Apache Kudu
一图以蔽之:
1.Apache Kudu介绍
部分内容翻译自Kudu 1.7.1文档
Kudu是为Apachche Hadoop平台开发的柱状存储管理器,Kudu有Hadoop生态系统应用的普遍技术属性:运行在商业硬件上,可以横向拓展,支持高可用操作。
Kudu的优点包括:
- 快速处理OLAP(联机分析处理)工作负载
- 与MR、Spark和其他Hadoop生态组件整合
- 与Apache Impala紧密结合,使它成为在Apache Parquet使用HDFS的一个好的,可变的替代方案
- 强大但灵活的一致性迷行,允许你根据每个请求选择一致性要求,包括严格可序列化一致性选项
- 同时运行顺序和随机工作负载的强大性能
- 对于管理员,使用Cloudera Manager容易管理
- 高可用、Tablet服务和Master使用共识算法,保证只要超过一半的副本可用,table就可以读写
- 结构化数据模型
通过结合这些特性,Kudu出现的目的是为了解决当前hadoop技术难以达成的应用场景,例如:
- 新到达的数据要被立刻提供给用户报表
- 时间序列应用必须同时支持的:大量历史数据的查询的要求、对某个细颗粒查询迅速返回的时间要求
- 在基于所有历史数据来做出实时决策的预测模型上的应用
2.Kudu与Impala在CDH中的集成

如图只要在impala的配置中配置该项目,配置项目为kudu_master_hosts,配置内容为kudu的master节点,端口号默认为7051
配置完成之后简单测试:
在HUE中调用impala的输入框中输入:
1 | CREATE TABLE my_first_table |
即可建立表格。
1 | insert into my_first_table values (99,"sarah"); |
1 | INSERT INTO my_first_table VALUES (1, "john"), (2, "jane"), (3, "jim"); |
插入语句
1 | select * from my_first_table; |
查表
1 | delete from my_first_table where id =99; |
删除语句
1 | update my_first_table set name='lilei' where id=99; |
改语句
1 | upsert into my_first_table values(1, "john"), (4, "tom"), (99, "lilei1"); |
Kudu中的upsert是update和insert的结合体,有更新就更新,没有该条数据就插入。
这边联想到mongo中的upsert,MongoDB 的update 方法的三个参数是upsert,这个参数是个布尔类型,默认是false。当它为true的时候,update方法会首先查找与第一个参数匹配的记录,在用第二个参数更新之。
1 | db.post.update({count:100},{"$inc":{count:10}},true); |
在找不到count=100这条记录的时候,自动插入一条count=100,然后再加10,最后得到一条 count=110的记录。
Kudu-Impala整合特征
CREATE/ALTER/DROP TABLE
Impala支持使用Kudu作为持久层创建、修改和删除表,这些表和Impala其他表使用同样的内部和外部方法,允许复杂的数据整合和查询。
INSERT
可以使用通用语法插入数据到Kudu-Imapala表格
UPDATE/DELETE
支持SQL命令逐行或者批量修改Kudu表中存在的数据。SQL的语法尽可能与现有的相同。
Flexible Partitioning
和Hive表类似,Kudu也支持hash或者range预先动态分区,以便在集群中均匀读写。你可以通过很多方式分区,比如说任意列的主键,任意数量的哈希。
并行扫描
为了在现在硬件上达到最高可用性能,Impala使用Kudu并行扫描多个客户端。
高效查询
可能的时候,Impala会吧谓词评估推送给kudu,以便尽可能接近数据,在很多工作下,查询性能和Parquet相当。
更多细节需要查询Impala文档。
3. 概念和术语
Columnar Data Store
列存储
Kudu是列存储,列存储是强类型的,通过适当的设计,相对于数仓是优越的,因为几个原因。
Read Efficiency
读取效率
对于分析查询,可以单独读取一列,或者一列的一部分,而忽略其他列。这意味着你可以在磁盘上读取最小的数据来满足查询。
Data Compression
数据压缩
因为是强类型,所以数据的压缩比要比基于行的解决方案效率高几个数量级。
Table
Table是数据存储在Kudu的位置,Table有schema和一个完全有序的主键,一个表被分割成叫做tablets的segment。
Tablet
首先,tablet是table的segment,类似于partition 机制。Tablet里面本身还涉及副本机制等。
Tablet Server
对于Tablet的副本机制来说,每个tablet都会有一个leader,别的是follower,leaders会接收读和写请求,followers只接受读请求。涉及到副本机制就涉及到共识算法,这里面用的共识算法是Raft Consensus Algorithm。
Master
Master跟踪tablets,tablet Server,Catalog Table 以及和Cluster关联的元数据,只能有一个master,如果挂了,那么会用Raft Consensus Algorithm重新选举一个出来。
Raft Consensus Algorithm
和Paxos一样是一个重要的共识算法
Catalog Table
Catalog Table是matadata的核心部位,记录table和tablets的信息,不能直接读写,只能通过Client API进行改动,存储两种类型的数据。
Tables:table的schemas, locations, and states
Tablets:tablets的list,tablet Server的映射关系,states,start and end keys
Logical Replication
逻辑复制:Kudu复制文件仅仅是逻辑上的复制,并没有涉及物理上的复制,这样做有几个好处:
尽管插入和更新操作通过网络传输数据,删除操作不需要移动任何数据。删除操作被送到每一个执行本地删除操作的tablet server。
压缩这样的物理操作,不需要通过网络传输,这和使用HDFS的存储系统是不同的,HDFS中的blocks需要通过网络传输block来满足复制的需求。
Tablets不需要在同一时间压缩,或者其他在物理层上的同步,这降低了tablet因为大量压缩和写入遇到延迟的可能性。
4.Java访问CDH集群中的Kudu
如果使用的不是局域网,跨网段需要进行配置。
需要在KuduMaster服务的高级配置“gflagfile 的 Master 高级配置代码段(安全阀)”增加配置
1 |
|
5.架构概述
下图显示了一个Kudu集群,三个Master和多个table servers,每一个Server服务多个tablets。
这个图表明了Raft共识算法是如何作用在master-tablet server的master和server上的。
此外,一个 tablet server 既可以成为tablets的leader,也可以成为一个别的follower
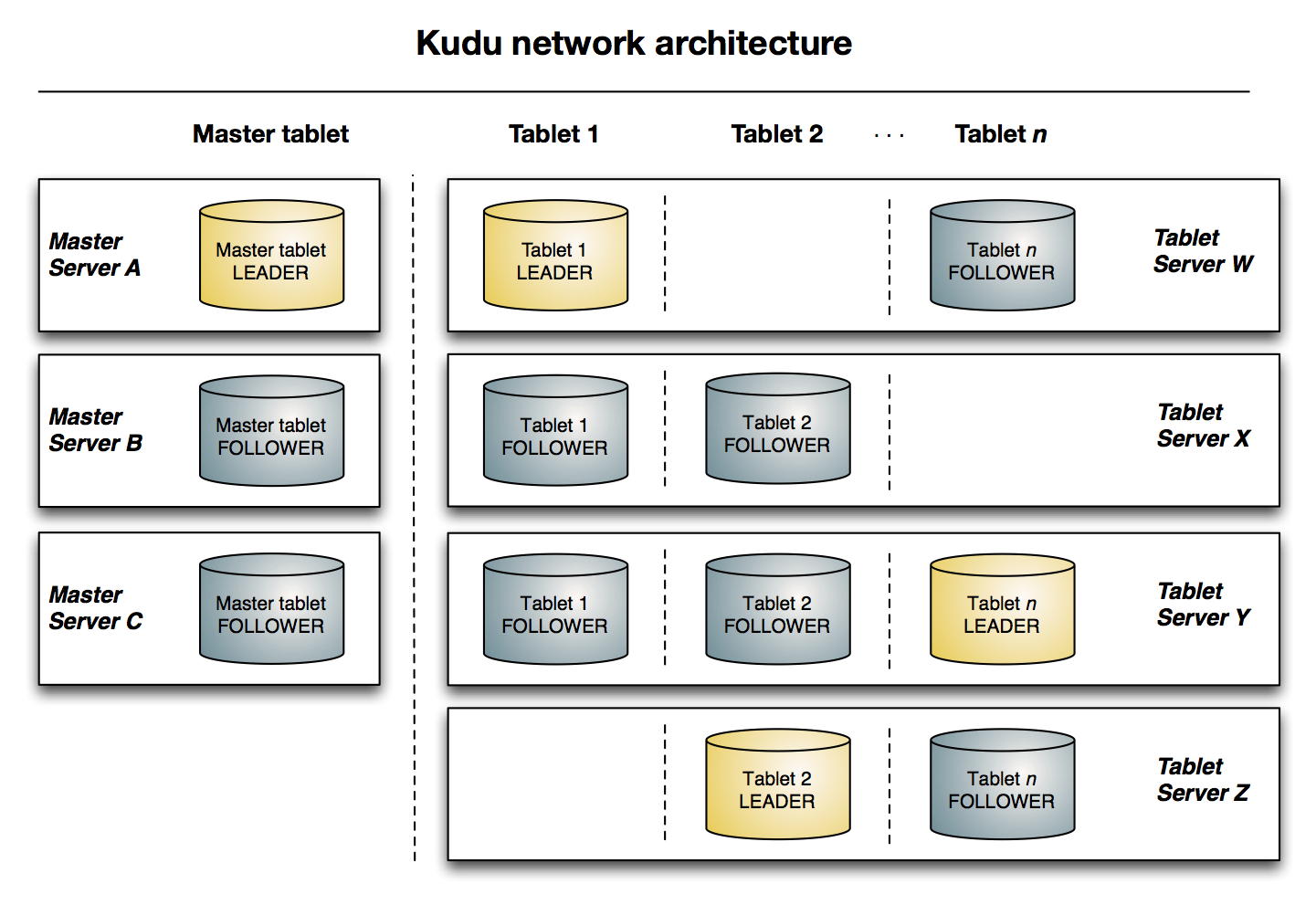
只要有一半以上的副本可用,该tablet便可用于读写,技师在leader tablet出现故障的情况下,读取功能也可以通过read-only(只读)follower tablets来进行服务,或者是leader宕机的情况下,根据raft算法重新选举leader。
开发语言:C++
- 建表的时候要求所有的tserver节点都活着
- 根据raft机制,允许(replication的副本数-)/ 2宕掉,集群还会正常运行,否则会报错找不到ip:7050(7050是rpc的通信端口号),需要注意一个问题,第一次运行的时候要保证集群处于正常状态下,也就是所有的服务都启动,如果运行过程中,允许(replication的副本数-)/ 2宕掉
- 读操作,只要有一台活着的情况下,就可以运行
- KUDU分区数必须预先预定
- 在内存中对每个Tablet分区维护一个MemRowSet来管理最新更新的数据,当尺寸超过32M后Flush到磁盘上形成DiskRowSet,多个DiskRowSet在适当的时候进行归并处理
- 和HBase采用的LSM(LogStructured Merge,很难对数据进行特殊编码,所以处理效率不高)方案不同的是,Kudu对同一行的数据更新记录的合并工作,不是在查询的时候发生的(HBase会将多条更新记录先后Flush到不同的Storefile中,所以读取时需要扫描多个文件,比较rowkey,比较版本等,然后进行更新操作),而是在更新的时候进行,在Kudu中一行数据只会存在于一个DiskRowSet中,避免读操作时的比较合并工作。那Kudu是怎么做到的呢? 对于列式存储的数据文件,要原地变更一行数据是很困难的,所以在Kudu中,对于Flush到磁盘上的DiskRowSet(DRS)数据,实际上是分两种形式存在的,一种是Base的数据,按列式存储格式存在,一旦生成,就不再修改,另一种是Delta文件,存储Base数据中有变更的数据,一个Base文件可以对应多个Delta文件,这种方式意味着,插入数据时相比HBase,需要额外走一次检索流程来判定对应主键的数据是否已经存在。因此,Kudu是牺牲了写性能来换取读取性能的提升。
- 更新、删除操作需要记录到特殊的数据结构里,保存在内存中的DeltaMemStore或磁盘上的DeltaFIle里面。DeltaMemStore是B-Tree实现的,因此速度快,而且可修改。磁盘上的DeltaFIle是二进制的列式的块,和base数据一样都是不可修改的。因此当数据频繁删改的时候,磁盘上会有大量的DeltaFiles文件,Kudu借鉴了Hbase的方式,会定期对这些文件进行合并。
- 既然存在Delta数据,也就意味着数据查询时需要同时检索Base文件和Delta文件,这看起来和HBase的方案似乎又走到一起去了,不同的地方在于,Kudu的Delta文件与Base文件不同,不是按Key排序的,而是按被更新的行在Base文件中的位移来检索的,号称这样做,在定位Delta内容的时候,不需要进行字符串比较工作,因此能大大加快定位速度,但是无论如何,Delta文件的存在对检索速度的影响巨大。因此Delta文件的数量会需要控制,需要及时的和Base数据进行合并。由于Base文件是列式存储的,所以Delta文件合并时,可以有选择性的进行,比如只把变化频繁的列进行合并,变化很少的列保留在Delta文件中暂不合并,这样做也能减少不必要的IO开销。
- 除了Delta文件合并,DRS自身也会需要合并,为了保障检索延迟的可预测性(这一点是HBase的痛点之一,比如分区发生Major Compaction时,读写性能会受到很大影响),Kudu的compaction策略和HBase相比,有很大不同,kudu的DRS数据文件的compaction,本质上不是为了减少文件数量,实际上Kudu DRS默认是以32MB为单位进行拆分的,DRS的compaction并不减少文件数量,而是对内容进行排序重组,减少不同DRS之间key的overlap(重复),进而在检索的时候减少需要参与检索的DRS的数量。
6.设计原理
设计初衷
有一个问题我一直在考虑就是Kudu出现的意义,官方文档中强调的优点很多都是列存储的优点。
那和Parquet相比,又有什么优点呢,和同事讨论,也只得到了细颗粒修改删除的区别。
看到设计初衷之后明白了
- 静态数据通常以Parquet/Carbon/Avro形式直接存放在HDFS中,对于分析场景,这种存储通常是更加适合的。但无论以哪种方式存在于HDFS中,都难以支持单条记录级别的更新,随机读取也并不高效。
- 可变数据的存储通常选择HBase或者Cassandra,因为它们能够支持记录级别的高效随机读写。但这种存储却并不适合离线分析场景,因为它们在大批量数据获取时的性能较差(针对HBase而言,有两方面的主要原因:一是HFile本身的结构定义,它是按行组织数据的,这种格式针对大多数的分析场景,都会带来较大的IO消耗,因为可能会读取很多不必要的数据,相对而言Parquet格式针对分析场景就做了很多优化。 二是由于HBase本身的LSM-Tree架构决定的,HBase的读取路径中,不仅要考虑内存中的数据,同时要考虑HDFS中的一个或多个HFile,较之于直接从HDFS中读取文件而言,这种读取路径是过长的)。
于是乎,上面的两种存储,都存在明显的优缺点:
- 直接存放于HDFS中,适合离线分析,缺不利于记录级别的随机读写。
- 直接将数据放于HBase/Cassandra中,适合记录级别的随机读写,对离线分析却不友好。
但在很多实际业务场景中,两种场景时常是并存的,基于Spark/Hive On HBase进行,性能较差
- 数据存放于HBase中,对于分析任务,基于Spark/Hive On HBase进行,性能较差。
- 对于分析性能要求较高的,可以将数据在HDFS/Hive中多冗余存放一份,或者,将HBase中的数据定期的导出成Parquet/Carbon格式的数据。 明显这种方案对业务应用提出了较高的要求,而且容易导致在线数据与离线数据之间的一致性问题。
Kudu的设计,就是试图在OLAP和OLTP之间,寻求一个最佳的结合点,从而在一个系统的一份数据中,技能支持OLAP,又能支持OLTP,另外一个初衷是,在Cloudera发布的《Kudu: New Apache Hadoop Storage for Fast Analytics on Fast Data》一文中有提及,Kudu作为一个新的分布式存储系统期望有效提升CPU的使用率,而低CPU使用率恰是HBase/Cassandra等系统的最大问题。
OLTP系统强调数据库内存效率,强调内存各种指标的命令率,强调绑定变量,强调并发操作
OLAP系统则强调数据分析,强调SQL执行市场,强调磁盘I/O,强调分区等
从功能角度来看,OLTP负责基本业务的正常运转,而业务数据积累时所产生的价值信息则被OLAP不断呈现,企业高层通过参考这些信息会不断调整经营方针,也会促进基础业务的不断优化,这是OLTP与OLAP最根本的区别
事务与一致性
Kudu仅仅提供单行事务,也不支持多行事务。这一点与HBase是相似的。但在数据一致性模型上,与HBase有较大的区别。 Kudu提供了如下两种一致性模型:
- Snapshot Consistency
这是Kudu中的默认一致性模型。在这种模型中,只保证一个客户端能够看到自己所提交的写操作,而并不保障全局的(跨多个客户端的)事务可见性。
- External Consistency
最早提出External Consistency机制的,应该是在Google的Spanner论文中。传统关系型数据库中的两阶段提交机制,需要两回合通信,这过程中带来的代价是较高的,但同时这过程中的复杂的锁机制也可能会带来一些可用性问题。一个更好的实现分布式事务/一致性的思路,是基于一个全局发布的Timestamp机制。Spanner提出了Commit-wait的机制,来保障全局事务的有序性:如果一个事务T1的提交先于另外一个事务T2的开始,则T1的Timestamp要小于T2的TimeStamp。我们知道,在分布式系统中,是很难于做这样的承诺的。在HBase中,我们可以想象,如果所有RegionServer中的SequenceID发布自同一个数据源,那么,HBase的很多事务性问题就迎刃而解了,然后最大的问题在于这个全局的SequenceID数据源将会是整个系统的性能瓶颈点。回到External Consistency机制,Spanner是依赖于高精度与可预见误差的本地时钟(TrueTime API)实现的(即需要一个高可靠和高精度的时钟源,同时,这个时钟的误差是可预见的。感兴趣的同学可以阅读Spanner论文,这里不赘述)。Kudu中提供了另外一种思路来实现External Consistency,基于Timestamp扩散机制,即,多个客户端可相互通信来告知彼此所提交的Timestamp值,从而保障一个全局的顺序。这种机制也是相对较为复杂的。
与Spanner类似,Kudu不允许用户自定义用户数据的Timestamp,但在HBase中却是不同,用户可以发起一次基于某特定Timestamp的查询。
7.小米对Kudu的经验分享
小米用了另一张图来表示kudu的特点,我觉的这张五芒星图能够更好的体现出Kudu的性能,不足之处和优点。

Kudu这个项目是2012年10月 Kudu发起的,一直到2015年10月才对外发布Beta版本,小米是2014年9月加入的,所以算是加入非常早的。
Kudu的设计目标
高性能:
- 快速的批量扫描2x Parquet
- 低延迟的随机读写1ms on SSD
可拓展
- 400 nodes,1000s of nodes
- low MTTR
关系型数据模型:
- 强schema,有限列,不支持BLOBs
- NoSQL APIs (insert/update/delete/scan), Java/C++ Client
事务支持:
- 单行的ACID支持
与Hadoop生态的集成
- Flume/Impala/Spark
数据模型和使用


分区

副本

容错

集群

Master

Tablet存储设计
- 类LSM:每个Tablet包含一个MemRowSet和多个DiskRowSet;新插入的数据存储在MemRowSet中,定期flush成DiskRowSet
- 不同于LSM。每一个Row只存在于一个RowSet中

DELTA COMPACTION

ROWSET COMPACTION

传统数据流

Kudu数据流

Kudu优势——统一数据存储

Kudu优势——事务和主键索引

例子 wordCount

OLAP云服务

OLAP服务

OLAP服务—NOSQL

OLAP服务—SQL

OLAP服务—容量规划和隔离


性能:随机读写

性能:分析性查询


Kudu vs Druid
数据精度不同:
- Druid对数据进行预聚合,不保存原始数据
内部存储不同
- 均是列存储,但Druid内部使用bitmap倒排表,Kudu使用bitshuffle等encoding方式
应用场景不同:
- Druid更适合做在线指标的实时统计等⼯作,Kudu适合实时的分析类查询
查询方式不同:
- Druid有自⼰的查询引擎,尚不支持join;Kudu依靠Impala/SparkSQL,对SQL的支持更加完整
查询性能不同:
- Druid查询的是OLAP Cube,速度更快;Kudu需要扫描原始数据,可支持的查询更灵活
Kudu vs 流式计算
流式计算的一些局限:
- 预计算固定的指标,Ad-hoc查询能力较弱
- 复杂的查询难以支持(大表join)
- 精度要求(TopN,count(distinct))
- 存在时间窗口
- 容错状态保存,依赖于外部存储,难以开发
MVCC 多版本并发控制
特点:对每一行都保存多个版本
能力:Snapshot读、历史读、增量备份、同一个Tablet内多行写的原子性
一个写操作的执行步骤
- leader收到写请求,获得要写的行锁
- 为写操作分配timestamp
- 通过raft协议备份写操作
- 真正对行数据做更改
- 更改timestamp为committed,对外可见
Flush过程

NoSQL API

Spark DataFrame

Kudu RDD

SparkSQL on Kudu


实时数仓
