笨猫不如烂笔头
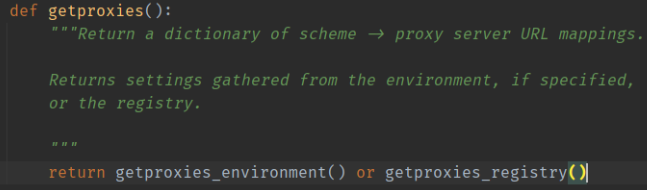
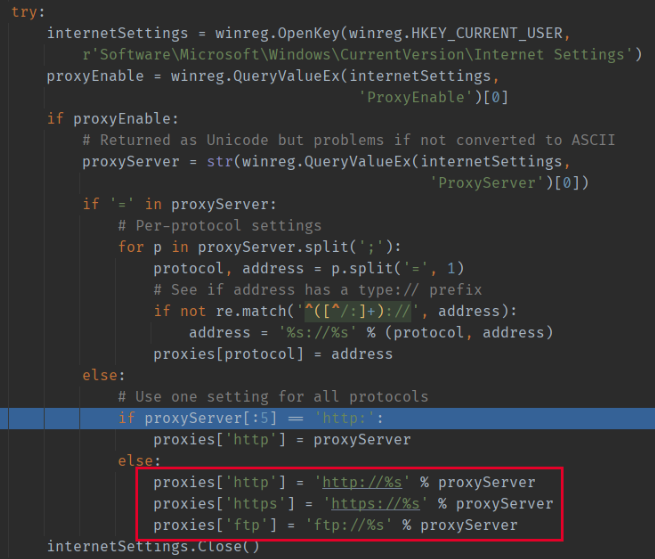
更友好的创建对象方式
上面的方式,对JVM来说是更友好的,因为堆内存的调用无法避免,所以从栈内存这边入手解决内存问题是一个不错的解决的方式
下面代码是否线程安全 1 2 3 4 5 6 7 8 9 10 11 public class Singleton static Singleton instance; static Singleton getInstance () if (instance == null ) { synchronized (Singleton.class ) { if (instance == null ) instance = new Singleton(); } } return instance; } }
乍一看类似饿汉式的单例,线程安全,其实是有问题的
虽然只有一个线程能够获得锁,并且这个锁还是类锁,所有对象共享的
关键在于 jvm 对 new 的优化,这个变量没有声明 volatile,new 不是一个线程安全的操作,
对于 new 这个指令,一般的顺序是申请内存空间,初始化内存空间,然后把内存地址赋给 instance 对象,但是 jvm 会对这段指令进行优化,优化之后变成 申请内存空间,内存地址赋给 instance 对象,初始化内存空间,这就导致 第二层检查可能会出错,标准写法只需要在变量前声明 volatile 即可。
volatile利用了什么协议来实现可见性 volatile 是通过内存屏障实现的,MESI协议,缓存一致性协议
JVM推荐书《The Java Language Specification》
Java Trainsient 关键字 1.一旦变量被transient修饰,变量将不再是对象持久化的一部分,该变量内容在序列化后无法获得访问。
2.transient关键字只能修饰变量,而不能修饰方法和类。注意,本地变量是不能被transient关键字修饰的。变量如果是用户自定义类变量,则该类需要实现Serializable接口。
3.一个静态变量不管是否被transient修饰,均不能被序列化。
使用总结和场景:某个类的有些属性需要序列化,其他属性不需要被序列化,比如:敏感信息(如密码,银行卡号等),java 的transient关键字为我们提供了便利,你只需要实现Serilizable接口,将不需要序列化的属性前添加关键字transient,序列化对象的时候,这个属性就不会序列化到指定的目的地中。
多线程中Random的使用 1.不要在多个线程间共享一个java.util.Random实例,而该把它放入ThreadLocal之中。
2.Java7以上我们更推荐使用java.util.concurrent.ThreadLocalRandom。
下面两条建议是 IDEA给的:
1.不要将将随机数放大10的若干倍然后取整,直接使用Random对象的nextInt或者nextLong方法
2.Math.random()应避免在多线程环境下使用
为什么阿里禁止使用Executor创建线程池 阿里规约之所以强制要求手动创建线程池,也是和这些参数有关。具体为什么不允许,规约是这么说的:
线程池不允许使用Executors去创建,而是通过ThreadPoolExecutor的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
Executor提供的四个静态方法创建线程池,但是阿里规约却并不建议使用它。
Executors各个方法的弊端:
看一下这两种弊端怎么导致的。
第一种,newFixedThreadPool和newSingleThreadExecutor分别获得 FixedThreadPool 类型的线程池 和 SingleThreadExecutor 类型的线程池。
1 2 3 4 5 public static ExecutorService newFixedThreadPool (int nThreads) return new ThreadPoolExecutor(nThreads, nThreads, 0L , TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); }
1 2 3 4 5 6 public static ExecutorService newSingleThreadExecutor() { return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>())); }
因为,创建了一个无界队列LinkedBlockingQueuesize,是一个最大值为Integer.MAX_VALUE的线程阻塞队列,当添加任务的速度大于线程池处理任务的速度,可能会在队列堆积大量的请求,消耗很大的内存,甚至导致OOM。
阿里开发手册上不推荐(禁止)使用Double的根本原因 精度丢失就不谈了,稍微深入一下为什么精度会丢失,分为一些不同情况
典型现象(一):条件判断超预期
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 System.out.println( 1f == 0.9999999f ); System.out.println( 1f == 0.99999999f ); 1.0 (十进制) ↓ 00111111 10000000 00000000 00000000 (二进制) ↓ 0x3F800000 (十六进制) 0.99999999 (十进制) ↓ 00111111 10000000 00000000 00000000 (二进制) ↓ 0x3F800000 (十六进制) 果不其然,这两个十进制浮点数的底层二进制表示是一毛一样的,怪不得==的判断结果返回true ! 浮点数的精度问题。 浮点数在计算机中的存储方式遵循IEEE 754 浮点数计数标准,可以用科学计数法表示为: 1 + 2 + 3 1 、符号部分(S)0 -正 1 -负2 、阶码部分(E)(指数部分):对于float 型浮点数,指数部分8 位,考虑可正可负,因此可以表示的指数范围为-127 ~ 128 对于double 型浮点数,指数部分11 位,考虑可正可负,因此可以表示的指数范围为-1023 ~ 1024 3 、尾数部分(M):浮点数的精度是由尾数的位数来决定的: 对于float 型浮点数,尾数部分23 位,换算成十进制就是 2 ^23 =8388608 ,所以十进制精度只有6 ~ 7 位; 对于double 型浮点数,尾数部分52 位,换算成十进制就是 2 ^52 = 4503599627370496 ,所以十进制精度只有15 ~ 16 位 所以对于上面的数值0.99999999f ,很明显已经超过了float 型浮点数据的精度范围,出问题也是在所难免的。
典型现象(二):数据转换超预期
1 2 3 4 float f = 1.1f ;double d = (double ) f;System.out.println(f); System.out.println(d);
典型现象(三):基本运算超预期
1 2 3 System.out.println( 0.2 + 0.7 );
典型现象(四):数据自增超预期
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 float f1 = 8455263f ;for (int i = 0 ; i < 10 ; i++) { System.out.println(f1); f1++; } float f2 = 84552631f ;for (int i = 0 ; i < 10 ; i++) { System.out.println(f2); f2++; }
解决办法:
1.我们我们可以用字符串或者数组来表示这种大数,然后按照四则运算的规则来手动模拟出具体计算过程,中间还需要考虑各种诸如:进位、借位、符号 等等问题的处理,有点复杂。
JDK早已为我们考虑到了浮点数的计算精度问题,因此提供了专用于高精度数值计算的大数类 来方便我们使用。
mac 清理maven仓库的脚本 1 2 3 4 5 6 7 # 这里写你的仓库路径 REPOSITORY_PATH=~/Documents/tools/apache-maven-3.0.3/repository echo 正在搜索... find $REPOSITORY_PATH -name "*lastUpdated*" | xargs rm -fr echo 删除完毕 mac(linux)系统-创建.sh文件脚本执行(mac用.command终端也可以)
idea目录较多,文件名较长产生的错误 1 2 3 Error running 'ServiceStarter': Command line is too long. Shorten command line for ServiceStarter or also for Application default configuration. 修改项目下 .idea\workspace.xml,找到标签 <component name="PropertiesComponent"> , 在标签里加一行 <property name="dynamic.classpath" value="true" />
Log4J 指定屏蔽某些特定报警信息 Logger.getLogger(“org.apache.library”).setLevel(Level.OFF)
Flink Source并行度为1的意义 对于需要设置EventTime的流来说,我们的TimestampAssigner应该在Source之后立即调用,原因是时间戳分配器看到的元素的顺序应该和source操作符产生数据的顺序是一样的,否则就乱了,也就是说,任何分区操作都会将元素的顺序打乱,例如:改变并行度 keyBy操作等等。,所以最佳实践是:
在尽量接近数据源source操作符的地方分配时间戳和产生水位线,甚至最好在SourceFunction中分配时间戳和产生水位线。当然在分配时间戳和产生水位线之前可以对流进行map和filter操作是没问题的,也就是说必须是窄依赖。
JB套件的一个实用功能 1 之前没注意,更改变量名字的时候直接使用refactor就可以了,真的实用
zk使用的分布式协议并不是paxos 为什么说NULL是计算机科学中最大的错误,至少值十亿美金 1 2 3 4 5 6 7 1.覆类型 2.是凌乱的 3.是一个特例 4.使 API 变得糟糕 5.使错误的语言决策更加恶化 6.难以调试 7.是不可组合的
1. NULL 颠覆类型 静态类型语言不需要实际去执行程序,就可以检查程序中类型的使用,并且提供一定的程序行为保证。
例如,在 Java 中,如果我编写 x.toUppercase(),编译器会检查 x 的类型。如果 x 是一个 String,那么类型检查成功;如果 x 是一个 Socket,那么类型检查失败。
在编写庞大的、复杂的软件时,静态类型检查是一个强大的工具。但是对于 Java,这些很棒的编译时检查存在一个致命缺陷:任何引用都可以是 null,而调用一个 null 对象的方法会产生一个 NullPointerException。所以,
toUppercase() 可以被任意 String 对象调用。除非 String 是 null。read() 可以被任意 InputStream 对象调用。除非 InputStream 是 null。toString() 可以被任意 Object 对象调用。除非 Object 是 null。
Java 不是唯一引起这个问题的语言;很多其它的类型系统也有同样的缺点,当然包括 AGOL W 语言。
在这些语言中,NULL 超出了类型检查的范围。它悄悄地越过类型检查,等待运行时,最后一下子释放出一大批错误。NULL 什么也不是,同时又什么都是。
2. NULL 是凌乱的 在很多情况下 null 是没有意义的。不幸的是,如果一种语言允许任何东西为 null,好吧,那么任何东西都可以是 null。
Java 程序员冒着患腕管综合症的风险写下
Java
if (str == null 丨丨 str.equals("")) {}
而在 C# 中添加 String.IsNullOrEmpty 是一个常见的语法
C#
if (string.IsNullOrEmpty(str)) {}
真可恶!
每次你写代码,将 null 字符串和空字符串混为一谈时,Guava 团队都要哭了。– Google Guava
说得好。但是当你的类型系统(例如,Java 或者 C#)到处都允许 NULL 时,你就不能可靠地排除 NULL 的可能性,并且不可避免的会在某个地方混淆。
null 无处不在的可能性造成了这样一个问题,Java 8 添加了 @NonNull 标注,尝试着在它的类型系统中以追溯方式解决这个缺陷。
3. NULL 是一个特例 考虑到 NULL 不是一个值却又起到一个值的作用,NULL 自然地成为各种特别处理方法的课题。
1 2 3 char c = 'A'; char *myChar = &c; std::cout << *myChar << std::endl;
单个 NUL 字符的例外已经导致无数的错误:API 的怪异行为、安全漏洞和缓冲区溢出。
NULL 是 C 字符串中最糟糕的错误;更确切地说,以 NUL 结尾的字符串是最昂贵的一字节 错误 。
4.NULL 使 API 变得糟糕 我们可以想象在很多语言中类似的类(Python、JavaScript、Java、C# 等)。
现在假设我们的程序有一个慢的或者占用大量资源的方法,来找到某个人的电话号码——可能通过连通一个网络服务。
为了提高性能,我们将会使用本地存储作为缓存,将一个人名映射到他的电话号码上。
然而,一些人没有电话号码(即他们的电话号码是 nil)。我们仍然会缓存那些信息,所以我们不需要在后面重新填充那些信息。
但是现在意味着我们的结果模棱两可!它可能表示:
这个人不存在于缓存中(Alice)
这个人存在于缓存中,但是没有电话号码(Tom)
一种情形要求昂贵的重新计算,另一种需要即时的答复。但是我们的代码不够精密来区分这两种情况。
在实际的代码中,像这样的情况经常会以复杂且不易察觉的方式出现。因此,简单通用的 API 可以马上变成特例,迷惑了 null 凌乱行为的来源。
用一个 contains() 方法来修补 Store 类可能会有帮助。但是这引入重复的查找,导致降低性能和竞争条件。
5.NULL 使错误的语言决策更加恶化 6.NULL 难以调试 来解释 NULL 是多么的麻烦,C++ 是一个很好的例子。调用成员函数指向一个 NULL 指针不一定会导致程序崩溃。更糟糕的是:它可能会导致程序崩溃。
7.NULL不可组合 IDEA maven修改pom文件,导致jdk版本重置问题 1 2 3 4 <properties> <maven.compiler.source>8</maven.compiler.source> <maven.compiler.target>8</maven.compiler.target> </properties>
MAVEN的scope 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 compile 默认就是compile,什么都不配置也就是意味着compile。compile表示被依赖项目需要参与当前项目的编译,当然后续的测试,运行周期也参与其中,是一个比较强的依赖。打包的时候通常需要包含进去。 test scope为test表示依赖项目仅仅参与测试相关的工作,包括测试代码的编译,执行。比较典型的如junit。 runntime runntime表示被依赖项目无需参与项目的编译,不过后期的测试和运行周期需要其参与。与compile相比,跳过编译而已,说实话在终端的项目(非开源,企业内部系统)中,和compile区别不是很大。比较常见的如JSR×××的实现,对应的API jar是compile的,具体实现是runtime的,compile只需要知道接口就足够了。oracle jdbc驱动架包就是一个很好的例子,一般scope为runntime。另外runntime的依赖通常和optional搭配使用,optional为true。我可以用A实现,也可以用B实现。 provided provided意味着打包的时候可以不用包进去,别的设施(Web Container)会提供。事实上该依赖理论上可以参与编译,测试,运行等周期。相当于compile,但是在打包阶段做了exclude的动作。 system 从参与度来说,也provided相同,不过被依赖项不会从maven仓库抓,而是从本地文件系统拿,一定需要配合systemPath属性使用。 scope的依赖传递 A–>B–>C。当前项目为A,A依赖于B,B依赖于C。知道B在A项目中的scope,那么怎么知道C在A中的scope呢? 答案是: 当C是test或者provided时,C直接被丢弃,A不依赖C; 否则A依赖C,C的scope继承于B的scope。
EXCEL一点小技巧 正好最近用来有点小用处
1 2 3 4 5 6 7 8 9 1.从固定的单元格里随机取一个值 =INDEX($G$2:$M$2, RANDBETWEEN(1,7)) $G$2:下拉的时候不会自动延伸 2.从固定列取值用在本单元格里 ="INSERT INTO `event_mapping` VALUES ('"&B2&"',"&C2&","&D2&");" 3.下拉到某行 在有第一行的情况下,直接双击右下角小箭头即可
Flink On Zeppelin上传Jar包的位置 1 2 3 4 5 6 /opt/flink-1.10/flink-1.10.0/lib 目前看来应该是放在flink包里面的,会稳定上传,已经确定 在interpreter 依赖里面设置了路劲 /opt/flink-1.10/flink-1.10.0/lib/jimipojo-1.0.jar
Flink系列深度好文,等待细读 1 2 https://www.jianshu.com/c/b6089c70072f flink的apply和process方法有什么区别呢
FastJson直接解析 1 2 3 4 5 6 7 8 .map( a -> JSON .parseObject( a, Pojo.class) ).returns( Pojo.class )
具体的还要试一下,我故意写的很难看来督促自己。。。
FastJson很多坑 准备放弃 配置框架无法访问的问题 1 2 3 有点脑残了,今天在mac上配置了zeppelin win无法访问,其原因是配置文件中的网络地址写死了 172.0.0.1, 如果想要别尔德位置能够访问的话,必须改变配置为其局域网id 更好的选择是更改为0.0.0.0
解决GitHub提交历史头像不显示问题,以及首页没有绿色方块的问题 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 最近把本地的一个项目提交推送到GitHub的时候发现有两个问题, 1.在commit提交历史里面 提交内容的旁边,显示的不是原本github主页的头像,而是默认的灰色章鱼头像 2.我的contributions里面提交的历史(绿色方块)也没有了 怎么解决呢? 1.首先在终端里切到项目所在目录 2.输入git show命令,你会发现 有一行写着Author: Apple <邮箱>,这个邮箱肯定不是你绑定到github的邮箱 3.输入git config user.email "你的邮箱地址",修改邮箱 4.修改完以后输入git config user.email 检查是否修改成了你的邮箱 5.到目前为止现在只是修改这个项目的邮箱,重新推送一个新的改动,在查看该项目的提交历史和contributions里面提交的历史(绿色方块),问题已经解决了(之前的依旧不显示) 6.如果你想其他项目提交时,也避免此类情况,把上面的两条命令改成 (1) git config --global user.email "your_email@example.com" (2)git config --global user.email 就可以了
解决anaconda无法连接的问题 1 win10下更换清华镜像后无法连接 是因为win10里面无法解析https协议,修改~\.condarc文件,把https换成http
排查挖矿程序中会用到的一些追踪某个进程的命令 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 # 查看PID启动文件的路径ls -l /proc/$PID/exe # 查看PID执行目录的路径ls -l /proc/$PID/cwd # 在定时器配置目录查看是否存在异常定时器配置/var/spool/cron/root 和/etc/crontab 和/etc/rc.lcoal # 查看定时器启动日志,跟踪自启动程序tail -f /var/log/cron # 查看各个进程的cpu使用情况,默认按cpu使用率排序top # 显示所有运行中的进程,q退出ps aux | less # 查看test.jar进程号ps -aux|grep test.jar | grep -v grep # 查看test.jar进程号ps -ef|grep test.jar | grep -v grep # 查看该进程下各个线程的cpu使用情况top -Hp pid # 将线程pid转换为十六进制 8f7printf "%x\n" pid # 查看pid进程里面的线程信息,线程Id为十六进制jstack pid | grep 8f7 # 查看该进程打开的文件lsof -p pid # 查看pid线程内存分配cat /proc/pid/maps # 查看PID启动文件的路径ls -l /proc/$PID/exe # 查看PID执行目录的路径ls -l /proc/$PID/cwd # 查看PID详细的内存占比cat /proc/$PID/status
Kerberos缺点 1 2 3 4 5 6 7 8 9 10 11 12 13 1、KDC 有单点风险,除非设置HA系统(Aictive Directory 可以做到这一点,目前apache directoryserver 也可以做到这一点); 2、访问压力可能使KDC过载;分布式服务使用Kerberos 必须做到这一点,KDC无法承受高负载请求;为什么Hadoop 要使用代理tokens的原因也是如此; 3、服务之间的通信通道也需要安全认证,kerberos不保证数据加密;如果通信通道不安全,tickets 可能会被拦截或者通信伪造; 4、机器之前需要保证时间的精确一致性,不然具备时限的tockens不会正常工作;这个在分布式领域是一个典型的问题,Paxos &Raft协议也必须保证时间的一致性; 5、如果机器间的时间没有被安全管理,理论上可能延长被盗token的使用时间; 6、被盗用的token可以拿来直接访问服务,在KDC是没有访问日志的。每一个application需要拥有自己的以用户为单位的审计日志,这样才能保证被盗的ticket可被追踪,比如在Hadoop里面HDFS审计日志; 7、这是一个仅仅认证服务:验证caller的合法性并准许给caller传递认证信息,他不处理任何授权信息;
mac无法运行.sh文件的解决办法 1 2 3 4 5 6 7 8 今天解决了一下内网穿透的问题, 轻量级的选择有frp, 重量级的有goproxy 几个问题记录一下,第一点: zsh无法运行.sh文件,要进行切换 chsh -s /bin/bash chsh -s /bin/zsh
解决git下载速度慢的终极方法 因为本地的网络始终有一些问题,再忍受了很久很久的龟速下载之后,终于找了个一个非常顶的方法
前提是现有一个vpn,但是vpn不会自动代理git的流量,不管是在windows下面还是在mac下面都不会自动代理git,这点一直让我十分苦恼,现在终于找到了一劳永逸的办法
1 2 git config --global http.proxy 'socks5://127.0.0.1:1080' git config --global https.proxy 'socks5://127.0.0.1:1080'
简单说明:vpn一般都是走的1080端口,通过这个端口转发git的流量,跳过本地运营商。
取消代理
1 2 3 4 # 取消代理 git config --global --unset http.proxy git config --global --unset https.proxy
Maven代理配置 不需要配置什么https或者http模式,在有代理的前提下,只要配置一个代理即可
1 2 3 4 5 6 7 8 9 10 <proxy > <id > ss</id > <active > true</active > <protocol > socks5</protocol > <username > </username > <password > </password > <host > 127.0.0.1</host > <port > 1080</port > <nonProxyHosts > 127.0.0.1</nonProxyHosts > </proxy >
要注意的是监控一下端口,如果代理没开的话那肯定是无法连接上的,mirror就不用设置了,直接从中央仓库拉去数据。
npm更换源 1 2 3 4 5 6 7 8 //设置淘宝源 npm config set registry https://registry.npm.taobao.org //设置公司的源 npm config set registry http://127.0.0.1:4873 //查看源,可以看到设置过的所有的源 npm config get registry
其实感觉应该把Mac管理node的brew n弄一下
HDFS的某个错误 HBase和Flink在运行的时候报错
hbase启动后region自动挂了,Flink任务失败,文件丢失,然后查看hdfs日志
错误原因 dfs.datanode.max.transfer.threads 的参数4096,已经不足以支持现在的Thread,修改为2倍或者4倍或者更多
IDEA MAVEN停止加载 经常遇到大型项目idea 停止加载mvn,然后就没办法了。。
1 2 3 4 maven -> maven goal idea的maven第六个按钮 点击 然后 mvn -U idea:idea 即可
窗口触发的一些问题 窗口是按 watermark 触发的,watermark 如果没有前进到 window end , window 是不会触发的。
Flink的窗口触发具体机制需要去源码里面探寻
Flink SQL中的爆炸函数 Lateral View() 在Flink SQL中是unnest
1 SELECT users , tag FROM Orders CROSS JOIN UNNEST (tags) AS t (tag)
Flink UI在Yarn下 1 Flink UI 在 Yarn下很多选线卡看不到详细信息,很正常,因为Yarn这个运行模式有的消息只能在Yarn上管理控制
Flink的时区问题 1 Flink的时间戳差了8个小时,可以用时间减去八个小时时差,生成一个减去8小时的列,作为watermark的时间戳。
Flink的心跳需求问题 1 2 3 4 5 使用flink sql在实时计算当天凌晨截止到现在的累计数据的时候,计算步长是10分钟,如果这10分钟内没有新数据达到的话,现在的情况是这10分钟没有写记录,这就会造成业务查这个数据的时候需要找last value这种情形,设计一条方案让没有数据到达的时候也生成一条记录,这条记录的值就是last value。 方案: 往数据源发心跳数据。 发送的数据格式和普通数据一样,只是这些数据不影响你的 agg 计算,比如 null 值。发送频率就根据需求去确定。
Flink避免重复劳动的一些方法 1 2 1.写DDL+DML分别声明数据源和进行数据处理。 2.groovy+ 规则引擎
oppo:
Flink配置参数 1 2 3 4 5 6 7 8 9 10 # 开启 distinct agg 切分 table.optimizer.distinct-agg.split.enabled=true # 开启两阶段 即local-global 优化 table.optimizer.agg-phase-strategy=TWO_PHASE # mini-batch 开启微批操作 table.exec.mini-batch.enabled=true # mini-batch的时间间隔,即作业需要额外忍受的延迟 table.exec.mini-batch.allow-latency=5s # 一个节点中允许最多缓存的数据 table.exec.mini-batch.size=5000
1 2 3 4 5 6 7 8 TableEnvironment tEnv = ... // access flink configuration Configuration configuration = tEnv.getConfig().getConfiguration(); // set low-level key-value options configuration.setString("table.exec.mini-batch.enabled", "true"); configuration.setString("table.exec.mini-batch.allow-latency", "5 s"); configuration.setString("table.exec.mini-batch.size", "5000");
Flink GlobalWindow 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @Test def testJoin () : Unit ={ val env = StreamExecutionEnvironment.getExecutionEnvironment env.setParallelism(3 ) val person = env.fromElements(("1" ,"小张" ),("2" ,"小刘" ),("3" ,"小力" ),("4" ,"小心" )) val money = env.fromElements(("1" ,100 ),("2" ,200 ),("3" ,300 )) person.join(money) .where(_._1) .equalTo(_._1) .window(GlobalWindows.create()) .apply((x,y) =>{ println( x+"===" +y) "xxx" }).print() env.execute() println("end" ) }
无法运行,加个triggle(xxx)解决,默认是NeverTrigger
1 2 3 4 .... .window.... .trigger(CountTrigger.of(1)) .apply...
如何排查Kafka消息的异常 1 记录住报错时的kafka offset,然后分阶段打印到控制台,再对比一下,把输出的格式分别调为Row.class 以前pojo类,或注释下一阶段代码,回放kafka 故障的offset数据,各个stream排查
MySQL的迁移 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 --涉及到MySQL的迁移,我这边推荐少量数据的话使用MySQLDump. --还涉及到mysql安装在docker里的情况 --mysqldump的用法 --备份所有数据库: mysqldump -uroot -p --all-databases > /backup/mysqldump/all.db --备份指定数据库: mysqldump -uroot -p test > /backup/mysqldump/test.db --备份指定数据库指定表(多个表以空格间隔) mysqldump -uroot -p mysql db event > /backup/mysqldump/2table.db --备份指定数据库排除某些表 mysqldump -uroot -p test --ignore-table=test.t1 --ignore-table=test.t2 > /backup/mysqldump/test2.db --Docker进入mysql容器 docker exec -it mysql1 bash //mysql1是我启动的mysql服务的name
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 --带docker的命令 1.查看当前启动的mysql运行容器 docker ps 2.使用以下命令备份导出数据库中的所有表结构和数据 docker exec -it mysql mysqldump -uroot -p123456 paas_portal > /cloud/sql/paas_portal.sql 3.只导数据不导结构 mysqldump -t 数据库名 -uroot -p > xxx.sql docker exec -it mysql mysqldump -t -uroot -p123456 paas_portal >/cloud/sql/paas_portal_dml.sql 4.只导结构不导数据 mysqldump --opt -d 数据库名 -u root -p > xxx.sql docker exec -it mysql mysqldump --opt -d -uroot -p123456 paas_portal >/cloud/sql/paas_portal_ddl.sql 5.导出特定表的结构 mysqldump -uroot -p -B 数据库名 --table 表名 > xxx.sql docker exec -it mysql mysqldump -uroot -p -B paas_portal --table user > user.sql
远程调试Flink
https://stackoverflow.com/questions/34816847/debugging-on-the-remote-cluster
Log4J 和 slf4j联合使用 slf4j是什么?slf4j只是定义了一组日志接口,但并未提供任何实现,既然这样,为什么要用slf4j呢?log4j不是已经满足要求了吗?
是的,log4j满足了要求,但是,日志框架并不只有log4j一个,你喜欢用log4j,有的人可能更喜欢logback,有的人甚至用jdk自带的日志框架,这种情况下,如果你要依赖别人的jar,整个系统就用了两个日志框架,如果你依赖10个jar,每个jar用的日志框架都不同,岂不是一个工程用了10个日志框架,那就乱了!
如果你的代码使用slf4j的接口,具体日志实现框架你喜欢用log4j,其他人的代码也用slf4j的接口,具体实现未知,那你依赖其他人jar包时,整个工程就只会用到log4j日志框架,这是一种典型的门面模式应用,与jvm思想相同,我们面向slf4j写日志代码,slf4j处理具体日志实现框架之间的差异,正如我们面向jvm写java代码,jvm处理操作系统之间的差异,结果就是,一处编写,到处运行。况且,现在越来越多的开源工具都在用slf4j了
1 2 3 4 5 <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-api</artifactId> <version>1.7.21</version> </dependency>
然后,弄到slf4j与log4j的关联jar包,通过这个东西,将对slf4j接口的调用转换为对log4j的调用,不同的日志实现框架,这个转换工具不同
1 2 3 4 5 <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>1.7.21</version> </dependency>
以及原来的
1 2 3 4 5 <dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>1.2.17</version> </dependency>
Log4J2的使用 Log4J2和Log4J1的比较 配置文件 log4j是通过一个**.properties的文件作为主配置文件的,而现在的log4j 2则已经弃用了这种方式,采用的是 .xml,.json或者.jsn**这种方式。
依赖 log4j只需要引入一个依赖
1 2 3 4 5 <dependency > <groupId > log4j</groupId > <artifactId > log4j</artifactId > <version > 1.2.17</version > </dependency >
log4j 2则是需要2个核心
1 2 3 4 5 6 7 8 9 10 <dependency > <groupId > org.apache.logging.log4j</groupId > <artifactId > log4j-core</artifactId > <version > 2.5</version > </dependency > <dependency > <groupId > org.apache.logging.log4j</groupId > <artifactId > log4j-api</artifactId > <version > 2.5</version > </dependency >
配置文件 log4J.properties
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 #此句为定义名为stdout的输出端是哪种类型,可以是 #org.apache.log4j.ConsoleAppender(控制台), #org.apache.log4j.FileAppender(文件), #org.apache.log4j.DailyRollingFileAppender(每天产生一个日志文件), #org.apache.log4j.RollingFileAppender(文件大小到达指定尺寸的时候产生一个新的文件) #org.apache.log4j.WriterAppender(将日志信息以流格式发送到任意指定的地方) log4j.appender.stdout=org.apache.log4j.ConsoleAppender #此句为定义名为stdout的输出端的layout是哪种类型,可以是 #org.apache.log4j.HTMLLayout(以HTML表格形式布局), #org.apache.log4j.PatternLayout(可以灵活地指定布局模式), #org.apache.log4j.SimpleLayout(包含日志信息的级别和信息字符串), #org.apache.log4j.TTCCLayout(包含日志产生的时间、线程、类别等等信息) log4j.appender.stdout.layout=org.apache.log4j.PatternLayout #如果使用pattern布局就要指定的打印信息的具体格式ConversionPattern,打印参数如下: #%m 输出代码中指定的消息 #%p 输出优先级,即DEBUG,INFO,WARN,ERROR,FATAL #%r 输出自应用启动到输出该log信息耗费的毫秒数 #%c 输出所属的类目,通常就是所在类的全名 #%t 输出产生该日志事件的线程名 #%n 输出一个回车换行符,Windows平台为“rn”,Unix平台为“n” #%d 输出日志时间点的日期或时间,默认格式为ISO8601,也可以在其后指定格式 #比如:%d{yyyy MMM dd HH:mm:ss,SSS} 输出类似:2002年10月18日 22:10:28,921 #%l 输出日志事件的发生位置,包括类目名、发生的线程,以及在代码中的行数。 #[Log4JDemo]是log信息的开头,可以为任意字符,一般为项目简称。 #log4j.appender.stdout.layout.ConversionPattern=[Log4JDemo] %p [%t] %C.%M(%L) | %m%n log4j.appender.stdout.layout.ConversionPattern=[Log4JDemo] %p [%t] %C.%M(%L) | %m%n #设置日志文件 log4j.appender.LogFile=org.apache.log4j.FileAppender log4j.appender.LogFile.File=log4j.log log4j.appender.LogFile.layout=org.apache.log4j.PatternLayout log4j.appender.LogFile.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %l %m%n #此句为将等级为ALL的日志信息输出到stdout和LogFile这两个目的地 #stdout和R的定义在下面的代码,可以任意起名 #等级可分为OFF、FATAL、ERROR、WARN、INFO、DEBUG、ALL #如果配置OFF则不打出任何信息 #如果配置为INFO这样只显示INFO, WARN, ERROR的log信息,而DEBUG信息不会被显示, #log4j.rootCategory=ERROR,stdout,LogFile #log4j.rootCategory=ERROR,LogFile log4j.rootCategory=ERROR,stdout
log4j2.xml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 <?xml version="1.0" encoding="UTF-8"?> <configuration status ="WARN" monitorInterval ="30" > <appenders > <console name ="Console" target ="SYSTEM_OUT" > <PatternLayout pattern ="[%d{HH:mm:ss:SSS}] [%p] - %l - %m%n" /> </console > <File name ="log" fileName ="log/test.log" append ="false" > <PatternLayout pattern ="%d{HH:mm:ss.SSS} %-5level %class{36} %L %M - %msg%xEx%n" /> </File > <RollingFile name ="RollingFileInfo" fileName ="${sys:user.home}/logs/info.log" filePattern ="${sys:user.home}/logs/$${date:yyyy-MM}/info-%d{yyyy-MM-dd}-%i.log" > <ThresholdFilter level ="info" onMatch ="ACCEPT" onMismatch ="DENY" /> <PatternLayout pattern ="[%d{HH:mm:ss:SSS}] [%p] - %l - %m%n" /> <Policies > <TimeBasedTriggeringPolicy /> <SizeBasedTriggeringPolicy size ="100 MB" /> </Policies > </RollingFile > <RollingFile name ="RollingFileWarn" fileName ="${sys:user.home}/logs/warn.log" filePattern ="${sys:user.home}/logs/$${date:yyyy-MM}/warn-%d{yyyy-MM-dd}-%i.log" > <ThresholdFilter level ="warn" onMatch ="ACCEPT" onMismatch ="DENY" /> <PatternLayout pattern ="[%d{HH:mm:ss:SSS}] [%p] - %l - %m%n" /> <Policies > <TimeBasedTriggeringPolicy /> <SizeBasedTriggeringPolicy size ="100 MB" /> </Policies > <DefaultRolloverStrategy max ="20" /> </RollingFile > <RollingFile name ="RollingFileError" fileName ="${sys:user.home}/logs/error.log" filePattern ="${sys:user.home}/logs/$${date:yyyy-MM}/error-%d{yyyy-MM-dd}-%i.log" > <ThresholdFilter level ="error" onMatch ="ACCEPT" onMismatch ="DENY" /> <PatternLayout pattern ="[%d{HH:mm:ss:SSS}] [%p] - %l - %m%n" /> <Policies > <TimeBasedTriggeringPolicy /> <SizeBasedTriggeringPolicy size ="100 MB" /> </Policies > </RollingFile > </appenders > <loggers > <logger name ="org.springframework" level ="INFO" > </logger > <logger name ="org.mybatis" level ="INFO" > </logger > <root level ="all" > <appender-ref ref ="Console" /> <appender-ref ref ="RollingFileInfo" /> <appender-ref ref ="RollingFileWarn" /> <appender-ref ref ="RollingFileError" /> </root > </loggers > </configuration >
调用 log4j
1 2 import org.apache.log4j.Logger;private final Logger LOGGER = Logger.getLogger(Test.class .getName ()) ;
log4j2
1 2 3 4 import org.apache.logging.log4j.Level;import org.apache.logging.log4j.LogManager;import org.apache.logging.log4j.Logger;private static Logger logger = LogManager.getLogger(Test.class .getName ()) ;
Spark On Yarn 结束任务的方式 1 2 3 4 1、yarn app -kill appid 丢数据或者多数据 2、kill -15 pid 丢数据或者多数据 3、监听http或hdfs目录方式 ok 建议大家用第三种方式
1 我们用的第一种 针对丢数据或者多数据 我们代码里把实时过来的数据checkpoint 下一次再跑的时候会去mysql里修改offset Kafka再读进来的数据和上次checkpoint的数据对比一下 去重
CharSequence 第一次见到这个CharSequence的时候感觉挺疑惑的,不知道为什么要有这个东西。这个CharSequence是String和Stringbuilder共同实现的接口类,在下面这种应用场景中,只有CharSequence是适用的。
1 2 3 4 String str = "abc" ; StringBuilder strbu = new StringBuilder("def" ); boolean boo = true ;CharSequence cs = boo?str:strbu;
并发编程,创建多少个线程合适 分为两种情况讨论,CPU密集型和 I/O密集型
在CPU密集型的程序中,理论上 线程数量 = CPU 核数(逻辑)就可以了,但是实际上,数量一般会设置为 CPU 核数(逻辑)+ 1,
计算(CPU)密集型的线程恰好在某时因为发生一个页错误或者因其他原因而暂停,刚好有一个“额外”的线程,可以确保在这种情况下CPU周期不会中断工作。
在I/O密集型程序的程序中,单核心线程数一般来说是这么设置的:
最佳线程数 = (1/CPU利用率) = 1 + (I/O耗时/CPU耗时)
多核心的线程数为:
最佳线程数 = CPU核心数 * (1/CPU利用率) = CPU核心数 * (1 + (I/O耗时/CPU耗时))
如果都是IO耗时的话,可以从纯理论上直接回答是2N或者2N+1
还有很多APM(Application Performance Manager)工具可以帮我们得到具体的数据比如 SkyWalking、CAT、zipkin
假设要求一个系统的 TPS(Transaction Per Second 或者 Task Per Second)至少为20,然后假设每个Transaction由一个线程完成,继续假设平均每个线程处理一个Transaction的时间为4s
如何设计线程个数,使得可以在1s内处理完20个Transaction?
但是,但是,这是因为没有考虑到CPU数目。家里又没矿,一般服务器的CPU核数为16或者32,如果有80个线程,那么肯定会带来太多不必要的线程上下文切换开销(希望这句话你可以主动说出来),这就需要调优了,来做到最佳 balance
计算操作需要5ms,DB操作需要 100ms,对于一台 8个CPU的服务器,怎么设置线程数呢?
线程数 = 8 * (1 + 100/5) = 168 (个)
Google AutoValue Google的 AutoValue 用起来说实话不是特别方便,对于一些需要用到映射的支持也不是十分友好,总之一句话,在国内的生态下是不太适合使用的,虽然EffectiveJava的作者嗯吹这个组件。
https://www.jianshu.com/p/e778e96fb751
这篇博客和AutoValue在Github上面自己的文档算是讲的比较好一点的文档。
Idea 注释模板设置 https://blog.csdn.net/shadow_zed/article/details/80551460#commentBox
Python中使用.join()替代+处理字符串 https://towardsdatascience.com/do-not-use-to-join-strings-in-python-f89908307273
存储图片 1.使用CDN 等技术替代数据库存储。
2.存储选择特殊文件系统,比如S3、淘宝的TFS等等
数据库里面尽量只要写路径
java的一些包的解释 PO(persistant object) 持久对象
VO(value object) 值对象
TO(Transfer Object),数据传输对象
BO(business object) 业务对象
POJO(plain ordinary java object)
简单无规则java对象
DAO(data access object) 数据访问对象
IDEA2020 显示内存大小 双击shift 填入
在里面打开ON
Java程序结束前运行的代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public class ShutdownTest public static void main (String[] args) System.out.println("开始" ); for (int i = 0 ; i < 1000000000 ; i++) { System.out.println("repeat" ); } Runtime.getRuntime().addShutdownHook(new Thread(){ @Override public void run () System.out.println("关闭" ); } }); } }
Java8 try()…catch() 1 2 3 4 5 6 try (FileWriter fw = new FileWriter("test.txt" )) { fw.write("test" ); } catch (Exception ex) { ex.printStackTrace(); }
通常我们使用try…catch()捕获异常的,如果遇到类似IO流的处理,要在finally部分关闭IO流,当然这个是JDK1.7之前的写法了;在JDK7优化后的try-with-resource语句,该语句确保了每个资源,在语句结束时关闭。所谓的资源是指在程序完成后,必须关闭的流对象。写在()里面的流对象对应的类都实现了自动关闭接口AutoCloseable。
idea中设置maven的jvm参数 1 2 file->setting->Build,Execution,Deployment->Maven->Runner VM option栏设置jvm参数,-Xmx1g -XX:MaxMetaspaceSize=128m
命令行中设置maven的jvm参数 1 2 1. 可以在mvn.cmd(linux中是mvn.sh或mvn)添加set MAVEN_OPTS=-Xmx1g -XX:MaxMetaspaceSize=128m 2. 也可以添加MAVEN_OPTS环境变量
String SubString 1 2 3 4 5 6 7 8 9 10 11 12 public static void main (String args[]) String Str = new String("www.runoob.com" ); System.out.print("返回值 :" ); System.out.println(Str.substring(4 ) ); System.out.print("返回值 :" ); System.out.println(Str.substring(4 , 10 ) ); } 返回值 :runoob.com 返回值 :runoob
通用的空间/地理空间ASL许可的开源Java库 Spatial4j
IntegerCache
1 2 3 4 5 6 public static void main (String[] args) Integer a = 1000 , b = 1000 ; System.out.println(a == b); Integer c = 100 , d = 100 ; System.out.println(c == d); }
false
因为存在这个IntegerCache,-128-127范围内是有Cache对象的,不会新生成。
书单推荐 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 《Effective Java中文版》 《实战Java虚拟机:JVM故障诊断与性能优化》 《HotSpot实战》 《实战Java高并发程序设计》 《深入分析Java Web技术内幕》 《大型网站技术架构 核心原理与案例分析》 《大型网站系统与Java中间件实践》 《从Paxos到ZooKeeper 分布式一致性原理与实践》 《代码大全(第2版) 》 《算法导论》 《计算机程序设计艺术》 《重构》 《设计模式》 《人月神话》 《程序员修炼之道》
反射API 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 package com.hugh.draft.reflection;import java.lang.reflect.Constructor;import java.lang.reflect.Method;import java.net.URL;public class RefleactionAPI public static void main (String[] args) throws Exception URL url = new URL("https://www.baidu.com" ); String urlString = url.toExternalForm(); System.out.println(urlString); System.out.println(); System.out.println("==============等价==============>" ); System.out.println(); Class<?> type = Class.forName("java.net.URL" ); Constructor<?> constructor = type.getConstructor(String.class ) ; Object instance = constructor.newInstance("https://www.baidu.com" ); Method method = type.getMethod("toExternalForm" ); Object methodCallResult = method.invoke(instance); System.out.println(methodCallResult); } }
简单的Java 反射API,还需要更深入的了解
最详细的Anaconda安装步骤和注意点 1 https://zhuanlan.zhihu.com/p/32925500
CUDA Driver版本选型 1 https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html#cuda-major-component-versions
CuDNN版本 CuDNN的版本是和CUDA版本对应,下载页面就能看到,安装十分简单,三个文件夹的文件和外面的一个文件,单独复制到已经安装好的CUDA文件夹中即可。
Maven 阿里云插件仓库配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 <repositories > <repository > <id > aliyun</id > <url > https://maven.aliyun.com/repository/public</url > <releases > <enabled > true</enabled > </releases > <snapshots > <enabled > false</enabled > </snapshots > </repository > </repositories > <pluginRepositories > <pluginRepository > <id > aliyun-plugin</id > <url > https://maven.aliyun.com/repository/public</url > <releases > <enabled > true</enabled > </releases > <snapshots > <enabled > false</enabled > </snapshots > </pluginRepository > </pluginRepositories >
IDEA配置仓库最好用HTTPS Win上有可能出现如下错误,mac上却没问题,佛了
Spring 五个常用框架
1.spring framework
2.spring boot
Spring Boot的核心思想是约定大于配置,应用只需要很少的配置即可,简化了应用开发模式。
3.Spring Data
4.Spring Cloud
5.Spring Security
本文涉及的流程与实现默认都是基于最新的5.x版本。
spring中的几个重要概念如下:
1.IOC IOC,就是控制反转,如最左边,拿公司招聘岗位来举例:
假设一个公司有产品、研发、测试等岗位。如果是公司根据岗位要求,逐个安排人选,如图中向下的箭头,这是正向流程。如果反过来,不用公司来安排候选人,而是由第三方猎头来匹配岗位和候选人,然后进行推荐,如图中向上的箭头,这就是控制反转。
在spring中,对象的属性是由对象自己创建的,就是正向流程;如果属性不是对象创建,而是由spring来自动进行装配,就是控制反转。这里的DI也就是依赖注入,就是实现控制反转的方式。正向流程导致了对象于对象之间的高耦合,IOC可以解决对象耦合的问题,有利于功能的复用,能够使程序的结构变得非常灵活。
2.context上下文和bean spring进行IOC实现时使用的有两个概念:context上下文和bean。
如中间图所示,所有被spring管理的、由spring创建的、用于依赖注入的对象,就叫做一个bean。Spring创建并完成依赖注入后,所有bean统一放在一个叫做context的上下文中进行管理。
3.AOP AOP就是面向切面编程。如右面的图,一般程序执行流程是从controller层调用service层、然后service层调用DAO层访问数据,最后在逐层返回结果。
这个是图中向下箭头所示的按程序执行顺序的纵向处理。但是,一个系统中会有多个不同的服务,例如用户服务、商品信息服务等等,每个服务的controller层都需要验证参数,都需要处理异常,如果按照图中红色的部分,对不同服务的纵向处理流程进行横切,在每个切面上完成通用的功能,例如身份认证、验证参数、处理异常等等、这样就不用在每个服务中都写相同的逻辑了,这就是AOP思想解决的问题。
AOP以功能进行划分,对服务顺序执行流程中的不同位置进行横切,完成各服务共同需要实现的功能。
Java加载properties的六种方式 Java加载properties文件的方式主要分为两大类:
一种是通过import java.util.Properties类中的load(InputStream in)方法加载;
另一种是通过import java.util.ResourceBundle类的getBundle(String baseName)方法加载。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 package com.util; import java.io.FileInputStream;import java.io.FileNotFoundException;import java.io.IOException;import java.io.InputStream;import java.util.Properties;import java.util.PropertyResourceBundle;import java.util.ResourceBundle; public class PropertiesUtil private static String basePath = "src/prop.properties" ; private static String name = "" ; private static String nickname = "" ; private static String password = "" ; public static String getName1 () try { Properties prop = new Properties(); InputStream is = new FileInputStream(basePath); prop.load(is); name = prop.getProperty("username" ); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } return name; } public static String getName2 () Properties prop = new Properties(); InputStream is = PropertiesUtil.class .getResourceAsStream("/com/util/prop.properties"); try { prop.load(is); name = prop.getProperty("username" ); } catch (IOException e) { e.printStackTrace(); } return name; } public static String getName3 () Properties prop = new Properties(); InputStream is = PropertiesUtil.class .getClassLoader () .getResourceAsStream("com/util/prop.properties"); try { prop.load(is); } catch (IOException e) { e.printStackTrace(); } return name; } public static String getName4 () Properties prop = new Properties(); InputStream is = ClassLoader .getSystemResourceAsStream("com/util/prop.properties" ); try { prop.load(is); name = prop.getProperty("username" ); } catch (IOException e) { e.printStackTrace(); } return name; } public static String getName5 () ResourceBundle rb = ResourceBundle.getBundle("com/util/prop" ); password = rb.getString("password" ); return password; } public static String getName6 () try { InputStream is = new FileInputStream(basePath); ResourceBundle rb = new PropertyResourceBundle(is); nickname = rb.getString("nickname" ); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } return nickname; } public static void main (String[] args) System.out.println("name1:" + PropertiesUtil.getName1()); System.out.println("name2:" + PropertiesUtil.getName2()); System.out.println("name3:" + PropertiesUtil.getName3()); System.out.println("name4:" + PropertiesUtil.getName4()); System.out.println("password:" + PropertiesUtil.getName5()); System.out.println("nickname:" + PropertiesUtil.getName6()); } }
GPS第三方工具 GIS基本概念
WKT(Well-known text)是开放地理空间联盟OGC(Open GIS Consortium )制定的一种文本标记语言,用于表示矢量几何对象、空间参照系统及空间参照系统之间的转换。
WKB(well-known binary) 是WKT的二进制表示形式,解决了WKT表达方式冗余的问题,便于传输和在数据库中存储相同的信息
GeoJSON 一种JSON格式的Feature信息输出格式,它便于被JavaScript等脚本语言处理,OpenLayers等地理库便是采用GeoJSON格式。此外,TopoJSON等更精简的扩展格式
几何对象 WKT可以表示的对象包括以下几种:
Point, MultiPoint
LineString, MultiLineString
Polygon, MultiPolygon
GeometryCollection
可以由多种Geometry组成,如:GEOMETRYCOLLECTION(POINT(4 6),LINESTRING(4 6,7 10)
Type
Shape
WKT
GeoJSON
Point
POINT (30 10)
{ “type”: “Point”, “coordinates”: [30, 10] }
LineString
LINESTRING (30 10, 10 30, 40 40)
{ “type”: “LineString”, “coordinates”: [ [30, 10], [10, 30], [40, 40] ] }
Polygon
POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))
{ “type”: “Polygon”, “coordinates”: [ [[30, 10], [40, 40], [20, 40], [10, 20], [30, 10]] ] }
Polygon
POLYGON ((35 10, 45 45, 15 40, 10 20, 35 10),(20 30, 35 35, 30 20, 20 30))
{ “type”: “Polygon”, “coordinates”: [ [[35, 10], [45, 45], [15, 40], [10, 20], [35, 10]], [[20, 30], [35, 35], [30, 20], [20, 30]] ] }
MultiPoint
MULTIPOINT ((10 40), (40 30), (20 20), (30 10))
{ “type”: “MultiPoint”, “coordinates”: [ [10, 40], [40, 30], [20, 20], [30, 10] ] }
MultiPoint
MULTIPOINT (10 40, 40 30, 20 20, 30 10)
{ “type”: “MultiPoint”, “coordinates”: [ [10, 40], [40, 30], [20, 20], [30, 10] ] }
MultiLineString
MULTILINESTRING ((10 10, 20 20, 10 40),(40 40, 30 30, 40 20, 30 10))
{ “type”: “MultiLineString”, “coordinates”: [ [[10, 10], [20, 20], [10, 40]], [[40, 40], [30, 30], [40, 20], [30, 10]] ] }
MultiPolygon
MULTIPOLYGON (((30 20, 45 40, 10 40, 30 20)),((15 5, 40 10, 10 20, 5 10, 15 5)))
{ “type”: “MultiPolygon”, “coordinates”: [ [ [[30, 20], [45, 40], [10, 40], [30, 20]] ], [ [[15, 5], [40, 10], [10, 20], [5, 10], [15, 5]] ] ] }
MultiPolygon
MULTIPOLYGON (((40 40, 20 45, 45 30, 40 40)),((20 35, 10 30, 10 10, 30 5, 45 20, 20 35),(30 20, 20 15, 20 25, 30 20)))
{ “type”: “MultiPolygon”, “coordinates”: [ [ [[40, 40], [20, 45], [45, 30], [40, 40]] ], [ [[20, 35], [10, 30], [10, 10], [30, 5], [45, 20], [20, 35]], [[30, 20], [20, 15], [20, 25], [30, 20]] ] ] }
WKB格式 WKB采用二进制进行存储,更方便于计算机处理,因此广泛运用于数据的传输与存储,以二位点Point(1 1)为例,
其WKB表达如下:
01 0100 0020 E6100000 000000000000F03F 000000000000F03F
byteOrder
webTypd
第二到第九字节对矢量数据基本信息进行了定义
第二与第三个字节规定了矢量数据的类型,如例子中的0100代表Point;
第三与第四个字节规定了矢量数据的维数,如例子中的0020代表该点是二位的;
第五到第九个字节规定了矢量数据的空间参考SRID,如例子中的E6100000是4326的整数十六位进制表达
srid
第五到第九个字节规定了矢量数据的空间参考SRID,如例子中的E6100000是4326的整数十六位进制表达
structPoint
第十个字节开始,每16个字节就代表一个坐标对,如例子中的000000000000F03F是浮点型1的十六进制表达
JTS 简介
JTS 是加拿大的 Vivid Solutions公司做的一套开放源码的 Java API。它提供了一套空间数据操作的核心算法。为在兼容OGC标准的空间对象模型中进行基础的几何操作提供2D空间谓词API。
操作 表示Geometry对象
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 package com.alibaba.autonavi;import com.vividsolutions.jts.geom.Coordinate;import com.vividsolutions.jts.geom.Geometry;import com.vividsolutions.jts.geom.GeometryCollection;import com.vividsolutions.jts.geom.GeometryFactory;import com.vividsolutions.jts.geom.LineString;import com.vividsolutions.jts.geom.LinearRing;import com.vividsolutions.jts.geom.Point;import com.vividsolutions.jts.geom.Polygon;import com.vividsolutions.jts.geom.MultiPolygon;import com.vividsolutions.jts.geom.MultiLineString;import com.vividsolutions.jts.geom.MultiPoint;import com.vividsolutions.jts.io.ParseException;import com.vividsolutions.jts.io.WKTReader;public class GeometryDemo private GeometryFactory geometryFactory = new GeometryFactory(); public Point createPoint () Coordinate coord = new Coordinate(109.013388 , 32.715519 ); Point point = geometryFactory.createPoint( coord ); return point; } public Point createPointByWKT () throws ParseException WKTReader reader = new WKTReader( geometryFactory ); Point point = (Point) reader.read("POINT (109.013388 32.715519)" ); return point; } public MultiPoint createMulPointByWKT () throws ParseException WKTReader reader = new WKTReader( geometryFactory ); MultiPoint mpoint = (MultiPoint) reader.read("MULTIPOINT(109.013388 32.715519,119.32488 31.435678)" ); return mpoint; } public LineString createLine () Coordinate[] coords = new Coordinate[] {new Coordinate(2 , 2 ), new Coordinate(2 , 2 )}; LineString line = geometryFactory.createLineString(coords); return line; } public LineString createLineByWKT () throws ParseException WKTReader reader = new WKTReader( geometryFactory ); LineString line = (LineString) reader.read("LINESTRING(0 0, 2 0)" ); return line; } public MultiLineString createMLine () Coordinate[] coords1 = new Coordinate[] {new Coordinate(2 , 2 ), new Coordinate(2 , 2 )}; LineString line1 = geometryFactory.createLineString(coords1); Coordinate[] coords2 = new Coordinate[] {new Coordinate(2 , 2 ), new Coordinate(2 , 2 )}; LineString line2 = geometryFactory.createLineString(coords2); LineString[] lineStrings = new LineString[2 ]; lineStrings[0 ]= line1; lineStrings[1 ] = line2; MultiLineString ms = geometryFactory.createMultiLineString(lineStrings); return ms; } public MultiLineString createMLineByWKT () throws ParseException WKTReader reader = new WKTReader( geometryFactory ); MultiLineString line = (MultiLineString) reader.read("MULTILINESTRING((0 0, 2 0),(1 1,2 2))" ); return line; } public Polygon createPolygonByWKT () throws ParseException WKTReader reader = new WKTReader( geometryFactory ); Polygon polygon = (Polygon) reader.read("POLYGON((20 10, 30 0, 40 10, 30 20, 20 10))" ); return polygon; } public MultiPolygon createMulPolygonByWKT () throws ParseException WKTReader reader = new WKTReader( geometryFactory ); MultiPolygon mpolygon = (MultiPolygon) reader.read("MULTIPOLYGON(((40 10, 30 0, 40 10, 30 20, 40 10),(30 10, 30 0, 40 10, 30 20, 30 10)))" ); return mpolygon; } public GeometryCollection createGeoCollect () throws ParseException LineString line = createLine(); Polygon poly = createPolygonByWKT(); Geometry g1 = geometryFactory.createGeometry(line); Geometry g2 = geometryFactory.createGeometry(poly); Geometry[] garray = new Geometry[]{g1,g2}; GeometryCollection gc = geometryFactory.createGeometryCollection(garray); return gc; } public Polygon createCircle (double x, double y, final double RADIUS) final int SIDES = 32 ; Coordinate coords[] = new Coordinate[SIDES+1 ]; for ( int i = 0 ; i < SIDES; i++){ double angle = ((double ) i / (double ) SIDES) * Math.PI * 2.0 ; double dx = Math.cos( angle ) * RADIUS; double dy = Math.sin( angle ) * RADIUS; coords[i] = new Coordinate( (double ) x + dx, (double ) y + dy ); } coords[SIDES] = coords[0 ]; LinearRing ring = geometryFactory.createLinearRing( coords ); Polygon polygon = geometryFactory.createPolygon( ring, null ); return polygon; } public static void main (String[] args) throws ParseException GeometryDemo gt = new GeometryDemo(); Polygon p = gt.createCircle(0 , 1 , 2 ); Coordinate coords[] = p.getCoordinates(); for (Coordinate coord:coords){ System.out.println(coord.x+"," +coord.y); } } }
火星坐标系 在谷歌还没有发布谷歌地图时,在GIS领域常见的坐标系主要有WGS84经纬度坐标、北京54坐标或西安80坐标等;但自从谷歌地图发布之后,其海量的高清卫星免费影像是让整个GIS领域为之震惊的,但同时也为安全问题带来了一定的隐患。为了对实际坐标进行加密,于是国测局研究了一套算法,凡是公开发布的商业互联网地图,一定要在此加密算法的基础上进行发布,这样一来地图的坐标就与实地的坐标不相符了,于是大家把这种坐标戏称为“火星坐标”,这里我们就针对这一坐标作一些更为详细的说明。
所有的电子地图、导航设备,都需要加入该保密插件。第一步,地图公司测绘地图,测绘完成后,送到国家测绘局,将真实坐标的电子地图,加密成“火星坐标”,这样的地图才是可以出版和发布的,然后才可以让GPS公司处理。第二步,所有的GPS公司,只要需要汽车导航的,需要用到导航电子地图的,都需要在软件中加入该保密算法,将COM口读出来的真实的坐标信号,加密转换成ZF要求的保密的坐标。这样,GPS导航仪和导航电子地图就可以完全匹配,GPS也就可以正常工作了。
GCJ02
GCJ-02是由中国国家测绘局(G表示Guojia国家,C表示Cehui测绘,J表示Ju局)制订的地理信息系统的坐标系统。
中文名:国家测量局02号标准
外文名:GCJ-02
它是一种对经纬度数据的加密算法,即加入随机的偏差。
国内出版的各种地图系统(包括电子形式),必须至少采用GCJ-02对地理位置进行首次加密。
综上所述,其实火星坐标系和GCJ-02是同一种事物,它是国家测量(绘)局制定的02号标准,是一种对经纬度坐标进行非线性的随机加偏算法。
为了响应国家制定的标准,国内所有在线地图服务商(如百度地图、高德地图、搜狗地图和SOSO地图等)和国外部分在线地图服务商(如谷歌地图、必应地图和雅虎地图等)都必须进行GCJ-02加密才对公众进行开放,这就是为什么大家在用地图时总是发现有偏移的原因。
GCJ-02只是一种坐标偏移标准(算法),对投影没有任何限制,如果再以投影为基础作细分
PrototBuf
IDEA莫名其妙每次自动生成变量都有final修饰符
FlinkKafka兼容性
Maven Dependency
Supported since
Consumer and Producer Class name
Kafka version
Notes
flink-connector-kafka-0.8_2.11
1.0.0
FlinkKafkaConsumer08 FlinkKafkaProducer08
0.8.x
Uses the SimpleConsumer API of Kafka internally. Offsets are committed to ZK by Flink.
flink-connector-kafka-0.9_2.11
1.0.0
FlinkKafkaConsumer09 FlinkKafkaProducer09
0.9.x
Uses the new Consumer API Kafka.
flink-connector-kafka-0.10_2.11
1.2.0
FlinkKafkaConsumer010 FlinkKafkaProducer010
0.10.x
This connector supports Kafka messages with timestamps both for producing and consuming.
flink-connector-kafka-0.11_2.11
1.4.0
FlinkKafkaConsumer011 FlinkKafkaProducer011
0.11.x
Since 0.11.x Kafka does not support scala 2.10. This connectorsupports Kafka transactional messaging to provide exactly once semantic for the producer.
flink-connector-kafka_2.11
1.7.0
FlinkKafkaConsumer FlinkKafkaProducer
>= 1.0.0
This universal Kafka connector attempts to track the latest version of the Kafka client.The version of the client it uses may change between Flink releases.Modern Kafka clients are backwards compatible with broker versions 0.10.0 or later.However for Kafka 0.11.x and 0.10.x versions, we recommend using dedicatedflink-connector-kafka-0.11_2.11 and flink-connector-kafka-0.10_2.11 respectively.Attention: as of Flink 1.7 the universal Kafka connector is considered to be in a BETA status and might not be as stable as the 0.11 connector. In case of problems withthe universal connector, you can try to use flink-connector-kafka-0.11_2.11 which should be compatible with all of the Kafka versions starting from 0.11.
关于数据仓库数据中台数据湖的一部分图片
元数据管理还有个普元元数据
Mac版本的终端要走Proxy除了梯子还需要一个设置 1 2 3 # proxy list alias proxy='export all_proxy=socks5://127.0.0.1:1080' alias unproxy='unset all_proxy'
无状态 和 有状态 的区别 在整个程序生态圈中,无状态的意思总是 不需要自己手动关闭,有状态的意识是 总是需要自己手动关闭
Linux Command most + more + less more, less and most are three pagers, we can compare them this way:
less is more than more,most is more than more, aproximatly,less and most are different, none is better.
linux通过进程号查看运行文件目录 CentOS查看版本 1 2 3 4 5 6 7 8 9 10 11 hostnamectl Static hostname: datanode127 Icon name: computer-server Chassis: server Machine ID: abe6faef122d47c1a66436e7936b4301 Boot ID: 8010542f5e21440797d9e3fc669fb752 Operating System: CentOS Linux 7 (Core) CPE OS Name: cpe:/o:centos:centos:7 Kernel: Linux 3.10.0-693.el7.x86_64 Architecture: x86-64
文件目录大小常见的命令 1 2 3 4 5 6 7 8 9 10 11 12 13 14 flyhugh@MacBook-Pro-2 ~/Documents/Env pwd /Users/flyhugh/Documents/Env flyhugh@MacBook-Pro-2 ~/Documents/Env ls apache-maven-3.6.3 brew_install.rb flyhugh@MacBook-Pro-2 ~/Documents/Env du -sh 7.2G . flyhugh@MacBook-Pro-2 ~/Documents/Env df -h Filesystem Size Used Avail Capacity iused ifree %iused Mounted on /dev/disk1s5 466Gi 10Gi 180Gi 6% 488290 4882988630 0% / devfs 187Ki 187Ki 0Bi 100% 646 0 100% /dev /dev/disk1s1 466Gi 271Gi 180Gi 61% 2520713 4880956207 0% /System/Volumes/Data /dev/disk1s4 466Gi 3.0Gi 180Gi 2% 4 4883476916 0% /private/var/vm map auto_home 0Bi 0Bi 0Bi 100% 0 0 100% /System/Volumes/Data/home /dev/disk1s3 466Gi 504Mi 180Gi 1% 54 4883476866 0% /Volumes/Recovery
Linux生僻命令 在两个文件夹之间来回切换
递归创建目录
Win10网络问题汇总 用无线网有个问题就是电脑开机时间久了 加上我使用科学上网频繁开关,导致网络会有错乱问题,在系统开了很多东西的情况下,直接重启,导致了网络错误,打开IDEA的时候出现了错误提示
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 Internal error. Please refer to http://jb.gg/ide/critical-startup-errors java.net.BindException: Address already in use: bind at java.base/sun.nio.ch.Net.bind0(Native Method) at java.base/sun.nio.ch.Net.bind(Net.java:461) at java.base/sun.nio.ch.Net.bind(Net.java:453) at java.base/sun.nio.ch.ServerSocketChannelImpl.bind(ServerSocketChannelImpl.java:227) at io.netty.channel.socket.nio.NioServerSocketChannel.doBind(NioServerSocketChannel.java:132) at io.netty.channel.AbstractChannel$AbstractUnsafe.bind(AbstractChannel.java:551) at io.netty.channel.DefaultChannelPipeline$HeadContext.bind(DefaultChannelPipeline.java:1345) at io.netty.channel.AbstractChannelHandlerContext.invokeBind(AbstractChannelHandlerContext.java:503) at io.netty.channel.AbstractChannelHandlerContext.bind(AbstractChannelHandlerContext.java:488) at io.netty.channel.DefaultChannelPipeline.bind(DefaultChannelPipeline.java:984) at io.netty.channel.AbstractChannel.bind(AbstractChannel.java:247) at io.netty.bootstrap.AbstractBootstrap$2.run(AbstractBootstrap.java:355) at io.netty.util.concurrent.AbstractEventExecutor.safeExecute(AbstractEventExecutor.java:163) at io.netty.util.concurrent.SingleThreadEventExecutor.runAllTasks(SingleThreadEventExecutor.java:416) at io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:515) at io.netty.util.concurrent.SingleThreadEventExecutor$5.run(SingleThreadEventExecutor.java:918) at io.netty.util.internal.ThreadExecutorMap$2.run(ThreadExecutorMap.java:74) at java.base/java.lang.Thread.run(Thread.java:834)
这个错误造成的原因就是hypervisior(Windows 10的Hyper-V虚拟机),把端口保留了
解决方法也很简单,hypervisior 重新开关一下
1 2 3 4 5 6 7 8 Disable hyper-v (which will required a couple of restarts) dism.exe /Online /Disable-Feature:Microsoft-Hyper-V When you finish all the required restarts, reserve the port you want so hyper-v doesn't reserve it back netsh int ipv4 add excludedportrange protocol=tcp startport=<端口号> numberofports=1 Re-Enable hyper-V (which will require a couple of restart) dism.exe /Online /Enable-Feature:Microsoft-Hyper-V /All
实际使用中第一个命令执行完直接重启就行了。
win10图形化查看端口占用工具 cports
重置win10网络命令 netsh winsock reset
win10远程窗口大小不可调的问题 我的显示器分辨率比较高,两台显示器都是4K分辨率的,但是远程的时候默认是锁定1600 * 1200的
并且默认是窗口化的,无法调整大小,这个时候需要使用命令行配置一下远程窗口的分辨率
1 mstsc /w:2560 /h:1440 /f
这个命令分别是长宽和全屏设置。
给win10商店设置代理 最近发现。。。只要有一个好的代理服务器,win10的商店原来也是能随便打开的,这里介绍一下win10的商店的流量怎么走代理
1 首先通过 Win + R 快捷键打开「运行」窗口,输入「Regedit」打开注册表编辑器,然后定位到 HKEY_CURRENT_USER\Software\Classes\Local Settings\Software\Microsoft\Windows\CurrentVersion\AppContainer\Mappings,接着在左边的注册表项中找到你想解除网络隔离的应用,右边的 DisplayName 就是应用名称,而左边那一大串字符就是应用的 SID 值了。
找到这个值之后,然后在cmd命令行中输入:
CheckNetIsolation.exe loopbackexempt -a -p=SID
这SID就是上面搜索到的,这样就行
关于SSTap转发UDP的问题 查看SSTap是否成功转发UDP需要用到一个工具,netcat,简称nc,使用这个工具,在命令行中
就可以像服务器发送UDP请求,然后在服务器上使用root用户
就可以查看转发日志
Tips:我在ubuntu上设置的ss-server 默认是不打开udp的端口的,需要在开启的时候手动打开。(加上 -u)
1 nohup ss-server -c /etc/shadowsocks.json -u
验证:
1 netstat -lnp | grep 10000
1 2 3 root@ubuntu:/home/ubuntu# netstat -lnp | grep 10000 tcp 0 0 0.0.0.0:10000 0.0.0.0:* LISTEN 25056/ss-server udp 0 0 0.0.0.0:10000 0.0.0.0:* 25056/ss-server
如图可以看到端口已经开放了udp和tcp即可,udp是无状态的,不会显示LISTEN,这个是正确的。
最终结论:是服务器上的SSR没有开启UDP转发,默认是不转发UDP的,这个是有问题的。
win10 访问墙外世界的最终办法: 使用 SSTap这类软件,SSTap是比较简单的,复杂的软件会有流量分流等等功能。
SSTap新建了一个虚拟网卡,所有的流量从新的虚拟网卡中转发出去,不用再考虑软件的流量进出口有没有被代理等等问题。
Win下Chrome无法访问新浪外链地址 拓展解决:
https://chrome.google.com/webstore/detail/wbimgfix/bdhgcfmghkbbdmejdaadfdhhdjphogkp/related
云服务器通过转发windows的3389端口,实现远程对PC的访问 https://www.jianshu.com/p/939dd2f78399
使用了文中的方法,需要注意的方法不是很多,一个是和 ssh 配置有关的问题,最后采用的配置文件,我在最后贴出来(这种配置文件下可以使用root帐号登录)。配置完成后使用
重启服务。
登录用到的keygen需要在cygwin64的文件系统中单独保存,使用的并不是windows下面的路径。
我最终使用的命令是
1 ssh -o ServerAliveInterval=180 -i /home/key/id_rsa_oracle_2 root@#服务器IP# -p 22 -R #以后远程登录要使用的端口,不建议使用3389,为了安全#:127.0.0.1:3389 -fN
ssh配置文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 # $OpenBSD: sshd_config,v 1.100 2016/08/15 12:32:04 naddy Exp $# This is the sshd server system-wide configuration file. See# sshd_config(5) for more information.# This sshd was compiled with PATH=/usr/local/bin:/usr/bin# The strategy used for options in the default sshd_config shipped with# OpenSSH is to specify options with their default value where# possible, but leave them commented. Uncommented options override the# default value.# If you want to change the port on a SELinux system, you have to tell# SELinux about this change.# semanage port -a -t ssh_port_t -p tcp #PORTNUMBER# # Port 22# AddressFamily any# ListenAddress 0.0.0.0# ListenAddress ::HostKey /etc/ssh/ssh_host_rsa_key # HostKey /etc/ssh/ssh_host_dsa_keyHostKey /etc/ssh/ssh_host_ecdsa_key HostKey /etc/ssh/ssh_host_ed25519_key # Ciphers and keying# RekeyLimit default none# Logging# SyslogFacility AUTHSyslogFacility AUTHPRIV # LogLevel INFO# Authentication:# LoginGraceTime 2mPermitRootLogin yes # StrictModes yes# MaxAuthTries 6# MaxSessions 10# PubkeyAuthentication yes# The default is to check both .ssh/authorized_keys and .ssh/authorized_keys2# but this is overridden so installations will only check .ssh/authorized_keysAuthorizedKeysFile .ssh/authorized_keys # AuthorizedPrincipalsFile none# AuthorizedKeysCommand none# AuthorizedKeysCommandUser nobody# For this to work you will also need host keys in /etc/ssh/ssh_known_hosts# HostbasedAuthentication no# Change to yes if you don't trust ~/.ssh/known_hosts for# HostbasedAuthentication# IgnoreUserKnownHosts no# Don't read the user's ~/.rhosts and ~/.shosts files# IgnoreRhosts yes# To disable tunneled clear text passwords, change to no here!# PasswordAuthentication yes# PermitEmptyPasswords noPasswordAuthentication yes # Change to no to disable s/key passwords# ChallengeResponseAuthentication yesChallengeResponseAuthentication no # Kerberos options# KerberosAuthentication no# KerberosOrLocalPasswd yes# KerberosTicketCleanup yes# KerberosGetAFSToken no# KerberosUseKuserok yes# GSSAPI optionsGSSAPIAuthentication yes GSSAPICleanupCredentials no # GSSAPIStrictAcceptorCheck yes# GSSAPIKeyExchange no# GSSAPIEnablek5users no# Set this to 'yes' to enable PAM authentication, account processing,# and session processing. If this is enabled, PAM authentication will# be allowed through the ChallengeResponseAuthentication and# PasswordAuthentication. Depending on your PAM configuration,# PAM authentication via ChallengeResponseAuthentication may bypass# the setting of "PermitRootLogin without-password".# If you just want the PAM account and session checks to run without# PAM authentication, then enable this but set PasswordAuthentication# and ChallengeResponseAuthentication to 'no'.# WARNING: 'UsePAM no' is not supported in Red Hat Enterprise Linux and may cause several# problems.UsePAM yes # AllowAgentForwarding yes# AllowTcpForwarding yesGatewayPorts yes X11Forwarding yes # X11DisplayOffset 10# X11UseLocalhost yes# PermitTTY yes# PrintMotd yes# PrintLastLog yes# TCPKeepAlive yes# UseLogin no# UsePrivilegeSeparation sandbox# PermitUserEnvironment no# Compression delayed# ClientAliveInterval 0# ClientAliveCountMax 3# ShowPatchLevel no# UseDNS yes# PidFile /var/run/sshd.pid# MaxStartups 10:30:100# PermitTunnel no# ChrootDirectory none# VersionAddendum none# no default banner path# Banner none# Accept locale-related environment variablesAcceptEnv LANG LC_CTYPE LC_NUMERIC LC_TIME LC_COLLATE LC_MONETARY LC_MESSAGES AcceptEnv LC_PAPER LC_NAME LC_ADDRESS LC_TELEPHONE LC_MEASUREMENT AcceptEnv LC_IDENTIFICATION LC_ALL LANGUAGE AcceptEnv XMODIFIERS # override default of no subsystemsSubsystem sftp /usr/libexec/openssh/sftp-server # Example of overriding settings on a per-user basis# Match User anoncvs# X11Forwarding no# AllowTcpForwarding no# PermitTTY no# ForceCommand cvs server
这种访问方式有点过于笨重,后来采用了frp工具来实现了远程代理
https://zhuanlan.zhihu.com/p/138092534
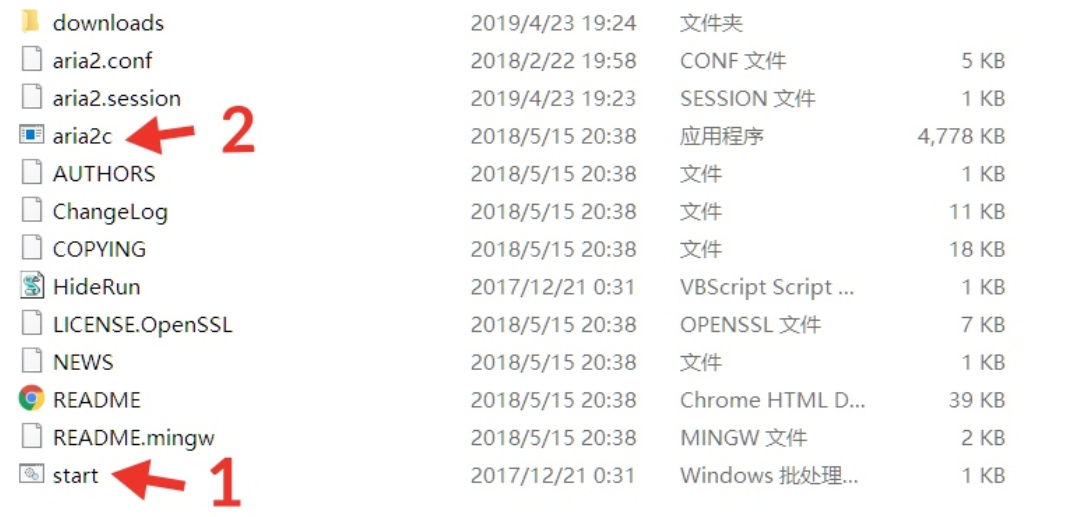
BT下载 扔掉迅雷
Aria2 下载 解压
配置文件 下载 解压
按照顺序使用管理员打开
默认的下载目录为downloads,可通过修改aria2.conf配置文件改变下载目录。
Aria2的没有自带下载面板的,因此需要自行下载第三方的面板。
常用的Aria2_Web有YAAW、webui-aria2、AriaNg
1 2 3 YAAW:https://github.com/binux/yaaw/archive/master.zip AriaNg:https://github.com/mayswind/AriaNg/releases webui-aria2:https://github.com/ziahamza/webui-aria2/archive/master.zip
我这里尝试使用AriaNg,下载下来直接点击那个网页就能使用,修改一下tracker
https://trackerslist.com/#/zh?id=xiu2trackerslistcollection
Tracker列表
网络知识 TCP/IP 建立TCP需要三次握手才能建立(客户端发起SYN,服务端SYN+ACK,客户端ACK),
断开连接则需要四次握手(客户端和服务端都可以发起,FIN-ACK-FIN-ACK)。
为什么连接的时候是三次握手,关闭的时候却是四次握手?
答:
SYN攻击:发送大量的SYN,导致服务端无法识别哪些是有效的
RPC RPC是指远程调用,两服务器A,B,A要调用B上的一个方法,由于不在一个内存空间,不能直接调用,需要通过网络来表达调用的语义和传达调用的数据
通讯问题:在客户端和服务端建立TCP连接,远程调用的所有交换数据都在这个连接里传输。
解决寻址问题:IP及端口寻址,方法名
序列化(Serialize):发生远程调用时,方法的参数需要通过底层的网络协议如TCP传送到服务器,由于网络协议是基于二进制的,内存中的参数值需要序列化成二进制的形式,通过寻址和传输序列化的二进制发送给服务器。
服务器反序列化:服务器收到请求后需要反序列化,恢复内存中的表达方式,然后找到对应的方法(寻址的一部分),进行本地调用。
返回值发送给客户端,这个部分也需要序列化和反序列化。
SOA
采用一组服务的方式来构建一个应用,服务(hedwig、jsf、RESTful)独立部署在不同的进程中,不同服务通过一些轻量级交互机制来通信,例如RPC、HTTP等。服务可独立扩展伸缩,每个服务定义了明确的边界,不同的服务甚至可以采用不同的编程语言来实现,由独立的团队来维护。
RPC 的实现是基于SOA这样的一个架构 C/S模式 远程调用的通讯使用TCP 然后hedwig restful jsf这些就是不同的服务形式
**http协议和tcp/ip 协议的关系
1. http协议是无状态的 ,指的是http协议对于事务处理没有记忆功能,客户端向服务端请求完数据之后,服务端不知道客户端是什么状态。
2. http的长连接和短连接,本质上是tcp层的长连接和短连接:
http 1.0 默认使用短连接,http 1.1 默认使用长连接,在使用的http协议,在响应头会加上 Connection:keep-alive
3. RPC比http请求快的原因 :http使用http协议,rpc使用tcp协议,比http少了应用层,表示层,会话层,这3层,rpc使用长连接,而长连接比短连接更节省资源,效率更高(每个连接的建立和释放都是需要资源和时间的)。
TCP/IP
是个协议组,可分为三个层次:网络层、传输层和应用层。
在网络层有IP协议、ICMP协议、ARP协议、RARP协议和BOOTP协议。
在传输层中有TCP协议与UDP协议。
在应用层有:TCP包括FTP、HTTP、TELNET、SMTP等协议
UDP包括DNS、TFTP等协议
当网络通信时采用TCP协议时,在真正的读写操作之前,server与client之间必须建立一个连接,当读写操作完成后,双方不再需要这个连接时它们可以释放这个连接,连接的建立是需要三次握手的,而释放则需要4次握手,所以说每个连接的建立都是需要资源消耗和时间消耗的。
通信过程:
主机 A 的应用程序要能和主机 B 的应用程序通信,必须通过 Socket 建立连接,而建立 Socket 连接必须需要底层 TCP/IP 协议来建立 TCP 连接。建立 TCP 连接需要底层 IP 协议来寻址网络中的主机。我们知道网络层使用的 IP 协议可以帮助我们根据 IP 地址来找到目标主机,但是一台主机上可能运行着多个应用程序,如何才能与指定的应用程序通信就要通过 TCP 或 UPD 的地址也就是端口号来指定。这样就可以通过一个 Socket 实例唯一代表一个主机上的一个应用程序的通信链路了。
建立通信链路
当客户端 要与服务端通信,客户端首先要创建一个 Socket 实例,操作系统将为这个 Socket 实例分配一个没有被使用的本地端口号,并创建一个包含本地和远程地址和端口号的套接字数据结构,这个数据结构将一直保存在系统中直到这个连接关闭。在创建 Socket 实例的构造函数正确返回之前,将要进行 TCP 的三次握手协议,TCP 握手协议完成后,Socket 实例对象将创建完成,否则将抛出 IOException 错误。
与之对应的服务端 将创建一个 ServerSocket 实例,ServerSocket 创建比较简单只要指定的端口号没有被占用,一般实例创建都会成功,同时操作系统也会为 ServerSocket 实例创建一个底层数据结构,这个数据结构中包含指定监听的端口号和包含监听地址的通配符,通常情况下都是“*”即监听所有地址。之后当调用 accept() 方法时,将进入阻塞状态,等待客户端的请求。当一个新的请求到来时,将为这个连接创建一个新的套接字数据结构,该套接字数据的信息包含的地址和端口信息正是请求源地址和端口。这个新创建的数据结构将会关联到 ServerSocket 实例的一个未完成的连接数据结构列表中,注意这时服务端与之对应的 Socket 实例并没有完成创建,而要等到与客户端的三次握手完成后,这个服务端的Socket 实例才会返回,并将这个 Socket 实例对应的数据结构从未完成列表中移到已完成列表中。所以 ServerSocket 所关联的列表中每个数据结构,都代表与一个客户端的建立的TCP 连接。
TCP短连接
TCP短连接,client向server发起连接请求,server接到请求,然后双方建立连接。client向server 发送消息,server回应client,然后一次读写就完成了,这时候双方任何一个都可以发起close操作,不过一般都是client先发起 close操作。因为一般的server不会回复完client后立即关闭连接的,当然不排除有特殊的情况。从上面的描述看,短连接一般只会在client/server间传递一次读写操作。短连接的优点是:管理起来比较简单,存在的连接都是有用的连接 ,不需要额外的控制手段。
TCP长连接
长连接,client向server发起连接,server接受client连接,双方建立连接。Client与server完成一次读写之后,它们之间的连接并不会主动关闭,后续的读写操作会继续使用这个连接。
TCP保活功能 ,保活功能主要为服务器应用提供,服务器应用希望知道客户主机是否崩溃,从而可以代表客户使用资 源。如果客户已经消失,使得服务器上保留一个半开放的连接,而服务器又在等待来自客户端的数据,则服务器将应远等待客户端的数据,保活功能就是试图在服务器端检测到这种半开放的连接。如果一个给定的连接在两小时内没有任何的动作,则服务器就向客户发一个探测报文段。客户主机必须处于以下4个状态之一:
1.客户主机依然正常运行,并从服务器可达。客户的TCP响应正常,而服务器也知道对方是正常的,服务器在两小时后将保活定时器复位。
2.客户主机已经崩溃,并且关闭或者正在重新启动。在任何一种情况下,客户的TCP都没有响应。服务端将不能收到对探测的响应,并在75秒后超时。服务器总共发送10个这样的探测 ,每个间隔75秒。如果服务器没有收到一个响应,它就认为客户主机已经关闭并终止连接。
3.客户主机崩溃并已经重新启动。服务器将收到一个对其保活探测的响应,这个响应是一个复位,使得服务器终止这个连接。
4.客户机正常运行,但是服务器不可达,这种情况与2类似,TCP能发现的就是没有收到探查的响应。
从上面可以看出,TCP保活功能主要为探测长连接的存活状况,不过这里存在一个问题,存活功能的探测周期太长,还有就是它只是探测TCP连接的存活,属于比较斯文的做法,遇到恶意的连接时,保活功能就不够使了。
在长连接的应用场景下,client端一般不会主动关闭它们之间的连接,Client与server之间的连接如果一直不关闭的话,会存在一个问 题,随着客户端连接越来越多,server早晚有扛不住的时候,这时候server端需要采取一些策略,如关闭一些长时间没有读写事件发生的连接,这样可以避免一些恶意连接导致server端服务受损;如果条件再允许就可以以客户端机器为颗粒度,限制每个客户端的最大长连接数,这样可以完全避免某个蛋疼的客户端连累后端服务。
长连接和短连接的产生在于client和server采取的关闭策略,具体的应用场景采用具体的策略,没有十全十美的选择,只有合适的选择。
HTTP长连接与短连接
长连接 :client方与server方先建立连接,连接建立后不断开,然后再进行报文发送和接收。
这种方式下由于通讯连接一直存在。此种方式常用于P2P通信。
短连接 :Client方与server每进行一次报文收发交易时才进行通讯连接,交易完毕后立即断开连接。
此方式常用于一点对多点通讯。C/S通信。
长连接和短连接异同
长连接: 长连接多用于操作频繁,点对点的通讯,而且连接数不能太多的情况。
每个TCP连接的建立都需要三次握手,每个TCP连接的断开要四次握手。
如果每次操作都要建立连接然后再操作的话处理速度会降低,所以每次操作后,下次操作时直接发送数据就可以了,不用再建立TCP连接。例如:数据库的连接用长连接,如果用短连接频繁的通信会造成socket错误,频繁的socket创建也是对资源的浪费。
\ 短连接\
发送接收方式
1、异步:报文发送和接收是分开的,相互独立,互不影响的。这种方式又分两种情况:
异步双工: 接收和发送在同一个程序中,有两个不同的子进程分别负责发送和接送。
异步单工: 接送和发送使用两个不同的程序来完成。
2、同步:报文发送和接收是同步进行,即报文发送后等待接送返回报文。同步方式一般需要考虑超时问题,试想我们发送报文以后也不能无限等待啊,所以我们要设定一个等待时候。超过等待时间发送方不再等待读返回报文。直接通知超时返回。
阻塞与非阻塞方式
1、非阻塞方式:读函数不停的进行读动作,如果没有报文接收到,等待一段时间后超时返回,这种情况一般需要指定超时时间。
2、阻塞方式:如果没有接收到报文,则读函数一直处于等待状态,知道报文到达。
及时通信与游戏的长短连接
实际场合究竟需要使用短连接还是长连接,主要看实时性要求、数据流向和并发量这三个问题。
长连接优点: 节约TCP握手时间,可以保证高实时性,数据流向可以采用服务器端的主动推模式。长连接缺点 :并发量不宜太高,持续占用服务端口(相对消耗资源)。
长连接、长轮询一般应用与WebIM、ChatRoom和一些需要及时交互的网站应用中。其真实案例有:WebQQ、Hi网页版、Facebook IM等。
1.现在游戏中的玩家与玩家之间的聊天无法实现实时性,而且系统有邮件或信息时也不能及时的通知玩家
2.客户端每隔几秒就会发送一个请求,这样服务器的压力岂不是很大?
NIO没有任何问题,大规模长连接处理的主流都是用NIO;而且也不是Java发明的,本身就是借助了操作系统的网络管理能力。
http keep-alive与tcp keep-alive ,不是同一回事,意图不一样。http keep-alive是为了让tcp活得更久一点,以便在同一个连接上传送多个http,提高socket的效率。而tcp keep-alive是TCP的一种检测TCP连接状况的保鲜机制
Maven问题汇总 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 <plugin > <groupId > org.apache.maven.plugins</groupId > <artifactId > maven-antrun-plugin</artifactId > <executions > <execution > <phase > generate-resources</phase > <configuration > <target > <exec executable ="cmd" > <arg value ="${project.basedir}/../build/spark-build-info" /> <arg value ="${project.build.directory}/extra-resources" /> <arg value ="${project.version}" /> </exec > </target > </configuration > <goals > <goal > run</goal > </goals > </execution > </executions > </plugin >
上面的这个插件 antrun里面的命令在linux环境下使用bash没有问题,在linux环境下应该配置bash
Maven手动添加Jar包之后没有加载 File->Setting->Maven->Repositories->Update(选择本地仓库的路径)
Active 使用遇到的坑 线上activemq内存超过限制,导致生产者无法推送告警信息。Activemq重启,导致部分堆积数据丢失
考虑一下ActiveMQ的监控
Redis持久化 RDB模式全栈快照,当内存比较大,访问比较频繁时(我们的设备实时信息是典形的写多读少,异于一般的写少读多的情况),刷新频率高,磁盘IO要求非常大。
AOF模式,文件体大,Rewrite时会有RDB类似的情况
AOF重写或是RDB进行Dump时都会fork子进程,当Redis使用物理内存过半时,会失败
LinkedList等队列size() JDK自带队列size()需要遍历集合,如果集合数据比较大,且该函数比较频繁访问情况下,可能会有性能问题。并发接近万数量级慎用
(可以用Stopwatch监控程序每个步骤运行时间)
开源协议
Flink问题汇总 Flink使用滑动窗口出现的一个问题 使用滑动窗口保存checkpoint失败,日志里面没有错误日志,个别情况下在使用不同的时间语义会出现成功的情况。
Flink数据写入了HDFS,Hive没有识别 1.11版本,需要设置sink.partition.commit参数,分区表
Flink-1.12.0编译密码: flink-runtime-web工程有几个特点,
=> 在网络OK,别的问题都没有的情况下,第一次编译成功,后面编译的话会报错(npm或者node.js被占用的错误),也就是说,只有第一次能编译成功。
时空数据结构简介
后面如果有时间的话 会把这部分独立出去重新整理一章
所谓时空数据,顾名思义,包含了两个维度的信息:空间信息与时间信息。空间信息,以地理位置点最为基础,还包括线、多边形以及更为复杂的多维结构。最典型的时空数据,莫过于移动对象的轨迹点数据,如每隔5秒钟记录的车辆实时位置信息。这类数据,在物联网领域司空见惯,在可预见的未来,这类数据将会出现爆炸性的增长。
关于时空索引,这里,了解到的主流技术有R-Trees、Quad-Trees、K-D Trees以及Space Filling Curve这四种技术。
RTree R-Trees源自论文《R-Trees: A Dynamic Index Structure For Spatial Searching》,下面的图也源自此论文:
R-Trees基于这样的思想设计:
每一个空间对象,如一个多边形区域,都存在一个最小的矩形,能够恰好包含此时空对象,如上图中的矩形R6所包含的弯月形区域。这个最小包围矩形被称之为MBR(Minimum Bounding Rectangle)。
多个相邻的矩形,可以被包含在一个更大的最小包围矩形中。如R6、R9以及R10三个矩形,可以被包含在R3中,而R11与R12则被包含在R4中。
继续迭代,总能找到若干个最大的区域,以一种树状的形式,将所有的时空对象给容纳进去,如上图中的R1, R2。这样,整个树状结构,呈现如下:
从最小的矩形区域,到最大的矩形区域,就好比地图中的行政区域划分:村 -> 县 -> 市 -> 省份。查询时,先从锁定的最大区域开始,逐级缩小比例尺后,就可找到最终的对象。如若将上图中的R1与R2理解成两个平级的”行政区域”,却又存在本质的区别:不同的行政区域,并不存在相互重叠,而R1与R2却可能是重叠的。
R-Trees的定义:
每一个Leaf Node包含m到M个索引记录(Root节点除外)。
每一个索引记录是一个关于(I, tuple-identifier)的二元组信息,I是空间对象的最小包围矩形,而tuple-identifier用来描述空间对象本身。
每一个Non-leaf节点,包含m到M个子节点(Root节点除外)。
Non-leaf节点上的每一个数据元素,是一个(I, child-pointer)的二元组信息,child-pointer指向其中一个子节点,而I则是这个子节点上所有矩形的最小包围矩形。
上图中,R3、R4以及R5,共同构成一个non-leaf节如点,R3指向包含元素R8,R9以及R10的子节点,这个指针就是child-pointer,而与R8,R9以及R10相关的最小包围矩形,就是I。
Root节点至少包含两个子节点,除非它本身也是一个Leaf Node。
所有的Leaf Nodes都出现在树的同一层上。
从定义上来看,R-Trees与B-Trees存在诸多类似:Root节点与Non-Leaf节点,均包含限定数量的子节点;所有的Leaf Nodes都出现在树的同一层上。这两种树也都是自平衡 的。
前面也已经提到了,B-Trees主要用来存放一维排序的数据元素,而R-Tree存放的则是多维空间数据元素。从查询方式上来看,两者也存在显著的差异:B-Trees更擅长于数据点查,它的设计并不利于数据的范围查询。基于空间元素的查询,却以范围查询为主,而且往往需要对多个子树进行并行查询,例如,在地图上划定某一个区域,查询这个区域内有哪些公园,可能有多个子树都与划定的这个区域存在交集。从这一点看来,R-Tree的搜索性能其实并没有很好的保障。
R-Trees有多种变种,如R+-Trees,R*-Trees,X-Trees, M-Trees,BR-Trees等等,不再展开过多的介绍。
Quad-Trees HBase中的数据按照RowKey单维度排序组织,而我们现在却面临的是一个多维数据问题。因此,HBase如果想很好的支持时空数据的存储,需要引入时空索引技术。
上图中的A,B,C,E,F,G均为Point,以每一个Point作为中心点,可以将一个区间分成4个象限。
假设,先写入Point A,以A为中心,将整个区间分成了4个象限。
写入Point B,Point B位于A的东北象限中,同样,以B为中心,依然可以将A东北象限进一步细分为4个子象限。
写入Point C,Point C位于A的东南象限中,以C为中心,可以将A的东南象限细分成4个子象限。
…..
任何新写入的一个Point,总能找到一个某一个已存在的Point的子象限,来存放这个新的Point。
整个树状结构呈现如下:
可见,Quad-Trees有几个鲜明的特点:1. 对于非叶子节点,均包含4个子节点,对应4个面积不一的象限。2.不平衡,树的结构与数据的写入顺序直接相关 。3.有空的Leaf Nodes,且所有的Leaf Nodes则是”参差不齐”的(并不一定都出现在树的同一层中)。4.数据既可能出现在分枝节点中,也可能出现在叶子节点中。
因为Quad-Trees存在诸多变种,为了有所区分,上面提到的最简单的这种Quad-Tree,被称之为Point Quad-Trees。还有一种典型的Quad-Trees,被称之为Point Region QuadTrees(简称为PR QuadTrees):
PR Quad-Trees中,每一次迭代出来的4个象限,面积相同,且不依赖于用户数据Point作为分割点,或者说,数据分区与用户数据无关 。每一个划分出来的子象限中,只允许存在一个Point。
与Point Quad-Trees相比,PR Quad-Trees允许两份不同的数据集,拥有相同的分区信息。但PR Quad-Trees存在的问题也明显:1. 两个相邻的Points,可能在树的Level高度上相隔甚远。2.两份数据集如果追求相同的分区信息,可能需要进行足够粒度的分割,这可能导致空间浪费。
K-D Trees K-D Trees是一种针对高维点向量数据的索引结构,一棵简单的K-D Tree如下图所示(原图源自James Fogarty的”K-D Trees and Quad Trees”,但为了更直观,关于分区分割线的线条做了改动):
与Quad Trees思想类似,K-D Trees也是将整个区间进行不断分割,不同之处在于,Quad Trees每一次迭代,将一个区间分割成四个象限,而K-D Trees则是分成左右或上下两个区间。如上图所示:S1把整个空间分成了左右两个区间,左侧区间中,又被S2横向分割成了上下两个区间,而S3又在S2的分割基础上,将下部分分割成了左右两个区间,….
Space Filling Curve 如果将一个完整的二维空间,分割成一个个大小相同的矩形,可以将Space Filling Curve简单理解为它是一种将所有的矩形区域用一条线”串”起来的方法,因”串”的方式不同,也就引申出了不同的Space Filling Curve算法。
比较典型的如Z-Order Curve:
再如Hilbert Curve:
GeoMesa使用了基于Z-order填充曲线的GeoHash空间索引技术, 并针对时间维度进行了扩展,具体分为: • Z2:空间,点索引 • Z3:时间+空间,点索引 • XZ2:空间,线\面索引 • XZ3:时间+空间,线\面索引。
为什么选择了RTree =>
原先的项目中选择RTree
别的项目没有RTree这么成熟的工业库
R树的操作 搜索 R树的搜索操作很简单,跟B树上的搜索十分相似。它返回的结果是所有符合查找信息的记录条目。而输入是什么?输入不仅仅是一个范围了,它更可以看成是一个空间中的矩形。也就是说,我们输入的是一个搜索矩形。
插入 R树的插入操作也同B树的插入操作类似。当新的数据记录需要被添加入叶子结点时,若叶子结点溢出,那么我们需要对叶子结点进行分裂操作。显然,叶子结点的插入操作会比搜索操作要复杂。插入操作需要一些辅助方法才能够完成。
删除 R树的删除操作与B树的删除操作会有所不同,不过同B树一样,会涉及到压缩等操作。相信读者看完以下的伪代码之后会有所体会。R树的删除同样是比较复杂的,需要用到一些辅助函数来完成整个操作。
优化
1 2 3 Rectangle r = Geometries.rectangle(1.0 , 2.0 , 3.0 , 4.0 ); Rectangle r = Geometries.rectangle(1.0f , 2.0f , 3.0f , 4.0f );
理论上这样使用RTree消耗的内存只有Double的一半。
使用R-Tree的变种 R*-Tree,对数据结构进行了优化,并且同样存在成熟的常用项目 RTee2 可以使用。
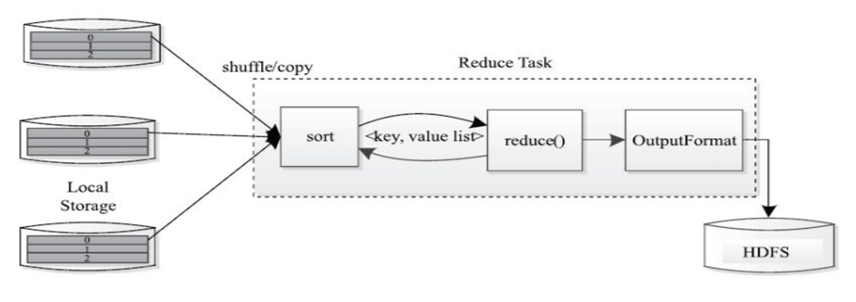
Base4BigData(Version.1) MapReduce MapReduce产生的灵感来源于2004年Google发表的《MapReduce》论文中的大数据计算模型,用于大规模数据集(TB甚至PB级)的并行计算,利用分治策略,将计算过程分两个阶段,Map阶段和Reduce阶段,可谓是第一代大数据分布式计算引擎,为后来各类优秀的大数据计算引擎的出现提供了基础和可行性。
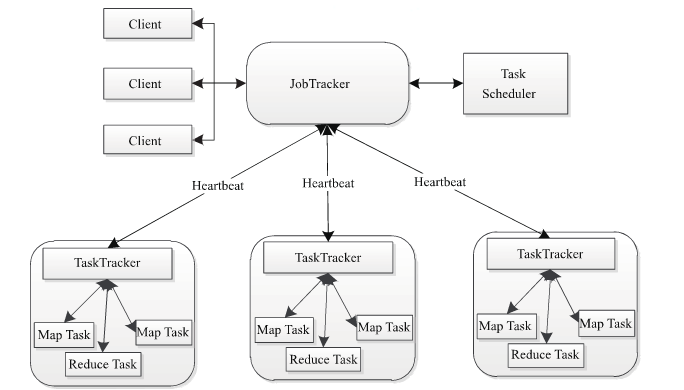
架构 MapReduce 1.x架构如下:
客户端向JobTracker提交任务
JobTraker将任务拆解为多个子任务,分配给TaskTracker执行TaskTracker定时与JobTracker保持心跳,汇报任务执行情况
存在的问题:
单点故障:一旦JobTracker出现故障,会导致任务无法提交和正常执行
JobTracker负载高:所有的任务的提交和分配以及资源管理都是由JobTracker控制,压力过于集中
场景有限制:只能运行MapReduce作业,可兼容性差
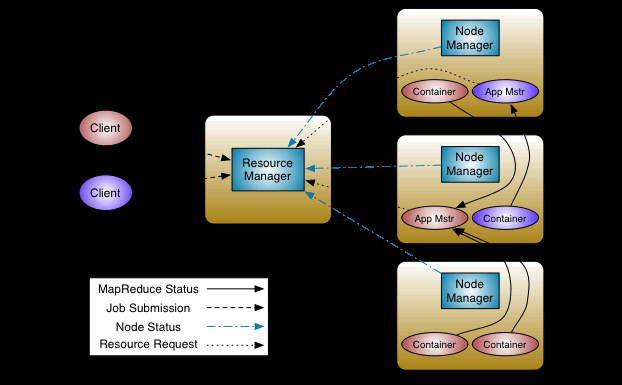
为了解决MR v1的问题,MapReduce v2引入了资源管理器YARN (Yet Another Resource Negotiator),即新一代的MapReduce 2.0。
YARN中的重要角色及功能:
ResourceManager :资源管理节点(RM),对应MR v1的JobTracker
负责处理来自客户端的提交的Job
启动Application Master管理任务
监控Application Master状态
为NodeManager分配资源(CPU、内存、磁盘、网络)
NodeManager :工作节点(NM),对应MR v1的TaskTracker
管理节点container任务资源和运行情况
与ResourceManager保持通信,汇报自身的状态
Application Master :任务管理服务(AM),其实就是ResourceManager的小弟
负责检查集群资源,申请mr程序所需资源
分配任务到相应的container容器执行
监控任务执行状态并向ResourceManager汇报任务执行情况
Container :YARN资源抽象,封装了节点上的资源,如内存、CPU、磁盘等
YARN的优势:
ResourceManager支持HA,解决了JobTracker单点故障的问题,提高集群可用性
实现资源管理和job管理分离,解决了JobTracker负载高的难题
提供Application Master负责监控所有的任务,解决了JobTracker集中管理监控的压力
高扩展性,不仅可以跑mr任务,还支持spark作业以及其他计算引擎任务
提高了资源的利用率
MapReduce核心计算阶段 Mapper阶段:负责数据 的载入、解析、转换和过滤,map任务的输出被称为中间键和中间值
Reducer阶段:负责处理map任务输出结果,对map任务处理完的结果集进行排序、局部聚合计算再汇总结果
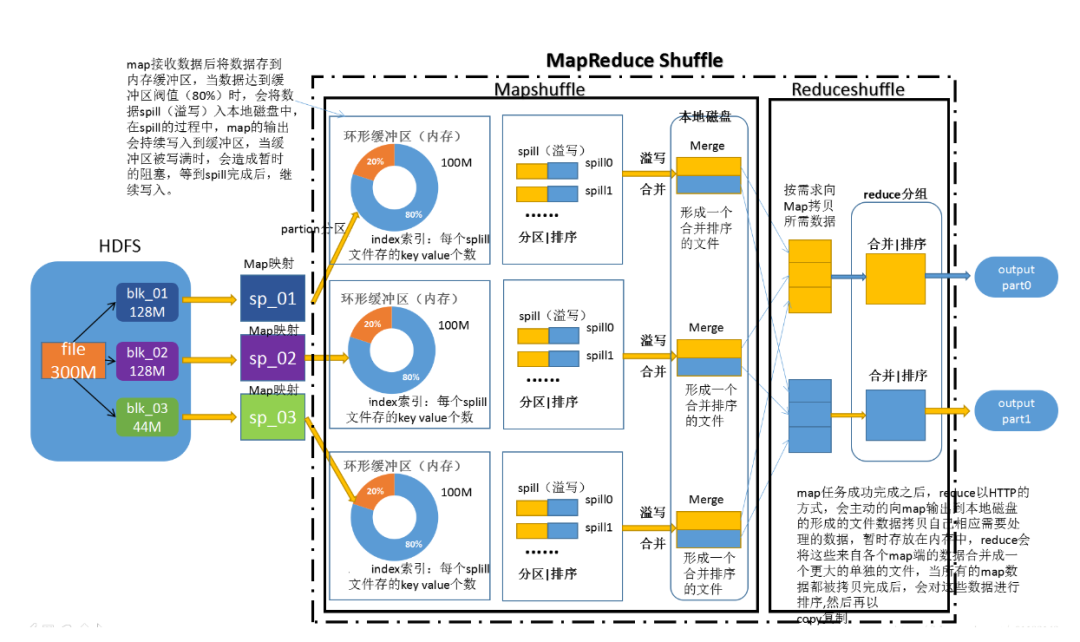
MapReduce为什么慢?
MapReduce是基于磁盘数据进行计算的
Shuffle过程进行一系列分区、排序,耗费大量时间
map计算结果频繁落盘
reduce任务通过磁盘获取数据,占用IO
spill会会产生大量的小文件,极大占用集群的资源
容错性差,错了就重头来过
MapReduce抽象层次低,只有map和reduce两种,处理数据效率较低
因此MapReduce只适用于处理大规模离线数据,延时高。MapReduce的局限性推动了计算引擎技术的革新,Spark的出现是为了解决MapReduce计算慢的问题,随着数据量的指数增长,对数据处理效率有了更高的要求,我们需要在更短的时间内得到正确的结果。
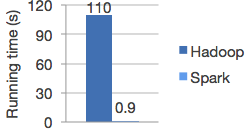
Spark Apache Spark是用于大规模数据处理的统一分析计算引擎,最初诞生于加州大学伯克利分校的AMP Lab实验室。基于内存进行并行计算,通过使用最先进的DAG调度器、查询优化器和物理执行引擎,实现了批处理和流处理的高性能,与Hadoop MapReduce相比,运行在内存中的计算速度要快上100倍(实际上或许没有快这么多),但是可见spark是要比Hadoop MapReduce计算能力更强的计算引擎。
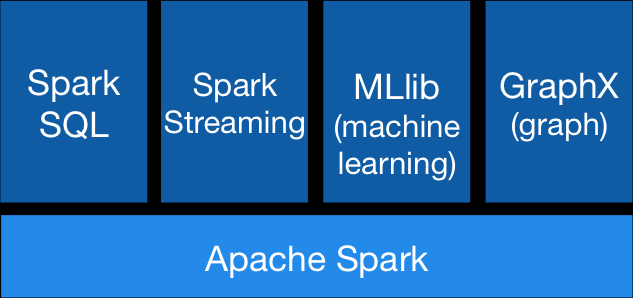
组件角色 Spark由Spark Core、Spark SQL、Spark Streaming、MLib和GraphX四大组件构成 .
角色说明:
Spark Core:spark的核心,将数据抽象为弹性分布式数据集(RDD),提供了分布式任务调度,RPC通信、序列化和压缩等特性,是内存计算的框架,用于离线计算
Spark SQL:基于Spark Core之上用于结构化数据建模和数据处理组件,实现交互式查询
Spark Streaming:利用Spark Core快速调度能力进行流式计算
MLib:是Spark上分布式机器学习框架,提供了大量的算法
GraphX:是Spark上的分布式图形处理框架,能进行高效的图计算
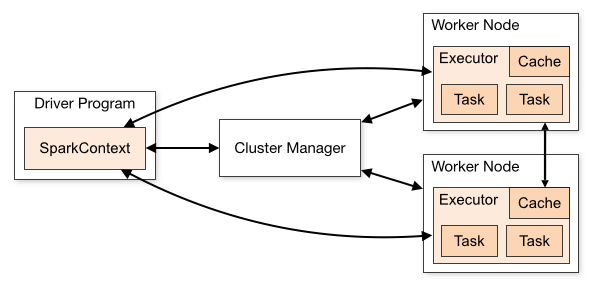
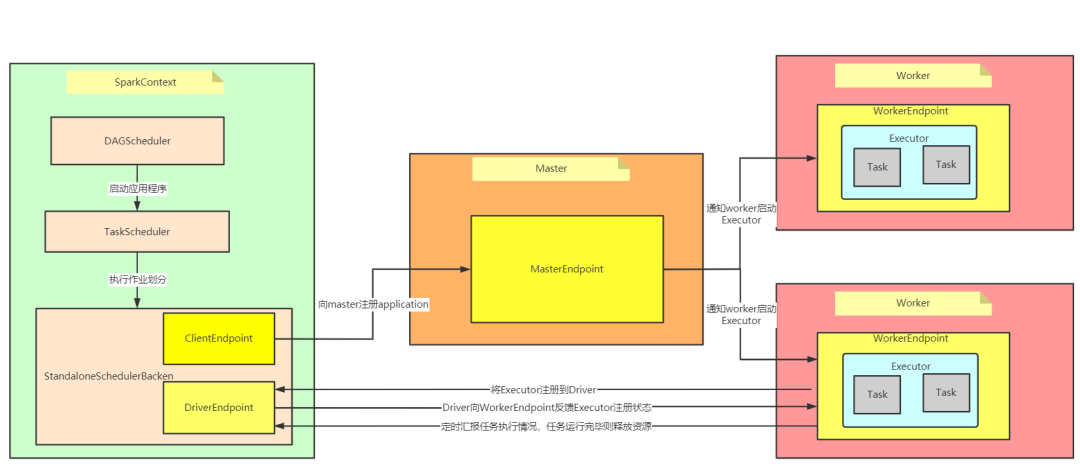
架构 Spark是一个典型的master/slave主从架构,基于内存计算引擎,提供了多种缓存机制,将RDD 缓存到内存或者磁盘中,这种机制使得Spark可以进行迭代计算和数据共享,从而减少数据读取的IO开销,架构如下:
Driver :初始化Spark运行环境,创建SparkContext上下文环境,是用户程序的入口,即main() 方法Cluster Manager :资源管理器,目前支持Standalone、YARN、Mesos和Kubernetes这几种模式,在Standalone模式中,Cluster Manager即为Master节点,控制整个集群Worker :spark计算节点,负责计算任务的管理,为task分配并启动Executor,定时向Cluster Manager汇报任务执行情况Executor :Spark Task工作的容器,是用户程序在worker节点上的一个进程,运行计算任务,负责数据的读取和写入,缓存中间数据
工作原理
Driver驱动程序会初始化SparkContext
初始化过程中会启动DAGScheduler和TaskScheduler
TaskScheduler通过后台进程向Master注册用户程序Master收到注册请求之后会通知Worker为用户程序启动多个Executor容器
Executor反向SparkContext注册
SparkContext将应用程序发给ExecutorSparkContext完成初始化,构建DAG,创建Job并且根据action操作划分Stage,形成TaskSet发送给TaskScheduler,最后发给Executor执行运行完释放资源
Spark 为什么比MapReduce快
Spark相对于MapReduce减少了磁盘IO,没有太多中间结果落盘
Spark采用了多线程模型,基于线程池复用降低task线程的开销
spark提供了多种缓存策略,避免了重复计算
灵活的内存管理策略
Spark的DAG(有向无环图)算法
提供丰富的抽象方法,MapReduce只有map和reduce两种抽象
缓存和checkpoint,通过lineage实现高度容错性
以上列举了spark比MapReduce快的部分特性,Spark的出现逐步取代了MapReduce成为新一代离线计算引擎的最佳选择,不仅如此,spark还提供了Spark Streaming组件作为流式计算引擎。
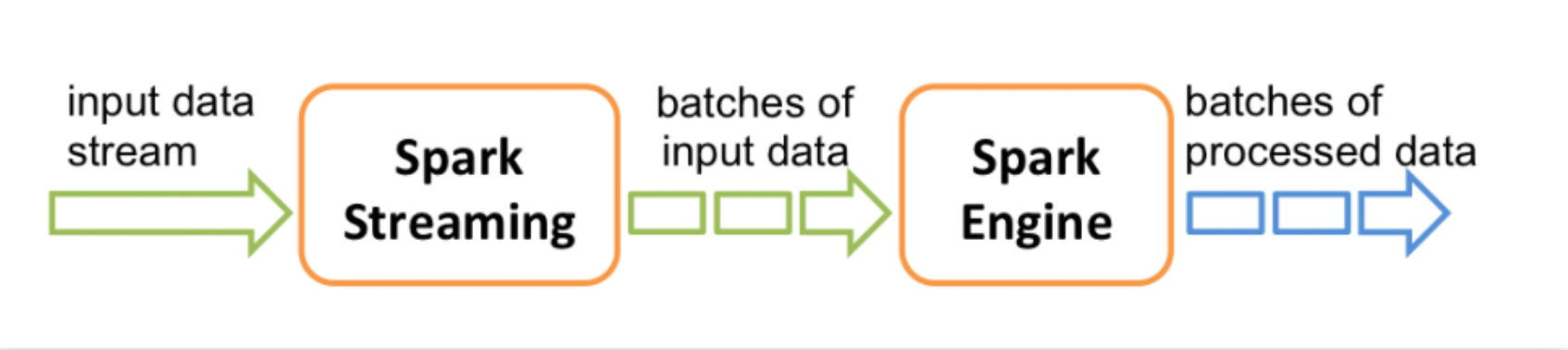
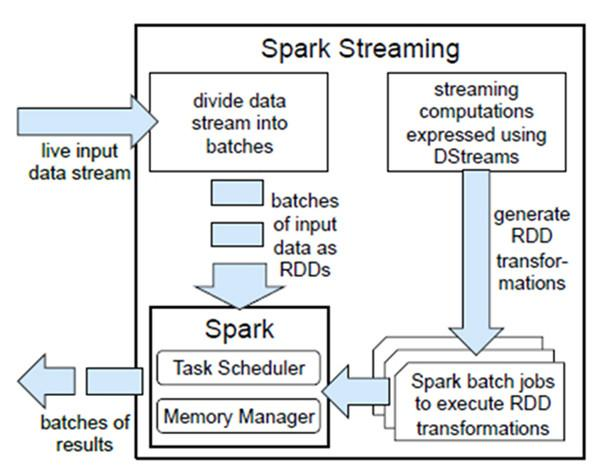
Spark Streaming Spark Streaming是Spark Core API的扩展,支持实时数据流的可伸缩、高吞吐量、容错流处理。支持多种数据源,数据可以从Kafka、Flume、HDFS、S3、Kinesis或TCP套接字等许多来源获取,并可以使用复杂的算法处理,这些算法由map、reduce、join和window等高级函数表达。最后,可以将处理过的数据推送到文件系统、数据库和实时仪表板中。
工作模型
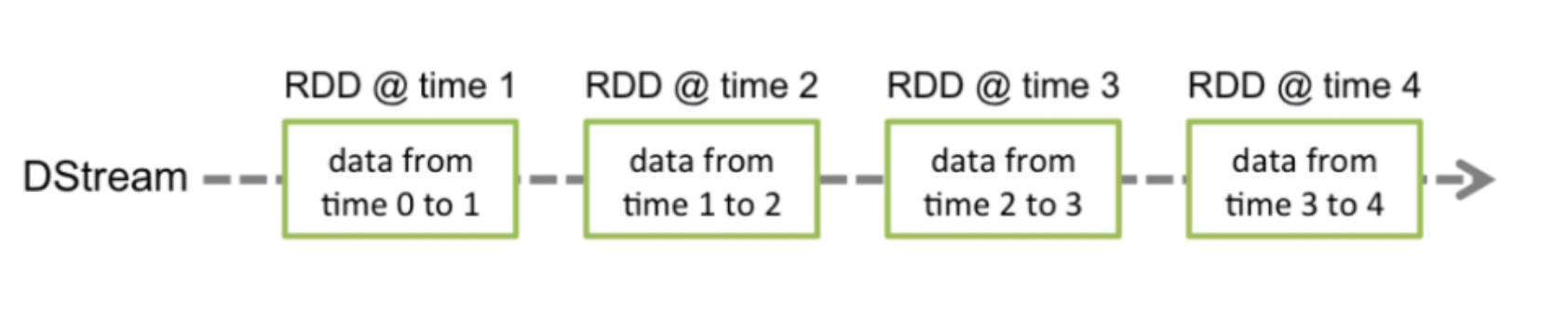
Spark Streaming基于micro batch方式的计算和处理流数据,提供了称为离散流或DStream的高级抽象,它表示连续的数据流。将接收到的数据流切分为多个独立的DStream,本质上也是一系列RDD,通过spark计算引擎进行计算。
DStreams(Discretized Streams) 离散数据流是Spark Streaming提供的基本抽象,将待处理数据转变为连续不断的数据流,可以是外部数据源转换而来,也可以通过内部流之间的转换生成,从DStream的内部流模型可以看到Dstream就是由一系列的RDD组成。
实际上,Dstream执行的操作都会转换为对底层RDD的操作。
Spark Streaming是怎么实现数据实时计算的呢?
当spark Streaming接收到数据后,会将数据流切分成多个批次,形成有界的数据集,设置时间间隔,当不同批次的数据进入窗口后会触发计算机制,通过Spark Core进行一系列tranformation和action操作,因为划分批次之后的数据比较小,实时计算得出结果。
为什么要用Spark Streaming呢? 从数据的边界来说,我们可以把数据分为有界数据和无界数据。顾名思义,有界数据是有范围的,一般来说与时间是强关联的,以历史数据最为典型。而无界数据就是难以限定范围的数据,会持续不断发生变化,最常见的场景就是实时数据流,看不到数据的尽头,一直在发生。
MapReduce和Spark SQL等框架只能进行离线计算,无法满足实时性要求高的业务场景,如购买商品后进行实时推荐、实时交易业务等等。而spark Streaming巧妙地将数据细分为多个微小的批次,依赖于spark计算引擎能做到准实时计算,不是真正意义上的实时计算,尽管如此,spark Streaming还是得到了业界的认可和广泛应用。
Spark Streaming优势:
实时性:Spark Streaming 是一个实时计算框架,微批处理数据,延迟可以控制到秒级
高容错性:Spark Streaming底层依赖RDD lineage特性、缓存机制、checkpoint机制以及WAL预写日志,可以实现高度容错
高吞吐:相对于实时计算框架Storm吞吐量更高
一体化:依托spark生态,不仅能进行实时计算,还能应用于机器学习和Spark SQL场景
对于大部分企业来说,秒级的延时是可以接受的,而且一个大数据项目通常会包含离线计算、交互式查询、数据分析、实时计算等模块,Spark Streaming毫无疑问是很好的选择。
Storm storm是一个真正的实时流计算引擎,相对于Spark Streaming的微批处理,storm则是来一条数据计算一条数据,延时可以控制到毫秒级。
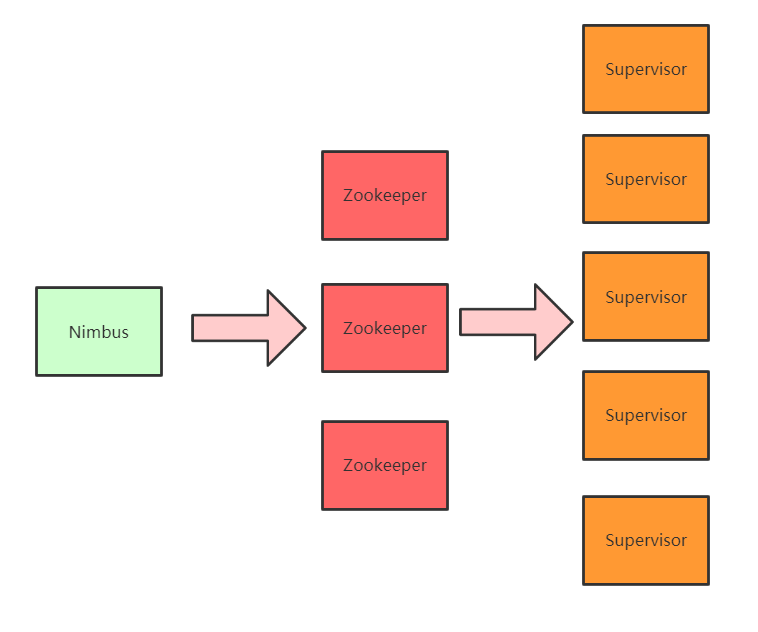
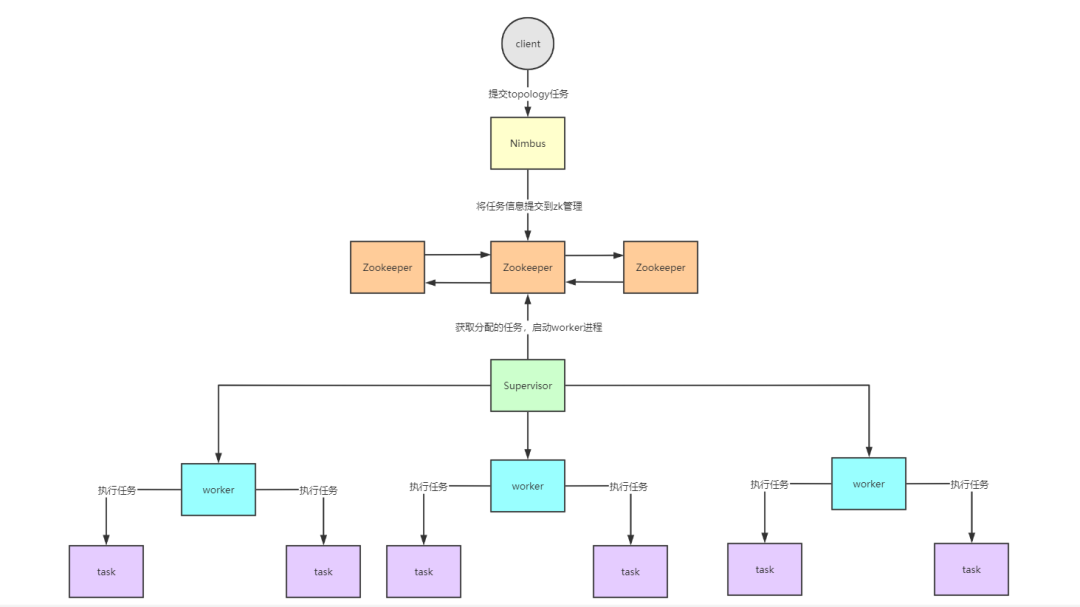
Storm架构 storm的架构与Hadoop相似,都是master/slave主从架构。
成员
Storm
Hadoop
主节点
Nimbus
JobTracker
从节点
Supervisor
TaskTracker
计算模型
Spout / Bolt
Map / Reduce
应用程序
Topology
Job
工作进程
Worker
Child
Nimbus:master节点,负责提交任务,分配到supervisor的worker上,运行Topology上的Spout/Bolt任务
Zookeeper:协调节点,负责管理storm集群的元数据信息,比如heartbeat信息、集群状态和配置信息以及Nimbus分配的任务信息等
Supervisor:slave节点,负责管理运行在supervisor节点上的worker进程
Storm工作流程
客户端提交topology任务到Nimbus节点
Nimbus主节点将任务提交到zookeeper集群管理
Supervisor节点从Zookeeper集群获取任务信息
启动worker进程开始执行任务
Storm Vs Spark Streaming 用一个生动形象的生活场景来比喻Storm和Spark Streaming,Storm好比是手扶电梯,一直在运行,来一个人都会将他带上/下楼,而Spark Streaming更像是升降电梯,要装满一批人才开始启动。
storm可以实现毫米级计算响应 VS Spark Streaming只能做到秒级响应
Storm吞吐量低 VS Spark Streaming吞吐量高
Item
Storm
Spark Streaming
Streaming Model
Native
Micro-Batch
Guarantees
At-Least-Once
Exactly-Once
Back Pressure
No
Yes
Latency
Very Low
Low
Throughput
Low
High
Fault Tolerance
Record ACKs
RDD Based CheckPoint
Stateful
No
Yes(DStream)
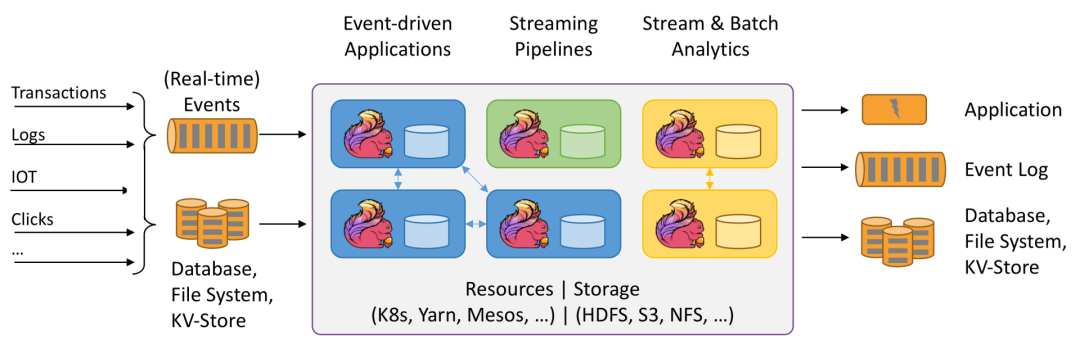
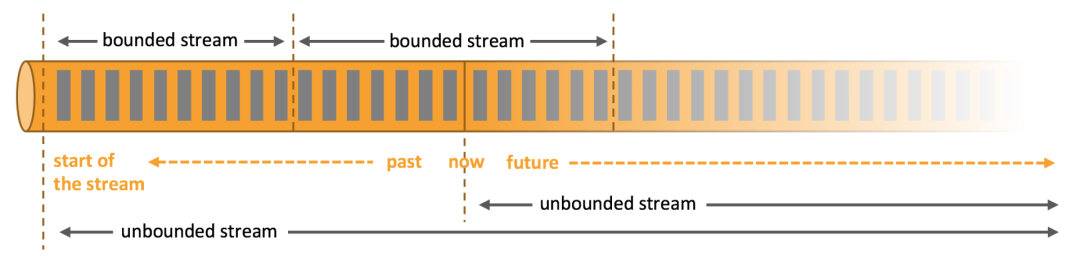
Flink Apache Flink是一个分布式处理引擎,用于在无边界和有边界 数据流上进行有状态的计算。Flink能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。现在Flink也是主流的实时流计算框架并且同时支持批处理,支持基于有状态的事件时间进行计算,成为大数据计算引擎的领头羊,大有盖过Spark风头之势。
擅长处理有界(bounded)数据和无界(unbounded)数据,有界数据通常指的是离线历史数据,用于批处理,而无界数据指数据流有定义数据产生的开始,却无法定义数据何时结束,因此无界数据流通常说的就是实时流,用于实时计算。
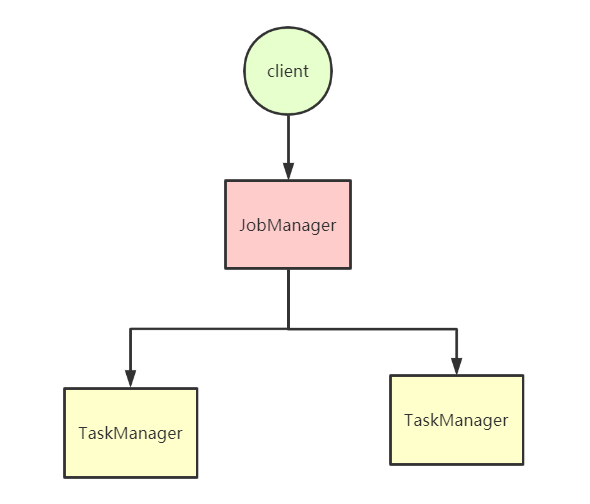
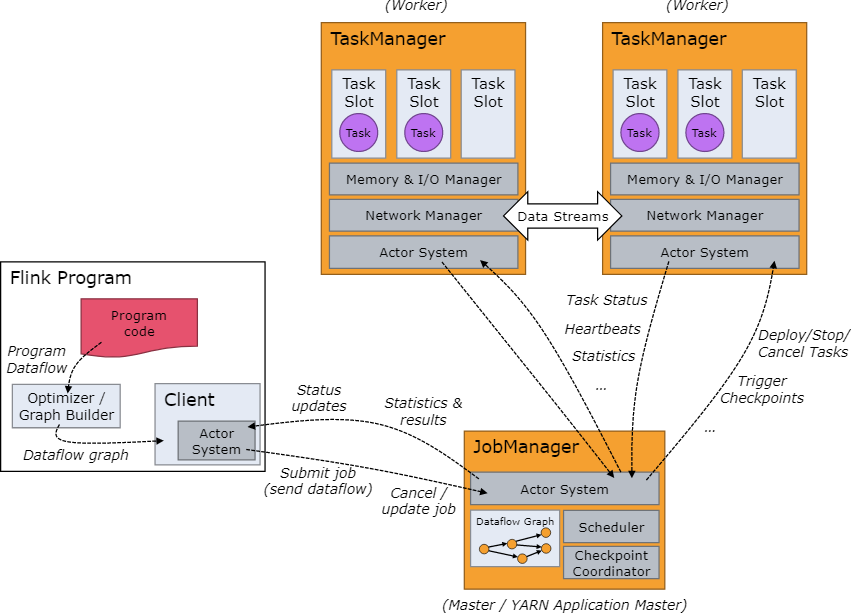
架构 Flink和Spark一样,也是主从架构,由JobManager和TaskManager组成
JobManager:主节点,负责处理客户端提交的Job,管理Job状态信息,调度分配集群任务,对完成的 Task 或执行失败做出反应、协调 checkpoint、并且协调从失败中恢复
TaskManager:从节点,负责管理节点上的资源,向JobManager汇报集群状态,执行计算JobManager分配的Task
Flink工作调度
用户提交Flink程序时,client会对程序进行预处理,构建Dataflow graph,封装成Job提交到JobManager
JobManager接收到client提交的Job,获取并管理Job的基本信息,构建DAG执行计划,通过Scheduler调度任务并分配到对应的TaskManager节点
TaskManager向JobManager注册,JobManager将Job分配到TaskManager执行,每个Task Slot代表着用来执行Task的资源,包括了内存、cpu等
TaskManager与JobManager保持心跳,定时汇报节点资源情况以及任务执行情况
JobManager将将任务执行的状态和结果反馈给客户端
Flink的优势
Flink支持实时计算,且基于内存管理,性能优越
具有高吞吐、低延迟、高性能的流处理特性
Flink与Hadoop生态高度融合
高度灵活的时间窗口语义
流批一体化,同时支持批处理和流计算
高容错,基于分布式快照(snapshot)和checkpoint检查点机制
具有反压(Backpressure)功能
支持有状态计算的Exactly-once语义
可以进行机器学习处理(FlinkML)、图分析(Gelly)、关系数据处理(FLink SQL)以及复杂事件处理(CEP)
Flink VS Storm VS Spark Streaming
Item
Flink
Storm
Spark Streaming
Streaming Model
Native
Native
Micro-Batch
Guarantees
Exactly-Once
At-Least-Once
Exactly-Once
Back Pressure
Yes
No
Yes
Latency
Medium
Very Low
Low
Throughput
High
Low
High
Fault Tolerance
Checkouting
Record ACKs
RDD Based CheckPoint
Stateful
Yes(Operators)
No
Yes(DStream)
VSCODE 插件搜索 @installed 可以查到已经安装的插件
自动格式化代码:Shift + Alt + F
特别有用的正则:
1.删除A之后的所有字符用:A.*$
2.删除A之前的所有字符用:^([^s]*)A
####如果是其他字符就把A替换为其他字符
注释:如何是特殊字符注意转义
Anaconda Navigator & Pyhton & 脚本语言 & Others Anaconda Navigator 介绍 / 背景 conda anaconda anaconda-navigator pip virtualenv区别
Anaconda是一个包含180+的科学包及其依赖项的发行版本。其包含的科学包包括:conda, numpy, scipy, ipython notebook等。
conda是包及其依赖项和环境的管理工具。
pip是用于安装和管理软件包的包管理器。
virtualenv:用于创建一个独立的 Python环境的工具。
“Anaconda-Navigator”中已经包含“Jupyter Notebook”、“Jupyterlab”、“Qtconsole”和“Spyder”。
conda基础操作 1 2 3 4 5 6 7 8 9 创建环境 conda create -n envname python=xxx 删除环境 conda remove -n envname --all 进入环境 conda activate envname (old version: source activate xxx) 离开环境 conda deactivate (old version: source deactivate) 列出所有环境 conda info -e #这里列出环境的同时会列出该环境的绝对路径
conda参数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 conda install -y 覆盖提示,默认yes The following NEW packages will be INSTALLED: libgfortran: 1.0-0 numpy: 1.10.2-py27_0 openblas: 0.2.14-3 pandas: 0.17.1-np110py27_0 python-dateutil: 2.4.2-py27_0 pytz: 2015.7-py27_0 six: 1.10.0-py27_0 Proceed ([y]/n)? y 等于提前输入了这个y ------------------- conda install -c 这个c的意思是channel,也就是指定了下载通道,在出现某些网络问题的情况下可以换一个下载源就这个意思 -------------------
conda install 和 pip install 的区别 1 2 3 pip只能安装python包,而conda可以安装由任何语言编写的包 pip不能创建虚拟环境,需要借助另外的包,例如virtualenv,而conda可以创建虚拟环境。 pip是按照python时自带的,而conda需要安装anaconda才能用。
具体区别可以在找个官网上找到 https://www.anaconda.com/blog/understanding-conda-and-pip
conda更新 很多时候打不开可能也是因为要更新了
管理员运行 conda promptconda update anaconda-navigator
第三步 anaconda-navigator --reset
第四步 conda update anaconda-client
第五步 conda update -f anaconda-client
Jupyter Book 使用技巧 端口
1 默认8888 值得一提的是如果同时开启jupyter book和jupyterlab需要小心端口冲突
快捷键
1 快捷键这里不过多介绍,因为我本身就是远程到windows机器上 `等待补充`
显示多行输出
1 Jupyter Book默认只显示一行输出,要想显示多行输出,需要添加如下代码
1 2 from IPython.core.interactiveshell import InteractiveShellInteractiveShell.ast_node_interactivity = 'all'
简易命令
1 2 不必离开Jupyter笔记本来执行Shell命令,而是可以在命令开头使用感叹号(!)。例如,您可以安装软件包。 !pip install matplotlib
大量魔术命令
1 2 魔术命令(magic commands)是有助于提高生产率的特殊命令。您可能最熟悉下面的魔术命令,该命令让Notebook渲染Python Matplotlib创建的图表。 %matplotlib inline
1 2 3 4 5 6 7 %pwd #打印当前工作目录 %cd #更改工作目录 %ls #显示当前目录中的内容 %load [在此处插入Python文件名] #将代码加载到Jupyter Notebook %store [在此处插入变量] #这使您可以传递Jupyter Notebooks之间的变量 %who #使用它列出所有变量 %lsmagic # 查看完整的魔术命令列表
记录单元格运行时间
显示函数文档
shift + tab
1 2 3 # 在Jupyter Book里面查看这个Book后面的Python版本的命令 import sys sys.version
Python python基础 1 2 print("Hello, Jupyter Book" )
1 2 3 import keywordprint(keyword.kwlist)
[‘False’, ‘None’, ‘True’, ‘and’, ‘as’, ‘assert’, ‘async’, ‘await’, ‘break’, ‘class’, ‘continue’, ‘def’, ‘del’, ‘elif’, ‘else’, ‘except’, ‘finally’, ‘for’, ‘from’, ‘global’, ‘if’, ‘import’, ‘in’, ‘is’, ‘lambda’, ‘nonlocal’, ‘not’, ‘or’, ‘pass’, ‘raise’, ‘return’, ‘try’, ‘while’, ‘with’, ‘yield’]
1 2 3 4 5 6 7 8 1.01 ** 365 print('-------' * 10 ) 10 / 20 9 // 2
37.78343433288728
----------------------------------------------------------------------
0.5
1 2 3 4 """ 多行注释 """ print("多行注释" )
'\n多行注释\n'
多行注释
1 2 3 4 5 account = 1101 print(type(account))
<class 'int'>
1 2 3 inputStr = input("记录输入" )
记录输入 (内容 )
int
1 2 3 4 5 6 7 8 9 10 11 12 13 14 name = "demo" print("我的名字叫 %s" % name) num = 1 print("学号是 %09d" % num) price = 8.5 weight = 7.5 money = price * weight print("苹果单价 %.2f元/斤 ,购买了 %.3f斤,需要支付%.4f元" % (price,weight,money)) scale = 0.8 print("数据比例是 %.2f%%" % (scale * 100 ))
我的名字叫 demo
1 2 3 import randomrandom.randint(10 ,20 )
16
1 2 3 4 5 6 7 8 9 10 11 row = 1 while row <= 5 : print("*" * row) row += 1 print()
1 2 3 4 5 6 7 8 9 row = 1 while row <= 9 : col = 1 while col <= row: print("%d * %d = %d" % (col, row, col * row ), end = "\t" ) col += 1 row += 1 print("" )
1 * 1 = 1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def multiple_table () : row = 1 while row <= 9 : col = 1 while col <= row: print("%d * %d = %d" % (col, row, col * row ), end = "\t" ) col += 1 row += 1 print("" ) multiple_table()
1 * 1 = 1
1 2 3 4 5 6 def sum_2_num (num1,num2) : result = num1 + num2 print("%d + %d = %d" % (num1,num2,result)) sum_2_num(50 ,20 )
50 + 20 = 70
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 lname_list = []
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 info_tuple = ("zhangsan" ,18 ) single_tuple = (5 ) type(single_tuple) single_tuple = (5 ,) type(single_tuple)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 xiaoming = { "name" : "小明" , "age" : 18 , "gender" : True , "height" : 1.75 , "weight" : 75.6 , } print(xiaoming) print(xiaoming["name" ]) xiaoming["age" ] = 10 xiaoming.pop("age" ) zidian = {"key" : "value" } zidian.update(xiaoming) print(zidian) zidian.clear() print(zidian) for k in xiaoming: print("%s - %s" % (k, xiaoming[k]))
{‘name’: ‘小明’, ‘age’: 18, ‘gender’: True, ‘height’: 1.75, ‘weight’: 75.6}
10
{‘key’: ‘value’, ‘name’: ‘小明’, ‘gender’: True, ‘height’: 1.75, ‘weight’: 75.6}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 str1 = "hello python" print(str1[0 ]) for k in str1: print(k) print(len(str1)) print(str1.count("o" )) print(str1.index("o" ))
h
p
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 num_str = "0123456789" num_str[2 :6 ] num_str[2 :] num_str[:6 ] num_str[:] num_str[::2 ] num_str[1 ::2 ] num_str[2 :-1 ] num_str[-1 ::-1 ] num_str[::-1 ]
1 2 3 4 5 6 7 8 a = 6 b = 100 a,b = (b,a) print(a) print(b)
1 2 3 4 5 6 7 8 9 10 11 12 num_list = [7 , 5 , 4 , 9 ] num_list.sort() print(num_list) num_list.sort(reverse=True ) print(num_list)
case:
1 2 3 4 5 6 7 def demo (num, *nums, **numss) : print(num) print(nums) print(numss)
1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 run(1 ,2 ,3 ) def run (a,*args) : print(a) print(args) print("对args拆包" ) print(*args) print("将未拆包的数据传给run1" ) run1(args) print("将拆包后的数据传给run1" ) run1(*args) def run1 (*args) : print("输出元组" ) print(args) print("对元组进行拆包" ) print(*args)
1 2 3 4 5 6 7 8 9 10 11 12 def run (**kwargs) : print(kwargs) print("对kwargs拆包" ) run1(**kwargs) def run1 (a,b) : print(a,b) run(a=1 ,b=2 )
{‘a’: 1, ‘b’: 2}
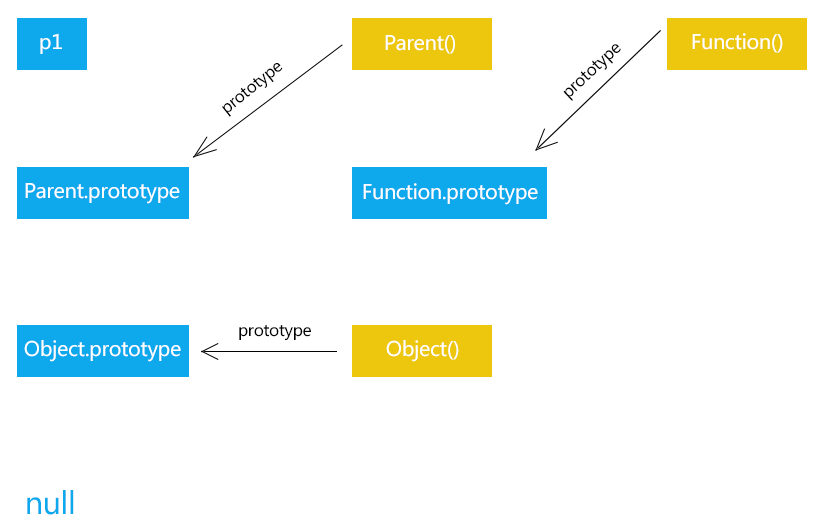
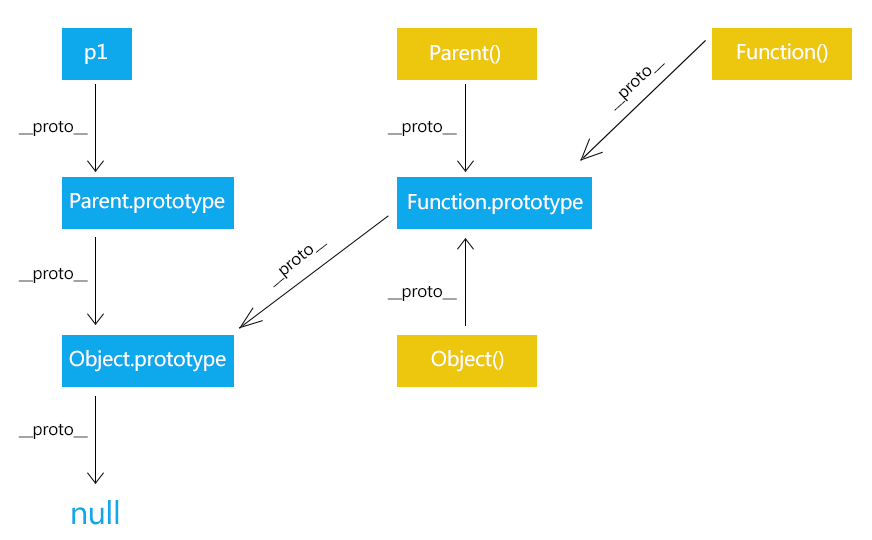
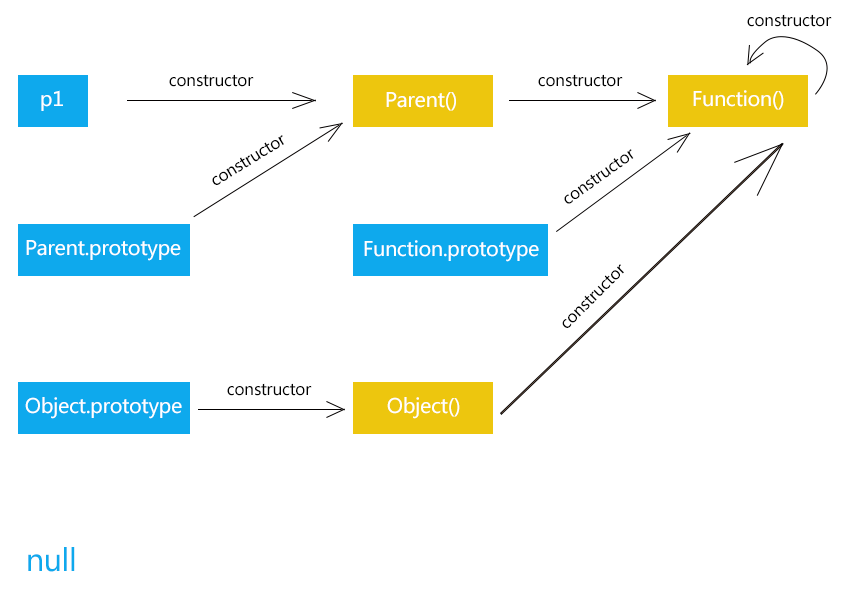
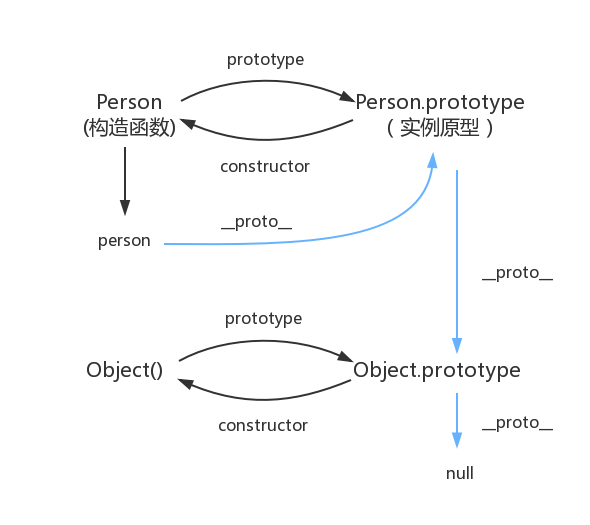
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 """ __init__方法是专门用来定义一个类具有哪些属性的 """ class Cat : def __init__ (self, new_name) : print("初始化" ) self.name = new_name def eat (self) : print("%s 爱吃鱼" % self.name) def __del__ (self) : print("%s 我去了" % self.name) def __str__ (self) : return "我是小猫 %s" % self.name tom = Cat("TomDemo" ) print(tom.name) tom.eat() print(tom) """ 身份运算符 is is是判断两个标示符是不是引用同一个对象 is not is not 是判断两个表示服是不是引用不用对象 is 与 == 的区别 is用于判断两个变量引用对象是否为同一个 ==用于判断引用变量的值是否相等 """
初始化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 class Animal : def eat (self) : print("吃" ) def drink (self) : print("喝" ) def run (self) : print("跑" ) def sleep (self) : print("睡" ) wangcai = Animal() wangcai.eat() wangcai.drink() wangcai.run() wangcai.sleep() class Dog (Animal) : def bark (self) : print("汪汪叫" ) wangwang = Dog() wangwang.eat() wangwang.drink() wangwang.run() wangwang.sleep() wangwang.bark() class XiaoTianQuan (Dog) : def fly (self) : print("我会飞" ) def bark (self) : print("我是啸天犬" ) super().bark() """ Dog.bark(self) """ print("aafsdwaerwgybds" ) xtq = XiaoTianQuan() xtq.bark()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class A : def __init__ (self) : self.num1 = 100 self.__num2 = 200 def __test (self) : print("私有方法 %d %d" % (self.num1, self.__num2)) class B (A) : def demo (self) : print("访问父类的私有属性 %d" % self.__num2) b = B() print(b) """ 在外界不能直接访问对象的私有属性,调用方法 print(b.__num2) b.__test() """ print(b.num1) b.demo()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 class C : def test (self) : print("test 方法" ) class D : def demo (self) : print("demo 方法" ) class E (C, D) : pass e = E() e.test() e.demo() """ python中多继承两个父类出现相同的方法 属性名的时候 使用MRO选择执行顺序的 """ print(E.__mro__) """ 新式类 以Object为基类的对象 旧式类 不以Object为基类的对象 两者在多继承时 会影响到方法的搜索顺序 """
test 方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Woman : def __init__ (self, name) : self.name = name self.__age = 18 def secret (self) : print("%s 的年龄是 %d" % (self.name, self.__age)) xiaofang = Woman("小芳" ) print(xiaofang.__age) print(xiaofang._Woman__age) xiaofang.secret()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 """ __init__ 为对象初始化 实例方法(self) 类对象 模版 只有一个 实例对象 可以有很多个 """ class Tool (object) : count = 0 def __init__ (self, name) : self.name = name Tool.count += 1 @classmethod def show_tool_count (cls) : print("工具对象的数量 %d" % cls.count) tool1 = Tool("斧头" ) tool2 = Tool("榔头" ) Tool.show_tool_count()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 """ python 中的self和cls一句话描述:self是类(Class)实例化对象,cls就是类(或子类)本身,取决于调用的是那个类。 __new__ 为对象分配空间 返回对象的引用 python获得了对象的引用后,将引用作为第一个参数,传递给__init__方法 重写__new__方法的代码非常固定 如下 """ class MusicPlayer (object) : def __new__ (cls, *args, **kwargs) : print("创建对象,分配空间" ) instance = super().__new__(cls) return instance def __init__ (self) : print("播放器初始化" ) player = MusicPlayer() print(player) """ 单例:让类创建的对象,在系统中只哦与唯一的一个实例 """ print("--------完整单例-------" ) class SingleMusicPlayer (object) : instance = None init_flag = False def __new__ (cls, *args, **kwargs) : if cls.instance is None : cls.instance = super().__new__(cls) return cls.instance def __init__ (self) : if SingleMusicPlayer.init_flag: return print("初始化播放器" ) SingleMusicPlayer.init_flag = True player1 = SingleMusicPlayer() print(player1) player2 = SingleMusicPlayer() print(player2)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 """ try: 尝试执行的代码 except: 出现错误的处理 """ try : num = int(input("请输入一个整数:" )) result = 8 / num print(result) except ZeroDivisionError: print("请输入正确的整数" ) except ValueError: print("请输入正确的整数" ) except Exception as result: print("未知错误 %s" % result) else : print("尝试成功" ) finally : print("总是会执行" ) print("-" * 50 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 """ 异常的传递 python 会把异常一直向上传递 """ def demo1 () : return int(input("输入整数:" )) def demo2 () : return demo1() print(demo2()) ''' ValueError Traceback (most recent call last) Input In [2], in <cell line: 47>() 43 def demo2(): 44 return demo1() ---> 47 print(demo2()) Input In [2], in demo2() 43 def demo2(): ---> 44 return demo1() Input In [2], in demo1() 39 def demo1(): ---> 40 return int(input("输入整数:")) ValueError: invalid literal for int() with base 10: 'dsf' '''
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 """ from package import sth from package import * """ """ __name__的用法 如果需要测试模块 就增加一个条件判断 这样增加了判断之后,在作为被包倒入的时候 下面的代码不会执行 """ """ 模版 # 导入模块 # 定义全局变量 # 定义类 # 定义函数 def main(): # ... pass # 根据__name__判断是否执行下方代码 if __name__ == "__main__" main() """
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 """ 包是一个包含多个模块的特殊目录 目录下有一个特殊的文件 __init__.py 包名的命名方式和变量名一直,小写字母+_ 好处 使用import 包名 可以一次性倒入包中所有的模块 在__init__.py文件中用 from . import 模块名 制定外部文件需要倒入的模块 """
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 """ 发布模块 三步 1. 创建setup.py """ """ 发布 固定模版: from distutils.core import setup # 多值的字典参数,setup是一个函数 setup(name="Hello", # 包名 version="1.0", # 版本 description="a simple example", # 描述信息 long_description="简单的模块发布例子", # 完整描述信息 author="FlyHugh", # 作者 author_email="flyhobo@live.com", # 作者邮箱 url="flymetothemars.github.io", # 主页 py_modules=["hello.request", "hello.response"]) # 记录包中包中包含的所有模块 """ """ 第二步 构建 python3 setup.py build """ """ 第三步 python3 setup.py sdist """ """ 安装 tar zxvf 解压 sudo python3 setup.py install 然后打开python3运行即可 """
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 """ python操作文件 open 打开文件 返回文件对象 read 文件内容读取到内存 write 将内容写入文件 close 关闭文件 文件指针 open()方法有两个参数 第二个参数制定的是打开的方式 存在r w a r+ w+ a+这些方式 用str格式传入 readline 按行读取 """ """ 小文件复制 file_read = open("README") file_write = open("README[复件]","w") text = file_read.read() file_write.write(text) file_read.close() file_write.close() 复制大文件 用readline """ """ 倒入 import os rename 重命名 remove 删除 listdir 目录列表 mkdir 创建目录 rmdir 删除目录 getcwd 获取当前目录 chdir 修改工作目录 path.isdir 判断是否是文件 """ """ python2.x 默认ASCII编码 python2 使用 # *-* coding:utf-8 *-* 来指定编码格式 python3.x 默认使用UTF-8 """
python包 众所周知,pyhton之所以能够流行火爆起来,他的各种开箱即用的工具包是一个很大的原因,我这里会把我能接触到的各种工具包陆陆续续的填上来。
pdf2pptx
用来把pdf转换成pptx的一个工具,会把每次做成一个单独的pptx,我唯一注意到的一个问题是,低一点的python版本可能不支持(大概3.6)3.8是随便能够安装使用的。
使用的时候命令也很简单pdf2pptx demo.pdf即可,文件最后会存放在同目录中。
Python随机随到的一些问题,那你妈逼随机就这么容易随到的啊 anaconda代理问题 设置代理的方法:找到位置在path-for-install目录下.condarc文件,添加Http和Https的代理,这里默认本地cfw
1 2 3 proxy_servers: http: http://127.0.0.1:7890 https: http://127.0.0.1:7890
如果有密码的话
1 2 3 proxy_servers: http: http://user:password@xxxx:8080 https: https://user:password@xxxx:8080
1 anaconda 并不能被Clash4Windows在Tun模式下代理,虽然不知道原因(后续知道了会在这补上),anaconda只能在配置了proxy之后才能被代理流量
python和Clash4windows的冲突问题 现象: 和pip有关的几乎一切指令都会报错
1 2 3 4 WARNING: Retrying (Retry(total=4, connect=None, read=None, redirect=None, status=None)) after connection broken by 'ProxyError('Cannot connect to proxy.', OSError(0, 'Error'))': /simple /gitpython/ WARNING: Retrying (Retry(total=3, connect=None, read=None, redirect=None, status=None)) after connection broken by 'ProxyError('Cannot connect to proxy.', OSError(0, 'Error'))': /simple /gitpython/
ts:
遇到这种问题那肯定是直接debug走起,首先用文本搜索到抛这个错的函数,然后在嫌疑语句上都打上断,我们就能找到罪魁祸首:
同时发现windwos中原生的python环境并没有这个问题,于是和venv外没问题的老版pip一比较,很容易就能发现不对劲:选中的那两行在老版是不存在的
有了这个额外信息,我们很容易就能找到这个 Support for web proxies is broken in pip 20.3 · Issue #9190 · pypa/pip (github.com) 来说明问题,2016年底,curl加入了这个把https协议前缀另加解释与定义的联盟:HTTPS proxy with curl | daniel.haxx.se ,而urllib3显然也跟上了这个脚步:
因为前缀设置了 tls_in_tls_required 之后,urllib3会企图把这个代理服务器看作一个套了tls的http CONNECT代理。https:// 前缀的代理服务器,这个行为是什么神奇的情况呢?
确实,env里面没有proxy,那按照windows的习俗找找注册表也情有可原对吧?
看红框的行为是不是好像很眼熟?IE的代理设置似乎就是这样的?
不,并不是一样的,因为IE的代理设置把HTTPS(在zh-MS方言里叫安全)代理定义为支持 CONNECT 动词的HTTP代理,尽管很久以来人们都是这样用的,但是当它前面出现一个协议前缀的时候就不一样了。
因为clash for windows打开系统代理的代理配置看起来并没有写明了protocol:
所以首先,我们的py会根据IE时代的约定俗成把这样一个没有指明protocol的proxy url自动补全三种协议 ,然后再按照约定俗成的行为为https请求使用https_proxy ,最后在一个http代理上试图开tls 。
这个配置在IE时代行为会是正常的,在现代的库中行为也是正常的,但是对于这样一个混杂了两种行为的库,模糊不清就成了问题。
似乎此问题在新版Python中的报错信息会变成 There was a problem confirming the ssl certificate: HTTPSConnection
Pool(host='pypi.org', port=443): Max retries exceeded with url: /simple/plotly/ (Caused by SSLError(SSLEOFError(8, 'EOF
occurred in violation of protocol (_ssl.c:1123)'))) 或者类似的错误。
在后续的版本更新中,CFW解决了Specify Protocol解决了部分此问题,但是解决的并不是很好,启用Specify Protocol会导致只设置http代理,https无代理。
可以看到如果只是单纯地把注册表项的内容由 127.0.0.1:7890改为http://127.0.0.1:7890的话,urllib只会返回一个只有一个key也就是http的代理dict。requests/utils.py的select_proxy函数:
因为红框中的部分的限制,当你请求https://pypi.org的时候,只有key为https/https://pypi.org/all/all://pypi.org的代理会被使用,上面那个http的代理自然也就不会被使用。
同时,因为urllib中还存在代理的类型推测代码,所以正确的设置应该是:http=http://127.0.0.1:7890;https=http://127.0.0.1:7891
python和解释性语言 https://blog.csdn.net/balabalamerobert/article/details/1649490
JavaScript 基础 诞生时间:javascript 诞生于 1995年
诞生目的:处理服务器端语言负责的一些输入验证操作
javascript组成部分:ECMAScript(核心) DOM (文档对象模型) BOM(浏览器对象模型)
简介 & 基本概念 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 <script>元素 属性(参数): async:可选。表示应该立即下载脚本,但不妨碍页面中的其他操作。只对外部文件有效 charset:可选。通过src属性指定代码的字符集。大部分浏览器都会忽略他的值,很少有人用 defer:可选。表示脚本可以延迟到文档完全被解析和显示之后再执行。只对外部脚本有效 language:已废弃。原来用于表示编写代码的脚本语言 src:可选。表示包含要执行的外部文件 type:可选。可以看成是language的替代属性 虽然text/javascript 和 text/ecmascript都不 推荐使用,但大部分开发者依然使用。默认值为text/javascript 注意事项 在使用<script>嵌入javascript代码时,不要在代码中任何地方出现</script>字符串 如果要使用要通过转义字符"/" 可以解决 <noscript>元素 触发条件 浏览器不支持脚本 浏览器支持脚本,但脚本被禁用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 语法 ECMAScript的语法大量借鉴了C及其他类C语言的语法 严格区分大小写 标识符 第一个字符必须是一个字母、下划线或一个美元符号 其他字符可以是字母、下划线、美元符号或数字 数据类型 undefined 只有一个值就是undefined。在使用变量但未对其加以初始化时, 这个变量的值就是undefined null 从逻辑角度来看,null值表示一个空对象指针,这也是typeof操作符 检测null时会返回Object的原因,如果定义的变量将用于保存对象,那么最好 将该变量初始化为null而不是其他值 boolean number string object
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 var arr = ['1' , '2' , '3' ]var obj = { a: 'bbb' } var func = function (} console .log(typeof undefined ) console .log(typeof null ) console .log(typeof true ) console .log(typeof 0 ) console .log(typeof 'aaa' ) console .log(typeof arr) console .log(typeof obj) console .log(typeof func) console .log('____________________________' )function type (any ) return Object .prototype.toString.call(any).slice(8 , -1 ).toLocaleLowerCase() } console .log(type(undefined )) console .log(type(null )) console .log(type(true )) console .log(type(0 )) console .log(type('aaa' )) console .log(type(arr)) console .log(type(obj)) console .log(type(func))
1 2 3 4 5 6 7 8 9 10 11 12 13 /* * object的通用属性和方法 * construct:保存着用于创建当前对象的函数 * hasOwnProperty(propertyName):用于检查给定属性在当前对象实例中(而不是 * 在实例的原型中)是否存在。其中作为参数的属性名(propertyName)必须以字 * 符串形式指定 * isPrototypeOf(object):用于检查传入的对象是否是传入对象的原型 * propertyIsEnumerable(propertyName):用于检查给定的属性是否能够使用for-in * 语句来枚举 * toLocaleString(): 返回对象字符串表示,改字符串与执行环境的地区对应 * toString() 返回对象字符串表示 * valueOf():返回对象字符串、数值或布尔表示。通常与toString()方法的返回值相同 * */
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 function addTen (num ) num += 10 ; return num } var count = 20 ;var result = addTen(count);console .log(count, result)function setName (obj ) obj.name = 'testName' } var person = {}setName(person) console .log(person.name) function setName2 (obj ) obj.name = 'testName' obj = {} obj.name = 'changeName' } var person2 = {}setName2(person2) console .log(person2.name)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 var s = "Nicholas" ;var b = true ;var i = 22 ;var u;var a = ['a' ]var n = null ;var o = {};console .log(typeof s); console .log(typeof i); console .log(typeof b); console .log(typeof u); console .log(typeof a); console .log(typeof n); console .log(typeof o); console .log(a instanceof Array ) console .log(a instanceof Object )
变量 & 作用 & 内存问题 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 if (true ) { var color = 'blue' ; } console .log(color) if (true ) { let color2 = 'blue' } for (var i = 0 ; i < 10 ; i++) { console .log('for var' ) } console .log(i) for (let j = 0 ; i < 10 ; j++) { console .log('for let' ) }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 var color3 = 'blue' function getColor ( return color3 } console .log(getColor()) var color4 = 'blue' function getColor2 ( var color4 = 'red' return color4 } console .log(getColor2())
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 var person = new Object ()person.name = 'tom' person.age = 29 var person2 = { name: 'tom' , age: 29 } console .log(person2['name' ])console .log(person2.name)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 var color = new Array (3 )var color2 = ['red' , 'blue' , 'green' ]console .log(color instanceof Array ) console .log(Array .isArray(color)) console .log(color2.toString()) console .log(color2.toLocaleString()) console .log(color2.valueOf()) console .log(color2) var person3 = { toLocaleString: function ( return 'toLocaleString3' }, toString: function ( return 'toString3' } } var person4 = { toLocaleString: function ( return 'toLocaleString4' }, toString: function ( return 'toString4' } } var person5 = [person3, person4]console .log(person5)console .log(person5.toString()) console .log(person5.toLocaleString())
toString和toLocalString还有另外一个valueOf的区别有点细,详细参考这个网页
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 var colors = []var count = colors.push('red' , 'green' )console .log(count) count = colors.push('black' ) var item = colors.pop()console .log(item) console .log(colors.length) var colors2 = []var count2 = colors2.push('red' , 'green' )console .log(count2) count2 = colors2.push('black' ) console .log(count2) var item2 = colors.shift()console .log(item2) var values = [1 , 2 , 3 , 4 , 5 ]console .log(values.reverse()) var values2 = [2 , 1 , 6 , 4 , 3 , 5 ]console .log(values2.sort(function (x, y ) return x - y })) var values3 = [1 , 2 , 3 , 4 ]var sum = values3.reduce(function (prev, cur ) return prev + cur }) console .log(sum)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 var date1 = new Date (2018 , 6 , 9 )var date2 = new Date (2018 , 6 , 10 )console .log(date1 > date2) console .log(date1 < date2)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 function sum2 (num1, num2 ) return num1 + num2 } console .log(sum2(10 , 10 )) var autoHerSum = sum2console .log(autoHerSum(10 , 10 )) sum2 = null console .log(autoHerSum(10 , 10 )) function callSomeFunction (someFunction, someArgument ) return someFunction(someArgument) } function add10 (num ) return num + 10 } var result = callSomeFunction(add10, 10 )console .log(result) function getGreeting (name ) return "Hello," + name } var result2 = callSomeFunction(getGreeting, 'Nicholas' )console .log(result2) function createComparisonFunction (propertyName ) return function (object1, object2 ) var value1 = object1[propertyName] var value2 = object2[propertyName] if (value1 < value2) { return -1 } else if (value1 > value2) { return 1 } else { return 0 } } } function CreateObject (name, age ) this .name = name this .age = age } CreateObject.prototype.toString = function ( return `{name:${this .name} ,age:${this .age} }` } var object1 = new CreateObject('Zachary' , 28 )var object2 = new CreateObject('Nicholas' , 29 )var data = [object1, object2]data.sort(createComparisonFunction('name' )) console .log(data.toString())data.sort(createComparisonFunction('age' )) console .log(data.toString())function factorial (num ) if (num <= 1 ) { return 1 } else { return num * factorial(num - 1 ) } } console .log(factorial(10 )) function factorial2 (num ) if (num <= 1 ) { return 1 } else { return num * arguments .callee(num - 1 ) } } console .log(factorial2(10 ))var color5 = 'red' var o = { color5: 'blue' } function sayColor ( console .log(this .color5) } sayColor() o.sayColor = sayColor o.sayColor()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 function sum4 (num1, num2 ) return num1 + num2 } function callSum1 (num1, num2 ) return sum4.apply(this , arguments ) } function callSum2 (num1, num2 ) return sum4.apply(this , [num1, num2]) } console .log(callSum1(10 , 10 )) console .log(callSum2(10 , 10 )) function callSum3 (num1, num2 ) return sum4.call(this , num1, num2) } console .log(callSum3(10 , 10 ))
js的连续赋值 1 2 3 4 5 var a = {n : 1 }var b = a;a.x = a = {n : 2 } console .log(a.x); console .log(b.x)
首先是
1 2 var a = {n:1}; var b = a;
在这里a指向了一个对象{n:1}(我们姑且称它为对象A),
b指向了a所指向的对象,也就是说,在这时候a和b都是指向对象A的,
接着继续看下一行非常重要的代码:a.x = a = {n: 2},这句话也是关键所在,根据js引擎语法解析,会先去从左到右寻找有没有未声明的变量 ,如果有就把该变量提升至作用域顶部并声明该变量。那么恭喜js引擎他找到a.x这个属性没有声明,那么他会在{n: 1}这个内存区声明一个x属性等待赋值!
接着按照从左到右的寻找变量顺序运行,a = {n: 2};,运行以后a的指向变成了一个新地址。
ok,接下来是最关键的一步,解析变量/变量名是从左往右的,但是运行的时候实际顺序是从右往左的,这个时候原先的a.x已经改变了表达方式,如图上的红圈,这个部分是a.x,而不是这个栈内存中的a指针所指向的地方,js里面很多东西讲的都是值本身,而非指针,所以最后的结果也并不难以理解了。
引用类型 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 var s1 = 'some text' ;var s2 = s1.substring(2 );console .log(s1, s2) var s3 = new String ('some text' )var s4 = s1.substring(2 )s3 = null console .log(s3, s4) var s5 = 'some text' ;s5.color = 'red' console .log(s5.color) var obj = new Object ('some text' )console .log(obj instanceof String )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 var BooleanObject = new Boolean (true )var falseObject = new Boolean (false )console .log(falseObject)var result = falseObject && true console .log(result) var falseValue = false result = falseValue && true console .log(result)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 var text = 'cat,bat,sat,fat' result = text.replace(/(.at)/g , 'word($`)' ) console .log(result)function htmlEscape (text ) return text.replace(/[<>"&]/g , function (match, pos, originalText ) switch (match) { case "<" : return "<" case ">" : return ">" case "&" : return "&" case "\"" : return """ } }) } console .log(htmlEscape('<p class="greeting">hello world!</p>' ))var colorText = "red,blue,green,yellow" console .log(colorText.split(',' )) console .log(colorText.split(',' , 2 )) console .log(colorText.split(/[^\,]+/ )) var stringValue = 'yellow' console .log(stringValue.localeCompare('brick' )) console .log(stringValue.localeCompare('yellow' )) console .log(stringValue.localeCompare('zoo' ))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 function selectFrom (min, max ) var choices = max - min + 1 ; return Math .floor(Math .random() * choices + min) } console .log(selectFrom(2 , 10 ))
面向对象 虽然说在JavaScript编程语言中,函数是第一公民 ,但是JavaScript不仅支持函数式编程,也支持面向对象编程。JavaScript对象设计成了一组属性的无序集合,由key和value组成,key为一个标识符名称,而value可以是任意类型的值,当函数作为对象的属性值时,这个函数就可以称之为对象的方法。
1.JavaScript创建对象的方式
一般地,常用于创建对象的方式有两种,早期经常使用Object类,通过new关键字来创建一个对象,有点类似于Java中创建对象,后来为了方便就直接使用对象字面量的方式来创建对象了,用法更为简洁。
使用Object类创建对象;
1 2 3 4 const obj = new Object () obj.name = 'curry' obj.age = 30
使用对象字面量创建对象;
1 2 3 4 5 const obj = { name: 'curry' , age: 30 }
2.对象属性操作的控制
对象创建出来后,如何对该对象进行操作控制呢?这里涉及到一个很重要的方法:Object.defineProperty()。
2.1.Object.defineProperty()
该方法可以在对象上定义一个新的属性,也可修 改对象现有属性,并将该对象返回。
1 Object.defineProperty(obj, prop, descriptor)
接收三个参数:
obj:指定操作的对象;
prop:指定需要定义或修改的属性名称;
description:定义或修改的属性描述符;
2.2.属性描述符的分类
什么是属性描述符?顾名思义就是对对象中的属性进行描述,简单来说就是给对象某个属性指定一些规则。属性描述符主要分为数据属性描述符 和存取属性描述符 两种类型。
对于属性描述符中的属性是否两者都可以设置呢?其实数据和存取属性描述符两者是有区别,下面的表格统计了两者可用和不可用的属性:
属性
configurable
enumerable
value
writable
get
set
数据属性描述符
可以
可以
可以
可以
不可以
不可以
存取属性描述符
可以
可以
不可以
不可以
可以
可以
那么为什么有些属性可以用,有些属性又不能用呢?因为数据属性描述符和存取属性描述符所担任的角色不一样,下面就来详细介绍一下,它们两者的区别。
2.3.数据属性描述符
从上面的表格可以知道,数据属性描述符可以使用configurable、enumerable、value、writable。而这就是数据属性描述符的四个特性。
Configurable :表示是否可以通过delete删除对象属性,是否可以修改它的特性,或者是否可以将它修改为存取属性描述符。当通过new Object()或者字面量的方式创建对象时,其中的属性的configurable默认为true,当通过属性描述符定义一个属性时,其属性的configurable默认为false。Enumerable :表示是否可以通过for-in或者Object.keys()返回该属性。当通过new Object()或者字面量的方式创建对象时,其中的属性的enumerable默认为true,当通过属性描述符定义一个属性时,其属性的enumerable默认为false。Writable :表示是否可以修改属性的值。当通过new Object()或者字面量的方式创建对象时,其中的属性的writable性描述符定义一个属性时,其属性的writable默认为false。Value :属性的value值,读取属性时会返回该值,修改属性时会对其进行修改。(默认:undefined)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 const obj = { name: 'curry' } Object .defineProperty(obj, 'age' , { configurable: false , enumerable: false , writable: false , value: 30 }) delete obj.ageconsole .log(obj) obj.age = 18 console .log(obj)
1 2 3 4 for (const key in obj) { console .log(key) }
2.4.存取属性描述符
存取属性描述符可以使用configurable、enumerable、get、set。在获取对象某个属性值时,可以通过get来拦截,在设置对象某个属性值时,可以通过set来拦截。configurable和enumerable的用法和特性跟数据属性描述符一样。
Get :获取属性时会执行的函数。(默认undefined)Set :设置属性时会执行的函数。(默认undefined)
get和set的使用场景:
2.5.同时给多个属性定义属性描述符
上面使用Object.defineProperty()方法都是给单个属性进行定义描述符,想要一次性定义多个属性,那么就可以使用Object.defineProperties()方法了。写法如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 Object .defineProperties(obj, { name: { configurable: true , enumerable: true , writable: true , value: 'curry' }, age: { configurable: false , enumerable: false , get : function() { return this ._age }, set : function(newValue) { this ._age = newValue } } })
3.Object中常用的方法
上面介绍了Object中defineProperty和defineProperties两个方法。其实Object中还有很多方法,下面介绍一些常用的。
获取对象的属性描述符:
获取单个属性:Object.getOwnPropertyDescriptor;
获取所有属性:Object.getOwnPropertyDescriptors;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 const obj = { name: 'curry' , age: 30 } console .log(Object .getOwnPropertyDescriptor(obj, 'age' )) console .log(Object .getOwnPropertyDescriptors(obj))
Object.preventExtensions():禁止对象扩展新属性,给一个对象添加新的属性会失败(在严格模式下会报错)。
Object.seal():将对象密封起来,不允许配置和删除属性。(实际还是调用preventExtensions,并且将现有属性的configurable设置为false)
Object.freeze():将对象冻结起来,不允许修改对象现有属性。(实际上是调用seal,并且将现有属性的writable设置为false)
4.JavaScript创建多个对象
上面提到的创建对象的方式仅适用于创建单个对象适用,如果有多个对象比较类似,那么一个个创建必然是很麻烦的,如何批量创建对象呢?JavaScript也给我们提供了一些方案。
4.1.方案一:工厂函数
如果我们不想在创建对象时做重复的工作,那么就可以定义一个函数为我们去做这些重复性的工作,我们只需要将属性对应的值传入函数即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 function createObj (name, age ) const obj = {} obj.name = name obj.age = age obj.sayHello = function ( console .log(`My name is ${this .namename} , I'm ${this .age} years old.` ) } return obj } const obj1 = createObj('curry' , 30 )const obj2 = createObj('kobe' , 24 )console .log(obj1) console .log(obj2) obj1.sayHello() obj2.sayHello()
缺点 :创建出来的对象全是通过字面量创建的,获取不到对象真实的类型。
4.2.方案二:构造函数 (1)什么是构造函数?
构造函数也称之为构造器(constructor),通常是我们在创建对象时会调用的函数;
在其他面向对象的编程语言里面,构造函数是存在于类中的一个方法,称之为构造方法;
如果一个普通的函数被使用new操作符来调用 了,那么这个函数就称之为是一个构造函数;
一般规定构造函数的函数名首字母大写;
(2)new操作符调用函数的作用
当一个函数被new操作符调用了,默认会进行如下几部操作:
在内存中创建一个新的对象 (空对象);
这个对象内部的**[[prototype]]属性会被赋值为该 构造函数的prototype属性**;
构造函数内部的this,会指向创建出来的新对象 ;
执行函数的内部代码 (函数体代码);
如果构造函数没有返回对象 ,则默认返回创建出来的新对象。
(3)构造函数创建对象的过程
通过构造函数创建的对象就真实的类型了,如下所示的Person类型;
1 2 3 4 5 6 7 8 9 10 11 12 13 function Person (name, age ) this .name = name this .age = age this .sayHello = function ( console .log(`My name is ${this .name} , I'm ${this .age} years old.` ) } } const p1 = new Person('curry' , 30 )const p2 = new Person('kobe' , 24 )console .log(p1) console .log(p2)
缺点 :在每次使用new创建新对象时,会重新给每个对象创建新的属性,包括对象中方法,实际上,对象中的方法是可以共用的,消耗了不必要的内存。
1 console .log(p1.sayHello === p2.sayHello)
4.3.方案三:原型+构造函数
在了解该方案之前,需要先简单的认识一下何为原型。
(1)对象的原型
JavaScript中每个对象都有一个特殊的内置属性[[prototype]](我们称之为隐式原型 ),这个特殊的属性指向另外一个对象。那么这个属性有什么用呢?
前面介绍了,当我们通过对象的key来获取对应的value时,会触发对象的get操作;
首先,get操作会先查看该对象自身是否有对应的属性,如果有就找到并返回其值;
如果在对象自身没有找到该属性就会去对象的[[prototype]]这个内置属性中查找;
那么对象的[[prototype]]属性怎么获取呢?主要有两种方法:
通过对象的__proto__属性访问;
通过Object.getPrototypeOf()方法获取;
1 2 3 4 5 6 7 const obj = { name: 'curry' , age: 30 } console .log(obj.__proto__)console .log(Object .getPrototypeOf(obj))
(2)函数的原型
所有的函数都有一个prototype属性,并且只有函数才有这个属性。前面提到了new操作符是如何在内存中创建一个对象,并给我们返回创建出来的对象,其中第二步这个对象内部的[[prototype]]属性会被赋值为该构造函数的prototype属性 。将代码与图结合,来看一下具体的过程。
示例代码:
1 2 3 4 5 6 7 8 9 10 function Person(name, age) { this.name = name this.age = age } const p1 = new Person('curry', 30) const p2 = new Person('kobe', 24) // 验证:对象(p1\p2)内部的[[prototype]]属性(__proto__)会被赋值为该构造函数(Person)的prototype属性; console.log(p1.__proto__ === Person.prototype) // true console.log(p2.__proto__ === Person.prototype) // true
内存表现:
p1和p2的原型都指向Person函数的prototype原型;
其中还有一个constructor属性,默认原型上都会有这个属性,并且指向当前的函数对象;
(3)结合对象和函数的原型,创建对象
先简单的总结一下:
前面使用构造函数创建对象的缺点是对象中的方法不能共用;
对象的属性可以通过[[prototype]]隐式原型进行查找;
构造函数创建出来的对象[[prototype]]与构造函数prototype指向同一个对象(同一个地址空间);
那么我们可以将普通的属性放在构造函数的内部,将方法放在构造函数的原型上,当查找方法时,就都会去到构造函数的原型上,从而实现方法共用;
1 2 3 4 5 6 7 8 9 10 11 12 13 function Person (name, age ) this .name = name this .age = age } Person.prototype.sayHello = function ( console .log(`My name is ${this .name} , I'm ${this .age} years old.` ) } const p1 = new Person('curry' , 30 )const p2 = new Person('kobe' , 24 )console .log(p1.sayHello === p2.sayHello)
4.4.其他 创建对象的模式还有许许多多,包括不限于动态原型模式、寄生构造函数模式、稳妥构造函数模式、``
原型模式 原型模式是一种设计模式,那么为什么要在JavaScript这章里面单独拿出来讲呢,因为js可以归纳为是一门基于原型的面向对象语言。基于原型这个概念是深入进js的基因的,所以在这里单独开一章。
简单地说,JavaScript 是基于原型的语言 。当我们调用一个对象的属性时,如果对象没有该属性,JavaScript 解释器就会从对象的原型对象上去找该属性,如果原型上也没有该属性,那就去找原型的原型,直到最后返回null为止,null没有原型。这种属性查找的方式被称为原型链(prototype chain)。
JavaScript原型 & 原型链
首先来一个总纲,总纲里面包括了原型/原型链的所有内容,然后我们把图拆解。
想要弄清楚原型和原型链,这几个属性必须要搞清楚,__proto__、prototype、 constructor。
其次你要知道js中对象和函数的关系,函数其实是对象的一种。
最后你要知道函数、构造函数的区别,任何函数都可以作为构造函数,但是并不能将任意函数叫做构造函数,只有当一个函数通过new关键字调用的时候才可以成为构造函数。如:
1 2 3 4 5 6 7 var Parent = function (} var p1 = new Parent();
我们再引出一个概念,开始说过了要想清楚原型就要先搞清楚这三个属性,__proto__、prototype、 constructor。
1.__proto__、 constructor属性是对象所独有的;prototype属性是函数独有的;__proto__、 constructor;
下面开始进入正题,我将上面的一张图拆分成3张图,分别讲解对应的3个属性。
1.prototype属性 为了方便举例,我们在这模拟一个场景,父类比作师父,子类比作徒弟。师父收徒弟,
prototype属性可以看成是一块特殊的存储空间,存储了供“徒弟”、“徒孙”们使用的方法和属性。
它是函数独有的属性,从图中可以看到它从一个函数指向另一个对象,代表这个对象是这个函数的原型对象,这个对象也是当前函数所创建的实例的原型对象。prototype设计之初就是为了实现继承,让由特定函数创建的所有实例共享属性和方法,也可以说是让某一个构造函数实例化的所有对象可以找到公共的方法和属性。有了prototype我们不需要为每一个实例创建重复的属性方法,而是将属性方法创建在构造函数的原型对象上(prototype)。那些不需要共享的才创建在构造函数中。
1 Parent.prototype.name = "我是原型属性,所有实例都可以读取到我" ;
这就是原型属性,当然你也可以添加原型方法。那问题来了,p1怎么知道他的原型对象上有这个方法呢,往下看↓↓↓
2.proto属性 __proto__属性相当于通往prototype(“琅琊福地”)唯一的路(指针)
__proto__属性是对象(包括函数)独有的。从图中可以看到__proto__属性是从一个对象指向另一个对象,即从一个对象指向该对象的原型对象(也可以理解为父对象)。显然它的含义就是告诉我们一个对象的原型对象是谁。Parent.prototype上添加的属性和方法叫做原型属性和原型方法,该构造函数的实例都可以访问调用。那这个构造函数的原型对象上的属性和方法,怎么能和构造函数的实例联系在一起呢,就是通过__proto__属性。每个对象都有__proto__属性,该属性指向的就是该对象的原型对象。
1 p1.__proto__ === Parent.prototype;
__proto__通常称为隐式原型,prototype通常称为显式原型,那我们可以说一个对象的隐式原型指向了该对象的构造函数的显式原型。那么我们在显式原型上定义的属性方法,通过隐式原型传递给了构造函数的实例。这样一来实例就能很容易的访问到构造函数原型上的方法和属性了。__proto__属性是对象(包括函数)独有的,那么Parent.prototype也是对象,那它有隐式原型么?又指向谁?
1 Parent.prototype.__proto__ === Object .prototype;
可以看到,构造函数的原型对象上的隐式原型对象指向了Object的原型对象。那么Parent的原型对象就继承了Object的原型对象。由此我们可以验证一个结论,万物继承自Object.prototype。这也就是为什么我们可以实例化一个对象,并且可以调用该对象上没有的属性和方法了。如:
我们可以调用很多我们没有定义的方法,这些方法是哪来的呢?现在引出原型链的概念,当我们调用p1.toString()的时候,先在p1对象本身寻找,没有找到则通过p1.__proto__找到了原型对象Parent.prototype,也没有找到,又通过Parent.prototype.__proto__找到了上一层原型对象Object.prototype。在这一层找到了toString方法。返回该方法供p1使用。Object.prototype.__proto__中寻找,但是Object.prototype.__proto__ === null所以就返回undefined。这就是为什么当访问对象中一个不存在的属性时,返回undefined了。
3.constructor属性 constructor属性是让“徒弟”、“徒孙” 们知道是谁创造了自己,这里可不是“师父”啊
补丁:上面的说法严格来讲并不正确,明显在逻辑上有一些不通顺的地方,那是因为:constructor属性本质上只有prototype对象才有,也就是说构造函数.prototype.contructor === 该构造函数,实例对象之所以会有是只是通过_proto继承来自其构造函数的原型对象。
所以p1 => Parent() => Function()这里的contructor属性应该用虚线表示,注明来自继承得来。
可以通过
1 2 p1.hasOwnProperty('constructor' ) Parent.prototype.hasOwnProperty('constructor' )
得到验证。
constructor是对象才有的属性,从图中看到它是从一个对象指向一个函数的。指向的函数就是该对象的构造函数。每个对象都有构造函数,好比我们上面的代码p1就是一个对象,那p1的构造函数是谁呢?我们打印一下。
1 console .log(p1.constructor);
通过输出结果看到,很显然是Parent函数。我们有说过函数也是对象,那Parent函数是不是也有构造函数呢?显然是有的。再次打印下。
1 console .log(Parent.constructor);
通过输出看到Parent函数的构造函数是Function(),这点也不奇怪,因为我们每次定义函数其实都是调用了new Function(),下面两种效果是一样的。
1 2 3 4 var fn1 = new Function ('msg' ,'alert(msg)' );function fn1 (msg ) alert(msg); }
那么我们再回来看下,再次打印Function.constructor
1 console .log(Function .constructor);
可以看到Function函数的构造函数就是本身了,那我们也就可以说Function是所有函数的根构造函数。p1的constructor属性指向了Parent,那么Parent就是p1的构造函数。同样Parent的constructor属性指向了Function,那么Function就是Parent的构造函数,然后又验证了Function就是根构造函数。
脑筋急转弯之 存在没有原型的对象吗?使用Objetct.create(null)可以创建出没有原型的对象。
4.总结 ok,上面的比喻是为了初学者能够方便的理解原型和原型链,下面梳理一下流程。
在这个过程里面,关于prototype我觉得有两个理解含义,在箭头上面的prototype有点类似于.prototype指针的意思,而Person.prototype毫无疑问就是常规意义上的原型对象。
5.使用习惯 关于构造函数,咱们引入一些使用习惯:
1 2 3 4 5 6 7 8 9 10 funcion A(name) { this .name = name; this .arr = [1 ]; this .say = function ( console .log('hello' ) } }
原型对象的使用习惯
原型对象的用途是为每个实例对象存储共享的方法和属性,它仅仅是一个普通对象而已。并且所有的实例是共享同一个原型对象,因此有别于实例方法或属性,原型对象仅有一份。而实例有很多份,且实例属性和方法是独立的。
在构造函数中:为了属性(实例基本属性)的私有性、以及方法(实例引用属性)的复用、共享。我们提倡:
1 2 3 4 5 6 funcion A(name) { this .name = name; } A.prototype.say = function ( console .log('hello' ) }
1 2 3 4 5 6 A.prototype = { say: function ( console .log('hello' ) } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 function Person ( this .name = 'John' ; } var person = new Person();Person.prototype.say = function ( console .log('Hello,' + this .name); }; person.say(); function Person ( this .name = 'John' ; } var person = new Person(); Person.prototype = { say: function ( console .log('Hello,' + this .name); } }; person.say();
JS继承
js中的继承有多种方式,大体上就是两种,一种是基于原型链覆盖的形式、一种是对象冒充也就是通过改变this指向。支持多继承,通过原型链可以一直往上找。
1.原型链继承 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 function Parent ( this .x = 100 ; } Parent.prototype.getX = function getX ( return this .x; } function Child ( this .y = 200 ; } Child.prototype = new Parent; Child.prototype.getY = function getY ( return this .y; } var child1 = new Child;
优点:父类方法可以复用
缺点:
1.父类所有的引用类型数据(对象,数组)会被子类共享,更改一个子类的数据,其他数据会受到影响,一直变化。
2.子类实例不能给父类构造函数传参
2.构造函数继承 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 function Person ( this .name = '小明' this .eats = ['苹果' ] this .getName = () => console .log(this .name) }; }; Person.prototype.get = () => console .log("Person.prototype上的方法" ) }; function Student ( Person.call(this ) } const stu1 = new Student;console .log(stu1.name);console .log(stu1.eats);stu1.getName(); stu1.get(); console .log(stu1)
这种情况下,在Child的构造函数中,使用Parent.call(this)直接调用了Parent的“构造函数”,这里是要突出这个引号,原因是其实只调用了这个函数,严格意义上并不能称之为构造函数,在JS中只有创建了实例的函数才能叫构造函数,但是在此例中并没有构造实例,也就造成了一个问题——因为并没有构造实例,并不会触发Parent.prototype,所以是没法调用到上面的getX的。
这种方式的优点是 父类的引用类型不会被子类共享,不会互相影响。
缺点是不能访问父类的原型属性(因为父类的原型属性根本没被创造出来)
3.组合继承 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 function Person ( this .name = '小明' this .eats = ['苹果' ] this .getName = () => console .log(this .name) }; }; Person.prototype.get = () => console .log("Person.prototype上的方法" ) }; function Student ( Person.call(this ) } Student.prototype = new Person(); const stu1 = new Student;console .log(stu1.name);console .log(stu1.eats);stu1.getName(); stu1.get(); console .log(stu1)
这种方式相当于是上面两种的合体,这种方式在第二种的前提上,真正的把父类的对象创建了,所以自然也就会调用到父类的原型对象。也能用到里面的方法。
但是这个里面也会有一个缺点。
可以看到,只需要一份的数据,在这种继承模式下,会分别在父类和子类里面都有一份,虽然能满足需求但是性能会比较差一点。
4.寄生组合继承 细推上面那种方式,想知道父类里面的重复数据是哪里来的,其实就是父类在创建对象的过程中,Student.prototype = new Person();这里把Person对象创建出来重新加载了一次。如果这个Person构造函数中没有属性的话(只有父类的原型对象有),其实是满足我们要求的。
考虑到这,那么有没有办法能够忽略到父类构造函数中属性的方法呢?
有的,使用解几何题中常见的手段——辅助线(中间函数)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 function Person ( this .name = '小明' this .eats = ['苹果' ] this .getName = () => console .log(this .name) }; }; Person.prototype.get = () => console .log("Person.prototype上的方法" ) }; function Student ( Person.call(this ) } const Fn = function (Fn.prototype = Person.prototype Student.prototype = new Fn() const stu1 = new Student;console .log(stu1.name);console .log(stu1.eats);stu1.getName(); stu1.get(); console .log(stu1)
使用Fn指向Person的原型对象,然后新建一个Fn,这样就相当于构建了一个没有属性的父类,等效的。
理论上是比较优秀的方案。
5.ES6自带继承 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Parent constructor (){ this .x=100 ; } getX(){ retrun this .x; } } class Child extends Parent constructor (){ super (); this .y=200 ; } getY(){ retrun this .y; } }
是更新之后,语言自己给出的解决方案。添加了一些class extend等新概念。
函数表达式 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 function functionName ( } var functionName2 = function ( } var x = function (a, b ) return a * b};var x = function (a, b ) return a * b};var z = x(4 , 3 );var x = function (a, b ) return a * b};var z = x(4 , 3 );var myFunction = new Function ("a" , "b" , "return a * b" );var x = myFunction(4 , 3 ); myFunction(5 ); function myFunction (y ) return y * y; } (function ( var x = "Hello!!" ; })();
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 function factorial (num ) if (num <= 1 ) { return 1 } else { return num * arguments .callee(num - 1 ) } } var factorial2 = (function f (num ) if (num <= 1 ) { return 1 } else { return num * f(num - 1 ) } })
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 function myFunction ( var a = 4 ; return a * a; } var a = 4 ;function myFunction ( return a * a; } var counter = 0 ; function add ( return counter += 1 ; } add(); add(); add(); function add ( var counter = 0 ; return counter += 1 ; } add(); add(); add(); function add ( var counter = 0 ; function plus (1 ;} plus(); return counter; } var add = (function ( var counter = 0 ; return function (return counter += 1 ;} })(); add(); add(); add();
…
BOM Browser Object Model
BOM的解释是:
1 2 3 4 5 BOM即浏览器对象模型。 BOM提供了独立于内容 而与浏览器窗口进行交互的对象; 由于BOM主要用于管理窗口与窗口之间的通讯,因此其核心对象是window; BOM由一系列相关的对象构成,并且每个对象都提供了很多方法与属性; BOM缺乏标准,JavaScript语法的标准化组织是ECMA,DOM的标准化组织是W3C,BOM最初是Netscape浏览器标准的一部分。
使用BOM,开发者可以操控浏览器显示页面之外的部分。而它最独特的地方,就是问题最多的地方,激素它唯一一个没有相关标注的javascript实现。总体来说,BOM主要针对的是浏览器窗口和子窗口,但是通常会把任何特定于浏览器的扩展都归于在BOM的范畴内。下面是一些拓展:
1 2 3 4 5 6 7 弹出新浏览器窗口的能力。 移动、缩放和关闭浏览器窗口的详近信息。 navigator对象,提供关于浏览器的详尽信息。 location对象,提供浏览器加载页面的详尽信息。 screen对象,提供关于用户屏幕分辨率的详尽信息。 performance对象,提供浏览器内存占用、导航行为和时间统计的详尽信息。 对cookie的支持。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 var pageWidth = window .innerWidth, pageHeight = window .innerHeight; if (typeof pageWidth !== "number" ) { if (document .compatMode === "CSS1Compat" ) { pageWidth = document .documentElement.clientWidth; pageHeight = document .documentElement.clientHeight; } else { pageWidth = document .body.clientWidth; pageHeight = document .body.clientHeight; } } function getQueryStringArgs ( var qs = (location.search.length > 0 ? location.search.substring(1 ) : "" ), args = {}, items = qs.length ? qs.split("&" ) : [], item = null , name = null , value = null , i = 0 , len = items.length; for (; i < len; i++) { item = items[i].split("=" ); name = decodeURIComponent (item[0 ]); value = decodeURIComponent (item[1 ]); if (name.length) { args[name] = value; } } return args; }
客户端检测 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 var browser={ versions:function ( var u = navigator.userAgent, app = navigator.appVersion; return { trident: u.indexOf('Trident' ) > -1 , presto: u.indexOf('Presto' ) > -1 , webKit: u.indexOf('AppleWebKit' ) > -1 , gecko: u.indexOf('Gecko' ) > -1 && u.indexOf('KHTML' ) == -1 , mobile: !!u.match(/AppleWebKit.*Mobile.*/ ), ios: !!u.match(/\(i[^;]+;( U;)? CPU.+Mac OS X/ ), android: u.indexOf('Android' ) > -1 || u.indexOf('Linux' ) > -1 , iPhone: u.indexOf('iPhone' ) > -1 , iPad: u.indexOf('iPad' ) > -1 , webApp: u.indexOf('Safari' ) == -1 , }; }(), language:(navigator.browserLanguage || navigator.language).toLowerCase() } alert(JSON .stringify(browser)); if (browser.versions.mobile) { var ua = navigator.userAgent.toLowerCase(); if (ua.match(/MicroMessenger/i ) === "micromessenger" ) { alert("微信" ); }else if (ua.match(/QQ/i ) === "qq" ){ alert("qq" ); } if (ua.match(/WeiBo/i ) === "weibo" ) { alert("新浪微博客户端" ); } if (browser.versions.ios) { alert("ios" ); } if (browser.versions.android){ alert("安卓浏览器" ); } }else { alert("pc" ); }
DOM 当网页被加载时,浏览器会创建页面的文档对象模型(Document Object Model)。
HTML DOM 模型被构造为对象 的树:
通过可编程的对象模型,JavaScript 获得了足够的能力来创建动态的 HTML。
JavaScript 能够改变页面中的所有 HTML 元素
JavaScript 能够改变页面中的所有 HTML 属性
JavaScript 能够改变页面中的所有 CSS 样式
JavaScript 能够对页面中的所有事件做出反应
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 function loadScript (url ) var script = document .createElement("script" ); script.type = "text/javascript" ; script.src = url; document .body.appendChild(script); } function loadScriptString (code ) var script = document .createElement("script" ); script.type = "text/javascript" ; try { script.appendChild(document .createTextNode(code)); } catch (ex){ script.text = code; } document .body.appendChild(script); } function loadStyles (url ) var link = document .createElement("link" ); link.rel = "stylesheet" ; link.type = "text/css" ; link.href = url; var head = document .getElementsByTagName("head" )[0 ]; head.appendChild(link); } function loadStyleString (css ) var style = document .createElement("style" ); style.type = "text/css" ; try { style.appendChild(document .createTextNode(css)); } catch (ex){ style.styleSheet.cssText = css; } var head = document .getElementsByTagName("head" )[0 ]; head.appendChild(style); } var table = document .createElement("table" );table.border = '1' ; table.width = "100%" ; var tbody = document .createElement("tbody" );table.appendChild(tbody); var row1 = document .createElement("tr" );tbody.appendChild(row1); var cell1_1 = document .createElement("td" );cell1_1.appendChild(document .createTextNode("Cell 1,1" )); row1.appendChild(cell1_1); var cell2_1 = document .createElement("td" );cell2_1.appendChild(document .createTextNode("Cell 2,1" )); row1.appendChild(cell2_1); var row2 = document .createElement("tr" );tbody.appendChild(row2); var cell1_2 = document .createElement("td" );cell1_2.appendChild(document .createTextNode("Cell 1,2" )); row2.appendChild(cell1_2); var cell2_2= document .createElement("td" );cell2_2.appendChild(document .createTextNode("Cell 2,2" )); row2.appendChild(cell2_2); document .body.appendChild(table);var table = document .createElement("table" );table.border = 1 ; table.width = "100%" ; var tbody = document .createElement("tbody" );table.appendChild(tbody); tbody.insertRow(0 ); tbody.rows[0 ].insertCell(0 ); tbody.rows[0 ].cells[0 ].appendChild(document .createTextNode("Cell 1,1" )); tbody.rows[0 ].insertCell(1 ); tbody.rows[0 ].cells[1 ].appendChild(document .createTextNode("Cell 2,1" )); tbody.insertRow(1 ); tbody.rows[1 ].insertCell(0 ); tbody.rows[1 ].cells[0 ].appendChild(document .createTextNode("Cell 1,2" )); tbody.rows[1 ].insertCell(1 ); tbody.rows[1 ].cells[1 ].appendChild(document .createTextNode("Cell 2,2" )); document .body.appendChild(table);var divs = document .getElementsByTagName("div" ), i, len, div; for (i=0 , len=divs.length; i < len; i++){ div = document .createElement("div" ); document .body.appendChild(div); } var classNames = div.className.split(/\s+/ );var pos = -1 , i, len; for (i=0 , len=classNames.length; i < len; i++){ if (classNames[i] === "user" ){ pos = i; break ; } } classNames.splice(i,1 ); div.className = classNames.join(" " ); div.classList.remove("disabled" ); div.classList.add("current" ); div.classList.toggle("user" ); var div = document .getElementById("myDiv" );var appId = div.dataset.appId;var myName = div.dataset.myname;div.dataset.appId = 23456 ; div.dataset.myname = "Michael" ; if (div.dataset.myname){ console .log("Hello, " + div.dataset.myname); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 function getViewport ( if (document .compatMode === "BackCompat" ) { return { width: document .body.clientWidth, height: document .body.clientHeight }; } else { return { width: document .documentElement.clientWidth, height: document .documentElement.clientHeight }; } } var docHeight = Math .max(document .documentElement.scrollHeight, document .documentElement.clientHeight); var docWidth = Math .max(document .documentElement.scrollWidth, document .documentElement.clientWidth); function getBoundingClientRect (element ) var scrollTop = document .documentElement.scrollTop; var scrollLeft = document .documentElement.scrollLeft; if (element.getBoundingClientRect) { if (typeof arguments .callee.offset != "number" ) { var temp = document .createElement("div" ); temp.style.cssText = "position:absolute;left:0;top:0;" ; document .body.appendChild(temp); arguments .callee.offset = -temp.getBoundingClientRect().top - scrollTop; document .body.removeChild(temp); temp = null ; } var rect = element.getBoundingClientRect(); var offset = arguments .callee.offset; return { left: rect.left + offset, right: rect.right + offset, top: rect.top + offset, bottom: rect.bottom + offset }; } else { var actualLeft = getElementLeft(element); var actualTop = getElementTop(element); return { left: actualLeft - scrollLeft, right: actualLeft + element.offsetWidth - scrollLeft, top: actualTop - scrollTop, bottom: actualTop + element.offsetHeight - scrollTop } } } var html = ` <div id="div1"> <p><b>Hello</b> world!</p> <ul> <li>List item 1</li> <li>List item 2</li> <li>List item 3</li> </ul> </div> ` document .body.innerHTML = htmlvar div = document .getElementById('div1' )var iterator = document .createNodeIterator(div, NodeFilter.SHOW_ELEMENT, null , false )var node = iterator.nextNode()while (node !== null ) { console .log(node.tagName) node = iterator.nextNode() } var div2 = document .getElementById("div1" );var walker = document .createTreeWalker(div2, NodeFilter.SHOW_ELEMENT, null , false ); walker.firstChild(); walker.nextSibling(); var node2 = walker.firstChild(); while (node2 !== null ) { console .log(node2.tagName); node2 = walker.nextSibling(); } var supportsRange = document .implementation.hasFeature("Range" , "2.0" );var alsoSupportsRange = (typeof document .createRange === "function" );var range1 = document .createRange(),range2 = document .createRange(); range1.selectNode(div2) range2.selectNodeContents(div2) console .log(range1,range2)
javascript 资料 现代JavaScript教程 https://zh.javascript.info/
VScode javascript windows
快捷键:
多行注释/取消:shift + alt + a
单行注释/取消:ctrl + /