更新操作。更新次数越多,保证一致性越麻烦。在单机环境我们可以上锁,可以用阻塞队列,可以用屏障……但是分布式场景中保证一致性(特别是强一致性)开销很大。因此我们说行存储适合事务,而列存储不适合。
索引
接下来,我们在行存储、列存储的基础上,讨论如何创建一些更高效的查询结构,这种结构通常称为索引。我们经常会遇到根据一个订单编号查订单的情况,比如说select * from order where id=1000000,这个时候就需要用到索引。而下面我将试图通过二分查找的场景,和你一起讨论索引是什么。
在亿级的订单 ID 中查找某个编号,很容易想到二分查找。要理解二分查找,最需要关心的是算法的进步机制。这个算法每进行一次查找,都会让问题的规模减半。当然,也有场景限制,二分查找只能应用在排序好的数据上。
比如我们要在下面排序好的数组中查找 3:
1,3,5,8,11,12,15,19,21,25
数组中一共有 10 个元素,因此我们第一次查找从数组正中间的元素找起。如果数组正中间有两个元素,就取左边的那个——对于这个例子是 11。我们比较 11 和 3 的值,因为 11 大于 3,因此可以排除包括 11 在内的所有 11 右边的元素。相当于我们通过一次运算将数据的规模减半。假设我们有 240 (1T 数据)个元素需要查询(规模已经相当大了,万亿级别),用二分查找只需要 40 次运算。
所以按照这个思路,我们需要做的是将数据按照订单 ID 排好序,查询的时候就可以应用二分查找了。而且按照二分查找的思路,也可以进行范围查找。比如要查找 [a,b] 之间的数据,可以先通过二分查找找到 a 的序号,再二分找到 b 的序号,两个序号之间的数据就是目标结果。
但是直接在原始数据上排序,我们可能会把数据弄乱,常规做法是设计冗余数据描述这种排序关系——这就是索引。下面我通过一个简单的例子告诉你为什么不能在原始数据上直接排序。
假设我们有一个订单表,里面有订单 ID 和金额。使用列存储做演示如下:
订单 ID 列:
10005 10001 ……
订单金额列:
99.00 100.00 ……
可以看到,订单(10001)是第 2 个订单。但是进行排序后,订单(10001)会到第 1 个位置。这样会弄乱订单 ID(10001)和 金额(100.00)对应的关系。
因此我们必须用空间换时间,额外将订单列拷贝一份排序:
10001,2,10005, 1
以上这种专门用来进行数据查询的额外数据,就是索引。索引中的一个数据,也称作索引条目。上面的索引条目一个接着一个,每个索引条目是 <订单 ID, 序号> 的二元组。
如果你考虑是行存储(比如 MySQL),那么依然可以生成上面的索引,订单 ID 和序号(行号)关联。如果有多个索引,就需要创造多个上面的数据结构。如果有复合索引,比如 <订单状态、日期、序号> 作为一个索引条目,其实就是先按照订单状态,再按照日期排序的索引。
所以复合索引,无非就是多消耗一些空间,排序维度多一些。而且你可以看出复合索引和单列索引完全是独立关系,所以我们可以认为每创造一组索引,就创造了一份冗余的数据。也创造了一种特别的查询方式。关于索引还有很多有趣的知识,我们先介绍这些,如果感兴趣可以自己查资料深挖。
接下来,请分析一个非常核心的问题:上面的索引是一个连续的、从小到大的索引,那么应不应该使用这种从小到大排序的索引呢?例如,我们需要查询订单,就事先创建另一个根据订单 ID 从小到大排序的索引,当用户查找某个订单的时候,无论是行存储、还是列存储,我们就用二分查找查询对应的索引条目。这种方式,我们姑且称为线性排序索引——看似很不错的一个方式,但是并不是非常好的一种做法,请看我接下来的讨论。
二叉搜索树
线性排序的数据虽然好用,但是插入新元素的时候性能太低。如果是内存操作,插入一个元素,需要将这个元素之后的所有元素后移一位。但如果这个操作发生在磁盘中呢?这必然是灾难性的。因为磁盘的速度比内存慢至少 10-1000 倍,如果是机械硬盘可能慢几十万到百万倍。
所以我们不能用一种线性结构将磁盘排序。那么树呢? 比如二叉搜索树(Binary Serach Tree)行不行呢?利用磁盘的空间形成一个二叉搜索树,例如将订单 ID 作为二叉搜索树的 Key。
如下图所示,二叉搜索树的特点是一个节点的左子树的所有节点都小于这个节点,右子树的所有节点都大于这个节点。而且,因为索引条目较少,确实可以考虑在查询的时候,先将足够大的树导入内存,然后再进行搜索。搜索的算法是递归的,与二分查找非常类似,每次计算可以将问题规模减半。当然,具体有多少数据可以导入内存,受实际可以使用的内存数量的限制。
在上面的二叉搜索树中,每个节点的数据分成 Key 和 Value。Key 就是索引值,比如订单 ID 创建索引,那么 Key 就是订单 ID。值中至少需要序号(对行存储也就是行号)。这样,如果们想找 18 对应的行,就可以先通过二叉搜索树找到对应的行号,然后再去对应的行读取数据。
二叉搜索树是一个天生的二分查找结构,每次查找都可以减少一半的问题规模。而且二叉搜索树解决了插入新节点的问题,因为二叉搜索树是一个跳跃结构,不必在内存中连续排列。这样在插入的时候,新节点可以放在任何位置,不会像线性结构那样插入一个元素,所有元素都需要向后排列。
那么回到本质问题,在使用磁盘的时候,二叉搜索树是不是一种合理的查询结构?
当然还不算,因此还需要继续优化我们的算法。二叉搜索树,在内存中是一个高效的数据结构。这是因为内存速度快,不仅可以随机存取,还可以高频操作。注意 CPU 缓存的穿透率只有 5% 左右,也就是 95% 的操作是在更快的 CPU 缓存中执行的。而且即便穿透,内存操作也是在纳秒级别可以完成。
但是,这个逻辑在磁盘中是不存在的,磁盘的速度慢太多了。我们可以尝试把尽可能多的二叉搜索树读入磁盘,但是如果数据量大,只能读入一部分呢?因此我们还需要继续改进算法。
B 树和 B+ 树
二叉搜索树解决了连续结构插入新元素开销很大的问题,同时又保持着天然的二分结构。但是,当需要索引的数据量很大,无法在一个磁盘 Block 中存下整棵二叉搜索树的时候。每一次递归向下的搜索,实际都是读取不同的磁盘块。这个时候二叉搜索树的开销很大。
试想一个一万亿条订单的表,进行 40 次查找找到答案,在内存中不是问题,要考虑到 CPU 缓存有 90% 以上的命中率(当然前提是内存足够大)。通常情况下我们没有这么大的内存空间,如果 40 次查找发生在磁盘上,也是非常耗时的。那么有没有更好的方案呢?
一个更好的方案,就是继续沿用树状结构,利用好磁盘的分块让每个节点多一些数据,并且允许子节点也多一些,树就会更矮。因为树的高度决定了搜索的次数。
上图中我们构造的树被称为 B 树(B-Tree),开头说过,B 这个字母具体是哪个单词或者人名的缩写,至今有争议,具体你可以查查资料。
B-Tree 是一种递归的搜索结构,与二叉搜索树非常类似。不同的是,B 树中的父节点中的数据会对子树进行区段分割。比如上图中节点 1 有 3 个子节点,并用数字 9,30 对子树的区间进行了划分。
上图中的 B 树是一个 3-4 B 树,3 指的是每个非叶子节点允许最大 3 个索引,4 指的是每个节点最多允许 4 个子节点,4 也指每个叶子节点可以存 4 个索引。上面只是一个例子,在实际的操作中,子节点有几十个、甚至上百个索引也很常见,因为我们希望树变矮,好减少磁盘操作。
B 树的每个节点是一个索引条目(例如:一个 <订单 ID,序号> 的组合),如果是行数据库可以索引到一条存储在磁盘上的记录。
继承 B 树:B+ 树
为了达到最高的效率,实战中我们往往使用的是一种继承于 B 树设计的结构,称为 B+ 树。B+ 树只有叶子节点才映射数据,下图中是对 B 树设计的一种改进,节点 1 为冗余节点,它不存储数据,只划定子树数据的范围。你可以看到节点 1 的索引 Key:12 和 30,在节点 3 和 4 中也有一份。
树的形成:插入
下面我以一棵 2-3 B+ 树来演示 B+ 树的插入过程。2 指的是 B+ 树每个非叶子节点允许 2 个数据,叶子节点最多允许 3 个索引,每个节点允许最多 3 个子节点。我们要在 2-3 B+ 树中依次插入 3,6,9,12,19,15,26,8,30。下图是演示:

插入 3,6,9 过程很简单,都写入一个节点即可,因为叶子节点最多允许每个 3 个索引。接下来我们插入 12,会发生一次过载,然后节点就需要拆分,这个时候按照 B+ 树的设计会产生冗余节点。
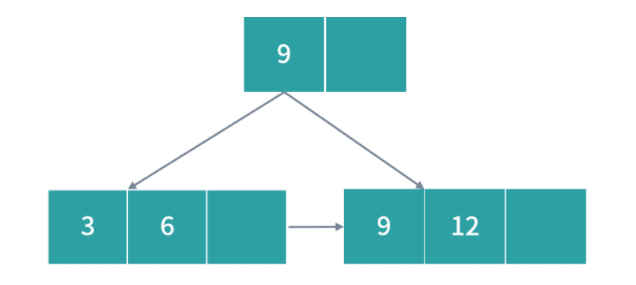
然后插入 15 非常简单,直接加入即可:
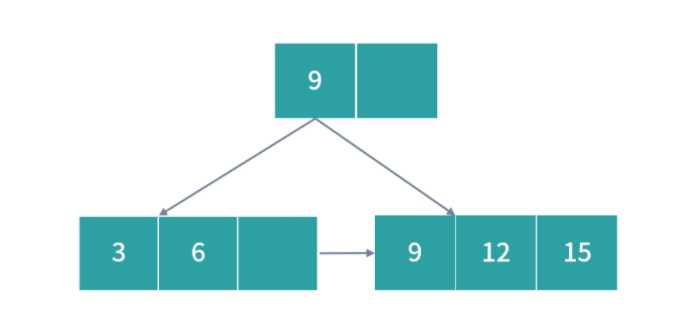
接下来插入 19, 这个时候下图中红色部分发生过载:
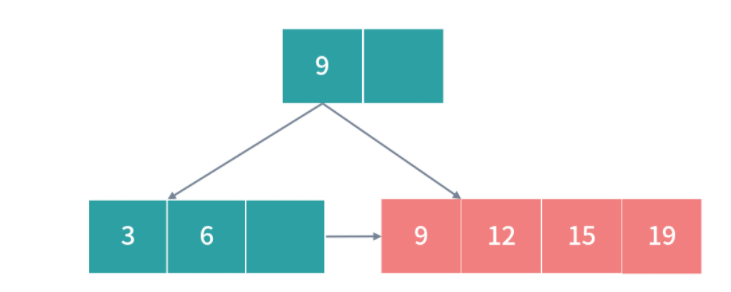
因此需要拆分节点数据,我们从中间把红色的节点拆开,15 作为冗余的索引写入父节点,就形成下图的情况:
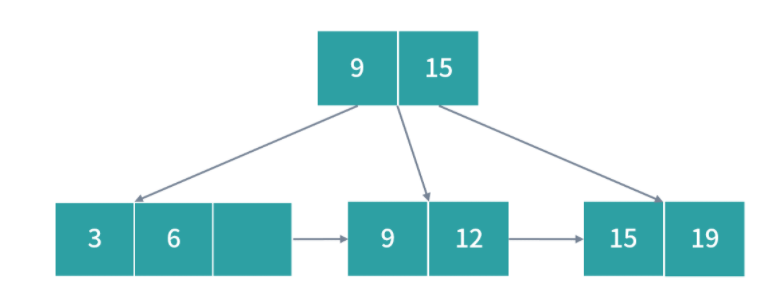
接着插入 26, 写入到对应位置即可。
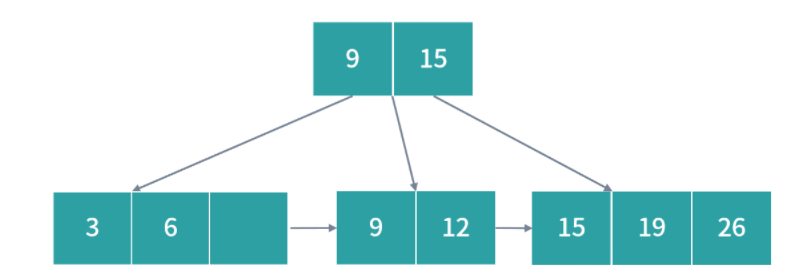
接下来,插入 8 到对应位置即可。
然后我们插入 30,此时右边节点发生过载:
解决完一次过载问题之后,因为 26 会浮上去,根节点又发生了过载:
再次解决过载,拆分红色部分,得到最后结果:
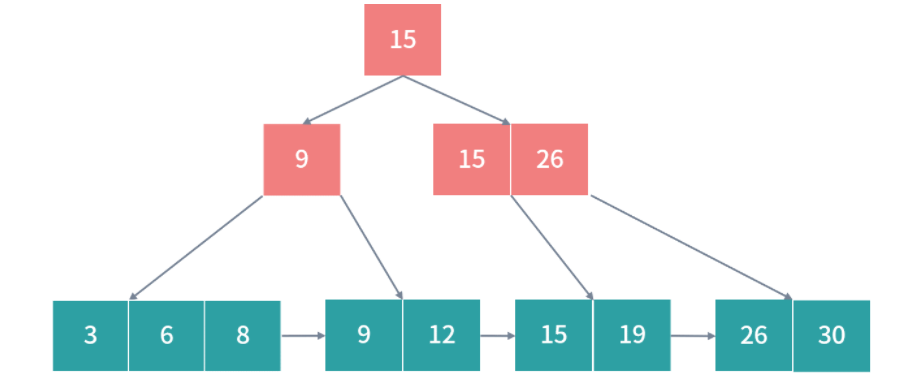
在上述过程中,B+ 树始终可以保持平衡状态,而且所有叶子节点都在同一层级。更复杂的数学证明,我就不在这里讲解了。不过建议对算法感兴趣对同学,可以学习《算法导论》中关于树的部分。
插入和删除效率
B+ 树有大量的冗余节点,比如删除一个节点的时候,可以直接从叶子节点中删除,甚至可以不动非叶子节点。这样删除非常快。B 树则不同,B 树没有冗余节点,删除节点的时候非常复杂。比如删除根节点中的数据,可能涉及复杂的树的变形。
B+ 树的插入也是一样,有冗余节点,插入可能存在节点的拆分(如果节点饱和),但是最多只涉及树的一条路径。而且 B+ 树会自动平衡,不需要更多复杂的算法,类似红黑树的旋转操作等。
因此,B+ 树的插入和删除效率更高。
搜索:链表的作用
B 树和 B+ 树搜索原理基本一致。先从根节点查找,然后对比目标数据的范围,最后递归的进入子节点查找。
你可能会注意到,B+ 树所有叶子节点间还有一个链表进行连接。这种设计对范围查找非常有帮助,比如说我们想知道 1 月 20 日和 1 月 22 日之间的订单,这个时候可以先查找到 1 月 20 日所在的叶子节点,然后利用链表向右遍历,直到找到 1 月22 日的节点。这样我们就进一步节省搜索需要的时间。
这一讲我们学习了在数据库中如何利用文件系统造索引。无论是行存储还是列存储,构造索引的过程都是类似的。索引有很多做法,除了 B+ 树,还有 HashTable、倒排表等。如果是存储海量数据的数据库,我们的思考点需要放在 I/O 的效率上。如果把今天的知识放到分布式数据库上,那除了需要节省磁盘读写还需要节省网络 I/O。
MySQL 中的 B 树和 B+ 树有什么区别?
B+ 树继承于 B 树,都限定了节点中数据数目和子节点的数目。B 树所有节点都可以映射数据,B+ 树只有叶子节点可以映射数据。
单独看这部分设计,看不出 B+ 树的优势。为了只有叶子节点可以映射数据,B+ 树创造了很多冗余的索引(所有非叶子节点都是冗余索引),这些冗余索引让 B+ 树在插入、删除的效率都更高,而且可以自动平衡,因此 B+ 树的所有叶子节点总是在一个层级上。所以 B+ 树可以用一条链表串联所有的叶子节点,也就是索引数据,这让 B+ 树的范围查找和聚合运算更快。
分布式文件系统是怎么回事?
们讨论大数据环境下的数据管理——分布式文件系统和分布式数据库。分布式文件系统通过计算机网络连接大量物理节点,将不同机器、不同磁盘、不同逻辑分区的数据组织在一起,提供海量的数据存储(一般是 Petabytes 级别,1PB = 1024TB)。分布式数据库则在分布式文件系统基础上,提供应对具体场景的海量数据解决方案。
说起大数据,就不得不提历史上在存储领域影响深远的两篇 Paper。
- Google File System
- BigTable:A Distributed Storage System for Structured Data
Google File System 是一个分布式文件系统,构成了今天大数据生态的底层存储,也是我们本讲主角 HDFS 的原型。HDFS(Hadoop Distributed File System)是 Google File System 的一个重要实现。
后者 BigTable 是一个分布式数据库。BigTable 本身是 Google 内部的项目,建立在 Google File System 之上,为 Google 的搜索引擎提供数据支撑。它是 2005 年公布的第一个版本,而且通过 Paper 公布了实现,在那个大数据还处于萌芽阶段的时代,BigTable 成为了启明星,今天我们常用的 HBase 还沿用着 BigTable 的设计。
因为两个重量级的 Paper 都是 Google 的产物,所以这一讲,我会结合搜索引擎的设计,带你走进分布式存储和数据库的世界。
存储所有的网页
作为搜索引擎最核心的一个能力,就是要存储所有的网页。目前世界上有 20 多亿个网站,每个网站还有大量的页面。搜索引擎不单单要存下这些页面,而且搜索引擎还需要存储这些网页的历史版本。
这里请你思考下,网站所有页面加起来有多大?举个例子,豆瓣所有页面加起来会有多大?如果把所有的变更都算上,比如一张页面经过 200 次迭代,就存 200 份,那么需要多少空间?Google 要把这些数据都存储下来,肯定是 PB 级别的数据。而且这个庞大的数据还需要提供给 Google 内部的分布式计算引擎等去计算,为网站打分、为用户生成索引,如果没有强大的存储能力是做不到的。
模型的选择
我们先来思考应该用何种模型存下这个巨大的网页表。
网页的历史版本,可以用 URL+ 时间戳进行描述。但是为了检索方便,网页不仅有内容,还有语言、外链等。在存储端可以先不考虑提供复杂的索引,比如说提供全文搜索。但是我们至少应该提供合理的数据读写方式。
网页除了内容,还有外链,外链就是链接到网页的外部网站。链接到一个网站的外链越多,那就说明这个网站在互联网中扮演的角色越重要。Google 创立之初就在基于外链的质量和数量为网站打分。外链可能是文字链接、图片链接等,因此外链也可以有版本,比如外链文本调整了,图片换了。除了外链还有标题、Logo,也需要存储。其实要存储的内容有很多,我不一一指出了。
我们先看看行存储,可不可以满足需求。比如每个网页( URL) 的数据是一行。 看似这个方案可行,可惜列不是固定。比如外链可能有很多个,如下表:

列不固定,不仅仅是行的大小不好确定,而是表格画不出来。何况每一列内容还可能有很多版本,不同版本是搜索引擎的爬虫在不同时间收录的内容,再加上内容本身也很大,有可能一个磁盘 Block 都存不下。看来行存储困难重重。
那么列存储行不行呢? 当然不行,我们都不确定到底有多少列? 有的网站有几千个外链,有的一个都没有,外链到底用多少列呢?
所以上表只可以作为我们存储设计的一个逻辑概念——这种逻辑概念在设计系统的时候,还有一个名词,叫作领域语言。领域语言是我们的思考方式,从搜索引擎的职责上讲,数据需要按照上面的结构聚合。况且根据 URL 拿数据,这是必须提供的能力。但是底层如何持久化,还需要进一步思考。
因为列是不确定的,这种情况下只能考虑用 Key-Value 结构,也就是 Map 存储。Map 是一种抽象的数据结构,本质是 Key-Value 数据的集合。 作为搜索引擎的支撑,Key 可以考虑设计为 <URL, Column,时间戳> 的三元组,值就是对应版本的数据。
列名(Column)可以考虑分成两段,用:分隔开。列名包括列家族(Family) 、列标识(Qualifier)。这样设计是因为有时候多个列描述的是相似的数据,比如说外链(Anchor),就是一个列家族。然后百度、搜狐是外链家族的具体的标识(Qualifier)。比如来自百度页面 a 外链的列名是anchor:baidu.com/a。分成家族还有一个好处就是权限控制,比如不同部门的内部人员可以访问不同列家族的数据。当然有的列家族可能只有一个列,比如网页语言;有的列家族可能有很多列,比如外链。
接下来,我们思考:这个巨大的 Map(Key-Value)的集合应该用什么数据结构呢?——数组?链表?树?哈希表?
小提示:Map 只是 Key-Value 的集合。并没有约定具体如何实现,比如 HashMap 就是用哈希表实现 Map,ArrayMap 就是用数组实现 Map。LinkedMap 就是用链表实现 Map。LinkedJumpMap 就是用跳表实现 Map……
考虑到一行的数据并不会太大,我们可以用 URL 作为行的索引。当用户想用 Key 查找 Value 时,先使用 Key 中 URL 帮用户找到完整的行。这里可以考虑使用上一讲学习的 B+ 树去存储所有的 URL,建立一个 URL 到行号的索引。你看看,知识总是被重复利用,再次证明了人类的本质是复读机,其实就是学好基础很重要。通过 B+ 树,这样即便真的有海量的数据,也可以在少数几次、几十次查询内完成找到 URL 对应的数据。况且,我们还可以设计缓存。
B+ 树需要一种顺序,比较好的做法是 URL 以按照字典序排列。这是因为,相同域名的网页资源同时被用到的概率更高,应该安排从物理上更近,尽量把相同域名的数据放到相邻的存储块中(节省磁盘操作)。
那么行内的数据应该如何存储呢?可以考虑分列存储。那么行内用什么数据结构呢?如果列非常多,也可以考虑继续用 B+ 树。还有一种设计思路,是先把大表按照行拆分,比如若干行形成一个小片称作 Tablet,然后 Tablet 内部再使用列存储,这个设计我们会在后面一点讨论。
查询和写入
当客户端查询的时候,请求参数中会包含 <URL, 列名>,这个时候我们可以通过 B+ 树定位到具体的行(也就是 URL 对应的数据)所在的块,再根据列名找到具体的列。然后,将一列数据导入到内存中,最后在内存中找到对应版本的数据。
客户端写入时,也是按照行→列的顺序,先找到列,再在这一列最后面追加数据。
对于修改、删除操作可以考虑不支持,因为所有的变更已经记录下来了。
分片(Tablet)的抽象
上面我们提到了可以把若干行组合在一起存储的设计。这个设计比较适合数据在集群中分布。假设存储网页的表有几十个 PB,那么先水平分表,就是通过 行(URL) 分表。URL 按照字典排序,相邻的 URL 数据从物理上也会相近。水平分表的结果,字典序相近的行(URL)数据会形成分片(Tablet),Tablet 这个单词类似药片的含义。
如上图所示:每个分片中含有一部分的行,视情况而定。分片(Tablet),可以作为数据分布的最小单位。分片内部可以考虑图上的行存储,也可以考虑内部是一个 B+ 树组织的列存储。
为了实现分布式存储,每个分片可以对应一个分布式文件系统中的文件。假设这个分布式文件系统接入了 Linux 的虚拟文件系统,使用和操作会同 Linux 本地文件并无二致。其实不一定会这样实现,这只是一个可行的方案。
为了存储安全,一个分片最少应该有 2 个副本,也就是 3 份数据。3 份数据在其中一份数据不一致后,可以对比其他两份的结果修正数据。这 3 份数据,我们不考虑跨数据中心。因为跨地域成本太高,吞吐量不好保证,假设它们还在同一地域的机房内,只不过在不同的机器、磁盘上。
块(Chunk)的抽象
比分片更小的单位是块(Chunk),这个单词和磁盘的块(Block)区分开。Chunk 是一个比 Block 更大的单位。Google File System 把数据分成了一个个 Chunk,然后每个 Chunk 会对应具体的磁盘块(Block)。
如下图,Table 是最顶层的结构,它里面含有许多分片(Tablets)。从数据库层面来看,每个分片是一个文件。数据库引擎维护到这个层面即可,至于这个文件如何在分布式系统中工作,就交给底层的文件系统——比如 Google File System 或者 Hadoop Distributed File System。
分布式文件系统通常会在磁盘的 Block 上再抽象一层 Chunk。一个 Chunk 通常比 Block 大很多,比如 Google File System 是 64KB,而通常磁盘的 Block 大小是 4K;HDFS 则是 128MB。这样的设计是为了减少 I/O 操作的频率,分块太小 I/O 频率就会上升,分块大 I/O 频率就减小。 比如一个 Google 的爬虫积攒了足够多的数据再提交到 GFS 中,就比爬虫频繁提交节省网络资源。
分布式文件的管理
接下来,我们来讨论一个完整的分布式系统设计。和单机文件系统一样,一个文件必须知道自己的数据(Chunk)存放在哪里。下图展示了一种最简单的设计,文件中包含了许多 Chunk 的 ID,然后每个 ChunkID 可以从 Chunk 的元数据中找到 Chunk 对应的位置。
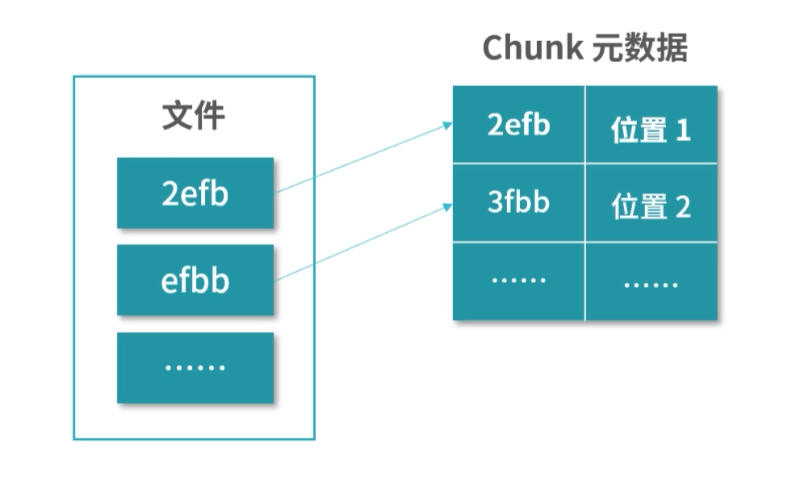
如果 Chunk 比较大,比如说 HDFS 中 Chunk 有 128MB,那么 1PB 的数据需要 8,388,608 个条目。如果每个条目用 64bit 描述,也就是 8 个字节,只需要 64M 就可以描述清楚。考虑到一个 Chunk 必然会有冗余存储,也就是多个位置,实际会比 64M 多几倍,但也不会非常大了。
因此像 HDFS 和 GFS 等,为了简化设计会把所有文件目录结构信息,加上 Chunk 的信息,保存在一个单点上,通常称为 Master 节点。
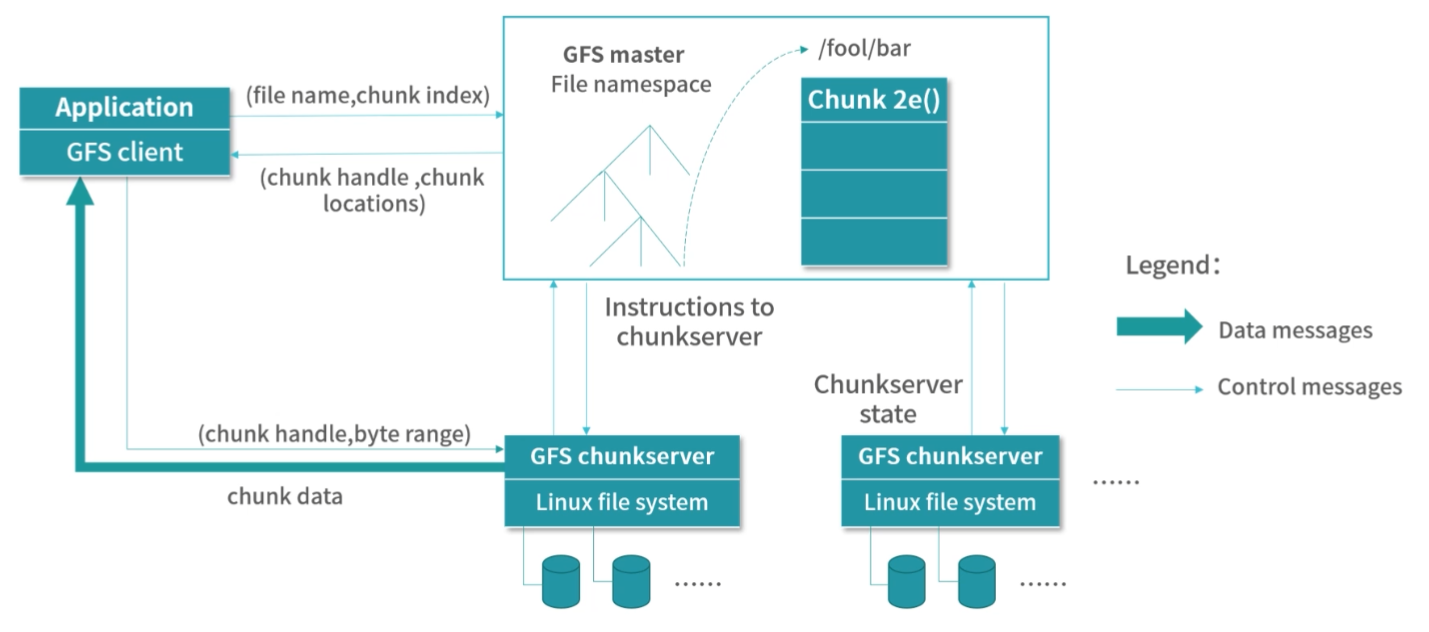
下图中,客户端想要读取/foo/bar中某个 Chunk 中某段内容(Byterange)的数据,会分成 4 个步骤:
- 客户端向 Master 发送请求,将想访问的文B件名、Chunk 的序号(可以通过 Chunk 大小和内容位置计算);
- Master 响应请求,返回 Chunk 的地址和 Chunk 的句柄(ID);
- 客户端向 Chunk 所在的地址(一台 ChunkServer)发送请求,并将句柄(ID)和内容范围(Byterange)作为参数;
- ChunkServer 将数据返回给客户端。
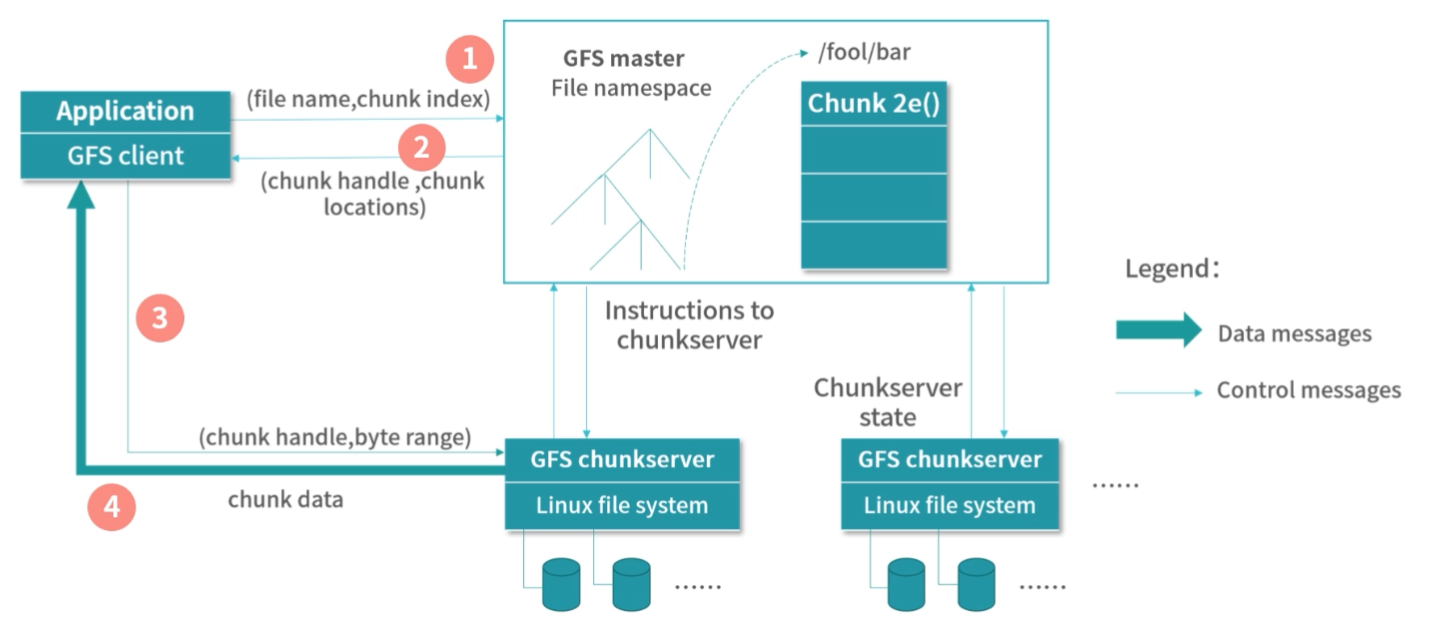
在上面这个模型中,有 3 个实体。
- 客户端(Client)或者应用(Application),它们是数据的实际使用方,比如说 BigTable 数据库是 GFS 的 Client。
- Master 节点,它存储了所有的文件信息、Chunk 信息,权限信息等。
- ChunkServer 节点,它存储了实际的 Chunk 数据。
Master 只有一台,ChunkServer 可以有很多台。上图中的 namespace 其实就是文件全名(含路径)的集合。Chunk 的 namespace 存储的是含文件全名 + ChunkLocation + ChunkID 的组合。文件的命名空间、Chunk 的命名空间,再加上文件和 Chunk 的对应关系,因为需要频繁使用,可以把它们全部都放到 Master 节点的内存中,并且利用 B 树等在内存中创建索引结构。ChunkServer 会和 Master 保持频繁的联系,将自己的变更告知 Master。这样就构成了一个完整的过程。
读和写
读取文件的过程需要两次往返(Round Trip),第一次是客户端和 Master 节点,第二次是客户端和某个 ChunkServer。
写入某个 Chunk 的时候,因为所有存储了这个 Chunk 的服务器都需要更新,所以需要将数据推送给所有的 ChunkServer。这里 GFS 设计中使用了一个非常巧妙的方案,先由客户端将数据推送给所有 ChunkServer 并缓存,而不马上更新。直到所有 ChunkServer 都收到数据后,再集中更新。这样的做法减少了数据不一致的时间。
下图是具体的更新步骤:
- 客户端要和服务器签订租约,得到一个租期(Lease)。其实就是 Chunk 和 Chunk 所有复制品的修改权限。如果一个客户端拿到租期,在租期内,其他客户端能不能修改这个 Chunk。
- Master 告诉客户端该 Chunk 所有的节点位置。包括 1 台主节点(Primary)和普通节点(Secondary)。当然主节点和普通节点,都是 ChunkServer。主 ChunkServer 的作用是协助更新所有从 ChunkServer 的数据。
- 这一步是设计得最巧妙的地方。客户端接下来将要写入的数据同时推送给所有关联的 ChunkServer。这些 ChunkServer 不会更新数据,而是把数据先缓存起来。
- 图中的所有 ChunkServer 都收到了数据,并且给客户端回复后,客户端向主 ChunkServer 请求写入。
- 主 ChunkServer 通知其他节点写入数据。因为数据已经推送过来了,所以这一步很快完成。
- 写入完数据的节点,所有节点给主 ChunkServer 回复。
- 主 ChunkServer 通知客户端成功。
以上,就是 GFS 的写入过程。这里有个规律,实现强一致性(所有时刻、所有客户端读取到的数据是一致的)就需要停下所有节点的工作牺牲可用性;或者牺牲分区容错性,减少节点。GFS 和 HDFS 的设计,牺牲的是一致性本身,允许数据在一定时间范围内是不一致的,从而提高吞吐量。
容灾
在 HDFS 设计中,Master 节点也被称为 NameNode,用于存储命名空间数据。ChunkServer 也被称为 DataNode,用来存储文件数据。在 HDFS 的设计中,还有一个特殊的节点叫作辅助节点(Secondary Node)。辅助节点本身更像一个客户端,它不断和 NameNode 交流,并把 NameNode 最近的变更写成日志,存放到 DataNode 中。类似日志文件系统,每过一段时间,在 HDFS 中这些日志会形成一个还原点文件,这个机制和上一讲我们提到的日志文件系统类似。如果 Master 节点发生了故障,就可以通过这些还原点进行还原。
其他
在分布式文件系统和分布式数据库的设计中,还有很多有趣的知识,比如缓存的设计、空间的回收。如果你感兴趣,你可以进一步阅读我开篇给出的两篇论文。
- Google File System
- BigTable:A Distributed Storage System for Structured Data
总结
现在,我们已经可以把所有的场景都串联起来。Google 需要的是一个分布式数据库,存储的数据是包括内容、外链、Logo、标题等在内的网页的全部版本和描述信息。为了描述这些信息,一台机器磁盘不够大,吞吐量也不够大。因此 Google 需要将数据分布存储,将这个大表(BigTable)拆分成很多小片(Tablet)。当然,这并不是直接面向用户的架构。给几十亿用户提供高效查询,还需要分布式计算,计算出给用户使用的内容索引。
Google 团队发现将数据分布出去是一个通用需求。不仅仅是 BigTable 数据库需要,很多其他数据库也可以在这个基础上构造。按照软件设计的原则,每个工具应该尽可能的专注和简单, Google 的架构师意识到需要一个底层的文件系统,就是 Google File System。这样,BigTable 使用 Tablet 的时候,只需要当成文件在使用,具体的分布式读写,就交给了 GFS。
后来,Hadoop 根据 GFS 设计了 Hadoop 分布式文件系统,用于处理大数据,仍然延续了整个 GFS 的设计。
以上,是一个完整的,分布式数据库、分布式存储技术的一个入门级探讨。
分布式文件系统是怎么回事?
分布式文件系统通过网络将不同的机器、磁盘、逻辑分区等存储资源利用起来,提供跨平台、跨机器的文件管理。通过这种方式,我们可以把很多相对廉价的服务器组合起来形成巨大的存储力量。
socket 文件都存在哪里?
socket 没有实体文件,只有 inode,所以 socket 是没有名字的文件。
你可以在 /proc/net/tcp 目录下找到所有的 TCP 连接,在 /proc/[pid]/fd 下也可以找到这些 socket 文件,都是数字代号,数字就是 socket 文件的 fd,如下图所示:
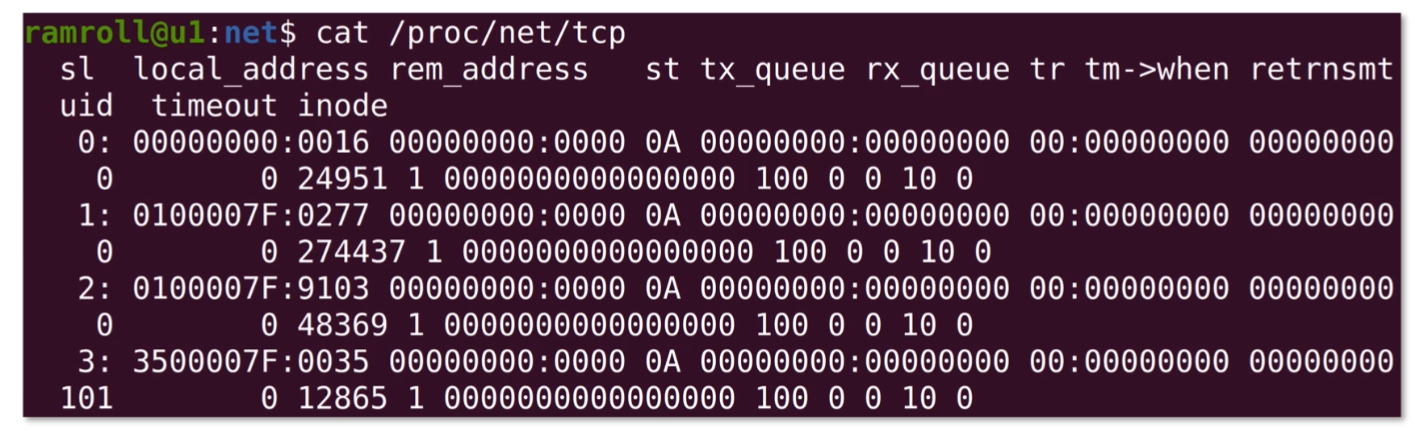
你也可以用lsof -i -a -p [pid查找某个进程的 socket 使用情况。下面结果和你用ls /proc/[pid]/fd看到的 fd 是一致的,如下图所示:
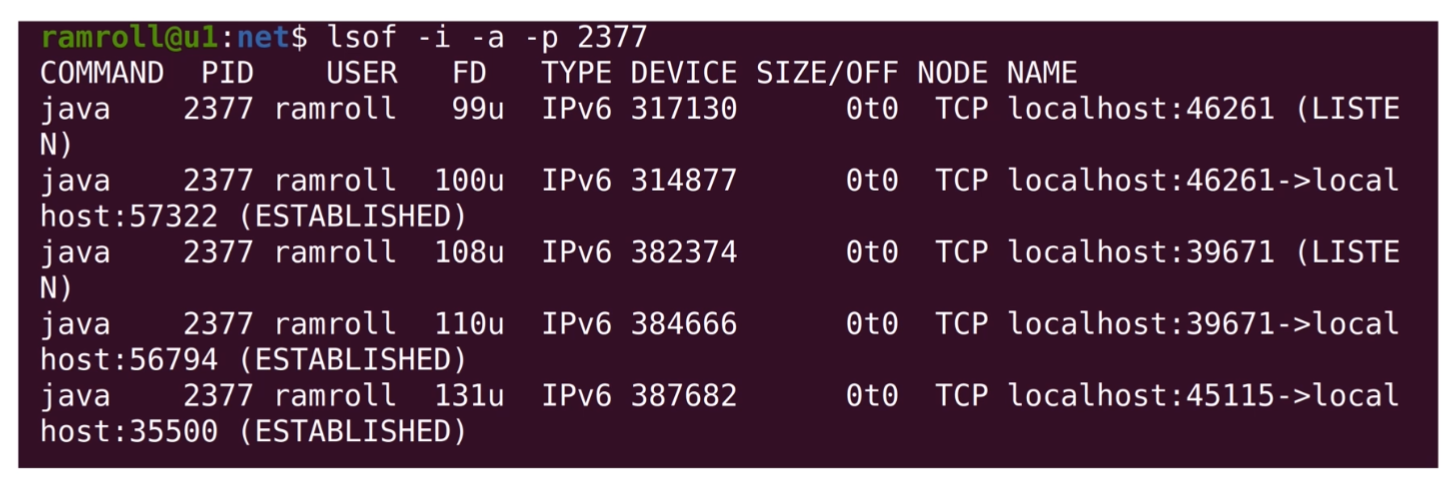
思考日志文件系统的数据冗余如何处理?
日志系统产生冗余几乎是必然发生的。 只要发生了修改、删除,肯定就会有数据冗余。日志系统通常不会主动压缩,但是日志文件系统通常会对磁盘碎片进行整理,这种机制和内存的管理非常相似。
首先我们把这个磁盘切割成很多等大的小块,大文件可能需要分配多个小块,多个小文件共用一个小块。而当很多文件被删除之后,磁盘中的小块会产生碎片,文件系统会进行碎片整理,比如把多个有很多碎片的区域拷贝到一起,使存储空间更加紧凑。
回到正题,最终的答案就是不压缩、不处理冗余,空间换时间,提升写入速度。
按照应该尽量减少磁盘读写操作的原则,是不是哈希表的索引更有优势?
哈希表是一种稀疏的离散结构,通常使用键查找值。给定一个键,哈希表会通过数学计算的方式找到值的内存地址。因此,从这个角度去分析,哈希表的查询速度非常快。单独查找某一个数据速度超过了 B+ 树(比如根据姓名查找用户)。因此,包括 MySQL 在内的很多数据库,在支持 B+ 树索引的同时,也支持哈希表索引。
这两种索引最大的区别是:B+ 树是对范围的划分,其中的数据还保持着连续性;而哈希表是一种离散的查询结构,数据已经分散到不同的空间中去了。所以当数据要进行范围查找时,比如查找某个区间内的订单,或者进行聚合运算,这个时候哈希表的性能就非常低了。
哈希表有一个设计约束,如果我们用了 m 个桶(Bucket,比如链表)去存储哈希表中的数据,再假设总共需要存储 N 个数据。那么平均查询次数 k = N/m。为了让 k 不会太大,当数据增长到一定规模时,哈希表需要增加桶的数目,这个时候就需要重新计算所有节点的哈希值(重新分配所有节点属于哪个桶)。
综上,对于大部分的操作 B+ 树都有较好的性能,比如说 >,<, =,BETWEEN,LIKE 等,哈希表只能用于等于的情况。
Master 节点如果宕机了,影响有多大,如何恢复?
在早期的设计中,Master 是一个单点(Single Point),如果发生故障,系统就会停止运转,这就是所谓的单点故障(Single Point of Failure)。由此带来的后果会非常严重。发生故障后,虽然我们可以设置第二节点不断备份还原点,通过还原点加快系统恢复的速度,但是在数据的恢复期间,整个系统是不可用的。
在一个高可用的设计当中,我们不希望发生任何的单点故障(SPoF),因此所有的节点都至少有两份。于是在 Hadoop 后来的设计当中,增加了一种主从结构。
如上图所示,我们同时维护两个 Master 节点(在 Hadoop 中称为 NameNode,NN)——一个活动(Active)的 NN 节点,一个待命(StandBy)的 NN 节点。
为了保证在系统出现故障的时候,可以迅速切换节点,我们需要一个故障控制单元。因为是分布式的设计,控制单元在每个 NN 中都必须有一个,这个单元可以考虑 NN 节点进程中的一个线程。控制单元不断地检测节点的状态,并且不断探测其他 NN 节点的状态。一旦检测到故障,控制单元随时准备切换节点。
一方面,因为我们不能信任任何的 NN 节点不出现故障,所以不能将节点的状态存在任何一个 NN 节点中。并且节点的状态也不适合存在数据节点中,因为大数据集群的数据节点实时性不够,它是用来存储大文件的。因此,可以考虑将节点的状态放入一个第三方的存储当中,通常就是 ZooKeeper。
另一方面,因为活动 NN 节点和待命 NN 节点数据需要完全一致,所以数据节点也会把自己的状态同时发送给活动节点和待命节点(比如命名空间变动等)。最后客户端会把请求发送给活动节点,因此活动节点会产生操作日志。不可以把活动节点的操作日志直接发送给待命节点,是因为我们不确定待命节点是否可用。
而且,为了保证日志数据不丢失,它们应该存储至少 3 份。即使其中一份数据发生损坏,也可以通过对比半数以上的节点(2 个)恢复数据。因此,这里需要设计专门的日志节点(Journal Node)存储日志。至少需要 3 个日志节点,而且必须是奇数。活动节点将自己的日志发送给日志节点,待命节点则从日志节点中读取日志,同步自己的状态。
我们再来回顾一下这个高可用的设计。为了保证可用性,我们增加了备用节点待命,随时替代活动节点。为了达成这个目标。有 3 类数据需要同步。
- 数据节点同步给主节点的日志。这类数据由数据节点同时同步给活动、待命节点。
- 活动节点同步给待命节点的操作记录。这类数据由活动节点同步给日志节点,再由日志节点同步给待命节点。日志又至少有 3 态机器的集群保管,每个上放一个日志节点。
- 记录节点本身状态的数据(比如节点有没有心跳)。这类数据存储在分布式应用协作引擎上,比如 ZooKeeper。
有了这样的设计,当活动节点发生故障的时候,只需要迅速切换节点即可修复故障。
总结
这个模块我们对文件系统进行了系统的学习,下面我来总结一下文件系统的几块核心要点。
- 理解虚拟文件系统的设计,理解在一个目录树结构当中,可以拥有不同的文件系统——一切皆文件的设计。基于这种结构,设备、磁盘、分布式文件系、网络请求都可以是文件。
- 将空间分块管理是一种高效的常规手段。方便分配、方便回收、方便整理——除了文件系统,内存管理和分布式文件系统也会用到这种手段。
- 日志文件系统的设计是重中之重,日志文件系统通过空间换时间,牺牲少量的读取性能,提升整体的写入效率。除了单机文件系统,这种设计在分布式文件系统和很多数据库当中也都存在。
- 分层架构:将数据库系统、分布式文件系搭建在单机文件管理之上——知识是死的、思路是活的。希望你能将这部分知识运用到日常开发中,提升自己系统的性能。
互联网协议群(TCP/IP):多路复用是怎么回事?
现在来看,“计算机网络”也许是一个过时的词汇,它讲的是怎么用计算实现通信。今天我们已经发展到了一个互联网、物联网的时代,社交网络、云的时代,再来看网络,意义已经发生转变。但这里面还是有很多经典的知识依旧在传承。比如说 TCP/IP 协议,问世后就逐渐成为占有统治地位的通信协议。虽然后面诞生出了许许多多的协议,但是我们仍然习惯性地把整个互联网的架构称为 TCP/IP 协议群,也叫作互联网协议群(Internet Protocol Suit)。
协议的分层
对于多数的应用和用户而言,使用互联网的一个基本要求就是数据可以无损地到达。用户通过应用进行网络通信,应用启动之后就变成了进程。因此,所有网络通信的本质目标就是进程间通信。世界上有很多进程需要通信,我们要找到一种通用的,每个进程都能认可和接受的通信方式,这就是协议。
应用层
从分层架构上看,应用工作在应用层(Application Layer)。应用的功能,都在应用层实现。所以应用层很好理解,说的就是应用本身。当两个应用需要通信的时候,应用(进程中的线程)就调用传输层进行通信。从架构上说,应用层只专注于为用户提供价值即可,没有必要思考数据如何传输。而且应用的开发商和传输库的提供方也不是一个团队。

传输层
为应用层提供网络支持的,就是传输层(Transport Layer)。
传输层控制协议(Transmission Control Protocol)是目前世界上应用最广泛的传输层协议。传输层为应用提供通信能力。比如浏览器想访问服务器,浏览器程序就会调用传输层程序;Web 服务接收浏览器的请求,Web 服务程序就会调用传输层程序接收数据。
考虑到应用需要传输的数据可能会非常大,直接传输不好控制。传输层需要将数据切块,即使一个分块传丢了、损坏了,可以重新发一个分块,而不用重新发送整体。在 TCP 协议中,我们把每个分块称为一个 TCP 段(TCP Segment)。
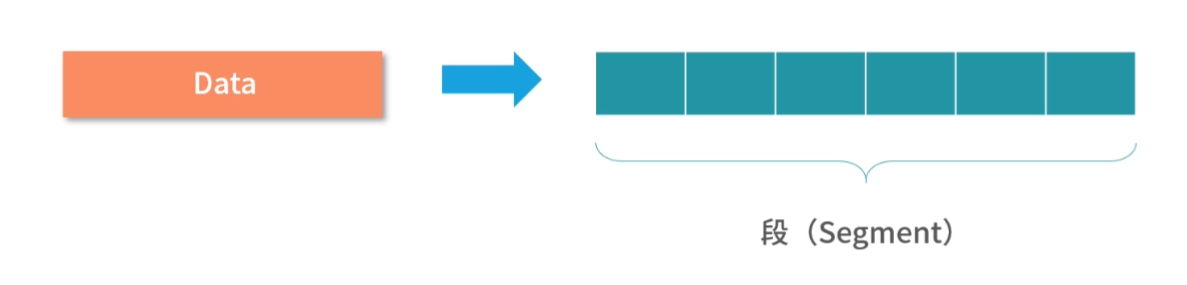
传输层负责帮助应用传输数据给应用。考虑到一台主机上可能有很多个应用在传输数据,而一台服务器上可能有很多个应用在接收数据。因此,我们需要一个编号将应用区分开。这个编号就是端口号。比如 80 端口通常是 Web 服务器在使用;22 端口通常是远程登录服务在使用。而桌面浏览器,可能每个打开的标签栏都是一个独立的进程,每个标签栏都会使用临时分配的端口号。TCP 封包(TCP Segment)上携带了端口号,接收方可以识别出封包发送给哪个应用。
网络层
接下来你要思考的问题是:传输层到底负不负责将数据从一个设备传输到另一个设备(主机到主机,Host To Host)。仔细思考这个过程,你会发现如果这样设计,传输层就会违反简单、高效、专注的设计原则。
我们从一个主机到另一个主机传输数据的网络环境是非常复杂的。中间会通过各种各样的线路,有形形色色的交叉路口——有各式各样的路径和节点需要选择。核心的设计原则是,我们不希望一层协议处理太多的问题。传输层作为应用间数据传输的媒介,服务好应用即可。对应用层而言,传输层帮助实现应用到应用的通信。而实际的传输功能交给传输层的下一层,也就是网络层(Internet Layer) 会更好一些。

IP 协议(Internet Protocol)是目前起到统治地位的网络层协议。IP 协议会将传输层的封包再次切分,得到 IP 封包。网络层负责实际将数据从一台主机传输到另一台主机(Host To Host),因此网络层需要区分主机的编号。
在互联网上,我们用 IP 地址给主机进行编号。例如 IPv4 协议,将地址总共分成了四段,每段是 8 位,加起来是 32 位。寻找地址的过程类似我们从国家、城市、省份一直找到区县。当然还有特例,比如有的城市是直辖市,有的省份是一个特别行政区。而且国与国体制还不同,像美国这样的国家,一个州其实可以相当于一个国家。
IP 协议里也有这个问题,类似行政区域划分,IP 协议中具体如何划分子网,需要配合子网掩码才能够明确。每一级网络都需要一个子网掩码,来定义网络子网的性质,相当于告诉物流公司到这一级网络该如何寻找目标地址,也就是寻址(Addressing)。关于更多子网掩码如何工作,及更多原理类的知识我会在拉勾教育的《计算机网络》专栏中和你分享。
除了寻址(Addressing),IP 协议还有一个非常重要的能力就是路由。在实际传输过程当中,数据并不是从主机直接就传输到了主机。而是会经过网关、基站、防火墙、路由器、交换机、代理服务器等众多的设备。而网络的路径,也称作链路,和现实生活中道路非常相似,会有岔路口、转盘、高速路、立交桥等。
因此,当封包到达一个节点,需要通过算法决定下一步走哪条路径。我们在现实生活中经常会碰到多条路径都可以到达同一个目的地的情况,在网络中也是如此。总结一下。寻址告诉我们去往下一个目的地该朝哪个方向走,路由则是根据下一个目的地选择路径。寻址更像在导航,路由更像在操作方向盘。
数据链路层(Data Link Layer)
考虑到现实的情况,网络并不是一个完整的统一体。比如一个基站覆盖的周边就会形成一个网络。一个家庭的所有设备,一个公司的所有设备也会形成一个网络。所以在现实的情况中,数据在网络中设备间或者跨网络进行传输。而数据一旦需要跨网络传输,就需要有一个设备同时在两个网络当中。通过路由,我们知道了下一个要去的 IP 地址,可是当前的网络中哪个设备对应这个 IP 地址呢?
为了解决这个问题,我们需要有一个专门的层去识别网络中的设备,让数据在一个链路(网络中的路径)中传递,这就是数据链路层(Data Link Layer)。数据链路层为网络层提供链路级别传输的支持。
物理层
当数据在实际的设备间传递时,可能会用电线、电缆、光纤、卫星、无线等各种通信手段。因此,还需要一层将光电信号、设备差异封装起来,为数据链路层提供二进制传输的服务。这就是物理层(Physical Layer)。
因此,从下图中你可以看到,由上到下,互联网协议可以分成五层,分别是应用层、传输层、网络层、数据链路层和物理层。
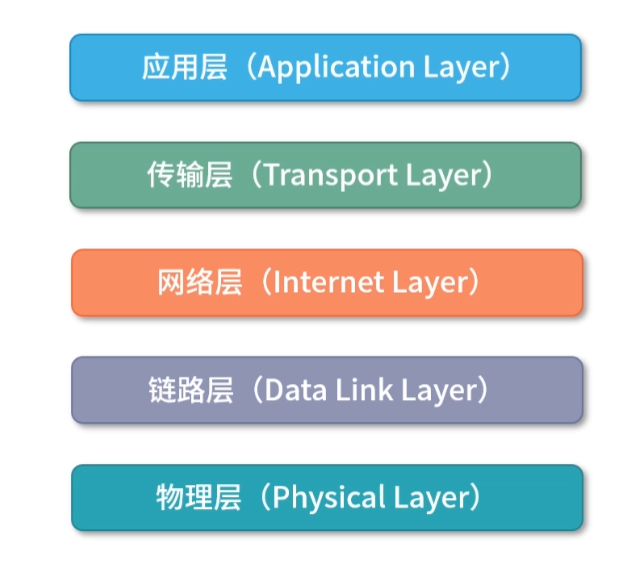
多路复用
在上述的分层模型当中,一台机器上的应用可以有很多。但是实际的出口设备,比如说网卡、网线通常只有一份。因此这里需要用到一个叫作多路复用(Multiplex)的技术。多路复用,就是多个信号,复用一个信道。
传输层多路复用
对应用而言,应用层抽象应用之间通信的模型——比如说请求返回模型。一个应用可能会同时向服务器发送多个请求。因为建立一个连接也是需要开销的,所以可以多个请求复用一个 TCP 连接。复用连接一方面可以节省流量,另一方面能够降低延迟。如果应用串行地向服务端发送请求,那么假设第一个请求体积较大,或者第一个请求发生了故障,就会阻塞后面的请求。
而使用多路复用技术,如下图所示,多个请求相当于并行的发送请求。即使其中某个请求发生故障,也不会阻塞其他请求。从这个角度看,多路复用实际上是一种 Non-Blocking(非阻塞)的技术。我们再来看下面这张图,不同的请求被传输层切片,我用不同的颜色区分出来,如果其中一个数据段(TCP Segment)发生异常,只影响其中一个颜色的请求,其他请求仍然可以到达服务。
网络层多路复用
传输层是一个虚拟的概念,但是网络层是实实在在的。两个应用之间的传输,可以建立无穷多个传输层连接,前提是你的资源足够。但是两个应用之间的线路、设备,需要跨越的网络往往是固定的。在我们的互联网上,每时每刻都有大量的应用在互发消息。而这些应用要复用同样的基础建设——网线、路由器、网关、基站等。
网络层没有连接这个概念。你可以把网络层理解成是一个巨大的物流公司。不断从传输层接收数据,然后进行打包,每一个包是一个 IP 封包。然后这个物流公司,负责 IP 封包的收发。所以,是很多很多的传输层在共用底下同一个网络层,这就是网络层的多路复用。
总结一下。应用层的多路复用,如多个请求使用同一个信道并行的传输,实际上是传输层提供的多路复用能力。传输层的多路复用,比如多个 TCP 连接复用一条线路,实际上是网络层在提供多路复用能力。你可以把网络层想象成一个不断收发包裹的机器,在网络层中并没有连接这个概念,所以网络层天然就是支持多路复用的。
多路复用的意义
在工作当中,我们经常会使用到多路复用的能力。多路复用让多个信号(例如:请求/返回等)共用一个信道(例如:一个 TCP 连接),那么在这个信道上,信息密度就会增加。在密度增加的同时,通过并行发送信号的方式,可以减少阻塞。比如说应用层的 HTTP 协议,浏览器打开的时候就会往服务器发送很多个请求,多个请求混合在一起,复用相同连接,数据紧密且互相隔离(不互相阻塞)。同理,服务之间的远程调用、消息队列,这些也经常需要多路复用。
多路复用是怎么回事?
【解析】多路复用让多个信号(例如:请求/返回等)共用一个信道(例如:一个 TCP 连接)。它有两个明显的优势。
- 提升吞吐量。多一个信号被紧密编排在一起(例如:TCP 多路复用节省了多次连接的数据),这样网络不容易空载。
- 多个信号间隔离。信号间并行传输,并且隔离,不会互相影响。
UDP 协议:UDP 和 TCP 相比快在哪里?
TCP 和 UDP 是目前使用最广泛的两个传输层协议,同时也是面试考察的重点内容。今天我会初步带你认识这两个协议,一起探寻它们之间最大的区别。
在开始本讲的重点内容前,我们先来说说 RFC 文档(Request For Comments,请求评论),互联网的很多基础建设都是以 RFC 的形式文档化,它给用户提供了阅读和学习的权限。在给大家准备《计算机网络》专栏的时候,我也经常查阅 RFC 文档。
如果你查阅 TCP 和 UDP 的 RFC 文档,会发现一件非常有趣的事情。TCP 协议的 RFC 很长,我足足读了好几天才把它们全部弄明白。UDP 的 RFC 非常短,只有短短的两页,一个小时就能读明白。这让我不禁感叹,如果能穿越到当时那个年代,我就去发明 UDP 协议,因为实在是太简单了。但即使是这个简单协议,也同样主宰着计算机网络协议的半壁江山。
那么这一讲我们就以 TCP 和 UDP 的区别为引,带你了解这两个在工作中使用频率极高、极为重要的传输层协议。
可靠性
首先我们比较一下这两个协议在可靠性(Reliablility)\上的区别。如果一个网络协议是可靠的,那么它能够保证数据被**无损**地传送到目的地。当应用的设计者选择一个具有可靠性的协议时,通常意味着这个应用不能容忍数据在传输过程中被损坏。
如果你是初学者,可能会认为所有的应用都需要可靠性。其实不然,比如说一个视频直播服务。如果在传输过程当中,视频图像发生了一定的损坏,用户看到的只是某几个像素、颜色不准确了,或者某几帧视频丢失了——这对用户来说是可以容忍的。但在观看视频的时候,用户最怕的不是实时数据发生一定的损坏,而是吞吐量得不到保证。比如视频看到一半卡住了,要等很久,或者丢失了一大段视频数据,导致错过精彩的内容。
TCP 协议,是一个支持可靠性的协议。UDP 协议,是一个不支持可靠性的协议。接下来我们讨论几个常见实现可靠性的手段。
校验和(Checksum)
首先我们来说说校验和。这是一种非常常见的可靠性检查手段。
尽管 UDP 不支持可靠性,但是像校验和(Checksum)这一类最基本的数据校验,它还是支持的。不支持可靠性,并不意味着完全放弃可靠性。TCP 和 UDP 都支持最基本的校验和算法。
下面我为你举例一种最简单的校验和算法:纵向冗余检查。伪代码如下:
复制代码
1 | byte c = 0; |
xor是异或运算。上面的程序在计算字节数组 bytes 的校验和。c是最终的结果。你可以看到将所有bytes两两异或,最终的结果就是校验和。假设我们要传输 bytes,如果在传输过程中bytes发生了变化,校验和有很大概率也会跟着变化。当然也可能存在bytes发生变化,校验和没有变化的特例,不过校验和可以很大程度上帮助我们识别数据是否损坏了。
当要传输数据的时候,数据会被分片,我们把每个分片看作一个字节数组。然后在分片中,预留几个字节去存储校验和。校验和随着数据分片一起传输到目的地,目的地会用同样的算法再次计算校验和。如果二者校验和不一致,代表中途数据发生了损坏。
对于 TCP 和 UDP,都实现了校验和算法,但二者的区别是,TCP 如果发现校验核对不上,也就是数据损坏,会主动丢失这个封包并且重发。而 UDP 什么都不会处理,UDP 把处理的权利交给使用它的程序员。
请求/应答/连接模型
另一种保证可靠性的方法是请求响应和连接的模型。TCP 实现了请求、响应和连接的模型,UDP 没有实现这个模型。
在通信当中,我们可以把通信双方抽象成两个人用电话通信一样,需要先建立联系(保持连接)。发起会话的人是发送请求,对方需要应答(或者称为响应)。会话双方保持一个连接,直到双方说再见。
在 TCP 协议当中,任何一方向另一方发送信息,另一方都需要给予一个应答。如果发送方在一定的时间内没有获得应答,发送方就会认为自己的信息没有到达目的地,中途发生了损坏或者丢失等,因此发送方会选择重发这条消息。
这样一个模式也造成了 TCP 协议的三次握手和四次挥手,下面我们一起来具体分析一下。
1. TCP 的三次握手
在 TCP 协议当中。我们假设 Alice 和 Bob 是两个通信进程。当 Alice 想要和 Bob 建立连接的时候,Alice 需要发送一个请求建立连接的消息给 Bob。这种请求建立连接的消息在 TCP 协议中称为同步(Synchronization, SYN)。而 Bob 收到 SYN,必须马上给 Alice 一个响应。这个响应在 TCP 协议当中称为响应(Acknowledgement,ACK)。请你务必记住这两个单词。不仅是 TCP 在用,其他协议也会复用这样的概念,来描述相同的事情。
当 Alice 给 Bob SYN,Bob 给 Alice ACK,这个时候,对 Alice 而言,连接就建立成功了。但是 TCP 是一个双工协议。所谓双工协议,代表数据可以双向传送。虽然对 Alice 而言,连接建立成功了。但是对 Bob 而言,连接还没有建立。为什么这么说呢?你可以这样思考,如果这个时候,Bob 马上给 Alice 发送信息,信息可能先于 Bob 的 ACK 到达 Alice,但这个时候 Alice 还不知道连接建立成功。 所以解决的办法就是 Bob 再给 Alice 发一次 SYN ,Alice 再给 Bob 一个 ACK。以上就是 TCP 的三次握手内容。
你可能会问,这明明是四次握手,哪里是三次握手呢?这是因为,Bob 给 Alice 的 ACK ,可以和 Bob 向 Alice 发起的 SYN 合并,称为一条 SYN-ACK 消息。TCP 协议以此来减少握手的次数,减少数据的传输,于是 TCP 就变成了三次握手。下图中绿色标签状是 Alice 和 Bob 的状态,完整的 TCP 三次握手的过程如下图所示:
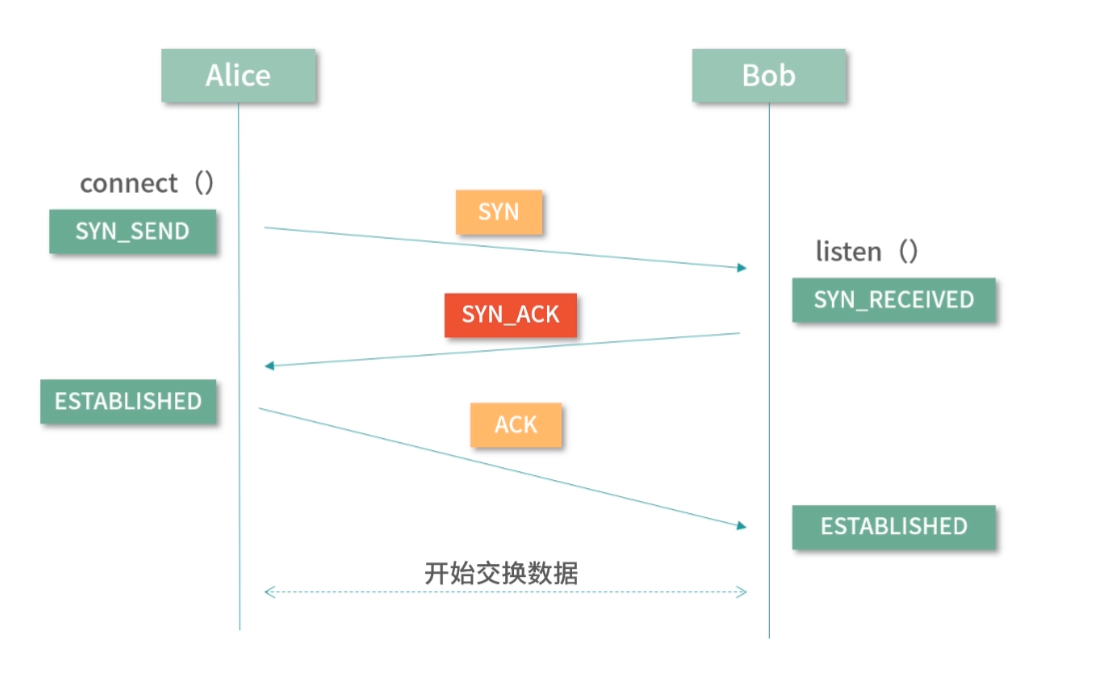
2. TCP 的四次挥手
四次挥手(TCP 断开连接)的原理类似。中断连接的请求我们称为 Finish(用 FIN 表示);和三次握手过程一样,需要分析成 4 步:
- 第 1 步是 Alice 发送 FIN
- 第 2 步是 Bob 给 ACK
- 第 3 步是 Bob 发送 FIN
- 第 4 步是 Alice 给 ACK
之所以是四次挥手,是因为第 2 步和 第 3 步在挥手的过程中不能合并为 FIN-ACK。原因是在挥手的过程中,Alice 和 Bob 都可能有未完成的工作。比如对 Bob 而言,可能还存在之前发给 Alice 但是还没有收到 ACK 的请求。因此,Bob 收到 Alice 的 FIN 后,就马上给 ACK。但是 Bob 会在自己准备妥当后,再发送 FIN 给 Alice。完整的过程如下图所示:
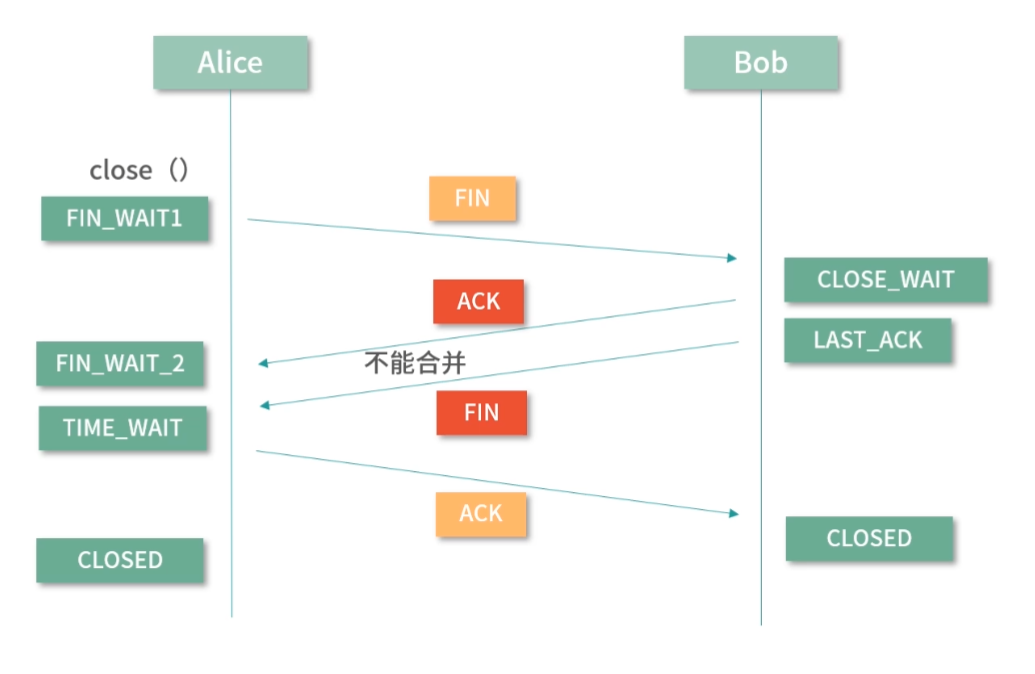
3. 连接
连接是一个虚拟概念,连接的目的是让连接的双方达成默契,倾尽资源,给对方最快的响应。经历了三次握手,Alice 和 Bob 之间就建立了连接。连接也是一个很好的编程模型。当连接不稳定的时候,可以中断连接后再重新连接。这种模式极大地增加了两个应用之间的数据传输的可靠性。
以上就是 TCP 中存在的,而 UDP 中没有的机制,你可以仔细琢磨琢磨。
封包排序
可靠性有一个最基本的要求是数据有序发出、无序传输,并且有序组合。TCP 协议保证了这种可靠性,UDP 则没有保证。
在传输之前,数据被拆分成分块。在 TCP 中叫作一个TCP Segment。在 UDP 中叫作一个UDP Datagram。Datagram 单词的含义是数据传输的最小单位。在到达目的地之后,尽管所有的数据分块可能是乱序到达的,但为了保证可靠性,乱序到达的数据又需要被重新排序,恢复到原有数据的顺序。
在这个过程当中,TCP 利用了滑动窗口、快速重传等算法,保证了数据的顺序。而 UDP,仅仅是为每个 Datagram 标注了序号,并没有帮助应用程序进行数据的排序,这也是 TCP 和 UDP 在保证可靠性上一个非常重要的区别。
使用场景
上面的内容中,我们比较了 TCP 和 UDP 在可靠性上的区别,接下来我们看看两个协议的使用场景。
我们先来看一道面试题:如果客户端和服务器之间的单程平均延迟是 30 毫秒,那么客户端 Ping 服务端需要多少毫秒?
【分析】这个问题最核心的点是需要思考 Ping 服务应该由 TCP 实现还是 UDP 实现?请你思考:Ping 需不需要保持连接呢?答案是不需要,Ping 服务器的时候把数据发送过去即可,并不需要特地建立一个连接。
请你再思考,Ping 需不需要保证可靠性呢?答案依然是不需要,如果发生了丢包, Ping 将丢包计入丢包率即可。所以从这个角度来看,Ping 使用 UDP 即可。
所以这道面试题应该是 Round Trip 最快需要在 60 毫秒左右。一个来回的时间,我们也通常称为 Round Trip 时间。
通过分析上面的例子,我想告诉你,TCP 和 UDP 的使用场景是不同的。TCP 适用于需要可靠性,需要连接的场景。UDP 因为足够简单,只对数据进行简单加工处理,就调用底层的网络层(IP 协议)传输数据去了。因此 UDP 更适合对可靠性要求不高的场景。
另外很多需要定制化的场景,非常需要 UDP。以 HTTP 协议为例,在早期的 HTTP 协议的设计当中就选择了 TCP 协议。因为在 HTTP 的设计当中,请求和返回都是需要可靠性的。但是随着 HTTP 协议的发展,到了 HTTP 3.0 的时候,就开始基于 UDP 进行传输。这是因为,在 HTTP 3.0 协议当中,在 UDP 之上有另一个QUIC 协议在负责可靠性。UDP 足够简单,在其上构建自己的协议就很方便。
你可以再思考一个问题:文件上传应该用 TCP 还是 UDP 呢?乍一看肯定是 TCP 协议,因为文件上传当然需要可靠性,防止数据损坏。但是如果你愿意在 UDP 上去实现一套专门上传文件的可靠性协议,性能是可以超越 TCP 协议的。因为你只需要解决文件上传一种需求,不用像 TCP 协议那样解决通用需求。
所以时至今日,到底什么情况应该用 TCP,什么情况用 UDP?这个问题边界的确在模糊化。总体来说,需要可靠性,且不希望花太多心思在网络协议的研发上,就使用 TCP 协议。
总结
最后我们再来总结一下,大而全的协议用起来舒服,比如 TCP;灵活的协议方便定制和扩展,比如 UDP。二者不分伯仲,各有千秋。
这一讲我们深入比较了 TCP 和 UDP 的可靠性及它们的使用场景。关于原理部分,比如具体 TCP 的滑动窗口算法、数据的切割算法、数据重传算法;TCP、UDP 的封包内部究竟有哪些字段,格式如何等。如果你感兴趣,可以来学习我将在拉勾教育推出的《计算机网络》专栏。
你现在可以尝试来回答本讲关联的面试题目:UDP 比 TCP 快在哪里?
【解析】使用 UDP 传输数据,不用建立连接,数据直接丢过去即可。至于接收方,有没有在监听?会不会接收?那就是接收方的事情了。UDP 甚至不考虑数据的可靠性。至于发送双方会不会基于 UDP 再去定制研发可靠性协议,那就是开发者的事情了。所以 UDP 快在哪里?UDP 快在它足够简单。因为足够简单,所以 UDP 对计算性能、对网络占用都是比 TCP 少的。
select/poll/epoll 有什么区别?
我们总是想方设法地提升系统的性能。操作系统层面不能给予处理业务逻辑太多帮助,但对于 I/O 性能,操作系统可以通过底层的优化,帮助应用做到极致。
这一讲我将和你一起讨论 I/O 模型。为了引发你更多的思考,我将同步/异步、阻塞/非阻塞等概念滞后讲解。我们先回到一个最基本的问题:如果有一台服务器,需要响应大量的请求,操作系统如何去架构以适应这样高并发的诉求。
说到架构,就离不开操作系统提供给应用程序的系统调用。我们今天要介绍的 select/poll/epoll 刚好是操作系统提供给应用的三类处理 I/O 的系统调用。这三类系统调用有非常强的代表性,这一讲我会围绕它们,以及处理并发和 I/O 多路复用,为你讲解操作系统的 I/O 模型。
从网卡到操作系统
为了弄清楚高并发网络场景是如何处理的,我们先来看一个最基本的内容:当数据到达网卡之后,操作系统会做哪些事情?
网络数据到达网卡之后,首先需要把数据拷贝到内存。拷贝到内存的工作往往不需要消耗 CPU 资源,而是通过 DMA 模块直接进行内存映射。之所以这样做,是因为网卡没有大量的内存空间,只能做简单的缓冲,所以必须赶紧将它们保存下来。
Linux 中用一个双向链表作为缓冲区,你可以观察下图中的 Buffer,看上去像一个有很多个凹槽的线性结构,每个凹槽(节点)可以存储一个封包,这个封包可以从网络层看(IP 封包),也可以从传输层看(TCP 封包)。操作系统不断地从 Buffer 中取出数据,数据通过一个协议栈,你可以把它理解成很多个协议的集合。协议栈中数据封包找到对应的协议程序处理完之后,就会形成 Socket 文件。
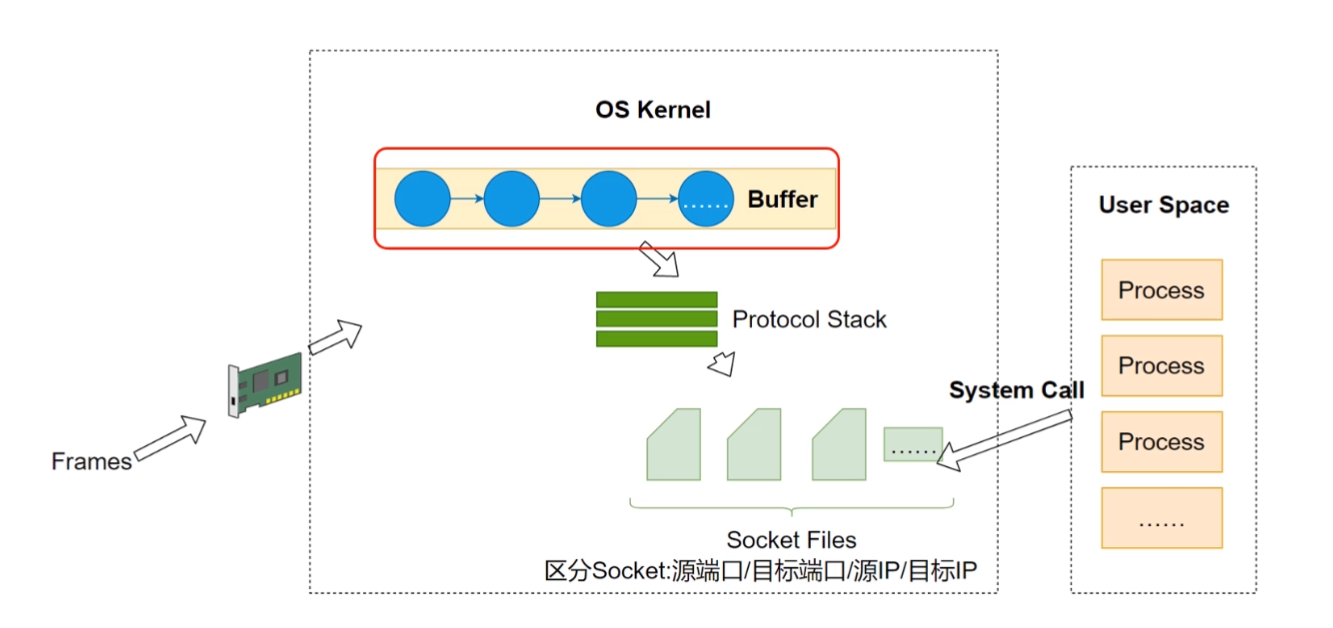
如果高并发的请求量级实在太大,有可能把 Buffer 占满,此时,操作系统就会拒绝服务。网络上有一种著名的攻击叫作拒绝服务攻击,就是利用的这个原理。操作系统拒绝服务,实际上是一种保护策略。通过拒绝服务,避免系统内部应用因为并发量太大而雪崩。
如上图所示,传入网卡的数据被我称为 Frames。一个 Frame 是数据链路层的传输单位(或封包)。现代的网卡通常使用 DMA 技术,将 Frame 写入缓冲区(Buffer),然后在触发 CPU 中断交给操作系统处理。操作系统从缓冲区中不断取出 Frame,通过协进栈(具体的协议)进行还原。
在 UNIX 系的操作系统中,一个 Socket 文件内部类似一个双向的管道。因此,非常适用于进程间通信。在网络当中,本质上并没有发生变化。网络中的 Socket 一端连接 Buffer, 一端连接应用——也就是进程。网卡的数据会进入 Buffer,Buffer 经过协议栈的处理形成 Socket 结构。通过这样的设计,进程读取 Socket 文件,可以从 Buffer 中对应节点读走数据。
对于 TCP 协议,Socket 文件可以用源端口、目标端口、源 IP、目标 IP 进行区别。不同的 Socket 文件,对应着 Buffer 中的不同节点。进程们读取数据的时候从 Buffer 中读取,写入数据的时候向 Buffer 中写入。通过这样一种结构,无论是读和写,进程都可以快速定位到自己对应的节点。
以上就是我们对操作系统和网络接口交互的一个基本讨论。接下来,我们讨论一下作为一个编程模型的 Socket。
Socket 编程模型
通过前面讲述,我们知道 Socket 在操作系统中,有一个非常具体的从 Buffer 到文件的实现。但是对于进程而言,Socket 更多是一种编程的模型。接下来我们讨论作为编程模型的 Socket。
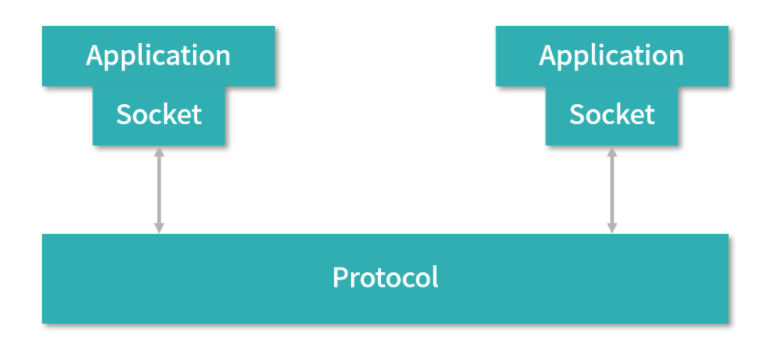
如上图所示,Socket 连接了应用和协议,如果应用层的程序想要传输数据,就创建一个 Socket。应用向 Socket 中写入数据,相当于将数据发送给了另一个应用。应用从 Socket 中读取数据,相当于接收另一个应用发送的数据。而具体的操作就是由 Socket 进行封装。具体来说,对于 UNIX 系的操作系统,是利用 Socket 文件系统,Socket 是一种特殊的文件——每个都是一个双向的管道。一端是应用,一端是缓冲区。
那么作为一个服务端的应用,如何知道有哪些 Socket 呢?也就是,哪些客户端连接过来了呢?这是就需要一种特殊类型的 Socket,也就是服务端 Socket 文件。
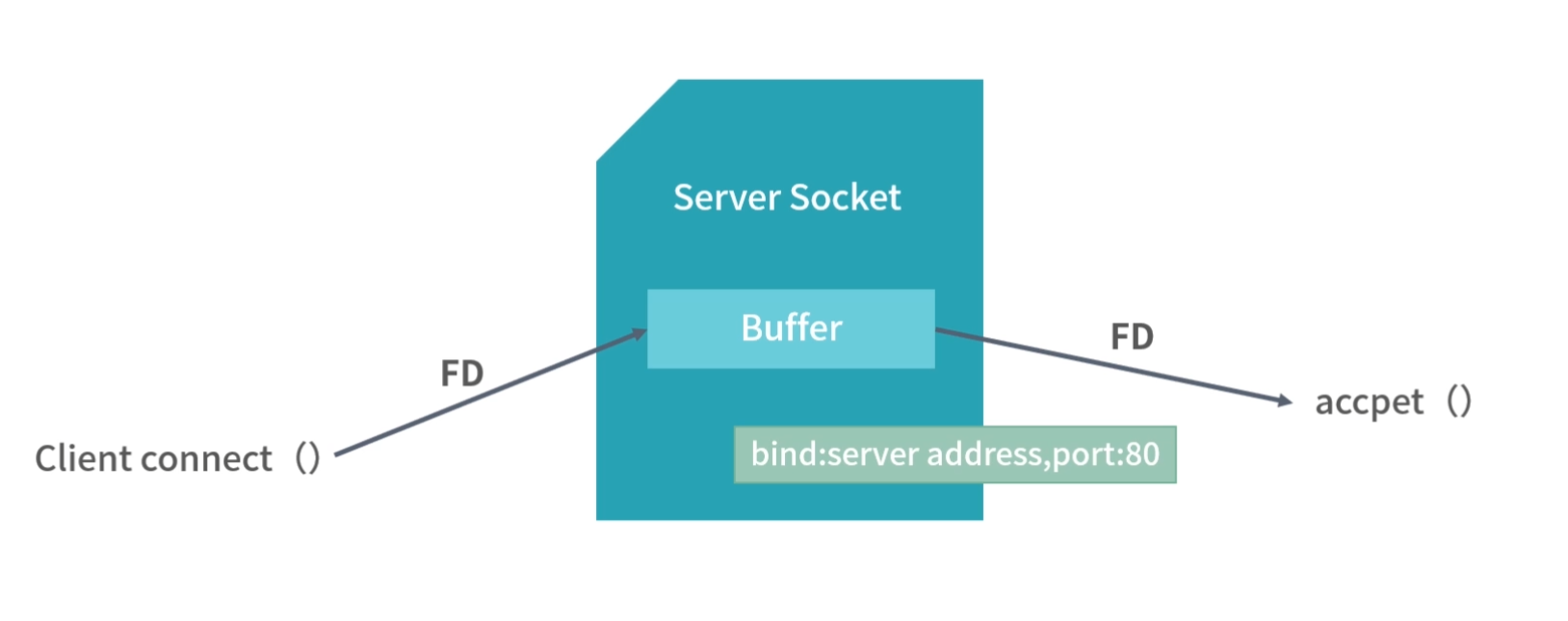
如上图所示,当有客户端连接服务端时,服务端 Socket 文件中会写入这个客户端 Socket 的文件描述符。进程可以通过 accept() 方法,从服务端 Socket 文件中读出客户端的 Socket 文件描述符,从而拿到客户端的 Socket 文件。
程序员实现一个网络服务器的时候,会先手动去创建一个服务端 Socket 文件。服务端的 Socket 文件依然会存在操作系统内核之中,并且会绑定到某个 IP 地址和端口上。以后凡是发送到这台机器、目标 IP 地址和端口号的连接请求,在形成了客户端 Socket 文件之后,文件的文件描述符都会被写入到服务端的 Socket 文件中。应用只要调用 accept 方法,就可以拿到这些客户端的 Socket 文件描述符,这样服务端的应用就可以方便地知道有哪些客户端连接了进来。
而每个客户端对这个应用而言,都是一个文件描述符。如果需要读取某个客户端的数据,就读取这个客户端对应的 Socket 文件。如果要向某个特定的客户端发送数据,就写入这个客户端的 Socket 文件。
以上就是 Socket 的编程模型。
I/O 多路复用
在上面的讨论当中,进程拿到了它关注的所有 Socket,也称作关注的集合(Intersting Set)。如下图所示,这种过程相当于进程从所有的 Socket 中,筛选出了自己关注的一个子集,但是这时还有一个问题没有解决:进程如何监听关注集合的状态变化,比如说在有数据进来,如何通知到这个进程?
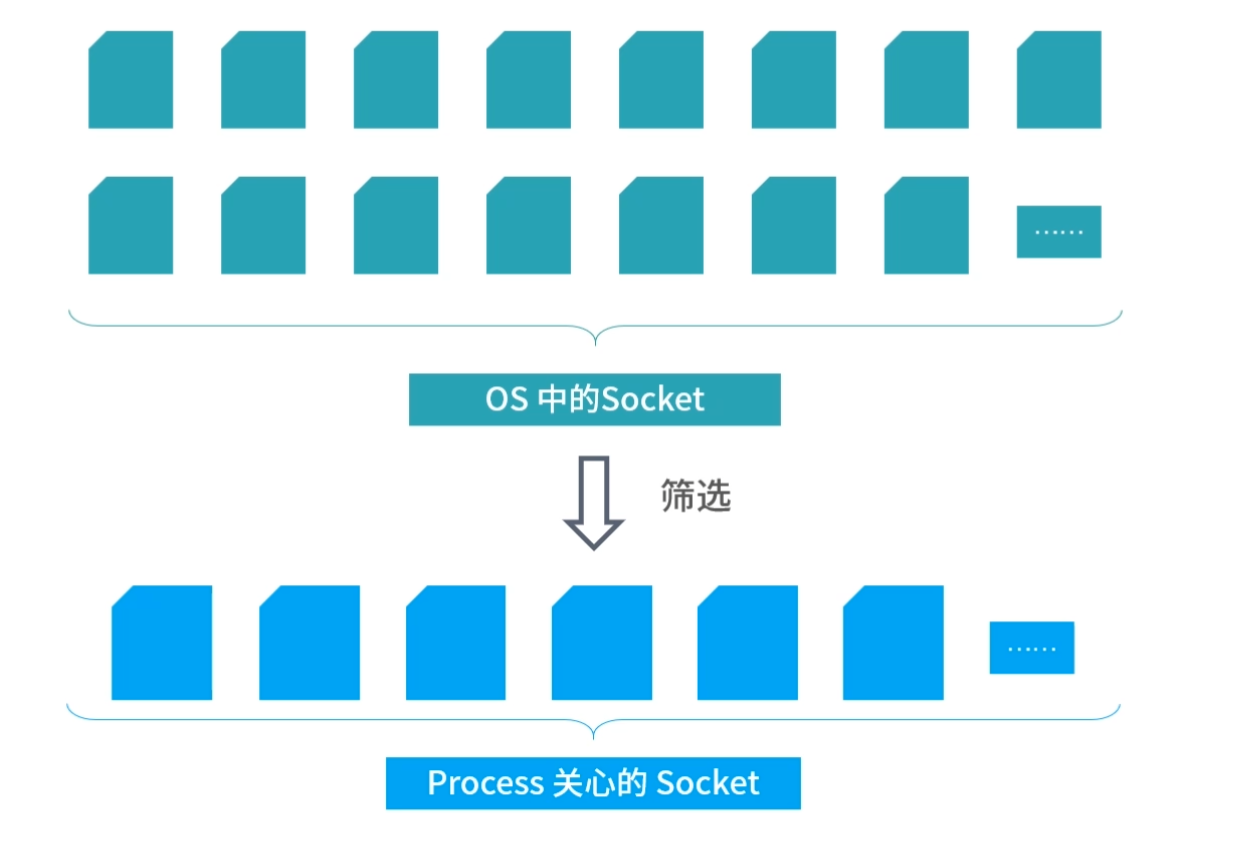
其实更准确地说,一个线程需要处理所有关注的 Socket 产生的变化,或者说消息。实际上一个线程要处理很多个文件的 I/O。所有关注的 Socket 状态发生了变化,都由一个线程去处理,构成了 I/O 的多路复用问题。如下图所示:
处理 I/O 多路复用的问题,需要操作系统提供内核级别的支持。Linux 下有三种提供 I/O 多路复用的 API,分别是:
- select
- poll
- epoll
如下图所示,内核了解网络的状态。因此不难知道具体发生了什么消息,比如内核知道某个 Socket 文件状态发生了变化。但是内核如何知道该把哪个消息给哪个进程呢?
一个 Socket 文件,可以由多个进程使用;而一个进程,也可以使用多个 Socket 文件。进程和 Socket 之间是多对多的关系。另一方面,一个 Socket 也会有不同的事件类型。因此操作系统很难判断,将哪样的事件给哪个进程。
这样在进程内部就需要一个数据结构来描述自己会关注哪些 Socket 文件的哪些事件(读、写、异常等)。通常有两种考虑方向,一种是利用线性结构,比如说数组、链表等,这类结构的查询需要遍历。每次内核产生一种消息,就遍历这个线性结构。看看这个消息是不是进程关注的?另一种是索引结构,内核发生了消息可以通过索引结构马上知道这个消息进程关不关注。
select()
select 和 poll 都采用线性结构,select 允许用户传入 3 个集合。如下面这段程序所示:
1 | fd_set read_fd_set, write_fd_set, error_fd_set; |
每次 select 操作会阻塞当前线程,在阻塞期间所有操作系统产生的每个消息,都会通过遍历的手段查看是否在 3 个集合当中。上面程序read_fd_set中放入的是当数据可以读取时进程关心的 Socket;write_fd_set是当数据可以写入时进程关心的 Socket;error_fd_set是当发生异常时进程关心的 Socket。
用户程序可以根据不同集合中是否有某个 Socket 判断发生的消息类型,程序如下所示:
1 | fd_set read_fd_set, write_fd_set, error_fd_set; |
上面程序中的 FD_SETSIZE 是一个系统的默认设置,通常是 1024。可以看出,select 模式能够一次处理的文件描述符是有上限的,也就是 FD_SETSIZE。当并发请求过多的时候, select 就无能为力了。但是对单台机器而言,1024 个并发已经是一个非常大的流量了。
接下来我给出一个完整的、用 select 实现的服务端程序供你参考,如下所示:
1 | #include <stdio.h> |
poll()
从写程序的角度来看,select 并不是一个很好的编程模型。一个好的编程模型应该直达本质,当网络请求发生状态变化的时候,核心是会发生事件。一个好的编程模型应该是直接抽象成消息:用户不需要用 select 来设置自己的集合,而是可以通过系统的 API 直接拿到对应的消息,从而处理对应的文件描述符。
比如下面这段伪代码就是一个更好的编程模型,具体的分析如下:
- poll 是一个阻塞调用,它将某段时间内操作系统内发生的且进程关注的消息告知用户程序;
- 用户程序通过直接调用 poll 函数拿到消息;
- poll 函数的第一个参数告知内核 poll 关注哪些 Socket 及消息类型;
- poll 调用后,经过一段时间的等待(阻塞),就拿到了是一个消息的数组;
- 通过遍历这个数组中的消息,能够知道关联的文件描述符和消息的类型;
- 通过消息类型判断接下来该进行读取还是写入操作;
- 通过文件描述符,可以进行实际地读、写、错误处理。
1 | while(true) { |
poll 虽然优化了编程模型,但是从性能角度分析,它和 select 差距不大。因为内核在产生一个消息之后,依然需要遍历 poll 关注的所有文件描述符来确定这条消息是否跟用户程序相关。
epoll
为了解决上述问题,epoll 通过更好的方案实现了从操作系统订阅消息。epoll 将进程关注的文件描述符存入一棵二叉搜索树,通常是红黑树的实现。在这棵红黑树当中,Key 是 Socket 的编号,值是这个 Socket 关注的消息。因此,当内核发生了一个事件:比如 Socket 编号 1000 可以读取。这个时候,可以马上从红黑树中找到进程是否关注这个事件。
另外当有关注的事件发生时,epoll 会先放到一个队列当中。当用户调用epoll_wait时候,就会从队列中返回一个消息。epoll 函数本身是一个构造函数,只用来创建红黑树和队列结构。epoll_wait调用后,如果队列中没有消息,也可以马上返回。因此epoll是一个非阻塞模型。
总结一下,select/poll 是阻塞模型,epoll 是非阻塞模型。当然,并不是说非阻塞模型性能就更好。在多数情况下,epoll 性能更好是因为内部有红黑树的实现。
最后我再贴一段用 epoll 实现的 Socket 服务给你做参考,这段程序的作者将这段代码放到了 Public Domain,你以后看到公有领域的代码可以放心地使用。
下面这段程序跟之前 select 的原理一致,对于每一个新的客户端连接,都使用 accept 拿到这个连接的文件描述符,并且创建一个客户端的 Socket。然后通过epoll_ctl将客户端的文件描述符和关注的消息类型放入 epoll 的红黑树。操作系统每次监测到一个新的消息产生,就会通过红黑树对比这个消息是不是进程关注的(当然这段代码你看不到,因为它在内核程序中)。
非阻塞模型的核心价值,并不是性能更好。当真的高并发来临的时候,所有的 CPU 资源,所有的网络资源可能都会被用完。这个时候无论是阻塞还是非阻塞,结果都不会相差太大。(前提是程序没有写错)。
epoll有 2 个最大的优势:
- 内部使用红黑树减少了内核的比较操作;
- 对于程序员而言,非阻塞的模型更容易处理各种各样的情况。程序员习惯了写出每一条语句就可以马上得到结果,这样不容易出 Bug。
1 | // Asynchronous Socket server - accepting multiple clients concurrently, |
重新思考:I/O 模型
在上面的模型当中,select/poll 是阻塞(Blocking)模型,epoll 是非阻塞(Non-Blocking)模型。阻塞和非阻塞强调的是线程的状态,所以阻塞就是触发了线程的阻塞状态,线程阻塞了就停止执行,并且切换到其他线程去执行,直到触发中断再回来。
还有一组概念是同步(Synchrounous)和异步(Asynchrounous),select/poll/epoll 三者都是同步调用。
同步强调的是顺序,所谓同步调用,就是可以确定程序执行的顺序的调用。比如说执行一个调用,知道调用返回之前下一行代码不会执行。这种顺序是确定的情况,就是同步。
而异步调用则恰恰相反,异步调用不明确执行顺序。比如说一个回调函数,不知道何时会回来。异步调用会加大程序员的负担,因为我们习惯顺序地思考程序。因此,我们还会发明像协程的 yield 、迭代器等将异步程序转为同步程序。
由此可见,非阻塞不一定是异步,阻塞也未必就是同步。比如一个带有回调函数的方法,阻塞了线程 100 毫秒,又提供了回调函数,那这个方法是异步阻塞。例如下面的伪代码:
1 | asleep(100ms, () -> { |
总结下,操作系统给大家提供各种各样的 API,是希望满足各种各样程序架构的诉求。但总体诉求其实是一致的:希望程序员写的单机代码,能够在多线程甚至分布式的环境下执行。这样你就不需要再去学习复杂的并发控制算法。从这个角度去看,非阻塞加上同步的编程模型确实省去了我们编程过程当中的很多思考。
但可惜的是,至少在今天这个时代,多线程、并发编程依然是程序员们的必修课。因此你在思考 I/O 模型的时候,还是需要结合自己的业务特性及系统自身的架构特点,进行选择。I/O 模型并不是选择效率,而是选择编程的手段。试想一个所有资源都跑满了的服务器,并不会因为是异步或者非阻塞模型就获得更高的吞吐量。
select/poll/epoll 有什么区别?
这三者都是处理 I/O 多路复用的编程手段。select/poll 模型是一种阻塞模型,epoll 是非阻塞模型。select/poll 内部使用线性结构存储进程关注的 Socket 集合,因此每次内核要判断某个消息是否发送给 select/poll 需要遍历进程关注的 Socket 集合。
而 epoll 不同,epoll 内部使用二叉搜索树(红黑树),用 Socket 编号作为索引,用关注的事件类型作为值,这样内核可以在非常快的速度下就判断某个消息是否需要发送给使用 epoll 的线程。
公私钥体系和网络安全:什么是中间人攻击?
设想你和一个朋友签订了合同,双方各执一份。如果朋友恶意篡改了合同内容,比如替换了合同中的条款,最后大家闹到法院、各执一词。这个时候就需要专业鉴定机构去帮你鉴定合同的真伪,朋友花越多心思去伪造合同,那么鉴定的成本就会越高。
在网络安全领域有个说法:没有办法杜绝网络犯罪,只能想办法提高网络犯罪的成本。我们的目标是提高作案的成本,并不是杜绝这种现象。今天我将带你初探网络安全的世界,学习网络安全中最重要的一个安全体系——公私钥体系。
摘要算法
一家具有公信力的机构对内部需要严格管理。那么当合同存储下来之后,为了防止内部人员篡改合同,这家机构需要做什么呢?
很显然,这家机构需要证明合同没有被篡改。一种可行的做法,就是将合同原文和摘要一起存储。你可以把摘要算法理解成一个函数,原文经过一系列复杂的计算后,产生一个唯一的散列值。只要原文发生一丁点的变动,这个散列值就会发生变化。
目前比较常见的摘要算法有消息摘要算法(\Message Digest Algorithm, MD5)和**安全散列算法**(Secure Hash Algorithm, SHA)。MD5 可以将任意长度的文章转化为一个 128 位的散列值。2004 年,MD5 被证实会发生碰撞,发生碰撞就是两篇原文产生了相同的摘要。这是非常危险的事情,这将允许黑客进行多种攻击手段,甚至可以伪造摘要。
因此在这之后,我们通常首选 SHA 算法。你不需要知道算法的准确运算过程,只需要知道 SHA 系的算法更加安全即可。在实现普通应用的时候可以使用 MD5,在计算对安全性要求极高的摘要时,就应该使用 SHA,比如订单、账号信息、证书等。
安全保存的困难
采用摘要算法,从理论上来说就杜绝了篡改合同的内容的做法。但在现实当中,公司也有可能出现内鬼。我们不能假定所有公司内部员工的行为就是安全的。因此可以考虑将合同和摘要分开存储,并且设置不同的权限。这样就确保在机构内部,没有任何一名员工同时拥有合同和摘要的权限。但是即便如此,依然留下了巨大的安全隐患。比如两名员工串通一气,或者员工利用安全漏洞,和外部的不法分子进行非法交易。
那么现在请你思考这个问题:如何确保公司内部的员工不会篡改合同呢?当然从理论上来说是做不到的。没有哪个系统能够杜绝内部人员接触敏感信息,除非敏感信息本身就不存在。因此,可以考虑将原文存到合同双方的手中,第三方机构中只存摘要。但是这又产生了一个新的问题,会不会有第三方机构的员工和某个用户串通一气修改合同呢?
至此,事情似乎陷入了僵局。由第三方平台保存合同,背后同样有很大的风险。而由用户自己保存合同,就是签约双方交换合同原文及摘要。但是这样的形式中,摘要本身是没有公信力的,无法证明合同和摘要确实是对方给的。
因此我们还要继续思考最终的解决方案:类比我们交换合同,在现实世界当中,还伴随着签名的交换。那么在计算机的世界中,签名是什么呢?
数字签名和证书
在计算机中,数字签名是一种很好的实现签名(模拟现实世界中签名)的方式。 所谓数字签名,就是对摘要进行加密形成的密文。
举个例子:现在 Alice 和 Bob 签合同。Alice 首先用 SHA 算法计算合同的摘要,然后用自己私钥将摘要加密,得到数字签名。Alice 将合同原文、签名,以及公钥三者都交给 Bob。如下图所示:
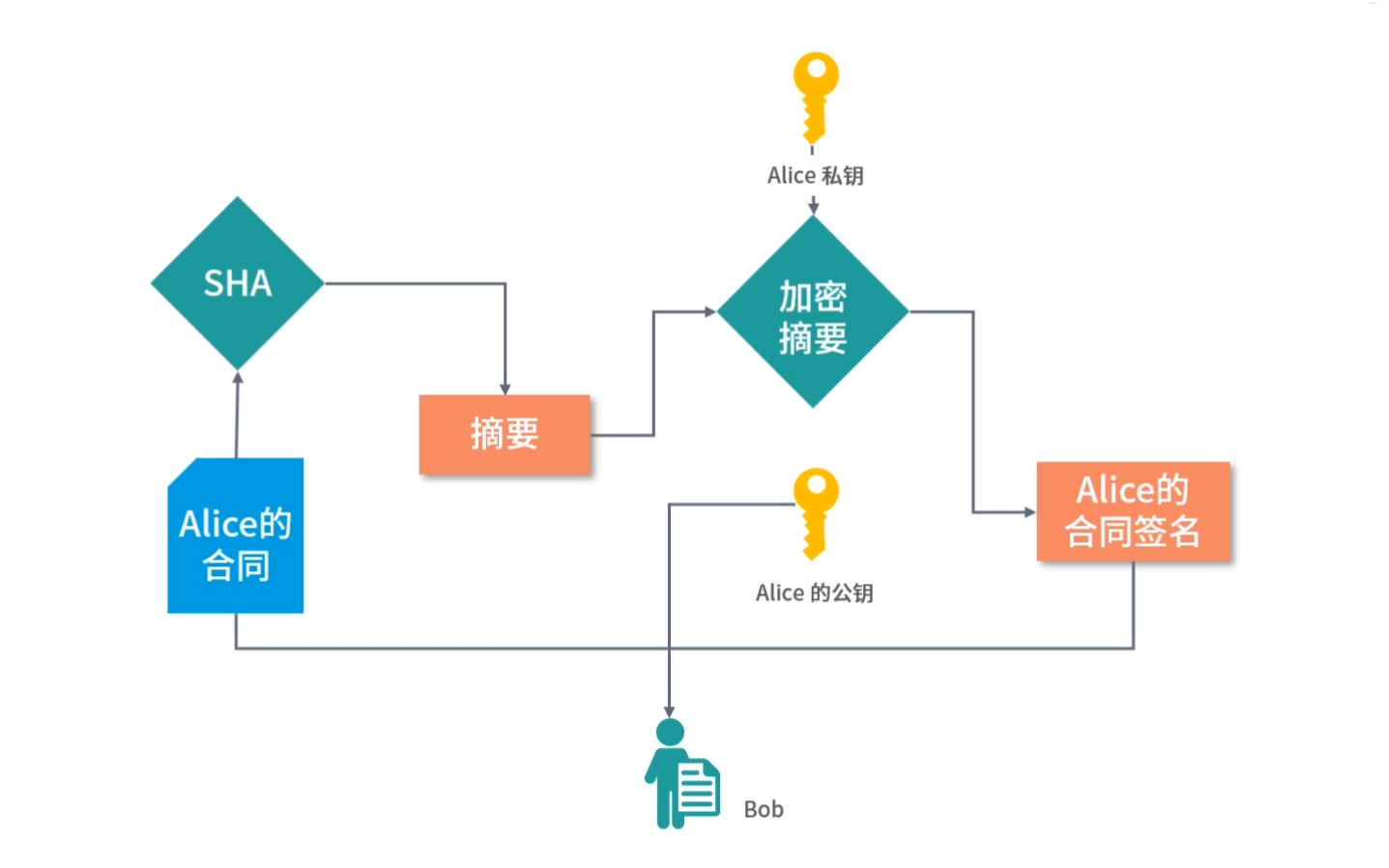
Bob 如果想证明合同是 Alice 的,就要用 Alice 的公钥,将签名解密得到摘要 X。然后,Bob 计算原文的 SHA 摘要 Y。Bob 对比 X 和 Y,如果 X = Y 则说明数据没有被篡改过。
在这样的一个过程当中,Bob 不能篡改 Alice 合同。因为篡改合同不但要改原文还要改摘要,而摘要被加密了,如果要重新计算摘要,就必须提供 Alice 的私钥。所谓私钥,就是 Alice 独有的密码。所谓公钥,就是 Alice 公布给他人使用的密码。
公钥加密的数据,只有私钥才可以解密。私钥加密的数据,只有公钥才可以解密。这样的加密方法我们称为非对称加密,基于非对称加密算法建立的安全体系,也被称作公私钥体系。用这样的方法,签约双方都不可以篡改合同。
证书
但是在上面描述的过程当中,仍然存在着一个非常明显的信任风险。这个风险在于,Alice 虽然不能篡改合同,但是可以否认给过 Bob 的公钥和合同。这样,尽管合同双方都不可以篡改合同本身,但是双方可以否认签约行为本身。
如果要解决这个问题,那么 Alice 提供的公钥,必须有足够的信誉。这就需要引入第三方机构和证书机制。
证书为公钥提供方提供公正机制。证书之所以拥有信用,是因为证书的签发方拥有信用。假设 Alice 想让 Bob 承认自己的公钥。Alice 不能把公钥直接给 Bob,而是要提供第三方公证机构签发的、含有自己公钥的证书。如果 Bb 也信任这个第三方公证机构,信任关系和签约就成立。当然,法律也得承认,不然没法打官司。
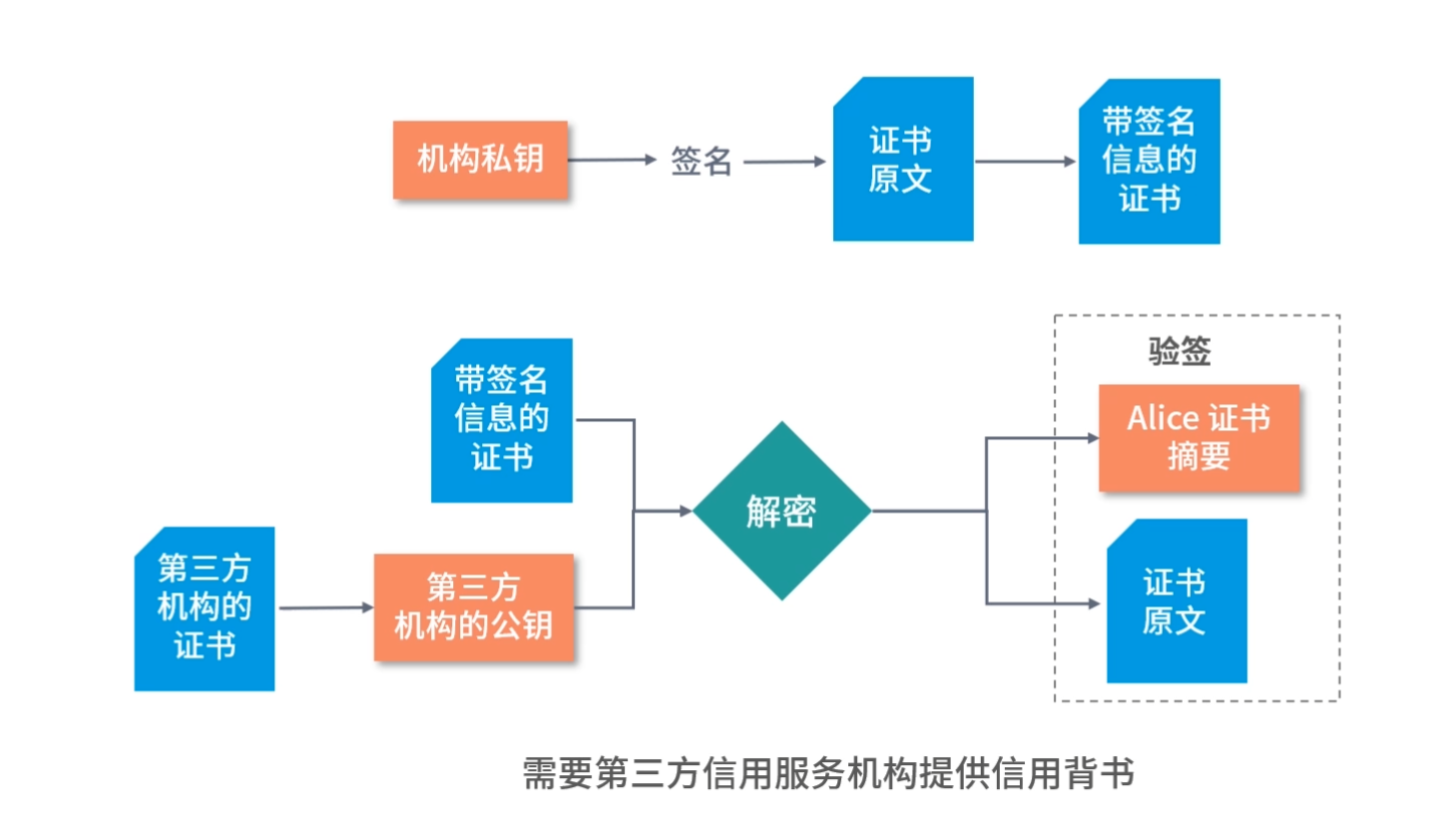
如上图所示,Alice 将自己的申请提交给机构,产生证书的原文。机构用自己的私钥签名 Alice 的申请原文(先根据原文内容计算摘要,再用私钥加密),得到带有签名信息的证书。Bob 拿到带签名信息的证书,通过第三方机构的公钥进行解密,获得 Alice 证书的摘要、证书的原文。有了 Alice 证书的摘要和原文,Bob 就可以进行验签。验签通过,Bob 就可以确认 Alice 的证书的确是第三方机构签发的。
用上面这样一个机制,合同的双方都无法否认合同。这个解决方案的核心在于需要第三方信用服务机构提供信用背书。这里产生了一个最基础的信任链,如果第三方机构的信任崩溃,比如被黑客攻破,那整条信任链条也就断裂了。
信任链
为了固化信任关系,减少风险。最合理的方式就是在互联网中打造一条更长的信任链,环环相扣,避免出现单点的信任风险。
上图中,由信誉最好的根证书机构提供根证书,然后根证书机构去签发二级机构的证书;二级机构去签发三级机构的证书;最后有由三级机构去签发 Alice 证书。
- 如果要验证 Alice 证书的合法性,就需要用三级机构证书中的公钥去解密 Alice 证书的数字签名。
- 如果要验证三级机构证书的合法性,就需要用二级机构的证书去解密三级机构证书的数字签名。
- 如果要验证二级结构证书的合法性,就需要用根证书去解密。
以上,就构成了一个相对长一些的信任链。如果其中一方想要作弊是非常困难的,除非链条中的所有机构同时联合起来,进行欺诈。
中间人攻击
最后我们再来说说中间人攻击。在 HTTPS 协议当中,客户端需要先从服务器去下载证书,然后再通过信任链验证服务器的证书。当证书被验证为有效且合法时,客户端和服务器之间会利用非对称加密协商通信的密码,双方拥有了一致的密码和加密算法之后,客户端和服务器之间会进行对称加密的传输。
在上述过程当中,要验证一个证书是否合法,就必须依据信任链,逐级的下载证书。但是根证书通常不是下载的,它往往是随着操作系统预安装在机器上的。如果黑客能够通过某种方式在你的计算机中预装证书,那么黑客也可以伪装成中间节点。如下图所示:

一方面,黑客向客户端提供伪造的证书,并且这个伪造的证书会在客户端中被验证为合法。因为黑客已经通过其他非法手段在客户端上安装了证书。举个例子,比如黑客利用 U 盘的自动加载程序,偷偷地将 U 盘插入客户端机器上一小段时间预装证书。
安装证书后,黑客一方面和客户端进行正常的通信,另一方面黑客和服务器之间也建立正常的连接。这样黑客在中间就可以拿到客户端到服务器的所有信息,并从中获利。
什么是中间人攻击?
【解析】中间人攻击中,一方面,黑客利用不法手段,让客户端相信自己是服务提供方。另一方面,黑客伪装成客户端和服务器交互。这样黑客就介入了客户端和服务之间的连接,并从中获取信息,从而获利。在上述过程当中,黑客必须攻破信任链的体系,比如直接潜入对方机房现场暴力破解、诱骗对方员工在工作电脑中安装非法的证书等。
另外,有很多的网络调试工具的工作原理,和中间人攻击非常类似。为了调试网络的请求,必须先在客户端装上自己的证书。这样作为中间人节点的调试工具,才可以获取客户端和服务端之间的传输。
IPv4 和 IPv6 有什么区别?
IPv4 和 IPv6 最大的区别是地址空间大小不同。
- IPv4 是用 32 位描述 IP 地址,理论极限约在 40 亿 IP 地址;
- IPv6 是用 128 位描述 IP 地址,IPv6 可以大到给每个人都分配 40 亿个 IP 地址,甚至更多的 IP 地址。
IPv4 地址不够用,因此需要划分子网。比如公司的几千台机器(计算机、手机),复用一个出口 IP 地址。子网内部,就用 192.168 开头的 IP 地址。
而 IPv6 地址够用,可以给全世界每台设备都分配一个地址,也可以给每一个组织(甚至家庭)都分配数以亿计的地址,目前不存在地址枯竭的问题。因此不需要像 IPv4 那样通过网络地址转换协议(NAT)去连接子网和外部网络。
因为地址数目的不同导致这两个协议在分配 IP 地址的时候行为也不一样。
IPv4 地址,空间小,如果没有一个中心的服务为所有设备分配地址,那么产生的冲突非常严重。所以IPv4 地址分配,是一种中心化的请求/返回的模式。客户端向服务端请求,分配地址。服务端,将计算好可以分配的地址返回给客户端。
而 IPv6 可以采用先计算,再申请的模式。由客户端自己随机抽取得出一个 IP 地址(能这样做是因为闲置的 IP 地址太多,随机抽取一个大概率没有设备使用),然后再向这个 IP 地址发送信息。如果没有得到返回,那么说明这个 IP 地址还没有设备使用。大体来说,这就是 IPv6 邻居发现协议,但上述内容只是其中该协议的一小部分。
以上是 IPv4 和 IPv6 最重要的几个区别。如果你对这块内容比较感兴趣,比如 IPv6 具体的地址格式?127.0.0.1 是什么 IP 地址?封包有什么区别?可以查阅更多的资料,比如 IPv6 的 RFC 文档。
SSH(Secure Shell)工具可不可以用 UDP 实现?
SSH(Secure Shell)是一种网络加密协议,可以帮助我们在不安全的网络上构建安全的传输。和 HTTPS 类似,SSH 先用非对称加密。协商密钥和参数,在目标机器登录后。利用对称加密,建立加密通道(Channel)传输数据。
通常的 SSH 协议的底层要求是 TCP 协议。但是如果你愿意用 UDP 实现 SSH 需要的可靠性,就可以替代原有 TCP 协议的能力。只不过因为 SSH 协议对吞吐量要求并不高,而 TCP 的延迟也足够用,所以这样做的收益也不会非常的高。如果想构建安全的远程桌面,可以考虑在 UDP 上实现专门的安全传输协议来提高吞吐量、降低延迟。
事实上,安全传输协议也有建立在 UDP 之上的。比如说IBM 的FASP(Fast and Secure Protocol)协议,它不像 TCP 一样自动去判断封包丢失,也不会给每一个封包一个响应,它只重传接收方显示指定没有收到的封包。因而这个协议在传输文件的时候,有更快的速度。
如果用 epoll 架构一个Web 服务器应该是一个怎样的架构?
每一个客户端连接进来之后都是一个 Socket 文件。接下来,对于 Web 服务器而言,要处理的是文件的 I/O,以及在 I/O 结束之后进行数据、业务逻辑的处理。
- I/O:这部分的主要开销在于从 Socket 文件中读出数据到用户空间。比如说读取出 HTTP 请求的数据并把它们存储到一个缓冲区当中。
- **处理部分(Processing)**:这部分的开销有很多个部分。比如说,需要将 HTTP 请求从字节的表示转化为字符串的表示,然后再解析。还需要将 HTTP 请求的字符串,分成各个部分。头部(Header)是一个 Key-Value 的映射(Map)。Body 部分,可能是 QueryString,JSON,XML 等。完成这些处理之后,可能还会进行读写数据库、业务逻辑计算、远程调用等。
我们先说处理部分(Processing) 的开销,目前主要有下面这样几种架构。
- 为每一次处理创建一个线程。
这样做线程之间的相互影响最小。只要有足够多的资源,就可以并发完成足够多的工作。但是缺点在于线程的、创建和销毁成本。虽然单次成本不高,但是积累起来非常也是一个不小的数字——比如每秒要处理 1 万个请求的情况。更关键的问题在于,在并发高的场景下,这样的设计可能会导致创建的线程太多,导致线程切换太频繁,最终大量线程阻塞,系统资源耗尽,最终引发雪崩。
- 通过线程池管理线程。
这样做最大的优势在于拥有反向压力。所谓反向压力(Back-Presure)就是当系统资源不足的时候可以阻塞生产者。对任务处理而言,生产者就是接收网络请求的 I/O 环节。当压力太大的时候,拒绝掉部分请求,从而缓解整个系统的压力。比如说我们可以控制线程池中最大的线程数量,一般会多于 CPU 的核数,小于造成系统雪崩的数量,具体数据需要通过压力测试得出。
- 利用协程。
在一个主线程中实现更轻量级的线程,通常是实现协程或者类似的东西。将一个内核级线程的执行时间分片,分配给 n 个协程。协程之间会互相转让执行资源,比如一个协程等待 I/O,就会将计算资源转让给其他的协程。转换过程不需要线程切换,类似函数调用的机制。这样最大程度地利用了计算资源,因此性能更好。
最后强调一下,GO 语言实现的不是协程,是轻量级的线程,但是效果也非常好。Node.js 实现了类似协程的单位,称为任务,效果也很不错。Java 新标准也在考虑支持协程,目前也有一些讨论——考虑用 Java 的异常处理机制实现协程。你可以根据自己的研究或者工作方向去查阅更多相关的资料。
接下来我们说说 I/O 部分的架构。I/O 部分就是将数据从 Socket 文件中读取出来存储到用户空间的内存中去。我们将所有需要监听的 Socket 文件描述符,都放到 epoll 红黑树当中,就进入了一种高性能的处理状态。但是读取文件的操作,还有几种选择。
- 单线程读取所有文件描述符的数据。 读取的过程利用异步 I/O,所以这个线程只需要发起 I/O 和响应中断。每次中断的时候,数据拷贝到用户空间,这个线程就将接收数据的缓冲区传递给处理模块。虽然这个线程要处理很多的 I/O,但因为只需要处理中断,所以压力并不大。
- 多线程同步 I/O。 用很多个线程通过同步 I/O 的模式去处理文件描述符。这个方式在通常的情况下,可以完成工作。但是在高并发的场景下,会浪费很多的 CPU 资源。
- 零拷贝技术, 通常和异步 I/O 结合使用。比如 mmap 处理过程——数据从磁盘文件读取到内核的过程不需要 CPU 的参与(DMA 技术),因此节省了大量开销。内核也不将数据再向用户空间拷贝,而是直接将缓冲区共享给用户空间,这样又节省了一次拷贝。但是需要注意,并不是所有的操作系统都支持这种模式。
由此可见,优化 Web 服务器底层是在优化 I/O 的模型;中间层是在优化处理数据、远程调用等的模型。这两个过程要分开来看,都需要优化。
如何预防中间人攻击?
中间人攻击最核心的就是要攻破信任链。比如说替换掉目标计算机中的验证程序,在目标计算机中安装证书,都可以作为中间人攻击的方式。因此在公司工作的时候,我们经常强调,要将电脑锁定再离开工位,防止有人物理破解。不要接收来历不明的邮件,防止一不小心被安装证书。也不要使用盗版的操作系统,以及盗版的软件。这些都是非法证书的来源。
另外一种情况就是服务器被攻破。比如内部员工机器中毒,密码泄露,导致黑客远程拿到服务器的私钥。再比如说,数据库被攻击、网站被挂码,导致系统被 Root。在这种情况下,黑客就可以作为中间人解密所有消息,为所欲为了。
安全无小事,在这里我再多说一句,平时大家不要将密码交给同事,也不要在安全的细节上掉以轻心。安全是所有公司的一条红线,需要大家一同去努力维护。
VMware 和 Docker 的区别?
都说今天是一个云时代,其实云的本质就是由基础架构提供商提供基础架构,应用开发商不再关心基础架构。我们可以类比人类刚刚发明电的时候,工厂需要自己建电站,而现在只需要电线和插座就可以使用电。
云时代让我们可以在分钟、甚至秒级时间内获得计算、存储、操作系统等资源。设备不再论个卖,而是以一个虚拟化单位售卖,比如:
- 用户可以买走一个 64 核 CPU 机器中的 0.25 个 CPU;
- 也可以买走一个 128GB 内存机器中的 512M 内存;
- 还可以买走 1/2 台机器三个小时了执行时间。
实现以上这些,就需要虚拟化技术。这一讲我将以虚拟化技术中两种最具代表性的设计——VMware 和 Docker,为你解读解虚拟化技术。
什么是“虚拟化”
顾名思义,虚拟是相对于现实而言。虚拟化(Virutualization)通常是指构造真实的虚拟版本。不严谨地说,用软件模拟计算机,就是虚拟机;用数字模拟价值,就是货币;用存储空间模拟物理存储,就是虚拟磁盘。
VMware 和 Docker 是目前虚拟化技术中最具代表性的两种设计。VMware 为应用提供虚拟的计算机(虚拟机);Docker 为应用提供虚拟的空间,被称作容器(Container),关于空间的含义,我们会在下文中详细讨论。
VMware在 1998 年诞生,通过 Hypervisor 的设计彻底改变了虚拟化技术。2005 年,VMware 不断壮大,在全球雇用了 1000 名员工,成为世界上最大的云基础架构提供商。
Docker则是 2013 年发布的一个社区产品,后来逐渐在程序员群体中流行了起来。大量程序员开始习惯使用 Docker,所以各大公司才决定使用它。在“38 讲”中我们要介绍的 Kubernates(K8s)容器编排系统,一开始也是将 Docker 作为主要容器。虽然业内不时有传出二者即将分道扬镳的消息,但是目前(2021 年)K8s 下的容器主要还是 Docker。
虚拟机的设计
接下来我们说说虚拟机设计。要虚拟一台计算机,要满足三个条件:隔离、仿真、高效。
隔离(Isolation), 很好理解,指的是一台实体机上的所有的虚拟机实例不能互相影响。这也是早期设计虚拟机的一大动力,比如可以在一台实体机器上同时安装 Linux、Unix、Windows、MacOS 四种操作系统,那么一台实体机器就可以执行四种操作系统上的程序,这就节省了采购机器的开销。
仿真(Simulation)指的是用起来像一台真的机器那样,包括开机、关机,以及各种各样的硬件设备。在虚拟机上执行的操作系统认为自己就是在实体机上执行。仿真主要的贡献是让进程可以无缝的迁移,也就是让虚拟机中执行的进程,真实地感受到和在实体机上执行是一样的——这样程序从虚拟机到虚拟机、实体机到虚拟机的应用迁移,就不需要修改源代码。
高效(Efficient)的目标是减少虚拟机对 CPU、对硬件资源的占用。通常在虚拟机上执行指令需要额外负担 10~15% 的执行成本,这个开销是相对较低的。因为应用通常很少将 CPU 真的用满,在容器中执行 CPU 指令开销会更低更接近在本地执行程序的速度。
为了实现上述的三种诉求,最直观的方案就是将虚拟机管理程序 Hypervisor 作为操作系统,在虚拟机管理程序(Hypervisor)之上再去构建更多的虚拟机。像这种管理虚拟机的架构,也称为 Type-1 虚拟机,如下图所示:
我们通常把虚拟机管理程序(Virtual Machine Monitor,VMM)称为 Hypervisor。在 Type-1 虚拟机中,Hypervisor 一方面作为操作系统管理硬件,另一方面作为虚拟机的管理程序。在 Hypervisor 之上创建多个虚拟机,每个虚拟机可以拥有不同的操作系统(Guest OS)。
二进制翻译
通常硬件的设计假定是由单操作系统管理的。如果多个操作系统要共享这些设备,就需要通过 Hypervisor。当操作系统需要执行程序的时候,程序的指令就通过 Hypervisor 执行。早期的虚拟机设计当中,Hypervisor 不断翻译来自虚拟机的程序指令,将它们翻译成可以适配在目标硬件上执行的指令。这样的设计,我们称为二进制翻译。
二进制翻译的弱点在于性能,所有指令都需要翻译。相当于在执行所有指令的时候,都会产生额外的开销。当然可以用动态翻译技术进行弥补,比如说预读指令进行翻译,但是依然会产生较大的性能消耗。
世界切换和虚拟化支持
另一种方式就是当虚拟机上的应用需要执行程序的时候,进行一次世界切换(World Switch)。所谓世界切换就是交接系统的控制权,比如虚拟机上的操作系统,进入内核接管中断,成为实际的机器的控制者。在这样的条件下,虚拟机上程序的执行就变成了本地程序的执行。相对来说,这种切换行为相较于二进制翻译,成本是更低的。
为了实现世界切换,虚拟机上的操作系统需要使用硬件设备,比如内存管理单元(MMR)、TLB、DMA 等。这些设备都需要支持虚拟机上操作系统的使用,比如说 TLB 需要区分是虚拟机还是实体机程序。虽然可以用软件模拟出这些设备给虚拟机使用,但是如果能让虚拟机使用真实的设备,性能会更好。现在的 CPU 通常都支持虚拟化技术,比如 Intel 的 VT-X 和 AMD 的 AMD-V(也称作 Secure Virtual Machine)。如果你对硬件虚拟化技术非常感兴趣,可以阅读这篇文档。
Type-2 虚拟机
Type-1 虚拟机本身是一个操作系统,所以需要用户预装。为了方便用户的使用,VMware 还推出了 Type-2 虚拟机,如下图所示:
在第二种设计当中,虚拟机本身也作为一个进程。它和操作系统中执行的其他进程并没有太大的区别。但是为了提升性能,有一部分 Hypervisor 程序会作为内核中的驱动执行。当虚拟机操作系统(Guest OS)执行程序的时候,会通过 Hypervisor 实现世界切换。因此,虽然和 Type-1 虚拟机有一定的区别,但是从本质上来看差距不大,同样是需要二进制翻译技术和虚拟化技术。
Hyper-V
随着虚拟机的发展,现在也出现了很多混合型的虚拟机,比如微软的 Hyper-v 技术。从下图中你会看到,虚拟机的管理程序(Parent Partition)及 Windows 的核心程序,都会作为一个虚拟化的节点,拥有一个自己的 VMBus,并且通过 Hypervisor 实现虚拟化。
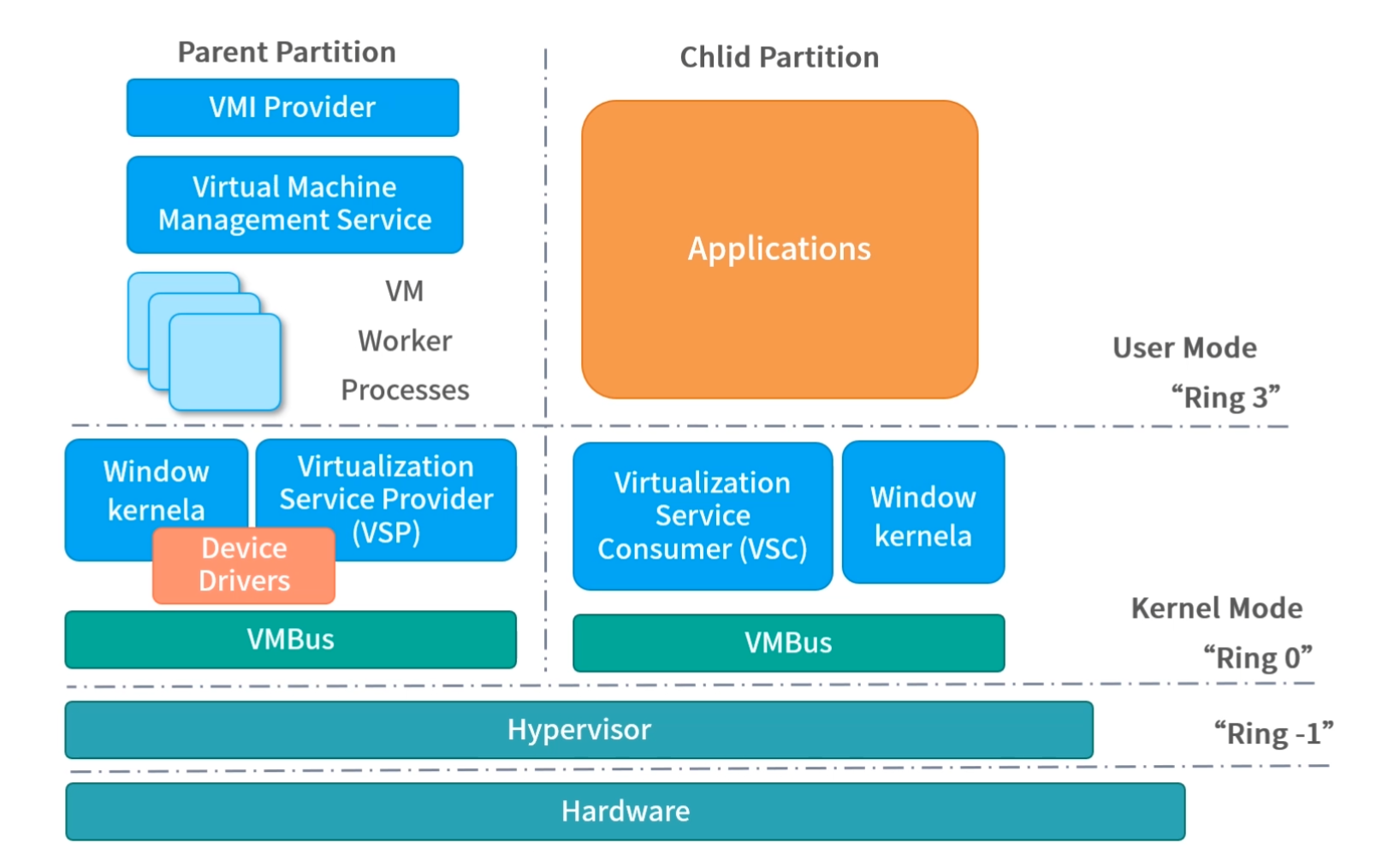
在 Hyper-V 的架构当中不存在一个主的操作系统。实际上,用户开机之后就在使用虚拟机,Windows 通过虚拟机执行。在这种架构下,其他的虚拟机,比如用 VMware 管理的虚拟机也可以复用这套架构。当然,你也可以直接把 Linux 安装在 Hyper-V 下,只不过安装过程没有 VMWare 傻瓜化,其实也是很不错的选择。
容器(Container)
虚拟机虚拟的是计算机,容器虚拟的是执行环境。每个容器都是一套独立的执行环境,如下图所示,容器直接被管理在操作系统之内,并不需要一个虚拟机监控程序。
和虚拟机有一个最大的区别就是:容器是直接跑在操作系统之上的,容器内部是应用,应用执行起来就是进程。这个进程和操作系统上的其他进程也没有本质区别,但这个架构设计没有了虚拟机监控系统。当然,容器有一个更轻量级的管理程序,用户可以从网络上下载镜像,启动起来就是容器。容器中预装了一些程序,比如说一个 Python 开发环境中,还会预装 Web 服务器和数据库。因为没有了虚拟机管理程序在中间的开销,因而性能会更高。而且因为不需要安装操作系统,因此容器安装速度更快,可以达到 ms 级别。
容器依赖操作系统的能力直接实现,比如:
- Linux 的 Cgroups(Linux Control Groups)能力,可以用来限制某组进程使用的 CPU 资源和内存资源,控制进程的资源能使用;
- 另外Linux 的 Namespace 能力,可以设置每个容器能看到能够使用的目录和文件。
有了这两个能力,就可以基本控制容器间的隔离,容器中的应用直接以进程的身份执行即可。进程间的目录空间、 CPU 资源已经被隔离了,所以不用担心互相影响。
VMware 和 Docker 的区别?
【解析】 VMware 提供虚拟机,Docker 提供容器。 虚拟机是一台完整的计算机,因此需要安装操作系统。虚拟机中的程序执行在虚拟机的操作系统上,为了让多个操作系统可以高效率地同时执行,虚拟机非常依赖底层的硬件架构提供的虚拟化能力。容器则是利用操作系统的能力直接实现隔离,容器中的程序可以以进程的身份直接执行。
如何利用 K8s 和 Docker Swarm 管理微服务?
现在的面试官都喜欢问微服务相关的内容。微服务(Micro Service),指的是服务从逻辑上不可再分,是宏服务(Mono Service)的反义词。
比如初学者可能认为交易相关的服务都应该属于交易服务,但事实上,交易相关的服务可能会有交易相关的配置服务、交易数据的管理服务、交易履约的服务、订单算价的服务、流程编排服务、前端服务……
所以到底什么是不可再分呢?
其实没有不可再分,永远都可以继续拆分下去。只不过从逻辑上讲,系统的拆分,应该结合公司部门组织架构的调整,反映公司的战斗结构编排。但总的来说,互联网上的服务越来越复杂,几个简单的接口就可能形成一个服务,这些服务都要上线。如果用实体机来承载这些服务,开销太大。如果用虚拟机来承载这些服务倒是不错的选择,但是创建服务的速度太慢,不适合今天这个时代的研发者们。
试想你的系统因为服务太多,该如何管理?尤其是在大型的公司,员工通过自发组织架构评审就可以上线微服务——天长日久,微服务越来越多,可能会有几万个甚至几十万个。那么这么多的微服务,如何分布到数万台物理机上工作呢?
如下图所示,为了保证微服务之间是隔离的,且可以快速上线。每个微服务我们都使用一个单独的容器,而一组容器,又包含在一个虚拟机当中,具体的关系如下图所示:
上图中的微服务 C 因为只有一个实例存在单点风险,可能会引发单点故障。因此需要为微服务 C 增加副本,通常情况下,我们必须保证每个微服务至少有一个副本,这样才能保证可用性。
上述架构的核心就是要解决两个问题:
- 减少 downtime(就是减少服务不可用的时间);
- 支持扩容(随时都可以针对某个微服务增加容器)。
因此,我们需要容器编排技术。容器编排技术指自动化地对容器进行部署、管理、扩容、迁移、保证安全,以及针对网络负载进行优化等一系列技术的综合体。Kubernetes 和 Docker Swarm 都是出色的容器编排方案。
Kubernetes
Kubernetes(K8s)是一个 Google 开源的容器编排方案。
节点(Master&Worker)
K8s 通过集群管理容器。用户可以通过命令行、配置文件管理这个集群——从而编排容器;用户可以增加节点进行扩容,每个节点是一台物理机或者虚拟机。如下图所示,Kubernetes 提供了两种分布式的节点。Master 节点是集群的管理者,Worker 是工作节点,容器就在 Worker 上工作,一个 Worker 的内部可以有很多个容器。
在我们为一个微服务扩容的时候,首选并不是去增加 Worker 节点。可以增加这个微服务的容器数量,也可以提升每个容器占用的 CPU、内存存储资源。只有当整个集群的资源不够用的时候,才会考虑增加机器、添加节点。
Master 节点至少需要 2 个,但并不是越多越好。Master 节点主要是管理集群的状态数据,不需要很大的内存和存储空间。Worker 节点根据集群的整体负载决定,一些大型网站还有弹性扩容的手段,也可以通过 K8s 实现。
单点架构
接下来我们讨论一下 Worker 节点的架构。所有的 Worker 节点上必须安装 kubelet,它是节点的管理程序,负责在节点上管理容器。
Pod 是 K8s 对容器的一个轻量级的封装,每个 Pod 有自己独立的、随机分配的 IP 地址。Pod 内部是容器,可以 1 个或多个容器。目前,Pod 内部的容器主要是 Docker,但是今后可能还会有其他的容器被大家使用,主要原因是 K8s 和 Docker 的生态也存在着竞争关系。总的来说,如下图所示,kubelet 管理 Pod,Pod 管理容器。当用户创建一个容器的时候,实际上在创建 Pod。
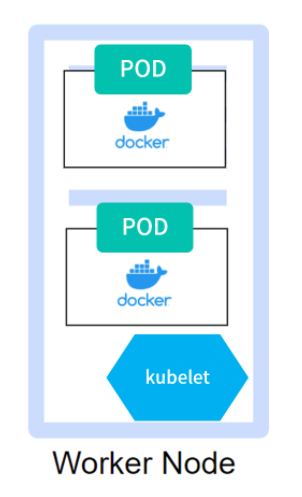
虽然 K8s 允许同样的应用程序(比如微服务),在一个节点上创建多个 Pod。但是为了保证可用性,通常我们会考虑将微服务分散到不同的节点中去。如下图所示,如果其中一个节点宕机了,微服务 A,微服务 B 还能正常工作。当然,有一些微服务。因为程序架构或者编程语言的原因,只能使用单进程。这个时候,我们也可能会在单一的节点上部署多个相同的服务,去利用更多的 CPU 资源。
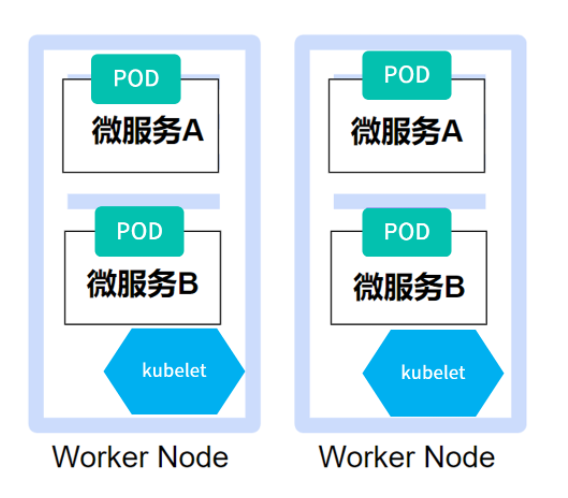
负载均衡
Pod 的 IP 地址是动态的,如果要将 Pod 作为内部或者外部的服务,那么就需要一个能拥有静态 IP 地址的节点,这种节点我们称为服务(Service),服务不是一个虚拟机节点,而是一个虚拟的概念——或者理解成一段程序、一个组件。请求先到达服务,然后再到达 Pod,服务在这之间还提供负载均衡。当有新的 Pod 加入或者旧的 Pod 被删除,服务可以捕捉到这些状态,这样就大大降低了分布式应用架构的复杂度。
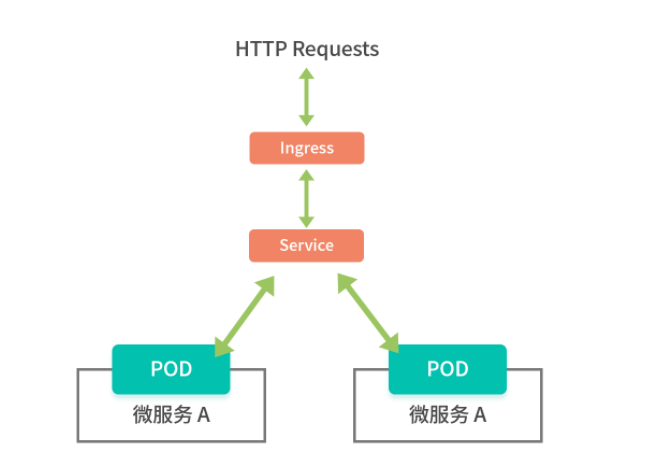
如上图所示,当我们要提供服务给外部使用时,对安全的考虑、对性能的考量是超过内部服务的。 K8s 解决方案:在服务的上方再提供薄薄的一层控制程序,为外部提供服务——这就是 Ingress。
以上,就是 K8s 的整体架构。 在使用的过程当中,相信你会感受到这个工具的魅力。比如说组件非常齐全,有数据加密、网络安全、单机调试、API 服务器等。如果你想了解更多的内容,可以查看这些资料。
Docker Swarm
Docker Swarm 是 Docker 团队基于 Docker 生态打造的容器编排引擎。下图是 Docker Swarm 整体架构图。
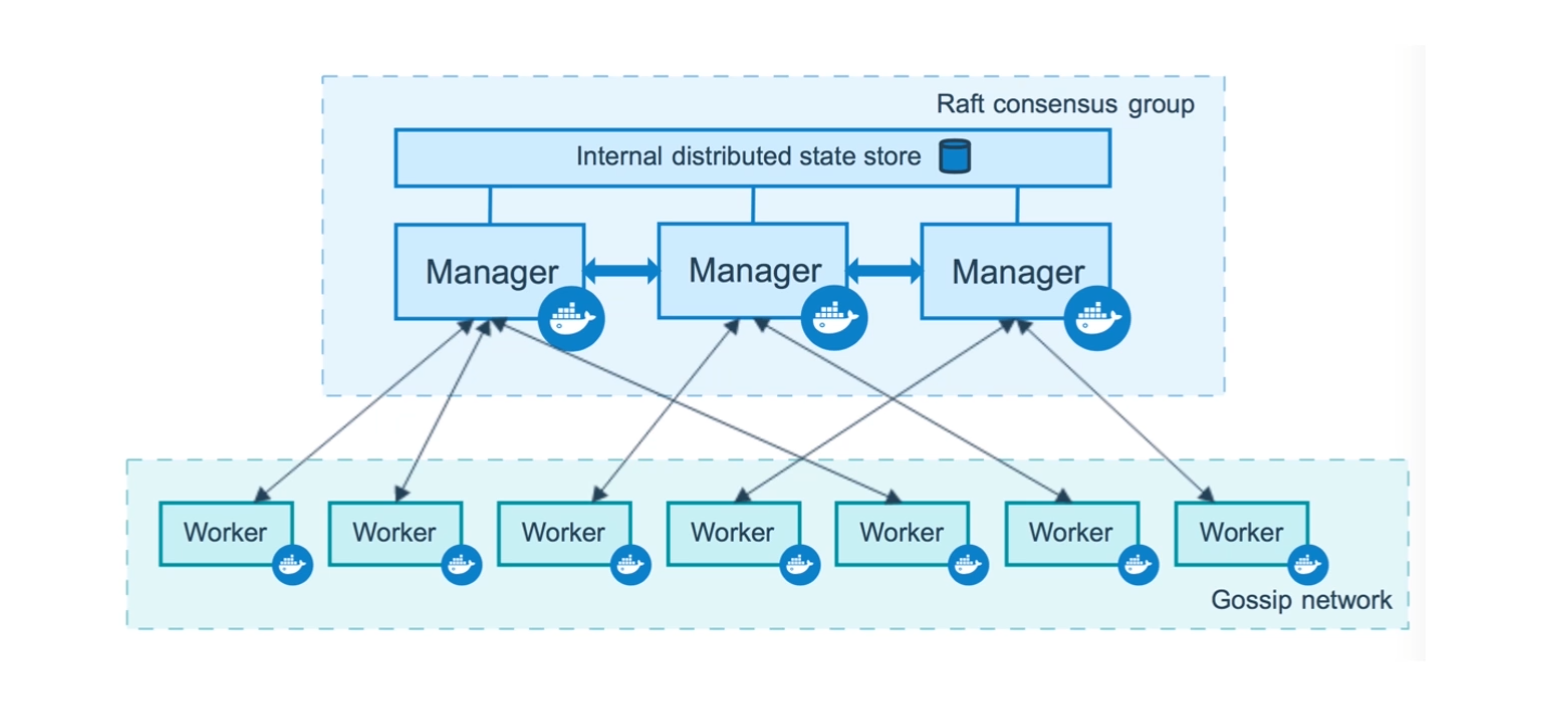
和 K8s 非常相似,节点被分成了 Manager 和 Worker。Manager 之间的状态数据通过 Raft 算法保证数据的一致性,Worker 内部是 Docker 容器。
和 K8s 的 Pod 类似,Docker Swarm 对容器进行了一层轻量级的封装——任务(Task),然后多个Task 通过服务进行负载均衡。
容器编排设计思考
这样的设计,用户只需要指定哪些容器开多少个副本,容器编排引擎自动就会在工作节点之中复制这些容器。而服务是容器的分组,多个容器共享一个服务。容器自动被创建,用户在维护的时候不需要维护到容器创建级别,只需要指定容器数目,并指定这类型的容器对应着哪个服务。至于之后,哪一个容器中的程序执行出错,编排引擎就会杀死这个出错的容器,并且重启一个新的容器。
在这样的设计当中,容器最好是无状态的,所以容器中最好不要用来运行 MySQL 这样的数据库。对于 MySQL 数据库,并不是多个实例都可以通过负载均衡来使用。有的实例只可以读,有的实例只可以写,中间还有 Binlog 同步。因此,虽然 K8s 提供了状态管理组件,但是使用起来可能不如虚拟机划算。
也是因为这种原因,我们现在倾向于进行无状态服务的开发。所有的状态都是存储在远程,应用本身并没有状态。当然,在开发测试环境,用容器来管理数据库是一个非常好的方案。这样可以帮助我们快速搭建、切换开发测试环境,并且可以做到一人一环境,互不影响,也可以做到开发环境、测试环境和线上环境统一。
如何利用 K8s 和 Docker Swarm 管理微服务?
这两个容器编排引擎都可以用来管理微服务。K8s 和 Docker Swarm 在使用微服务的时候有许多共性的步骤。
- 制作容器镜像:我们就是要先制作容器,如果使用 Docker 作为容器,那就要写 DockerFile,然后生成容器镜像。
- 上传镜像:制作好容器之后,我们往往会将容器上传到容器的托管平台。很多公司内部有自己的容器托管平台,这样下载容器的速度会非常快。
- 搭建集群:再接下来,我们要搭建一个 K8s 或者 Docker Swarm 的集群,将节点添加进去。
- 添加微服务 Pod/Task:然后我们要在集群中添加 Pod 的或者 Task,可以通过命令行工具,也可以通过书写配置文件。
- 设置服务:为 Pod/Task 设置服务,之后都通过服务来访问容器内的应用。
以上 5 个步骤是无论用哪个容器编排引擎都需要做的。具体使用过程当中,还有很多差异。比如,有的时候使用图形界面就可以完成上面的管理;不同的引擎配置文件,参数格式都会有差异。但是从整体架构到使用方式,它们都有着很大的相似性。因此你在学习容器编排引擎时,不应该着眼于学习某一个引擎,而是将它们看作一类知识,对比着学习。
Linux 架构优秀在哪里?
我们在面试的时候经常会和面试官聊架构,多数同学可能会认为架构是一个玄学问题,讨论的是“玄而又玄”的知识——如同道德经般的开头“玄之又玄、众妙之门”。其实架构领域也有通用的语言,有自己独有的词汇。虽然架构师经常为了系统架构争得面红耳赤,但是即使发生争吵,大家也会遵守架构思想准则。
这些优秀的架构思想和准则,很大一部分来自早期的黑客们对程序语言编译器实现的探索、对操作系统实现方案的探索,以及对计算机网络应用发展的思考,并且一直沿用至今。比如现在的面向对象编程、函数式编程、子系统的拆分和组织,以及分层架构设计,依然沿用了早期的架构思路。
其中有一部分非常重要的思想,被著名的计算机科学家、Unix 代码贡献者 Douglas McIlroy 誉为 Unix 哲学,也是 Linux 遵循的设计思想。今天我就和你一起讨论下,这部分前人留下的思想精华,希望可以帮助到你日后的架构工作。
组合性设计(Composability)
Unix 系设计的哲学,都在和单体设计(Monolithic Design)和中心化唱反调。作为社区产品,开发者来自全世界不同的地方,这就构成了一个巨大的开发团队,自然会反对中心化。
而一个巨大的开发团队的管理,一定不能是 Mono 的。举个例子,如果代码仓库是Mono的,这意味着所有的代码都存放在一个仓库里。如果要上线项目中的一个功能,那所有项目中的代码都要一起上线,只要一个小地方出了问题,就会影响到全局。在我们设计这个系统的时候,应该允许不同的程序模块通过不同的代码仓库发布。
再比如说,整体的系统架构应该是可以组合的。比如文件系统的设计,每个目录可以有不同的文件系统,我们可以随时替换文件系统、接入新的文件系统。比如接入一个网络的磁盘,或者接入一个内存文件系统。
与其所有的程序工具模块都由自己维护,不如将这项权利分发给需要的人,让更多的人参与进来。让更多的小团队去贡献代码,这样才可以把更多的工具体验做到极致。
这个思想在面向对象以及函数式编程的设计中,同样存在。比如在面向对象中,我们会尽量使用组合去替代继承。因为继承是一种 Mono 的设计,一旦发生继承关系,就意味着父类和子类之间的强耦合。而组合是一种更轻量级的复用。对于函数式编程,我们有 Monad 设计(单子),本质上是让事物(对象)和处理事物(计算)的函数之间可以进行组合,这样就可以最小粒度的复用函数。
同理,Unix 系操作系统用管道组合进程,也是在最小粒度的复用程序。
管道设计(Pipeline)
提到最小粒度的复用程序,就必然要提到管道(Pipeline)。Douglas McIlroy 在 Unix 的哲学中提到:一个应用的输出,应该是另一个应用的输入。这句话,其实道出了计算的本质。
计算其实就是将一个计算过程的输出给另一个计算过程作为输入。在构造流计算、管道运算、Monad 类型、泛型容器体系时——很大程度上,我们希望计算过程间拥有一定的相似性,比如泛型类型的统一。这样才可以把一个过程的输出给到另一个过程的输入。
重构和丢弃
在 Unix 设计当中有一个非常有趣的哲学。就是希望每个应用都只做一件事情,并且把这件事情做到极致。如果当一个应用变得过于复杂的时候,就去重构这个应用,或者重新写一个应用。而不是在原有的应用上增加功能。
上述逻辑和商业策略是否有相悖的地方?
关于这个问题,我觉得需要你自己进行思考,我不能给你答案,但欢迎把你的想法和答案写在留言区,我们一起交流。
设想一下,我们把微信的聊天工具、朋友圈、短视频、游戏都做成不同的应用,是不是会更好一些?
这是一个见仁见智的问题。但是目前来看,如果把短视频做成一个单独的应用,比如抖音,它在全球已经拥有 10 几亿的用户了;如果把游戏做成一个单独的应用,比如王者荣耀和 LoL,它们深受程序员们和广大上班族的喜爱。
还有,以我多年从事大型系统开发的经验来看,我宁愿重新做一些微服务,也不愿意去重构巨大的、复杂的系统。换句话说,我更乐意将新功能做到新系统里面,而不是在一个巨大的系统上不断地迭代和改进。这样不仅节省开发成本,还可以把事情做得更好。从这个角度看,我们进入微服务时代,是一个不可逆的过程。
另外多说一句,如果一定要在原有系统上增加功能,也应该多重构。重构和重写原有的系统有很多的好处,希望你不要有畏难情绪。优秀的团队,总是处在一个代码不断迭代的过程。一方面是因为业务在高速发展,旧代码往往承接不了新需求;另一方面,是因为程序员本身也在不断地追求更好的架构思路。
而重构旧代码,还经常可以看到业务逻辑中出问题的地方,看到潜在的隐患和风险,同时让程序员更加熟悉系统和业务逻辑。而且程序的复杂度,并不是随着需求量线性增长的。当需求量超过一定的临界值,复杂度增长会变快,类似一条指数曲线。因此,控制复杂度也是软件工程的一个核心问题。
写复杂的程序就是写错了
我们经常听到优秀的架构师说,程序写复杂了,就是写错了。在 Unix 哲学中,也提出过这样的说法:写一个程序的时候,先用几周时间去构造一个简单的版本,如果发现复杂了,就重写它。
确实实际情景也是如此。我们在写程序的时候,如果一开始没有用对工具、没有分对层、没有选对算法和数据结构、没有用对设计模式,那么写程序的时候,就很容易陷入大量的调试,还会出现很多 Bug。优秀的程序往往是思考的过程很长,调试的时间很短,能够迅速地在短时间内完成测试和上线。
所以当你发现一段代码,或者一段业务逻辑很消耗时间的时候,可能是你的思维方式出错了。想一想是不是少了必要的工具的封装,或者遗漏了什么中间环节。当然,也有可能是你的架构设计有问题,这就需要重新做架构了。
优先使用工具而不是“熟练”
关于优先使用工具这个哲学,我深有体会。
很多程序员在工作当中都忽略了去积累工具。比如说:
- 你经常要重新配置自己的开发环境,也不肯做一个 Docker 的镜像;
- 你经常要重新部署自己的测试环境,而且有时候还会出现使用者太多而不够用的情况。即使这样的情况屡屡发生,也不肯做一下容器化的管理;
- Git 的代码提交之后,不会触发自动化测试,需要人工去点鼠标,甚至需要由资深的测试手动去测。
很多程序员都认为自己对某项技术足够熟练了。因此,宁愿长年累月投入更多的时间,也不愿意主动跳脱出固化思维。宁愿不断使用某一项技术,而不愿意将重复劳动转化成工具。比如写一个小型的 ORM 框架、缓存引擎、业务容器……总之,养成良好的习惯,可以让开发效率越来越高。
在 Unix 哲学当中,有这样一条规则:有些人使用“熟练”而不是使用工具来减轻工作,即便是临时需要去构造一个工具,你也应该尽可能去尝试实现。
我们现在每天都用的 Git 版本控制工具,就是基于这样的哲学被构建出来的。当时刚好是 Linux 内核研发团队的商业代码管理工具到期了,Linux 的缔造者们基于这个经验教训,就自主研发了 Git 这款工具,不仅顺利地推进了后续的研发工作,还做成了一个巨大的程序员交友生态。
再给你讲一个我身边的故事:我刚刚工作的时候,我的老板自己写了一个小程序,去判断 HR 发过来简历是否符合他的用人条件。所以他每天可以看完几百份简历,并筛选出面试人选。而那些没有利用工具的技术 Leader,每天都在埋怨简历太多看不过来。
这些故事告诉我们,作为程序员,不仅仅需要完成工作,还要重视中间过程的工具缔造。
其他优秀的原则
我在学习 Unix 哲学的过程中,还看到很多有趣的规则,这里我摘选了一些和你分享。
比如:不要试图猜测程序可能的瓶颈在哪里,而是试图证明这个瓶颈,因为瓶颈会出现在出乎意料的地方。这句话告诉我们,要多写性能测试程序并且构造压力测试的场景。只有这样,才能让你的程序更健壮,承载更大的压力。
再比如:花哨的算法在业务规模小的时候通常运行得很慢,因此业务规模小的时候不要用花哨的算法。简单的算法,往往性能更高。如果你的业务规模很大,可以尝试去测试并证明需要用怎样的算法。
这也是我们在架构程序的时候经常会出错的地方。我们习惯性地选择用脑海中记忆的时间复杂度最低的算法,但是却忽略了时间复杂度只是一种增长关系,一个算法在某个场景中到底可不可行,是要以实际执行时收集数据为准的。
再比如:数据主导规则。当你的数据结构设计得足够好,那么你的计算方法就会深刻地反映出你系统的逻辑。这也叫作自证明代码。编程的核心是构造好的数据结构,而不是算法。
尽管我们在学习的时候,算法和数据结构是一起学的。但是在大牛们看来,数据结构的抽象可以深刻反映系统的本质。比如抽象出文件描述符反应文件、抽象出页表反应内存、抽象出 Socket 反应连接——这些数据结构才是设计系统最核心的东西。
最后,再和你分享一句 Unix 的设计者Ken Thompson 的经典语录:搞不定就用蛮力。这是打破所有规则的规则。在我们开发的过程当中,首先要把事情搞定!只有把事情搞定,才有我们上面谈到的这一大堆哲学产生价值的可能性。事情没有搞定,一切都尘归尘土归土,毫无意义。
今天所讲的这些哲学,可以作为你平时和架构师们沟通的语言。架构有自己领域的语言,比如设计模式、编程范式、数据结构,等等。还有许多像 Unix 哲学这样——经过历史积淀,充满着人文气息的行业标准和规范。
如果你想仔细看看当时 Unix 的设计者都总结了哪些哲学,可以阅读这篇文档。
商业操作系统:电商操作系统是不是一个噱头?
关于电商操作系统是不是一个噱头?我觉得对于想要哄抬股价、营造风口的资本来说,这无疑是一场盛宴。但是对于从事多年业务架构,为了这件事情努力的架构师们而言,这似乎不是一个遥远的梦想,而是可以通过手中的键盘、白板上的图纸去付诸实践的目标。
我们暂且不为这个问题是不是噱头定性,不如先来聊一聊什么是商业操作系统,聊一聊它的设计思路和基本理念。
进程的抽象
你可以把一个大型的电商公司想象成一个商业操作系统,它的目标是为其中的每个参与者分配资源。这些资源不仅仅是计算资源,还会有市场资源、渠道资源、公关资源、用户资源,等等。
这样操作系统上的进程也被分成了几种类别,比如说内核程序,其实就是电商公司。应用程序就包括商家、供应商、品牌方、第三方支付、大数据分析公司等一系列组织的策略。
接下来,我们以商家为例讨论进程。在操作系统中进程是应用程序的执行副本。它不仅仅是在内核的进程表中留下一条记录,它更像拥有独立思考能力的人,它需要什么资源就会自己去操作系统申请。它会遵循操作系统的规则,为自己的用户服务,完成自己的商业目的。
所以如果上升到操作系统的高度来设计电商系统。我们不仅要考虑如何在数据库表中记录这个商家、如何实现跟这个商家相关的业务逻辑,还要让商家的行为是定制化的,可以自发地组织营业。同时,也要服从平台制定的规则,共同维护商业秩序,比如定价策略、物流标准、服务水平,等等。
你可能会说,要达到这点其实很容易。实现一个开放平台,将所有的平台能力做成 API。让商家可以自己开发程序,去调用这些 API 来完成自己的服务。商家可以利用这些接口自定义自己的办公自动化软件。
事实上很多电商公司也确实是这样去做的,但我认为这样做没有抓住问题的核心。一方面是系统的开发、对接成本会难住很多中小型商家。但最重要的并不是研发成本,而是开放的 API 平台通常只能提供基础能力——比如说订单查询、商品创建、活动创建,等等。这些能力是电商平台已有能力的一种投影,超不过商家本身能在后台中配置和使用的范畴,基于这样的 API 架构出来的应用程序,可以节省商家的时间,但是不能称为进程。因为独立性不够,且不够智能。
所以真正的发展方向和目标是商业的智能化。这里有一个在游戏领域常见的设计模式,可以实现智能化,叫作代理人(Agent)模式。就是为每一个商家提供一个或者多个代理(Agent)程序。这些代理人像机器人一样,会帮助商家运营自己的网店、客服、物流体系,等等。
代理人知道什么时候应该做什么,比如说:
- 帮商家预约物流、为新老用户提供不同的服务;
- 通过分析数据决定是否需要花钱做活动;
- 当品牌方有活动的时候,帮助商家联系;
- 当线上商店经营出现问题的时候,主动帮商家分析;
- ……
你可以把代理人理解成一个游戏的 AI,它们会根据一些配置选项自发地完成任务。而代理人的提供者,也就是程序员,只需要证明在某些方面,代理人比人更优秀即可。而在这些优秀的方面,就可以交给代理人处理。
这样,商家放弃了一部分的管理权限,也减轻了很大的负担,成了代理人决策中的某个节点——比如有时候需要邮件确认一些内容、有时候需要支付运营费用、有时候会遵循代理人的建议对商店进行装修等。
资源和权限
对于一个计算机上的操作系统而言,我们对进程使用了什么样的资源并不是非常的敏感。而对于一个商业操作系统来说,我们就需要设计严格的权限控制。因为权限从某种意义上就代表着收入,代表着金钱。
资源是一个宽泛的概念。广告位是资源,可以带来直接的流量。基于用户的历史行为,每个用户看到的广告位是不同的,这个也叫作“千人千面”,所以一个广告位可以卖给很多个代理人。站内信、用户召回的权限也可以看作资源。 有权利建立自己的会员体系,可以看作资源。数据分析的权限可以看作资源。如果将商业系统看作一个操作系统,资源就是所有在这个系统中流通的有价值的东西。
有同学可能会认为,一切资源都可以用数据描述,那么权限控制也应该会比较简单。比如说某一个推广位到底给哪个商家、到底推广多长时间……
其实并不是这样,虽然有很多权限可以用数据描述但是并不好控制。比如一个商品,“商家最低可以设置多少价格”就是一件非常不好判断的事情。商品有标品也有非标品,标品的价格好控制,非标品的价格缺少参照。如果平台方不希望花费太多精力在价格治理上,就要想办法让这些不守规则的商家无法盈利。比如说一旦发现恶性价格竞争,或者虚报价格骗钱的情况,需要及时给予商家打击和处罚。
和权限对应的就是资源。如果让商家以代理人的身份在操作系统中运行,那么这个代理人可以使用多少资源,就需要有一个访问权限控制列表(Access Control List,,ACL)。这里有一个核心的问题,在传统的 ACL 设计中,是基于权限的管控,而不是权限、内容的发现。而对于设计得优秀的代理人 (Agent),应该是订阅所有的可能性,知道如何获取、申请所有的权限,然后不断思考怎样做更好。对代理人而言,这不是一个权限申请的问题,而是一个最优化策略——思考如何盈利。
策略
商家、组织在操作系统上化身成为代理人,也就是进程。商业操作系统的调度不仅仅体现在给这些代理人足够的计算、存储资源,更重要的是为这些代理人的决策提供上下文以及资源。
就好像真实的人一样:听到、看到、触摸到,然后做决策。做决策需要策略,一个好的策略可能是赚钱的,而一个坏的策略可能是灾难性的。从人做决策到机器做决策,有一个中间的过程。一开始的目标可以设立在让机器做少量的决策,比如说,机器通过观察近期来到商店用户的行为,决定哪些商品出现在店铺的首页上。但是在做这个决策之前,机器需要先咨询人的意愿。这样就把人当成了决策节点,机器变成了工具人。这样做一方面为人节省了时间,一方面也避免了错误。
再比如说机器可以通过数据预估一个广告位的收益,通过用户集群的画像得知在某个广告位投放店铺广告是否划算。如果机器得到一个正向的结果,可能会通知商家来完成付费和签约。那么问题来了,商家是否可以放心将付费和签约都交给机器呢?
当然不可以。如果家里急着用钱,可能就无法完成这笔看上去是划算的交易。另外,如果有其他的商家也看上了这个广告位。可能就需要竞价排名,所以需要人和机器的混合决策。
上述的模式会长期存在,例如设置价格是一个复杂的模型——疫情来了,口罩的销量会上升。机器可以理解这个口罩销量上升的过程,但是机器很难在疫情刚刚开始、口罩销量还没有上升的时候就预判到这个趋势。如果逻辑是确定的,那机器可以帮人做到极致,但如果逻辑不确定呢?如果很多判断是预判,是基于复杂的现实世界产生的思考,那么这就不是机器擅长的领域了。
所以智能的目标并不是替代人,而是让人更像人、机器更像机器。
另外再和你聊一下我自己的观点,以自动驾驶为例。如果一个完全自动驾驶的汽车发生车祸,那么应该由汽车制造商、算法的提供方、自动驾驶设备的提供方、保险公司来共同来承担责任。类比下,如果策略可以售卖,那么提供策略的人就要承担相应的责任。比如说策略出现故障,导致营销券被大量套现,那提供策略方就需要承担相应的赔偿。
在可预见到的未来,策略也会成为一种可交易的资源。维护一个网上商店,从原材料到生产加工、渠道、物流体系、获客、销售环节,再到售后——以目前的技术水平,可以实现到一种半人工参与的状态。但这样也产生了很多非常现实的问题,比如说,既然开店变得如此容易,那资本为什么不自己开店。这样去培养合格、服务态度更好的店员不是更加容易吗?
这也是互联网让人深深担忧的原因之一。所有的东西被自动化之后,代表着一种时代的变迁,剩下不能够自动化的,都变成了“节点”。很多过程不需要人参与之后,人就变成了在某些机器无法完成工作的节点上不断重复劳动的工具——这也是近年来小朋友们经常说自己是“工具人”的原因了。
而且,我们程序员是在推动这样的潮流。因此你可以想象,未来对程序员的需求是很大的。一个普通的商店可能会雇佣一名程序员,花上半年匠心打造某个策略,收费标准可能会像现在的住房装修一样贵。这个策略成功之后还会进行微调,这就是后期的服务费用。完全做到配置化的策略,会因为不够差异化,无法永久盈利。最终在商业市场上竞争的,会是大量将人作为决策节点的 AI。
总结
商业是人类繁荣后的产物,电商是信息时代商业早期形式,未来的发展方向一定是像一个操作系统那样,让每个实体,都可以有自己的策略。用户可以写策略订餐,比如说我每天中午让 AI 帮助我挑选、并订一份午餐。商家写策略运营,比如运营网店。
至于商业操作系统到底是不是一个噱头?我觉得这是商业的发展方向。操作系统上的进程应该是策略,或者说是机器人。这样的未来也让我深深的焦虑过:它可能让人失去工作,让连接变得扁平,焦虑散播在加速——这些问题都需要解决,而解决需要时间、需要探索。
如果你有更多的想法可以把你的想法和方案写到留言区,和我一起交流。
这一讲就到这里,发现求知的乐趣,我是林䭽。感谢你学习本次课程,下一讲我们将学习本专栏的最后一节内容,加餐 | 练习题详解(八)。 再见!
自己尝试用 Docker 执行一个自己方向的 Web 程序:比如 Spring/Django/Express 等?
【解析】关于如何安装 Docker,你可以参考这篇文档。然后这里还有一个不错的 SpringBoot+MySQL+Redis 例子,你可以参考这篇内容。
其他方向可以参考上面例子中的 Compose.yml 去定义自己的环境。 一般开发环境喜欢把所有工具链用 Compose 放到一起,上线的环境数据库一般不会用 Docker 容器。 Docker-Compose 是一个专门用来定义多容器任务的工具,你可以在这里得到。
国内镜像可以用 Aliyun 的,具体你可以参考这篇文档。
(注:需要一个账号并且登录)
为什么会有多个容器共用一个 Pod 的需求?
【解析】Pod 内部的容器共用一个网络空间,可以通过 localhost 进行通信。另外多个容器,还可以共享一个存储空间。
比如一个 Web 服务容器,可以将日志、监控数据不断写入共享的磁盘空间,然后由日志服务、监控服务处理将日志上传。
再比如说一些跨语言的场景,比如一个 Java 服务接收到了视频文件传给一 个 OpenCV 容器进行处理。
以上这种设计模式,我们称为边车模式(Sidecar),边车模式将数个容器放入一个分组内(例如 K8s 的 Pod),让它们可以分配到相同的节点上。这样它们彼此间可以共用磁盘、网络等。
在边车模式中,有一类容器,被称为Ambassador Container,翻译过来是使节容器。对于一个主容器(Main Container)上的服务,可以通过 Ambassador Container 来连接外部服务。如下图所示:
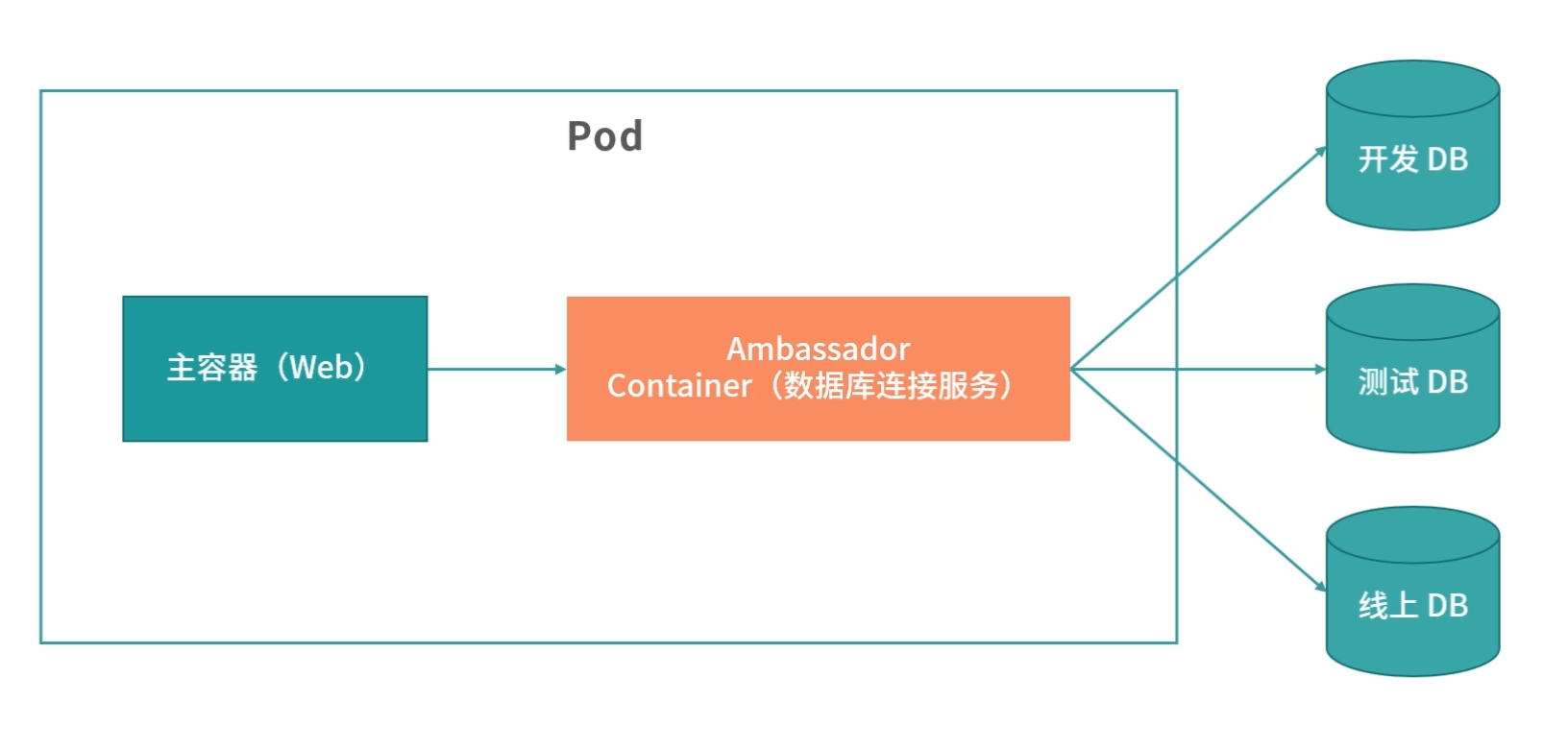
我们在开发的时候经常会配置不同的环境。如果每个 Web 应用都要实现一套环境探测程序,比如判断是开发、测试还是线上环境,从而连接不同的 MySQL、Redis 等服务,那么每个项目都需要引入一个公用的库,或者实现一套逻辑。这样我们可以使用一个边车容器,专门提供数据库连接的服务。让连接服务可以自动探测环境,并且从远程读取全局配置,这样每个项目的开发者不需要再关心数据库有多少套环境、如何配置了。
计算机网络相关
知识结构
模块一:互联网和传输层协议
介绍互联网的体系和整体框架,参与的硬件设备,以及它们的作用。还会介绍传输层协议 TCP 和 UDP,重点讨论它们的工作原理、算法和优化策略。这部分知识是计算机网络的基础,也最能体现网络设计的精髓。
模块二:网络层协议
围绕局域网和 IP 协议展开,包括 ARP、IPv4、IPv6、NAT 等基本概念,探讨 IPv6 的工作原理,以及 IPv6 和 IPv4 的兼容策略。IP 协议几乎是网络层的唯一协议,是大厂面试最为热门的内容之一。模块一和模块二属于基础篇,是计算机网络最底层的基础知识。
模块三:网络编程
围绕 Socket 讨论网络编程,介绍各种网络 I/O 模型和编程方式的优缺点,并以 RPC 框架设计为题去落地学到的这些知识和实现。讨论在不同的并发量、针对不同服务特性选择不同的 I/O 模型,调整 TCP 关联的参数,等等,进而帮助你学习如何优化自己系统的网络。这部分内容会为企业带来实际价值,因此面试官会重点提问。
模块四:Web 技术
讨论平时使用最多且最重要的应用层协议——HTTP 协议(包括 HTTP 2.0),并扩大讨论范围到 Web 技术生态,比如从 DNS 看缓存、从 CDN 看负载均衡、从 HTTP 协议看开发规范、从流媒体技术看协议选择,以及从爬虫技术看网络安全。
模块五:网络安全
讨论网络安全技术,一部分是基础设施,比如证书、加解密、公私钥体系、信任链等;另一部分是具体的攻击手段,比如 DDoS、XSS、SQL 注入、ARP 攻击、中间人攻击等,以及它们的防御手段。安全是所有互联网公司的高压线,学完这块内容能够帮助你屏蔽掉一些高危操作,在工作中避免出现安全问题。
构成应用程序的 7 种基本元素
什么是蜂窝移动网络?
网络的组成
我们习惯称今天的时代为云时代,整个世界可以看作一张巨大的、立体的网。在这个时代里产生的各种服务,就好像水和电一样,打开即用。透过这张巨大的网去观察,里面还会有一个个小型的网络。你可以想象,用无数个节点构成一个个小型网络,再用小型网络组成中型网络,再组成大型网络,以此类推,最后组成完整的一个如星河般的世界。
公司内网
如果你仔细分析一个小型网络,比如一个公司网络,就会得到下图 1 所示的结构:
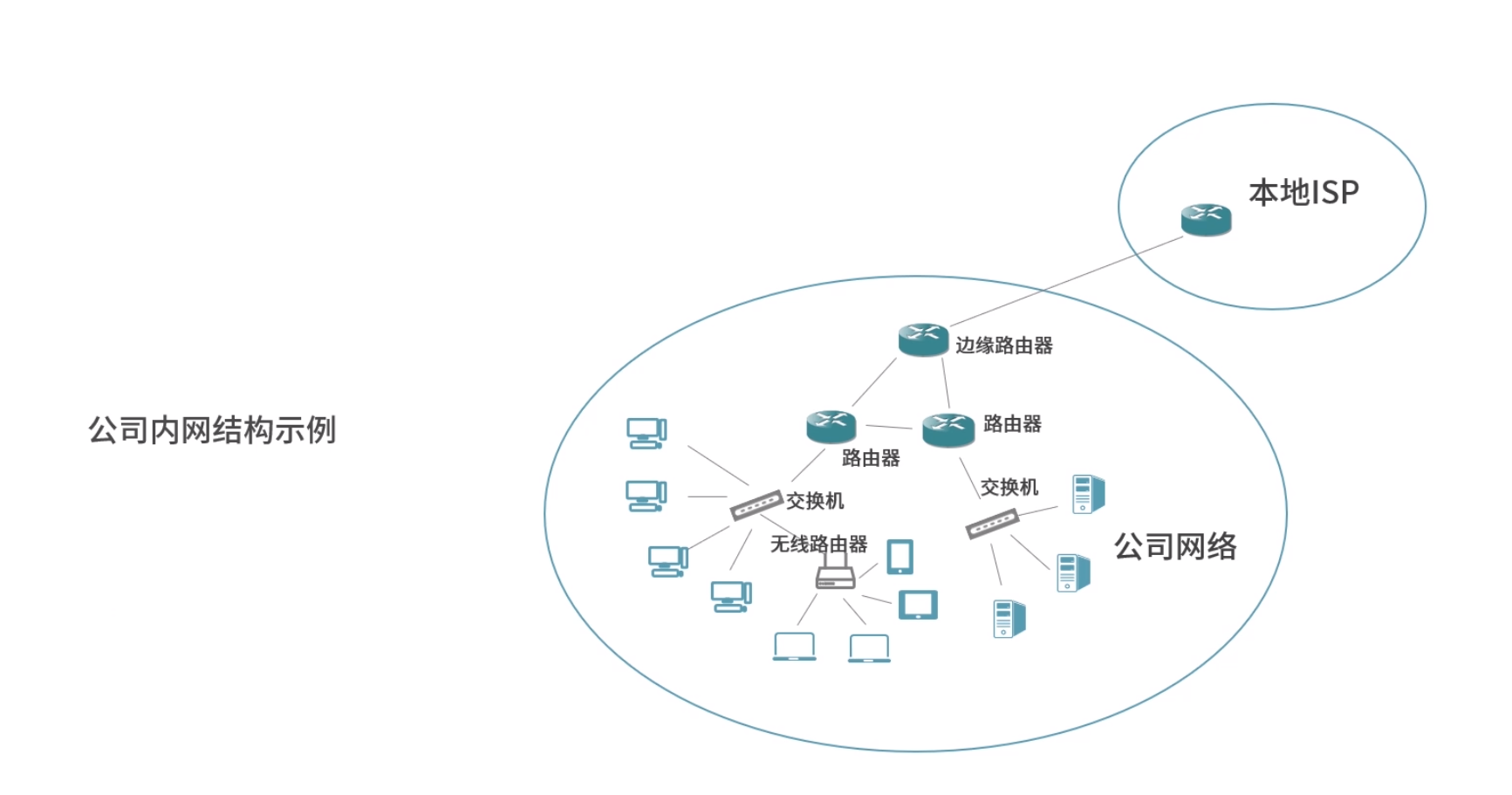
公司网络从本地网络服务提供商 (Internet Service Provider) 接入,然后内部再分成一个个子网。上图 1 中,你看到的线路,也被称作通信链路(Communication Link),用于传输网络信号。你可以观察到,有的网络节点,同时接入了 2 条以上的链路,这个时候因为路径发生了分叉,数据传输到这些节点需要选择方向,因此我们在这些节点需要进行交换(Switch)。
数据发生交换的时候,会先从一条链路进入交换设备,然后缓存下来,再转发(切换)到另一条路径,如下图 2 所示:
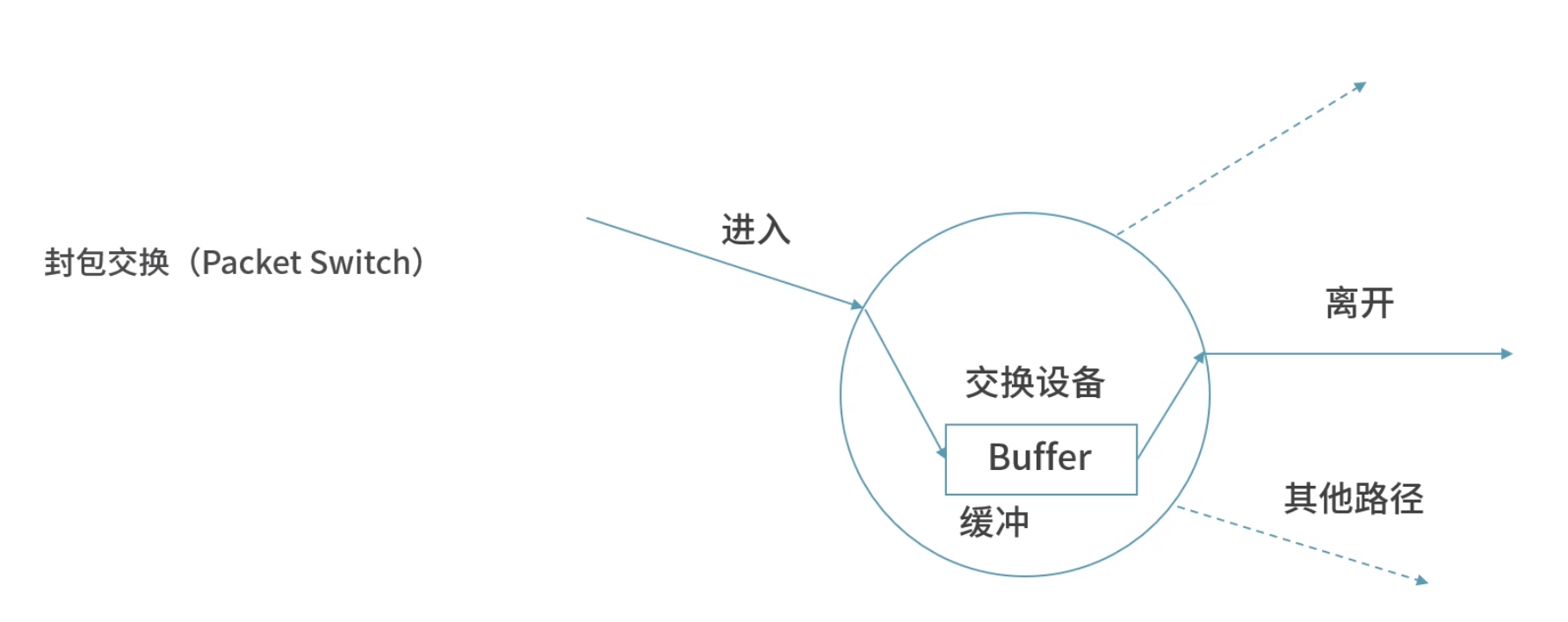
交换技术的本质,就是让数据切换路径。因为,网络中的数据是以分组或封包(Packet)的形式传输,因此这个技术也称作封包交换技术(Packet Switch)。
比如说,你要传递一首 2Mb 的 MP3 的歌曲,歌曲本身不是一次传输完成的,而是被拆分成很多个封包。每个封包只有歌曲中的一部分数据,而封包一旦遇到岔路口,就需要封包交换技术帮助每个封包选择最合理的路径。
在网络中,常见的具有交换能力的设备是路由器(Router)和链路层交换机(Link-Layer Switch)。通常情况下,两个网络可以通过路由器进行连接,多台设备可以通过交换机进行连接。但是路由器通常也具有交换机的功能。
在上图 1 中,公司内部网络也被分成了多级子网。每个路由器、交换机构成一级子网。最高级的路由器在公司网络的边缘,它可以将网络内部节点连接到其他的网络(网络外部)。本地网络提供商(ISP)提供的互联网先到达边缘的路由器,然后再渗透到内部的网络节点。公司内部的若干服务器可以通过交换机形成一个局域网络;公司内部的办公设备,比如电脑和笔记本,也可以通过无线路由器或者交换机形成局域网络。局域网络之间,可以通过路由器、交换机进行连接,从而构成一个更大的局域网。
移动网络
前面我们提到,网络传输需要通信链路(Communication Link),而通信链路是一个抽象概念。这里说的抽象,就是面向对象中抽象类和继承类的关系,比如同轴电缆是通信链路,无线信号的发送接收器可以构成通信链路,蓝牙信道也可以构成通信链路。
在移动网络中,无线信号构成了通信链路。在移动网络的设计中,通信的核心被称作蜂窝塔(Cellular Tower),有时候也称作基站(BaseStation)。之所以有这样的名称,是因为每个蜂窝塔只覆盖一个六边形的范围,如果要覆盖一个很大的区域就需要很多的蜂窝塔(六边形)排列在一起,像极了蜜蜂的巢穴。这种六边形的结构,可以让信号无死角地覆盖。想象一下,如果是圆形结构,那么圆和圆之间就会有间隙,造成一部分无法覆盖的信号死角,而六边形就完美地解决了这个问题。
对于构成移动网络最小的网络结构——蜂窝网络来说,构造大体如图
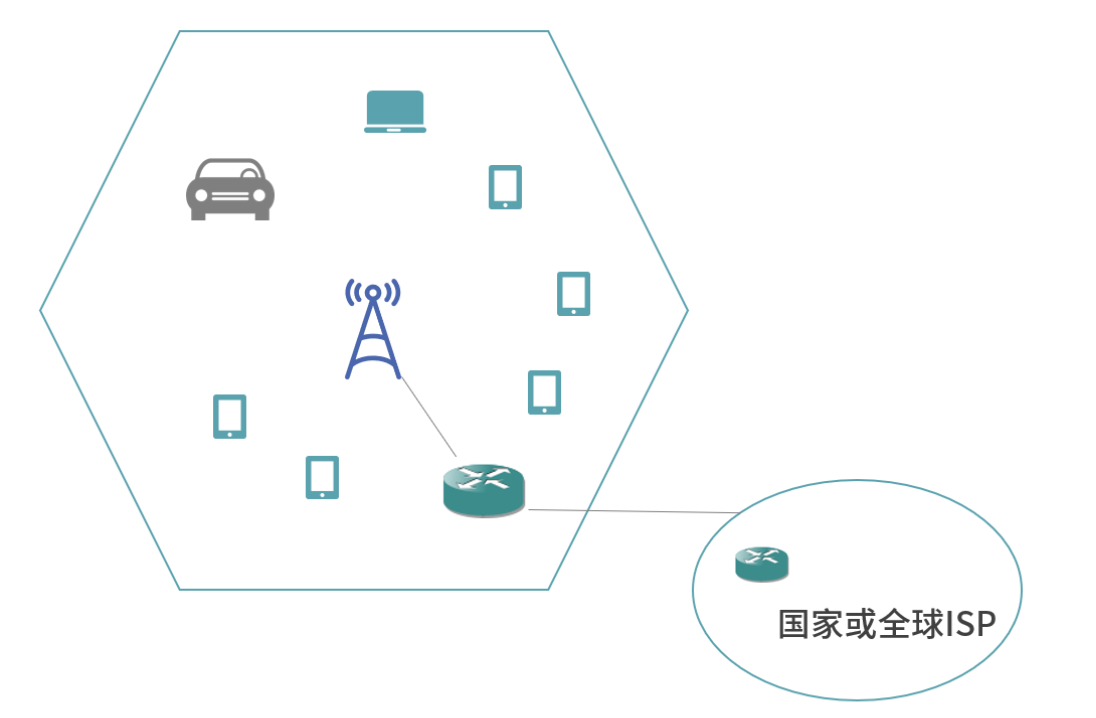
图 4 中,国家或全球网络提供商将网络供给处于蜂窝网络边缘的路由器,路由器连接蜂窝塔,再通过蜂窝塔(基站)提供给处于六边形地区中的设备。通常是国家级别的网络服务提供商负责部署基站,比如中国电信、中国联通。将网络提供给一个子网的行为,通常称为网络提供(Network Provider),反过来,对一个子网连接提供商的网络,称为网络接入(Network Access)。
随着移动网络的发展,一个蜂窝网格中的设备越来越多,也出现了基站覆盖有重叠关系的网格,如下
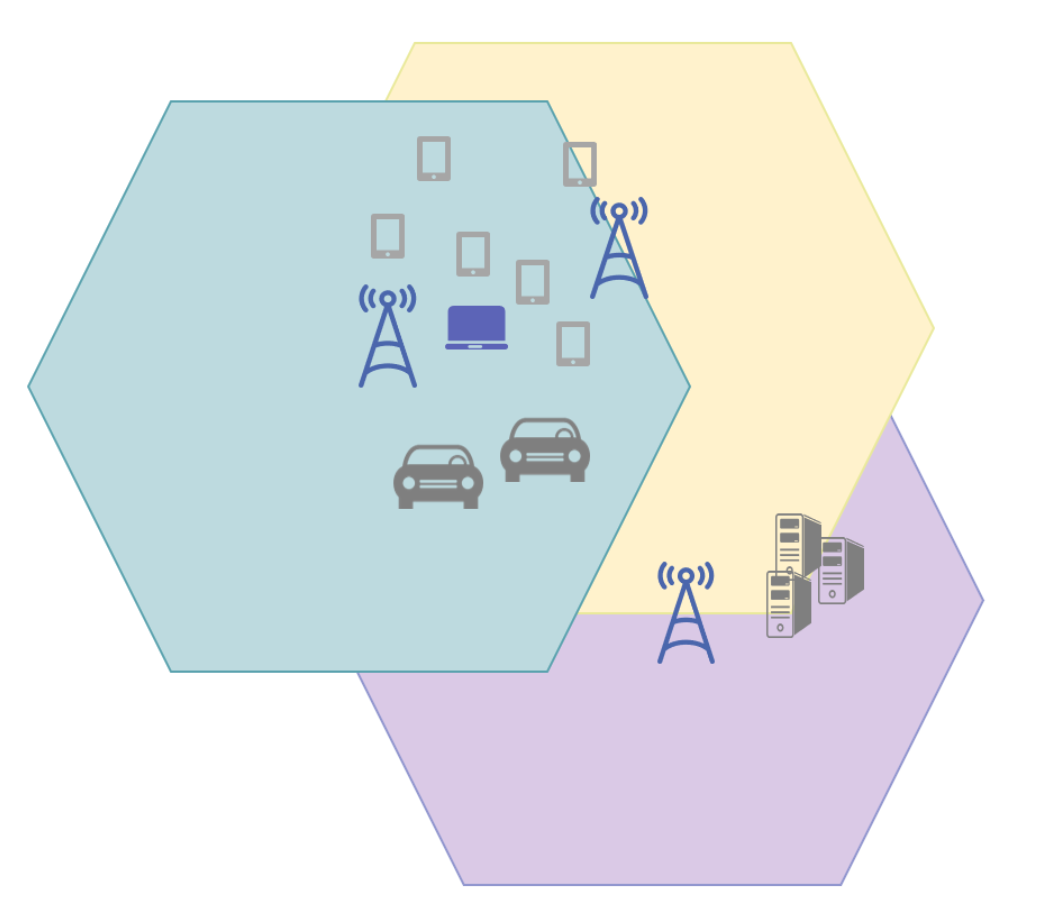
这样设计的好处是,当一个基站过载、出现故障,或者用户设备周边信号出现不稳定,就可以切换到另一个基站的网络,不影响用户继续使用网络服务。
另一方面,在一定范围内的区域,离用户较近的地方还可以部署服务器,帮助用户完成计算。这相当于计算资源的下沉,称为边缘计算。相比中心化的计算,边缘计算延迟低、链路短,能够将更好的体验带给距离边缘计算集群最近的节点。从而让用户享受到更优质、延迟更低、算力更强的服务。
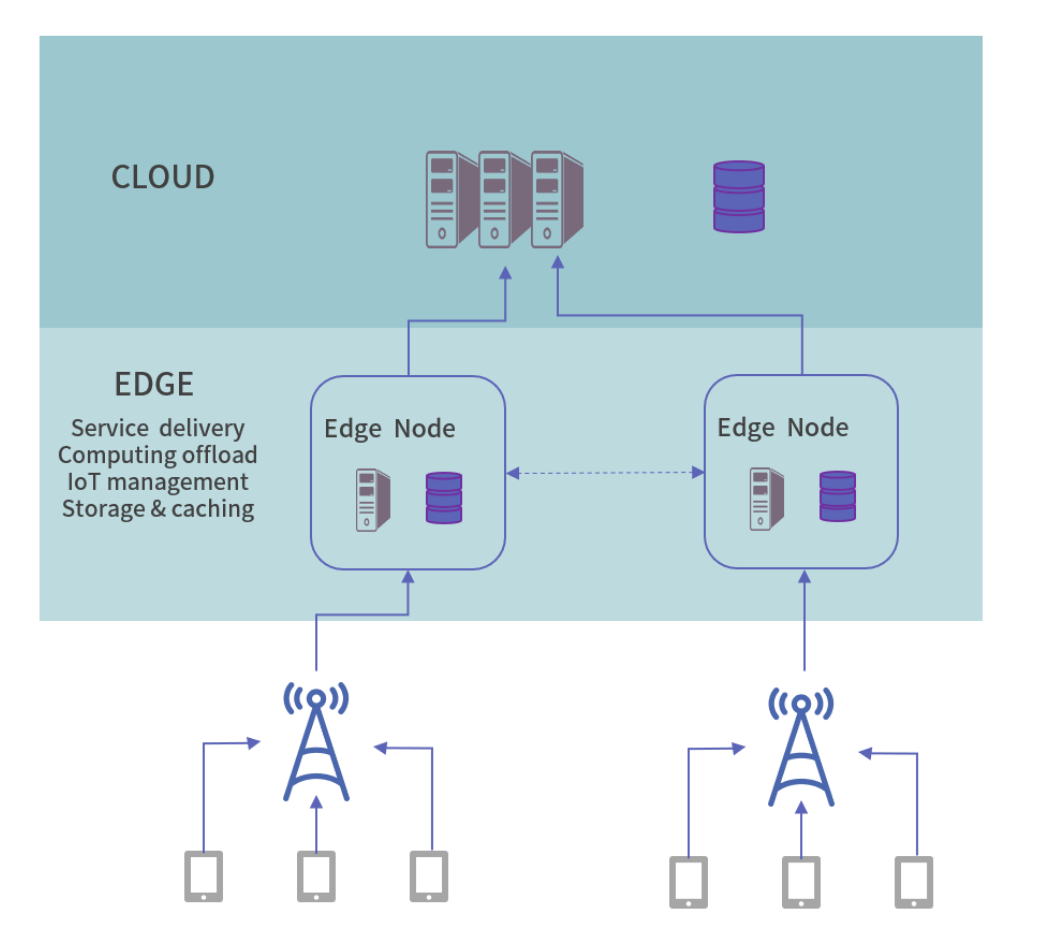
家用网络
还有一个值得讨论的是家用网络。近些年,家用联网设备越来越多。比如说冰箱、空调、扫地机器人、灯光、电动窗帘……
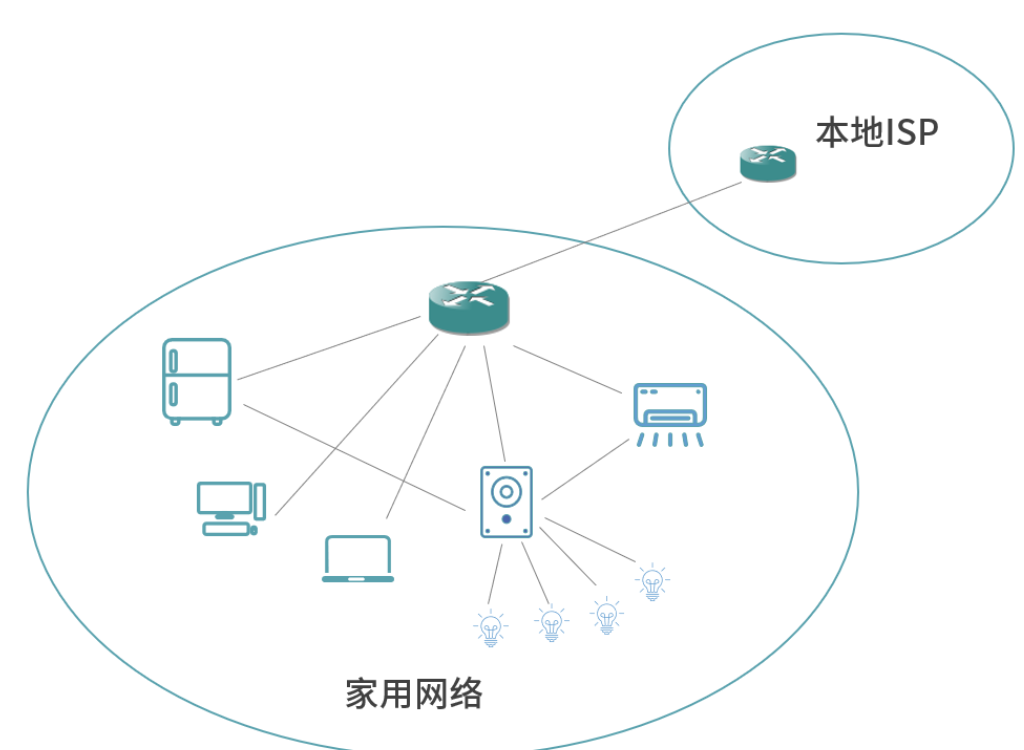
家用网络现在已经发展成一种网格状的连接。一方面家用网络会通过路由器接入本地 ISP 提供的网络服务。另一方面,一些设备,比如电脑、笔记本、手机、冰箱等都可以直接和路由器连接。路由器也承担了链路层网关的作用,作为家用电器之间信息的交换设备。
还有一些家用设备,比如说 10 多块钱的灯泡,不太适合内部再嵌入一个几十块钱可以接收 WI-FI 的芯片,这个时候就可以考虑用蓝牙控制电灯。路由器提供蓝牙不现实,因此一些家用电器也承担了蓝牙设备的控制器——比如说智能音箱。上图 7 中的智能音箱把家用网络带向了一个网格状,有的设备会同时连接路由器(WI-FI)和智能音箱,这样手机和音箱都可以直接控制这些设备。这样的设计,即便网络断开,仍然可以控制这些家用设备。
最顶部的全球或国家大型的 ISP 之间联网,构成了网络的主干。然后区域性的 ISP 承接主干网络,在这个基础之上再向家庭和公司提供接入服务。移动蜂窝网络因为部署复杂,往往也是由大型 ISP 直接提供。
数据的传输
上述的网络结构中,由庞大数目的个人、公司、组织、基站,形成一个个网络。在这些网络中,传递数据不是一件容易的事情。
为了传递数据,在网络中有几个特别重要的抽象。最终提供服务或者享受服务的设备,称为终端(Terminal),或者端系统(End System),有时候简单称为主机(Host)。比如说:电脑、手机、冰箱、汽车等,我们都可以看作是一个主机(Host)。
然后,我们可以把网络传输分成两类,一类是端到端(Host-to-Host)的能力,由 TCP/IP 协议群提供。还有一类是广播的能力,是一对多、多对多的能力,可以看作是端到端(Host-to-Host)能力的延伸。
你可以思考一下,一个北京的主机(Host)向一个深圳的主机(Host)发送消息。那么,中间会穿越大量的网络节点,这些节点可以是路由器、交换机、基站等。在发送消息的过程中,可能跨越很多网络、通过很多边缘,也可能会通过不同的网络提供商提供的网络……而且,传输过程中,可能会使用不同材质的通信链路(Communication Link),比如同轴电缆、双绞线、光纤,或者通过无线传输的 WI-FI、卫星等。
网络基础设施往往不能一次性传输太大的数据量,因此通常会将数据分片传输。比如传输一个 MP3,我们会将 MP3 内容切分成很多个组,每个组也称作一个封包,英文都是 Packet。这样,如果一个封包损坏,只需要重发损坏的封包,而不需要重发所有数据。你可以类比下中文的活字印刷技术。
另一方面,网络中两点间的路径非常多,如果一条路径阻塞了,部分封包可以考虑走其他路径。发送端将数据拆分成封包(Packet),封包在网络中遇到岔路,由交换器和路由器节点决定走向,图 9 中是对封包交换技术的一个演示。
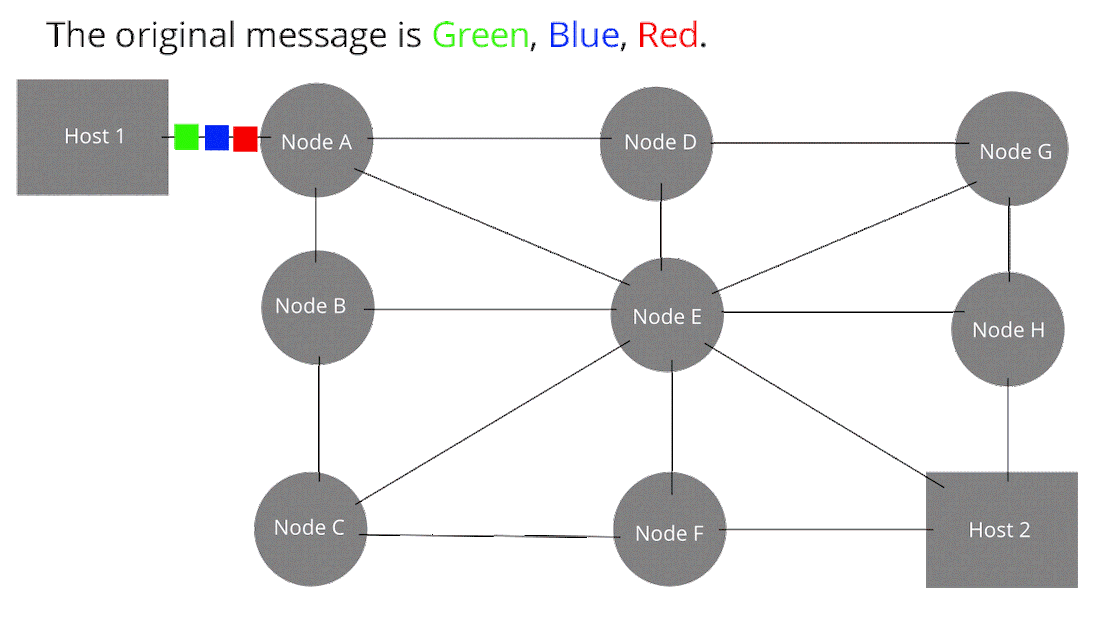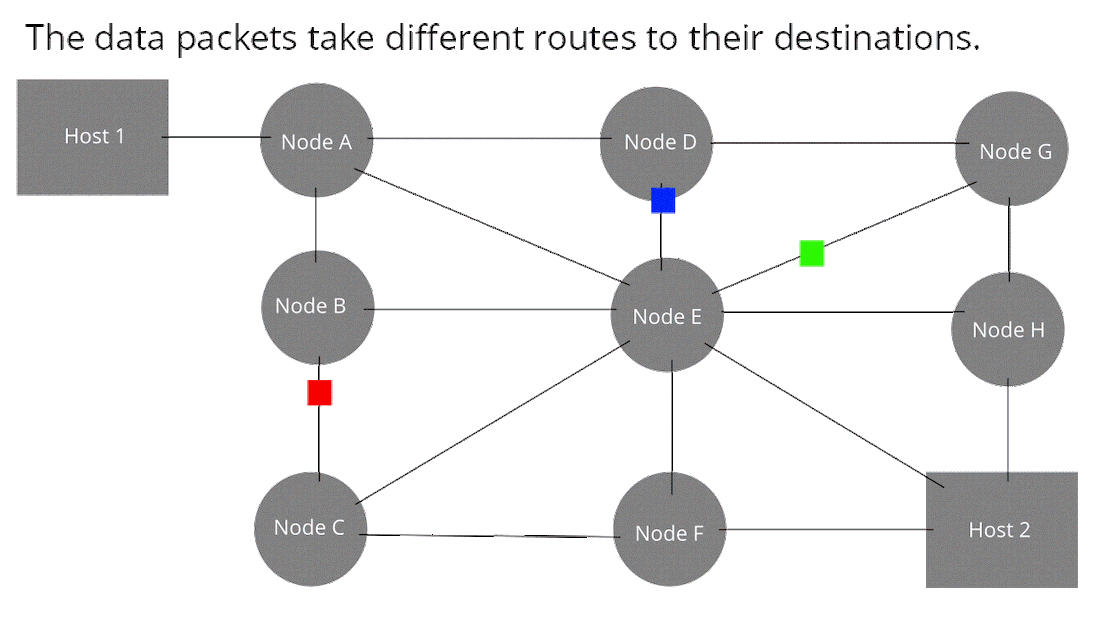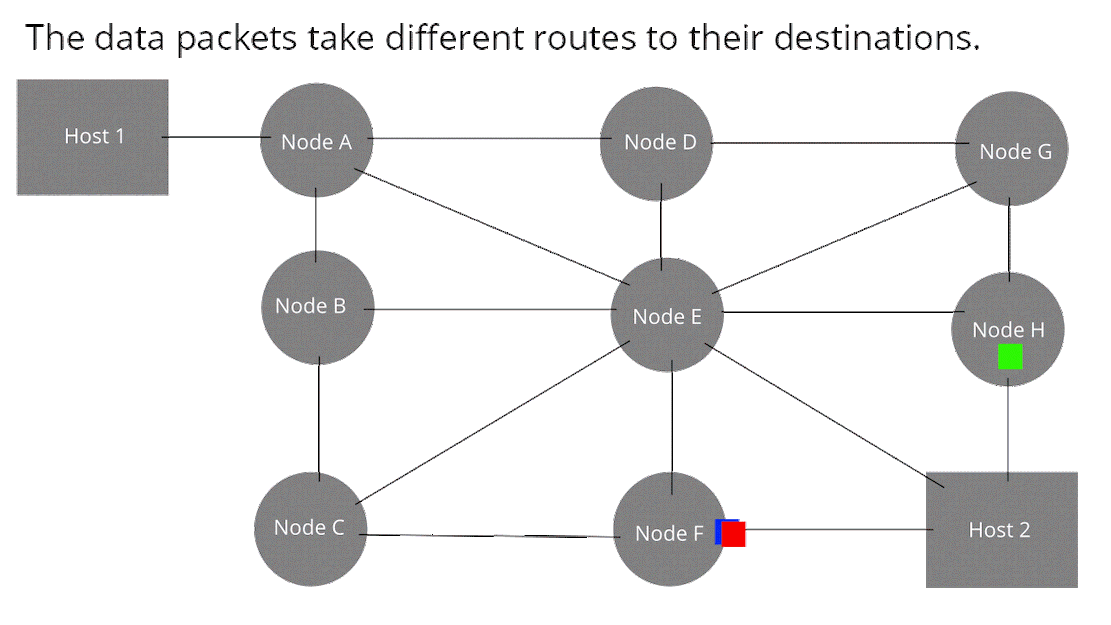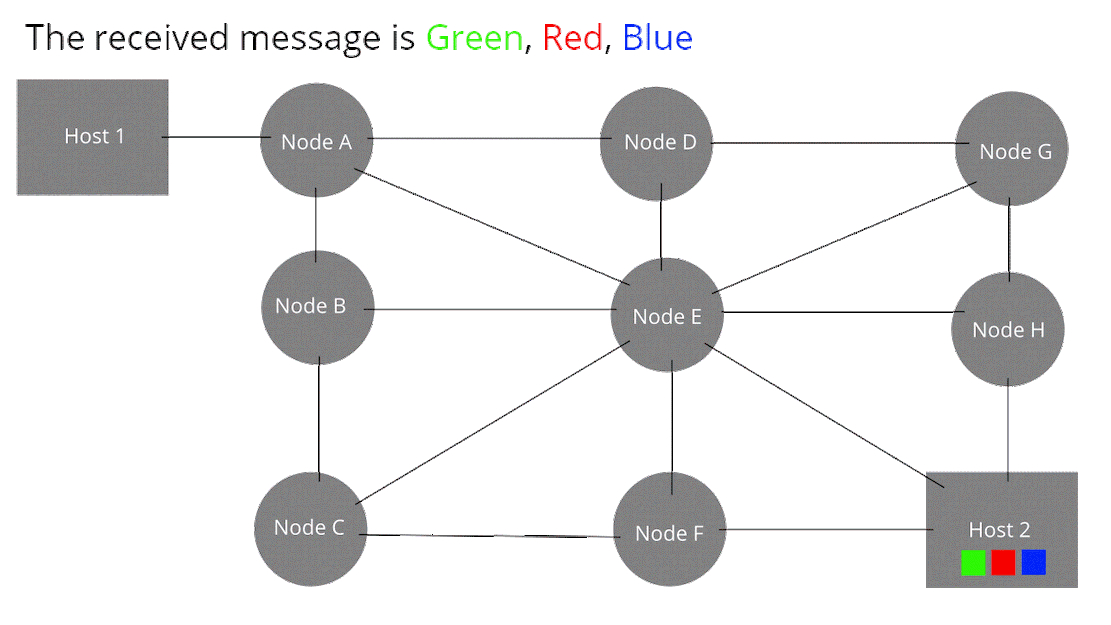
TCP 为什么握手是 3 次、挥手是 4 次?
TCP 协议
要想把开篇这道面试题回答得漂亮,我们有必要先说一下概念,然后我再逐字给你解读。
TCP(Transport Control Protocol)是一个传输层协议,提供 Host-To-Host 数据的可靠传输,支持全双工,是一个连接导向的协议。
这里面牵涉很多概念,比如主机到主机、连接、会话、双工/单工及可靠性等,接下来我会为你逐一解释。
主机到主机(Host-To-Host)
TCP 提供的是 Host-To-Host 传输,一台主机通过 TCP 发送数据给另一台主机。这里的主机(Host)是一个抽象的概念,可以是手机、平板、手表等。收发数据的设备都是主机,所以双方是平等的。

TCP 协议往上是应用到应用(Application-To-Application)的协议。什么是应用到应用的协议呢?比如你用微信发信息给张三,你的微信客户端、微信聊天服务都是应用。微信有自己的聊天协议,微信的聊天协议是应用到应用的协议;如果微信的聊天协议想要工作,就需要一个主机到主机的协议帮助它实现通信。
而 TCP 上层有太多的应用,不仅仅有微信,还有原神、抖音、网易云音乐……因此 TCP 上层的应用层协议使用 TCP 能力的时候,需要告知 TCP 是哪个应用——这就是端口号。端口号用于区分应用,下文中我们还会详细讨论。
TCP 要实现主机到主机通信,就需要知道主机们的网络地址(IP 地址),但是 TCP 不负责实际地址到地址(Address-To-Address)的传输,因此 TCP 协议把 IP 地址给底层的互联网层处理。
互联网层,也叫网络层(Network Layer),提供地址到地址的通信,IP 协议就在这一层工作。互联网层解决地址到地址的通信,但是不负责信号在具体两个设备间传递。因此,网络层会调用下方的链路层在两个相邻设备间传递信息。当信号在两个设备间传递的时候,科学家又设计出了物理层封装最底层的物理设备、传输介质等,由最下方的物理层提供最底层的传输能力。
以上的 5 层架构,我们称为互联网协议群,也称作 TCP/IP 协议群。总结下,主机到主机(Host-To-Host)为应用提供应用间通信的能力。
什么是连接和会话?
下一个关联的概念是连接(Connection)——连接是数据传输双方的契约。
连接是通信双方的一个约定,目标是让两个在通信的程序之间产生一个默契,保证两个程序都在线,而且尽快地响应对方的请求,这就是连接(Connection)。
设计上,连接是一种传输数据的行为。传输之前,建立一个连接。具体来说,数据收发双方的内存中都建立一个用于维护数据传输状态的对象,比如双方 IP 和端口是多少?现在发送了多少数据了?状态健康吗?传输速度如何?等。所以,连接是网络行为状态的记录。
和连接关联的还有一个名词,叫作会话(Session),会话是应用的行为。比如微信里张三和你聊天,那么张三和你建立一个会话。你要和张三聊天,你们创建一个聊天窗口,这个就是会话。你开始 Typing,开始传输数据,你和微信服务器间建立一个连接。如果你们聊一段时间,各自休息了,约定先不要关微信,1 个小时后再回来。那么连接会断开,因为聊天窗口没关,所以会话还在。
在有些系统设计中,会话会自动重连(也就是重新创建连接),或者帮助创建连接。 此外,会话也负责在多次连接中保存状态,比如 HTTP Session 在多次 HTTP 请求(连接)间保持状态(如用户信息)。
总结下,会话是应用层的概念,连接是传输层的概念。
双工/单工问题
接下来我们聊聊什么是双工/单工。
在任何一个时刻,如果数据只能单向发送,就是单工,所以单工需要至少一条线路。如果在某个时刻数据可以向一个方向传输,也可以向另一个方向反方向传输,而且交替进行,叫作半双工;半双工需要至少 1 条线路。最后,如果任何时刻数据都可以双向收发,这就是全双工,全双工需要大于 1 条线路。当然这里的线路,是一个抽象概念,你可以并发地处理信号,达到模拟双工的目的。
TCP 是一个双工协议,数据任何时候都可以双向传输。这就意味着客户端和服务端可以平等地发送、接收信息。正因为如此,客户端和服务端在 TCP 协议中有一个平等的名词——Host(主机)。
什么是可靠性?
上文提到 TCP 提供可靠性,那么可靠性是什么?
可靠性指数据保证无损传输。如果发送方按照顺序发送,然后数据无序地在网络间传递,就必须有一种算法在接收方将数据恢复原有的顺序。另外,如果发送方同时要把消息发送给多个接收方,这种情况叫作多播,可靠性要求每个接收方都无损收到相同的副本。多播情况还有强可靠性,就是如果有一个消息到达任何一个接收者,那么所有接受者都必须收到这个消息。说明一下,本专栏中,我们都是基于单播讨论可靠性。
TCP 的握手和挥手
TCP 是一个连接导向的协议,设计有建立连接(握手)和断开连接(挥手)的过程。TCP 没有设计会话(Session),因为会话通常是一个应用的行为。
TCP 协议的基本操作
TCP 协议有这样几个基本操作:
如果一个 Host 主动向另一个 Host 发起连接,称为 SYN(Synchronization),请求同步;
如果一个 Host 主动断开请求,称为 FIN(Finish),请求完成;
如果一个 Host 给另一个 Host 发送数据,称为 PSH(Push),数据推送。
以上 3 种情况,接收方收到数据后,都需要给发送方一个 ACK(Acknowledgement)响应。请求/响应的模型是可靠性的要求,如果一个请求没有响应,发送方可能会认为自己需要重发这个请求。
建立连接的过程(三次握手)
因为要保持连接和可靠性约束,TCP 协议要保证每一条发出的数据必须给返回,返回数据叫作 ACK(也就是响应)。
按照这个思路,你可以看看建立连接是不是需要 3 次握手:
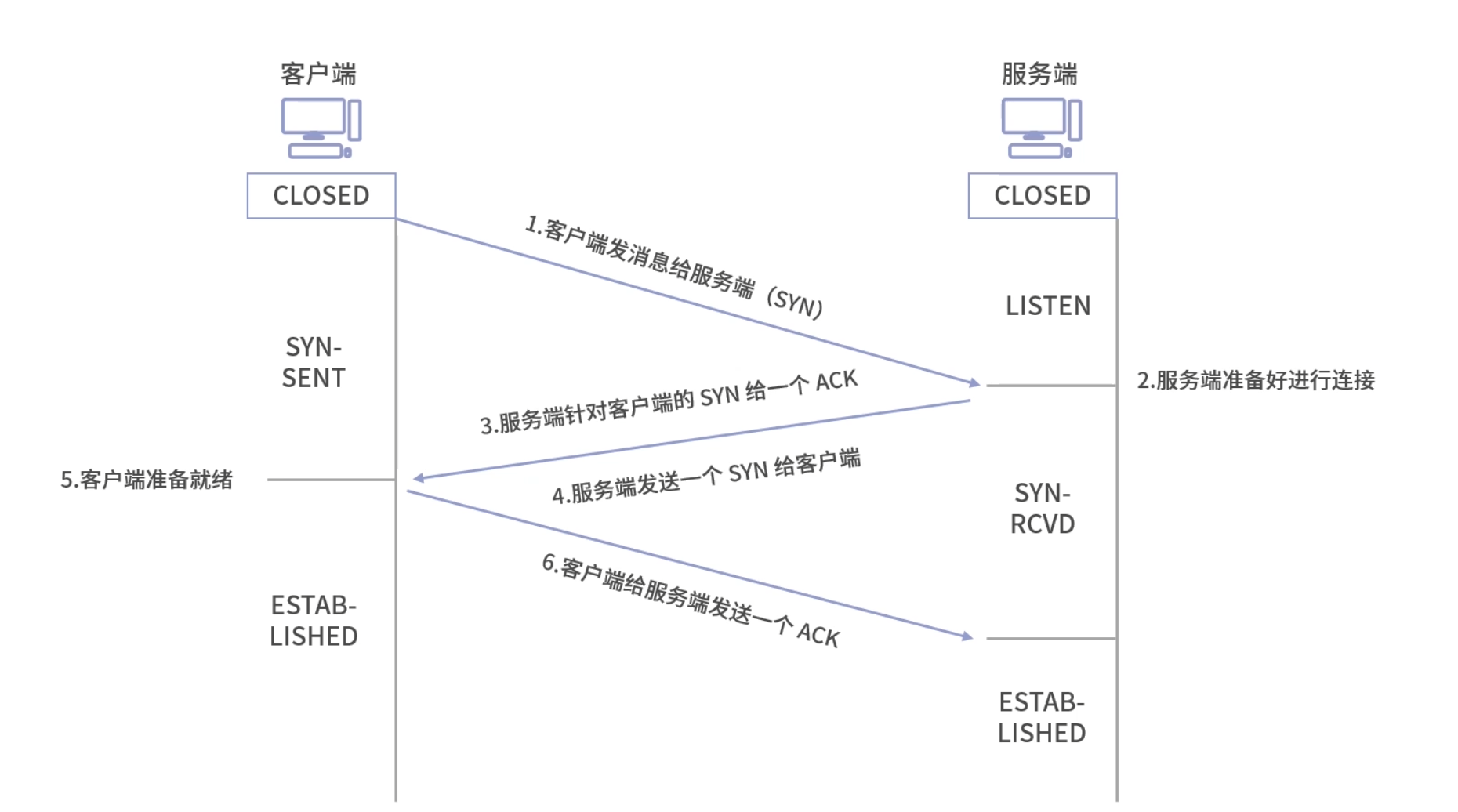
客户端发消息给服务端(SYN)
服务端准备好进行连接
服务端针对客户端的 SYN 给一个 ACK
你可以能会问,到这里不就可以了吗?2 次握手就足够了。但其实不是,因为服务端还没有确定客户端是否准备好了。比如步骤 3 之后,服务端马上给客户端发送数据,这个时候客户端可能还没有准备好接收数据。因此还需要增加一个过程。
接下来还会发生以下操作:
服务端发送一个 SYN 给客户端
客户端准备就绪
客户端给服务端发送一个 ACK
你可能会问,上面不是 6 个步骤吗? 怎么是 3 次握手呢?下面我们一起分析一下其中缘由。
步骤 1 是 1 次握手;
步骤 2 是服务端的准备,不是数据传输,因此不算握手;
步骤 3 和步骤 4,因为是同时发生的,可以合并成一个 SYN-ACK 响应,作为一条数据传递给客户端,因此是第 2 次握手;
步骤 5 不算握手;
步骤 6 是第 3 次握手。
为了方便你理解步骤 3 和步骤 4,这里我画了一张图。可以看到下图中 SYN 和 ACK 被合并了,因此建立连接一共需要 3 次握手,过程如下图所示:
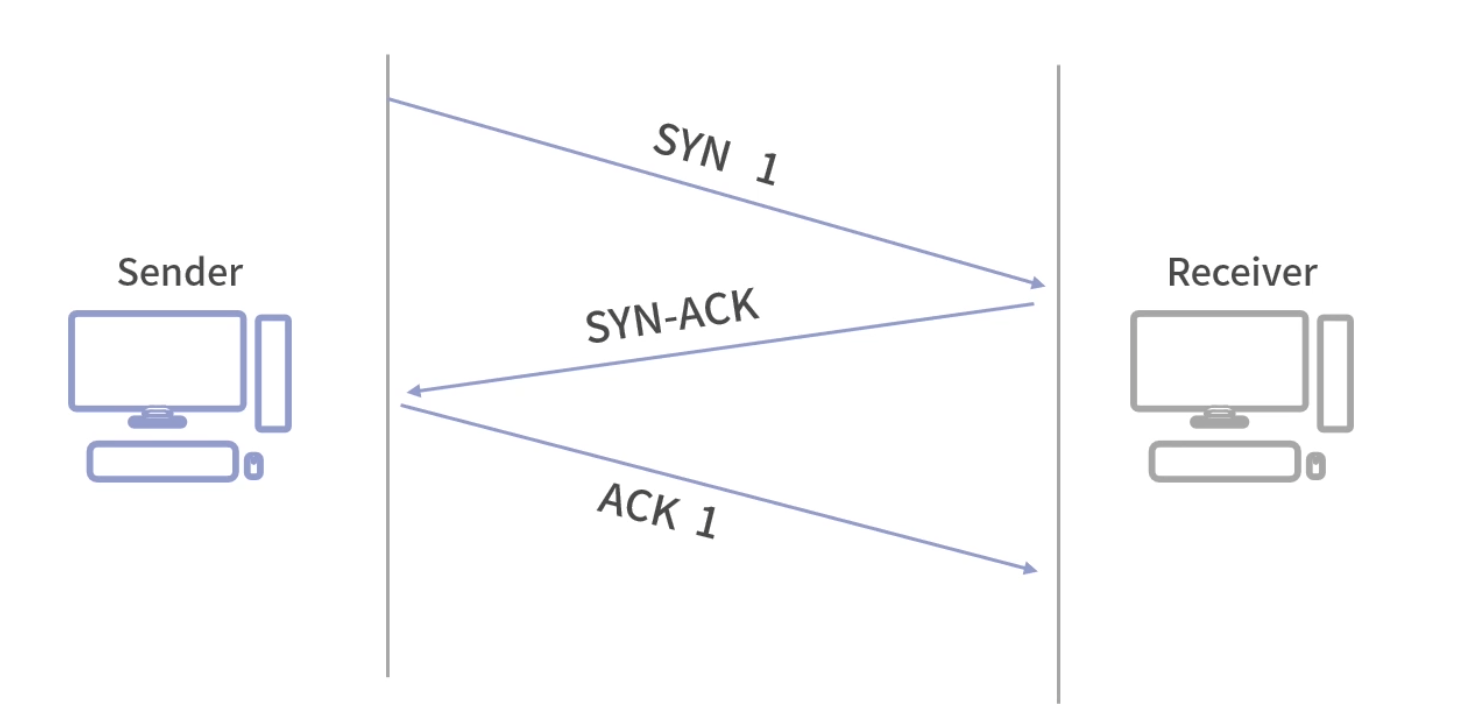
从上面的例子中,你可以进一步思考 SYN、ACK、PSH 这些常见的标识位(Flag)在传输中如何表示。
一种思路是为 TCP 协议增加协议头。在协议头中取多个位(bit),其中 SYN、ACK、PSH 都占有 1 个位。比如 SYN 位,1 表示 SYN 开启,0 表示关闭。因此,SYN-ACK 就是 SYN 位和 ACK 位都置 1。这种设计,我们也称为标识(Flag)。标识位是放在 TCP 头部的,关于标识位和 TCP 头的内容,我会在“04 | TCP 的稳定性:滑动窗口和流速控制是怎么回事?”中详细介绍。
断开连接的过程(4 次挥手)
继续上面的思路,如果断开连接需要几次握手?给你一些提示,你可以在脑海中这样构思。
客户端要求断开连接,发送一个断开的请求,这个叫作(FIN)。
服务端收到请求,然后给客户端一个 ACK,作为 FIN 的响应。
这里你需要思考一个问题,可不可以像握手那样马上传 FIN 回去?
其实这个时候服务端不能马上传 FIN,因为断开连接要处理的问题比较多,比如说服务端可能还有发送出去的消息没有得到 ACK;也有可能服务端自己有资源要释放。因此断开连接不能像握手那样操作——将两条消息合并。所以,服务端经过一个等待,确定可以关闭连接了,再发一条 FIN 给客户端。
客户端收到服务端的 FIN,同时客户端也可能有自己的事情需要处理完,比如客户端有发送给服务端没有收到 ACK 的请求,客户端自己处理完成后,再给服务端发送一个 ACK。
经过以上分析,就可以回答上面这个问题了。是不是刚刚好 4 次挥手?过程如下图所示:
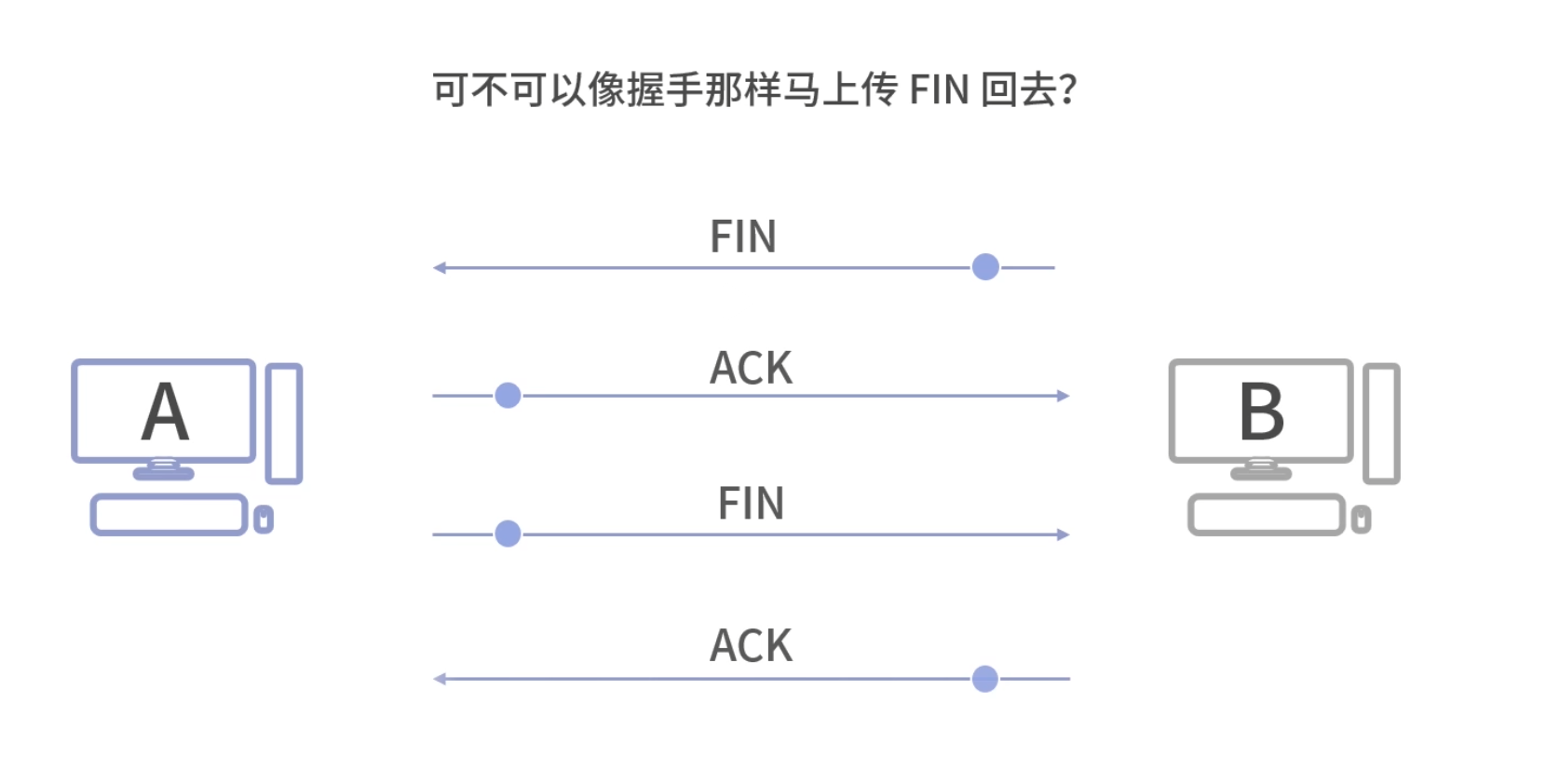
总结
在学习 3 次握手、4 次挥手时,你一定要理解为什么这么设计,而不是死记硬背。最后。我们一起总结一下今天的重点知识。
TCP 提供连接(Connection),让双方的传输更加稳定、安全。
TCP 没有直接提供会话,因为应用对会话的需求多种多样,比如聊天程序会话在保持双方的聊天记录,电商程序会话在保持购物车、订单一致,所以会话通常在 TCP 连接上进一步封装,在应用层提供。
TCP 是一个面向连接的协议(Connection -oriented Protocol),说的就是 TCP 协议参与的双方(Host)在收发数据之前会先建立连接。后面我们还会学习 UDP 协议,UDP 是一个面向报文(Datagram-oriented)的协议——协议双方不需要建立连接,直接传送报文(数据)。
最后,连接需要消耗更多的资源。比如说,在传输数据前,必须先协商建立连接。因此,不是每种场景都应该用连接导向的协议。像视频播放的场景,如果使用连接导向的协议,服务端每向客户端推送一帧视频,客户端都要给服务端一次响应,这是不合理的。
TCP 为什么是 3 次握手,4 次挥手?
【解析】TCP 是一个双工协议,为了让双方都保证,建立连接的时候,连接双方都需要向对方发送 SYC(同步请求)和 ACK(响应)。
握手阶段双方都没有烦琐的工作,因此一方向另一方发起同步(SYN)之后,另一方可以将自己的 ACK 和 SYN 打包作为一条消息回复,因此是 3 次握手——需要 3 次数据传输。
到了挥手阶段,双方都可能有未完成的工作。收到挥手请求的一方,必须马上响应(ACK),表示接收到了挥手请求。类比现实世界中,你收到一个 Offer,出于礼貌你先回复考虑一下,然后思考一段时间再回复 HR 最后的结果。最后等所有工作结束,再发送请求中断连接(FIN),因此是 4 次挥手。
一台内存在 8G 左右的服务器,可以同时维护多少个连接?
tcp连接数上限其实受限于机器的内存,以8G内存为例,假设一个tcp连接需要占用的最小内存是8k(发送接收缓存各4k,当然还要考虑socket描述符),那么最大连接数为:810241024/8=1048576个,即约100万个tcp长连接。不过这只是理论数值,并未考虑实际业务。
http为什么是单工,ws是双工?
http应用层设计就请求/响应模型。这个模型比较好理解,或者说符合用户打开一次浏览器,开一张页面的逻辑。ws应用层设计是聊天用的,当然就得是双工。是需求解决的了最终的选择,而不能反过来思考。
TCP 为什么要粘包和拆包?
如今,大半个互联网都建立在 TCP 协议之上,我们使用的 HTTP 协议、消息队列、存储、缓存,都需要用到 TCP 协议——这是因为 TCP 协议提供了可靠性。简单来说,可靠性就是让数据无损送达。但若是考虑到成本,就会变得非常复杂——因为还需要尽可能地提升吞吐量、降低延迟、减少丢包率。
TCP 协议具有很强的实用性,而可靠性又是 TCP 最核心的能力,所以理所当然成为面试官们津津乐道的问题。具体来说,从一个终端有序地发出多个数据包,经过一个复杂的网络环境,到达目的地的时候会变得无序,而可靠性要求数据恢复到原始的顺序。这里我先给你提出两个问题:
TCP 协议是如何恢复数据的顺序的?
拆包和粘包的作用是什么?
下面请你带着这两个问题开始今天的学习。
TCP 的拆包和粘包
TCP 是一个传输层协议。TCP 发送数据的时候,往往不会将数据一次性发送,像下图这样:

而是将数据拆分成很多个部分,然后再逐个发送。像下图这样:

同样的,在目的地,TCP 协议又需要逐个接收数据。请你思考,TCP 为什么不一次发送完所有的数据?比如我们要传一个大小为 10M 的文件,对于应用层而言,就是一次传送完成的。而传输层的协议为什么不选择将这个文件一次发送完呢?
这里有很多原因,比如为了稳定性,一次发送的数据越多,出错的概率越大。再比如说为了效率,网络中有时候存在着并行的路径,拆分数据包就能更好地利用这些并行的路径。再有,比如发送和接收数据的时候,都存在着缓冲区。如下图所示:

缓冲区是在内存中开辟的一块区域,目的是缓冲。因为大量的应用频繁地通过网卡收发数据,这个时候,网卡只能一个一个处理应用的请求。当网卡忙不过来的时候,数据就需要排队,也就是将数据放入缓冲区。如果每个应用都随意发送很大的数据,可能导致其他应用实时性遭到破坏。
还有一些原因我们在《重学操作系统》专栏的“24 | 虚拟内存 :一个程序最多能使用多少内存?”中讨论过。比如内存的最小分配单位是页表,如果数据的大小超过一个页表,可能会存在页面置换问题,造成性能的损失。如果你对这一部分的知识感兴趣,可以学习我在拉勾教育推出的《重学操作系统》专栏。
总之,方方面面的原因:在传输层封包不能太大。这种限制,往往是以缓冲区大小为单位的。也就是 TCP 协议,会将数据拆分成不超过缓冲区大小的一个个部分。每个部分有一个独特的名词,叫作 TCP 段(TCP Segment)。
在接收数据的时候,一个个 TCP 段又被重组成原来的数据。
像这样,数据经过拆分,然后传输,然后在目的地重组,俗称拆包。所以拆包是将数据拆分成多个 TCP 段传输。那么粘包是什么呢?有时候,如果发往一个目的地的多个数据太小了,为了防止多次发送占用资源,TCP 协议有可能将它们合并成一个 TCP 段发送,在目的地再还原成多个数据,这个过程俗称粘包。所以粘包是将多个数据合并成一个 TCP 段发送。
TCP Segment
那么一个 TCP 段长什么样子呢?下图是一个 TCP 段的格式:

我们可以看到,TCP 的很多配置选项和数据粘在了一起,作为一个 TCP 段。
显然,让你把每一部分都记住似乎不太现实,但是我会带你把其中最主要的部分理解。TCP 协议就是依靠每一个 TCP 段工作的,所以你每认识一个 TCP 的能力,几乎都会找到在 TCP Segment 中与之对应的字段。接下来我先带你认识下它们。
Source Port/Destination Port 描述的是发送端口号和目标端口号,代表发送数据的应用程序和接收数据的应用程序。比如 80 往往代表 HTTP 服务,22 往往是 SSH 服务……
Sequence Number 和 Achnowledgment Number 是保证可靠性的两个关键。具体见下文的讨论。
Data Offset 是一个偏移量。这个量存在的原因是 TCP Header 部分的长度是可变的,因此需要一个数值来描述数据从哪个字节开始。
Reserved 是很多协议设计会保留的一个区域,用于日后扩展能力。
URG/ACK/PSH/RST/SYN/FIN 是几个标志位,用于描述 TCP 段的行为。也就是一个 TCP 封包到底是做什么用的?
1)URG 代表这是一个紧急数据,比如远程操作的时候,用户按下了 Ctrl+C,要求终止程序,这种请求需要紧急处理。
2)ACK 代表响应,我们在“02 | 传输层协议 TCP:TCP 为什么握手是 3 次、挥手是 4 次?”讲到过,所有的消息都必须有 ACK,这是 TCP 协议确保稳定性的一环。
3)PSH 代表数据推送,也就是在传输数据的意思。
4)SYN 同步请求,也就是申请握手。
5)FIN 终止请求,也就是挥手。
特别说明一下:以上这 5 个标志位,每个占了一个比特,可以混合使用。比如 ACK 和 SYN 同时为 1,代表同步请求和响应被合并了。这也是 TCP 协议,为什么是三次握手的原因之一。
6) Window 也是 TCP 保证稳定性并进行流量控制的工具,我们会在“04 | TCP 的稳定性:滑动窗口和流速控制是怎么回事?”中详细介绍。
7)Checksum 是校验和,用于校验 TCP 段有没有损坏。
8)Urgent Pointer 指向最后一个紧急数据的序号(Sequence Number)。它存在的原因是:有时候紧急数据是连续的很多个段,所以需要提前告诉接收方进行准备。
9)Options 中存储了一些可选字段,比如接下来我们要讨论的 MSS(Maximun Segment Size)。
10)Padding 存在的意义是因为 Options 的长度不固定,需要 Pading 进行对齐。
Sequence Number 和 Acknowledgement Number
在 TCP 协议的设计当中,数据被拆分成很多个部分,部分增加了协议头。合并成为一个 TCP 段,进行传输。这个过程,我们俗称拆包。这些 TCP 段经过复杂的网络结构,由底层的 IP 协议,负责传输到目的地,然后再进行重组。
这里请你思考一个问题:稳定性要求数据无损地传输,也就是说拆包获得数据,又需要恢复到原来的样子。而在复杂的网络环境当中,即便所有的段是顺序发出的,也不能保证它们顺序到达,因此,发出的每一个 TCP 段都需要有序号。这个序号,就是 Sequence Number(Seq)。

如上图所示。发送数据的时候,为每一个 TCP 段分配一个自增的 Sequence Number。接收数据的时候,虽然得到的是乱序的 TCP 段,但是可以通过 Seq 进行排序。
但是这样又会产生一个新的问题——接收方如果要回复发送方,也需要这个 Seq。而网络的两个终端,去同步一个自增的序号是非常困难的。因为任何两个网络主体间,时间都不能做到完全同步,又没有公共的存储空间,无法共享数据,更别说实现一个分布式的自增序号了。
其实这个问题的本质就好像两个人在说话一样,我们要确保他们说出去的话,和回答之间的顺序。因为 TCP 是一个双工的协议,两边可能会同时说话。所以聪明的科学家想到了确定一句话的顺序,需要两个值去描述——也就是发送的字节数和接收的字节数。

我们重新定义一下 Seq(如上图所示),对于任何一个接收方,如果知道了发送者发送某个 TCP 段时,已经发送了多少字节的数据,那么就可以确定发送者发送数据的顺序。
但是这里有一个问题。如果接收方也向发送者发送了数据请求(或者说双方在对话),接收方就不知道发送者发送的数据到底对应哪一条自己发送的数据了。
举个例子:下面 A 和 B 的对话中,我们可以确定他们彼此之间接收数据的顺序。但是无法确定数据之间的关联关系,所以只有 Sequence Number 是不够的。
1 | A:今天天气好吗? |
人类很容易理解这几句话的顺序,但是对于机器来说就需要特别的标注。因此我们还需要另一个数据,就是每个 TCP 段发送时,发送方已经接收了多少数据。用 Acknowledgement Number 表示,下面简写为 ACK。
下图中,终端发送了三条数据,并且接收到四条数据,通过观察,根据接收到的数据中的 Seq 和 ACK,将发送和接收的数据进行排序。
例如上图中,发送方发送了 100 字节的数据,而接收到的(Seq = 0 和 Seq =100)的两个封包,都是针对发送方(Seq = 0)这个封包的。发送 100 个字节,所以接收到的 ACK 刚好是 100。说明(Seq= 0 和 Seq= 100)这两个封包是针对接收到第 100 个字节数据后,发送回来的。这样就确定了整体的顺序。
注意,无论 S\**eq**\ 还是 ACK,都是针对“对方”而言的。是对方发送的数据和对方接收到的数据**。我们在实际的工作当中,可以通过 Whireshark 调试工具观察两个 TCP 连接的 Seq和 ACK。
具体的使用方法,我会在“09 | TCP 实战:如何进行 TCP 抓包调试?”中和你讨论。

MSS(Maximun Segment Size)
接下来,我们讨论下 MSS,它也是面试经常会问到的一个 TCP Header 中的可选项(Options),这个可选项控制了 TCP 段的大小,它是一个协商字段(Negotiate)。协议是双方都要遵循的标准,因此配置往往不能由单方决定,需要双方协商。
TCP 段的大小(MSS)涉及发送、接收缓冲区的大小设置,双方实际发送接收封包的大小,对拆包和粘包的过程有指导作用,因此需要双方去协商。
如果这个字段设置得非常大,就会带来一些影响。
首先对方可能会拒绝,作为服务的提供方,你可能不会愿意接收太大的 TCP 段。因为大的 TCP 段,会降低性能,比如内存使用的性能。具体你可以参考《重学操作系统》课程中关于页表的讨论。
还有就是资源的占用。一个用户占用服务器太多的资源,意味着其他的用户就需要等待或者降低他们的服务质量。
其次,支持 TCP 协议工作的 IP 协议,工作效率会下降。TCP 协议不肯拆包,IP 协议就需要拆出大量的包。那么 IP 协议为什么需要拆包呢?这是因为在网络中,每次能够传输的数据不可能太大,这受限于具体的网络传输设备,也就是物理特性。但是 IP 协议,拆分太多的封包并没有意义。因为可能会导致属于同个 TCP 段的封包被不同的网络路线传输,这会加大延迟。同时,拆包,还需要消耗硬件和计算资源。
那是不是 MSS 越小越好呢?MSS 太小的情况下,会浪费传输资源(降低吞吐量)。因为数据被拆分之后,每一份数据都要增加一个头部。如果 MSS 太小,那头部的数据占比会上升,这让吞吐量成为一个灾难。所以在使用的过程当中,MSS 的配置,往往都是一个折中的方案。而根据 Unix 的哲学,不要去猜想什么样的方案是最合理的,而是要尝试去用实验证明它,一切都要用实验依据说话。
TCP 协议是如何恢复数据的顺序的,TCP 拆包和粘包的作用是什么?
TCP 拆包的作用是将任务拆分处理,降低整体任务出错的概率,以及减小底层网络处理的压力。拆包过程需要保证数据经过网络的传输,又能恢复到原始的顺序。这中间,需要数学提供保证顺序的理论依据。TCP 利用(发送字节数、接收字节数)的唯一性来确定封包之间的顺序关系。具体的算法,我们会在下一讲“04 | TCP 的稳定性解决方案 :滑动窗口和流量控制是怎么回事?”中给出。粘包是为了防止数据量过小,导致大量的传输,而将多个 TCP 段合并成一个发送。
滑动窗口和流速控制是怎么回事?
TCP 作为一个传输层协议,最核心的能力是传输。传输需要保证可靠性,还需要控制流速,这两个核心能力均由滑动窗口提供。而滑动窗口中解决的问题,是你在今后的工作中可以长期使用的,比如设计一个分布式的 RPC 框架、实现一个消息队列或者分布式的文件系统等。
所以请你带着今天的问题“滑动窗口和流速控制是怎么回事?”开始今天的学习吧!
请求/响应模型
TCP 中每个发送的请求都需要响应。如果一个请求没有收到响应,发送方就会认为这次发送出现了故障,会触发重发。
大体的模型,和下图很像。但是如果完全和下图一样,每一个请求收到响应之后,再发送下一个请求,吞吐量会很低。因为这样的设计,会产生网络的空闲时间,说白了,就是浪费带宽。带宽没有用满,意味着可以同时发送更多的请求,接收更多的响应。
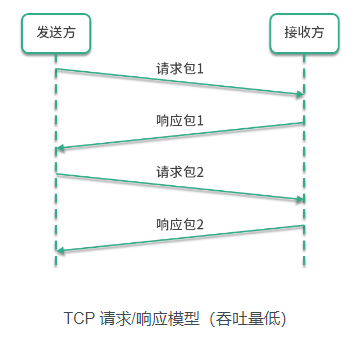
一种改进的方式,就是让发送方有请求就发送出去,而不是等待响应。通过这样的处理方式,发送的数据连在了一起,响应的数据也连在了一起,吞吐量就提升了。
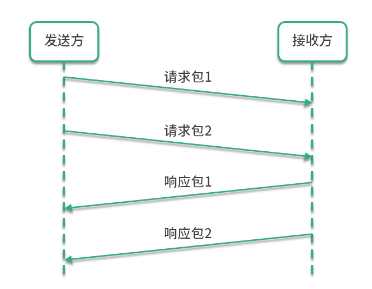
但是如果可以同时发送的数据真的非常多呢?比如成百上千个 TCP 段都需要发送,这个时候带宽可能会不足。很多个数据封包都需要发送,该如何处理呢?
排队(Queuing)
在这种情况下,通常我们会考虑排队(Queuing)机制。
考虑这样一个模型,如上图所示,在 TCP 层实现一个队列。新元素从队列的一端(左侧)排队,作为一个未发送的数据封包。开始发送的数据封包,从队列的右侧离开。你可以思考一下,这个模型有什么问题吗?
这样做就需要多个队列,我们要将未发送的数据从队列中取出,加入发送中的队列。然后再将发送中的数据,收到 ACK 的部分取出,放入已接收的队列。而发送中的封包,何时收到 ACK 是一件不确定的事情,这样使用队列似乎也有一定的问题。
滑动窗口(Sliding Window)
在上面的模型当中,我们之所以觉得算法不好设计,是因为用错了数据结构。有个说法叫作如果程序写复杂了,那就是写错了。这里其实应该用一种叫作滑动窗口的数据结构去实现。
如上图所示:
- 深绿色代表已经收到 ACK 的段
- 浅绿色代表发送了,但是没有收到 ACK 的段
- 白色代表没有发送的段
- 紫色代表暂时不能发送的段
下面我们重新设计一下不同类型封包的顺序,将已发送的数据放到最左边,发送中的数据放到中间,未发送的数据放到右边。假设我们最多同时发送 5 个封包,也就是窗口大小 = 5。窗口中的数据被同时发送出去,然后等待 ACK。如果一个封包 ACK 到达,我们就将它标记为已接收(深绿色)。
如下图所示,有两个封包的 ACK 到达,因此标记为绿色。
这个时候滑动窗口可以向右滑动,如下图所示:
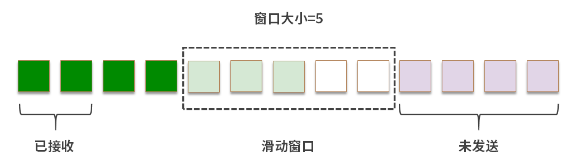
重传
如果发送过程中,部分数据没能收到 ACK 会怎样呢?这就可能发生重传。
如果发生下图这样的情况,段 4 迟迟没有收到 ACK。
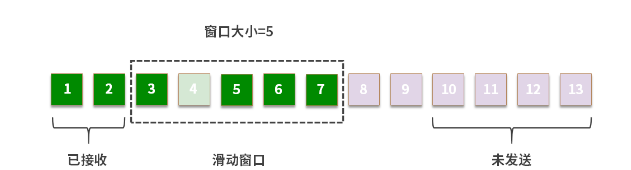
这个时候滑动窗口只能右移一个位置,如下图所示:
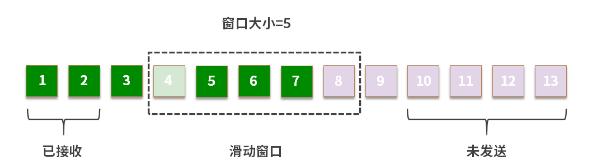
在这个过程中,如果后来段 4 重传成功(接收到 ACK),那么窗口就会继续右移。如果段 4 发送失败,还是没能收到 ACK,那么接收方也会抛弃段 5、段 6、段 7。这样从段 4 开始之后的数据都需要重发。
快速重传
在 TCP 协议中,如果接收方想丢弃某个段,可以选择不发 ACK。发送端超时后,会重发这个 TCP 段。而有时候,接收方希望催促发送方尽快补发某个 TCP 段,这个时候可以使用快速重传能力。
例如段 1、段 2、段 4 到了,但是段 3 没有到。 接收方可以发送多次段 3 的 ACK。如果发送方收到多个段 3 的 ACK,就会重发段 3。这个机制称为快速重传。这和超时重发不同,是一种催促的机制。
为了不让发送方误以为段 3 已经收到了,在快速重传的情况下,接收方即便收到发来的段 4,依然会发段 3 的 ACK(不发段 4 的 ACK),直到发送方把段 3 重传。
窗口大小的单位是?
请你思考另一个问题,窗口大小的单位是多少呢?在上面所有的图片中,窗口大小是 TCP 段的数量。实际操作中,每个 TCP 段的大小不同,限制数量会让接收方的缓冲区不好操作,因此实际操作中窗口大小单位是字节数。
流速控制
发送、接收窗口的大小可以用来控制 TCP 协议的流速。窗口越大,同时可以发送、接收的数据就越多,支持的吞吐量也就越大。当然,窗口越大,如果数据发生错误,损失也就越大,因为需要重传越多的数据。
举个例子:我们用 RTT 表示 Round Trip Time,就是消息一去一回的时间。
假设 RTT = 1ms,带宽是 1mb/s。如果窗口大小为 1kb,那么 1ms 可以发送一个 1kb 的数据(含 TCP 头),1s 就可以发送 1mb 的数据,刚好可以将带宽用满。如果 RTT 再慢一些,比如 RTT = 10ms,那么这样的设计就只能用完 1/10 的带宽。 当然你可以提高窗口大小提高吞吐量,但是实际的模型会比这个复杂,因为还存在重传、快速重传、丢包等因素。
而实际操作中,也不可以真的把带宽用完,所以最终我们会使用折中的方案,在延迟、丢包率、吞吐量中进行选择,毕竟鱼和熊掌不可兼得。
总结
为了提高传输速率,TCP 协议选择将多个段同时发送,为了让这些段不至于被接收方拒绝服务,在发送前,双方要协商好发送的速率。但是我们不可能完全确定网速,所以协商的方式,就变成确定窗口大小。
有了窗口,发送方利用滑动窗口算法发送消息;接收方构造缓冲区接收消息,并给发送方 ACK。滑动窗口的实现只需要数组和少量的指针即可,是一个非常高效的算法。像这种算法,简单又实用,比如求一个数组中最大的连续 k 项和,就可以使用滑动窗口算法。如果你对这个问题感兴趣,不妨用你最熟悉的语言尝试解决一下。
滑动窗口和流速控制是怎么回事?
滑动窗口是 TCP 协议控制可靠性的核心。发送方将数据拆包,变成多个分组。然后将数据放入一个拥有滑动窗口的数组,依次发出,仍然遵循先入先出(FIFO)的顺序,但是窗口中的分组会一次性发送。窗口中序号最小的分组如果收到 ACK,窗口就会发生滑动;如果最小序号的分组长时间没有收到 ACK,就会触发整个窗口的数据重新发送。
另一方面,在多次传输中,网络的平均延迟往往是相对固定的,这样 TCP 协议可以通过双方协商窗口大小控制流速。补充下,上面我们说的分组和 TCP 段是一个意思。
TCP 协议和 UDP 协议的优势和劣势?
TCP 和 UDP 是今天应用最广泛的传输层协议,拥有最核心的垄断地位。TCP 最核心的价值是提供了可靠性,而 UDP 最核心的价值是灵活,你几乎可以用它来做任何事情。例如:HTTP 协议 1.1 和 2.0 都基于 TCP,而到了 HTTP 3.0 就开始用 UDP 了。
如果你打开 TCP 协议的 RFC文档,可以看到目录中一共有 85 页;如果你打开 UDP 的 RFC 文档,会看到目录中只有 3 页。一个只有 3 页的协议,能够成为今天最主流的传输层协议之一,那么它一定有非常值得我们学习的地方。
UDP 协议
UDP(User Datagram Protocol),目标是在传输层提供直接发送报文(Datagram)的能力。Datagram 是数据传输的最小单位。UDP 协议不会帮助拆分数据,它的目标只有一个,就是发送报文。
有细心的同学可能会问: 为什么不直接调用 IP 协议呢? 如果裸发数据,IP 协议不香吗?
这是因为传输层协议在承接上方应用层的调用,需要提供应用到应用的通信——因此要附上端口号。每个端口,代表不同的应用。传输层下层的 IP 协议,承接传输层的调用,将数据从主机传输到主机。IP 层不能区分应用,导致哪怕是在 IP 协议上进行简单封装,也需要单独一个协议。这就构成了 UDP 协议的市场空间。
UDP 的封包格式
UDP 的设计目标就是在允许用户直接发送报文的情况下,最大限度地简化应用的设计。下图是 UDP 的报文格式。
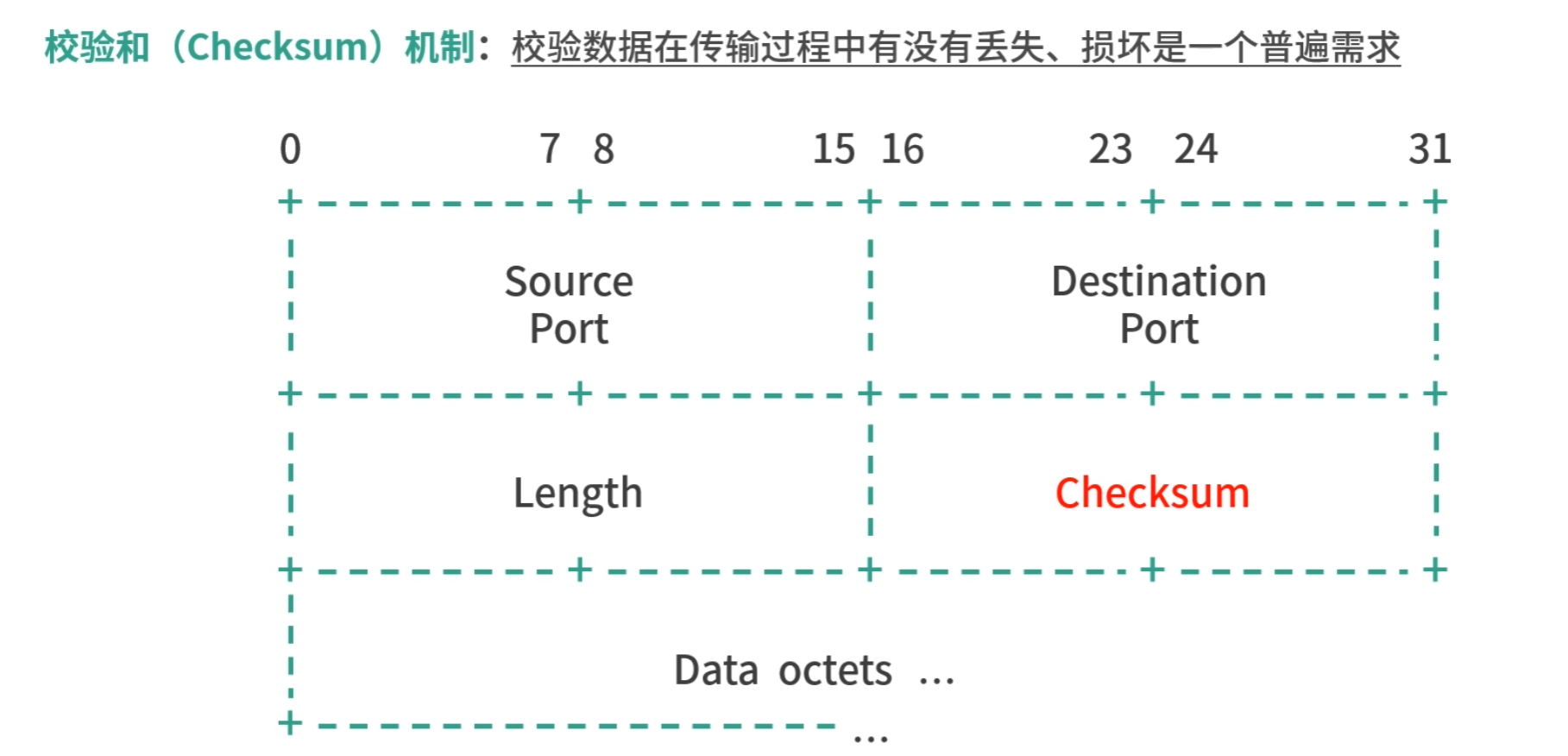
你可以看到,UDP 的报文非常简化,只有 5 个部分。
Source Port 是源端口号。因为 UDP 协议的特性(不需要 ACK),因此这个字段是可以省略的。但有时候对于防火墙、代理来说,Source Port 有很重要的意义,它们需要用这个字段行过滤和路由。
Destination Port 是目标端口号(这个字段不可以省略)。
Length 是消息体长度。
Checksum 是校验和,作用是检查封包是否出错。
Data octets 就是一个字节一个字节的数据,Octet 是 8 位。
下面我们先简单聊聊校验和(Checksum)机制,这个机制在很多的网络协议中都会存在,因为校验数据在传输过程中有没有丢失、损坏是一个普遍需求。在一次网络会话中,我们传输的内容可能是:“你好!”,但事实上传输的是 01 组成的二进制。请你思考这样一个算法,我们把数据分成一个一个 byte,然后将所有 byte 相加,再将最终的结果取反。
比如现在数据有 4 个 byte:a,b,c,d,那么一种最简单的校验和就是:
1 | checksum=(a+b+c+d) ^ 0xff |
如果发送方用上述方式计算出 Checksum,并将 a,b,c,d 和 Checksum 一起发送给接收方,接收方就可以用同样的算法再计算一遍,这样就可以确定数据有没有发生损坏(变化)。当然 Checksum 的做法,只适用于数据发生少量变化的情况。如果数据发生较大的变动,校验和也可能发生碰撞。
你可以看到 UDP 的可靠性保证仅仅就是 Checksum 一种。如果一个数据封包 Datagram 发生了数据损坏,UDP 可以通过 Checksum 纠错或者修复。 但是 UDP 没有提供再多的任何机制,比如 ACK、顺序保证以及流控等。
UDP 与 TCP的区别
接下来我们说说 UDP 和 TCP 的区别。
目的差异
首先,这两个协议的目的不同:TCP 协议的核心目标是提供可靠的网络传输,而 UDP 的目标是在提供报文交换能力基础上尽可能地简化协议轻装上阵。可靠性差异
TCP 核心是要在保证可靠性提供更好的服务。TCP 会有握手的过程,需要建立连接,保证双方同时在线。而且TCP 有时间窗口持续收集无序的数据,直到这一批数据都可以合理地排序组成连续的结果。
UDP 并不具备以上这些特性,它只管发送数据封包,而且 UDP 不需要 ACK,这意味着消息发送出去成功与否 UDP 是不管的。
连接 vs 无连接
TCP 是一个面向连接的协议(Connection-oriented Protocol),传输数据必须先建立连接。 UDP 是一个无连接协议(Connection-less Protocol),数据随时都可以发送,只提供发送封包(Datagram)的能力。流控技术(Flow Control)
TCP 使用了流控技术来确保发送方不会因为一次发送过多的数据包而使接收方不堪重负。TCP 在发送缓冲区中存储数据,并在接收缓冲区中接收数据。当应用程序准备就绪时,它将从接收缓冲区读取数据。如果接收缓冲区已满,接收方将无法处理更多数据,并将其丢弃。UDP 没有提供类似的能力。传输速度
UDP 协议简化,封包小,没有连接、可靠性检查等,因此单纯从传输速度上讲,UDP 更快。场景差异
TCP 每个数据封包都需要确认,因此天然不适应高速数据传输场景,比如观看视频(流媒体应用)、网络游戏(TCP 有延迟)等。具体来说,如果网络游戏用 TCP,每个封包都需要确认,可能会造成一定的延迟;再比如音、视频传输天生就允许一定的丢包率;Ping 和 DNSLookup,这类型的操作只需要一次简单的请求/返回,不需要建立连接,用 UDP 就足够了。
近些年有一个趋势,TCP/UDP 的边界逐渐变得模糊,UDP 应用越来越多。比如传输文件,如果考虑希望文件无损到达,可以用 TCP。如果考虑希望传输足够块,就可能会用 UDP。再比如 HTTP 协议,如果考虑请求/返回的可靠性,用 TCP 比较合适。但是像 HTTP 3.0 这类应用层协议,从功能性上思考,暂时没有找到太多的优化点,但是想要把网络优化到极致,就会用 UDP 作为底层技术,然后在 UDP 基础上解决可靠性。
所以理论上,任何一个用 TCP 协议构造的成熟应用层协议,都可以用 UDP 重构。这就好比,本来用一个工具可以解决所有问题,但是如果某一类问题体量非常大,就会专门为这类问题创造工具。因此,UDP 非常适合需要定制工具的场景。
下面我把场景分成三类,TCP 应用场景、UDP 应用场景、模糊地带(TCP、UDP 都可以考虑),你可以参考。
第一类:TCP 场景
远程控制(SSH)
File Transfer Protocol(FTP)
邮件(SMTP、IMAP)等
点对点文件传出(微信等)
第二类:UDP 场景
网络游戏
音视频传输
DNS
Ping
直播
第三类:模糊地带
HTTP(目前以 TCP 为主)
文件传输
以上我们从多个方面了解了 TCP 和 UDP 的区别,最后再来总结一下。UDP 不提供可靠性,不代表我们不能解决可靠性。UDP 的核心价值是灵活、轻量,构造了最小版本的传输层协议。在这个之上,还可以实现连接(Connection),实现会话(Session),实现可靠性(Reliability)……
总结
这一讲我们针对 UDP 协议的内容进行了探讨,到这里互联网协议群的传输层讲解就结束了。协议对于我们来说是非常重要的,协议的制定让所有参与者一致、有序地工作。
学习协议的设计,对你的工作非常有帮助。比如:
学习 TCP 协议可以培养你思维的缜密性——序号的设计、滑动窗口的设计、快速重发的设计、内在状态机的设计,都是非常精妙的想法;
学习 UDP 协议可以带动我们反思自己的技术架构,有时候简单的工具更受欢迎。Linux 下每个工具都是那么简单、专注,容易理解。相比 TCP 协议,UDP 更容易理解。
从程序架构上来说,今天我们更倾向于简单专注的设计,我们更期望有解决报文传输的工具、有解决可靠性的工具、有解决流量控制的工具、有解决连接和会话的工具……我相信这应该是未来的趋势——由大量优质的工具逐渐取代历史上沉淀下来完整统一的系统。从这个角度,我希望通过学习传输层的知识,能够帮助你重新审视自己的系统设计,看看自己还有哪些进步的空间。
TCP 协议和 UDP 协议的优势和劣势?
【解析】TCP 最核心的价值就是提供封装好的一套解决可靠性的优秀方案。 在前面 3 讲中,你可以看到解决可靠性是非常复杂的,要考虑非常多的因素。TCP 帮助我们在确保吞吐量、延迟、丢包率的基础上,保证可靠性。
历史上 TCP 也是靠可靠性起家的,有一次著名的实验,TCP 协议的设计者做了一次演示——利用 TCP 协议将数据在卫星和地面之间传播了很多次,没有发生任何数据损坏。从那个时候开始,研发人员开始大量选择 TCP 协议。然后随着生态的发展,逐渐提供了流控等能力。TCP 的成功在于它给人们提供了很多现成、好用的能力。
UDP 则不同,UDP 提供了最小版的实现,只支持 Checksum。UDP 最核心的价值是灵活、轻量、传输速度快。考虑到不同应用的特性,如果不使用一个大而全的方案,为自己的应用特性量身定做,可能会做得更好。比如网络游戏中游戏客户端不断向服务端发送玩家的位置,如果某一次消息丢失了,只要这个消息不影响最终的游戏结果,就可以只看下一个消息。不同应用有不同的特性,需要的可靠性级别不一样,这就是越来越多的应用开始使用 UDP 的原因之一。
其实对于我们来说,TCP 协议和 UDP 协议根本不存在什么优势和劣势,只不过是场景不同,选择不同而已。最后还有一个非常重要的考虑因素就是成本,如果没有足够专业的团队解决网络问题,TCP 无疑会是更好的选择。
Tips
有哪些好用的压测工具?
压力测试最常见的工具是 Apache Benchmark(简称 AB),在 Linux 下面可以通过包管理器安装 ab:
1 | yum install httpd-tools |
ab 安装好后,可以利用下面这条指令向某个网站发送并发 1000 的 10000 次请求:
1 | ab -n 10000 -p 1000 https://example.com/ |
ab 是用 C 语言写的,作为一个随手就可以用的工具,它的设计非常简单,是一个单线程的工作模型,因此如果遇到阻塞情况,可能直接导致 ab 工具自己积压崩溃。
所以。这里我给你推荐一个 Java 生态好用的工具“JMeter”,拥有可视化的界面
既然发送方有窗口,那么接收方也需要有窗口吗?
我们一起思考下,接收方收到发送方的每个数据分组(或者称为 TCP Segment),接收方肯定需要缓存。举例来说,如果发送方发送了:1, 2, 3, 4。 那么接收方可能收到的一种情况是:1,4,3。注意,没有收到 2 的原因可能是延迟、丢包等。这个时候,接收方有两种选择。
选择一:什么都不做(这样分组 2 的 ACK 就不会发送给发送方,发送方发现没有收到 2 的 ACK,过一段时间就有可能重发 2,3,4,5)。 当然具体设计还需要探讨,比如不重发整个分组,只重发已发送没有收到 ACK 的分组。
这种方法的缺陷是性能太差,重发了整个分组(或部分)。因此我们可以考虑另一种选择。
选择二:如果重发一个窗口,或部分窗口,问题就不会太大了。虽然增加了网络开销,但是毕竟有进步(1 进步了,不会再重发)。
性能方面最大的开销是等待超时的时间,就是发送方要等到超时时间才重发窗口,这样操作性能太差。因此,TCP 协议有一个快速重传的机制——接收方发现接收到了 1,但是没有接收到 2,那么马上发送 3 个分组 2 的 ACK 给到发送方,这样发送方收到多个 ACK,就知道接收方没有收到 2,于是马上重发 2。
无论是上面哪种方案,接收方也维护一个滑动窗口,是一个不错的选择。接收窗口的状态,可以和发送窗口的状态相互对应了。
Moba 类游戏的网络应该用 TCP 还是 UDP?
所有在线联机游戏都有件非常重要的事情需要完成,就是确定事件发生的唯一性,这个性质和聊天工具是类似的。听我这么说,是不是有点迷?请听我慢慢道来。
你在王者荣耀中控制后羿释放技能,这是一个事件。同时,王昭君放了大招,这是第二个事件。两个事件一定要有先后顺序吗?答案是当然要有。因为游戏在同一时刻只能有一个状态。
类比一下,多个线程同时操作内存,发生了竞争条件(具体分析可以参见[《重学操作系统》](https://kaiwu.lagou.com/course/courseInfo.htm?courseId=478&sid=20-h5Url-0&buyFrom=2&pageId=1pz4&utm_source=zhuanlan article&utm_medium=bottom&utm_campaign=《计算机网络通关 29讲》专栏内嵌&_channel_track_key=D2LoirKK#/content)专栏关于“线程”的内容),那么是不是意味着,内存在同一时刻有两个状态呢?当然不是,内存同时刻只能有一个状态,所以多个线程的操作必须有先有后。
回到 Moba 游戏的问题,每个事件,游戏服务器必须给一个唯一的时序编号,对应后羿的技能和王昭君的技能。所以,在线竞技类游戏,事实上是玩家在不断向服务器竞争一个自增序列号的过程。无论客户端发生怎样的行为,只有竞争到自增 ID 才能进步。也就是说,服务器要尽快响应多个客户端提交的事件,并以最快的速度分配自增序号,然后返回给客户端。
所以,Moba 服务端的核心是自增序号的计算和尽量缩减延迟。从这个角度出发,你再来看看,应该用 TCP 协议还是 UDP 协议呢?
虽然TCP 协议有 3 次握手,但是连接上之后,双方就不会再有额外的传输成本,因此创建连接的成本,可以忽略不计。
同时,TCP 协议还提供稳定性支持,不需要自己实现稳定性。如果规模较小的在线竞技类游戏,TCP 完全适用。但是当游戏玩家体量上升后,TCP 协议的头部(数据封包)较大,会增加服务器额外的 I/O 压力。要发送更多的数据,自然有更大的 I/O 压力。从这个角度来看,UDP 就有了用武之地。
路由和寻址的区别是什么?
如果说传输层协议,除了 TCP/UDP,我们还可以有其他选择,比如 Google 开发的 QUIC 协议,帮助在传输层支持 HTTP 3.0 传输。但是在网络层,IP 协议几乎一统天下。IP 协议目前主要有两个版本 IPv4 和 IPv6。这一讲我们先介绍 IPv4 协议。
根据 Google 统计,使用 IPv6 的Google 用户比例在 30% 左右。
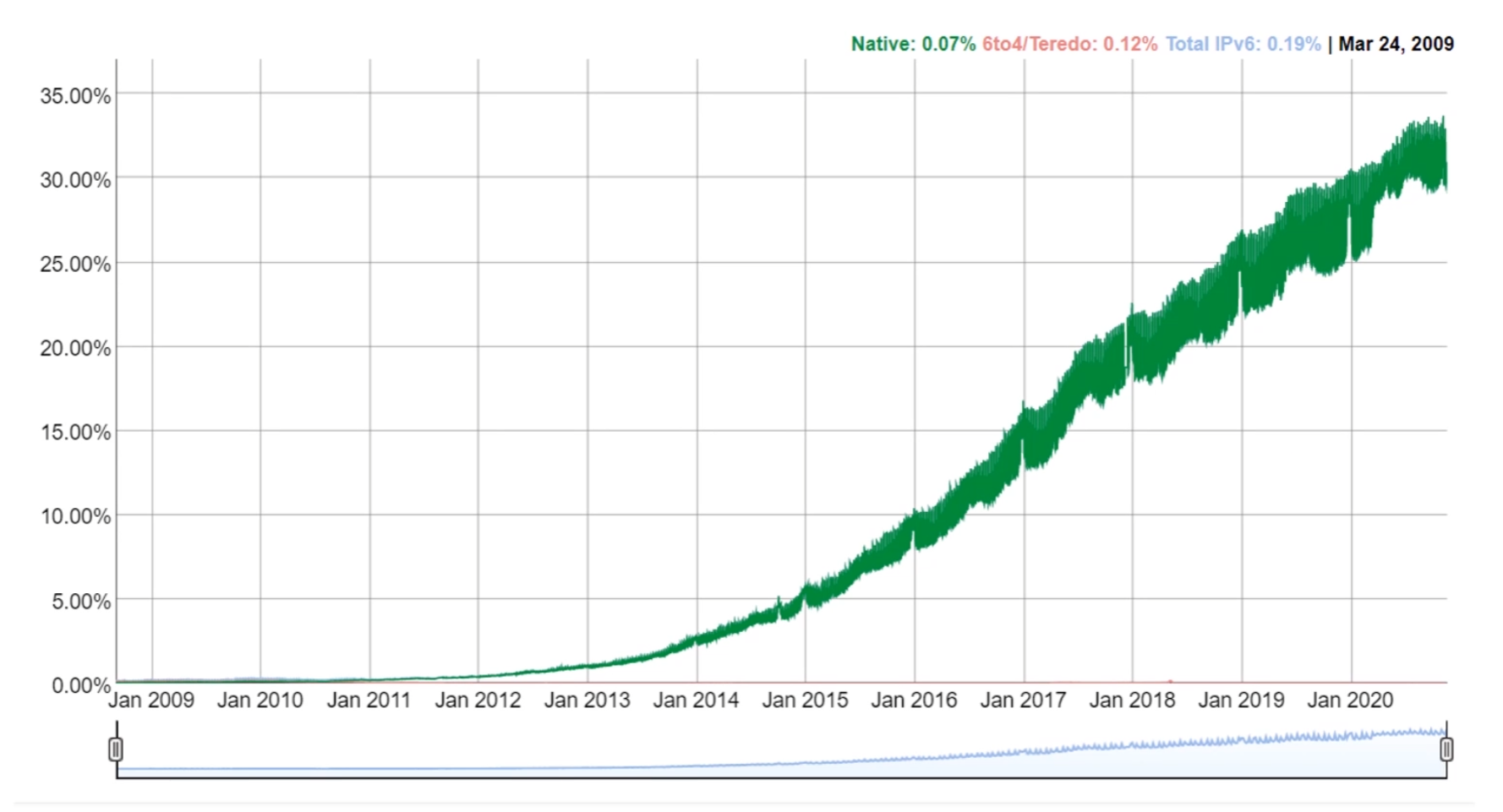
IPv4使用范围很大,平时工作中很容易遇到,比如开发场景、网络优化场景、解决线上问题场景等。相信你经常会碰到一些和 IP 协议相关的名词,比如说这一讲关联的面试题目:路由和寻址的区别是什么?
什么是 IP 协议?
IP 协议(Internet Protocol)是一个处于垄断地位的网络层协议。 IPv4 就是 IP 协议的第 4 个版本,是目前互联网的主要网络层协议。IPv4 为传输层提供 Host-To-Host 的能力,IPv4 需要底层数据链路层的支持。

IP 协议并不负责数据的可靠性。传输数据时,数据被切分成一个个数据封包。IP 协议上层的传输层协议会对数据进行一次拆分,IP 协议还会进一步进行拆分。进行两次拆分是为了适配底层的设备。
之前我们提到过, 数据在网络中交换(封包交换算法),并不需要预先建立一个连接,而是任由数据在网络中传输,每个节点通过路由算法帮助数据封包选择下一个目的地。
这里再复习一下可靠性,可靠性保证数据无损地到达目的地。可靠性是 IP 协议上方的 Host-To-Host 协议保证的,比如 TCP 协议通过应答机制、窗口等保证数据的可靠性。 IP 协议自身不能保证可靠性。比如 IP 协议可能会遇到下面这几个问题:
- 封包损坏(数据传输过程中被损坏);
- 丢包(数据发送过程中丢失);
- 重发(数据被重发,比如中间设备通过 2 个路径传递数据);
- 乱序(到达目的地时数据和发送数据不一致)。
但是 IP 协议并不会去处理这些问题,因为网络层只专注解决网络层的问题, 而且不同特性的应用在不同场景下需要解决的问题不一样。对于网络层来说,这里主要有 3 个问题要解决:
- 延迟
- 吞吐量
- 丢包率
这三个是鱼和熊掌不能兼得,我们后续会讨论。
另外,IP 协议目前主要有两种架构,一种是 IPv4,是目前应用最广泛的互联网协议;另一种是 IPv6,目前世界各地正在积极地部署 IPv6。这块我们最后讨论。
IP 协议的工作原理
IP 协议接收 IP 协议上方的 Host-To-Host 协议传来的数据,然后进行拆分,这个能力叫作分片(Fragmentation)。然后 IP 协议为每个片段(Fragment)增加一个 IP 头(Header),组成一个IP 封包(Datagram)。之后,IP 协议调用底层的局域网(数据链路层)传送数据。最后 IP 协议通过寻址和路由能力最终把封包送达目的地。接下来为你讲述完整的过程。
分片(Fragmentation)
分片就是把数据切分成片。 IP 协议通过它下层的局域网(链路层)协议传输数据,因此需要适配底层传输网络的传输能力。数据太大通常就不适合底层网络传输,这就需要把大的数据切片。 当然也可能选择不切片,IP 协议提供了一个能力就是把封包标记为不切片,当底层网络看到不切片的封包,又没有能力传输的时候,就会丢弃这个封包。你要注意,在网络环境中往往存在多条路径,一条路径断了,说不定其他路径可以连通。
增加协议头(IP Header)
切片完成之后,IP 协议会为每个切片(数据封包 Datagram)增加一个协议头。一个 IPv4 的协议头看上去就是如下图所示的样子:
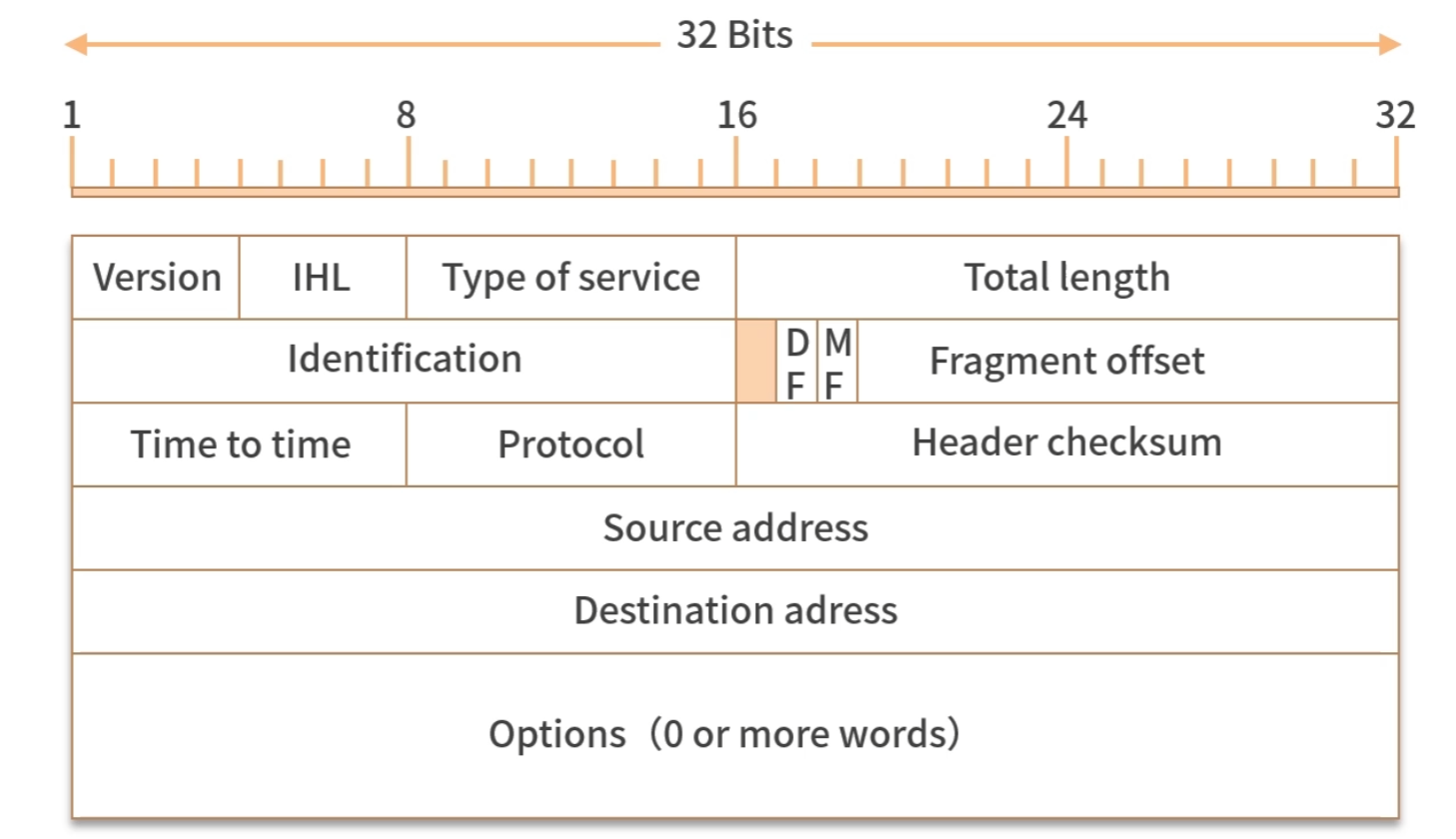
其中分成 4 个部分。
- 最重要的是原地址和目标地址。IPv4 的地址是 4 组 8 位的数字,总共是 32 位。具体地址的作用我们在下面的“寻址部分”介绍。
- Type Of Service 服务的类型,是为了响应不同的用户诉求,用来选择延迟、吞吐量和丢包率之间的关系。关于这块知识,本讲后半部分就会分析。
- IHL(Internet Header Length)用来描述 IP 协议头的大小。所以 IP 协议头的大小是可变的。IHL 只有 4 位,最大值 1111 = 15。最大是 15 个双字(15*4 字节 = 60 字节)。
- Total Length 定义报文(封包 Datagram)的长度。
- Identification(报文的 ID),发送方分配,代表顺序。
- Fragment offset 描述要不要分包(拆分),以及如何拆分。
- Time To Live 描述封包存活的时间。因此每个 IP 封包发送出去后,就开始销毁倒计时。如果倒计时为 0,就会销毁。比如中间的路由器看到一个 TTL 为 0 的封包,就直接丢弃。
- Protocol 是描述上层的协议,比如 TCP = 6,UDP = 17。
- Options 代表可选项。
- Checksum 用来检验封包的正确性,具体原理我们在“05 | UDP 协议:TCP 协议和 UDP 协议的优势和劣势?”中已经介绍过了,如果 Checksum 对不上,就需要选择丢弃这个封包。
“鱼和熊掌”不能兼得——延迟、吞吐量、丢包率
上面我们看到 IPv4 协议中提供了一个叫作 Type of Service(服务类型)的字段。这个字段是为了在延迟、吞吐量和丢包率三者间选择。
延迟(latency)
延迟指的是 1 bit 的数据从网络的一个终端传送到另一个终端需要的时间。这个时间包括在发送端准备发送的时间、排队发送的时间、发送数据的时间、数据传输的时间等。
吞吐量(Throughput)
吞吐量指单位时间内可以传输的平均数据量。比如用 bit/s 作为单位,就是 bps。吞吐量和延迟没有联系,比如延迟很高的网络,有可能吞吐量很高。可以类比成水管很大流速很慢,对比水管很细流速很快,这两种情况,最终流量可以是相等的。
丢包率(Packet loss)
丢表率指发送出去的封包没有到达目的地的比例。 在最大流速确定的网络中,丢表率会直接影响吞吐量。
我们的网络有时候需要低延迟,比如玩一款 RTS 游戏或者 Moba 游戏,这种时候延迟非常重要。另外如果把延迟看作一个平均指标,丢包也会影响延迟——一个包丢了,需要重发。而有的应用需要高吞吐量,延迟不是很重要,比如说网盘下载文件。大部分应用期望丢包不能太严重,比如语音电话,少量丢包还能听清,大量丢包就麻烦了,根本听不清对方说什么。严格希望不丢包的应用比较少,只有极特殊的网络控制管理场景,才需要在互联网层要求不丢包。
当然这三个条件,通常不能同时满足。如果同时追求延迟、吞吐量、丢包率,那么对网络设备的要求就会非常高,说白了就会非常贵。因此 IP 协议头中的 Type of Service 字段里,有以下 4 种主要的类型可以选择:
- 低延迟
- 高吞吐量
- 低丢包率
- 低成本
寻址(Addressing)
地址想要表达的是一个东西在哪里。寻址要做的就是:给一个地址,然后找到这个东西。IPv4 协议的寻址过程是逐级寻址。
IPv4 地址
IPv4 地址是 4 个 8 位(Octet)排列而成,总共可以编址 43 亿个地址。
比如 103.16.3.1 就是一个合法的 Ipv4 地址。4 组数字用.分开,是为了让人可读,实际上在内存和传输过程中,就是直接用 32 位。
寻址过程
寻址就是如何根据 IP 地址找到设备。因为 IPv4 的世界中,网络是一个树状模型。顶层有多个平行的网络,每个网络有自己的网络号。然后顶层网络下方又有多个子网,子网下方还有子网,最后才是设备。
IP 协议的寻址过程需要逐级找到网络,最后定位设备。下面我们具体分析下这个过程。

当然子网掩码也不一定都是255,比如这个子网掩码255.240.0.0也是可以的。但通常我们把 IPv4 的网络分成这样 4 层。
路由(Routing)
在寻址过程中,数据总是存于某个局域网中。如果目的地在局域网中,就可以直接定位到设备了。如果目的地不在局域网中,这个时候,就需再去往其他网络。
由于网络和网络间是网关在连接,因此如果目的地 IP 不在局域网中,就需要为 IP 封包选择通往下一个网络的路径,其实就是选择其中一个网关。你可能会问:网关有多个吗?如果一个网络和多个网络接壤,那自然需要多个网关了。下图中,路由器在选择 IP 封包下一个应该是去往哪个 Gateway?
假如,我们要为 IP 地址 14.215.177.38 寻址,当前路由器所在的网络的编号是16.0.0.0。那么我们就需要知道去往 14.0.0.0 网络的 Gateway IP 地址。
如果你在当前网络中用route查看路由表,可能可以看到一条下面这样的记录。
- Destination:14.0.0.0
- Gateway:16.12.1.100
- Mask:255.0.0.0
- Iface:16.12.1.1
这条记录就说明如果你要去往 14.0.0.0 网络,IP 地址 14.215.177.38 先要和 255.0.0.0 进行位运算,然后再查表,看到 14.0.0.0,得知去往 Gateway 的网卡(IFace)是 16.12.1.1。
当封包去向下一个节点后,会进入新的路由节点,然后会继续上述路由过程,直到最终定位到设备。
总结
这一讲我们学习了 IP 协议和 IP 协议的工作原理。首先 IP 协议会进行分片,将上游数据拆成一个个的封包(Datagram),然后为封包增加 IP 头部。封包发送出去后,就开始了寻址过程。寻址就是找到 IP 地址对应的设备。在局域网内,如果找不到设备,就需要路由。路由就是找到数据应该往哪里发送。最后通过层层路由定位到具体的设备。
路由和寻址的区别是什么?
【解析】寻址(Addressing)就是通过地址找设备。和现实生活中的寻址是一样的,比如根据地址找到一个公寓。在 IPv4 协议中,寻址找到的是一个设备所在的位置。
路由(Routing)本质是路径的选择。就好像知道地址,但是到了每个十字路口,还需要选择具体的路径。
所以,要做路由,就必须能够理解地址,也就是需要借助寻址的能力。要通过寻址找到最终的设备,又要借助路由在每个节点选择数据传输的线路。因此,路由和寻址,是相辅相成的关系。
Tunnel 技术是什么?
IPv4 用 32 位整数描述地址,最多只能支持 43 亿设备,显然是不够用的,这也被称作 IP 地址耗尽问题。
为了解决这个问题,有一种可行的方法是拆分子网。拆分子网,会带来很多问题,比如说内外网数据交互,需要网络地址转换协议(NAT 协议),增加传输成本。再比如说,多级网络会增加数据的路由和传输链路,降低网络的速度。理想的状态当然是所有设备在一个网络中,互相可以通过地址访问。
为了解决这个问题,1998 年互联网工程工作小组推出了全新款的 IP 协议——IPv6 协议。但是目前 IPv6 的普及程度还不够高,2019 年据中国互联网络信息中心(CNNIC)统计,IPv6 协议目前在我国普及率为 60%,已经位居世界首位。
既然不能做到完全普及,也就引出了本讲关联的一道面试题目:什么是 Tunnel 技术?下面请你带着这个问题,开启今天的学习吧!
IPv4 和 IPv6 相似点
IPv6 的工作原理和 IPv4 类似,分成切片(Segmentation)、增加封包头、路由(寻址)这样几个阶段去工作。IPv6 同样接收上方主机到主机(Host-to-Host)协议传递来的数据,比如一个 TCP 段(Segment),然后将 TCP 段再次切片做成一个个的 IPv6 封包(Datagram or Packet),再调用底层局域网能力(数据链路层)传输数据。具体的过程如下图所示:
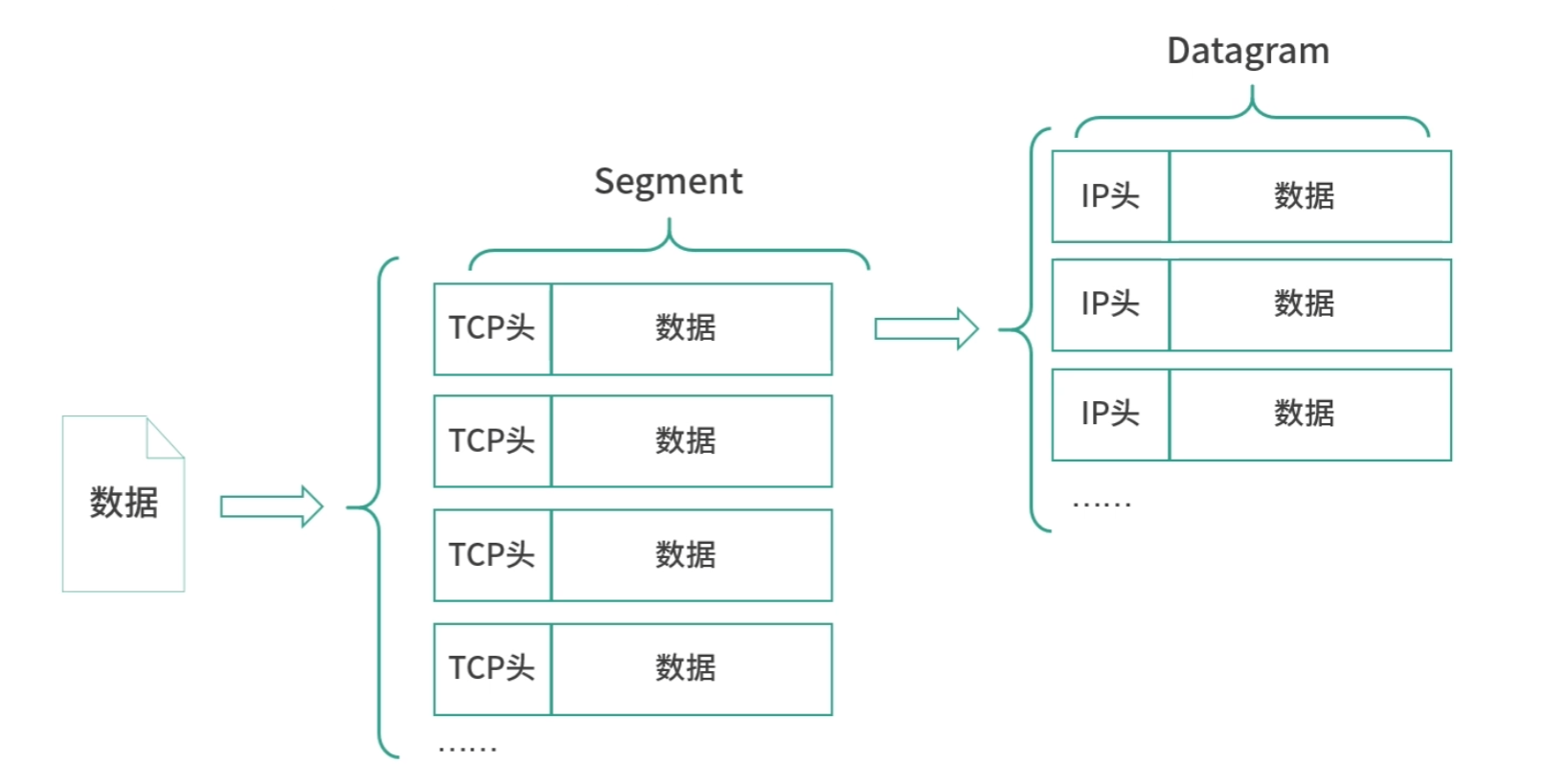
作为网络层协议的 IPv6,最核心的能力是确保数据可以从发送主机到达接收主机。因此,和 IPv4 类似,IPv6同样需要定义地址的格式,以及路由算法如何工作。
IPv6 地址
接下来我们重点说说地址格式的区别。
IPv4 的地址是 4 个 8 位(octet),总共 32 位。 IPv6 的地址是 8 个 16 位(hextet),总共 128 位。从这个设计来看,IPv6 可以支持的地址数量是 IPv4 的很多倍。就算将 IPv6 的地址分给每个人,每个人拥有的地址数量,依旧是今天总地址数量的很多倍。
格式上,IPv4 的地址用.分割,如103.28.7.35。每一个是 8 位,用 0-255 的数字表示。
IPv6 的地址用:分割,如0123:4567:89ab:cdef:0123:4567:89ab:cdef,总共 8 个 16 位的数字,通常用 16 进制表示。
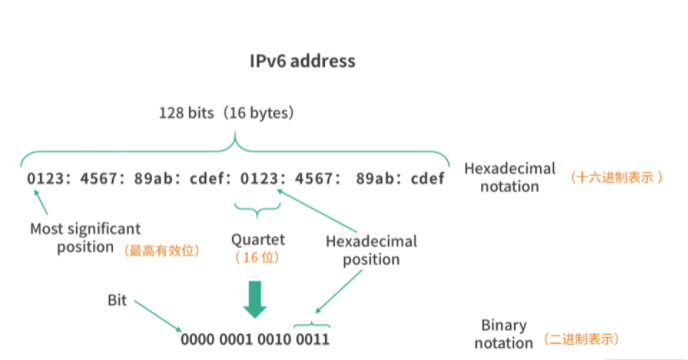
- Hexadecimal notation:十六进制表示
- Quartet:16 位
- Most significant:最高有效位
- Binary notation:二进制表示
::只能出现一次,相当于省略了若干组0000。比如说1111::2222相当于中间省略了 6 组0000。为什么不能出现两个::呢?因为如果有两个::,就会对省略的0000的位置产生歧义。比如说1111::2222:3333,你就不知道究竟0000在1111::2222和2222::3333是怎么分布的。
开头的 0 也可以简写,就变成如下的样子:
1 | 123:4567::123:4567:0:cdef |
还有一种情况我们想要后面部分都填0,比如说3c4d::/16,这个代表只有前16位有数据,后面是0;1234:5878:abcd/64代表只有左边64位有数据,后面是 0;再比如ff00/8,只有左边 8 位是有数据的。
IPv6 的寻址
接下来我们讨论下寻址,和 IPv4 相同,寻址的目的是找到设备,以及规划到设备途经的路径。和 IPv4 相同,IPv6寻址最核心的内容就是要对网络进行划分。IPv6 地址很充裕,因此对网络的划分和 IPv4 有很显著的差异。
IPv6 的寻址分成了几种类型:
- 全局单播寻址(和 IPv4 地址作用差不多,在互联网中通过地址查找一个设备,简单来说,单播就是 1 对 1);
- 本地单播(类似 IPv4 里的一个内部网络,要求地址必须以
fe80开头,类似我们 IPv4 中127开头的地址); - 分组多播(Group Multicast),类似今天我们说的广播,将消息发送给多个接收者;
- 任意播(Anycast),这个方式比较特殊,接下来我们会详细讲解。
全局单播
全局单播,就是将消息从一个设备传到另一个设备,这和 IPv4 发送/接收消息大同小异。而全局单播地址,目标就是定位网络中的设备,这个地址和 IPv4 的地址作用相同,只不过格式略有差异。总的来说,IPv6 地址太多,因此不再需要子网掩码,而是直接将 IPv6 的地址分区即可。
在实现全局单播时,IPv6 地址通常分成 3 个部分:
- 站点前缀(Site Prefix)48bit,一般是由 ISP(Internet Service Providor,运营商)或者RIR(Regional Internet Registry, 地区性互联网注册机构),RIR 将 IP 地址分配给运营商;
- 子网号(Subnet ID),16bit,用于站点内部区分子网;
- 接口号(Interface ID), 64bit,用于站点内部区分设备。
因此 IPv6 也是一个树状结构,站点前缀需要一定资质,子网号和接口号内部定义。IPv6 的寻址过程就是先通过站点前缀找到站点,然后追踪子网,再找到接口(也就是设备的网卡)。
从上面全局单播的分区,我们可以看出,IPv6 分给站点的地址非常多。一个站点,有 16bit 的子网,相当于 65535 个子网;每个子网中,还可以用 64 位整数表示设备。
本地单播
理论上,虽然 IPv6 可以将所有的设备都连入一个网络。但在实际场景中,很多公司还是需要一个内部网络的。这种情况在 IPv6 的设计中属于局域网络。
在局域网络中,实现设备到设备的通信,就是本地单播。IPv6 的本地单播地址组成如下图所示:
这种协议比较简单,本地单播地址必须以fe80开头,后面 64 位的 0,然后接上 54 位的设备编号。上图中的 Interface 可以理解成网络接口,其实就是网卡。
分组多播
有时候,我们需要实现广播。所谓广播,就是将消息同时发送给多个接收者。
IPv6 中设计了分组多播,来实现广播的能力。当 IP 地址以 8 个 1 开头,也就是ff00开头,后面会跟上一个分组的编号时,就是在进行分组多播。
这个时候,我们需要一个广播设备,在这个设备中已经定义了这些分组编号,并且拥有分组下所有设备的清单,这个广播设备会帮助我们将消息发送给对应分组下的所有设备。
任意播(Anycast)
任意播,本质是将消息发送给多个接收方,并选择一条最优的路径。这样说有点抽象,接下来我具体解释一下。
比如说在一个网络中有多个授时服务,这些授时服务都共享了一个任播地址。当一个客户端想要获取时间,就可以将请求发送到这个任播地址。客户端的请求扩散出去后,可能会找到授时服务中的一个或者多个,但是距离最近的往往会先被发现。这个时候,客户端就使用它第一次收到的授时信息修正自己的时间。
IPv6 和 IPv4 的兼容
目前 IPv6 还没有完全普及,大部分知名的网站都是同时支持 IPv6 和 IPv4。这个时候我们可以分成 2 种情况讨论:
- 一个 IPv4 的网络和一个 IPv6 的网络通信;
- 一个 IPv6 的网络和一个 IPv6 的网络通信,但是中间需要经过一个 IPv4 的网络。
下面我们具体分析一下。
情况 1:IPv4 网络和 IPv6 网络通信
例如一个 IPv6 的客户端,想要访问 IPv4 的服务器,步骤如下图所示:
- 客户端通过 DNS64 服务器查询 AAAA 记录。DNS64 是国际互联网工程任务组(IETF)提供的一种解决 IPv4 和 IPv6 兼容问题的 DNS 服务。这个 DNS 查询服务会把 IPv4 地址和 IPv6 地址同时返回。
- DNS64 服务器返回含 IPv4 地址的 AAAA 记录。
- 客户端将对应的 IPv4 地址请求发送给一个 NAT64 路由器
- 由这个 NAT64 路由器将 IPv6 地址转换为 IPv4 地址,从而访问 IPv4 网络,并收集结果。
- 消息返回到客户端。
情况 2:两个 IPv6 网络被 IPv4 隔离
这种情况在普及 IPv6 的过程中比较常见,IPv6 的网络一开始是一个个孤岛,IPv6 网络需要通信,就需要一些特别的手段。
不知道你有没有联想到坐火车穿越隧道的感觉,连接两个孤岛 IPv6 网络,其实就是在 IPv4 网络中建立一条隧道。如下图所示:
隧道的本质就是在两个 IPv6 的网络出口网关处,实现一段地址转换的程序。
总结
总结下,IPv6 解决的是地址耗尽的问题。因为解决了地址耗尽的问题,所以很多其他问题也得到了解决,比如说减少了子网,更小的封包头部体积,最终提升了性能等。
除了本讲介绍的内容,下一讲你还会从局域网络中看到更多对 NAT 技术的解读、对路由器的作用的探讨。随着 IPv6 彻底普及,你可以想象一下,运营商可以给到每个家庭一大批固定的 IP 地址,发布网页似乎可以利用家庭服务器……总之,林䭽也不知道最终会发生什么,我也对未来充满了期待,让我们拭目以待吧。
那么,通过这一讲的学习,你可以尝试回答本讲关联的面试题目:Tunnel 技术是什么了吗?
【解析】Tunnel 就是隧道,这和现实中的隧道是很相似的。隧道不是只有一辆车通过,而是每天都有大量的车辆来来往往。两个网络,用隧道连接,位于两个网络中的设备通信,都可以使用这个隧道。隧道是两个网络间用程序定义的一种通道。具体来说,如果两个 IPv6 网络被 IPv4 分隔开,那么两个 IPv6 网络的出口处(和 IPv4 网络的网关处)就可以用程序(或硬件)实现一个隧道,方便两个网络中设备的通信。
IPv6与IPv4的区别主要有以下几点:1.IPv6的地址空间更大。IPv4中规定IP地址长度为32,即有2^32-1个地址;而IPv6中IP地址的长度为128,即有2^128-1个地址。夸张点说就是,如果IPV6被广泛应用以后,全世界的每一粒沙子都会有相对应的一个IP地址。2.IPv6的路由表更小。IPv6的地址分配一开始就遵循聚类(Aggregation)的原则,这使得路由器能在路由表中用一条记录(Entry)表示一片子网,大大减小了路由器中路由表的长度,提高了路由器转发数据包的速度。3.IPv6的组播支持以及对流的支持增强。这使得网络上的多媒体应用有了长足发展的机会,为服务质量控制提供了良好的网络平台。4.IPv6加入了对自动配置的支持。这是对DHCP协议的改进和扩展,使得网络(尤其是局域网)的管理更加方便和快捷。5.IPv6具有更高的安全性。在使用IPv6网络中,用户可以对网络层的数据进行加密并对IP报文进行校验,这极大地增强了网络安全
NAT 是如何工作的?
数据到王者荣耀服务器可以通过寻址和路由找到目的地,但是数据从王者荣耀服务器回来的时候,王者荣耀服务器如何知道192.168开头的地址应该如何寻址呢?
要想回答这个问题,就涉及网络地址转换协议(NAT 协议)。下面请你带着这个问题,开启今天的学习吧。
内部网络和外部网络
对一个组织、机构、家庭来说,我们通常把内部网络称为局域网,外部网络就叫作外网。下图是一个公司多个部门的网络架构。
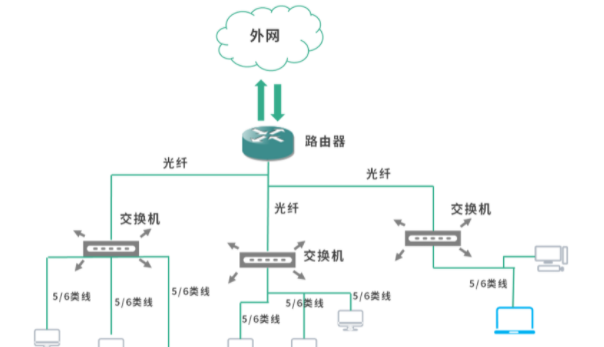
局域网数据交换(MAC 地址)
接下来我们讨论下同一个局域网中的设备如何交换消息。
首先,我们先明确一个概念,设备间通信的本质其实是设备拥有的网络接口(网卡)间的通信。为了区别每个网络接口,互联网工程任务组(IETF)要求每个设备拥有一个唯一的编号,这个就是 MAC 地址。
你可能会问:IP 地址不也是唯一的吗?其实不然,一旦设备更换位置,比如你把你的电脑从北京邮寄的广州,那么 IP 地址就变了,而电脑网卡的 MAC 地址不会发生变化。总的来说,IP 地址更像现实生活中的地址,而 MAC 地址更像你的身份证号。
然后,我们再明确另一个基本的概念。在一个局域网中,我们不可以将消息从一个接口(网卡)发送到另一个接口(网卡),而是要通过交换机。为什么是这样呢?因为两个网卡间没有线啊!所以数据交换,必须经过交换机,毕竟线路都是由网卡连接交换机的。
总结下,数据的发送方,将自己的 MAC 地址、目的地 MAC 地址,以及数据作为一个分组(Packet),也称作 Frame 或者封包,发送给交换机。交换机再根据目的地 MAC 地址,将数据转发到目的地的网络接口(网卡)。
最后一个问题,你可能问,这个分组或者 Frame,是不是 IP 协议的分组呢?——不是,这里提到的是链路层的数据交换,它支持 IP 协议工作,是网络层的底层。所以,如果 IP 协议要传输数据,就要将数据转换成为链路层的分组,然后才可以在链路层传输。
链路层分组大小受限于链路层的网络设备、线路以及使用了链路层协议的设计。你有时候可能会看到 MTU 这个缩写词,它指的是 Maximun Transmission Unit,最大传输单元,意思是链路层网络允许的最大传输数据分组的大小。因此 IP 协议要根据 MTU 拆分封包。
之前在“04 | TCP 的稳定性:滑动窗口和流速控制是怎么回事?”介绍 TCP 协议滑动窗口的时候,还提到过一个词,叫作 MSS,这里我们复习下。MSS(Maximun Segment Size,最大段大小)是 TCP 段,或者称为 TCP 分组(TCP Packet)的最大大小。MSS 是传输层概念,MTU 是链路层概念。
1 | MTU = MSS + TCP Header + IP Header |
这个思路有一定道理,但是不对。先说说这个思路怎么来的,你可能会这么思考:TCP 传输数据大于 MSS,就拆包。每个封包加上 TCP Header ,之后经过 IP 协议,再加上 IP Header。于是这个加上 IP 头的分组(Packet)不能超过 MTU。固然这个思路很有道理,可惜是错的。因为 TCP 解决的是广域网的问题,MTU 是一个链路层的概念,要知道不同网络 MTU 是不同的,所以二者不可能产生关联。这也是为什么 IP 协议还可能会再拆包的原因。
地址解析协议(ARP)
上面我们讨论了 MAC 地址,链路层通过 MAC 地址定位网络接口(网卡)。在一个网络接口向另一个网络接口发送数据的时候,至少要提供这样 3 个字段:
- 源 MAC 地址
- 目标 MAC 地址
- 数据
这里我们一起再来思考一个问题,对于一个网络接口,它如何能知道目标接口的 MAC 地址呢?我们在使用传输层协议的时候,清楚地知道目的地的 IP 地址,但是我们不知道 MAC 地址。这个时候,就需要一个中间服务帮助根据 IP 地址找到 MAC 地址——这就是地址解析协议(Address Resolution Protocol,ARP)。
整个工作过程和 DNS 非常类似,如果一个网络接口已经知道目标 IP 地址对应的 MAC 地址了,它会将数据直接发送给交换机,交换机将数据转发给目的地,这个过程如下图所示:
那么如果网络接口不知道目的地地址呢?这个时候,地址解析协议就开始工作了。发送接口会发送一个广播查询给到交换机,交换机将查询转发给所有接口。
如果某个接口发现自己就是对方要查询的接口,则会将自己的 MAC 地址回传。接下来,会在交换机和发送接口的 ARP 表中,增加一个缓存条目。也就是说,接下来发送接口再次向 IP 地址 2.2.2.2 发送数据时,不需要再广播一次查询了。
前面提到这个过程和 DNS 非常相似,采用的是逐级缓存的设计减少 ARP 请求。发送接口先查询本地的 ARP 表,如果本地没有数据,然后广播 ARP 查询。这个时候如果交换机中有数据,那么查询交换机的 ARP 表;如果交换机中没有数据,才去广播消息给其他接口。注意,ARP 表是一种缓存,也要考虑缓存的设计。通常缓存的设计要考虑缓存的失效时间、更新策略、数据结构等。
比如可以考虑用 TTL(Time To Live)的设计,为每个缓存条目增加一个失效时间。另外,更新策略可以考虑利用老化(Aging)算法模拟 LRU。
最后请你思考路由器和交换机的异同点。不知道你有没有在网上订购过家用无线路由器,通常这种家用设备也会提供局域网,具备交换机的能力。同时,这种设备又具有路由器的能力。所以,很多同学可能会分不清路由器和交换机。
总的来说,家用的路由器,也具备交换机的功能。但是当 ARP 表很大的时候,就需要专门的、能够承载大量网络接口的交换设备。就好比,如果用数组实现 ARP 表,数据量小的时候,遍历即可;但如果数据量大的话,就需要设计更高效的查询结构和设计缓存。
详细的缓存设计原理的介绍,可以参考《重学操作系统》专栏中关于 CPU 缓存的设计,以及 MMU 中 TLB 的设计的内容,分别在以下 3 讲:
连接内网
有时候,公司内部有多个子网。这个时候一个子网如果要访问另一个子网,就需要通过路由器。
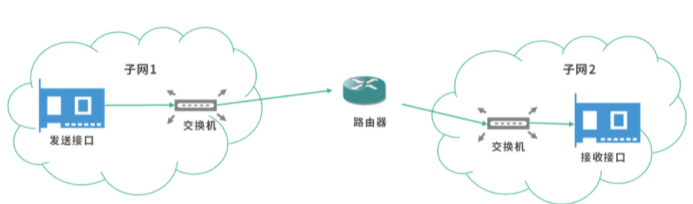
也就是说,图中的路由器,其实充当了两个子网通信的桥梁。在上述过程中,发送接口不能直接通过 MAC 地址发送数据到接收接口,因为子网 1 的交换机不知道子网 2 的接口。这个时候,发送接口需要通过 IP 协议,将数据发送到路由器,再由路由器转发信息到子网 2 的交换机。这里提一个问题,子网 2 的交换机如何根据 IP 地址找到接收接口呢?答案是通过查询 ARP 表。
连接外网(网络地址转换技术,NAT)
最后我们讨论下连接外网的问题。
IPv4 协议因为存在网络地址耗尽的问题,不能为一个公司提供足够的地址,因此内网 IP 可能会和外网重复。比如内网 IP 地址192.168.0.1发送信息给22.22.22.22,这个时候,其实是跨着网络的。
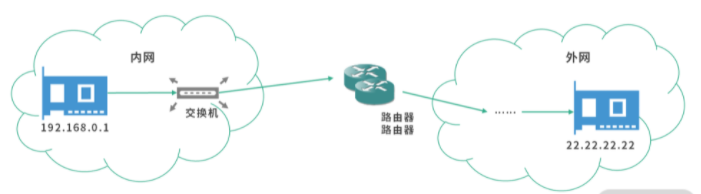
跨网络必然会通过多次路由,最终将消息转发到目的地。但是这里存在一个问题,寻找的目标 IP 地址22.22.22.22是一个公网 IP,可以通过正常的寻址 + 路由算法定位。当22.22.22.22寻找192.168.0.1的时候,是寻找一个私网 IP,这个时候是找不到的。解决方案就是网络地址转换技术(Network Address Translation)。

NAT 技术转换的是 IP 地址,私有 IP 通过 NAT 转换为公网 IP 发送到服务器。服务器的响应,通过 NAT 转换为私有 IP,返回给客户端。通过这种方式,就解决了内网和外网的通信问题。
总结
总结一下,链路层发送数据靠的是 MAC 地址,MAC 地址就好像人的身份证一样。局域网中,数据不可能从一个终端直达另一个终端,而是必须经过交换机交换。交换机也叫作链路层交换机,它的工作就是不断接收数据,然后转发数据。通常意义上,交换机不具有路由功能,路由器往往具有交换功能。但是往往路由器交换的效率,不如交换机。已知 IP 地址,找到 MAC 地址的协议,叫作地址解析协议(ARP)。
网络和网络的衔接,必须有路由器(或者等价的设备)。一个网络的设备不能直接发送链路层分组给另一个网络的设备,而是需要通过 IP 协议让路由器转发。
那么,通过这一讲的学习,你可以来回答本讲关联的面试题目:网络地址转换协议是如何工作的?
【解析】网络地址解析协议(NAT)解决的是内外网通信的问题。NAT 通常发生在内网和外网衔接的路由器中,由路由器中的 NAT 模块提供网络地址转换能力。从设计上看,NAT 最核心的能力,就是能够将内网中某个 IP 地址映射到外网 IP,然后再把数据发送给外网的服务器。当服务器返回数据的时候,NAT 又能够准确地判断外网服务器的数据返回给哪个内网 IP。
你可以思考下 NAT 是如何做到这点的呢?需要做两件事。
- NAT 需要作为一个中间层替换 IP 地址。 发送的时候,NAT 替换源 IP 地址(也就是将内网 IP 替换为出口 IP);接收的时候,NAT 替换目标 IP 地址(也就是将出口 IP 替换回内网 IP 地址)。
- NAT 需要缓存内网 IP 地址和出口 IP 地址 + 端口的对应关系。也就是说,发送的时候,NAT 要为每个替换的内网 IP 地址分配不同的端口,确保出口 IP 地址+ 端口的唯一性,这样当服务器返回数据的时候,就可以根据出口 IP 地址 + 端口找到内网 IP。
这里不去讨论更加详细复杂的情况,NAT技术又细分为静态动态等等几个情况。
如何进行 TCP 抓包调试?
这一讲给你带来了一个网络调试工具——Wireshark。Wireshark 是世界上应用最广泛的网络协议分析器,它让我们在微观层面上看到整个网络正在发生的事情。
Wireshark 本身是一个开源项目,所以也得到了很多志愿者的支持。同时,Wireshark 具有丰富的功能集,包括:
- 深入检查数百个协议,并不断添加更多协议;
- 实时捕获和离线分析;
- 支持 Windows、Linux、macOS、Solaris、FreeBSD、NetBSD,以及许多其他平台;
- 提供 GUI 浏览,也可以通过 TTY;
- 支持 VOIP;
- 支持 Gzip;
- 支持 IPSec。
- ……
是不是觉得Wireshark非常强大?无论你从事哪种开发工作,它都可以帮到你,因此也是面试经常考察的内容。比如本讲关联的面试题:如何进行 TCP 抓包和调试?下面请你带着问题,开始今天的学习吧。
注:你可以到 Wireshark 的主页:https://www.wireshark.org/download.html下载 Wireshark。
如果你是一个黑客、网络安全工程师,或者你的服务总是不稳定,就需要排查,那么你会如何 hack 这些网络连接、网络接口以及分析网络接口的封包呢?
接口列表
Whireshark 可以帮你看到整个网络交通情况,也可以帮你深入了解每个封包。而且 Whireshark 在 macOS、Linux、Windows 上的操作都是一致的,打开 Wireshark 会先看到如下图所示的一个选择网络接口的界面。

我们要做的第一件事情就是选择一个网络接口(Network Interface)。Linux 下可以使用ifconfig指令看到所有的网络接口,Windows 下则使用 ipconfig。可以看到,上图中有很多网络接口,目前我教学这台机器上,连接路由器的接口是以太网 2。另外可以看到,我的机器上还有VMware的虚拟网络接口(你的机器可能和我的机器显示的不一样)。
开启捕获功能
选择好接口之后,点击左上角的按钮就可以开启捕获,开启后看到的是一个个数据条目。
因为整个网络的数据非常多,大量的应用都在使用网络,你会看到非常多数据条目,每个条目是一次数据的发送或者接收。如下图所示:
以下是具体捕获到的内容:
- 序号(No.)是 Wireshark 分配的一个从捕获开始的编号。
- 时间(Time)是从捕获开始过去的时间戳,具体可以在视图中设置,比如可以设置成中文的年月日等。这里有很多配置需要你自己摸索一下,我就不详细介绍了。
- 源地址和目标地址(Source 和 Destination)是 IP 协议,注意这里有 IPv6 的地址,也有 IPV4 的地址。
- 协议可能有很多种,比如 TCP/UDP/ICMP 等,ICMP 是 IP 协议之上搭建的一个消息控制协议(Internet Control Message Protocol),比如 Ping 用的就是 ICMP;还有 ARP 协议(Address Resolution Protocol)用来在局域网广播自己的 MAC 地址。
- Length 是消息的长度(Bytes)。
- Info 是根据不同协议显示的数据,比如你可以看到在TCP 协议上看到Seq 和 ACK。这里的 Seq 和 ACK 已经简化过了,正常情况下是一个大随机数,Whireshark 帮你共同减去了一个初始值。
观察 TCP 协议
如果你具体选择一个 TCP 协议的捕获,可以看到如下图所示的内容:

然后在这下面可以观察到详情内容:

我们可以从不同的层面来看这次捕获。从传输层看是 TCP 段;从网络层来看是 IP 封包;从链路层来看是 Frame。
点开不同层面观察这个 TCP 段,就可以获得对它更具体的认识,例如下图是从 TCP 层面理解这次捕获:
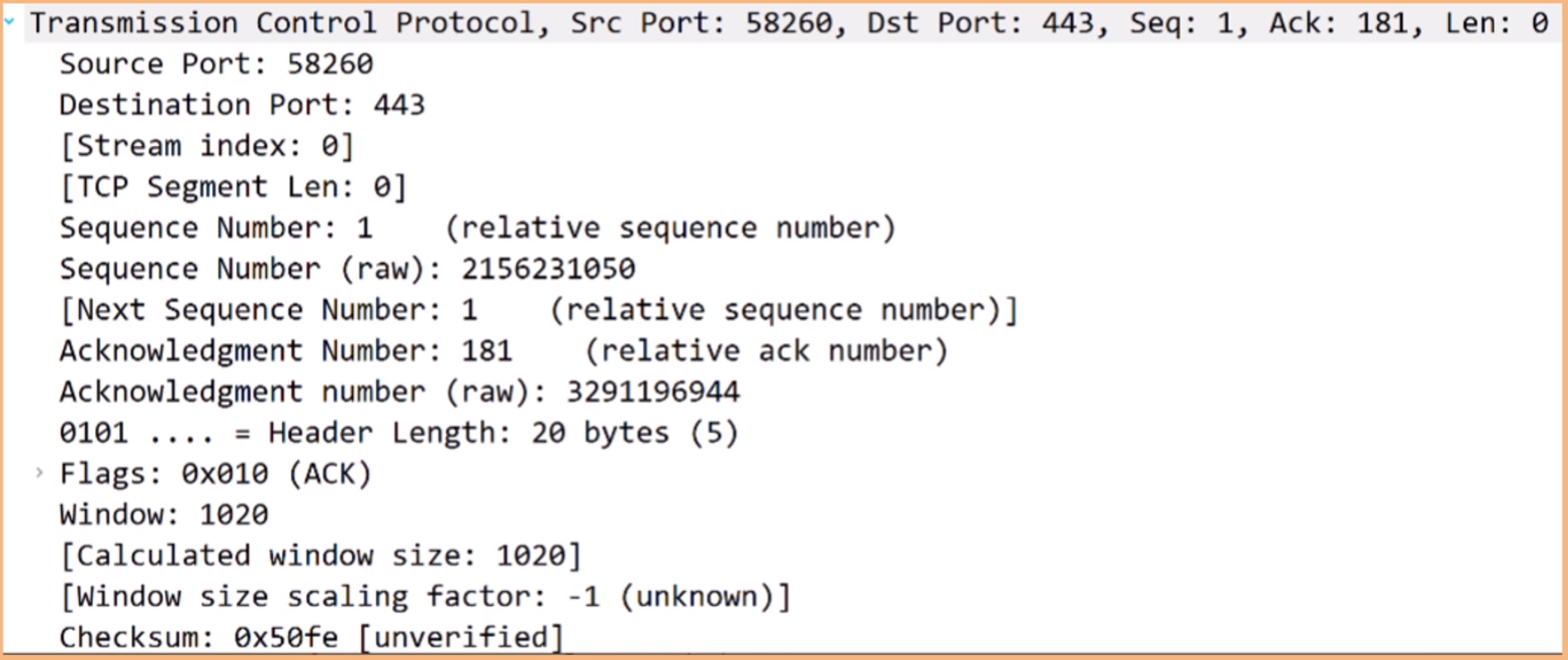
你可以看到这次捕获是一次 ACK(见 Flags)字段,从端口 58260 发往 443,那么大概率是 HTTPS 客户端给服务器的响应。
消息视图
如果你选中一条消息,下面会出现一个消息视图。还有一个二进制视图。二进制视图里面是数据的二进制形式,消息视图是对二进制形式的解读。
Whireshark 追溯的是最底层网卡传输的 Frame(帧),可以追溯到数据链路层。因此对二进制形式的解读,也就是我们的消息视图也要分层。因为对于同样的数据,不同层的解读是不同的。
- 最上面是 Frame 数据,主要是关注数据的收发时间和大小。
- 接着是数据链路层数据,关注的是设备间的传递。你可以在这里看到源 MAC 地址和目标 MAC 地址。
- 然后是网络层数据,IP 层数据。这里有 IP 地址(源 IP 地址和目标 IP 地址);也有头部的 Checksum(用来纠错的)。这里就不一一介绍了,你可以回到“06 | IPv4 协议:路由和寻址的区别是什么?”复习这块内容。
- 最下面是传输层数据。 也就是 TCP 协议。关注的是源端口,目标端口,Seq、ACK 等。
- 有的传输层上还有一个 TLS 协议,这是因为用 HTTPS 请求了数据。TLS 也是传输层。TLS 是建立在 TCP 之上,复用了 TCP 的逻辑。
观察 HTTP 协议
Wireshark 还可以用来观察其他的协议,比如说 HTTP 协议,下图是对 HTTP 协议的一次捕获:
可以看到,Wireshark 不仅仅捕获了应用层,还可以看到这次 HTTP 捕获对应的传输层、网络层和链路层数据。
过滤和筛选
Wireshark 还提供了捕获的过滤,我们只需要输入过滤条件,就可以只看符合条件的捕获。
比如我们想分析一次到百度的握手。首先开启捕获,然后在浏览器输入百度的网址,最后通过ping指令看下百度的 IP 地址,如下图所示:
看到IP 地址之后,我们在 Wireshark 中输入表达式,如下图所示:
这样看到的就是和百度关联的所有连接。上图中刚好是一次从建立 TCP 连接(3 次握手),到 HTTPS 协议传输握手的完整过程。你可以只看从192.168.1.5到14.215.177.39的请求。
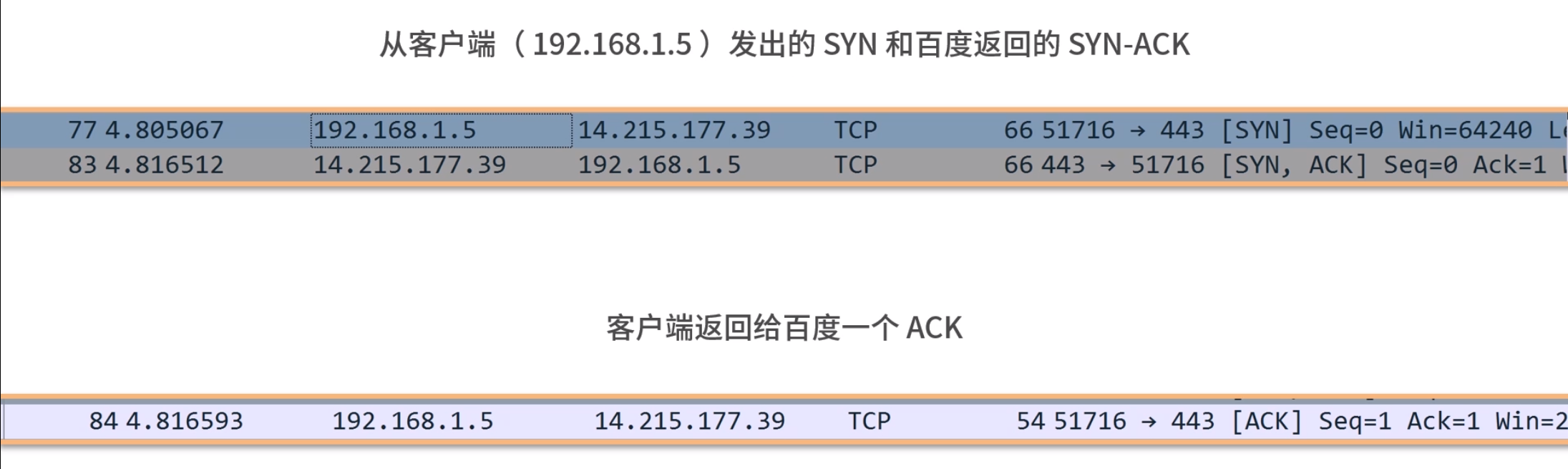




报文颜色
在抓包过程中,黑色报文代表各类报文错误;红色代表出现异常;其他颜色代表正常传输。
Wireshark 是个强大的工具,支持大量的协议。还有很多关于 Wireshark 的能力,希望你可以进一步探索,如下图中鼠标右键一次捕获,可以看到很多选项,都是可以深挖的。
模块二加餐
下面这几个地址 127.0.0.1, localhost, 0.0.0.0 有什么不同?
127.0.0.1是本地回环地址(loopback),发送到 loopback 的数据会被转发到本地应用。
localhost 指代的是本地计算机,用于访问绑定在 loopback 上的服务。localhost 是一个主机名,不仅仅可以指向 IPv4 的本地回环地址,也可以指向 IPv6 的本地回环地址 [::1]。
0.0.0.0是一个特殊目的 IP 地址,称作不可路由 IP 地址,它的用途会被特殊规定。通常情况下,当我们把一个服务绑定到0.0.0.0,相当于把服务绑定到任意的 IP 地址。比如一台服务器上有多个网卡,不同网卡连接不同的网络,如果服务绑定到 0.0.0.0 就可以保证服务在多个 IP 地址上都可以用。
IPv6 和 IPv4 究竟有哪些区别?
IPv6 和 IPv4 最核心的区别是地址空间大小不同。IPv6 用 128 位地址,解决了 IP 地址耗尽问题。因为地址空间大小不同,它们对地址的定义,对路由寻址策略都有显著的差异。
在路由寻址策略上,IPv6 消除了设备间地址冲突的问题,改变了划分子网的方式。在 IPv4 网络中,一个局域网往往会共享一个公网 IP,因此需要 NAT 协议和外网连接。
在划分子网的时候,IPv4 地址少,需要子网掩码来处理划分子网。IPv6 有充足的地址,因此不需要局域网共享外网 IP。也正因为 IPv6 地址多,可以直接将 IPv6 地址划分成站点、子网、设备,每个段都有充足的 IP 地址。
因为 IPv6 支持的 IP 地址数量大大上升,一个子网可以有 248 个 IP 地址,这个子网可能是公司网络、家庭网络等。这样 IP 地址的分配方式也发生了变化,IPv4 网络中设备分配 IP 地址的方式是中心化的,由 DHCP(动态主机协议)为局域网中的设备分配 IP 地址。而在 IPv6 网络中,因为 IP 地址很少发生冲突,可以由设备自己申请自己的 IP 地址。
另外因为 IPv6 中任何一个节点都可以是一个组播节点,这样就可以构造一个对等的网络,也就是可以支持在没有中心化的路由器,或者一个网络多个路由器的情况下工作。节点可以通过向周围节点类似打探消息的方式,发现更多的节点。这是一个配套 IPv6 的能力,叫作邻居发现(ND)。
IPv6 协议还需要 NAT 吗?
IPv6 解决了 IP 耗尽的问题,为机构、组织、公司、家庭等网络提供了充足的 IP 资源,从这个角度看是不是就不需要 NAT 协议了呢?
在没有 IPv6 之前,NAT 是 IP 资源耗尽的主流解决方案。在一个内网中的全部设备通过 NAT 协议共享一个外网的 IPv4 地址,是目前内外网对接的主要方式。IPv6 地址资源充足,可以给全球每个设备一个独立的地址。从这个角度看 IPv6 的确不需要 NAT 协议。
但是目前的情况,是 IPv6 网络还没有完全普及。尽管很多公司已经支持自己的互联网产品可以使用 IPv6 访问,但是公司内部员工使用的内部网络还是 IPv4。如果要连接 IPv6 和 IPv4 网络,仍然需要 NAT 协议(NAT64),这个协议可以让多个 IPv6 的设备共享一个 IPv4 的公网地址。
写一个 UDP 连接程序,然后用 Wireshark 抓包。
服务端程序:
1 | var socket = new DatagramSocket(8888); |
1 | var buf = "Hello".getBytes(); |
发现发送和接收的都是Datagram报文。而且服务端和客户端之间不需要建立连接。服务端可以通过读取客户端的地址区分客户端,客户端通过服务端地址和端口发送数据到服务端。
Socket 编程:epoll 为什么用红黑树?
从编程的角度来看,客户端将数据发送给在客户端侧的Socket 对象,然后客户端侧的 Socket 对象将数据发送给服务端侧的 Socket 对象。Socket 对象负责提供通信能力,并处理底层的 TCP 连接/UDP 连接。对服务端而言,每一个客户端接入,就会形成一个和客户端对应的 Socket 对象,如果服务器要读取客户端发送的信息,或者向客户端发送信息,就需要通过这个客户端 Socket 对象。
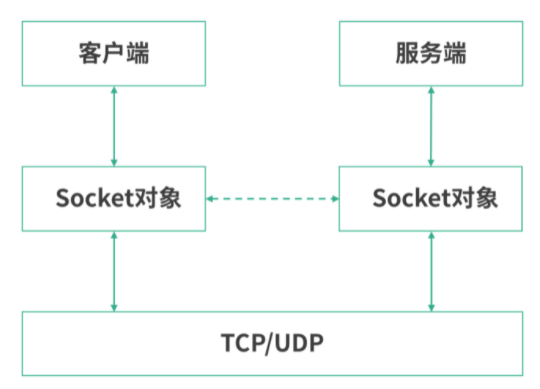
但是如果从另一个角度去分析,Socket 还是一种文件,准确来说是一种双向管道文件。什么是管道文件呢?管道会将一个程序的输出,导向另一个程序的输入。那么什么是双向管道文件呢?双向管道文件连接的程序是对等的,都可以作为输入和输出。
比如下面这段服务端侧程序:
1 | var serverSocket = new ServerSocket(); |
看起来我们创建的是一个服务端 Socket 对象,但如果单纯看这个对象,它又代表什么呢?如果我们理解成代表服务端本身合不合理呢——这可能会比较抽象,在服务端存在一个服务端 Socket。但如果我们从管道文件的层面去理解它,就会比较容易了。其一,这是一个文件;其二,它里面存的是所有客户端 Socket 文件的文件描述符。
当一个客户端连接到服务端的时候,操作系统就会创建一个客户端 Socket 的文件。然后操作系统将这个文件的文件描述符写入服务端程序创建的服务端 Socket 文件中。服务端 Socket 文件,是一个管道文件。如果读取这个文件的内容,就相当于从管道中取走了一个客户端文件描述符。
如上图所示,服务端 Socket 文件相当于一个客户端 Socket 的目录,线程可以通过 accept() 操作每次拿走一个客户端文件描述符。拿到客户端文件描述符,就相当于拿到了和客户端进行通信的接口。
前面我们提到 Socket 是一个双向的管道文件,当线程想要读取客户端传输来的数据时,就从客户端 Socket 文件中读取数据;当线程想要发送数据到客户端时,就向客户端 Socket 文件中写入数据。客户端 Socket 是一个双向管道,操作系统将客户端传来的数据写入这个管道,也将线程写入管道的数据发送到客户端。
有同学会说,那既然可以双向传送,这不就是两个单向管道被拼凑在了一起吗?这里具体的实现取决于操作系统,Linux 中的管道文件都是单向的,因此 Socket 文件是一种区别于原有操作系统管道的单独的实现。
总结下,Socket 首先是文件,存储的是数据。对服务端而言,分成服务端 Socket 文件和客户端 Socket 文件。服务端 Socket 文件存储的是客户端 Socket 文件描述符;客户端 Socket 文件存储的是传输的数据。读取客户端 Socket 文件,就是读取客户端发送来的数据;写入客户端文件,就是向客户端发送数据。对一个客户端而言, Socket 文件存储的是发送给服务端(或接收的)数据。
综上,Socket 首先是文件,在文件的基础上,又封装了一段程序,这段程序提供了 API 负责最终的数据传输。
服务端 Socket 的绑定
为了区分应用,对于一个服务端 Socket 文件,我们要设置它监听的端口。比如 Nginx 监听 80 端口、Node 监听 3000 端口、SSH 监听 22 端口、Tomcat 监听 8080 端口。端口监听不能冲突,不然客户端连接进来创建客户端 Socket 文件,文件描述符就不知道写入哪个服务端 Socket 文件了。这样操作系统就会把连接到不同端口的客户端分类,将客户端 Socket 文件描述符存到对应不同端口的服务端 Socket 文件中。
因此,服务端监听端口的本质,是将服务端 Socket 文件和端口绑定,这个操作也称为 bind。有时候我们不仅仅绑定端口,还需要绑定 IP 地址。这是因为有时候我们只想允许指定 IP 访问我们的服务端程序。
扫描和监听
对于一个服务端程序,可以定期扫描服务端 Socket 文件的变更,来了解有哪些客户端想要连接进来。如果在服务端 Socket 文件中读取到一个客户端的文件描述符,就可以将这个文件描述符实例化成一个 Socket 对象。
之后,服务端可以将这个 Socket 对象加入一个容器(集合),通过定期遍历所有的客户端 Socket 对象,查看背后 Socket 文件的状态,从而确定是否有新的数据从客户端传输过来。
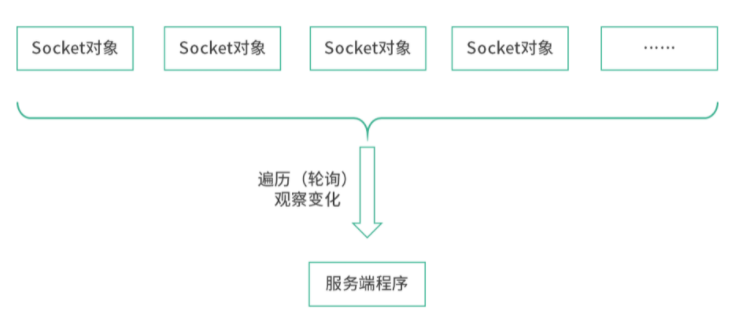
上述的过程,我们通过一个线程就可以响应多个客户端的连接,也被称作I/O 多路复用技术。
响应式(Reactive)
在 I/O 多路复用技术中,服务端程序(线程)需要维护一个 Socket 的集合(可以是数组、链表等),然后定期遍历这个集合。这样的做法在客户端 Socket 较少的情况下没有问题,但是如果接入的客户端 Socket 较多,比如达到上万,那么每次轮询的开销都会很大。
从程序设计的角度来看,像这样主动遍历,比如遍历一个 Socket 集合看看有没有发生写入(有数据从网卡传过来),称为命令式的程序。这样的程序设计就好像在执行一条条命令一样,程序主动地去查看每个 Socket 的状态。
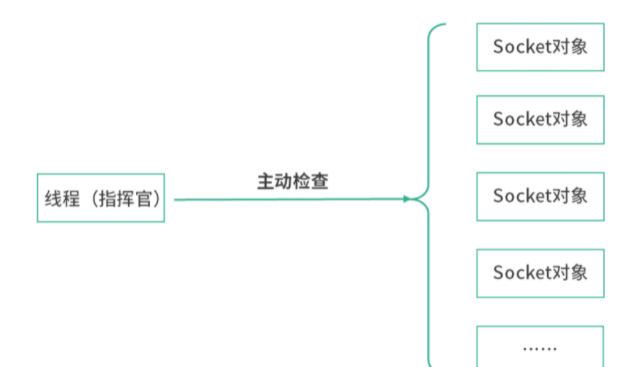
命令式会让负责下命令的程序负载过重,例如,在高并发场景下,上述讨论中循环遍历 Socket 集合的线程,会因为负担过重导致系统吞吐量下降。
与命令式相反的是响应式(Reactive),响应式的程序就不会有这样的问题。在响应式的程序当中,每一个参与者有着独立的思考方式,就好像拥有独立的人格,可以自己针对不同的环境触发不同的行为。
从响应式的角度去看 Socket 编程,应该是有某个观察者会观察到 Socket 文件状态的变化,从而通知处理线程响应。线程不再需要遍历 Socket 集合,而是等待观察程序的通知。
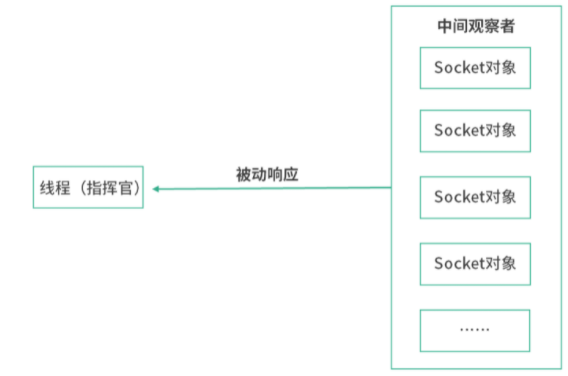
当然,最合适的观察者其实是操作系统本身,因为只有操作系统非常清楚每一个 Socket 文件的状态。原因是对 Socket 文件的读写都要经过操作系统。在实现这个模型的时候,有几件事情要注意。
- 线程需要告诉中间的观察者自己要观察什么,或者说在什么情况下才响应?比如具体到哪个 Socket 发生了什么事件?是读写还是其他的事件?这一步我们通常称为注册。
- 中间的观察者需要实现一个高效的数据结构(通常是基于红黑树的二叉搜索树)。这是因为中间的观察者不仅仅是服务于某个线程,而是服务于很多的线程。当一个 Socket 文件发生变化的时候,中间观察者需要立刻知道,究竟是哪个线程需要这个信息,而不是将所有的线程都遍历一遍。
为什么用红黑树?
关于为什么要红黑树,这里我给你再仔细解释一下。考虑到中间观察者最核心的诉求有两个。
第一个核心诉求,是让线程可以注册自己关心的消息类型。比如线程对文件描述符 =123 的 Socket 文件读写都感兴趣,会去中间观察者处注册。当 FD=123 的 Socket 发生读写时,中间观察者负责通知线程,这是一个响应式的模型。
第二个核心诉求,是当 FD=123 的 Socket 发生变化(读写等)时,能够快速地判断是哪个线程需要知道这个消息。
所以,中间观察者需要一个快速能插入(注册过程)、查询(通知过程)一个整数的数据结构,这个整数就是 Socket 的文件描述符。综合来看,能够解决这个问题的数据结构中,跳表和二叉搜索树都是不错的选择。
因此,在 Linux 的 epoll 模型中,选择了红黑树。红黑树是二叉搜索树的一种,红与黑是红黑树的实现者才关心的内容,对于我们使用者来说不用关心颜色,Java 中的 TreeMap 底层就是红黑树。
总结
总结一下,Socket 既是一种编程模型,或者说是一段程序,同时也是一个文件,一个双向管道文件。你也可以这样理解,Socket API 是在 Socket 文件基础上进行的一层封装,而 Socket 文件是操作系统提供支持网络通信的一种文件格式。
在服务端有两种 Socket 文件,每个客户端接入之后会形成一个客户端的 Socket 文件,客户端 Socket 文件的文件描述符会存入服务端 Socket 文件。通过这种方式,一个线程可以通过读取服务端 Socket 文件中的内容拿到所有的客户端 Socket。这样一个线程就可以负责响应所有客户端的 I/O,这个技术称为 I/O 多路复用。
主动式的 I/O 多路复用,对负责 I/O 的线程压力过大,因此通常会设计一个高效的中间数据结构作为 I/O 事件的观察者,线程通过订阅 I/O 事件被动响应,这就是响应式模型。在 Socket 编程中,最适合提供这种中间数据结构的就是操作系统的内核,事实上 epoll 模型也是在操作系统的内核中提供了红黑树结构。
epoll 为什么用红黑树?
【解析】在 Linux 的设计中有三种典型的 I/O 多路复用模型 select、poll、epoll。
select 是一个主动模型,需要线程自己通过一个集合存放所有的 Socket,然后发生 I/O 变化的时候遍历。在 select 模型下,操作系统不知道哪个线程应该响应哪个事件,而是由线程自己去操作系统看有没有发生网络 I/O 事件,然后再遍历自己管理的所有 Socket,看看这些 Socket 有没有发生变化。
poll 提供了更优质的编程接口,但是本质和 select 模型相同。因此千级并发以下的 I/O,你可以考虑 select 和 poll,但是如果出现更大的并发量,就需要用 epoll 模型。
epoll 模型在操作系统内核中提供了一个中间数据结构,这个中间数据结构会提供事件监听注册,以及快速判断消息关联到哪个线程的能力(红黑树实现)。因此在高并发 I/O 下,可以考虑 epoll 模型,它的速度更快,开销更小。
流和缓冲区:缓冲区的 flip 是怎么回事?
计算机中,数据往往会被抽象成流,然后传输。比如读取一个文件,数据会被抽象成文件流;播放一个视频,视频被抽象成视频流。处理节点为了防止过载,又会使用缓冲区削峰(减少瞬间压力)。在传输层协议当中,应用往往先把数据放入缓冲区,然后再将缓冲区提供给发送数据的程序。发送数据的程序,从缓冲区读取出数据,然后进行发送。
流
流代表数据,具体来说是随着时间产生的数据,类比自然界的河流。你不知道一个流什么时候会完结,直到你将流中的数据都读完。
读取文件的时候,文件被抽象成流。流的内部构造,决定了你每次能从文件中读取多少数据。从流中读取数据的操作,本质上是一种迭代器。流的内部构造决定了迭代器每次能读出的数据规模。比如你可以设计一个读文件的流,每次至少会读出 4k 大小,也可以设计一个读文件的程序,每次读出一个字节大小。
通常情况读取数据的流,是读取流;写入数据的流,是写入流。那么一个写入流还能被理解成随着时间产生的数据吗?其实是一样的,随着时间产生的数据,通过写入流写入某个文件,或者被其他线程、程序拿走使用。
这里请你思考一个问题:流中一定有数据吗?看上去的确是这样。对于文件流来说,打开一个文件,形成读取流。读取流的本质当然是内存中的一个对象。当用户读取文件内容的时候,实际上是通过流进行读取,看上去好像从流中读取了数据,而本质上读取的是文件的数据。从这个角度去观察整体的设计,数据从文件到了流,然后再到了用户线程,因此数据是经过流的。
但是仔细思考这个问题,可不可以将数据直接从文件传输到用户线程呢?比如流对象中只设计一个整数型指针,一开始指向文件的头部,每次发生读取,都从文件中读出内容,然后再返回给用户线程。做完这次操作,指针自增。通过这样的设计,流中就不需要再有数据了。可见,流中不一定要有数据。再举一个极端的例子,如果我们设计一个随机数的产生流,每次读取流中的数据,都调用随机数函数生成一个随机数并返回,那么流中也不需要有数据的存储。
为什么要缓冲区?
在上面的例子当中,我们讨论的时候发现,设计文件流时,可以只保留一个位置指针,不用真的将整个文件都读入内存,像下图这样:
把文件看作是一系列线性排列连续字节的合集,用户线程调用流对象的读取数据方法,每次从文件中读取一个字节。流中只保留一个读取位置 position,指向下一个要读取的字节。
看上去这个方案可行,但实际上性能极差。因为从文件中读取数据这个操作,是一次磁盘的 I/O 操作,非常耗时。正确的做法是每次读取 2k、4k 这样大小的数据,这是因为操作系统中的内存分页通常是这样的大小,而磁盘的读写往往是会适配页表大小。而且现在的文件系统主要都是日志文件系统,存储的并不是原始数据本身,也就是说多数情况下你看到的文件并不是一个连续紧密的字节线性排列,而是日志。关于这块内容,具体可以参考《重学操作系统》中《30 | 文件系统的底层实现:FAT、NTFS 和 Ext3 有什么区别》。
如果你不想花时间再去完整地学习一遍“操作系统”相关的内容,我这里先给一个结论:当你向磁盘读取 2k 数据,读取到的不一定是 2k 实际的数据,很有可能会比 2k 少,这是因为文件内容是以日志形式存储,会有冗余。
我们用下面这张图来描述下需求:

如上图所示,内核每次从文件系统中读取到的数据是确定的,但是里边的有效数据是不确定的。流对象的设计,至少应该支持两种操作:一种是读取一个字节,另一种是读取多个字节。而无论读取一个字节还是读取多个字节,都应该适配内核的底层行为。也就是说,每次流对象读取一个字节,内核可能会读取 2k、4k 的数据。这样的行为,才能真的做到减少磁盘的 I/O 操作。那么有同学可能会问:内核为什么不一次先读取几兆数据或者读取更大的数据呢?这有两个原因。
如果是高并发场景下,并发读取数据时内存使用是根据并发数翻倍的,如果同时读取的数据量过大,可能会导致内存不足。
读取比 2k/4k……大很多倍的数据,比如 1M/2M 这种远远大于内存分页大小的数据,并不能提升性能。
所以最后我们的解决办就是创建两个缓冲区。
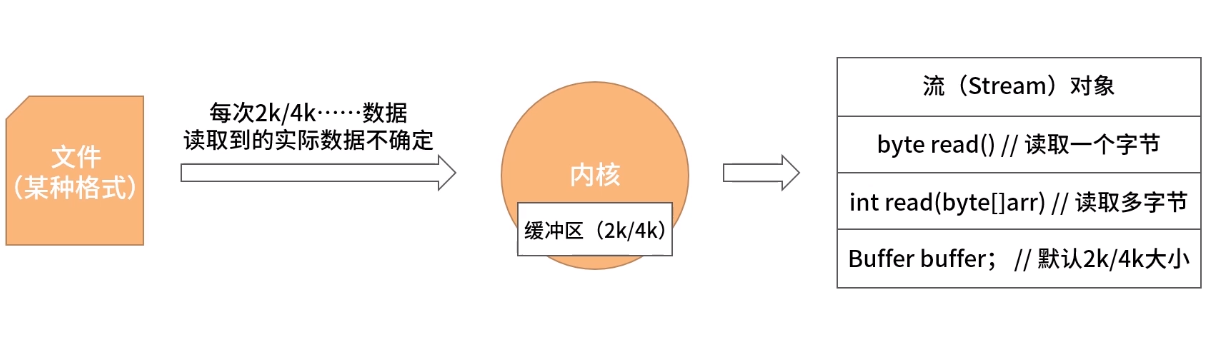
上图中内核中的缓冲区,用于缓冲读取文件中的数据。流中的缓冲区,用于缓冲内核中拷贝过来的数据。有同学可能不理解,为什么不把内核的缓冲区直接给到流呢?这是因为流对象工作在用户空间,内核中的缓冲区工作在内核空间。用户空间的程序不可以直接访问内核空间的数据,这是操作系统的一种保护策略。具体可以参考《重学操作系统》中《14 | 用户态和内核态:用户态线程和内核态线程有什么区别?》,这里不再赘述。
当然也存在一种叫作内存映射的方式,就是内核通过内存映射,直接将内核空间中的一块内存区域分享给用户空间只读使用,这样的方式可以节省一次数据拷贝。这个能力在 Java 的 NIO 中称作 DirectMemory,对应 C 语言是 mmap。
缓冲区
上面的设计中,我们已经开始用缓冲区解决问题了。那么具体什么是缓冲区呢?缓冲区就是一块用来做缓冲的内存区域。在上面的例子当中,为了应对频繁的字节读取,我们在内存当中设置一个 2k 大小缓冲区。这样读取 2048 次,才会真的发生一次读取。同理,如果应对频繁的字节写入,也可以使用缓冲区。
不仅仅如此,比如说你设计一个秒杀系统,如果同时到达的流量过高,也可以使用缓冲区将用户请求先存储下来,再进行处理。这个操作我们称为削峰,削去流量的峰值。
缓冲区中的数据通常具有朴素的公平,说白了就是排队,先进先出(FIFO)。从数据结构的设计上,缓冲区像一个队列。在实际的使用场景中,缓冲区有一些自己特别的需求,比如说缓冲区需要被重复利用。多次读取数据,可以复用一个缓冲区,这样可以节省内存,也可以减少分配和回收内存的开销。
举个例子:读取一个流的数据到一个缓冲区,然后再将缓冲区中的数据交给另一个流。 比如说读取文件流中的数据交给网络流发送出去。首先,我们要将文件流的数据写入缓冲区,然后网络流会读取缓冲区中的数据。这个过程会反反复复进行,直到文件内容全部发送。
这个设计中,缓冲区需要支持这几种操作:
写入数据
读出数据
清空(应对下一次读写)
那么具体怎么设计这个缓冲区呢?首先,数据可以考虑存放到一个数组中,下图是可以存 8 个字节的缓冲区:
写入数据的时候,需要一个指针指向下一个可以写入的位置,如下图所示:
每次写入数据,position 增 1,比如我们顺序写入 a,b,c,d 后,缓冲区如下图所示:
那么如果这个时候,要切换到读取状态该怎么做呢?再增加一个读取指针吗?聪明的设计者想到了一个办法,增加一个 limit 指针,随着写入指针一起增长,如下图所示:
当需要切换到读取状态的时候,将 position 设置为 0,limit 不变即可。下图中,我们可以从 0 开始读取数据,每次读取 position 增 1。
我们将 position 设置为 0,limit 不变的操作称为flip操作,flip 本意是翻转,在这个场景中是读、写状态的切换。
读取操作可以控制循环从 position 一直读取到 limit,这样就可以读取出 a,b,c,d。那么如果要继续写入应该如何操作呢? 这个时候就需要用到缓冲区的clear操作,这个操作会清空缓冲区。具体来说,clear操作会把 position,limit 都设置为 0,而不需要真的一点点擦除缓冲区中已有的值,就可以做到重复利用缓冲区了。
写入过程从 position = 0 开始,position 和 limit 一起自增。读取时,用flip操作切换缓冲区读写状态。读取数据完毕,用clear操作重置缓冲区状态。
总结
总结一下,流是随着时间产生的数据。数据抽象成流,是因为客观世界存在着这样的现象。数据被抽象成流之后,我们不需要把所有的数据都读取到内存当中进行计算和迭代,而是每次处理或者计算一个缓冲区的数据。
缓冲区的作用是缓冲,它在高频的 I/O 操作中很有意义。针对不同场景,也不只有这一种缓冲区的设计,比如用双向链表实现队列(FIFO 结构)可以作为缓冲区;Redis 中的列表可以作为缓冲区;RocketMQ,Kafka 等也可以作为缓冲区。针对某些特定场景,比如高并发场景下的下单处理,可能会用订单队列表(MySQL 的表)作为缓冲区。
因此从这个角度来说,作为开发者我们首先要有缓冲的意识,去减少 I/O 的次数,提升 I/O 的性能,然后才是思考具体的缓冲策略。
那么通过这一讲的学习,你可以尝试来回答本讲关联的面试题目:缓冲区的 flip 操作是怎么回事?
【解析】flip 操作意味翻转,是切换缓冲区的读写状态,在 flip 操作中,通常将 position 指针置 0,limit 指针不变。
网络 I/O 模型:BIO、NIO 和 AIO 有什么区别?
从本质上说,讨论 BIO、NIO、AIO 的区别,其实就是在讨论 I/O 的模型,我们可以从下面 3 个方面来思考 。
编程模型:合理设计 API,让程序写得更舒服。
数据的传输和转化成本:比如减少数据拷贝次数,合理压缩数据等。
高效的数据结构:利用好缓冲区、红黑树等(见本讲后续讨论)。
I/O 的编程模型
我们先从编程模型上讨论下 BIO、NIO 和 AIO 的区别。
BIO(Blocking I/O,阻塞 I/O),API 的设计会阻塞程序调用。比如:
1 | byte a = readKey() |
假设readKey方法会从键盘中读取一个用户的按键,如果是阻塞 I/O 的设计,ReadKey 会阻塞当前用户线程直到用户按键。这个阻塞指的是线程进入阻塞态。进入阻塞态的线程,状态会被存在内存中,执行会被中断,也就是不会占用 CPU å资源。阻塞态的线程要恢复执行,先要进入就绪态排队,然后轮到自己才能够继续执行。从一个线程执行切换到另一个线程执行,也叫作线程的上下文切换(Context Switch),是一个相对耗时的操作。
再说说 NIO (None Blocking I/O,非阻塞 IO),API 的设计不会阻塞程序的调用,比如:
1 | byte a = readKey() |
假设readKey方法从键盘读取一个按键,如果是非阻塞 I/O 的设计,readKey不会阻塞当前的线程。你可能会问:那如果用户没有按键怎么办?在阻塞 I/O 的设计中,如果用户没有按键线程会阻塞等待用户按键,在非阻塞 I/O 的设计中,线程不会阻塞,没有按键会返回一个空值,比如 null。
最后我们说说 AIO(Asynchronous I/O, 异步 I/O),API 的设计会多创造一条时间线。比如:
1 | func callBackFunction(byte keyCode) { |
在异步 I/O 中,readKey方法会直接返回,但是没有结果。结果需要一个回调函数callBackFunction去接收。从这个角度看,其实有两条时间线。第一条是程序的主干时间线,readKey的执行到readKey下文的程序都在这条主干时间线中。而callBackFunction的执行会在用户按键时触发,也就是时间不确定,因此callBackFunction中的程序是另一条时间线也是基于这种原因产生的,我们称作异步,异步描述的就是这种时间线上无法同步的现象,你不知道callbackFunction何时会执行。
但是我们通常说某某语言提供了异步 I/O,不仅仅是说提供上面程序这种写法,上面的写法会产生一个叫作回调地狱的问题,本质是异步程序的时间线错乱,导致维护成本较高。
1 | request("/order/123", (data1) -> { |
比如上面这段程序(称作回调地狱)维护成本较高,因此通常提供异步 API 编程模型时,我们会提供一种将异步转化为同步程序的语法。比如下面这段伪代码:
1 | Future future1 = request("/order/123") |
request 函数是一次网络调用,请求订单 ID=123 的订单数据。本身 request 函数不会阻塞,会马上执行完成,而网络调用是一次异步请求,调用不会在request("/order/123")下一行结束,而是会在未来的某个时间结束。因此,我们用一个 Future 对象封装这个异步操作。future.get()是一个阻塞操作,会阻塞直到网络调用返回。
在request和future.get之间,我们还可以进行很多别的操作,比如发送更多的请求。 像 Future 这样能够将异步操作再同步回主时间线的操作,我们称作异步转同步,也叫作异步编程。通常一门语言如果提供异步编程的能力,指的是提供异步转同步的能力,程序员更适应同步操作,同步程序更好维护。
数据的传输和转化成本
上面我们从编程的模型上对 I/O 进行了思考,接下来我们从内部实现分析下 BIO、NIO 和 AIO。无论是哪种 I/O 模型,都要将数据从网卡拷贝到用户程序(接收),或者将数据从用户程序传输到网卡(发送)。另一方面,有的数据需要编码解码,比如 JSON 格式的数据。还有的数据需要压缩和解压。数据从网卡到内核再到用户程序是 2 次传输。注意,将数据从内存中的一个区域拷贝到另一个区域,这是一个 CPU 密集型操作。数据的拷贝归根结底要一个字节一个字节去做。
从网卡到内核空间的这步操作,可以用 DMA(Direct Memory Access)技术控制。DMA 是一种小型设备,用 DMA 拷贝数据可以不使用 CPU,从而节省计算资源。遗憾的是,通常我们写程序的时候,不能直接控制 DMA,因此 DMA 仅仅用于设备传输数据到内存中。不过,从内核到用户空间这次拷贝,可以用内存映射技术,将内核空间的数据映射到用户空间。
本文关于 DMA 技术和多线程讨论较浅,对这两个技术感兴趣的同学可以看下我在拉勾教育平台推出的《重学操作系统》专栏。
有同学会问:上面我们讨论的内容和 I/O 模型有什么关联吗?其实我是想告诉你,无论 I/O 的编程模型如何选择,数据传输和转化成本是逃不掉的。或者说不会因为选择某种模型,就减少数据传输、数据压缩解压、数据编码解码这方面的成本。但是通过 DMA 技术和内存映射技术,就可以节省这部分成本。之所以会特别强调这点,是因为网上很多的博文会把 DMA、内存映射技术和 BIO/AIO/NIO 等概念混为一谈。
数据结构运用
在处理网络 I/O 问题的时候,还有一个重点问题要注意,就是数据结构的运用。
缓冲区
缓冲区是一种在处理 I/O 问题中常用的数据结构,一方面缓冲区起到缓冲作用,在瞬时 I/O 量较大的时候,利用排队机制进行处理。另一方面,缓冲区起到一个批处理的作用,比如 1000 次 I/O 请求进入缓冲区,可以合并成 50 次 I/O 请求,那么整体性能就会上一个档次。
举个例子,比如你有 1000 个订单要写入 MySQL,如果这个时候你可以将这 1000 次请求合并成 50 次,那么磁盘写入次数将大大减少。同理,假设有 10000 次网络请求,如果可以合并发送,会减少 TCP 协议握手时间,可以最大程度地复用连接;另一方面,如果这些请求都较小,还可以粘包复用 TCP 段。在处理 Web 网站的时候,经常会碰到将多个 HTTP 请求合并成一个发送,从而减少整体网络开销的情况。
除了上述两方面原因,缓冲区还可以减少实际对内存的诉求。数据在网卡到内核,内核到用户空间的过程中,建议都要使用缓冲区。当收到的某个请求较大的时候,抽象成流,然后使用缓冲区可以减少对内存的使用压力。这是因为使用了缓冲区和流,就不需要真的准备和请求数据大小一致的内存空间了。可以将缓冲区大小规模的数据分成多次处理完,实际的内存开销是缓冲区的大小。
I/O 多路复用模型
在运用数据结构的时候,还要思考 I/O 的多路复用用什么模型。
假设你在处理一个高并发的网站,每秒有大量的请求打到你的服务器上,你用多少个线程去处理 I/O 呢?对于没有需要压缩解压的场景,处理 I/O 的主要开销还是数据的拷贝。那么一个 CPU 核心每秒可以完成多少次数据拷贝呢?
拷贝,其实就是将内存中的数据从一个地址拷贝到另一个地址。再加上有 DMA,内存映射等技术,拷贝是非常快的。不考虑 DMA 和内存映射,一个 3GHz 主频的 CPU 每秒可以拷贝的数据也是百兆级别的。当然,速度还受限于内存本身的速度。因此总的来说,I/O 并不需要很大的计算资源。通常我们在处理高并发的时候,也不需要大量的线程去进行 I/O 处理。
对于多数应用来说,处理 I/O 的成本小于处理业务的成本。处理高并发的业务,可能需要大量的计算资源。每笔业务也可能会需要更多的 I/O,比如远程的 RPC 调用等。
因此我们在处理高并发的时候,一种常见的 I/O 多路复用模式就是由少量的线程处理大量的网络接收、发送工作。然后再由更多的线程,通常是一个线程池处理具体的业务工作。在这样一个模式下,有一个核心问题需要解决,就是当操作系统内核监测到一次 I/O 操作发生,它如何具体地通知到哪个线程调用哪段程序呢?
这时,一种高效的模型会要求我们将线程、线程监听的事件类型,以及响应的程序注册到内核。具体来说,比如某个客户端发送消息到服务器的时候,我们需要尽快知道哪个线程关心这条消息(处理这个数据)。例如 epoll 就是这样的模型,内部是红黑树。我们可以具体地看到文件描述符构成了一棵红黑树,而红黑树的节点上挂着文件描述符对应的线程、线程监听事件类型以及相应程序。
最后,你可能会问:老师你讲了这么多,和 BIO、AIO、NIO 有什么关系?这里有两个联系。
首先是无论哪种编程模型都需要使用缓冲区,也就是说 BIO、AIO、NIO 都需要缓冲区,因此关系很大。在我们使用任何编程模型的时候,如果内部没有使用缓冲区,那么一定要在外部增加缓冲区。另一个联系是类似 epoll 这种注册+消息推送的方式,可以帮助我们节省大量定位具体线程以及事件类型的时间。这是一个通用技巧,并不是独有某种 I/O 模型才可以使用。
不过从能力上分析,使用类似 epoll 这种模型,确实没有必要让处理 I/O 的线程阻塞,因为操作系统会将需要响应的事件源源不断地推送给处理的线程,因此可以考虑不让处理线程阻塞(比如用 NIO)。
总结
这一讲我们从 3 个方面讨论了 I/O 模型。
- 第一个是编程模型,阻塞、非阻塞、异步 3 者 API 的设计会有比较大的差异。通常情况下我们说的异步编程是异步转同步。异步转同步最大的价值,就是提升代码的可读性。可读,就意味着维护成本的下降以及扩展性的提升。
- 第二个在设计系统的 I/O 时,另一件需要考虑的就是数据传输以及转化的成本。传输主要是拷贝,比如可以使用内存映射来减少数据的传输。但是这里要注意一点,内存映射使用的内存是内核空间的缓冲区,因此千万不要忘记回收。因为这一部分内存往往不在我们所使用的语言提供的内存回收机制的管控范围之内。
- 最后是关于数据结构的运用,针对不同的场景使用不同的缓冲区,以及选择不同的消息通知机制,也是处理高并发的一个核心问题。
从上面几个角度去看 I/O 的模型,你会发现,编程模型是编程模型、数据的传输是数据的传输、消息的通知是消息的通知,它们是不同的模块,完全可以解耦,也可以根据自己不同的业务特性进行选择。虽然在一个完整的系统设计中,往往提出的是一套完整的解决方案(这也是很多网上的博文会将者 3 者混为一谈的原因),但实际上我们还是应该将它们分开去思考,这样可以产生更好的设计思路。
那么现在你可以尝试来回答本讲关联的面试题目:BIO、NIO 和 AIO 有什么区别?
【解析】总的来说,这三者是三个 I/O 的编程模型。BIO 接口设计会直接导致当前线程阻塞。NIO 的设计不会触发当前线程的阻塞。AIO 为 I/O 提供了异步能力,也就是将 I/O 的响应程序放到一个独立的时间线上去执行。但是通常 AIO 的提供者还会提供异步编程模型,就是实现一种对异步计算封装的数据结构,并且提供将异步计算同步回主线的能力。
通常情况下,这 3 种 API 都会伴随 I/O 多路复用。如果底层用红黑树管理注册的文件描述符和事件,可以在很小的开销内由内核将 I/O 消息发送给指定的线程。另外,还可以用 DMA,内存映射等方式优化 I/O。
零拷贝
零拷贝的核心是CPU不执行将数据从一个存储区复制到另一个存储区的任务。
可能你会说,那零拷贝是不是0次调用CPU消耗资源啊?既对也不对,为什么这样说呢?
实际上,零拷贝有广义和狭义之分。
广义零拷贝
能减少拷贝次数,减少不必要的数据拷贝,就算作“零拷贝”。
这是目前,对零拷贝最为广泛的定义,我们需要知道的是,这是广义上的零拷贝,并不是操作系统意义上的零拷贝。
狭义零拷贝
Linux 2.4 内核新增 sendfile 系统调用,提供了零拷贝。磁盘数据通过 DMA 拷贝到内核态 Buffer 后,直接通过 DMA 拷贝到 NIC Buffer(socket buffer),无需 CPU 拷贝。这是真正操作系统意义上的零拷贝(也就是狭义零拷贝)。
Linux I/O 机制
介绍 DMA 之前,我们先来了解下 Linux I/O 机制。
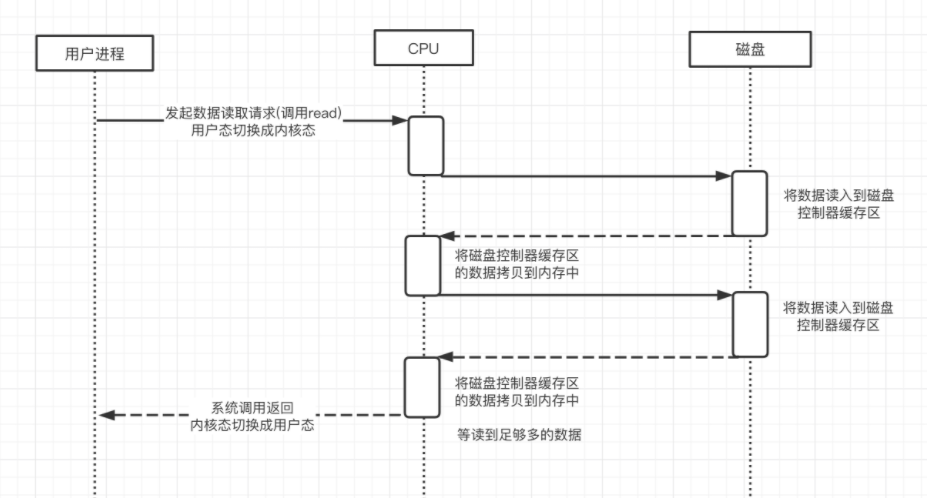
为了解决CPU的上下文切换,聪明的程序员们提出了 DMA(Direct Memory Access,直接内存存取),是所有现代电脑的重要特色,它允许不同速度的硬件装置来沟通,而不需要依赖于 CPU 的大量中断负载。通俗点理解,就是让硬件可以跳过CPU的调度,直接访问主内存。
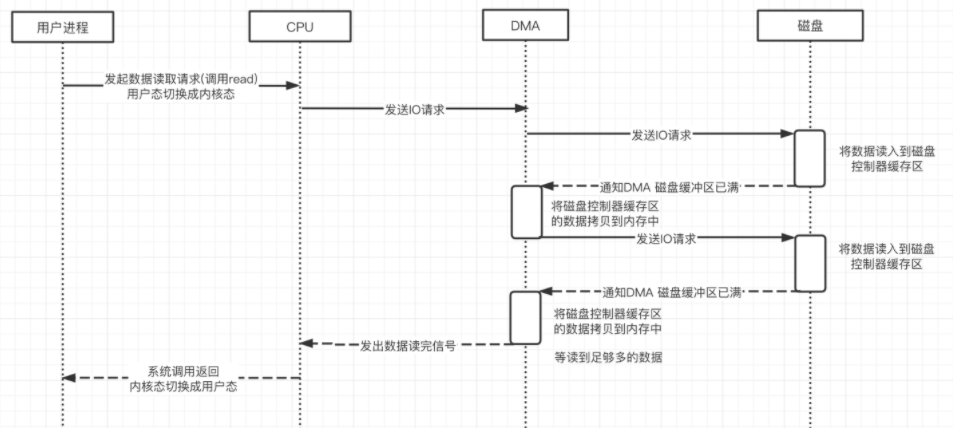
DMA 控制器,接管了数据读写请求,减少 CPU 的负担。这样一来,CPU 能高效工作了。
现代硬盘基本都支持 DMA。
比如我们常见的磁盘控制器、显卡、网卡、声卡都是支持 DMA 的,可以说 DMA 已经彻底融入我们的计算机世界了。
Linux IO 流程
那么什么又是DMA拷贝呢?
因为对于一个IO操作而言,都是通过CPU发出对应的指令来完成,但是相比CPU来说,IO的速度太慢了,CPU有大量的时间处于等待IO的状态。
因此就产生了DMA(Direct Memory Access)直接内存访问技术,本质上来说他就是一块主板上独立的芯片,通过它来进行内存和IO设备的数据传输,从而减少CPU的等待时间。
但是无论谁来拷贝,频繁的拷贝耗时也是对性能的影响。
实际因此 IO 读取,涉及两个过程:
- DMA 等待数据准备好,把磁盘数据读取到操作系统内核缓冲区;
- 用户进程,将内核缓冲区的数据 copy 到用户空间。
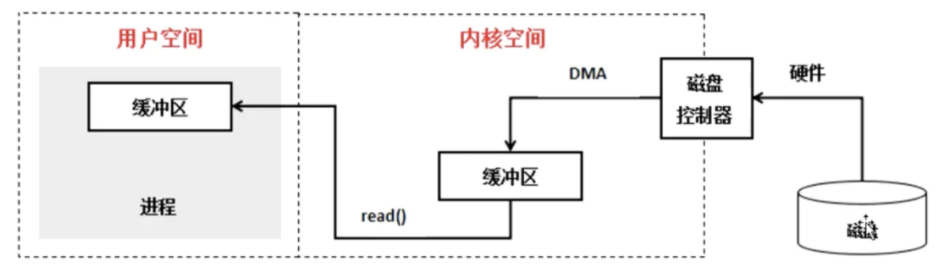
了解完 DMA 以及 Linux I/O 流程,相信你对 Linux I/O 机制有个大致的脉络了,但你可能会问,了解完这些,跟我们零拷贝技术有啥关联么?有的.
传统 IO 的劣势
我们刚学 Java 的时候,都会学 IO 和 网络编程,最常见的就是写个聊天程序或是群聊。
我们来写个简单的,代码如下:
1 | File file = new File("index.html"); |
服务端读取 html 里的内容后变成字节数组,然后监听 8080 端口,接收请求处理,将 html 里的字节流写到 socket 中,那么,我们调用read、write这两个方法,在 OS 底层发生了什么呢?
整个过程发生了4次用户态和内核态的上下文切换和4次拷贝
read 调用导致用户态到内核态的一次变化,同时,
- 第一次复制开始:DMA(Direct Memory Access,直接内存存取,即不使用 CPU 拷贝数据到内存,而是 DMA 引擎传输数据到内存)引擎从磁盘读取 index.html 文件,并将数据放入到内核缓冲区。
- 发生第二次数据拷贝,即:将内核缓冲区的数据拷贝到用户缓冲区,同时,发生了一次用内核态到用户态的上下文切换。
- 发生第三次数据拷贝,我们调用 write 方法,系统将用户缓冲区的数据拷贝到 socket 缓冲区。此时,又发生了一次用户态到内核态的上下文切换。
- 第四次拷贝,数据异步的从 socket 缓冲区,使用 DMA 引擎拷贝到网络协议引擎。这一段,不需要进行上下文切换。
write 方法返回,再次从内核态切换到用户态。
目的:减少 IO 流程中不必要的拷贝
零拷贝需要 OS 支持,也就是需要 kernel暴 露 api,虚拟机不能操作内核。
Linux 支持的(常见)零拷贝
1、mmap 内存映射
那我们这里先来了解下什么是mmap 内存映射。
在 Linux 中我们可以使用 mmap 用来在进程虚拟内存地址空间中分配地址空间,创建和物理内存的映射关系。
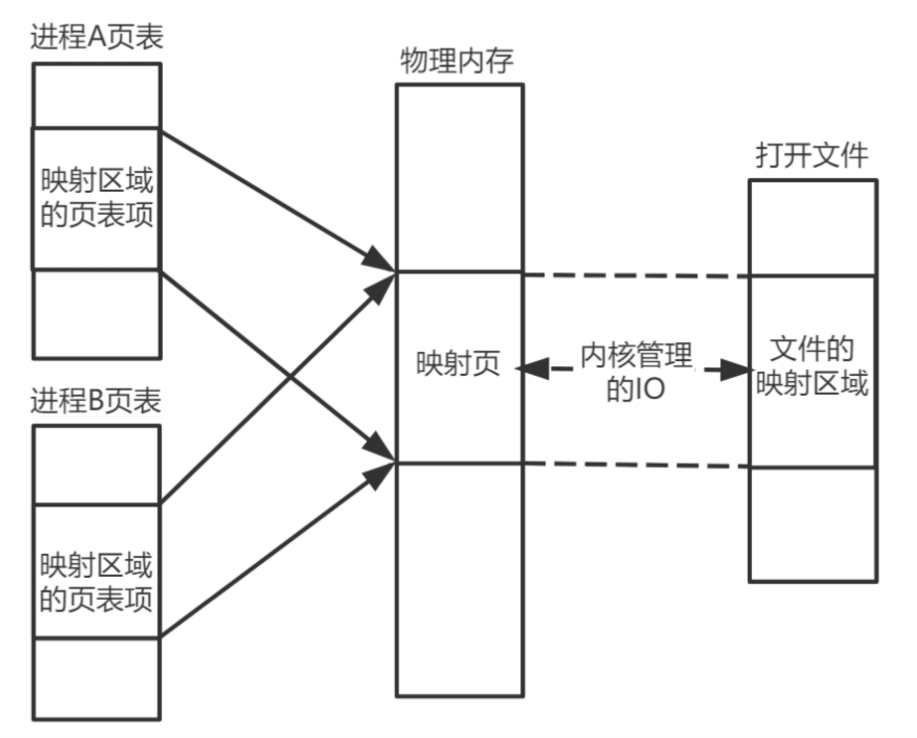
映射关系可以分为两种
- 文件映射:磁盘文件映射进程的虚拟地址空间,使用文件内容初始化物理内存。
- 匿名映射:初始化全为 0 的内存空间。
而对于映射关系是否共享又分为
私有映射(MAP_PRIVATE) 多进程间数据共享,修改不反应到磁盘实际文件,是一个 copy-on- write(写时复制) 的映射方式。
共享映射(MAP_SHARED) 多进程间数据共享,修改反应到磁盘实际文件中。
因此总结起来有4种组合
- 私有文件映射:多个进程使用同样的物理内存页进行初始化,但是各个进程对内存文件的修改不会共享,也不会反应到物理文件中。
- 私有匿名映射:mmap会创建一个新的映射,各个进程不共享,这种使用主要用于分配内存 (malloc分配大内存会调用mmap)。 例如开辟新进程时,会为每个进程分配虚拟的地址空间,这些虚拟地址映射的物理内存空间各个进程间读的时候共享,写的时候会 copy-on-write。
- 共享文件映射:多个进程通过虚拟内存技术共享同样的物理内存空间,对内存文件的修改会反应到实际物理文件中,他也是进程间通信(IPC)的一种机制。
- 共享匿名映射:这种机制在进行fork的时候不会采用写时复制,父子进程完全共享同样的物理内存页,这也就实现了父子进程通信(IPC)。
mmap 只是在虚拟内存分配了地址空间,只有在第一次访问虚拟内存的时候才分配物理内存。
在 mmap 之后,并没有在将文件内容加载到物理页上,只上在虚拟内存中分配了地址空间。当进程在访问这段地址时,通过查找页表,发现虚拟内存对应的页没有在物理内存中缓存,则产生”缺页”,由内核的缺页异常处理程序处理,将文件对应内容,以页为单位(4096)加载到物理内存,注意是只加载缺页,但也会受操作系统一些调度策略影响,加载的比所需的多。
mmap+write
mmap+write简单来说就是使用mmap替换了read+write中的read操作,减少了一次CPU的拷贝。
mmap主要实现方式是将读缓冲区的地址和用户缓冲区的地址进行映射,内核缓冲区和应用缓冲区共享,从而减少了从读缓冲区到用户缓冲区的一次CPU拷贝。
整个过程发生了4次用户态和内核态的上下文切换和3次拷贝,具体流程如下:
- 用户进程通过
mmap()方法向操作系统发起调用,上下文从用户态转向内核态 - DMA控制器把数据从硬盘中拷贝到读缓冲区
- 上下文从内核态转为用户态,mmap调用返回
- 用户进程通过
write()方法发起调用,上下文从用户态转为内核态 - CPU将读缓冲区中数据拷贝到socket缓冲区
- DMA控制器把数据从socket缓冲区拷贝到网卡,上下文从内核态切换回用户态,
write()返回
mmap的方式节省了一次CPU拷贝,同时由于用户进程中的内存是虚拟的,只是映射到内核的读缓冲区,所以可以节省一半的内存空间,比较适合大文件的传输。
2、sendfile
其基本原理如下:数据根本不经过用户态,直接从内核缓冲区进入到 Socket Buffer,同时,由于和用户态完全无关,就减少了一次上下文切换。
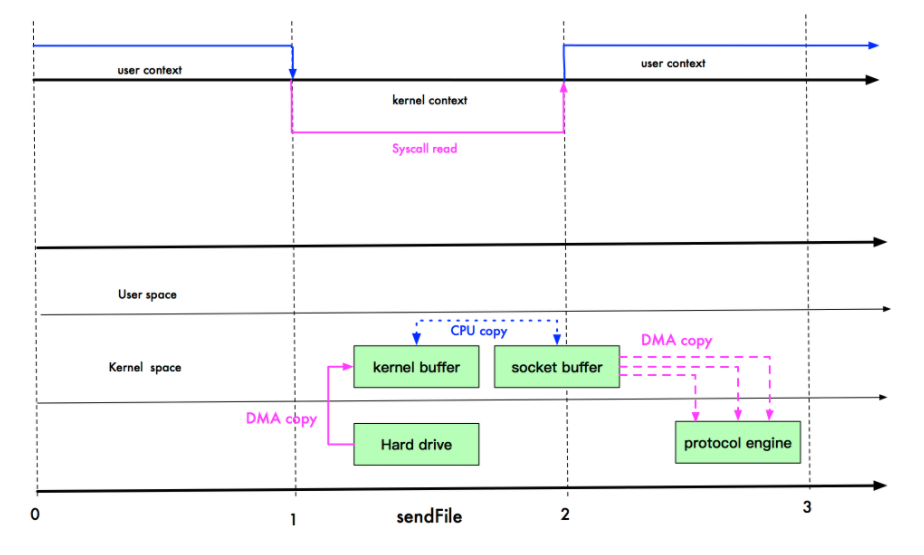
如上图,我们进行 sendFile 系统调用时,数据被 DMA 引擎从文件复制到内核缓冲区,然后调用 write 方法时,从内核缓冲区进入到 socket,这时,是没有上下文切换的,因为都在内核空间。
最后,数据从 socket 缓冲区进入到协议栈。此时,数据经过了 3 次拷贝,2 次上下文切换。那么,还能不能再继续优化呢? 例如直接从内核缓冲区拷贝到网络协议栈?
sendfile是Linux2.1内核版本后引入的一个系统调用函数,通过使用sendfile数据可以直接在内核空间进行传输,因此避免了用户空间和内核空间的拷贝,同时由于使用sendfile替代了read+write从而节省了一次系统调用,也就是2次上下文切换。
整个过程发生了2次用户态和内核态的上下文切换和3次拷贝,具体流程如下:
- 用户进程通过
sendfile()方法向操作系统发起调用,上下文从用户态转向内核态 - DMA控制器把数据从硬盘中拷贝到读缓冲区
- CPU将读缓冲区中数据拷贝到socket缓冲区
- DMA控制器把数据从socket缓冲区拷贝到网卡,上下文从内核态切换回用户态,
sendfile调用返回
sendfile方法IO数据对用户空间完全不可见,所以只能适用于完全不需要用户空间处理的情况,比如静态文件服务器。
3、Sendfile With DMA Scatter/Gather Copy
实际上,Linux 在 2.4 版本中,做了一些优化。
避免了从内核缓冲区拷贝到 socket buffer 的操作,直接拷贝到协议栈,从而再一次减少了数据拷贝。
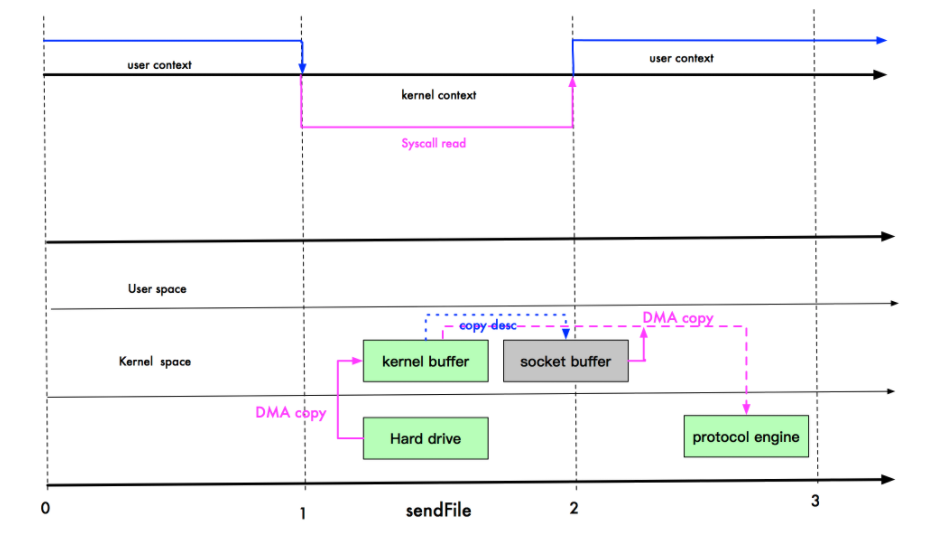
Scatter/Gather 可以看作是 sendfile 的增强版,批量 sendfile。
现在,index.html 要从文件进入到网络协议栈,只需 2 次拷贝:第一次使用 DMA 引擎从文件拷贝到内核缓冲区,第二次从内核缓冲区将数据拷贝到网络协议栈;内核缓存区只会拷贝一些 offset 和 length 信息到 socket buffer,基本无消耗。
首先我们说零拷贝,是从操作系统的角度来说的(也就是我们上文所说的狭义零拷贝)。因为内核缓冲区之间,没有数据是重复的(只有 kernel buffer 有一份数据,sendFile 2.1 版本实际上有 2 份数据,算不上零拷贝(严谨点的话叫狭义零拷贝))。例如我们刚开始的例子,内核缓存区和 socket 缓冲区的数据就是重复的。
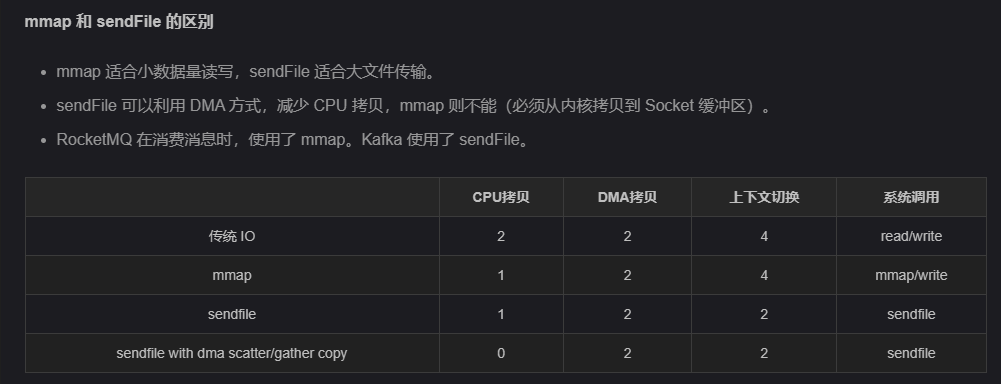
整个过程发生了2次用户态和内核态的上下文切换和2次拷贝,其中更重要的是完全没有CPU拷贝,具体流程如下:
- 用户进程通过
sendfile()方法向操作系统发起调用,上下文从用户态转向内核态 - DMA控制器利用scatter把数据从硬盘中拷贝到读缓冲区离散存储
- CPU把读缓冲区中的文件描述符和数据长度发送到socket缓冲区
- DMA控制器根据文件描述符和数据长度,使用scatter/gather把数据从内核缓冲区拷贝到网卡
sendfile()调用返回,上下文从内核态切换回用户态
DMA gather和sendfile一样数据对用户空间不可见,而且需要硬件支持,同时输入文件描述符只能是文件,但是过程中完全没有CPU拷贝过程,极大提升了性能。
总结
传统的IOread+write方式会产生2次DMA拷贝+2次CPU拷贝,同时有4次上下文切换。
而通过mmap+write方式则产生2次DMA拷贝+1次CPU拷贝,4次上下文切换,通过内存映射减少了一次CPU拷贝,可以减少内存使用,适合大文件的传输。
sendfile方式是新增的一个系统调用函数,产生2次DMA拷贝+1次CPU拷贝,但是只有2次上下文切换。因为只有一次调用,减少了上下文的切换,但是用户空间对IO数据不可见,适用于静态文件服务器。
sendfile+DMA gather方式产生2次DMA拷贝,没有CPU拷贝,而且也只有2次上下文切换。虽然极大地提升了性能,但是需要依赖新的硬件设备支持。