
笨猫不如烂笔头
更友好的创建对象方式

上面的方式,对JVM来说是更友好的,因为堆内存的调用无法避免,所以从栈内存这边入手解决内存问题是一个不错的解决的方式
下面代码是否线程安全
1 | public class Singleton { |
乍一看类似饿汉式的单例,线程安全,其实是有问题的
虽然只有一个线程能够获得锁,并且这个锁还是类锁,所有对象共享的
关键在于 jvm 对 new 的优化,这个变量没有声明 volatile,new 不是一个线程安全的操作,
对于 new 这个指令,一般的顺序是申请内存空间,初始化内存空间,然后把内存地址赋给 instance 对象,但是 jvm 会对这段指令进行优化,优化之后变成 申请内存空间,内存地址赋给 instance 对象,初始化内存空间,这就导致 第二层检查可能会出错,标准写法只需要在变量前声明 volatile 即可。

volatile利用了什么协议来实现可见性
volatile 是通过内存屏障实现的,MESI协议,缓存一致性协议
JVM推荐书《The Java Language Specification》
volatile 修饰的变量如果值发生变化 发现线程的高速缓存与主存数据不一致时候 由于缓存一致性协议 则总线将高速缓存中的值清空 其他线程只能通过访问主存来获取最新的值 并缓存到告诉缓存上。
Java Trainsient 关键字
1.一旦变量被transient修饰,变量将不再是对象持久化的一部分,该变量内容在序列化后无法获得访问。
2.transient关键字只能修饰变量,而不能修饰方法和类。注意,本地变量是不能被transient关键字修饰的。变量如果是用户自定义类变量,则该类需要实现Serializable接口。
3.一个静态变量不管是否被transient修饰,均不能被序列化。
使用总结和场景:某个类的有些属性需要序列化,其他属性不需要被序列化,比如:敏感信息(如密码,银行卡号等),java 的transient关键字为我们提供了便利,你只需要实现Serilizable接口,将不需要序列化的属性前添加关键字transient,序列化对象的时候,这个属性就不会序列化到指定的目的地中。
多线程中Random的使用
1.不要在多个线程间共享一个java.util.Random实例,而该把它放入ThreadLocal之中。
2.Java7以上我们更推荐使用java.util.concurrent.ThreadLocalRandom。
下面两条建议是 IDEA给的:
1.不要将将随机数放大10的若干倍然后取整,直接使用Random对象的nextInt或者nextLong方法
2.Math.random()应避免在多线程环境下使用
为什么阿里禁止使用Executor创建线程池
阿里规约之所以强制要求手动创建线程池,也是和这些参数有关。具体为什么不允许,规约是这么说的:
线程池不允许使用Executors去创建,而是通过ThreadPoolExecutor的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
Executor提供的四个静态方法创建线程池,但是阿里规约却并不建议使用它。
Executors各个方法的弊端:
1)newFixedThreadPool和newSingleThreadExecutor:
主要问题是堆积的请求处理队列可能会耗费非常大的内存,甚至OOM。
2)newCachedThreadPool和newScheduledThreadPool:
主要问题是线程数最大数是Integer.MAX_VALUE,可能会创建数量非常多的线程,甚至OOM。
看一下这两种弊端怎么导致的。
第一种,newFixedThreadPool和newSingleThreadExecutor分别获得 FixedThreadPool 类型的线程池 和 SingleThreadExecutor 类型的线程池。
1 | public static ExecutorService newFixedThreadPool(int nThreads) { |
1 | public static ExecutorService newSingleThreadExecutor() { |
因为,创建了一个无界队列LinkedBlockingQueuesize,是一个最大值为Integer.MAX_VALUE的线程阻塞队列,当添加任务的速度大于线程池处理任务的速度,可能会在队列堆积大量的请求,消耗很大的内存,甚至导致OOM。
阿里开发手册上不推荐(禁止)使用Double的根本原因
精度丢失就不谈了,稍微深入一下为什么精度会丢失,分为一些不同情况
典型现象(一):条件判断超预期
1 | System.out.println( 1f == 0.9999999f ); // 打印:false |
典型现象(二):数据转换超预期
1 | float f = 1.1f; |
典型现象(三):基本运算超预期
1 | System.out.println( 0.2 + 0.7 ); |
典型现象(四):数据自增超预期
1 | float f1 = 8455263f; |
解决办法:
1.我们我们可以用字符串或者数组来表示这种大数,然后按照四则运算的规则来手动模拟出具体计算过程,中间还需要考虑各种诸如:进位、借位、符号等等问题的处理,有点复杂。
- JDK早已为我们考虑到了浮点数的计算精度问题,因此提供了专用于高精度数值计算的大数类来方便我们使用。
mac 清理maven仓库的脚本
1 | # 这里写你的仓库路径 |
idea目录较多,文件名较长产生的错误
1 | Error running 'ServiceStarter': Command line is too long. Shorten command line for ServiceStarter or also for Application default configuration. |
Log4J 指定屏蔽某些特定报警信息
Logger.getLogger(“org.apache.library”).setLevel(Level.OFF)
Flink Source并行度为1的意义
对于需要设置EventTime的流来说,我们的TimestampAssigner应该在Source之后立即调用,原因是时间戳分配器看到的元素的顺序应该和source操作符产生数据的顺序是一样的,否则就乱了,也就是说,任何分区操作都会将元素的顺序打乱,例如:改变并行度 keyBy操作等等。,所以最佳实践是:
在尽量接近数据源source操作符的地方分配时间戳和产生水位线,甚至最好在SourceFunction中分配时间戳和产生水位线。当然在分配时间戳和产生水位线之前可以对流进行map和filter操作是没问题的,也就是说必须是窄依赖。
JB套件的一个实用功能
1 | 之前没注意,更改变量名字的时候直接使用refactor就可以了,真的实用 |
zk使用的分布式协议并不是paxos
1 | 而是zab协议 |
为什么说NULL是计算机科学中最大的错误,至少值十亿美金
1 | 1.覆类型 |
1. NULL 颠覆类型
静态类型语言不需要实际去执行程序,就可以检查程序中类型的使用,并且提供一定的程序行为保证。
例如,在 Java 中,如果我编写 x.toUppercase(),编译器会检查 x 的类型。如果 x 是一个 String,那么类型检查成功;如果 x 是一个 Socket,那么类型检查失败。
在编写庞大的、复杂的软件时,静态类型检查是一个强大的工具。但是对于 Java,这些很棒的编译时检查存在一个致命缺陷:任何引用都可以是 null,而调用一个 null 对象的方法会产生一个 NullPointerException。所以,
toUppercase()可以被任意String对象调用。除非String是 null。read()可以被任意InputStream对象调用。除非InputStream是 null。toString()可以被任意Object对象调用。除非Object是 null。
Java 不是唯一引起这个问题的语言;很多其它的类型系统也有同样的缺点,当然包括 AGOL W 语言。
在这些语言中,NULL 超出了类型检查的范围。它悄悄地越过类型检查,等待运行时,最后一下子释放出一大批错误。NULL 什么也不是,同时又什么都是。
2. NULL 是凌乱的
在很多情况下 null 是没有意义的。不幸的是,如果一种语言允许任何东西为 null,好吧,那么任何东西都可以是 null。
Java 程序员冒着患腕管综合症的风险写下
Java
if (str == null 丨丨 str.equals("")) {}
而在 C# 中添加 String.IsNullOrEmpty 是一个常见的语法
C#
if (string.IsNullOrEmpty(str)) {}
真可恶!
每次你写代码,将 null 字符串和空字符串混为一谈时,Guava 团队都要哭了。– Google Guava
说得好。但是当你的类型系统(例如,Java 或者 C#)到处都允许 NULL 时,你就不能可靠地排除 NULL 的可能性,并且不可避免的会在某个地方混淆。
null 无处不在的可能性造成了这样一个问题,Java 8 添加了 @NonNull 标注,尝试着在它的类型系统中以追溯方式解决这个缺陷。
3. NULL 是一个特例
考虑到 NULL 不是一个值却又起到一个值的作用,NULL 自然地成为各种特别处理方法的课题。
1 | char c = 'A'; |
单个 NUL 字符的例外已经导致无数的错误:API 的怪异行为、安全漏洞和缓冲区溢出。
NULL 是 C 字符串中最糟糕的错误;更确切地说,以 NUL 结尾的字符串是最昂贵的一字节错误。
4.NULL 使 API 变得糟糕
我们可以想象在很多语言中类似的类(Python、JavaScript、Java、C# 等)。
现在假设我们的程序有一个慢的或者占用大量资源的方法,来找到某个人的电话号码——可能通过连通一个网络服务。
为了提高性能,我们将会使用本地存储作为缓存,将一个人名映射到他的电话号码上。
然而,一些人没有电话号码(即他们的电话号码是 nil)。我们仍然会缓存那些信息,所以我们不需要在后面重新填充那些信息。
但是现在意味着我们的结果模棱两可!它可能表示:
- 这个人不存在于缓存中(Alice)
- 这个人存在于缓存中,但是没有电话号码(Tom)
一种情形要求昂贵的重新计算,另一种需要即时的答复。但是我们的代码不够精密来区分这两种情况。
在实际的代码中,像这样的情况经常会以复杂且不易察觉的方式出现。因此,简单通用的 API 可以马上变成特例,迷惑了 null 凌乱行为的来源。
用一个 contains() 方法来修补 Store 类可能会有帮助。但是这引入重复的查找,导致降低性能和竞争条件。
5.NULL 使错误的语言决策更加恶化
6.NULL 难以调试
来解释 NULL 是多么的麻烦,C++ 是一个很好的例子。调用成员函数指向一个 NULL 指针不一定会导致程序崩溃。更糟糕的是:它可能会导致程序崩溃。
7.NULL不可组合
IDEA maven修改pom文件,导致jdk版本重置问题
1 | <properties> |
MAVEN的scope
1 | compile |
EXCEL一点小技巧
正好最近用来有点小用处
1 | 1.从固定的单元格里随机取一个值 |
Flink On Zeppelin上传Jar包的位置
1 | /opt/flink-1.10/flink-1.10.0/lib |
Flink系列深度好文,等待细读
1 | https://www.jianshu.com/c/b6089c70072f |
FastJson直接解析
1 | .map( |
具体的还要试一下,我故意写的很难看来督促自己。。。
FastJson很多坑 准备放弃
配置框架无法访问的问题
1 | 有点脑残了,今天在mac上配置了zeppelin win无法访问,其原因是配置文件中的网络地址写死了 172.0.0.1, 如果想要别尔德位置能够访问的话,必须改变配置为其局域网id |
解决GitHub提交历史头像不显示问题,以及首页没有绿色方块的问题
1 | 最近把本地的一个项目提交推送到GitHub的时候发现有两个问题, |
解决anaconda无法连接的问题
1 | win10下更换清华镜像后无法连接 是因为win10里面无法解析https协议,修改~\.condarc文件,把https换成http |
排查挖矿程序中会用到的一些追踪某个进程的命令
1 | 查看PID启动文件的路径 |
Kerberos缺点
1 | 1、KDC 有单点风险,除非设置HA系统(Aictive Directory 可以做到这一点,目前apache directoryserver 也可以做到这一点); |
mac无法运行.sh文件的解决办法
1 | 今天解决了一下内网穿透的问题, |
解决git下载速度慢的终极方法
因为本地的网络始终有一些问题,再忍受了很久很久的龟速下载之后,终于找了个一个非常顶的方法
前提是现有一个vpn,但是vpn不会自动代理git的流量,不管是在windows下面还是在mac下面都不会自动代理git,这点一直让我十分苦恼,现在终于找到了一劳永逸的办法
1 | git config --global http.proxy 'socks5://127.0.0.1:1080' |
简单说明:vpn一般都是走的1080端口,通过这个端口转发git的流量,跳过本地运营商。
取消代理
1 | # 取消代理 |
Maven代理配置
不需要配置什么https或者http模式,在有代理的前提下,只要配置一个代理即可
1 | <proxy> |
要注意的是监控一下端口,如果代理没开的话那肯定是无法连接上的,mirror就不用设置了,直接从中央仓库拉去数据。
npm更换源
1 | //设置淘宝源 |
其实感觉应该把Mac管理node的brew n弄一下
HDFS的某个错误
HBase和Flink在运行的时候报错
hbase启动后region自动挂了,Flink任务失败,文件丢失,然后查看hdfs日志
错误原因 dfs.datanode.max.transfer.threads 的参数4096,已经不足以支持现在的Thread,修改为2倍或者4倍或者更多
IDEA MAVEN停止加载
经常遇到大型项目idea 停止加载mvn,然后就没办法了。。
1 | maven -> maven goal idea的maven第六个按钮 |
窗口触发的一些问题
窗口是按 watermark 触发的,watermark 如果没有前进到 window end , window 是不会触发的。
Flink的窗口触发具体机制需要去源码里面探寻
Flink SQL中的爆炸函数
Lateral View() 在Flink SQL中是unnest
1 | SELECT users, tag FROM Orders CROSS JOIN UNNEST(tags) AS t (tag) |
Flink UI在Yarn下
1 | Flink UI 在 Yarn下很多选线卡看不到详细信息,很正常,因为Yarn这个运行模式有的消息只能在Yarn上管理控制 |
Flink的时区问题
1 | Flink的时间戳差了8个小时,可以用时间减去八个小时时差,生成一个减去8小时的列,作为watermark的时间戳。 |
Flink的心跳需求问题
1 | 使用flink sql在实时计算当天凌晨截止到现在的累计数据的时候,计算步长是10分钟,如果这10分钟内没有新数据达到的话,现在的情况是这10分钟没有写记录,这就会造成业务查这个数据的时候需要找last value这种情形,设计一条方案让没有数据到达的时候也生成一条记录,这条记录的值就是last value。 |
Flink避免重复劳动的一些方法
1 | 1.写DDL+DML分别声明数据源和进行数据处理。 |
oppo:


Flink配置参数
1 | # 开启 distinct agg 切分 |
1 | TableEnvironment tEnv = ... |
Flink GlobalWindow
1 |
|
无法运行,加个triggle(xxx)解决,默认是NeverTrigger
1 | .... |
如何排查Kafka消息的异常
1 | 记录住报错时的kafka offset,然后分阶段打印到控制台,再对比一下,把输出的格式分别调为Row.class 以前pojo类,或注释下一阶段代码,回放kafka 故障的offset数据,各个stream排查 |
MySQL的迁移
1 | --涉及到MySQL的迁移,我这边推荐少量数据的话使用MySQLDump. |
1 | --带docker的命令 |
远程调试Flink

https://stackoverflow.com/questions/34816847/debugging-on-the-remote-cluster
Log4J 和 slf4j联合使用
slf4j是什么?slf4j只是定义了一组日志接口,但并未提供任何实现,既然这样,为什么要用slf4j呢?log4j不是已经满足要求了吗?
是的,log4j满足了要求,但是,日志框架并不只有log4j一个,你喜欢用log4j,有的人可能更喜欢logback,有的人甚至用jdk自带的日志框架,这种情况下,如果你要依赖别人的jar,整个系统就用了两个日志框架,如果你依赖10个jar,每个jar用的日志框架都不同,岂不是一个工程用了10个日志框架,那就乱了!
如果你的代码使用slf4j的接口,具体日志实现框架你喜欢用log4j,其他人的代码也用slf4j的接口,具体实现未知,那你依赖其他人jar包时,整个工程就只会用到log4j日志框架,这是一种典型的门面模式应用,与jvm思想相同,我们面向slf4j写日志代码,slf4j处理具体日志实现框架之间的差异,正如我们面向jvm写java代码,jvm处理操作系统之间的差异,结果就是,一处编写,到处运行。况且,现在越来越多的开源工具都在用slf4j了
1 | <dependency> |
然后,弄到slf4j与log4j的关联jar包,通过这个东西,将对slf4j接口的调用转换为对log4j的调用,不同的日志实现框架,这个转换工具不同
1 | <dependency> |
以及原来的
1 | <dependency> |
Log4J2的使用
Log4J2和Log4J1的比较
配置文件
log4j是通过一个**.properties的文件作为主配置文件的,而现在的log4j 2则已经弃用了这种方式,采用的是.xml,.json或者.jsn**这种方式。
依赖
log4j只需要引入一个依赖
1 | <dependency> |
log4j 2则是需要2个核心
1 | <dependency> |
配置文件
log4J.properties
1 | #此句为定义名为stdout的输出端是哪种类型,可以是 |
log4j2.xml
1 |
|
调用
log4j
1 | import org.apache.log4j.Logger; |
log4j2
1 | import org.apache.logging.log4j.Level; |
Spark On Yarn 结束任务的方式
1 | 1、yarn app -kill appid 丢数据或者多数据 |
1 | 我们用的第一种 针对丢数据或者多数据 我们代码里把实时过来的数据checkpoint 下一次再跑的时候会去mysql里修改offset Kafka再读进来的数据和上次checkpoint的数据对比一下 去重 |
CharSequence
第一次见到这个CharSequence的时候感觉挺疑惑的,不知道为什么要有这个东西。这个CharSequence是String和Stringbuilder共同实现的接口类,在下面这种应用场景中,只有CharSequence是适用的。
1 | String str = "abc"; |
并发编程,创建多少个线程合适
分为两种情况讨论,CPU密集型和 I/O密集型
在CPU密集型的程序中,理论上 线程数量 = CPU 核数(逻辑)就可以了,但是实际上,数量一般会设置为 CPU 核数(逻辑)+ 1,
计算(CPU)密集型的线程恰好在某时因为发生一个页错误或者因其他原因而暂停,刚好有一个“额外”的线程,可以确保在这种情况下CPU周期不会中断工作。
在I/O密集型程序的程序中,单核心线程数一般来说是这么设置的:
最佳线程数 = (1/CPU利用率) = 1 + (I/O耗时/CPU耗时)
多核心的线程数为:
最佳线程数 = CPU核心数 * (1/CPU利用率) = CPU核心数 * (1 + (I/O耗时/CPU耗时))
如果都是IO耗时的话,可以从纯理论上直接回答是2N或者2N+1
还有很多APM(Application Performance Manager)工具可以帮我们得到具体的数据比如 SkyWalking、CAT、zipkin
假设要求一个系统的 TPS(Transaction Per Second 或者 Task Per Second)至少为20,然后假设每个Transaction由一个线程完成,继续假设平均每个线程处理一个Transaction的时间为4s
如何设计线程个数,使得可以在1s内处理完20个Transaction?
但是,但是,这是因为没有考虑到CPU数目。家里又没矿,一般服务器的CPU核数为16或者32,如果有80个线程,那么肯定会带来太多不必要的线程上下文切换开销(希望这句话你可以主动说出来),这就需要调优了,来做到最佳 balance
计算操作需要5ms,DB操作需要 100ms,对于一台 8个CPU的服务器,怎么设置线程数呢?
线程数 = 8 * (1 + 100/5) = 168 (个)
Google AutoValue
Google的 AutoValue 用起来说实话不是特别方便,对于一些需要用到映射的支持也不是十分友好,总之一句话,在国内的生态下是不太适合使用的,虽然EffectiveJava的作者嗯吹这个组件。
https://www.jianshu.com/p/e778e96fb751
这篇博客和AutoValue在Github上面自己的文档算是讲的比较好一点的文档。
Idea 注释模板设置
https://blog.csdn.net/shadow_zed/article/details/80551460#commentBox
Python中使用.join()替代+处理字符串
https://towardsdatascience.com/do-not-use-to-join-strings-in-python-f89908307273
存储图片
1.使用CDN 等技术替代数据库存储。
2.存储选择特殊文件系统,比如S3、淘宝的TFS等等
数据库里面尽量只要写路径
java的一些包的解释
PO(persistant object) 持久对象
在o/r映射的时候出现的概念,如果没有o/r映射,没有这个概念存在了。通常对应数据模型(数据库),本身还有部分业务逻辑的处理。可以看成是与数据库 中的表相映射的java对象。最简单的PO就是对应数据库中某个表中的一条记录,多个记录可以用PO的集合。PO中应该不包含任何对数据库的操作。
VO(value object) 值对象
通常用于业务层之间的数据传递,和PO一样也是仅仅包含数据而已。但应是抽象出的业务对象,可以和表对应,也可以不,这根据业务的需要.个人觉得同DTO(数据传输对象),在web上传递。
TO(Transfer Object),数据传输对象
在应用程序不同tie(关系)之间传输的对象
BO(business object) 业务对象
从业务模型的角度看,见UML元件领域模型中的领域对象。封装业务逻辑的java对象,通过调用DAO方法,结合PO,VO进行业务操作。
POJO(plain ordinary java object)
简单无规则java对象
纯的传统意义的java对象。就是说在一些Object/Relation Mapping工具中,能够做到维护数据库表记录的persisent object完全是一个符合Java Bean规范的纯Java对象,没有增加别的属性和方法。我的理解就是最基本的Java Bean,只有属性字段及setter和getter方法。
DAO(data access object) 数据访问对象
是一个sun的一个标准j2ee设计模式,这个模式中有个接口就是DAO,它负持久层的操作。为业务层提供接口。此对象用于访问数据库。通常和PO结合使 用,DAO中包含了各种数据库的操作方法。通过它的方法,结合PO对数据库进行相关的操作。夹在业务逻辑与数据库资源中间。配合VO, 提供数据库的CRUD操作…
IDEA2020 显示内存大小
双击shift 填入
1 | show memory indicator |
在里面打开ON
Java程序结束前运行的代码
1 | public class ShutdownTest { |
Java8 try()…catch()
1 | // 这个FileWriter会自己关掉 |
通常我们使用try…catch()捕获异常的,如果遇到类似IO流的处理,要在finally部分关闭IO流,当然这个是JDK1.7之前的写法了;在JDK7优化后的try-with-resource语句,该语句确保了每个资源,在语句结束时关闭。所谓的资源是指在程序完成后,必须关闭的流对象。写在()里面的流对象对应的类都实现了自动关闭接口AutoCloseable。
idea中设置maven的jvm参数
1 | file->setting->Build,Execution,Deployment->Maven->Runner |
命令行中设置maven的jvm参数
1 | 1. 可以在mvn.cmd(linux中是mvn.sh或mvn)添加set MAVEN_OPTS=-Xmx1g -XX:MaxMetaspaceSize=128m |
String SubString
1 | public static void main(String args[]) { |
通用的空间/地理空间ASL许可的开源Java库
Spatial4j
IntegerCache

1 | public static void main(String[] args) { |
false
true
因为存在这个IntegerCache,-128-127范围内是有Cache对象的,不会新生成。
书单推荐
1 | 《Effective Java中文版》 |
反射API
1 | package com.hugh.draft.reflection; |
简单的Java 反射API,还需要更深入的了解
最详细的Anaconda安装步骤和注意点
1 | https://zhuanlan.zhihu.com/p/32925500 |
CUDA Driver版本选型
1 | https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html#cuda-major-component-versions |

CuDNN版本
CuDNN的版本是和CUDA版本对应,下载页面就能看到,安装十分简单,三个文件夹的文件和外面的一个文件,单独复制到已经安装好的CUDA文件夹中即可。
Maven 阿里云插件仓库配置
1 | <repositories> |
IDEA配置仓库最好用HTTPS
Win上有可能出现如下错误,mac上却没问题,佛了

Spring
五个常用框架

1.spring framework
也就是我们经常说的spring框架,包括了ioc依赖注入,Context上下文、bean管理、springmvc等众多功能模块,其它spring项目比如spring boot也会依赖spring框架。
2.spring boot
它的目标是简化Spring应用和服务的创建、开发与部署,简化了配置文件,使用嵌入式web服务器,含有诸多开箱即用的微服务功能,可以和spring cloud联合部署。
Spring Boot的核心思想是约定大于配置,应用只需要很少的配置即可,简化了应用开发模式。
3.Spring Data
是一个数据访问及操作的工具集,封装了多种数据源的操作能力,包括:jdbc、Redis、MongoDB等。
4.Spring Cloud
是一套完整的微服务解决方案,是一系列不同功能的微服务框架的集合。Spring Cloud基于Spring Boot,简化了分布式系统的开发,集成了服务发现、配置管理、消息总线、负载均衡、断路器、数据监控等各种服务治理能力。比如sleuth提供了全链路追踪能力,Netflix套件提供了hystrix熔断器、zuul网关等众多的治理组件。config组件提供了动态配置能力,bus组件支持使用RabbitMQ、kafka、Activemq等消息队列,实现分布式服务之间的事件通信。
5.Spring Security
主要用于快速构建安全的应用程序和服务,在Spring Boot和Spring Security OAuth2的基础上,可以快速实现常见安全模型,如单点登录,令牌中继和令牌交换。你可以了解一下oauth2授权机制和jwt认证方式。oauth2是一种授权机制,规定了完备的授权、认证流程。JWT全称是JSON Web Token,是一种把认证信息包含在token中的认证实现,oauth2授权机制中就可以应用jwt来作为认证的具体实现方法。

本文涉及的流程与实现默认都是基于最新的5.x版本。
spring中的几个重要概念如下:
1.IOC
IOC,就是控制反转,如最左边,拿公司招聘岗位来举例:
假设一个公司有产品、研发、测试等岗位。如果是公司根据岗位要求,逐个安排人选,如图中向下的箭头,这是正向流程。如果反过来,不用公司来安排候选人,而是由第三方猎头来匹配岗位和候选人,然后进行推荐,如图中向上的箭头,这就是控制反转。
在spring中,对象的属性是由对象自己创建的,就是正向流程;如果属性不是对象创建,而是由spring来自动进行装配,就是控制反转。这里的DI也就是依赖注入,就是实现控制反转的方式。正向流程导致了对象于对象之间的高耦合,IOC可以解决对象耦合的问题,有利于功能的复用,能够使程序的结构变得非常灵活。
2.context上下文和bean
spring进行IOC实现时使用的有两个概念:context上下文和bean。
如中间图所示,所有被spring管理的、由spring创建的、用于依赖注入的对象,就叫做一个bean。Spring创建并完成依赖注入后,所有bean统一放在一个叫做context的上下文中进行管理。
3.AOP
AOP就是面向切面编程。如右面的图,一般程序执行流程是从controller层调用service层、然后service层调用DAO层访问数据,最后在逐层返回结果。
这个是图中向下箭头所示的按程序执行顺序的纵向处理。但是,一个系统中会有多个不同的服务,例如用户服务、商品信息服务等等,每个服务的controller层都需要验证参数,都需要处理异常,如果按照图中红色的部分,对不同服务的纵向处理流程进行横切,在每个切面上完成通用的功能,例如身份认证、验证参数、处理异常等等、这样就不用在每个服务中都写相同的逻辑了,这就是AOP思想解决的问题。
AOP以功能进行划分,对服务顺序执行流程中的不同位置进行横切,完成各服务共同需要实现的功能。
Java加载properties的六种方式
Java加载properties文件的方式主要分为两大类:
一种是通过import java.util.Properties类中的load(InputStream in)方法加载;
另一种是通过import java.util.ResourceBundle类的getBundle(String baseName)方法加载。
1 | package com.util; |
GPS第三方工具
GIS基本概念
- WKT(Well-known text)是开放地理空间联盟OGC(Open GIS Consortium )制定的一种文本标记语言,用于表示矢量几何对象、空间参照系统及空间参照系统之间的转换。
- WKB(well-known binary) 是WKT的二进制表示形式,解决了WKT表达方式冗余的问题,便于传输和在数据库中存储相同的信息
- GeoJSON 一种JSON格式的Feature信息输出格式,它便于被JavaScript等脚本语言处理,OpenLayers等地理库便是采用GeoJSON格式。此外,TopoJSON等更精简的扩展格式
几何对象
WKT可以表示的对象包括以下几种:
- Point, MultiPoint
- LineString, MultiLineString
- Polygon, MultiPolygon
- GeometryCollection
- 可以由多种Geometry组成,如:GEOMETRYCOLLECTION(POINT(4 6),LINESTRING(4 6,7 10)
| Type | Shape | WKT | GeoJSON |
|---|---|---|---|
| Point |  |
POINT (30 10) | { “type”: “Point”, “coordinates”: [30, 10] } |
| LineString |  |
LINESTRING (30 10, 10 30, 40 40) | { “type”: “LineString”, “coordinates”: [ [30, 10], [10, 30], [40, 40] ] } |
| Polygon |  |
POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10)) | { “type”: “Polygon”, “coordinates”: [ [[30, 10], [40, 40], [20, 40], [10, 20], [30, 10]] ] } |
| Polygon |  |
POLYGON ((35 10, 45 45, 15 40, 10 20, 35 10),(20 30, 35 35, 30 20, 20 30)) | { “type”: “Polygon”, “coordinates”: [ [[35, 10], [45, 45], [15, 40], [10, 20], [35, 10]], [[20, 30], [35, 35], [30, 20], [20, 30]] ] } |
| MultiPoint |  |
MULTIPOINT ((10 40), (40 30), (20 20), (30 10)) | { “type”: “MultiPoint”, “coordinates”: [ [10, 40], [40, 30], [20, 20], [30, 10] ] } |
| MultiPoint | |
MULTIPOINT (10 40, 40 30, 20 20, 30 10) | { “type”: “MultiPoint”, “coordinates”: [ [10, 40], [40, 30], [20, 20], [30, 10] ] } |
| MultiLineString |  |
MULTILINESTRING ((10 10, 20 20, 10 40),(40 40, 30 30, 40 20, 30 10)) | { “type”: “MultiLineString”, “coordinates”: [ [[10, 10], [20, 20], [10, 40]], [[40, 40], [30, 30], [40, 20], [30, 10]] ] } |
| MultiPolygon |  |
MULTIPOLYGON (((30 20, 45 40, 10 40, 30 20)),((15 5, 40 10, 10 20, 5 10, 15 5))) | { “type”: “MultiPolygon”, “coordinates”: [ [ [[30, 20], [45, 40], [10, 40], [30, 20]] ], [ [[15, 5], [40, 10], [10, 20], [5, 10], [15, 5]] ] ] } |
| MultiPolygon |  |
MULTIPOLYGON (((40 40, 20 45, 45 30, 40 40)),((20 35, 10 30, 10 10, 30 5, 45 20, 20 35),(30 20, 20 15, 20 25, 30 20))) | { “type”: “MultiPolygon”, “coordinates”: [ [ [[40, 40], [20, 45], [45, 30], [40, 40]] ], [ [[20, 35], [10, 30], [10, 10], [30, 5], [45, 20], [20, 35]], [[30, 20], [20, 15], [20, 25], [30, 20]] ] ] } |
WKB格式
WKB采用二进制进行存储,更方便于计算机处理,因此广泛运用于数据的传输与存储,以二位点Point(1 1)为例,
其WKB表达如下:
01 0100 0020 E6100000 000000000000F03F 000000000000F03F

- byteOrder
表示编码方式,00为使用big-endian编码(XDR),01为使用little-endian编码(NDR)。他们的不同仅限于在内存中放置字节的顺序,比如我们将0x1234abcd写入到以0×0000开始的内存中,则结果如下表:
Address big-endian little-endian 0×0000 0x12 0xcd 0×0001 0x34 0xab 0×0002 0xab 0x34 0×0003 0xcd 0x12
- webTypd
第二到第九字节对矢量数据基本信息进行了定义
- 第二与第三个字节规定了矢量数据的类型,如例子中的0100代表Point;
- 第三与第四个字节规定了矢量数据的维数,如例子中的0020代表该点是二位的;
- 第五到第九个字节规定了矢量数据的空间参考SRID,如例子中的E6100000是4326的整数十六位进制表达
- srid
- 第五到第九个字节规定了矢量数据的空间参考SRID,如例子中的E6100000是4326的整数十六位进制表达
- structPoint
- 第十个字节开始,每16个字节就代表一个坐标对,如例子中的000000000000F03F是浮点型1的十六进制表达
JTS
简介
- JTS是加拿大的 Vivid Solutions公司做的一套开放源码的 Java API。它提供了一套空间数据操作的核心算法。为在兼容OGC标准的空间对象模型中进行基础的几何操作提供2D空间谓词API。
操作
表示Geometry对象
1 | package com.alibaba.autonavi; |
火星坐标系
在谷歌还没有发布谷歌地图时,在GIS领域常见的坐标系主要有WGS84经纬度坐标、北京54坐标或西安80坐标等;但自从谷歌地图发布之后,其海量的高清卫星免费影像是让整个GIS领域为之震惊的,但同时也为安全问题带来了一定的隐患。为了对实际坐标进行加密,于是国测局研究了一套算法,凡是公开发布的商业互联网地图,一定要在此加密算法的基础上进行发布,这样一来地图的坐标就与实地的坐标不相符了,于是大家把这种坐标戏称为“火星坐标”,这里我们就针对这一坐标作一些更为详细的说明。
所有的电子地图、导航设备,都需要加入该保密插件。第一步,地图公司测绘地图,测绘完成后,送到国家测绘局,将真实坐标的电子地图,加密成“火星坐标”,这样的地图才是可以出版和发布的,然后才可以让GPS公司处理。第二步,所有的GPS公司,只要需要汽车导航的,需要用到导航电子地图的,都需要在软件中加入该保密算法,将COM口读出来的真实的坐标信号,加密转换成ZF要求的保密的坐标。这样,GPS导航仪和导航电子地图就可以完全匹配,GPS也就可以正常工作了。
GCJ02
GCJ-02是由中国国家测绘局(G表示Guojia国家,C表示Cehui测绘,J表示Ju局)制订的地理信息系统的坐标系统。
中文名:国家测量局02号标准
外文名:GCJ-02
它是一种对经纬度数据的加密算法,即加入随机的偏差。
国内出版的各种地图系统(包括电子形式),必须至少采用GCJ-02对地理位置进行首次加密。
综上所述,其实火星坐标系和GCJ-02是同一种事物,它是国家测量(绘)局制定的02号标准,是一种对经纬度坐标进行非线性的随机加偏算法。
为了响应国家制定的标准,国内所有在线地图服务商(如百度地图、高德地图、搜狗地图和SOSO地图等)和国外部分在线地图服务商(如谷歌地图、必应地图和雅虎地图等)都必须进行GCJ-02加密才对公众进行开放,这就是为什么大家在用地图时总是发现有偏移的原因。
GCJ-02只是一种坐标偏移标准(算法),对投影没有任何限制,如果再以投影为基础作细分
PrototBuf

IDEA莫名其妙每次自动生成变量都有final修饰符

FlinkKafka兼容性
| Maven Dependency | Supported since | Consumer and Producer Class name | Kafka version | Notes |
|---|---|---|---|---|
| flink-connector-kafka-0.8_2.11 | 1.0.0 | FlinkKafkaConsumer08 FlinkKafkaProducer08 | 0.8.x | Uses the SimpleConsumer API of Kafka internally. Offsets are committed to ZK by Flink. |
| flink-connector-kafka-0.9_2.11 | 1.0.0 | FlinkKafkaConsumer09 FlinkKafkaProducer09 | 0.9.x | Uses the new Consumer API Kafka. |
| flink-connector-kafka-0.10_2.11 | 1.2.0 | FlinkKafkaConsumer010 FlinkKafkaProducer010 | 0.10.x | This connector supports Kafka messages with timestamps both for producing and consuming. |
| flink-connector-kafka-0.11_2.11 | 1.4.0 | FlinkKafkaConsumer011 FlinkKafkaProducer011 | 0.11.x | Since 0.11.x Kafka does not support scala 2.10. This connectorsupports Kafka transactional messaging to provide exactly once semantic for the producer. |
| flink-connector-kafka_2.11 | 1.7.0 | FlinkKafkaConsumer FlinkKafkaProducer | >= 1.0.0 | This universal Kafka connector attempts to track the latest version of the Kafka client.The version of the client it uses may change between Flink releases.Modern Kafka clients are backwards compatible with broker versions 0.10.0 or later.However for Kafka 0.11.x and 0.10.x versions, we recommend using dedicatedflink-connector-kafka-0.11_2.11 and flink-connector-kafka-0.10_2.11 respectively.Attention: as of Flink 1.7 the universal Kafka connector is considered to be in a BETA status and might not be as stable as the 0.11 connector. In case of problems withthe universal connector, you can try to use flink-connector-kafka-0.11_2.11 which should be compatible with all of the Kafka versions starting from 0.11. |
关于数据仓库数据中台数据湖的一部分图片






元数据管理还有个普元元数据
Mac版本的终端要走Proxy除了梯子还需要一个设置
1 | ➜ ~ vim ~/.zshrc |
1 | # proxy list |
1 | ➜ ~ source ~/.zshrc |
1 | 切换: |
无状态 和 有状态 的区别
在整个程序生态圈中,无状态的意思总是 不需要自己手动关闭,有状态的意识是 总是需要自己手动关闭
Linux Command
most + more + less
more, less and most are three pagers, we can compare them this way:
lessis more thanmore,mostis more thanmore, aproximatly,lessandmostare different, none is better.
linux通过进程号查看运行文件目录
1 | ll /proc/{进程号}/cwd |
CentOS查看版本
1 | hostnamectl |
文件目录大小常见的命令
1 | flyhugh@MacBook-Pro-2 ~/Documents/Env pwd |
Linux生僻命令
在两个文件夹之间来回切换
1 | cd - |
递归创建目录
1 | mkdir -p |
Win10网络问题汇总
用无线网有个问题就是电脑开机时间久了 加上我使用科学上网频繁开关,导致网络会有错乱问题,在系统开了很多东西的情况下,直接重启,导致了网络错误,打开IDEA的时候出现了错误提示
1 | Internal error. Please refer to http://jb.gg/ide/critical-startup-errors |
这个错误造成的原因就是hypervisior(Windows 10的Hyper-V虚拟机),把端口保留了
解决方法也很简单,hypervisior重新开关一下
1 | Disable hyper-v (which will required a couple of restarts) |
实际使用中第一个命令执行完直接重启就行了。
win10图形化查看端口占用工具
cports
重置win10网络命令
netsh winsock reset
win10远程窗口大小不可调的问题
我的显示器分辨率比较高,两台显示器都是4K分辨率的,但是远程的时候默认是锁定1600 * 1200的
并且默认是窗口化的,无法调整大小,这个时候需要使用命令行配置一下远程窗口的分辨率
1 | mstsc /w:2560 /h:1440 /f |
这个命令分别是长宽和全屏设置。
给win10商店设置代理
最近发现。。。只要有一个好的代理服务器,win10的商店原来也是能随便打开的,这里介绍一下win10的商店的流量怎么走代理
1 | 首先通过 Win + R 快捷键打开「运行」窗口,输入「Regedit」打开注册表编辑器,然后定位到 HKEY_CURRENT_USER\Software\Classes\Local Settings\Software\Microsoft\Windows\CurrentVersion\AppContainer\Mappings,接着在左边的注册表项中找到你想解除网络隔离的应用,右边的 DisplayName 就是应用名称,而左边那一大串字符就是应用的 SID 值了。 |
找到这个值之后,然后在cmd命令行中输入:
CheckNetIsolation.exe loopbackexempt -a -p=SID
这SID就是上面搜索到的,这样就行
关于SSTap转发UDP的问题
查看SSTap是否成功转发UDP需要用到一个工具,netcat,简称nc,使用这个工具,在命令行中
1 | .\nc64.exe -u ip 10000 |
就可以像服务器发送UDP请求,然后在服务器上使用root用户
1 | tcpdump udp port 10000 |
就可以查看转发日志
Tips:我在ubuntu上设置的ss-server 默认是不打开udp的端口的,需要在开启的时候手动打开。(加上 -u)
1 | nohup ss-server -c /etc/shadowsocks.json -u |
验证:
1 | netstat -lnp | grep 10000 |
1 | root@ubuntu:/home/ubuntu# netstat -lnp | grep 10000 |
如图可以看到端口已经开放了udp和tcp即可,udp是无状态的,不会显示LISTEN,这个是正确的。
最终结论:是服务器上的SSR没有开启UDP转发,默认是不转发UDP的,这个是有问题的。
win10 访问墙外世界的最终办法:
使用 SSTap这类软件,SSTap是比较简单的,复杂的软件会有流量分流等等功能。
SSTap新建了一个虚拟网卡,所有的流量从新的虚拟网卡中转发出去,不用再考虑软件的流量进出口有没有被代理等等问题。
Win下Chrome无法访问新浪外链地址
拓展解决:
https://chrome.google.com/webstore/detail/wbimgfix/bdhgcfmghkbbdmejdaadfdhhdjphogkp/related
云服务器通过转发windows的3389端口,实现远程对PC的访问
https://www.jianshu.com/p/939dd2f78399
使用了文中的方法,需要注意的方法不是很多,一个是和 ssh 配置有关的问题,最后采用的配置文件,我在最后贴出来(这种配置文件下可以使用root帐号登录)。配置完成后使用
1 | systemctl restart sshd |
重启服务。
登录用到的keygen需要在cygwin64的文件系统中单独保存,使用的并不是windows下面的路径。
我最终使用的命令是
1 | ssh -o ServerAliveInterval=180 -i /home/key/id_rsa_oracle_2 root@#服务器IP# -p 22 -R #以后远程登录要使用的端口,不建议使用3389,为了安全#:127.0.0.1:3389 -fN |
ssh配置文件:
1 | $OpenBSD: sshd_config,v 1.100 2016/08/15 12:32:04 naddy Exp $ |
这种访问方式有点过于笨重,后来采用了frp工具来实现了远程代理
https://zhuanlan.zhihu.com/p/138092534
BT下载 扔掉迅雷
Aria2 下载解压
配置文件 下载解压
按照顺序使用管理员打开
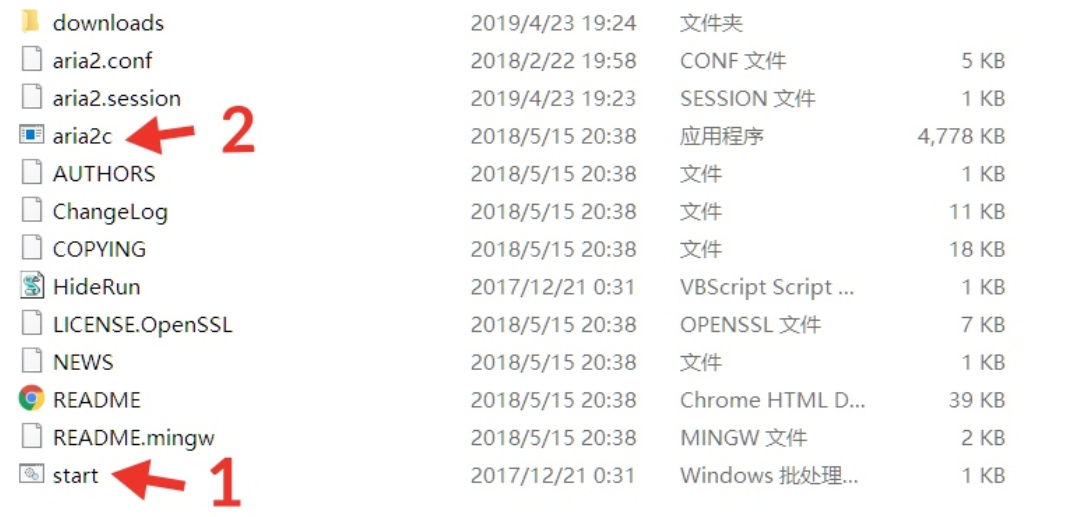
默认的下载目录为
downloads,可通过修改aria2.conf配置文件改变下载目录。Aria2的没有自带下载面板的,因此需要自行下载第三方的面板。
常用的Aria2_Web有YAAW、webui-aria2、AriaNg
1 | YAAW:https://github.com/binux/yaaw/archive/master.zip |
我这里尝试使用AriaNg,下载下来直接点击那个网页就能使用,修改一下tracker
https://trackerslist.com/#/zh?id=xiu2trackerslistcollection
Tracker列表
网络知识
TCP/IP
建立TCP需要三次握手才能建立(客户端发起SYN,服务端SYN+ACK,客户端ACK),
断开连接则需要四次握手(客户端和服务端都可以发起,FIN-ACK-FIN-ACK)。
为什么连接的时候是三次握手,关闭的时候却是四次握手?
答:
因为当Server端收到Client端的SYN连接请求报文后,可以直接发送SYN+ACK报文。其中ACK报文是用来应答的,SYN报文是用来同步的。但是关闭连接时,当Server端收到FIN报文时,很可能并不会立即关闭SOCKET,所以只能先回复一个ACK报文,告诉Client端,”你发的FIN报文我收到了”。只有等到Server端所有的报文都发送完了,我才能发送FIN报文,因此不能一起发送。故需要四步握手。
SYN攻击:发送大量的SYN,导致服务端无法识别哪些是有效的
RPC
RPC是指远程调用,两服务器A,B,A要调用B上的一个方法,由于不在一个内存空间,不能直接调用,需要通过网络来表达调用的语义和传达调用的数据
通讯问题:在客户端和服务端建立TCP连接,远程调用的所有交换数据都在这个连接里传输。
解决寻址问题:IP及端口寻址,方法名
序列化(Serialize):发生远程调用时,方法的参数需要通过底层的网络协议如TCP传送到服务器,由于网络协议是基于二进制的,内存中的参数值需要序列化成二进制的形式,通过寻址和传输序列化的二进制发送给服务器。
服务器反序列化:服务器收到请求后需要反序列化,恢复内存中的表达方式,然后找到对应的方法(寻址的一部分),进行本地调用。
返回值发送给客户端,这个部分也需要序列化和反序列化。
SOA
采用一组服务的方式来构建一个应用,服务(hedwig、jsf、RESTful)独立部署在不同的进程中,不同服务通过一些轻量级交互机制来通信,例如RPC、HTTP等。服务可独立扩展伸缩,每个服务定义了明确的边界,不同的服务甚至可以采用不同的编程语言来实现,由独立的团队来维护。
RPC 的实现是基于SOA这样的一个架构 C/S模式 远程调用的通讯使用TCP 然后hedwig restful jsf这些就是不同的服务形式
**http协议和tcp/ip 协议的关系
**(1) http是应用层协议,tcp协议是传输层协议,ip协议是网络协议。
(2) IP协议主要解决网络路由和寻址问题
(3) tcp协议主要解决在IP层协议之上,如何可靠的传输数据,即接收端收到的数据包的大小和顺序,和发送端保持一致。tcp协议是可靠的面相连接的。
1. http协议是无状态的,指的是http协议对于事务处理没有记忆功能,客户端向服务端请求完数据之后,服务端不知道客户端是什么状态。
2. http的长连接和短连接,本质上是tcp层的长连接和短连接:
http 1.0 默认使用短连接,http 1.1 默认使用长连接,在使用的http协议,在响应头会加上 Connection:keep-alive
3. RPC比http请求快的原因:http使用http协议,rpc使用tcp协议,比http少了应用层,表示层,会话层,这3层,rpc使用长连接,而长连接比短连接更节省资源,效率更高(每个连接的建立和释放都是需要资源和时间的)。
TCP/IP
是个协议组,可分为三个层次:网络层、传输层和应用层。
在网络层有IP协议、ICMP协议、ARP协议、RARP协议和BOOTP协议。
在传输层中有TCP协议与UDP协议。
在应用层有:TCP包括FTP、HTTP、TELNET、SMTP等协议
UDP包括DNS、TFTP等协议
当网络通信时采用TCP协议时,在真正的读写操作之前,server与client之间必须建立一个连接,当读写操作完成后,双方不再需要这个连接时它们可以释放这个连接,连接的建立是需要三次握手的,而释放则需要4次握手,所以说每个连接的建立都是需要资源消耗和时间消耗的。
通信过程:
主机 A 的应用程序要能和主机 B 的应用程序通信,必须通过 Socket 建立连接,而建立 Socket 连接必须需要底层 TCP/IP 协议来建立 TCP 连接。建立 TCP 连接需要底层 IP 协议来寻址网络中的主机。我们知道网络层使用的 IP 协议可以帮助我们根据 IP 地址来找到目标主机,但是一台主机上可能运行着多个应用程序,如何才能与指定的应用程序通信就要通过 TCP 或 UPD 的地址也就是端口号来指定。这样就可以通过一个 Socket 实例唯一代表一个主机上的一个应用程序的通信链路了。
建立通信链路
当客户端要与服务端通信,客户端首先要创建一个 Socket 实例,操作系统将为这个 Socket 实例分配一个没有被使用的本地端口号,并创建一个包含本地和远程地址和端口号的套接字数据结构,这个数据结构将一直保存在系统中直到这个连接关闭。在创建 Socket 实例的构造函数正确返回之前,将要进行 TCP 的三次握手协议,TCP 握手协议完成后,Socket 实例对象将创建完成,否则将抛出 IOException 错误。
与之对应的服务端将创建一个 ServerSocket 实例,ServerSocket 创建比较简单只要指定的端口号没有被占用,一般实例创建都会成功,同时操作系统也会为 ServerSocket 实例创建一个底层数据结构,这个数据结构中包含指定监听的端口号和包含监听地址的通配符,通常情况下都是“*”即监听所有地址。之后当调用 accept() 方法时,将进入阻塞状态,等待客户端的请求。当一个新的请求到来时,将为这个连接创建一个新的套接字数据结构,该套接字数据的信息包含的地址和端口信息正是请求源地址和端口。这个新创建的数据结构将会关联到 ServerSocket 实例的一个未完成的连接数据结构列表中,注意这时服务端与之对应的 Socket 实例并没有完成创建,而要等到与客户端的三次握手完成后,这个服务端的Socket 实例才会返回,并将这个 Socket 实例对应的数据结构从未完成列表中移到已完成列表中。所以 ServerSocket 所关联的列表中每个数据结构,都代表与一个客户端的建立的TCP 连接。
TCP短连接
TCP短连接,client向server发起连接请求,server接到请求,然后双方建立连接。client向server 发送消息,server回应client,然后一次读写就完成了,这时候双方任何一个都可以发起close操作,不过一般都是client先发起 close操作。因为一般的server不会回复完client后立即关闭连接的,当然不排除有特殊的情况。从上面的描述看,短连接一般只会在client/server间传递一次读写操作。短连接的优点是:管理起来比较简单,存在的连接都是有用的连接,不需要额外的控制手段。
TCP长连接
长连接,client向server发起连接,server接受client连接,双方建立连接。Client与server完成一次读写之后,它们之间的连接并不会主动关闭,后续的读写操作会继续使用这个连接。
TCP保活功能,保活功能主要为服务器应用提供,服务器应用希望知道客户主机是否崩溃,从而可以代表客户使用资 源。如果客户已经消失,使得服务器上保留一个半开放的连接,而服务器又在等待来自客户端的数据,则服务器将应远等待客户端的数据,保活功能就是试图在服务器端检测到这种半开放的连接。如果一个给定的连接在两小时内没有任何的动作,则服务器就向客户发一个探测报文段。客户主机必须处于以下4个状态之一:
1.客户主机依然正常运行,并从服务器可达。客户的TCP响应正常,而服务器也知道对方是正常的,服务器在两小时后将保活定时器复位。
2.客户主机已经崩溃,并且关闭或者正在重新启动。在任何一种情况下,客户的TCP都没有响应。服务端将不能收到对探测的响应,并在75秒后超时。服务器总共发送10个这样的探测 ,每个间隔75秒。如果服务器没有收到一个响应,它就认为客户主机已经关闭并终止连接。
3.客户主机崩溃并已经重新启动。服务器将收到一个对其保活探测的响应,这个响应是一个复位,使得服务器终止这个连接。
4.客户机正常运行,但是服务器不可达,这种情况与2类似,TCP能发现的就是没有收到探查的响应。
从上面可以看出,TCP保活功能主要为探测长连接的存活状况,不过这里存在一个问题,存活功能的探测周期太长,还有就是它只是探测TCP连接的存活,属于比较斯文的做法,遇到恶意的连接时,保活功能就不够使了。
在长连接的应用场景下,client端一般不会主动关闭它们之间的连接,Client与server之间的连接如果一直不关闭的话,会存在一个问 题,随着客户端连接越来越多,server早晚有扛不住的时候,这时候server端需要采取一些策略,如关闭一些长时间没有读写事件发生的连接,这样可以避免一些恶意连接导致server端服务受损;如果条件再允许就可以以客户端机器为颗粒度,限制每个客户端的最大长连接数,这样可以完全避免某个蛋疼的客户端连累后端服务。
长连接和短连接的产生在于client和server采取的关闭策略,具体的应用场景采用具体的策略,没有十全十美的选择,只有合适的选择。
HTTP长连接与短连接
长连接:client方与server方先建立连接,连接建立后不断开,然后再进行报文发送和接收。
这种方式下由于通讯连接一直存在。此种方式常用于P2P通信。
短连接:Client方与server每进行一次报文收发交易时才进行通讯连接,交易完毕后立即断开连接。
此方式常用于一点对多点通讯。C/S通信。
长连接和短连接异同
长连接:长连接多用于操作频繁,点对点的通讯,而且连接数不能太多的情况。
每个TCP连接的建立都需要三次握手,每个TCP连接的断开要四次握手。
如果每次操作都要建立连接然后再操作的话处理速度会降低,所以每次操作后,下次操作时直接发送数据就可以了,不用再建立TCP连接。例如:数据库的连接用长连接,如果用短连接频繁的通信会造成socket错误,频繁的socket创建也是对资源的浪费。
\短连接\:**web网站的http服务一般都用短连接。因为长连接对于服务器来说要耗费一定的资源。像web网站这么频繁的成千上万甚至上亿客户端的连接用短连接更省一些资源。试想如果都用长连接,而且同时用成千上万的用户,每个用户都占有一个连接的话,可想而知服务器的压力有多大。所以并发量大,但是每个用户又不需频繁操作的情况下需要短连接。
发送接收方式
1、异步:报文发送和接收是分开的,相互独立,互不影响的。这种方式又分两种情况:
异步双工:接收和发送在同一个程序中,有两个不同的子进程分别负责发送和接送。
异步单工:接送和发送使用两个不同的程序来完成。
2、同步:报文发送和接收是同步进行,即报文发送后等待接送返回报文。同步方式一般需要考虑超时问题,试想我们发送报文以后也不能无限等待啊,所以我们要设定一个等待时候。超过等待时间发送方不再等待读返回报文。直接通知超时返回。
阻塞与非阻塞方式
1、非阻塞方式:读函数不停的进行读动作,如果没有报文接收到,等待一段时间后超时返回,这种情况一般需要指定超时时间。
2、阻塞方式:如果没有接收到报文,则读函数一直处于等待状态,知道报文到达。
及时通信与游戏的长短连接
实际场合究竟需要使用短连接还是长连接,主要看实时性要求、数据流向和并发量这三个问题。
长连接优点:节约TCP握手时间,可以保证高实时性,数据流向可以采用服务器端的主动推模式。
长连接缺点:并发量不宜太高,持续占用服务端口(相对消耗资源)。
长连接、长轮询一般应用与WebIM、ChatRoom和一些需要及时交互的网站应用中。其真实案例有:WebQQ、Hi网页版、Facebook IM等。
1.现在游戏中的玩家与玩家之间的聊天无法实现实时性,而且系统有邮件或信息时也不能及时的通知玩家
—— 如果涉及到聊天的话,一般来说还是用长连接会更合适,否则大量时间浪费到握手上了;
—— 但是手机的网络长连接网络质量可能会比较撮,你需要严重考虑容错和重链机制。
2.客户端每隔几秒就会发送一个请求,这样服务器的压力岂不是很大?
—— 压力会比较大,关键是聊天往往对时间的要求很高,如果是团战的话,1秒内没看到信息,可能就会觉得完全受不了了;当然也看你聊天的场景如何,是群聊还是单聊,以后会不会发展为语音啥的;
NIO没有任何问题,大规模长连接处理的主流都是用NIO;而且也不是Java发明的,本身就是借助了操作系统的网络管理能力。
http keep-alive与tcp keep-alive,不是同一回事,意图不一样。http keep-alive是为了让tcp活得更久一点,以便在同一个连接上传送多个http,提高socket的效率。而tcp keep-alive是TCP的一种检测TCP连接状况的保鲜机制
Maven问题汇总
1 | <plugin> |
上面的这个插件 antrun里面的命令在linux环境下使用bash没有问题,在linux环境下应该配置bash
Maven手动添加Jar包之后没有加载
File->Setting->Maven->Repositories->Update(选择本地仓库的路径)
Active 使用遇到的坑
线上activemq内存超过限制,导致生产者无法推送告警信息。Activemq重启,导致部分堆积数据丢失
考虑一下ActiveMQ的监控
Redis持久化
RDB模式全栈快照,当内存比较大,访问比较频繁时(我们的设备实时信息是典形的写多读少,异于一般的写少读多的情况),刷新频率高,磁盘IO要求非常大。
AOF模式,文件体大,Rewrite时会有RDB类似的情况
AOF重写或是RDB进行Dump时都会fork子进程,当Redis使用物理内存过半时,会失败
LinkedList等队列size()
JDK自带队列size()需要遍历集合,如果集合数据比较大,且该函数比较频繁访问情况下,可能会有性能问题。并发接近万数量级慎用
(可以用Stopwatch监控程序每个步骤运行时间)
开源协议

Flink问题汇总
Flink使用滑动窗口出现的一个问题
使用滑动窗口保存checkpoint失败,日志里面没有错误日志,个别情况下在使用不同的时间语义会出现成功的情况。
Flink数据写入了HDFS,Hive没有识别
1.11版本,需要设置sink.partition.commit参数,分区表
Flink-1.12.0编译密码:
flink-runtime-web工程有几个特点,
=> 在网络OK,别的问题都没有的情况下,第一次编译成功,后面编译的话会报错(npm或者node.js被占用的错误),也就是说,只有第一次能编译成功。
时空数据结构简介
后面如果有时间的话 会把这部分独立出去重新整理一章
所谓时空数据,顾名思义,包含了两个维度的信息:空间信息与时间信息。空间信息,以地理位置点最为基础,还包括线、多边形以及更为复杂的多维结构。最典型的时空数据,莫过于移动对象的轨迹点数据,如每隔5秒钟记录的车辆实时位置信息。这类数据,在物联网领域司空见惯,在可预见的未来,这类数据将会出现爆炸性的增长。
关于时空索引,这里,了解到的主流技术有R-Trees、Quad-Trees、K-D Trees以及Space Filling Curve这四种技术。
RTree
R-Trees源自论文《R-Trees: A Dynamic Index Structure For Spatial Searching》,下面的图也源自此论文:

R-Trees基于这样的思想设计:
每一个空间对象,如一个多边形区域,都存在一个最小的矩形,能够恰好包含此时空对象,如上图中的矩形R6所包含的弯月形区域。这个最小包围矩形被称之为MBR(Minimum Bounding Rectangle)。
多个相邻的矩形,可以被包含在一个更大的最小包围矩形中。如R6、R9以及R10三个矩形,可以被包含在R3中,而R11与R12则被包含在R4中。
继续迭代,总能找到若干个最大的区域,以一种树状的形式,将所有的时空对象给容纳进去,如上图中的R1, R2。这样,整个树状结构,呈现如下:

从最小的矩形区域,到最大的矩形区域,就好比地图中的行政区域划分:村 -> 县 -> 市 -> 省份。查询时,先从锁定的最大区域开始,逐级缩小比例尺后,就可找到最终的对象。如若将上图中的R1与R2理解成两个平级的”行政区域”,却又存在本质的区别:不同的行政区域,并不存在相互重叠,而R1与R2却可能是重叠的。
R-Trees的定义:
每一个Leaf Node包含m到M个索引记录(Root节点除外)。
每一个索引记录是一个关于(I, tuple-identifier)的二元组信息,I是空间对象的最小包围矩形,而tuple-identifier用来描述空间对象本身。
每一个Non-leaf节点,包含m到M个子节点(Root节点除外)。
Non-leaf节点上的每一个数据元素,是一个(I, child-pointer)的二元组信息,child-pointer指向其中一个子节点,而I则是这个子节点上所有矩形的最小包围矩形。
上图中,R3、R4以及R5,共同构成一个non-leaf节如点,R3指向包含元素R8,R9以及R10的子节点,这个指针就是child-pointer,而与R8,R9以及R10相关的最小包围矩形,就是I。
- Root节点至少包含两个子节点,除非它本身也是一个Leaf Node。
- 所有的Leaf Nodes都出现在树的同一层上。
从定义上来看,R-Trees与B-Trees存在诸多类似:Root节点与Non-Leaf节点,均包含限定数量的子节点;所有的Leaf Nodes都出现在树的同一层上。这两种树也都是自平衡的。
前面也已经提到了,B-Trees主要用来存放一维排序的数据元素,而R-Tree存放的则是多维空间数据元素。从查询方式上来看,两者也存在显著的差异:B-Trees更擅长于数据点查,它的设计并不利于数据的范围查询。基于空间元素的查询,却以范围查询为主,而且往往需要对多个子树进行并行查询,例如,在地图上划定某一个区域,查询这个区域内有哪些公园,可能有多个子树都与划定的这个区域存在交集。从这一点看来,R-Tree的搜索性能其实并没有很好的保障。
R-Trees有多种变种,如R+-Trees,R*-Trees,X-Trees, M-Trees,BR-Trees等等,不再展开过多的介绍。
Quad-Trees
HBase中的数据按照RowKey单维度排序组织,而我们现在却面临的是一个多维数据问题。因此,HBase如果想很好的支持时空数据的存储,需要引入时空索引技术。

上图中的A,B,C,E,F,G均为Point,以每一个Point作为中心点,可以将一个区间分成4个象限。
假设,先写入Point A,以A为中心,将整个区间分成了4个象限。
写入Point B,Point B位于A的东北象限中,同样,以B为中心,依然可以将A东北象限进一步细分为4个子象限。
写入Point C,Point C位于A的东南象限中,以C为中心,可以将A的东南象限细分成4个子象限。
…..
任何新写入的一个Point,总能找到一个某一个已存在的Point的子象限,来存放这个新的Point。
整个树状结构呈现如下:

可见,Quad-Trees有几个鲜明的特点:1. 对于非叶子节点,均包含4个子节点,对应4个面积不一的象限。2.不平衡,树的结构与数据的写入顺序直接相关。3.有空的Leaf Nodes,且所有的Leaf Nodes则是”参差不齐”的(并不一定都出现在树的同一层中)。4.数据既可能出现在分枝节点中,也可能出现在叶子节点中。
因为Quad-Trees存在诸多变种,为了有所区分,上面提到的最简单的这种Quad-Tree,被称之为Point Quad-Trees。还有一种典型的Quad-Trees,被称之为Point Region QuadTrees(简称为PR QuadTrees):

PR Quad-Trees中,每一次迭代出来的4个象限,面积相同,且不依赖于用户数据Point作为分割点,或者说,数据分区与用户数据无关。每一个划分出来的子象限中,只允许存在一个Point。
与Point Quad-Trees相比,PR Quad-Trees允许两份不同的数据集,拥有相同的分区信息。但PR Quad-Trees存在的问题也明显:1. 两个相邻的Points,可能在树的Level高度上相隔甚远。2.两份数据集如果追求相同的分区信息,可能需要进行足够粒度的分割,这可能导致空间浪费。
K-D Trees
K-D Trees是一种针对高维点向量数据的索引结构,一棵简单的K-D Tree如下图所示(原图源自James Fogarty的”K-D Trees and Quad Trees”,但为了更直观,关于分区分割线的线条做了改动):

与Quad Trees思想类似,K-D Trees也是将整个区间进行不断分割,不同之处在于,Quad Trees每一次迭代,将一个区间分割成四个象限,而K-D Trees则是分成左右或上下两个区间。如上图所示:S1把整个空间分成了左右两个区间,左侧区间中,又被S2横向分割成了上下两个区间,而S3又在S2的分割基础上,将下部分分割成了左右两个区间,….
Space Filling Curve
如果将一个完整的二维空间,分割成一个个大小相同的矩形,可以将Space Filling Curve简单理解为它是一种将所有的矩形区域用一条线”串”起来的方法,因”串”的方式不同,也就引申出了不同的Space Filling Curve算法。
比较典型的如Z-Order Curve:

再如Hilbert Curve:

GeoMesa使用了基于Z-order填充曲线的GeoHash空间索引技术, 并针对时间维度进行了扩展,具体分为: • Z2:空间,点索引 • Z3:时间+空间,点索引 • XZ2:空间,线\面索引 • XZ3:时间+空间,线\面索引。
为什么选择了RTree =>
- 原先的项目中选择
RTree - 别的项目没有
RTree这么成熟的工业库

RTree的优化方向比较好找RTree可以理解为BTree的多维版本,相对来说比较熟悉,此外R树还可以退化成一维,但是分割的线段存在重叠问题,效果不如Btree。
R树的操作
搜索
R树的搜索操作很简单,跟B树上的搜索十分相似。它返回的结果是所有符合查找信息的记录条目。而输入是什么?输入不仅仅是一个范围了,它更可以看成是一个空间中的矩形。也就是说,我们输入的是一个搜索矩形。
插入
R树的插入操作也同B树的插入操作类似。当新的数据记录需要被添加入叶子结点时,若叶子结点溢出,那么我们需要对叶子结点进行分裂操作。显然,叶子结点的插入操作会比搜索操作要复杂。插入操作需要一些辅助方法才能够完成。
来看一下伪代码:
删除
R树的删除操作与B树的删除操作会有所不同,不过同B树一样,会涉及到压缩等操作。相信读者看完以下的伪代码之后会有所体会。R树的删除同样是比较复杂的,需要用到一些辅助函数来完成整个操作。
优化
- 为了最小化内存使用可以针对数据类型优化–>
1 | Rectangle r = Geometries.rectangle(1.0, 2.0, 3.0, 4.0); |
理论上这样使用RTree消耗的内存只有Double的一半。
- 使用R-Tree的变种 R*-Tree,对数据结构进行了优化,并且同样存在成熟的常用项目
RTee2可以使用。
Base4BigData(Version.1)
MapReduce
MapReduce产生的灵感来源于2004年Google发表的《MapReduce》论文中的大数据计算模型,用于大规模数据集(TB甚至PB级)的并行计算,利用分治策略,将计算过程分两个阶段,Map阶段和Reduce阶段,可谓是第一代大数据分布式计算引擎,为后来各类优秀的大数据计算引擎的出现提供了基础和可行性。
架构
MapReduce 1.x架构如下:
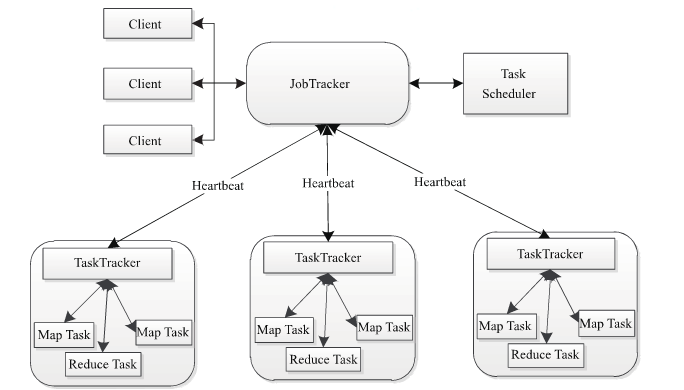
- 客户端向
JobTracker提交任务 JobTraker将任务拆解为多个子任务,分配给TaskTracker执行TaskTracker定时与JobTracker保持心跳,汇报任务执行情况
存在的问题:
- 单点故障:一旦JobTracker出现故障,会导致任务无法提交和正常执行
- JobTracker负载高:所有的任务的提交和分配以及资源管理都是由JobTracker控制,压力过于集中
- 场景有限制:只能运行MapReduce作业,可兼容性差
为了解决MR v1的问题,MapReduce v2引入了资源管理器YARN (Yet Another Resource Negotiator),即新一代的MapReduce 2.0。
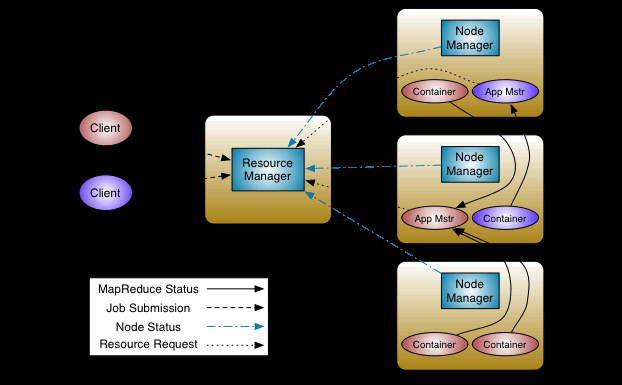
YARN中的重要角色及功能:
ResourceManager:资源管理节点(RM),对应MR v1的JobTracker
- 负责处理来自客户端的提交的Job
- 启动Application Master管理任务
- 监控Application Master状态
- 为NodeManager分配资源(CPU、内存、磁盘、网络)
NodeManager:工作节点(NM),对应MR v1的TaskTracker
- 管理节点container任务资源和运行情况
- 与ResourceManager保持通信,汇报自身的状态
Application Master:任务管理服务(AM),其实就是ResourceManager的小弟
- 负责检查集群资源,申请mr程序所需资源
- 分配任务到相应的container容器执行
- 监控任务执行状态并向ResourceManager汇报任务执行情况
Container:YARN资源抽象,封装了节点上的资源,如内存、CPU、磁盘等
YARN的优势:
- ResourceManager支持HA,解决了JobTracker单点故障的问题,提高集群可用性
- 实现资源管理和job管理分离,解决了JobTracker负载高的难题
- 提供Application Master负责监控所有的任务,解决了JobTracker集中管理监控的压力
- 高扩展性,不仅可以跑mr任务,还支持spark作业以及其他计算引擎任务
- 提高了资源的利用率
MapReduce核心计算阶段
Mapper阶段:负责数据 的载入、解析、转换和过滤,map任务的输出被称为中间键和中间值
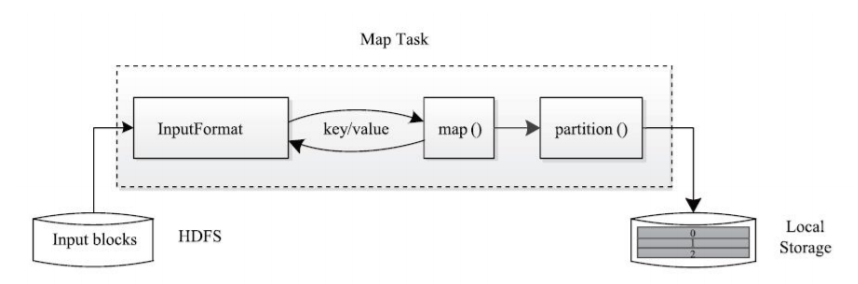
Reducer阶段:负责处理map任务输出结果,对map任务处理完的结果集进行排序、局部聚合计算再汇总结果
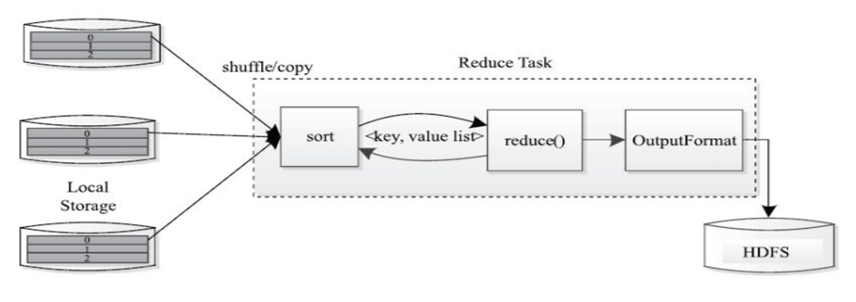
MapReduce为什么慢?
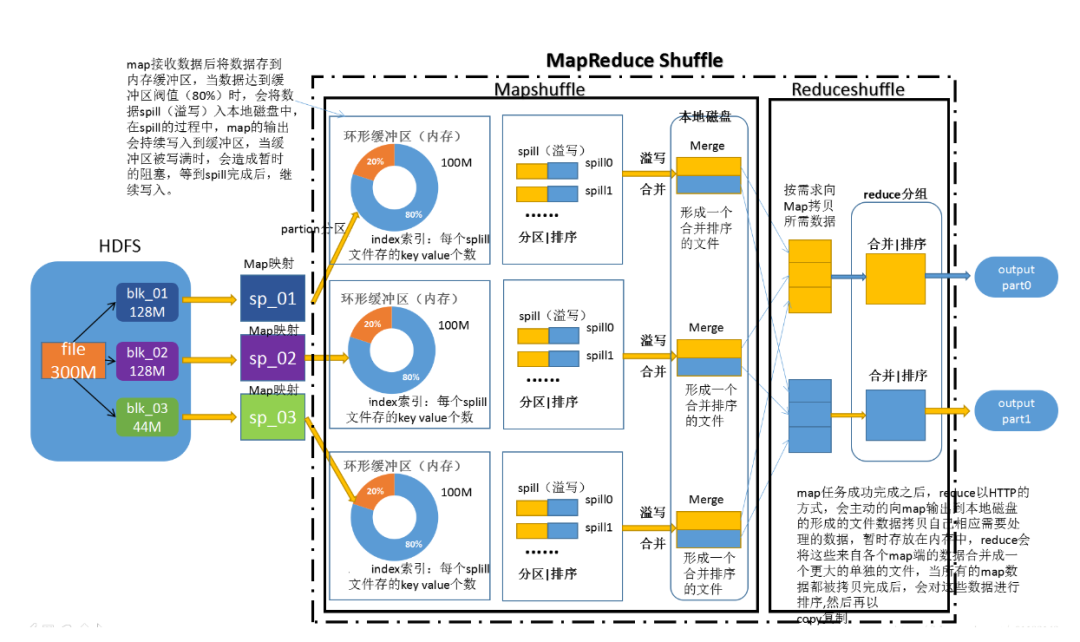
- MapReduce是基于磁盘数据进行计算的
- Shuffle过程进行一系列分区、排序,耗费大量时间
- map计算结果频繁落盘
- reduce任务通过磁盘获取数据,占用IO
- spill会会产生大量的小文件,极大占用集群的资源
- 容错性差,错了就重头来过
- MapReduce抽象层次低,只有map和reduce两种,处理数据效率较低
因此MapReduce只适用于处理大规模离线数据,延时高。MapReduce的局限性推动了计算引擎技术的革新,Spark的出现是为了解决MapReduce计算慢的问题,随着数据量的指数增长,对数据处理效率有了更高的要求,我们需要在更短的时间内得到正确的结果。
Spark
Apache Spark是用于大规模数据处理的统一分析计算引擎,最初诞生于加州大学伯克利分校的AMP Lab实验室。基于内存进行并行计算,通过使用最先进的DAG调度器、查询优化器和物理执行引擎,实现了批处理和流处理的高性能,与Hadoop MapReduce相比,运行在内存中的计算速度要快上100倍(实际上或许没有快这么多),但是可见spark是要比Hadoop MapReduce计算能力更强的计算引擎。
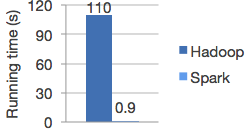
组件角色
Spark由Spark Core、Spark SQL、Spark Streaming、MLib和GraphX四大组件构成 .
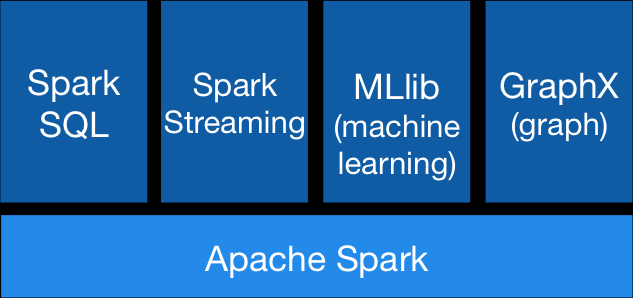
角色说明:
- Spark Core:spark的核心,将数据抽象为弹性分布式数据集(RDD),提供了分布式任务调度,RPC通信、序列化和压缩等特性,是内存计算的框架,用于离线计算
- Spark SQL:基于Spark Core之上用于结构化数据建模和数据处理组件,实现交互式查询
- Spark Streaming:利用Spark Core快速调度能力进行流式计算
- MLib:是Spark上分布式机器学习框架,提供了大量的算法
- GraphX:是Spark上的分布式图形处理框架,能进行高效的图计算
架构
Spark是一个典型的master/slave主从架构,基于内存计算引擎,提供了多种缓存机制,将RDD 缓存到内存或者磁盘中,这种机制使得Spark可以进行迭代计算和数据共享,从而减少数据读取的IO开销,架构如下:
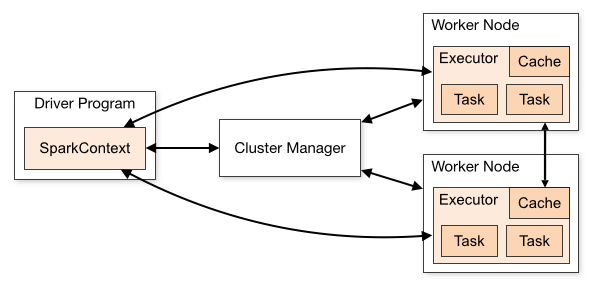
- Driver:初始化Spark运行环境,创建SparkContext上下文环境,是用户程序的入口,即main() 方法
- Cluster Manager:资源管理器,目前支持Standalone、YARN、Mesos和Kubernetes这几种模式,在Standalone模式中,Cluster Manager即为Master节点,控制整个集群
- Worker:spark计算节点,负责计算任务的管理,为task分配并启动Executor,定时向Cluster Manager汇报任务执行情况
- Executor:Spark Task工作的容器,是用户程序在worker节点上的一个进程,运行计算任务,负责数据的读取和写入,缓存中间数据
工作原理
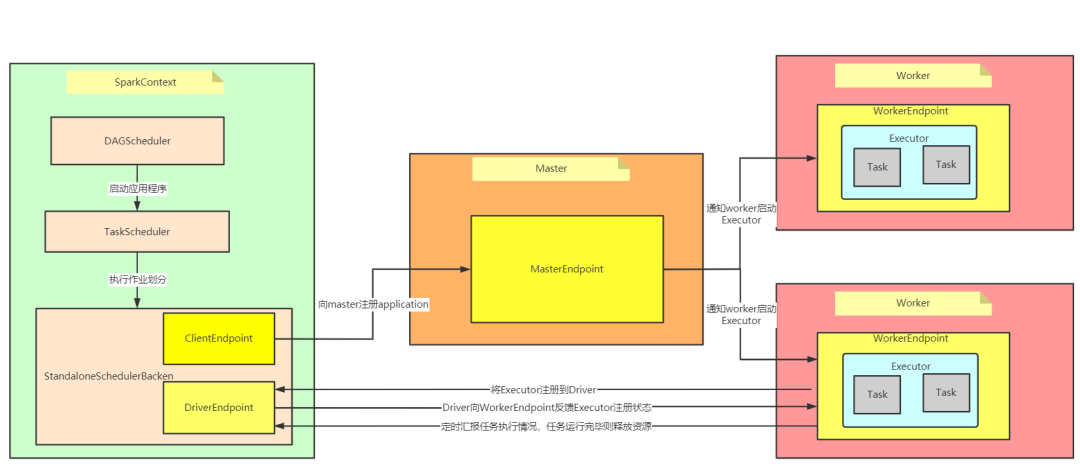
- Driver驱动程序会初始化
SparkContext - 初始化过程中会启动
DAGScheduler和TaskScheduler TaskScheduler通过后台进程向Master注册用户程序- Master收到注册请求之后会通知Worker为用户程序启动多个Executor容器
- Executor反向
SparkContext注册 SparkContext将应用程序发给ExecutorSparkContext完成初始化,构建DAG,创建Job并且根据action操作划分Stage,形成TaskSet发送给TaskScheduler,最后发给Executor执行- 运行完释放资源
Spark 为什么比MapReduce快
- Spark相对于MapReduce减少了磁盘IO,没有太多中间结果落盘
- Spark采用了多线程模型,基于线程池复用降低task线程的开销
- spark提供了多种缓存策略,避免了重复计算
- 灵活的内存管理策略
- Spark的DAG(有向无环图)算法
- 提供丰富的抽象方法,MapReduce只有map和reduce两种抽象
- 缓存和checkpoint,通过lineage实现高度容错性
以上列举了spark比MapReduce快的部分特性,Spark的出现逐步取代了MapReduce成为新一代离线计算引擎的最佳选择,不仅如此,spark还提供了Spark Streaming组件作为流式计算引擎。
Spark Streaming
Spark Streaming是Spark Core API的扩展,支持实时数据流的可伸缩、高吞吐量、容错流处理。支持多种数据源,数据可以从Kafka、Flume、HDFS、S3、Kinesis或TCP套接字等许多来源获取,并可以使用复杂的算法处理,这些算法由map、reduce、join和window等高级函数表达。最后,可以将处理过的数据推送到文件系统、数据库和实时仪表板中。

工作模型
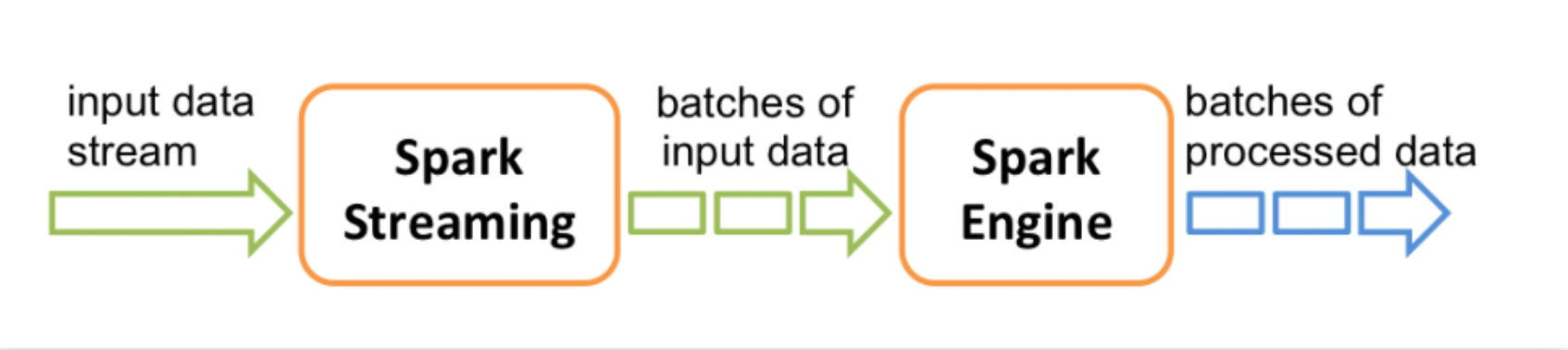
Spark Streaming基于micro batch方式的计算和处理流数据,提供了称为离散流或DStream的高级抽象,它表示连续的数据流。将接收到的数据流切分为多个独立的DStream,本质上也是一系列RDD,通过spark计算引擎进行计算。
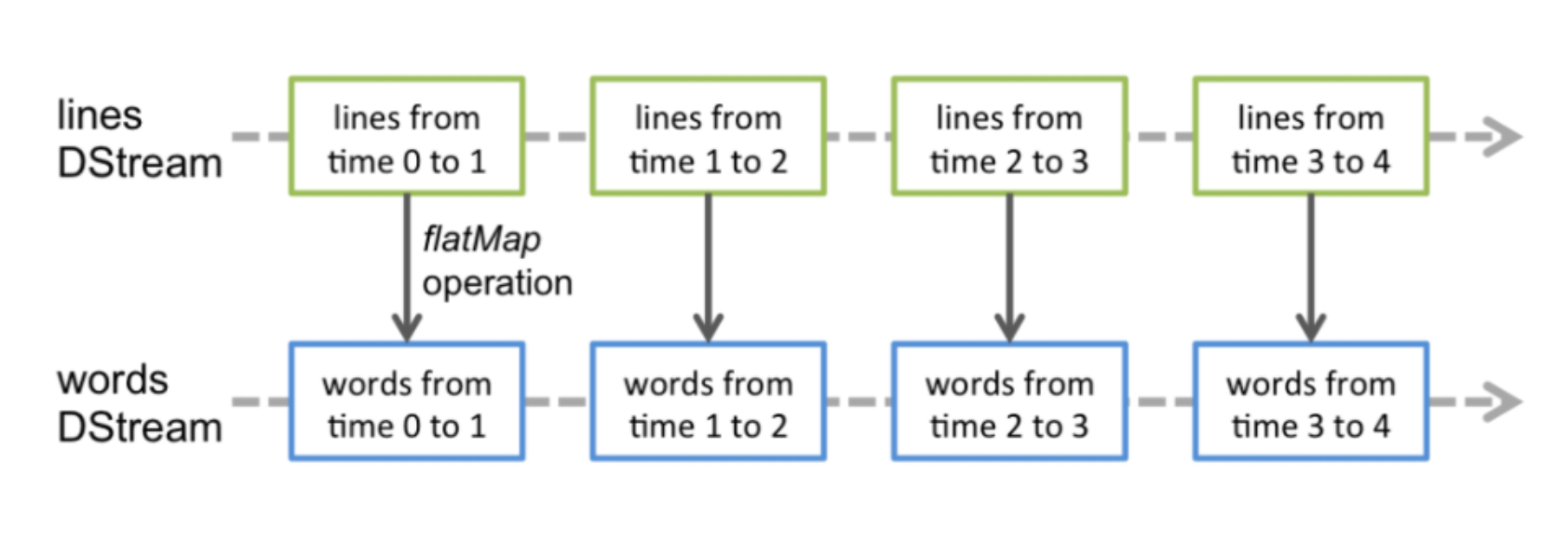
DStreams(Discretized Streams)
离散数据流是Spark Streaming提供的基本抽象,将待处理数据转变为连续不断的数据流,可以是外部数据源转换而来,也可以通过内部流之间的转换生成,从DStream的内部流模型可以看到Dstream就是由一系列的RDD组成。
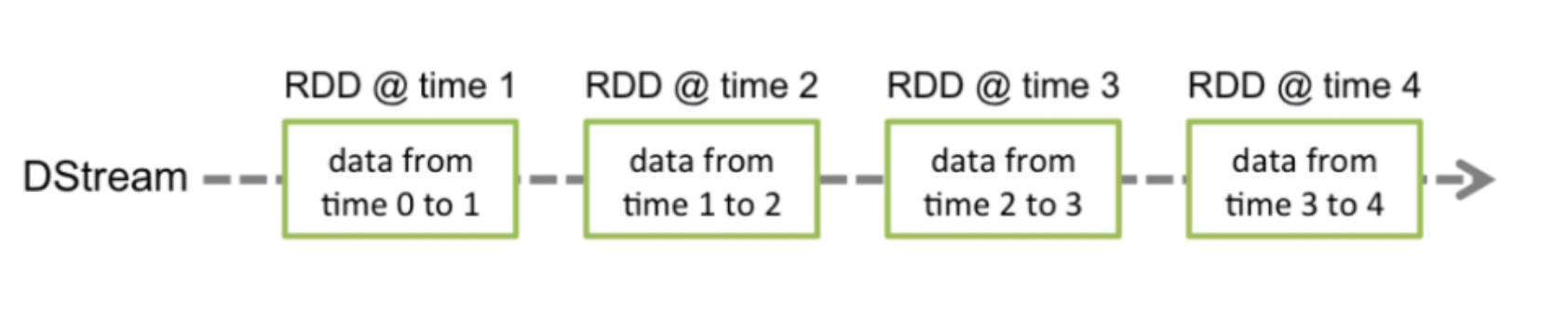
实际上,Dstream执行的操作都会转换为对底层RDD的操作。
Spark Streaming是怎么实现数据实时计算的呢?
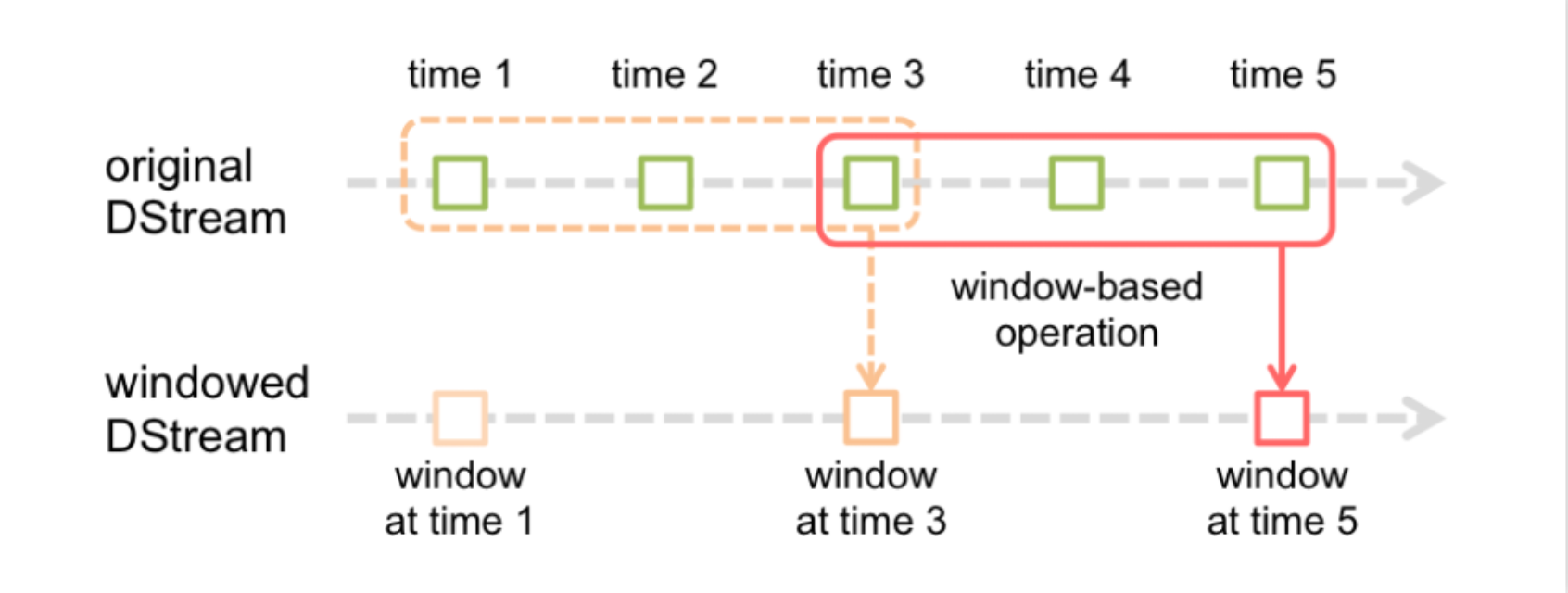
当spark Streaming接收到数据后,会将数据流切分成多个批次,形成有界的数据集,设置时间间隔,当不同批次的数据进入窗口后会触发计算机制,通过Spark Core进行一系列tranformation和action操作,因为划分批次之后的数据比较小,实时计算得出结果。
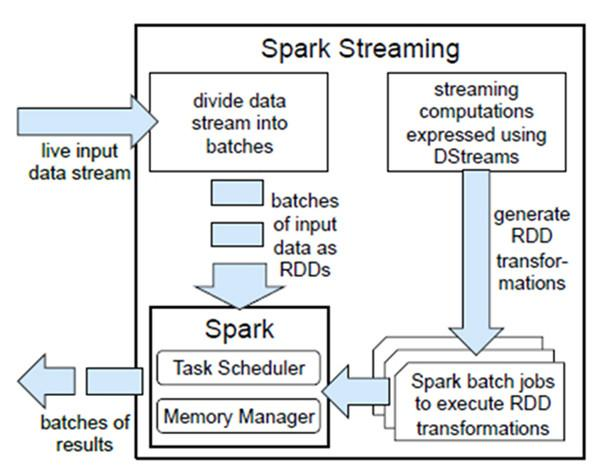
为什么要用Spark Streaming呢?
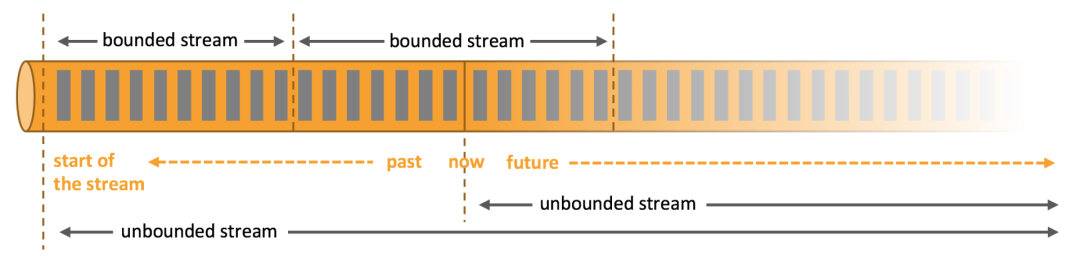
从数据的边界来说,我们可以把数据分为有界数据和无界数据。顾名思义,有界数据是有范围的,一般来说与时间是强关联的,以历史数据最为典型。而无界数据就是难以限定范围的数据,会持续不断发生变化,最常见的场景就是实时数据流,看不到数据的尽头,一直在发生。
MapReduce和Spark SQL等框架只能进行离线计算,无法满足实时性要求高的业务场景,如购买商品后进行实时推荐、实时交易业务等等。而spark Streaming巧妙地将数据细分为多个微小的批次,依赖于spark计算引擎能做到准实时计算,不是真正意义上的实时计算,尽管如此,spark Streaming还是得到了业界的认可和广泛应用。
Spark Streaming优势:
- 实时性:Spark Streaming 是一个实时计算框架,微批处理数据,延迟可以控制到秒级
- 高容错性:Spark Streaming底层依赖RDD lineage特性、缓存机制、checkpoint机制以及WAL预写日志,可以实现高度容错
- 高吞吐:相对于实时计算框架Storm吞吐量更高
- 一体化:依托spark生态,不仅能进行实时计算,还能应用于机器学习和Spark SQL场景
对于大部分企业来说,秒级的延时是可以接受的,而且一个大数据项目通常会包含离线计算、交互式查询、数据分析、实时计算等模块,Spark Streaming毫无疑问是很好的选择。
Storm
storm是一个真正的实时流计算引擎,相对于Spark Streaming的微批处理,storm则是来一条数据计算一条数据,延时可以控制到毫秒级。
Storm架构
storm的架构与Hadoop相似,都是master/slave主从架构。
| 成员 | Storm | Hadoop |
|---|---|---|
| 主节点 | Nimbus | JobTracker |
| 从节点 | Supervisor | TaskTracker |
| 计算模型 | Spout / Bolt | Map / Reduce |
| 应用程序 | Topology | Job |
| 工作进程 | Worker | Child |
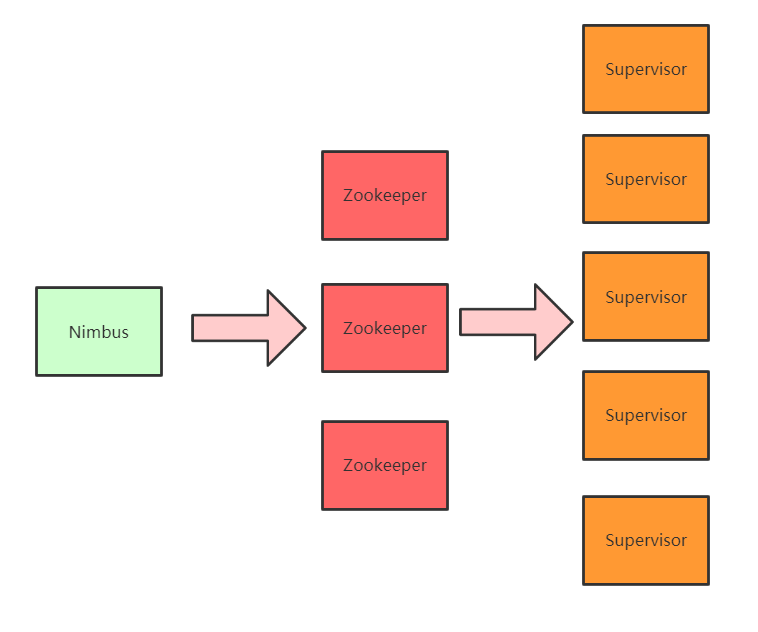
Nimbus:master节点,负责提交任务,分配到supervisor的worker上,运行Topology上的Spout/Bolt任务
Zookeeper:协调节点,负责管理storm集群的元数据信息,比如heartbeat信息、集群状态和配置信息以及Nimbus分配的任务信息等
Supervisor:slave节点,负责管理运行在supervisor节点上的worker进程
Storm工作流程
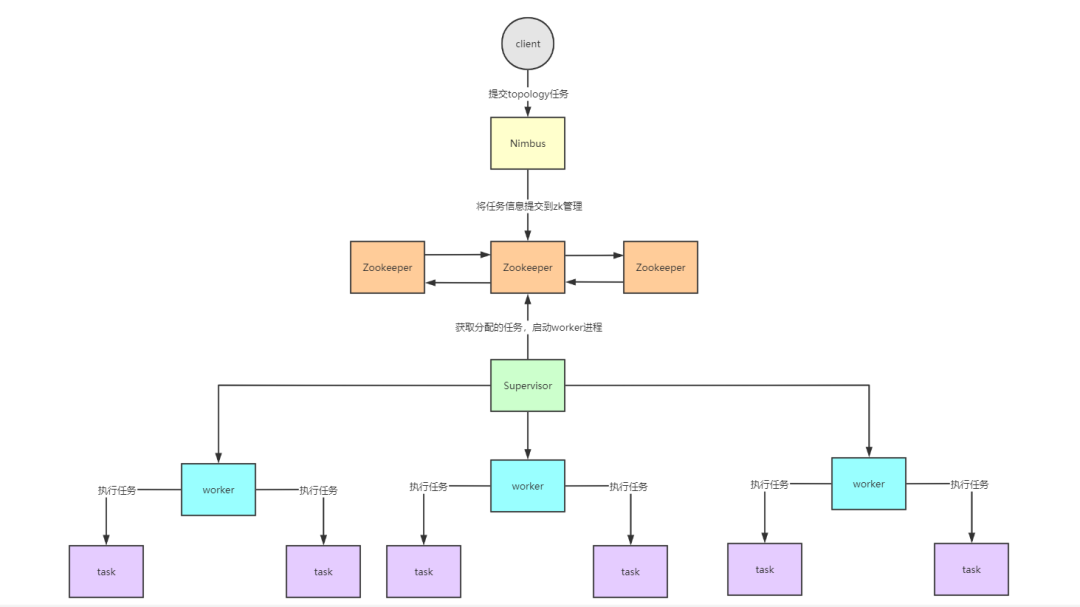
- 客户端提交topology任务到Nimbus节点
- Nimbus主节点将任务提交到zookeeper集群管理
- Supervisor节点从Zookeeper集群获取任务信息
- 启动worker进程开始执行任务
Storm Vs Spark Streaming
用一个生动形象的生活场景来比喻Storm和Spark Streaming,Storm好比是手扶电梯,一直在运行,来一个人都会将他带上/下楼,而Spark Streaming更像是升降电梯,要装满一批人才开始启动。
- storm可以实现毫米级计算响应 VS Spark Streaming只能做到秒级响应
- Storm吞吐量低 VS Spark Streaming吞吐量高
| Item | Storm | Spark Streaming |
|---|---|---|
| Streaming Model | Native | Micro-Batch |
| Guarantees | At-Least-Once | Exactly-Once |
| Back Pressure | No | Yes |
| Latency | Very Low | Low |
| Throughput | Low | High |
| Fault Tolerance | Record ACKs | RDD Based CheckPoint |
| Stateful | No | Yes(DStream) |
Flink
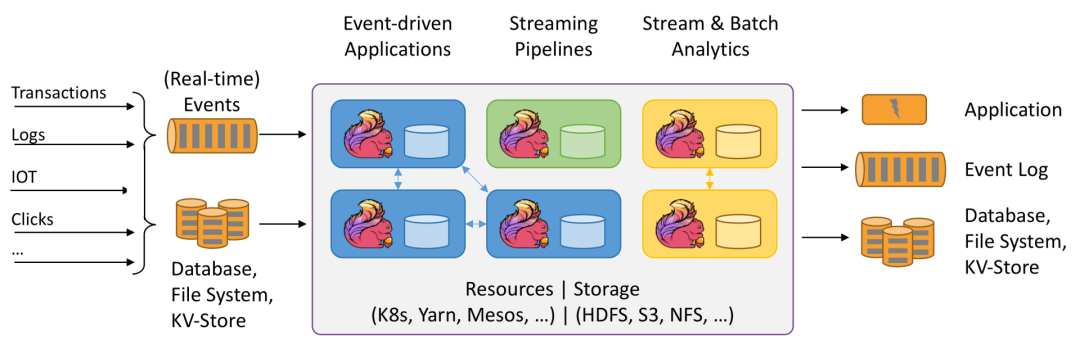
Apache Flink是一个分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。现在Flink也是主流的实时流计算框架并且同时支持批处理,支持基于有状态的事件时间进行计算,成为大数据计算引擎的领头羊,大有盖过Spark风头之势。
擅长处理有界(bounded)数据和无界(unbounded)数据,有界数据通常指的是离线历史数据,用于批处理,而无界数据指数据流有定义数据产生的开始,却无法定义数据何时结束,因此无界数据流通常说的就是实时流,用于实时计算。
架构
Flink和Spark一样,也是主从架构,由JobManager和TaskManager组成
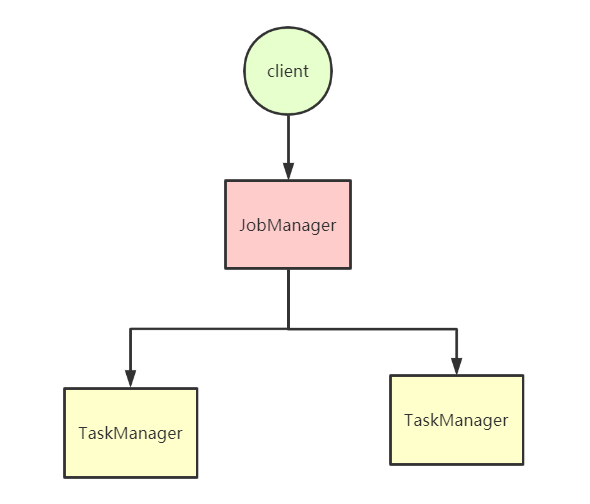
JobManager:主节点,负责处理客户端提交的Job,管理Job状态信息,调度分配集群任务,对完成的 Task 或执行失败做出反应、协调 checkpoint、并且协调从失败中恢复
TaskManager:从节点,负责管理节点上的资源,向JobManager汇报集群状态,执行计算JobManager分配的Task
Flink工作调度
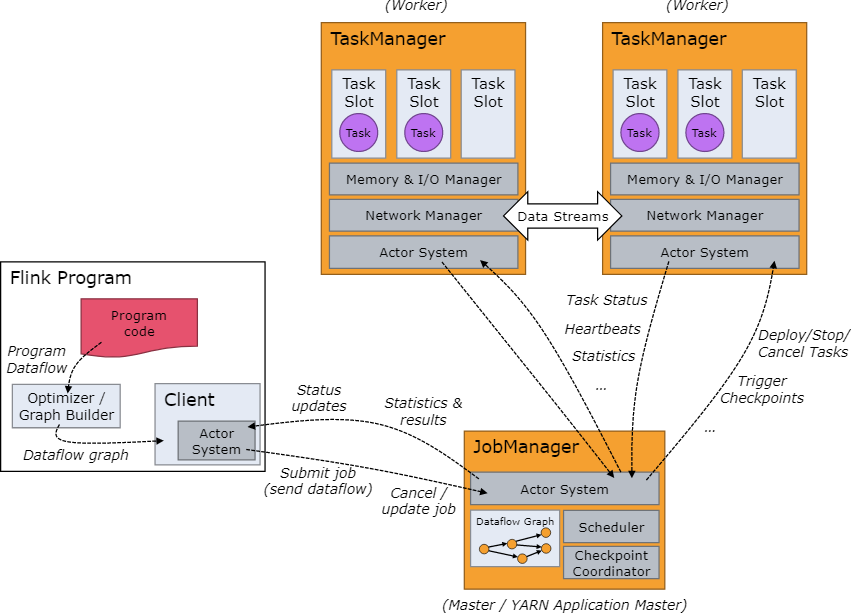
- 用户提交Flink程序时,client会对程序进行预处理,构建Dataflow graph,封装成Job提交到JobManager
- JobManager接收到client提交的Job,获取并管理Job的基本信息,构建DAG执行计划,通过Scheduler调度任务并分配到对应的TaskManager节点
- TaskManager向JobManager注册,JobManager将Job分配到TaskManager执行,每个Task Slot代表着用来执行Task的资源,包括了内存、cpu等
- TaskManager与JobManager保持心跳,定时汇报节点资源情况以及任务执行情况
- JobManager将将任务执行的状态和结果反馈给客户端
Flink的优势
- Flink支持实时计算,且基于内存管理,性能优越
- 具有高吞吐、低延迟、高性能的流处理特性
- Flink与Hadoop生态高度融合
- 高度灵活的时间窗口语义
- 流批一体化,同时支持批处理和流计算
- 高容错,基于分布式快照(snapshot)和checkpoint检查点机制
- 具有反压(Backpressure)功能
- 支持有状态计算的Exactly-once语义
- 可以进行机器学习处理(FlinkML)、图分析(Gelly)、关系数据处理(FLink SQL)以及复杂事件处理(CEP)
Flink VS Storm VS Spark Streaming
| Item | Flink | Storm | Spark Streaming |
|---|---|---|---|
| Streaming Model | Native | Native | Micro-Batch |
| Guarantees | Exactly-Once | At-Least-Once | Exactly-Once |
| Back Pressure | Yes | No | Yes |
| Latency | Medium | Very Low | Low |
| Throughput | High | Low | High |
| Fault Tolerance | Checkouting | Record ACKs | RDD Based CheckPoint |
| Stateful | Yes(Operators) | No | Yes(DStream) |